本文以保险安全驾驶辅导项目为例,对比了XGBoost预测模型与因果估计器在干预定向中的效果差异。通过合成保险数据集,展示了IPW、S-Learner、T-Learner、DML及CausalForestDML五种方法的表现,其中CausalForestDML将最优价值捕获率从19%提升至71%。文章还讨论了可识别性条件、缺失混淆变量的影响,以及因果ML在小样本和重叠性不足时的失效场景。
1 引言
1.1 预测模型的定向误区
你的经理问:"我们有一个安全驾驶辅导项目。应该向哪些投保人提供?"你有一个训练好的XGBoost模型来预测理赔成本。你按预测成本对客户排序,并处理前20%。简单。可辩护。但是是错误的。
这个错误有个名字:台灯谬误。打开台灯与太阳落山相关,但它并不会导致天黑。定向预测理赔成本最高的客户,找到的是昂贵的客户,而不是那些如果接受处理成本会下降的客户。
1.2 观察性数据的特殊性
这是一个观察性数据特有的问题:处理不是随机分配的场景。如果你进行了随机入组的恰当A/B测试,简单的均值差就能给出有效的因果估计,你就不需要这些。麻烦始于入组是自愿的,而报名的人与未报名的人存在系统性差异。
1.3 项目概览
下面,我带你浏览一个为将这一麻烦具体化而构建的示例项目:除生产级Python代码库(含Makefile)、六个Jupyter笔记本、一个Streamlit应用外,还有一个真实值已知的合成保险数据集,因此每个估计器的误差都可以直接测量。所有内容在2核GitHub Codespace上五分钟内即可运行。
该项目也可在GitHub上获取:
https://github.com/Dima806/causal_ml_101
2 ML预测模型的表现与局限
2.1 XGBoost预测性能
训练用于预测理赔成本的XGBoost表现不错。交叉验证RMSE为1,341欧元,R方为0.60。特征重要性显示驾驶经验和地区位居前列,符合预期。
2.2 定向策略的问题
接下来是定向步骤。取预测成本最高的前20%,并将他们入组:
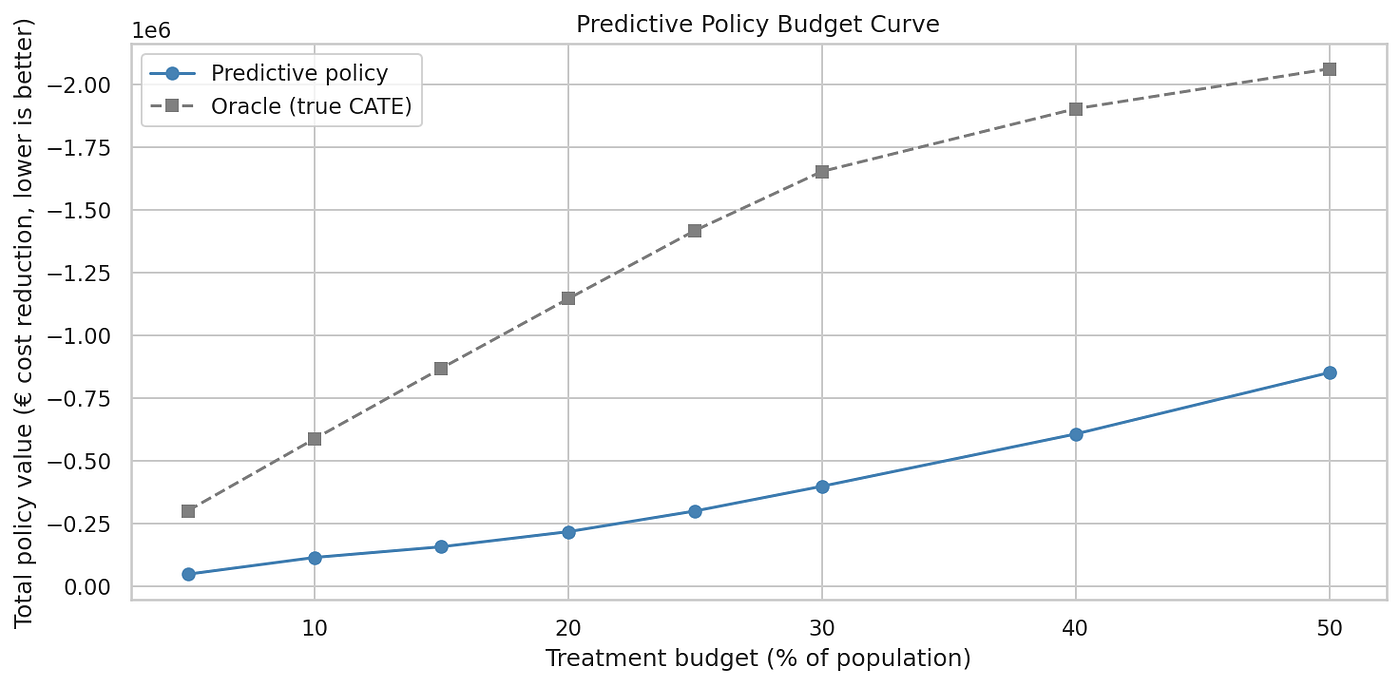
