文章目录
从零到上线,一个测试运维工程师和 AI 搭档的真实开发故事(非全职开发,利用空闲时间和周末时间)。
起因
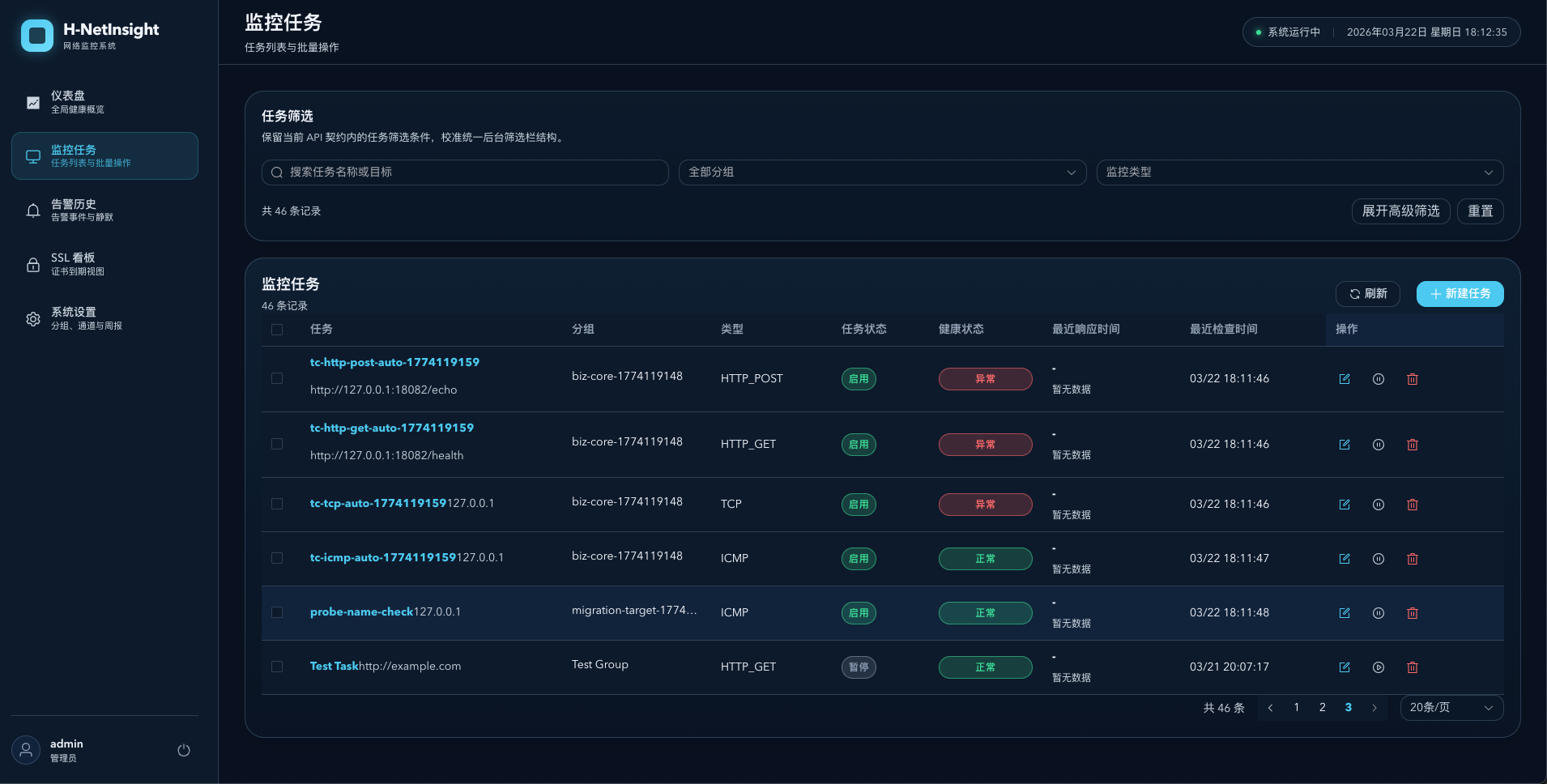
团队需要一个网络监控系统。
市面上的方案,要么太重(Prometheus + Grafana + AlertManager 全家桶),要么太贵(SaaS 按量计费),要么功能不贴合需求。
需求其实很简单:
- 能 Ping 几十台服务器,看通不通
- 能检测 TCP 端口开没开
- 能检查 HTTP 接口返回正不正常
- 能监控 SSL 证书快到期了提醒一下
- 出问题了钉钉和邮件通知一下
- 每周一自动发一份可用率报告
这些需求,用传统方式开发,一个有经验的全栈工程师大概要 3-4 周。
但这次我想试试完全由 AI 辅助开发。
最终结果:11 天(非全职),59 次提交,一套完整可用的网络监控系统。
第一天:立规矩
很多人用 AI 写代码,最大的问题是:AI 写着写着就跑偏了。
加个功能、改个设计、重构一下......等你回过神来,代码已经面目全非。
所以在写第一行代码之前,我做了一件事:写宪法。
没错,constitution.md,项目开发宪法。
这份文件定了 7 条不能违背的开发原则:
第一条:简单性原则
只实现规格说明中明确要求的功能。不提前抽象未来需求。不引入非必需的依赖。
第二条:测试先行铁律(不可协商)
所有新功能必须先写一个失败的测试,再写实现,最后重构。禁止跳过测试直接改代码。
第三条:明确性原则
所有 API 输入输出必须显式定义类型。禁止裸 except。禁止吞异常。
还有异步优先、安全默认、前端规范、代码风格......
宪法是最高优先级的。AI Agent 在这个项目里工作,必须先读宪法,然后无条件遵守。
试下来效果很好:AI 不再自作主张加功能了。
但后面我才意识到,真正让这套方法稳定下来的,不只是这 7 条大原则,而是后面不断补进去的细规则。
很多规则其实不是一开始就想全了,而是被问题逼出来的。比如 HttpOnly Cookie 方案踩坑之后,我才明确写下"前端不能依赖 document.cookie 判断登录态";时间展示在列表、详情、Dashboard 三处漂移之后,我才把"所有时间统一走 frontend/src/utils/datetime.ts"定成硬规则;前端测试因为漏了 ElConfigProvider mock 把 vitest worker 拖死之后,我才真正意识到"测试桩必须覆盖运行时真实依赖"不是一句形式化要求,而是会直接影响进度的工程纪律。
