1. fastdfs 、nginx 文件管理模块
1. 1 fastdfs 三大组件
1.1.1 tracker server
相当于一个调度器 ,其内部不存储文件,只存储storage 服务器相关的一些元信息(存在于内存中) ,通过连接storage后由storage汇报的信息 生成的,根据这些信息 组成一个 group --> storage 的关联信息。
当需要上传文件的时候,
- 分配goup : 客户端先访问tracker ,tracker根据负载均衡的策略(比如:某个剩余空间大的storage服务器),分配一个group;
- 分配storage :然后再到group中选择一个storage 并给出path;
- 客户端访问storage: 客户端将向storage发送写文件请求,storage将会为文件分配一个数据存储目录
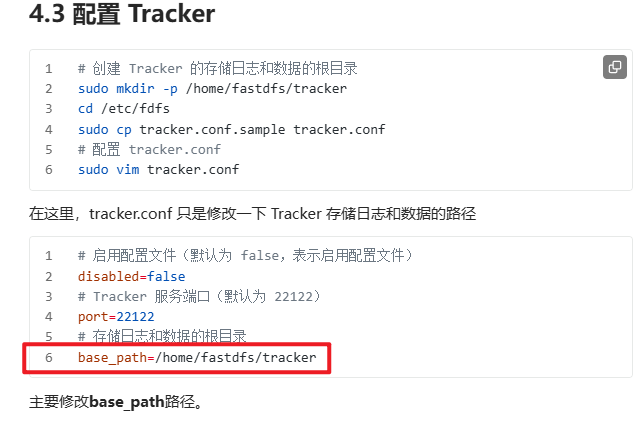
配置tracker : 只需要配置data和logs路径!
1.1.2 storage server
真正存储文件的服务器,其中经过tracker的分配,会有一个逻辑上的组:group ,每个group中含有多个storage ,互为备份 ,当上传文件的时候选择其中一个上传,其余storage后续通过binlog日志进行同步 。一般内部会有 256*256个子目录 去存储文件。比如 00/00/ 00/01等。
当文件上传的时候:
- 记录Fileid :storage会为文件生成一个Fileid,由:storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成,然后将这个二进制串进行base64编码,转换为可打印的字符串。
- 存储到两级目录: 每个存储目录下有两级256*256的子目录,storage会按文件fileid进行两次hash(猜测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下
- 生成文件名: 当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由:group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。

配置storage: ① 需要设置好data的存储位置;② 需要设置好M00的映射地址(真正的物理地址)

1.1.3 client
提供的一个客户端,相当于需要往fastdfs中输入一些指令 upload xx xx 、download xx xx
1.1.4 fastdfs-nginx-module 下载文件
该模块是fastdfs中长期使用的稳定模块,而且配置文件的路径和storage一致,这个模块的作用
- 如果没有此模块:
- 后端从数据库取出文件ID:
如 group1/M00/00/00/xxx.txt - 后端连接Tracker : 调用指令获取文件所在的地址
- 后端发送读取请求,获取文件流: 调用指令读取文件
- 后端返回文件流给前端
- 后端从数据库取出文件ID:
- 如果有此模块:
- 后端只返回一个 HTTP URL 给前端:
http://10.0.0.1:80/group1/M00/00/00/xxx.txt - 前端直接使用URL下载: 前端直接使用这个 URL 下载(<a 标签或 window.open),流量直接从 Nginx 流向客户端,不经过业务后端
- 后端只返回一个 HTTP URL 给前端:
1. 2 nginx 模块
nginx-upload-module用于上传文件
如果没有该模块,则上传文件的二进制内容 全都要放在请求体中 ,数据解析困难 。
引入该模块之后,便可以在nginx层面解析multipart/form-data ,将文件保存到临时目录 ,然后生成包含文件信息的变量 (如$upload_tmp_path等),再将请求转发到后端 (如/api/upload),后端从变量或环境变量中获取文件路径来处理。
2. 文件上传
2.0 文件秒传
其实就是根据MD5,查看file_info中是否已经存在相同MD5的文件,如果已经存在则再去查user_file_list中有没有,如果没有则添加一条记录,并且把file_info的引用计数 +1。
如果秒传失败,则触发2.1
2.1 上传
经过nginx-upload-file 模块的recv的数据是和前端调用axios后发送的有所不同!
- content解析: 其中content 以一个
WebKitFormBoundaryjWE3qXXORSg2hZiB分割,进行filename、filetype、md5等信息的解析; - 文件名拼接: 在经过nginx模块上传后,文件统一去掉了后缀名,这里找到type和filename进行拼接即可;
- fastdfs命令上传: 用到了进程间通信 ,需要执行
fdfs_upload_file(指令) /etc/fdfs/client.conf(配置文件路径) 123.txt(文件),此步骤完成后可以获取到group1/M00/00/00/xxx.txtpipe(int fd[2]): 创建一个无名管道,其中fd0 表示读端 ,fd1 表示写端;pid_t pid = fork(): 创建子进程,子进程会完全复制父进程的地址空间,但是区分pid;- 子进程:
pid = 0则说明是子进程- 关闭读端,保留写端;
- 将标准输出重定向到写管道;
- 父进程:
pid = 1则说明是父进程- 关闭写端,保留读端;
- 设置读取数据的端
read(fd[0], fileid, TEMP_BUF_MAX_LEN),读取数据到fileid中
wait(NULL)/close(fd[0]): 等待子进程结束,并关闭挥手
- 完整路径:
- 依旧使用父子进程方式,执行命令
fdfs_file_info,获取ip - 拼接 http:// + ip +
group1/M00/00/00/xxx.txt
- 依旧使用父子进程方式,执行命令
- 数据库持久化: 将上传文件信息插入表做持久化,file_info 插入一条,user_file_list 插入一条;
父子间进程通信的原理: 可以使用popen() 是在fork()、pipe()之上的封装
在fork()创建子进程后,共享父进程的数据 (也就是说父子进程皆可以访问管道的读写端,持有其fd ),如果是在此之前创建了pipe() ,那么父子进程都会有pipe读端和写端的引用 ,如果写端引用不为0 ,则无法在读端读取数据,因此需要关闭子进程的读和父进程的写!