在2,000名被定向的客户中,42%的真实CATE为正------项目使他们的状况更糟。该策略仅捕获了最大可能价值的19%。预算流向了经验丰富、因历史和里程数而昂贵的农村驾驶员,而不是那些会对辅导产生反应的驾驶员。
模型没有坏。它很好地预测了成本。"谁成本高"和"谁从处理中受益"是两个不同的问题,针对其中一个进行训练无法回答另一个。
3 因果识别:先验证再估计
3.1 三个识别条件
在运行任何估计器之前,先决问题是效果是否可以从观察性数据中识别出来。
在这里,需要满足三个条件:
- 可忽略性:在观测协变量条件下,处理和对照下的潜在结果与实际处理分配独立------没有未测量的变量同时驱动谁入组以及他们理赔多少。
- 正值性/重叠性:每个协变量剖面在处理两侧都出现,因此没有估计是对空区域的外推。
- SUTVA(稳定单位处理值假设):一个投保人的入组不会影响另一个人的理赔。对于共享道路并相互影响驾驶习惯的驾驶员来说,最后一个条件是假设,而非既定事实。
3.2 使用DoWhy明确假设
DoWhy库强制将这些假设明确化。你声明调整集并调用 identify_effect(),它会检查是否满足有效的后门准则。这一步捕捉了大多数ML流程从不检查的误差。因果图来自领域知识------在真实项目中与主题专家一起审查,而不是从数据中推断。
python
from dowhy import CausalModel
model = CausalModel(
data=df,
treatment="enrolled",
outcome="claims_cost",
common_causes=[
"age",
"driving_experience_years",
"region",
"annual_mileage",
"prior_claims_count",
"vehicle_age",
],
)
identified = model.identify_effect(proceed_when_unidentifiable=True)3.3 PSW估计与反驳检验
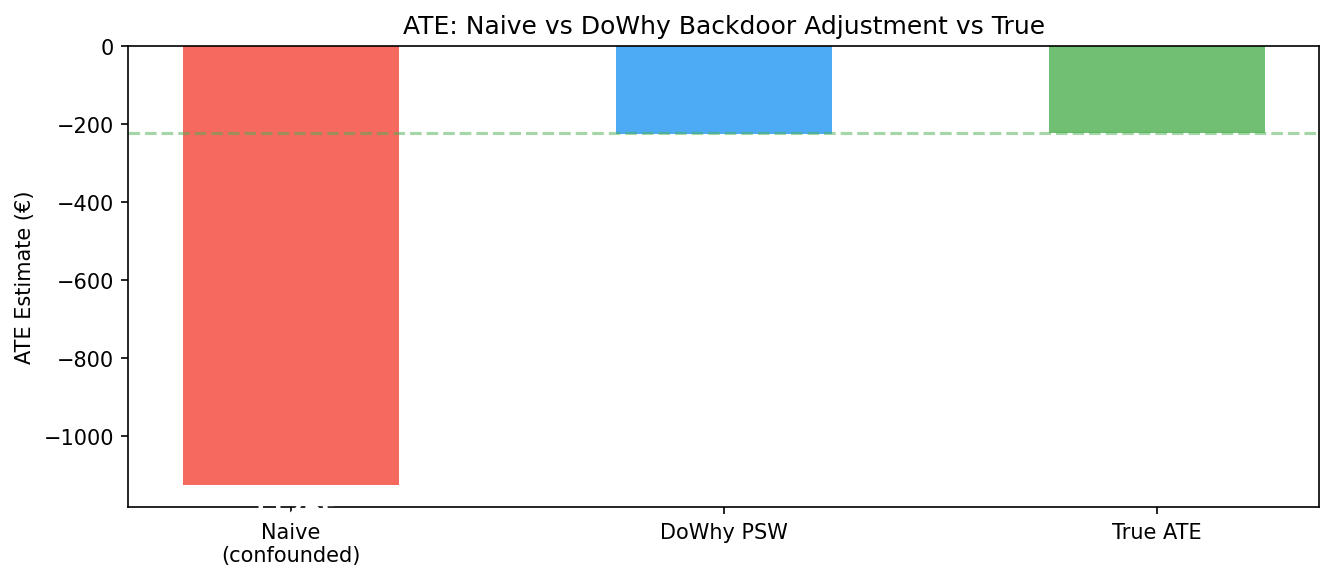