也就是说,这不是一套写完就不动的制度,而是一套边做边被现实校正出来的方法。
顺便说一下,这个项目没用单一的 AI 工具,而是按任务类型组合了好几个:
- 写后端代码(API 路由、数据库模型、探测引擎)主要用 Claude Code + GLM-5,生成的代码比较稳定
- 代码审查和 Bug 排查用 Codex + GPT-5.4,推理链条更长,能挖到问题的根因
- 前端页面微调用 TRAE + Gemini 3.1 Pro Preview,改 .vue 文件时能同时看到 template 和 script 的上下文
- 原型设计用 Figma,导出 TSX 代码后给前端对照着实现
- 文档整理用 Claude Code + Kimi-K2.5,800 行的 spec 和 298 个任务的管理文档,长上下文是刚需
不同模型确实有分工的价值。GLM-5 写业务逻辑稳,GPT-5.4 查 Bug 准。关键不是选"最好的模型",而是把合适的模型放到合适的环节。
第二到第三天:写规格,画原型
接下来写需求文档。
spec.md 写了大约 800 行,包括:
- 4 种监控类型的详细设计(ICMP/TCP/HTTP GET/HTTP POST)
- 告警状态机的完整生命周期
- 5 个核心页面的 UI 规格
- 数据库表设计
- API 端点规划
- 非功能性需求(性能、安全、部署)
然后是 UI 原型。
找了一些参考截图,让 AI 提取视觉风格:
深邃科技(Deep Tech):深藏青/夜空蓝为基调
克制对比(Restrained Contrast):不使用大面积高亮色
高信噪比(High Signal-to-Noise Ratio):摒弃多余修饰
硬朗专业(Crisp & Professional):小圆角、细边框
然后定义了完整的设计 Tokens:色彩体系、字体层级、间距系统、组件规范。最后把 Figma 设计原型导出为 319 个 TSX 文件。
不过这里有个坑,后面会提到。
这个阶段的核心就是:把一切想清楚再动手。
