支持向量机主要解决二维、三维、甚至更高维空间的分类问题。本文主要讲述在线性可分、线性不可分的各维度空间中,怎么利用SVM进行分类的问题。帮助大家更好的理解SVM的作用,求解过程,和涉及到的新的概念。
目录
一、SVM整体的核心逻辑
当你听到svm时是不是和小博一样感到头大,满脑子都是数学公式、超平面、核函数......但当具体问到svm究竟是什么,到底能解决什么问题时,我好像还真不太清楚。
没关系,小博带你来深度解读一下svm的核心逻辑。
用大白话说,svm就是四个字:划清界限。
想象一下,平面中有两类不同的点,如果你想把他们分开,会怎么做。
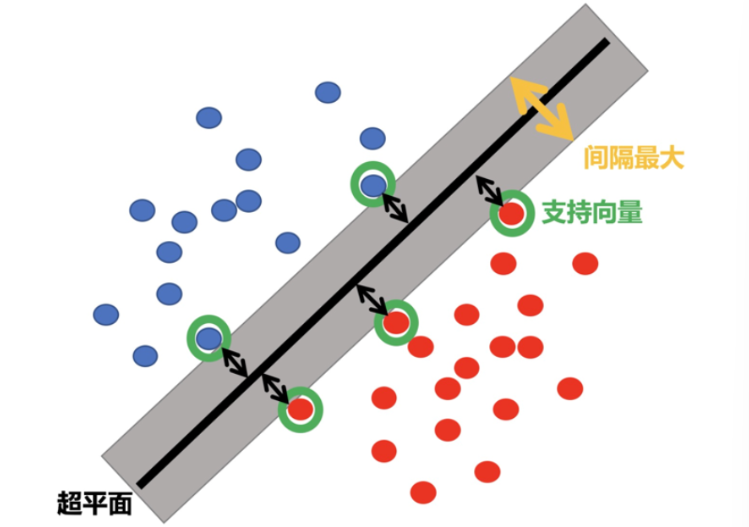
在二维平面中,我们可以通过一条直线将两群点分开,但svm是个强迫症,他不仅要分得开,还要分的完美,所以他的目标是:找到那条离两边都最远的直线。这条最终中间的直线就叫做**"最优超平面"。在平面的两边,我们要留出一段"无人区",这就叫"间隔"**。
我们要注意的是,在平面中虽然有成千上万个点,但真正决定这条线位置的,其实只有离直线最近的那几个点。这几个起决定性作用的"钉子户",就叫做支持向量。而该模型为什么叫做支持向量机,也就是因为他只需要这几个关键点就能支撑起整个分类体系。
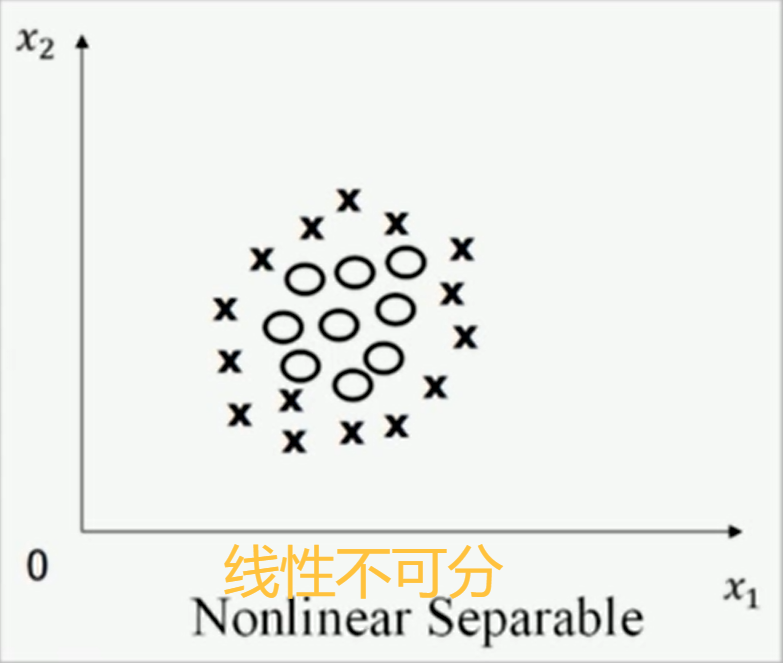
但是,如果我们遇到两类样本,用一条直线分不开怎么办?