识别确认后,倾向得分加权(PSW)恢复的真实ATE偏差仅为1.5%,而朴素均值差的偏差为405% 。即使缺少 risk_aversion_score,PSW在这里表现也不错,因为风险厌恶与年龄和驾驶经验等可观测特征高度相关------倾向模型在不直接看到它的情况下部分地对其进行了调整。朴素估计中5倍的膨胀来自于更安全的驾驶员既更多地入组,又理赔更少,因此原始比较将选择偏差计入了处理效应。
总体而言,这些反驳检验检查稳健性。随机置换处理标签应返回接近零的效应------确实如此。在80%的数据上重新拟合应返回类似的估计------确实如此。
4 五种估计器对比
4.1 朴素均值差与IPW
在这里,我将五种方法与已知的真实ATE -223欧元进行了比较。
- 朴素均值差返回-1,126欧元:超过真实效应的五倍。如预期,存在混淆偏差,大且明显。
- **逆概率加权(IPW)**落在-611欧元。缺少
risk_aversion_score大概意味着倾向模型可以减少混淆,但不能消除它。
4.2 S-Learner与T-Learner
- S-Learner(一个将处理作为特征的模型)给出-277欧元,最接近,偏差24%。不是因为它理论上更好,而是因为它的正则化恰好吸收了该数据集上的一些未观测混淆。
- T-Learner 为处理组和对照组拟合单独的模型,返回-497欧元,比S-Learner更差。单独模型没有向共同效应的正则化,因此每组的模型都过拟合到自身的噪声。由于只有32%的投保人入组,处理组模型比对照组模型工作在一个更小且更特殊的样本上。
4.3 双重机器学习(DML)
- 双重机器学习(DML)以-414欧元是最原则性的方法,当调整集完整时。它为结果和处理分配拟合单独的模型,从两者中取残差,然后将结果残差对处理残差进行回归。
斜率就是ATE------你问的是,在协变量条件下同样令人惊讶的人群中,处理是否预测结果。然而,请记住,在我们的例子中,risk_aversion_score与观测特征相关,因此残差化吸收了部分混淆,但剩余的变化仍然携带了最终回归无法从处理效应中分离的信号。将risk_aversion_score添加到特征集中将估计移至-148欧元 。遗漏变量偏差为266欧元,大于真实效应本身。当强混淆变量缺失时,DML比简单方法更不明显地失败。