那时候我其实挺乐观的。规格写清楚了,原型也有了,任务再拆细一点,AI 看起来就能像流水线一样往前推。后面事实证明,这个判断只对了一半。
第四天:骨架搭建
开始写代码。但不是直接写业务逻辑,先搭骨架。
项目配置文件(pyproject.toml、package.json、Dockerfile、Makefile),FastAPI 入口,数据库会话,ORM 基类,工具函数......这个阶段用 Claude Code + GLM-5。
每一步都是 TDD:先写测试,再写实现。
比如加密工具:
- 先写一个测试:
test_encrypt_then_decrypt_returns_original - 跑测试,红(失败)
- 写 AES-256-GCM 实现
- 跑测试,绿(通过)
- 重构(如果需要)
看起来很慢,实际上很快。AI 写测试的速度远超人类,而且测试本身就是最好的规格文档。
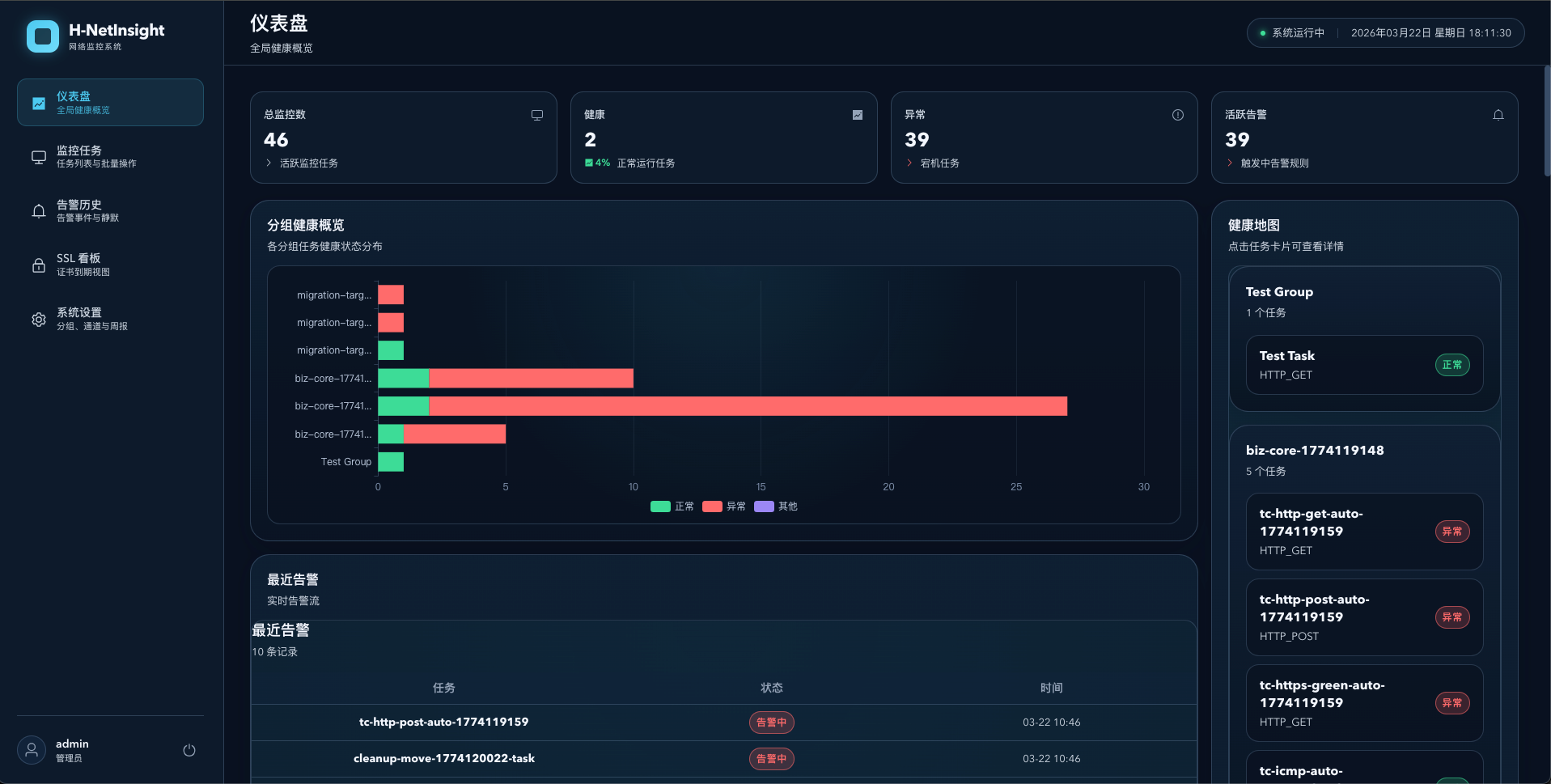
第五到第七天:核心功能冲刺
这几天是最密集的开发期。
一天之内完成了:
- 7 个数据库模型 + 数据库迁移
- 14 个 API Schema 定义
- 认证、用户、分组、告警规则、通知通道的完整 CRUD
- 4 种探测引擎(ICMP/TCP/HTTP/SSL)
- 调度器集成
- 前端 API 模块和基础组件
最高产的一天做了 11 次提交。
关键在于任务分解。整个项目拆成 298 个原子任务,每个任务只改一个文件。AI 按依赖关系自主推进,不用我逐条指导。主力工具仍然是 Claude Code + GLM-5。
比如:
T094 [P] 创建统一探测结果类型测试
T095 创建探测结果类型文件(依赖 T094)
T096 [P] 创建 ICMP Probe 测试
T097 创建 ICMP Probe 实现(依赖 T095, T096)[P] 标记的任务可以并行,AI 会自动识别依赖关系。
到这里为止,我还觉得局面基本在掌控里。最难的部分好像已经过去了。
第八到第十天:完善与打磨
功能跑通之后,进入打磨阶段。
这时候前后端问题开始交叉出现,工具也跟着切换:排查问题用 Codex + GPT-5.4(推理链长,能挖根因),前端微调用 TRAE + Gemini 3.1 Pro Preview(改 .vue 文件更精准)。
