本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
一、前言(承接第四篇)
上一篇我们成功实现了职场办公型Azure Agent,完成了"读取Word/PDF/TXT文件→自动总结→保存结果"的完整闭环,复用了第三篇的"记忆+多工具"架构,解决了手动处理单个文件的重复工作,代码可直接运行、容错性强,完全贴合职场基础办公需求。
但在实际职场场景中,我们常常会遇到「批量处理多个文件」(如批量总结10个会议纪要、批量提取多个PDF关键信息)、「需要Excel格式保存结果」(方便统计、汇报和数据对比)的高频需求,同时缺乏进度提示,处理多个文件时无法判断进度,体验不够流畅。
这一篇我们基于第四篇的实战代码,进行三大核心进阶优化,全程复用你已有的Azure GPT-4模型、azure_config.json配置文件和依赖环境,代码可直接复制运行,无需额外配置,新手也能轻松上手,完美衔接第四篇的实战成果,让Agent从"单次处理"升级为"高效批量处理",真正适配高强度办公场景。
本篇核心目标:实现「批量处理多个文件」「Excel格式保存结果」「实时进度提示」三大功能,优化Agent的稳定性和交互体验,解决批量文件处理效率低、结果统计不便的痛点,同时延续前四篇的模块化架构,保持代码的扩展性和连贯性。

二、实操准备
复用前面的Azure环境、Python环境和所有依赖包,无需重新安装之前的依赖(python-docx、PyPDF2、openpyxl等),只需确认以下2点即可:
-
确认已安装openpyxl依赖(上一篇已安装,用于Excel保存),若未安装,打开CMD/PowerShell执行以下命令:
pip install openpyxl --user -
确认azure_config.json文件存在(与本篇代码放在同一目录)。
提示:若忘记依赖安装状态,可直接执行上述openpyxl安装命令,重复安装不会影响环境;批量处理时,建议将需要处理的所有文件(Word/PDF/TXT)放在同一个文件夹中,方便Agent遍历读取,提升处理效率。
三、代码
将以下代码保存为agent_advanced.py,建议放在同一目录(无需重新输入Azure配置,直接复用前序配置文件):
python
from openai import AzureOpenAI
import json
import os
from docx import Document # 读取Word文件(复用上一篇)
from PyPDF2 import PdfReader # 读取PDF文件(复用上一篇)
import openpyxl # Excel保存(复用上一篇依赖,新增逻辑)
import datetime # 时间戳、进度计时(新增)
# ===================== 1. Azure配置加载 =====================
CONFIG_FILE = "azure_config.json"
def load_azure_config():
"""加载Azure OpenAI配置,沿用前四篇的容错处理,避免配置错误导致程序崩溃"""
if os.path.exists(CONFIG_FILE):
try:
with open(CONFIG_FILE, "r", encoding="utf-8") as f:
config = json.load(f)
# 验证核心配置是否完整(适配GPT-4部署,与前四篇一致)
required_keys = ["azure_endpoint", "api_key", "deployment_name"]
if all(key in config for key in required_keys):
return config
else:
print("⚠️ Azure配置文件不完整,将重新引导输入")
except Exception as e:
print(f"⚠️ 配置文件读取失败({str(e)}),将重新引导输入")
# 若配置文件不存在/读取失败,引导用户重新输入并生成新文件(与前四篇逻辑一致)
config = {
"azure_endpoint": input("请输入Azure Endpoint:"),
"api_key": input("请输入Azure OpenAI API Key:"),
"deployment_name": input("请输入GPT-4模型部署名称:")
}
with open(CONFIG_FILE, "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=4)
return config
# 初始化Azure OpenAI客户端(稳定调用GPT-4,版本与前四篇一致)
config = load_azure_config()
client = AzureOpenAI(
azure_endpoint=config["azure_endpoint"],
api_key=config["api_key"],
api_version="2024-08-01-preview" # 兼容GPT-4的稳定版本,与前四篇保持一致
)
# ===================== 2. 核心工具模块(新增批量+Excel保存,复用前四篇工具) =====================
# 工具1:读取文件(完全复用上一篇,无修改,保证功能连贯性)
def read_file(file_path: str) -> str:
"""读取文件内容,自动识别文件格式,返回纯文本,容错处理沿用前四篇思路"""
if not os.path.exists(file_path):
return f"❌ 文件不存在,请检查文件路径是否正确(当前路径:{file_path})"
file_ext = os.path.splitext(file_path)[1].lower()
try:
if file_ext == ".docx": # Word文件
doc = Document(file_path)
content = "\n".join([para.text for para in doc.paragraphs if para.text.strip()])
elif file_ext == ".pdf": # PDF文件
reader = PdfReader(file_path)
content = "\n".join([page.extract_text() for page in reader.pages if page.extract_text().strip()])
elif file_ext == ".txt": # TXT文件
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
else:
return f"❌ 不支持该文件格式({file_ext}),仅支持.docx/.pdf/.txt"
if not content.strip():
return "❌ 文件内容为空,无法进行处理"