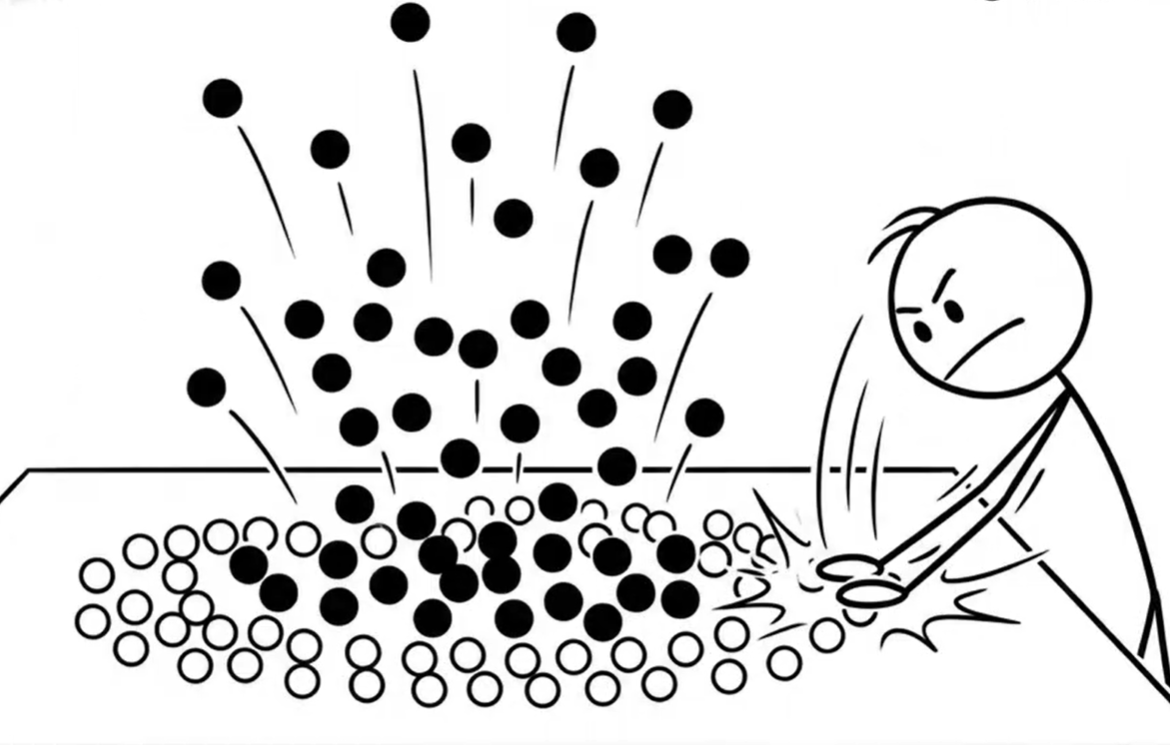
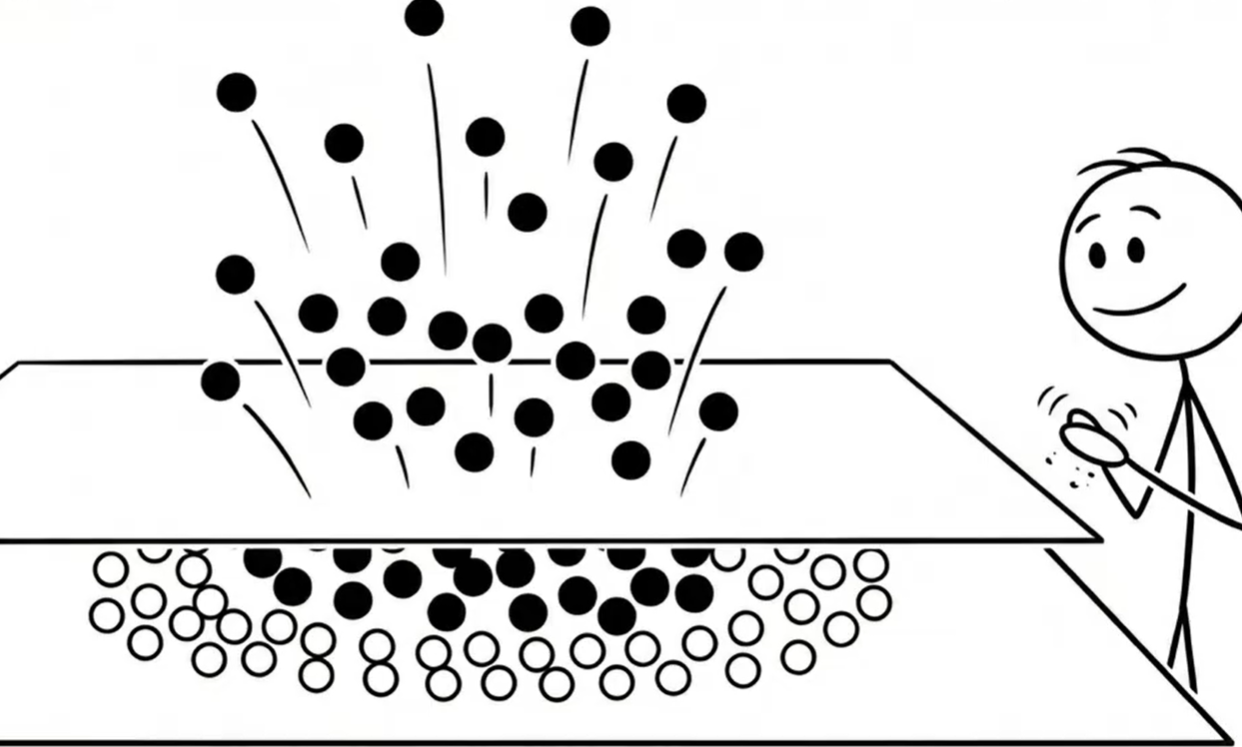
这就是svm发挥"绝招"的关键时候了,他是"降维打击"的反向操作:升维。这就是svm最神奇的地方:核函数。他能把在低维度分不开的东西,投射到高维度去。然后在中间插进一个平面,这不就分开了。
二、线性可分和线性不可分的定义
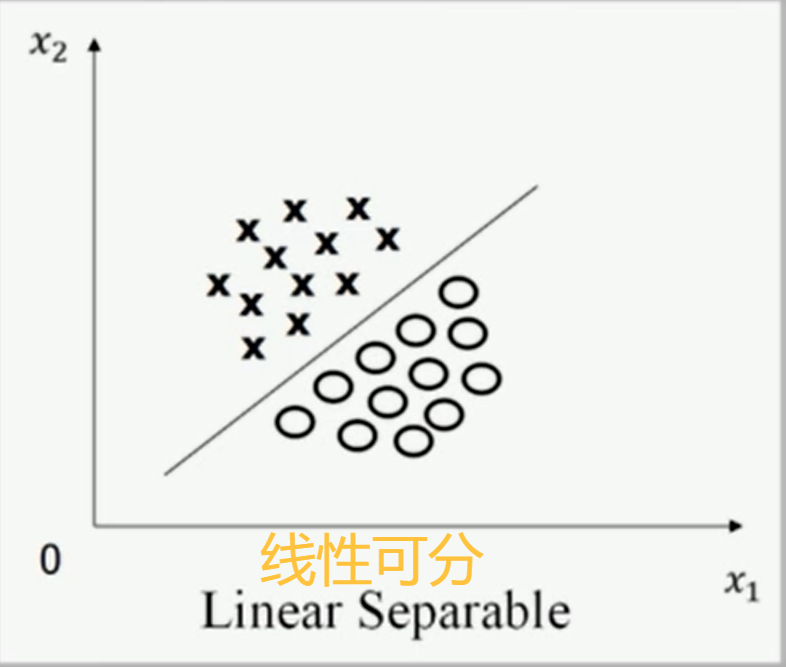
二维空间