这段时间解决了很多"最后 10%"的问题:
前后端契约漂移------前端允许选择"最近 24 小时"筛选,但后端 API 只接受 1d/7d/30d,用户一选就报错。
时间格式不一致------列表页显示到秒,详情页只到分钟,Dashboard 又是另一种格式。
探测指标混淆------ICMP 的"响应时间"用了总执行耗时,而不是真正的 RTT。
级联删除遗漏------删分组时,组内任务的历史探测数据没清干净。
这些问题看着都不大,但每一个都会影响用户体验。更麻烦的是,没有测试覆盖的话,修一个 Bug 很容易再引入新的。
真正让人疲惫的不是某个单独的大坑,而是它们几乎都跨层。前端一个筛选项,后端一个枚举,测试里一个 mock,页面上一个时间格式,看起来都只是小问题,串起来就变成半天起步。我也是从这个阶段开始意识到,复杂工程里最难的不是把功能写出来,而是把这些跨层契约一条条收紧。
这几天还有一次压测,结果不太好看。任务列表 P95 很高,高并发下还出现了 database is locked。我第一反应其实挺沮丧的,因为前面一直觉得 SQLite 这个选择是稳的。后来反过来看,这轮压测反而很值钱。它把边界打清楚了:SQLite 不是不能用,而是只能在我们说清楚的单实例、有限负载场景里用;一旦查询写法放松,或者并发超出预期,问题就会立刻暴露。
第十一天:安全加固
原本我以为,核心功能做完以后,最后一天更多是收尾。真正进了安全审查才发现,根本不是"修几个点"那么简单,而是要把底层基线重新校准一遍。
问题不只是 JWT 从 localStorage 改成 HttpOnly Cookie。安全测试还把另外几个缺口一起打了出来:登录接口没有限流,API 响应缺少安全头,FastAPI 默认 422 校验错误和项目自己的错误结构也不一致。也就是从这里开始,我对 AI 的一个认知更清楚了:它可以很快补实现,但安全基线仍然得靠人来定。哪些规则要全局生效,哪些只能条件输出,哪些默认行为不能接受,这些都不能让模型自己猜。
最后一天做安全。
JWT Token 从 localStorage 改为 HttpOnly Cookie,防止 XSS 窃取。加了安全响应头中间件(X-Content-Type-Options、X-Frame-Options、HSTS)。实现了 Token 黑名单。加了 RBAC 角色权限。修了 SSL 证书验证的漏洞。