return content
except Exception as e:
return f"❌ 文件读取失败:{str(e)}(可能是文件损坏或格式异常)"
# 工具2:文本总结(完全复用上一篇,无修改,适配批量处理场景)
def summary_tool(text: str) -> str:
"""文件内容总结工具,GPT-4驱动,沿用前四篇逻辑,贴合职场汇报需求"""
try:
response = client.chat.completions.create(
model=config["deployment_name"],
messages=[
{"role": "system", "content": "你是职场办公总结助手,总结文件内容时,需突出核心要点、关键数据和结论,语言简洁、专业,控制在150字内,避免冗余,适配职场汇报场景。"},
{"role": "user", "content": f"请总结以下文件内容:\n{text}"}
],
temperature=0.2 # 降低随机性,确保总结结果稳定、准确,与前四篇一致
)
return response.choices[0].message.content.strip()
except Exception as e:
return f"❌ 总结失败:{str(e)}(请检查Azure配置或网络连接)"
# 工具3:结果保存(升级,支持TXT/Excel双格式,新增Excel保存逻辑)
def save_result(result_list: list, save_format: str = "txt", file_name: str = None) -> str:
"""保存处理结果,支持TXT(单个/批量)和Excel(批量优先),延续前四篇简洁实用思路"""
# 自动生成文件名(含时间戳),适配批量/单个场景
if not file_name:
now = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
file_name = f"agent_advanced_result_{now}"
try:
if save_format.lower() == "excel":
# 新增:Excel格式保存(批量处理优先,支持单个结果)
wb = openpyxl.Workbook()
ws = wb.active
# 设置表头(适配批量统计,清晰直观)
ws.append(["处理时间", "文件名称", "文件路径", "处理结果"])
# 填充数据(支持单个结果和批量结果)
for item in result_list:
ws.append([
item["time"],
item["file_name"],
item["file_path"],
item["result"]
])
# 调整列宽,避免内容溢出
ws.column_dimensions['A'].width = 20
ws.column_dimensions['B'].width = 30
ws.column_dimensions['C'].width = 50
ws.column_dimensions['D'].width = 80
# 保存Excel文件
excel_path = f"{file_name}.xlsx"
wb.save(excel_path)
return f"✅ 批量结果已保存为Excel:{os.path.abspath(excel_path)}"
else:
# 复用上一篇TXT保存逻辑,适配批量处理
txt_path = f"{file_name}.txt" if file_name.endswith(".txt") else f"{file_name}.txt"
with open(txt_path, "w", encoding="utf-8") as f:
f.write(f"Agent批量处理结果({datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')})\n")
f.write("="*80 + "\n")
for idx, item in enumerate(result_list, 1):
f.write(f"【第{idx}个文件】\n")
f.write(f"文件名称:{item['file_name']}\n")
f.write(f"文件路径:{item['file_path']}\n")
f.write(f"处理结果:{item['result']}\n")
f.write("-"*80 + "\n")
return f"✅ 批量结果已保存为TXT:{os.path.abspath(txt_path)}"
except Exception as e:
return f"❌ 结果保存失败:{str(e)}(请检查目录写入权限)"
# 工具4:批量处理文件(新增核心工具,适配职场批量需求)
def batch_process(folder_path: str) -> list:
"""批量处理文件夹下所有Word/PDF/TXT文件,返回处理结果列表,用于后续保存"""
# 验证文件夹是否存在
if not os.path.isdir(folder_path):
return [{"time": "", "file_name": "", "file_path": folder_path, "result": f"❌ 文件夹不存在,请检查路径是否正确"}]
# 遍历文件夹,筛选支持的文件格式
file_list = [f for f in os.listdir(folder_path) if f.lower().endswith((".docx", ".pdf", ".txt"))]
if not file_list:
return [{"time": "", "file_name": "", "file_path": folder_path, "result": "❌ 文件夹下无支持的文件(仅支持.docx/.pdf/.txt)"}]
# 批量处理,记录每个文件的处理结果
result_list = []
total = len(file_list)
for idx, file_name in enumerate(file_list, 1):
# 拼接完整文件路径
file_path = os.path.join(folder_path, file_name)
# 读取文件内容(复用工具1)
file_content = read_file(file_path)
# 处理结果(读取失败则直接记录错误,读取成功则总结)
if file_content.startswith("❌"):
result = file_content
else:
result = summary_tool(file_content)
# 记录当前处理结果(含时间戳,方便统计)
result_list.append({
"time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"file_name": file_name,