直线划分
三维空间****
平面划分
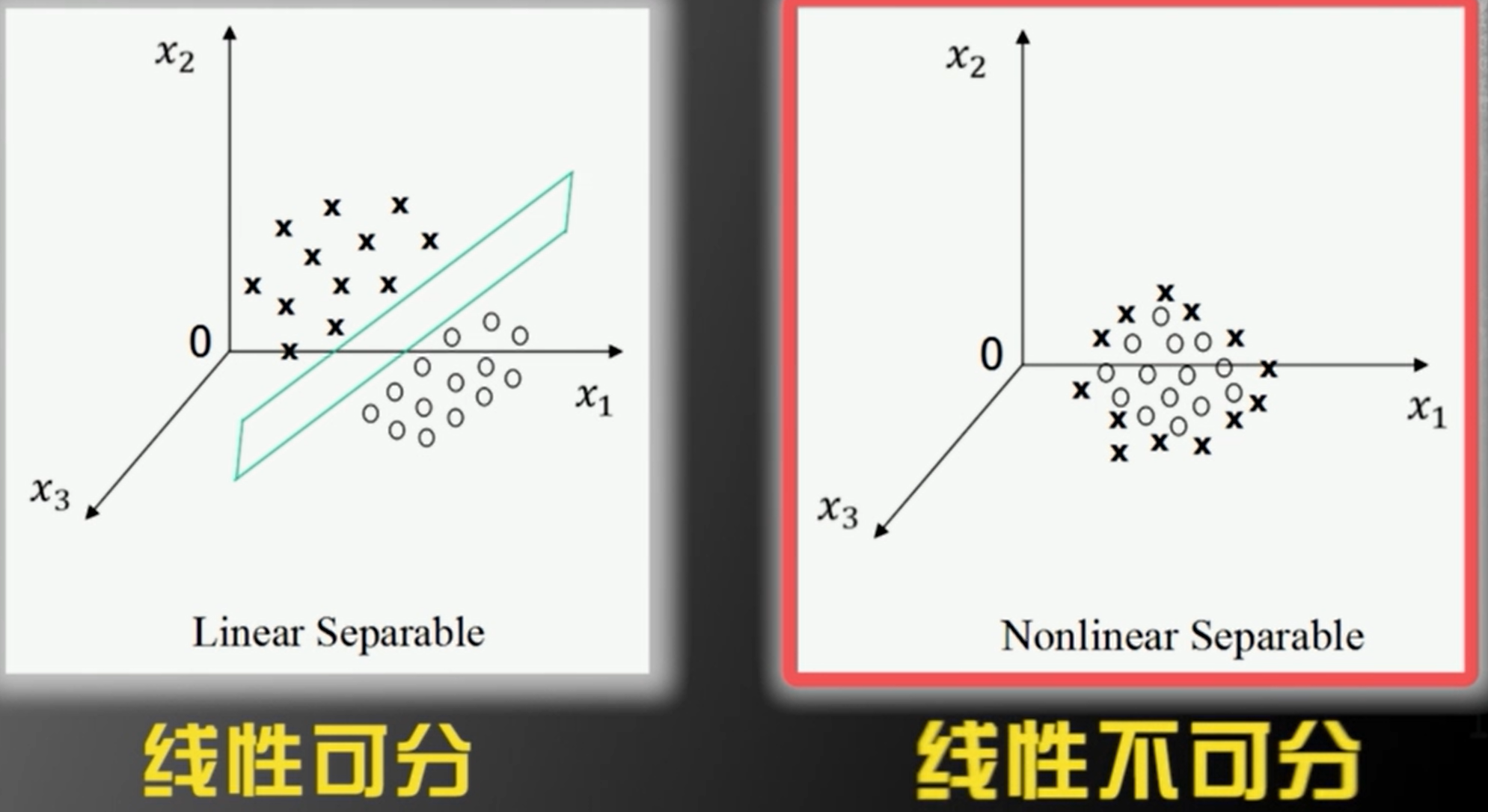
特征空间维度>3维
超平面划分,由于人眼对空间的感知只能达到3维,所以我们无法通过画图来区分线性是否可分的情况,这是我们就要借助数学,给线性可分和线性不可分一个精准的定义。
三、特征空间的数学定义
这里小博不过多解释原理的部分,主要是讲解公式的定义,帮助大家更通俗易懂的理解。
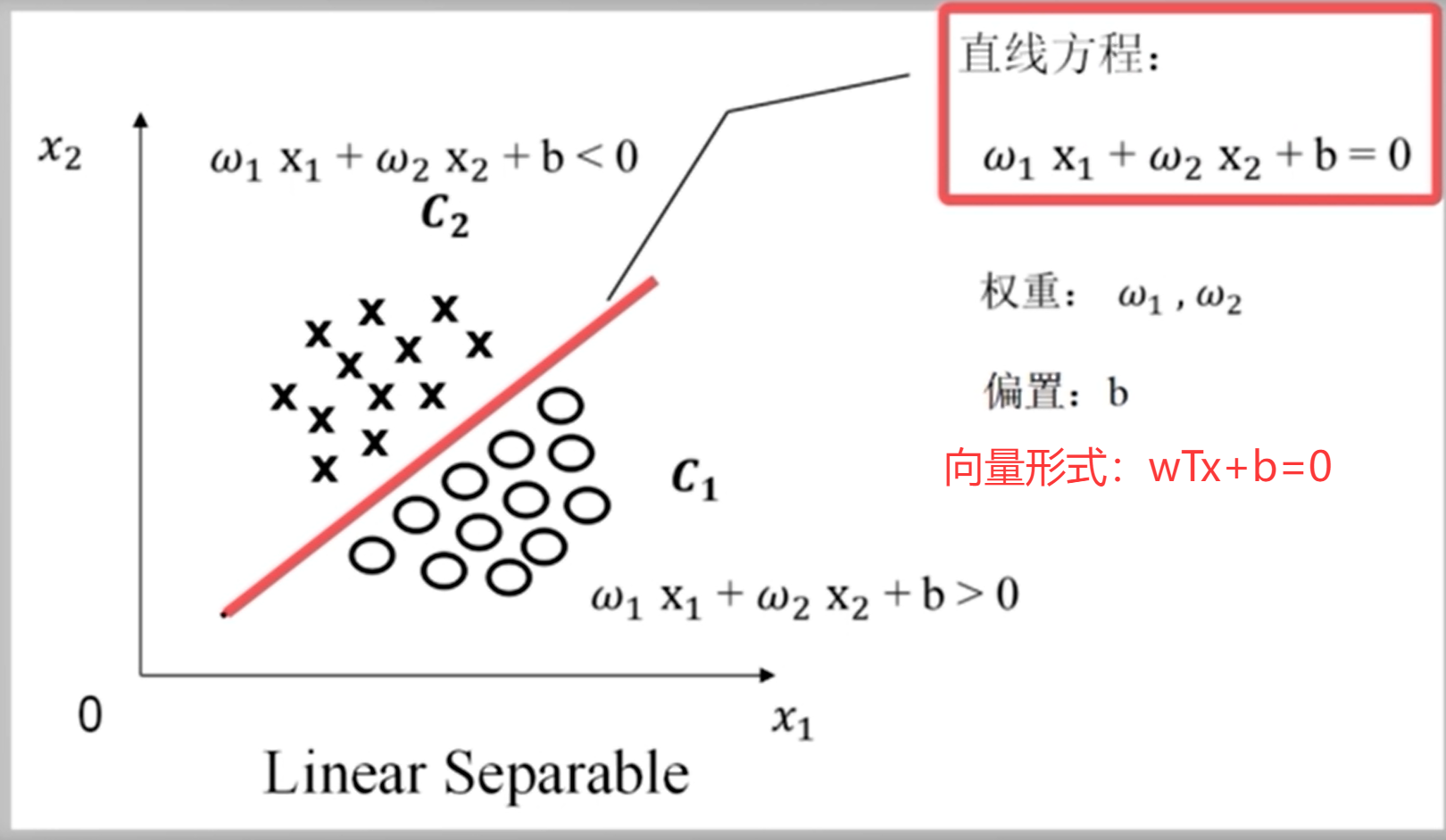
这里我们要理解一下,直线方程的写法:在 SVM 里 常写成: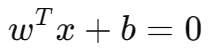
可以理解成:
- w决定超平面的方向
- b决定超平面的平移位置
其中 w 还是这个超平面的法向量。
首先,我们要理解一下这是怎么变换来的:

其次,要理解一下,为什么要进行转置:
在SVM中,样本本来就是多维特征组成的;而线性模型本质上就是对这些特征做加权求和。向量写法能把这个过程写得更简洁、更容易推广、更方便做几何分析和优化计算。
比如:
在机器学习里,一个样本通常不是只有两个量,而是很多个特征:
- 身高
- 体重
- 年龄
- 收入
- 点击次数
- 像素值
- 词频
- ...
这些特征放在一起,本来就最适合写成一个向量: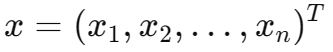
而每一个特征都有一个权重对应:
式子: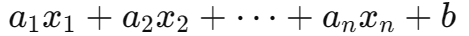
表示的是:
- 第1个特征乘一个权重
- 第2个特征乘一个权重
- ...
