当 class_weight='balanced' 时,每个类别 i 的权重 w_i 计算如下:
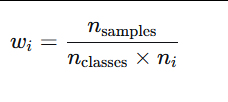
nsamples :训练集总样本数
nclasses :类别总数(不包含背景,如果有)
ni :类别 i 的样本数
例
假设训练集共有 1000 个样本,分为 3 个类别:
类别 A:500 个样本
类别 B:300 个样本
类别 C:200 个样本那么:
类别 A 的权重:1000/(3×500)=1000/1500≈0.6671000/(3×500)=1000/1500≈0.667
类别 B 的权重:1000/(3×300)=1000/900≈1.1111000/(3×300)=1000/900≈1.111
类别 C 的权重:1000/(3×200)=1000/600≈1.6671000/(3×200)=1000/600≈1.667类别 C(样本最少)获得最大权重,类别 A(样本最多)权重最小。
在 SVM 中的作用
SVM 的目标是最小化:
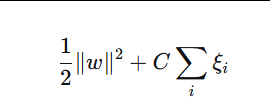
其中 ξi是松弛变量。
class_weight 将样本的惩罚系数 C 乘以对应的类别权重。实际效果是:
对少数类样本,其松弛变量 ξi 的惩罚被放大,迫使模型更努力地正确分类它们(或允许更少的误分类)。
对多数类样本,惩罚相对减小,模型对它们的误分类容忍度更高。最终,模型会倾向于找到一个决策边界,使得少数类样本被更准确地分类,从而提升整体的类别平衡性能。