"file_path": file_path,
"result": result
})
# 新增:进度提示,实时显示处理进度
progress = (idx / total) * 100
print(f"📊 批量处理进度:{idx}/{total}({progress:.1f}%),当前处理:{file_name}")
return result_list
# ===================== 3. 进阶Agent核心(整合所有工具,沿用前四篇架构) =====================
class AdvancedAgent:
def __init__(self):
self.history = [] # 多轮记忆(复用第三、四篇的记忆机制)
self.last_file_path = None # 记录最近一次读取的文件路径(复用上一篇)
self.last_folder_path = None # 新增:记录最近一次批量处理的文件夹路径
# 工具映射,沿用前四篇的字典映射逻辑,新增批量处理工具
self.tools = {
"读取文件": read_file,
"总结文件": summary_tool,
"保存结果": save_result,
"批量处理": batch_process
}
def parse_intent(self, instruction: str) -> tuple:
"""智能解析用户指令,优化批量处理识别,沿用前四篇关键词匹配逻辑"""
instruction_lower = instruction.lower()
file_path = None
folder_path = None
# 提取文件路径(复用上一篇逻辑)
if any(ext in instruction for ext in [".docx", ".pdf", ".txt"]):
import re
pattern = r"([^\s]+?\.(docx|pdf|txt))"
match = re.search(pattern, instruction)
if match:
file_path = match.group(1)
self.last_file_path = file_path
else:
file_path = self.last_file_path
# 新增:提取文件夹路径(适配批量处理指令)
if any(keyword in instruction_lower for keyword in ["批量", "文件夹", "目录"]):
import re
# 提取文件夹路径(适配空格、中文路径)
pattern = r"([^\s]+?[\\/][^\s]+?)(?=\s|$)"
match = re.search(pattern, instruction)
if match:
folder_path = match.group(1)
self.last_folder_path = folder_path
else:
folder_path = self.last_folder_path
# 判断任务类型,新增批量处理意图识别,与前四篇逻辑一致
if any(keyword in instruction_lower for keyword in ["批量", "批量处理"]):
return "批量处理", folder_path, instruction
elif any(keyword in instruction_lower for keyword in ["读取", "打开"]):
return "读取文件", file_path, instruction
elif any(keyword in instruction_lower for keyword in ["总结", "概括", "提炼"]):
return "总结文件", file_path, instruction
elif any(keyword in instruction_lower for keyword in ["保存", "导出"]):
# 识别保存格式(Excel/TXT)
save_format = "excel" if "excel" in instruction_lower else "txt"
return "保存结果", save_format, instruction
else:
return "未知", None, instruction
def run(self, instruction: str) -> str:
"""Agent运行入口,串联批量处理、Excel保存、进度提示全流程,沿用前四篇核心逻辑"""
print(f"🔍 Agent接收指令:{instruction}")
intent, param, raw_instruction = self.parse_intent(instruction)
# 处理不同任务类型
if intent == "批量处理":
if not param:
result = "❌ 未识别到文件夹路径,请输入包含文件夹的指令(如:批量处理 D:/docker/files)"
else:
print(f"🚀 开始批量处理文件夹:{param}")
print(f"📌 正在筛选文件夹下支持的文件(.docx/.pdf/.txt)...")
# 调用批量处理工具,获取结果列表
batch_result = self.tools["批量处理"](param)
# 批量处理完成后,自动保存结果(默认Excel格式,贴合职场统计需求)
save_result = self.tools["保存结果"](batch_result, save_format="excel")
# 统计处理情况(成功/失败数量)
success_count = len([item for item in batch_result if not item["result"].startswith("❌")])
fail_count = len(batch_result) - success_count
result = f"✅ 批量处理完成!\n📊 处理统计:共{len(batch_result)}个文件,成功{success_count}个,失败{fail_count}个\n{save_result}"
# 存入记忆
self.history.append(("批量处理", param, result))
elif intent == "读取文件":
# 复用上一篇逻辑,无修改,保证连贯性
if not param:
result = "❌ 未识别到文件路径,请先读取文件(如:读取文件 D:/test.pdf),再输入「总结这个文件」"
else:
result = self.tools["读取文件"](param)
if not result.startswith("❌"):
self.last_file_path = param
self.history.append(("读取文件", param, result[:50] + "..."))