python
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_predict
rf = RandomForestRegressor(n_estimators=100, n_jobs=2, random_state=42)
y_hat = cross_val_predict(rf, features, outcome, cv=3)
t_hat = cross_val_predict(rf, features, treatment, cv=3)
y_res = outcome - y_hat
t_res = treatment - t_hat
lr = LinearRegression()
lr.fit(t_res.reshape(-1, 1), y_res)
dml_manual = float(lr.coef_[0])5 找到受益者
5.1 从ATE到CATE
显然,平均处理效应隐藏了定向信号。在真实ATE为-223欧元时,处理每个人每人带来223欧元的预期价值。只处理正确的人每人带来573欧元,并避免伤害15%的人口。
CausalForestDML是估计个体层面CATE最稳定的起点。当倾向模型设定良好时,DRLearner可以超越它;当处理组和对照组严重不平衡时,X-Learner值得尝试。在该数据集上,三者都面临相同的缺失混淆变量,因此没有一个达到其理论上限。
5.2 CausalForestDML实现
CausalForestDML通过森林最终阶段扩展了DML:不是单一的斜率,它拟合一个让处理效应随协变量变化的森林。拟合在2核CPU上约需45秒,样本量n=10,000。
python
from econml.dml import CausalForestDML
model = CausalForestDML(
n_estimators=100,
max_depth=8,
n_jobs=2,
random_state=42,
cv=3,
)
model.fit(outcome, treatment, X=features)