- 最后全加起来,再加偏置
这些权重也自然组成一个向量: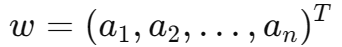
于是整个加权求和就是: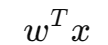
这比一项一项写简洁得多。

所以线性可分的定义可以表示为:
为了方便计算,我们通常可以
四、线性可分最优超平面求解
根据以上知识,我们可知,支持向量机寻找的最优分类直线应满足:
(1)该直线分开了两类;
(2)该直线最大化间隔(margin);
(3)该直线处于间隔的中间,到所有支持向距离相等。
根据这个思路,我们可以找到一个支持向量,通过求他到超平面的直线距离d即可;
1、转化为凸函数
我们都知道,点到直线的距离公式和向量计算公式如下:


由此我们可以将支持向量到超平面的距离表示为:
然而通过缩放,我们可以得出
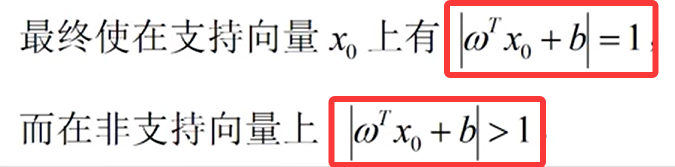
缩放过程小博推导如下:

最终支持向量到超平面的距离表示为:
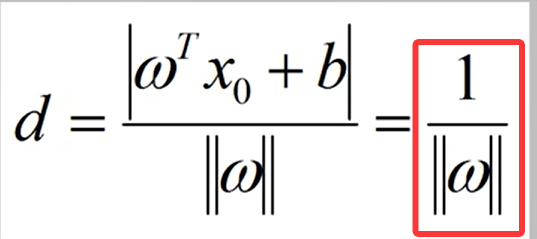
因此,最大化支持向量到超平面的距离,等价于最小化||w||。
最终我们将优化问题定为了:


即
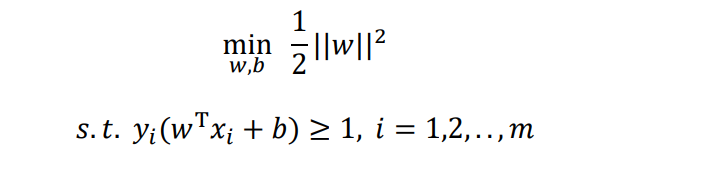
2、用拉格朗日乘子法和KKT条件求解最优值:
这部分大家不理解,可以先跳转到第八、第九部分,看一下原问题和对偶问题的关系,以及什么是KKT条件。

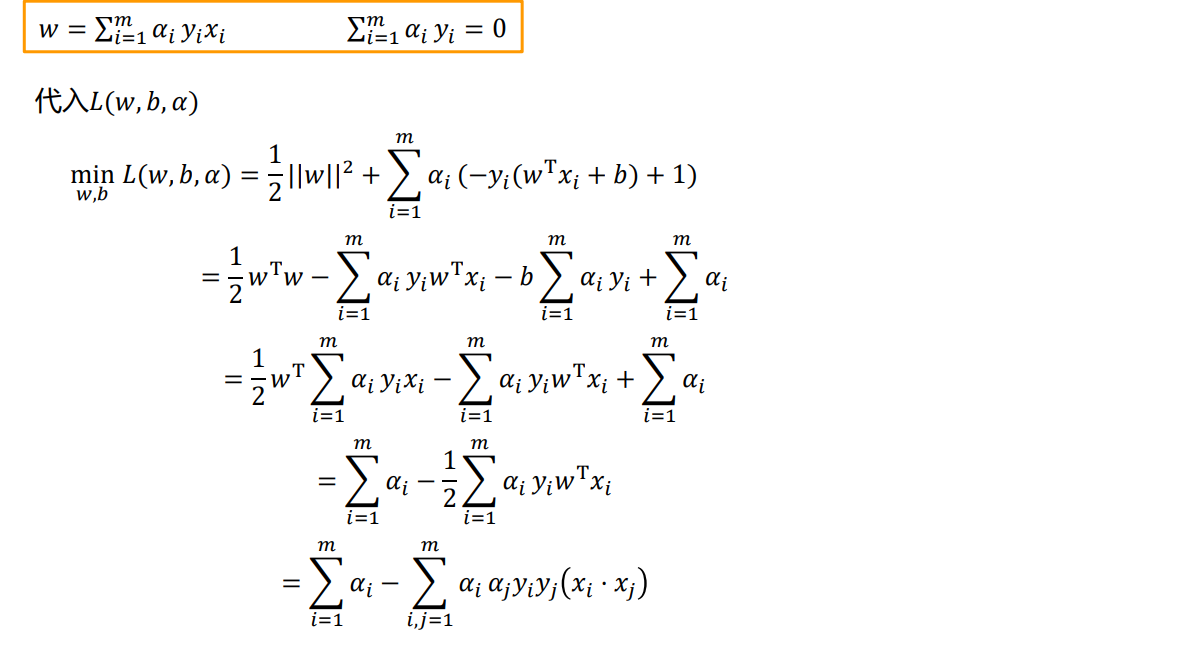
3、转化为对偶问题求解
这部分大家不理解的,可以先跳转到第八部分,看一下原问题和对偶问题的关系。

五、线性不可分的最优化超平面
对于线性不可分的情况,其实是不存在w和b,满足上面所以N个现在条件的,因此我们是需要适当的放松限制条件,使最优化问题有解。我们引入松弛变量。