elif intent == "总结文件":
# 复用上一篇逻辑,无修改,支持"总结这个文件"指令
if not param:
result = "❌ 未识别到文件路径,请先读取文件(如:读取文件 D:/test.pdf),再输入「总结这个文件」"
else:
file_content = self.tools["读取文件"](param)
if file_content.startswith("❌"):
result = file_content
else:
result = self.tools["总结文件"](file_content)
self.history.append(("总结文件", param, result))
elif intent == "保存结果":
# 升级:支持手动选择保存格式(Excel/TXT),复用记忆逻辑
if not self.history:
result = "❌ 暂无可保存的结果,请先处理文件(读取/总结/批量处理)"
else:
# 判断是否为批量处理结果
last_task, last_param, last_result = self.history[-1]
if last_task == "批量处理":
# 批量结果已自动保存,提示用户可手动指定格式保存
result = f"📌 最近一次为批量处理({last_param}),已自动保存为Excel格式\n若需保存为TXT格式,输入:保存结果 TXT"
else:
# 单个结果保存,支持指定格式
save_result = self.tools["保存结果"](
[{"time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"file_name": os.path.basename(last_param),
"file_path": last_param,
"result": last_result}],
save_format=param
)
result = save_result
else:
# 未识别到任务类型,提示优化,新增批量处理指令示例
result = "❌ 未识别到任务,请输入以下类型的指令:\n1. 读取文件:包含.docx/.pdf/.txt路径(如:读取 D:/会议纪要.docx)\n2. 总结文件:包含文件路径或先读取文件后输入「总结这个文件」\n3. 批量处理:包含文件夹路径(如:批量处理 D:/docker/files)\n4. 保存结果:可选指定格式(如:保存结果 Excel / 保存结果 TXT)"
# 存入记忆,控制记忆长度(沿用第三、四篇逻辑,保留最近5次交互)
self.history.append(("用户指令", raw_instruction, result))
if len(self.history) > 5:
self.history.pop(0)
return result
# ===================== 4. 运行测试(进阶场景,直接复制样本测试) =====================
if __name__ == "__main__":
# 初始化高效办公型Agent,沿用前四篇的初始化逻辑
advanced_agent = AdvancedAgent()
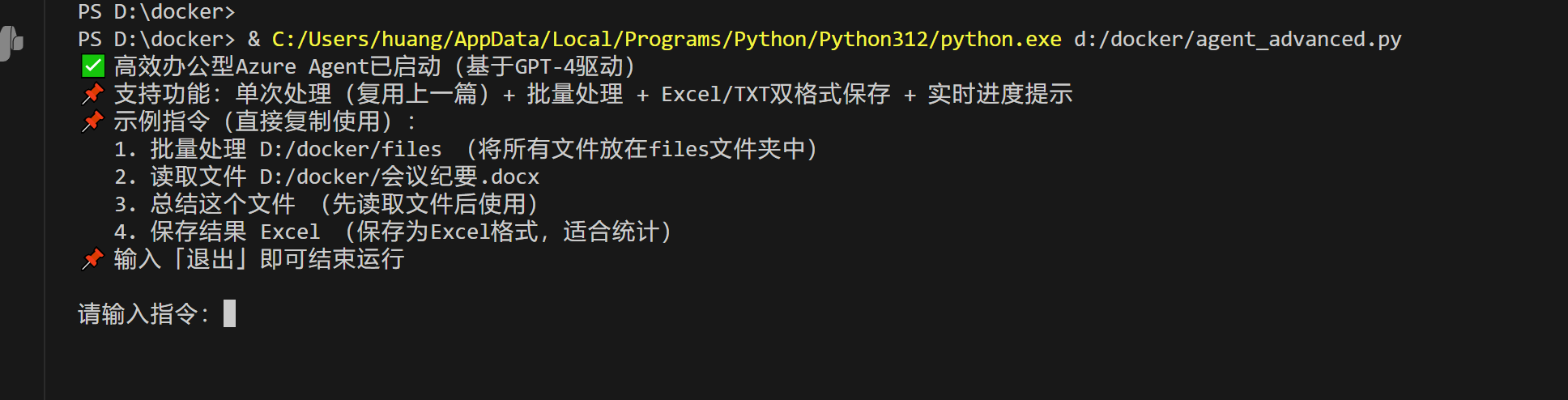
print("✅ 高效办公型Azure Agent已启动(基于GPT-4驱动)")
print("📌 支持功能:单次处理(复用上一篇)+ 批量处理 + Excel/TXT双格式保存 + 实时进度提示")
print("📌 示例指令(直接复制使用):")
print(" 1. 批量处理 D:/docker/files (将所有文件放在files文件夹中)")
print(" 2. 读取文件 D:/docker/会议纪要.docx")
print(" 3. 总结这个文件 (先读取文件后使用)")
print(" 4. 保存结果 Excel (保存为Excel格式,适合统计)")
print("📌 输入「退出」即可结束运行")
# 交互测试,模拟职场批量办公场景,延续前四篇的交互风格
while True:
