OpenCV 作为开源的计算机视觉库,凭借丰富的 API 和高效的底层实现,成为开发者解决图像预处理、特征检测、模式匹配等问题的核心工具。本文将结合四段完整的实战代码,从图像几何矫正、特征点检测,到特征匹配验证,最终实现完整的指纹识别系统,系统讲解 OpenCV 在实际开发中的核心用法,让读者快速掌握从基础操作到工程化应用的全流程。
一、图像几何矫正:解决拍摄畸变问题
在文档扫描、票据识别等场景中,拍摄角度导致的图像畸变是常见问题。第一段代码完整实现了倾斜图像的透视变换矫正,并通过图像增强提升内容可读性,核心流程包括图像预处理、轮廓检测、透视变换和图像优化。
核心代码与关键解析
python
import numpy as np
import cv2
# 图像显示封装函数
def cv_show(name, image):
cv2.imshow(name, image)
cv2.waitKey(0)
# 角点排序函数:确定四个角点的左上、右上、右下、左下顺序
def order_points(pts):
rect = np.zeros((4, 2), dtype='float32')
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)] # 左上角(x+y最小)
rect[2] = pts[np.argmax(s)] # 右下角(x+y最大)
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)] # 右上角(y-x最小)
rect[3] = pts[np.argmax(diff)] # 左下角(y-x最大)
return rect
# 透视变换核心函数:将倾斜图像矫正为正视角
def four_point_transform(image, pts):
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算变换后图像的宽度和高度(取两组对边的最大值)
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 定义变换后的目标坐标(正视角矩形)
dst = np.array([[0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype='float32')
# 生成透视变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
# 执行透视变换
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
# 图像等比例缩放函数
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
# 主流程:图像读取与预处理
image = cv2.imread('fapiao.jpg')
cv_show('image', image)
ratio = image.shape[0] / 500.0
orig = image.copy()
image = resize(orig, height=500) # 统一缩放到高度500,方便处理
cv_show('1', image)
# STEP 1: 轮廓检测
print('STEP 1:轮廓检测')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度化
# 二值化(OTSU自动阈值)
edged = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# 提取轮廓(RETR_LIST提取所有轮廓,CHAIN_APPROX_SIMPLE压缩轮廓点)
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[-2]
image_contours = cv2.drawContours(image.copy(), cnts, -1, (0, 0, 255), 1)
cv_show('image_contours', image_contours)
# STEP 2: 筛选最大轮廓(目标区域)
print('STEP 2:获得最大轮廓')
screenCnt = sorted(cnts, key=cv2.contourArea, reverse=True)[0] # 按面积降序取第一个
print(screenCnt.shape)
peri = cv2.arcLength(screenCnt, True) # 计算轮廓周长
# 轮廓逼近:将不规则轮廓简化为四边形(0.05*peri为逼近精度)
screenCnt = cv2.approxPolyDP(screenCnt, 0.05 * peri, True)
print(screenCnt.shape)
image_contour = cv2.drawContours(image.copy(), [screenCnt], -1, (0, 255, 0), 2)
cv2.imshow('image_contour', image_contour)
cv2.waitKey(0)
# STEP 3: 透视变换矫正
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio) # 还原原始比例
cv2.imwrite('invoice_new.jpg', warped)
cv2.namedWindow('xx', cv2.WINDOW_NORMAL)