cate_estimates = model.effect(X=features).flatten()
lower, upper = model.effect_interval(X=features, alpha=0.1)在这里,我们可以用点估计对投保人排序,并用置信区间决定估计是否可靠到足以采取行动:如果一个投保人的90%区间跨越零,其效应在统计上与零无区别。
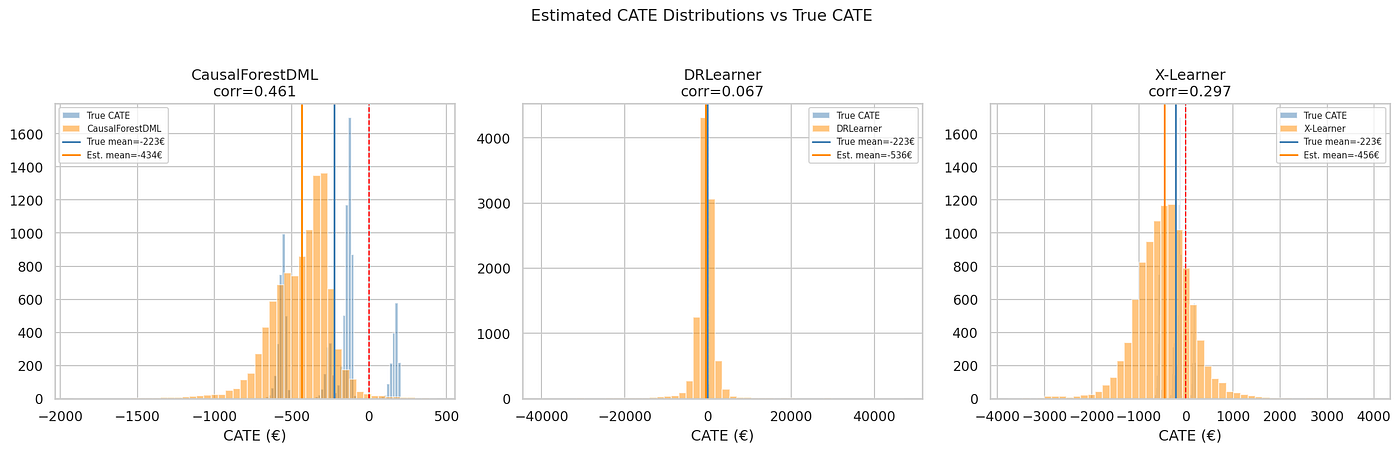
对于CausalForestDML模型,估计CATE与真实CATE的相关性为0.46。对于top-k定向,重要的是极端处的排序(模型是否正确区分了受益最多的人和受害的人),而不是每个估计的全局准确性。估计分布相对于真实CATE被压缩了,但排序是正确的。
5.3 定向效果对比
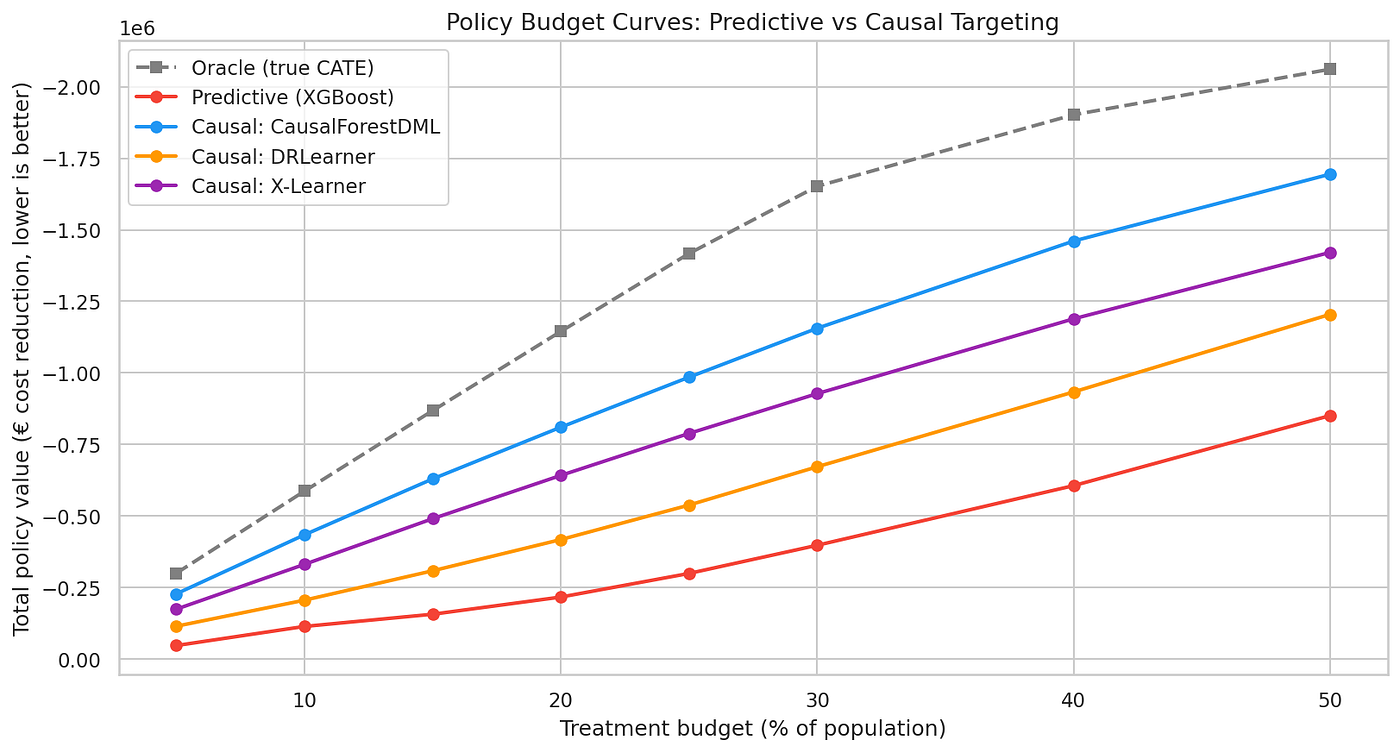
在这里,在20%预算下,预测策略捕获了最优价值的19%,假阳性率为42%。相比之下,CausalForestDML捕获了71%,假阳性率为4%。同样的花费,3.7倍的价值。
20%阈值不是固定的;它是一个选择。当估计CATE低于干预的单位成本时,处理所有人。如果辅导每人花费50欧元,处理模型估计将节省超过50欧元的所有人。上面的预算曲线让你从单位经济学中读出正确的阈值。
X-Learner达到最优的56%,而DRLearner尽管具有双重稳健性,仅捕获37%。当两个组件模型(倾向或结果)中至少一个设定良好时,DR保证成立;当缺少 risk_aversion_score 时,两者都设定不良。DRLearner还需要 min_propensity=0.05 来防止倾向得分接近0或1导致权重爆炸。所有三个估计器都假设二元处理;像剂量或折扣大小这样的连续干预需要不同的EconML模型类。
5.4 生产环境部署建议
当从笔记本转向生产时,将任何预处理管道与EconML模型一起保存:model.effect() 期望使用训练时的相同特征表示:
python
import joblib
joblib.dump(model, "causal_forest.pkl")