user_input = input("\n请输入指令:")
if user_input in ["退出", "exit", "quit"]:
print("❌ Agent已停止运行")
break
# 运行Agent并输出结果
result = advanced_agent.run(user_input)
print(f"\nAgent:{result}\n")启动成功:
四、测试
测试前准备:在电脑中创建一个文件夹(如:D:/docker/files),放入2-5个Word/PDF/TXT文件(用于批量测试);
测试样本1:批量处理文件夹
复制以下指令(替换成你自己的文件夹路径),粘贴到Agent的「请输入指令:」后面:
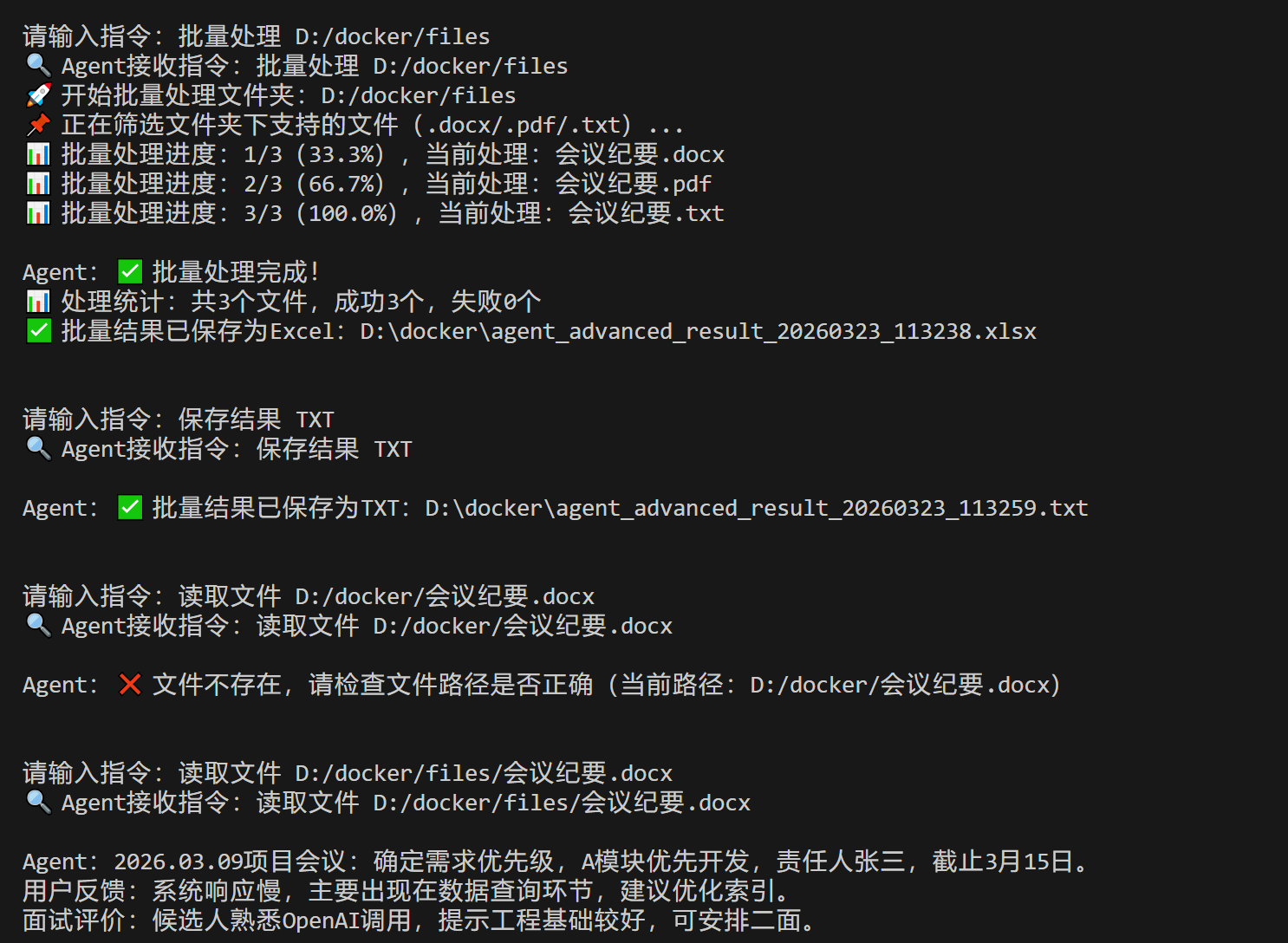
批量处理 D:/docker/files
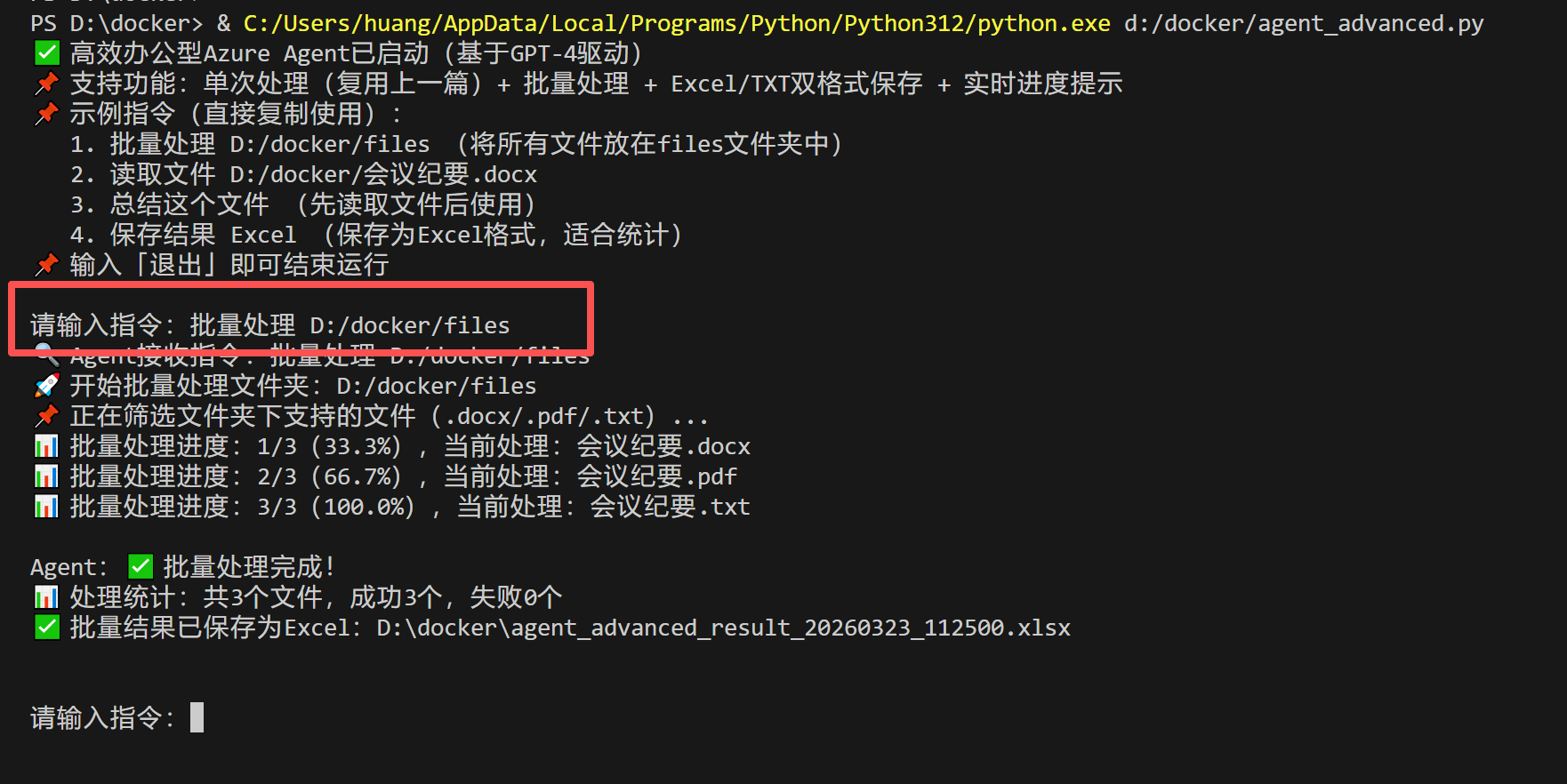
预期结果:1. Agent会提示"正在筛选文件夹下支持的文件";2. 实时显示进度(如:1/3(33.3%),当前处理:会议纪要.pdf);3. 处理完成后,自动保存为Excel文件,返回保存路径;4. 显示处理统计(成功/失败数量),完美实现批量处理+进度提示+Excel保存。

测试样本2:Excel格式手动保存
-
先输入:读取文件 D:/docker/files/会议纪要.pdf(替换成你的文件路径);
-
再输入:总结这个文件;
-
最后输入:保存结果 Excel。
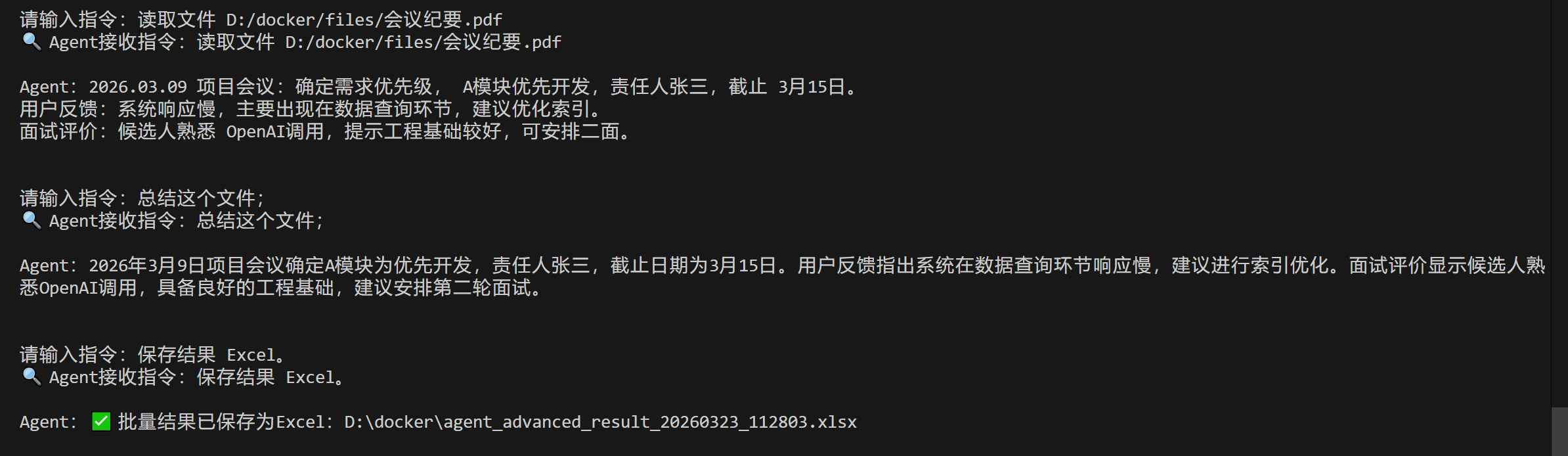
预期结果:Agent将总结结果保存为Excel文件,返回保存路径,打开Excel可看到"处理时间、文件名称、文件路径、处理结果"四大表头,数据清晰,适合职场统计和汇报。

测试样本3:TXT格式保存
完成测试样本2的总结后,输入:
保存结果 TXT
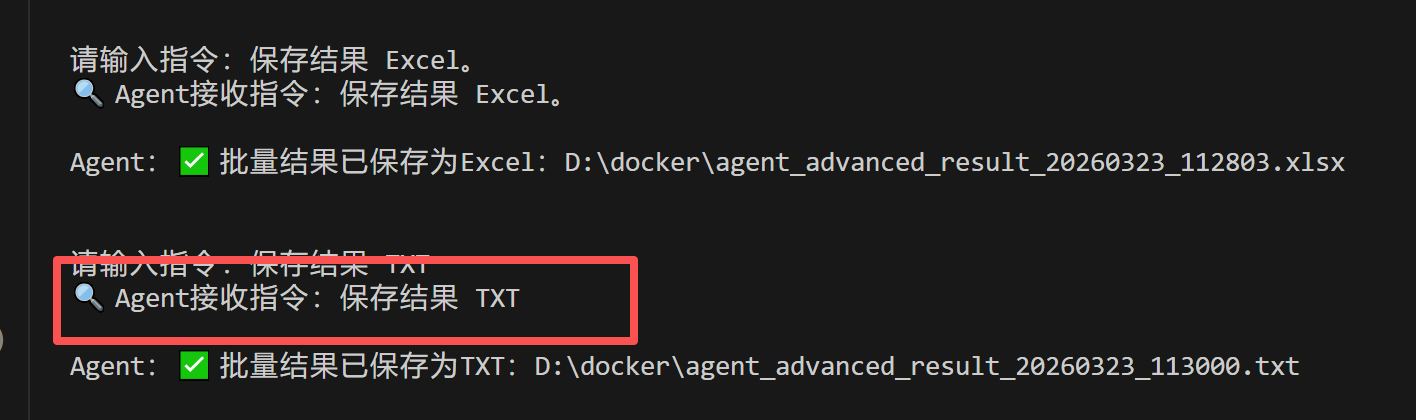