其中,平衡两项的比例因子C,是人为设定的,称为算法的超参数,我们在实际应用中,会不断地变化C的值,去测试算法的识别率,选取使识别率达到最大的超参数C的值。一个算法中的超参数越多,就说明该算法需要手动优化的地方也就越多,算法的自动性就会降低。而支持向量机就是超参数很少的算法模型。
六、低纬到高纬的映射
在我们最初的了解中,我们知道svm有一个绝招,就是可以将低纬不可分的问题映射到高纬上去。这里小博就不将原理了,这里我们举个例子说明,如果一个二维空间映射到五维中,构造对应的映射为(x),那么支持向量机的优化问题就可以转化为

七、核函数的定义
根据上文,我们已经了解到了可以通过引入映射(x),来解决低维不可分的问题。那么所谓的
(x)究竟是什么呢?由于
(x)是比较复杂的,所以我们其实不用去研究
(x)的具体形式,而是引入了一个核函数,通过研究核函数和映射
(x)之间的关系进一步来解决。
核函数用**K(X1,X2)**表示,它是一个数,其中X1、X2分别是样本类别。等于(X1)的转置这个行向量,和维度相同的列向量
(X2)的乘积。核函数和低纬到高纬的映射
(x)之间的相互关系可以表示为:
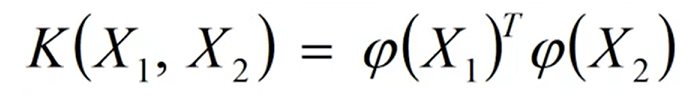
我们举个例子来证明一下,假设(x)是一个将二维向量映射到三维向量的映射:
(x)可表示为:
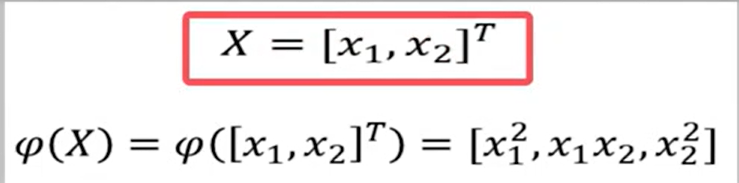
已知(x),则
(x)对应的核函数K(X1,X2)可表示为:
假设有两个二维向量X1,X2,分别有两个分量组成:
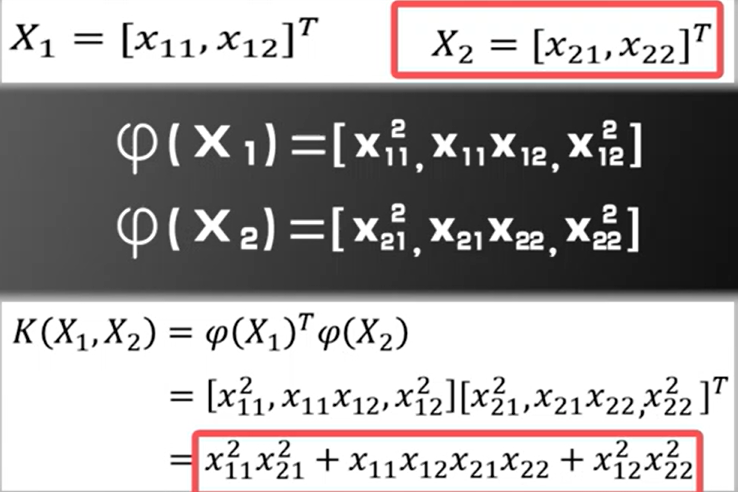
已知核函数K,则对应的映射(x)可表示为:
假设有两个二维向量X1,X2,分别有两个分量组成:
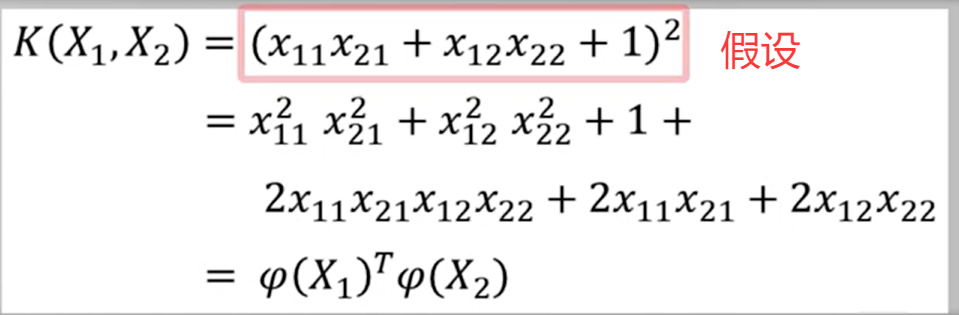