model = joblib.load("causal_forest.pkl")
cate_scores = model.effect(X=new_features).flatten()在对新数据评分之前,需要检查它是否落在训练集的协变量支撑范围内。训练集中未表示的投保人剖面产生的是外推,而不是估计。建议随时间监测倾向得分分布,特别是得分在0.1, 0.9之外的分数以及训练批与当前批之间的柯尔莫哥洛夫-斯米尔诺夫(KS)检验。如果入组比例或协变量混合显著变化,需要重新拟合。
6 因果ML何时失效
6.1 重叠性缺失
当DGP中农村驾驶员的入组概率设为零时,农村CATE的RMSE从470跃升至560。当某个子群体中没有人被处理时,你无法从该数据中估计他们的处理效应,你只能外推。重叠图立即显示了差距。将估计修剪到重叠区域,并明确说明覆盖了哪些子群体。
6.2 未观测混淆变量
隐藏 risk_aversion_score 在223欧元的真实效应上引入了266欧元的偏差。敏感性分析(即Rosenbaum边界)告诉你一个未观测混淆变量需要多强才能反转你的结论。DoWhy的 random_common_cause 提供了一个快速的合理性检查。两者都不能消除偏差;然而,它们帮助你在采取行动前决定结果的可信度。
6.3 样本量不足
CausalForestDML在n=10,000时与真实CATE的相关性为0.47。然而,在n=500时,该相关性降至-0.18:
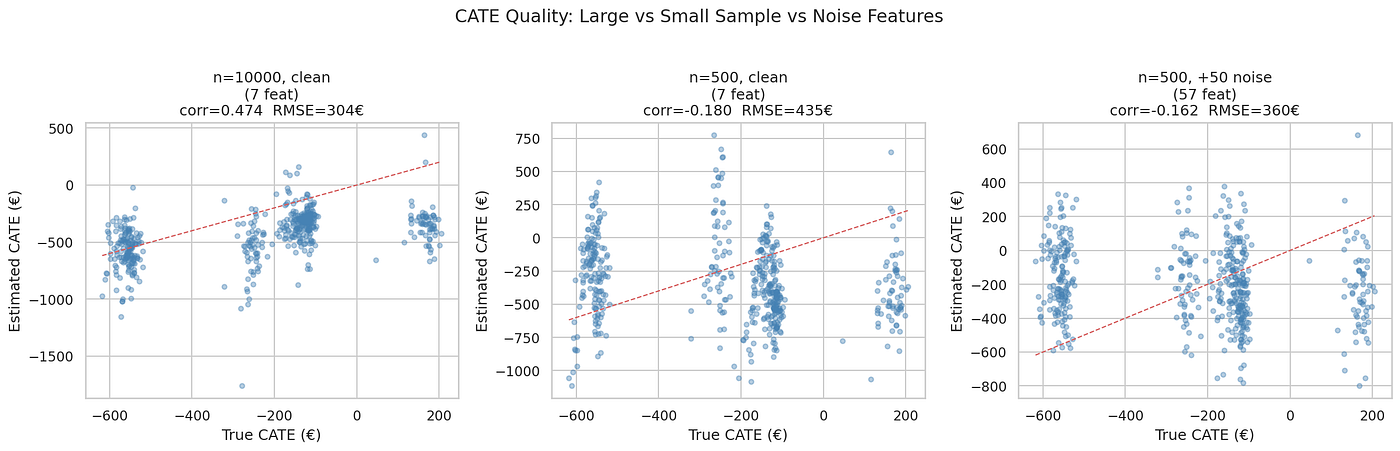
如我们所见,预测随数据行数减少而优雅地退化。然而,因果估计不会退化;它需要足够的数据来残差化、估计异质性效应,并在子群体中保持协变量支撑。一个解决方案是在根据小数据集的估计采取行动前,检查CATE在bootstrap样本中的稳定性。
7 结论
总结:如果你的干预定向流程从预测谁昂贵开始,那么上面19%(标准Xgboost模型)与71%(CausalForestDML模型)的最优价值差距可能就藏在其中某处。昂贵和敏感是两个不同的东西。 没有如上例中使用因果ML,你一直在为错误的目标优化。