预期结果:Agent将总结结果保存为TXT文件,返回保存路径,格式与上一篇一致,确保兼容性,满足不同保存需求。
测试样本4:多轮批量+记忆测试
-
先输入:批量处理 D:/docker/files;
-
再输入:保存结果 TXT;
-
最后输入:读取文件 D:/docker/会议纪要.docx。
预期结果:Agent能连贯处理批量和单次任务,记忆功能正常,批量处理结果可重复保存为不同格式。
五、核心知识点讲解
- 新增模块核心逻辑
-
批量处理模块:通过os.listdir遍历文件夹,筛选支持的文件格式,循环调用上一篇的读取和总结工具,实现批量处理;同时记录每个文件的处理结果,用于后续批量保存,逻辑简洁,复用前序工具,避免重复开发。
-
Excel保存模块:基于openpyxl依赖,创建工作簿和工作表,设置表头和列宽,将批量处理结果按"时间、文件名、路径、结果"整理保存,贴合职场统计需求,同时支持单个结果保存,兼容性强;
-
进度提示模块:通过"当前处理数量/总数量"计算进度百分比,实时打印进度信息,解决批量处理时"无反馈、不知道进度"的痛点,提升交互体验;
-
意图解析优化:新增文件夹路径提取逻辑,自动识别"批量处理"指令,支持自然语言输入(如"批量处理D:/files""批量总结文件夹"),延续前四篇"无需死板输入指令头"的设计思路。
- 与前四篇的衔接要点
本次进阶Agent完全复用前四篇的核心资源和架构逻辑,无需重复操作,重点衔接以下5点:
-
配置复用:Azure配置加载、客户端初始化代码完全复用,azure_config.json文件通用,无需重新输入Endpoint、API Key;
-
工具复用:读取文件、文本总结工具完全复用第四篇,无任何修改,保证功能连贯性和一致性;
-
架构复用:沿用第三篇的"工具映射字典"和"多轮记忆"架构,新增批量处理、Excel保存工具只需添加映射,无需重构核心代码,延续扩展性优势;
-
交互复用:Agent的启动提示、交互风格、容错逻辑与前四篇完全一致,新增批量处理指令示例,降低学习成本;
-
依赖复用:完全复用第四篇安装的所有依赖(python-docx、PyPDF2、openpyxl),无需额外安装,上手更顺畅。