cv2.imshow('xx', warped)
cv2.waitKey(0)
# 图像增强:提升内容可读性
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] # 二值化
ref = resize(ref, width=500)
kernel = np.ones((2, 2), np.uint8)
ref_new = cv2.erode(ref, kernel, iterations=1) # 腐蚀去噪
cv2.imshow('ref_new', ref_new)
rotated_image = cv2.rotate(ref_new, cv2.ROTATE_90_COUNTERCLOCKWISE) # 旋转调整方向
cv2.imshow("result", rotated_image)
cv2.waitKey(0)


关键技术点说明
- 透视变换 :核心是
cv2.getPerspectiveTransform生成变换矩阵,cv2.warpPerspective执行变换,解决图像倾斜问题; - 轮廓处理 :
cv2.findContours提取轮廓后,通过面积排序筛选目标区域,cv2.approxPolyDP将轮廓简化为规则四边形,精准定位角点; - 图像增强 :二值化突出内容,腐蚀操作(
cv2.erode)消除噪声点,最终旋转调整图像方向,提升可读性。
二、特征点检测:角点与 SIFT 特征提取
特征点是图像的 "关键标识",Harris 角点检测适合快速定位特征位置,SIFT 特征则具有尺度、旋转不变性,是后续匹配的核心。第二段代码完整实现了这两种特征检测方法。
核心代码与关键解析
python
import numpy as np
import cv2
# ------------------- 角点检测 --------------------
img = cv2.imread('img1.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Harris角点检测(参数:邻域大小4,Sobel孔径3,自由参数0.04)
dst = cv2.cornerHarris(gray, 4, 3, 0.04)
# 标记角点为红色(阈值:0.05*最大值)
img[dst > 0.05 * dst.max()] = [0, 0, 255]
cv2.imshow('img', img)
cv2.waitKey(0)
# --------------------- 特征提取SIFT -----------------
man = cv2.imread('phone.png')
man_gray = cv2.cvtColor(man, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create() # 创建SIFT特征提取器
kp = sift.detect(man_gray) # 检测关键点
# 绘制关键点(含大小、方向)
man_sift = cv2.drawKeypoints(man, kp, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('man_sift', man_sift)
cv2.waitKey(0)
# 计算关键点描述符(128维特征向量,用于后续匹配)
kp, des = sift.compute(man, kp)
print(np.array(kp).shape, des.shape) # 输出关键点数量和描述符维度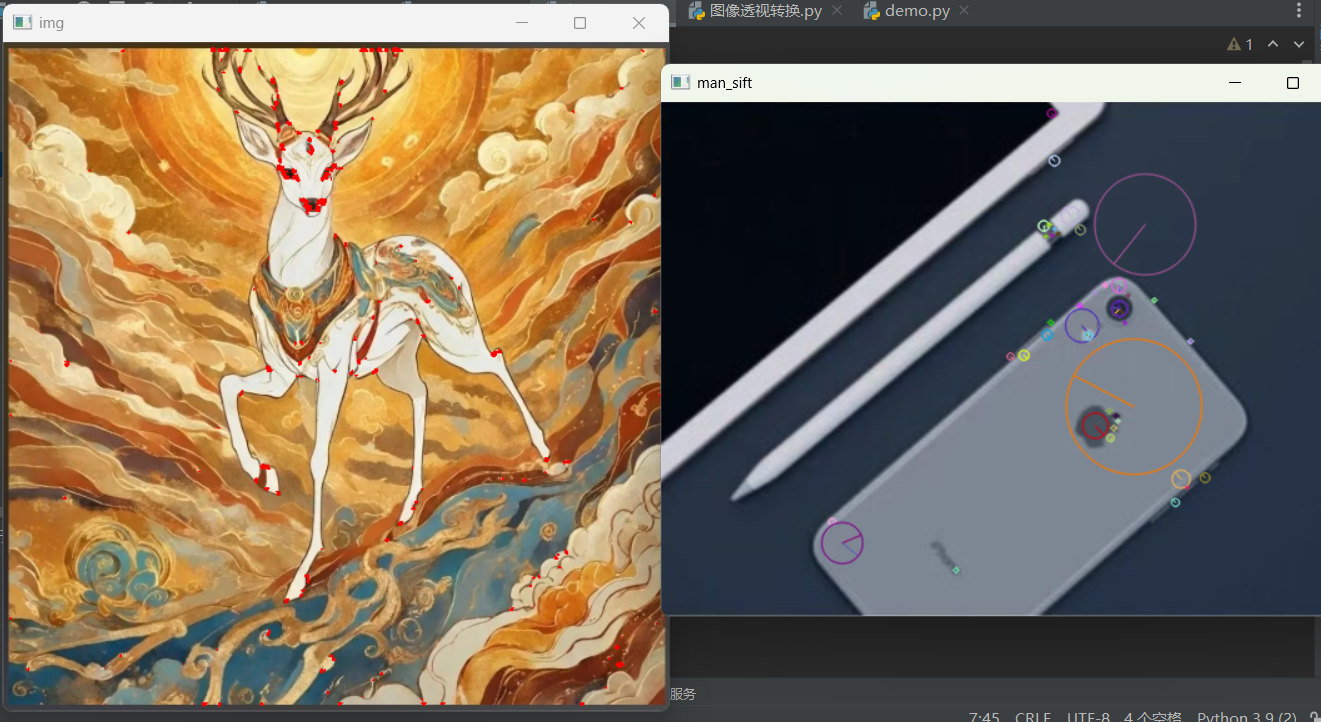
关键技术点说明
- Harris 角点检测 :通过计算图像局部灰度变化,定位角点(向任意方向移动灰度变化显著的点),参数
0.04控制检测灵敏度,值越小检测到的角点越多; - SIFT 特征 :
sift.detect检测具有尺度 / 旋转不变性的关键点,sift.compute生成 128 维描述符,即使图像缩放、旋转,描述符仍能保持一致性,是特征匹配的核心。
三、特征匹配:基于 SIFT 的身份验证
第三段代码基于 SIFT 特征和 FLANN 匹配器,实现了简单的身份验证功能,核心是通过特征匹配数量判断两张图像是否为同一目标。
核心代码与关键解析
python
import cv2
# 图像显示封装函数
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
# 身份验证函数:对比源图像与模板图像的特征匹配数
def verification(src, model):
# 创建SIFT特征提取器
sift = cv2.SIFT_create()
# 提取源图像和模板图像的特征点与描述符
kp1, des1 = sift.detectAndCompute(src, None)
kp2, des2 = sift.detectAndCompute(model, None)
# 创建FLANN匹配器(快速近邻匹配,效率高于暴力匹配)
flann = cv2.FlannBasedMatcher()
# K近邻匹配(k=2,取前两个最优匹配)
matches = flann.knnMatch(des1, des2, k=2)
ok = []
for m, n in matches:
# Lowe's比率测试:筛选有效匹配(最优匹配距离 < 0.8*次优匹配距离)
if m.distance < 0.8 * n.distance:
ok.append((m, n))