通过观察,我们可以看出核函数K和映射(x)是一一对应关系,知道其中一个就可以求出另一个,然而要注意,核函数K的形式不能随意取,需要满足一定的条件,才能写成两个
(x)内积的形式。

这里,我们不用去纠结什么什么是半正定性,了解即可,知道需要满足这两个条件,才能写出(x)内积的形式即可。
八、原问题和对偶问题
一般在优化问题中经常用到,通过求出对偶问题的解,来求出对应的原问题的解。接下来,我将用通俗点的说法讲一下什么是对偶问题。
首先我们要搞明白,原问题和对偶问题的关系。
假设原问题如下:

则该原问题的对偶问题如下:

上面的对偶函数就是这样,像高数中的用拉格朗日乘子法 去求解最优化问题差不多。通常,我们可以根据对偶函数求解出满足L函数的最小的w值,同时把这个最小的w对应的L函数值记为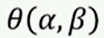 ,并且有其对应的限制条件, 大家理解一下,这很关键。
,并且有其对应的限制条件, 大家理解一下,这很关键。

根据原问题和对偶问题的定义,我们可以得到:

大家仔细看各部分的对应关系,这都是可以推出来的。因此我们最终可以得出:原问题的解总是大于等于对偶问题的最小值。即: ,他们之间的差值,叫做对偶差距。
,他们之间的差值,叫做对偶差距。
九、KKT条件
然而,放在支持向量机中,我们应该如何应用呢?
在这里,我们可以这样去理解,如果原问题的目标函数是凸函数 ,限制条件是线性函数,那么原问题的解和对偶问题的最小值就会相等,即  。 在这种情况下,对偶差距等于零。这也是所谓的 强对偶定理**。**
。 在这种情况下,对偶差距等于零。这也是所谓的 强对偶定理**。**
根据上面的知识我们就可以推出KKT条件:
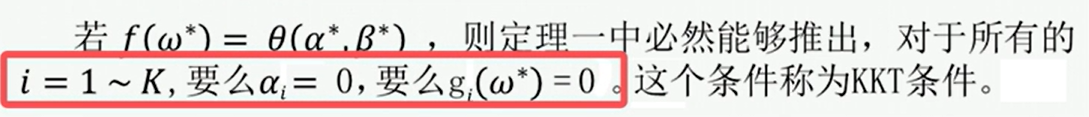
oK,上面小博就先介绍这么多了,希望可以帮到大家!
送一句喜欢的话给大家:有用的东西不一定难,难易只是一种学习的状态,跟有没有用没什么必然的关系。