- 可扩展性说明
本次进阶Agent的架构可进一步扩展,延续前四篇"模块化扩展"的思路,后续可基于此代码添加以下职场高级功能:
-
支持Excel文件的批量读取和总结(提取表格数据,生成数据分析报告);
-
添加邮件发送功能(将批量处理的Excel/TXT结果自动发送到指定邮箱,适配汇报场景);
-
支持文件筛选(批量处理时,可指定仅处理某一种格式的文件,如仅批量总结PDF);
-
添加日志记录功能(记录每次处理的详细信息,方便后续追溯和问题排查)。
总结与系列回顾
总结
本篇我们基于第四篇的实战代码,完成了Azure Agent的进阶优化,实现了「批量处理文件」「Excel格式保存结果」「实时进度提示」三大核心功能,复用了前四篇的Azure配置、核心工具和架构逻辑,代码可直接运行、容错性强,完美解决了职场中批量文件处理效率低、结果统计不便的痛点,让Agent从"单次处理"升级为"高效办公助手"。
通过本次实操,你不仅掌握了批量处理、Excel保存、进度提示的核心代码,还进一步巩固了前四篇的模块化扩展思路------新增功能无需重构核心,只需添加对应工具,为后续开发更复杂的办公功能打下了坚实基础。
- 系列文章回顾
本系列文章从基础到实战、从单次处理到批量优化,逐步搭建了一个完整的职场办公型Azure Agent,全程新手友好,代码可直接复制运行,核心成果回顾如下:
-
第二篇(基础入门):实现极简版Azure Agent,掌握Azure GPT-4调用、配置文件生成,核心功能:文本总结;
-
第三篇(升级增强):新增多轮记忆、多工具调度,优化意图解析,核心功能:文本总结+智能问答(带记忆);
-
第四篇(实战落地):新增文件读取、TXT保存,实现"读文件→总结→保存"闭环,核心功能:单次文件处理;
-
第五篇(进阶优化):新增批量处理、Excel保存、进度提示,核心功能:批量文件处理+高效统计,适配高强度办公场景。
至此,一个完整的、可落地、可扩展的职场办公型Azure Agent已搭建完成。
接下来的系列打算尝试一下AI 的其他部分。