# 根据匹配数量判断验证结果
num = len(ok)
if num >= 500:
result = "认证通过"
else:
result = "认证失败"
return result
# 主函数:验证示例
if __name__ == "__main__":
src1 = cv2.imread("12.BMP")
cv_show('src1', src1)
src2 = cv2.imread("13.BMP")
cv_show('src2', src2)
model = cv2.imread("14.BMP")
cv_show('model', model)
result1 = verification(src1, model)
result2 = verification(src2, model)
print("src1验证结果为:", result1)
print("src2验证结果为:", result2)
关键技术点说明
- FLANN 匹配器 :
cv2.FlannBasedMatcher是快速近邻匹配库,适合大规模特征匹配,相比暴力匹配(cv2.BFMatcher)速度提升显著; - Lowe's 比率测试 :通过对比最优匹配和次优匹配的距离,过滤噪声匹配,
0.8为经验阈值,可根据场景调整; - 验证逻辑:匹配数≥500 则认证通过,阈值需根据实际场景(如图像分辨率、特征复杂度)调整,平衡精度与召回率。
四、实战进阶:完整的指纹识别系统
第四段代码整合前文的特征提取与匹配技术,搭建了完整的指纹识别系统,实现 "指纹匹配→编号识别→姓名匹配" 的全流程,可直接应用于简单的指纹身份验证场景。
核心代码与关键解析
python
import os
import cv2
# ------------- 计算两个指纹间匹配点的个数 -------------------
def getNum(src, model):
img1 = cv2.imread(src)
img2 = cv2.imread(model)
sift = cv2.SIFT_create() # 替换为orb_create()可提升速度
# 提取特征点与描述符
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# FLANN匹配
flann = cv2.FlannBasedMatcher()
matches = flann.knnMatch(des1, des2, k=2)
ok = []
for m, n in matches:
# Lowe's比率测试筛选有效匹配
if m.distance < 0.8 * n.distance:
ok.append(m)
num = len(ok)
return num
# ---------------- 匹配指纹数据库,获取指纹编号 --------------
def getID(src, database):
max = 0
# 遍历指纹数据库中的所有模板
for file in os.listdir(database):
model = os.path.join(database, file)
num = getNum(src, model)
print("文件名:", file, "匹配点个数:", num)
# 记录最大匹配数对应的指纹文件
if num > max:
max = num
name = file
# 提取文件名称中的编号(假设文件名第一位为编号)
ID = name[0]
# 匹配数过低则标记为未找到
if max < 200:
ID = 9999
return ID
# ---------------- 根据指纹编号,映射对应姓名 ---------------
def getName(ID):
# 编号-姓名映射字典
nameID = {0: '张三', 1: '李四', 2: '王五', 3: '赵六', 4: '朱老七',
5: '钱八', 6: '曹九', 7: '王二麻子', 8: 'andy', 9: 'Anna', 9999: "没找到"}
name = nameID.get(int(ID))
return name
# ------------ 主函数:指纹识别全流程 --------------
if __name__ == "__main__":
src = "src.BMP" # 待识别指纹
database = "database" # 指纹数据库路径
ID = getID(src, database) # 获取匹配的指纹编号
name = getName(ID) # 映射姓名
print("识别结果为:", name)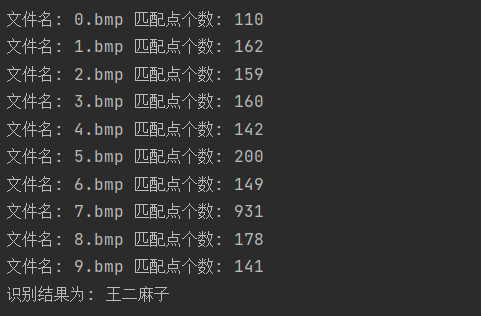
关键技术点说明
- 指纹匹配核心:复用 SIFT+FLANN 匹配逻辑,返回有效匹配点数量,作为指纹相似度的判断依据;
- 数据库遍历 :
os.listdir遍历指纹数据库,os.path.join拼接文件路径,找到匹配数最多的指纹模板; - 编号映射:通过字典实现编号到姓名的快速映射,匹配数 <200 时标记为 "未找到",避免误识别。
OpenCV 的学习核心是 "实战结合原理",从简单的图像预处理到复杂的指纹识别系统,每一个 API 都对应着经典的计算机视觉算法。掌握这些基础用法后,可进一步探索 OpenCV 与深度学习的结合(如目标检测、图像分割),解锁更多高阶应用场景。无论是文档矫正、物体识别还是生物特征验证,OpenCV 都能提供高效、易用的解决方案,是入门计算机视觉的必备工具。