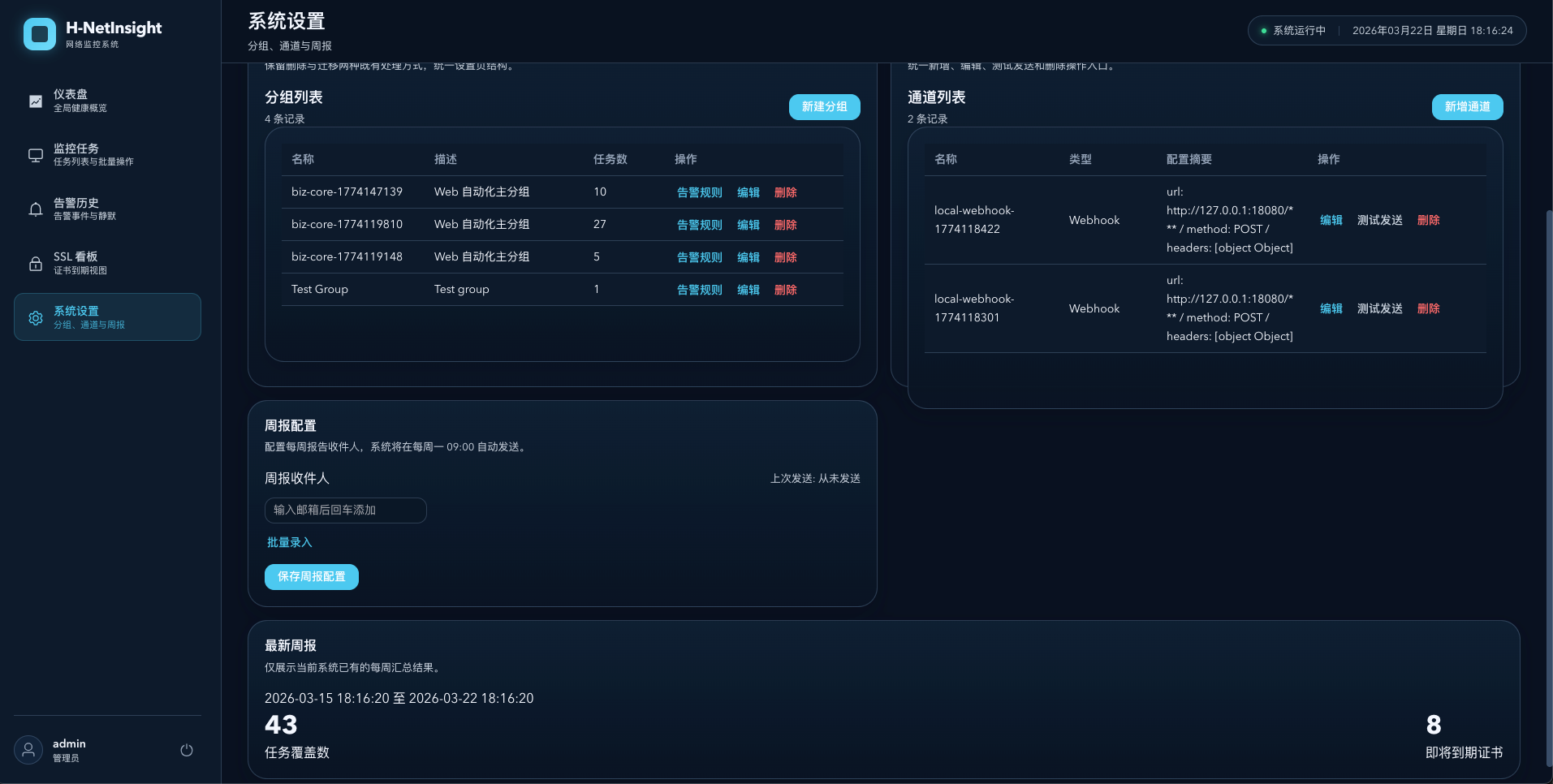
同时设计了 CI/CD 流水线(Gitee Go + Docker Compose),从代码提交到自动部署打通。最后的文档整理工作交给 Claude Code + Kimi-K2.5 处理。
一些数字
| 指标 | 数值 |
|---|---|
| 开发周期 | 11 天 |
| 提交次数 | 59 次 |
| 代码行数 | 173,000+ 行 |
| 开发任务 | 298 个 |
| 文档 | 793 个 Markdown |
| 测试文件 | 449 个(后端 208 + 前端 241) |
这套方法为什么有效?
回过头来看,我觉得有几个原因。
宪法 + 指南划出了 AI 的行为边界。光跟 AI 说"帮我写个监控系统",它会给你一个四不像。但如果告诉它:必须用 SQLite,不能用 PostgreSQL;必须先写测试;敏感字段必须加密,密码必须 bcrypt;每个函数只做一件事------AI 就会在这些约束下给出靠谱的代码。
298 个任务拆得足够细,每个只改一个文件,AI 可以像流水线一样持续推进。
测试是兜底的。没有测试的 AI 编程就像没系安全绳攀岩,每次重构、每次修复都是赌博。
793 个 Markdown 不只是给人看的,它们是 AI Agent 的"长期记忆"。每次新会话开始,AI 会读这些文档来了解项目全貌。
踩过的坑
当然也不是一帆风顺。
坑 1:AI 真的会"过度聪明"。有一次它看到 N+1 查询,第一反应不是优化查询,而是想引入缓存层。单看代码,这个建议甚至不算离谱;但它和项目边界是冲突的。我们明确说了单实例、轻量、不要 Redis。那一刻我意识到,AI 最大的风险不是写不出来,而是写出一个"局部看上去很合理、整体却不该出现"的方案。后来我就把这类经验不断写回规则里,尽量不给它留发挥过头的空间。
坑 2:前后端契约漂移,比我预想得频繁得多。最开始我以为这种问题就是修个值映射,十分钟搞定。实际症状往往很烦:页面明明给了选项,用户一点击就 400;接口看起来通了,图表却显示不对;详情页和列表页读的是同一个字段,展示出来却不是一回事。难查的地方在于,单看前端像前端的问题,单看后端像后端的问题,只有把类型、接口入参、服务层允许值和页面常量一起摊开,才知道错位在哪。后来我才真正接受,这类问题不能靠默契,只能靠契约测试和更窄的类型定义。
坑 3:HttpOnly Cookie 认证链路,让我把"运行时真实世界"这件事看得更重了。最初以为登录接口改成设置 Cookie 就够了,剩下前端照旧读 token 就行。结果一联调就出问题了:后端受保护接口还只认 Authorization 头,前端测试甚至用 document.cookie 去模拟 HttpOnly Cookie。这个坑之所以别扭,是因为每一层单看都有点像对的,串起来却完全不成立。最后只能把整个链路一起改:后端支持从 Cookie 取 token,前端不再读取 Cookie,而是用显式会话状态判断登录态,再补后端和前端两侧的回归测试。这件事后来也变成了一条硬规则:认证载体必须前后一致,不能混搭。
坑 4:测试环境和运行时不是一回事。那次前端测试里漏了 ElConfigProvider mock,直接把 vitest worker 拖成了僵尸进程,内存一直涨。问题最烦的地方在于,它会制造一种错觉:你以为是在修一个组件问题,实际上是在修测试环境契约。后来不仅补了 mock,还加了 afterEach 清理,重置模块缓存和状态。我也是从这个坑开始更警惕"测试全绿"这句话,因为它不自动等于"页面真能跑"。
坑 5:Figma 原型导出的代码没法直接用。最开始我的想法很简单:原型都能导出 TSX 了,前端照着落就行。结果一打开才发现完全不是这么回事。Figma 默认导出的是 React + Tailwind + Radix UI,而我们的前端是 Vue 3 + TypeScript + Element Plus。React hooks 不能直接翻,Tailwind 类名和 Element Plus 组件 API 对不上,Radix 的行为模式也不是 Vue 这套。难受的点不在于它不能用,而在于它"看起来像能用"。最后只能把 319 个 TSX 文件当视觉参照,重新翻译成 Vue 组件。这事花了整整一天,也顺手打掉了我一个不太成熟的想法:设计稿导出代码,不等于你真的拿到了可复用实现。
写在最后
这次经历让我重新理解了"AI 原生开发"。
程序员的角色当然在变。你需要想清楚要做什么(需求),定好规矩(宪法),拆好任务,审好代码。执行工作确实可以更多交给 AI。
但做到后面,我越来越确定,有三件事 AI 不能替我做。
第一,它不能替我定义边界。单实例就是单实例,v1 不做的东西就是不做,不能因为某个方案听起来更高级就临时加进去。
第二,它不能替我判断跨文件、跨层之间的一致性。前端、后端、测试、运行时,任何一层单看都可能没问题,串起来才知道哪里是错的。
第三,它不能替我确认一个"看起来合理"的方案,是否真的符合当前项目约束。这个判断,说到底还是工程经验。
所以 AI 更像加速器,不是自动驾驶。它能把速度提得很高,但方向盘还得我自己握着。
避坑指南(给准备动手的人)
几个实战层面的建议,方法论之外的东西。
先跑起来,别搞完美主义。不要一上来就想设计一套完美的架构。先用最简单的方案解决问题,跑通了,再慢慢优化。我们的宪法和任务体系就是边做边完善的,不是一开始就写好的。
组合拳才有效。真实世界的开发问题很复杂,单靠一种工具搞不定。Commands + Skills + Hooks + MCP,组合起来用。排查 Bug 时 GPT-5.4 做推理,改 UI 时 TRAE 做微调,文档整理用 Kimi-K2.5,各自干各自擅长的事。
隔离噪声,保持上下文干净。测试跑完几百行日志直接扔进主对话,AI 的上下文就"脏"了,后面回答质量会下降。高噪声任务用子代理隔离,只留结果。我们压测时就是这么干的,只把 P95/P99 数据返回主对话。
系统比 AI 更可靠。凡是"必须做"的事情(安全检查、格式化、测试覆盖),用系统级 Hooks 保障。AI 会忘,代码不会。我们的 CI/CD 里这些检查都是强制执行的。
自动化测试要分清层次。测试工具不是"点一下自动生成"的魔法,而是一套方法论:技能层定义怎么测,脚本层写具体用例(Python + Playwright),辅助脚本管环境。三层各司其职。
如果想试这种方法,建议从小项目开始。写好宪法,拆好任务,让 AI 跑起来。它确实比很多人想象中靠谱。
但如果只让我选一个这 11 天里最值钱的产物,我现在不会选代码量,也不会选提交次数。
更值钱的是,我们把一套怎么和 AI 一起做复杂工程的方法,硬生生从问题里磨出来了。哪些边界必须先定,哪些坑必须写成规则,哪些问题必须靠测试和文档兜底,这套东西比单个项目更耐用。