cvpr2026 MLLM逆袭传统检测器!Rex-Omni:用Next Point Prediction实现高精度通用目标检测。
**论文标题:**Detect Anything via Next Point Prediction
**作者团队:**International Digital Economy Academy (IDEA) Qing Jiang, Junan Huo等
**发表会议:**arXiv 2025年10月
**核心结论:**提出3B参数的Rex-Omni模型,通过量化坐标表示、大规模数据引擎和SFT+GRPO两阶段训练,在零样本目标检测、指代表达理解等10+任务上超越传统检测器和现有MLLM,解决了MLLM定位精度低、重复预测等关键问题。
1.论文摘要
传统目标检测器(如DINO、Grounding DINO)在定位精度上表现出色,但缺乏复杂语言理解能力;而多模态大语言模型(MLLM)虽然具备强语言理解能力,却在精细视觉定位上存在低召回率、坐标漂移和重复预测等问题。针对这一矛盾,本文提出了Rex-Omni------一个3B参数的MLLM模型,通过三大核心设计实现了高精度定位与强语言理解的统一:1)采用量化相对坐标表示,将坐标映射为1000个特殊token,降低学习难度并提升token效率;2)构建四大数据引擎生成22M高质量训练数据,覆盖目标检测、指代表达理解等多任务;3)采用SFT+GRPO两阶段训练,解决SFT阶段的离散几何误差和行为规范问题。实验结果表明,Rex-Omni在COCO、LVIS等多个数据集上的零样本性能超越传统检测器和现有MLLM,成为首个在通用视觉感知任务上全面比肩传统检测器的MLLM。
2. 总架构设计
Rex-Omni基于Qwen2.5-VL-3B架构构建,对模型进行了最小化修改:将原词汇表的最后1000个token重新定义为量化坐标的特殊token,每个token对应0-999的量化坐标值。模型采用统一的文本-视觉接口,所有任务都通过自然语言指令驱动输入输出。输入支持文本提示和视觉提示( bounding box转换为坐标token),输出则统一为结构化token序列,包括描述短语、坐标token和分隔符。模型通过直接预测坐标token序列来完成目标检测、点定位、OCR等多种视觉感知任务,实现了多任务的统一建模。

图1:Rex-Omni整体架构设计
3.核心创新点
▪ 高效量化坐标表示方案:将坐标量化为0-999的相对值,每个值用1个特殊token表示,相比绝对坐标减少了token长度(一个bbox仅需4个token,而原子token表示需要15个),同时降低了坐标预测的学习难度。这种设计既保留了MLLM的语言理解能力,又提升了定位精度和推理效率。
▪ 大规模高质量数据引擎:构建了四个定制化数据引擎,包括Grounding数据引擎(3M grounding标注)、Referring数据引擎(3M指代表达标注)、Pointing数据引擎(5M点标注)和OCR数据引擎(2M OCR标注),结合8.9M公开数据集,共生成22M高质量训练数据,为模型提供了丰富的空间推理和语言 grounding 监督。
▪ SFT+GRPO两阶段训练策略:第一阶段通过SFT在22M数据上学习基础坐标预测能力;第二阶段采用GRPO强化学习,通过几何感知奖励(IoU、点-in-mask等)和行为感知优化,解决SFT阶段的离散几何误差和输出行为不规范问题,显著减少重复预测和大框错误,提升模型的输出一致性和定位精度。
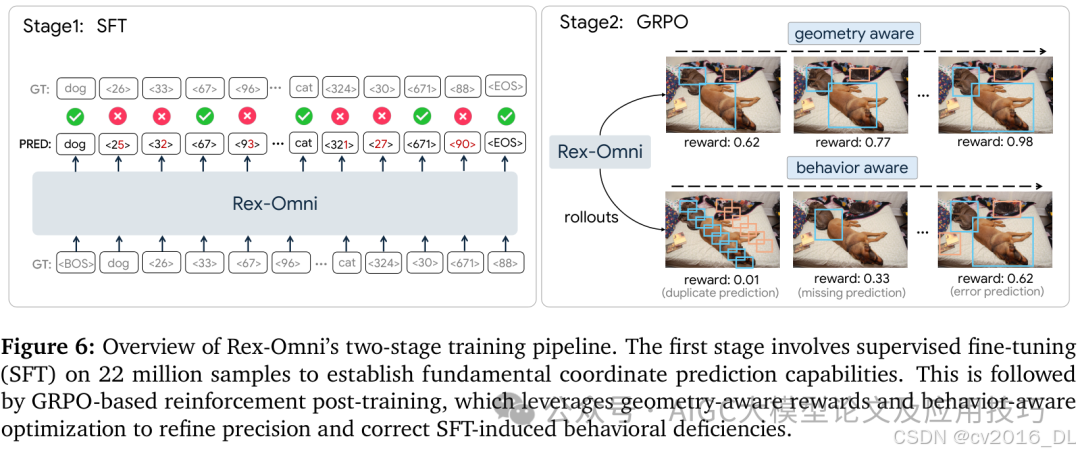
图2:SFT+GRPO两阶段训练架构
4.关键方法与实验结果
论文在11个视觉感知任务上对Rex-Omni进行了全面评估,包括通用目标检测(COCO、LVIS)、密集小目标检测(VisDrone、Dense200)、指代表达理解(HumanRef、RefCOCOg)、UI grounding、文档布局理解等。实验对比了传统检测器(DINO、Grounding DINO)和主流MLLM(Qwen2.5-VL、SEED1.5-VL等),结果显示Rex-Omni在零样本设置下显著超越现有方法。

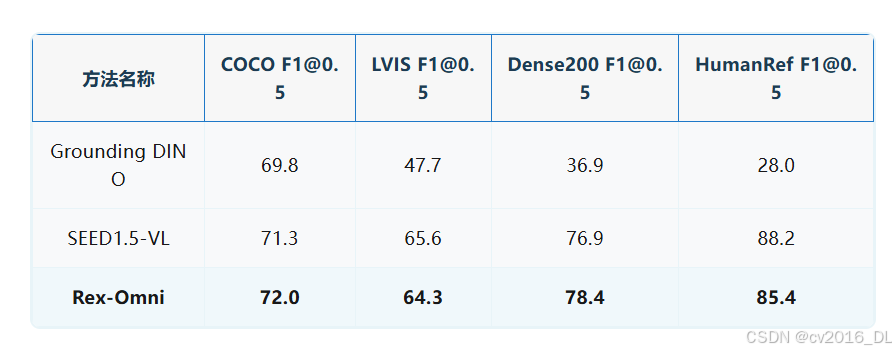
图3:目标检测结果对比分析
在COCO数据集上,Rex-Omni的F1@IoU=0.5达到72.0,超越Grounding DINO(69.8)和SEED1.5-VL(71.3);在LVIS长尾巴数据集上,F1@IoU=0.5达到64.3,远超Grounding DINO的47.7;在密集小目标检测任务中,Rex-Omni在Dense200数据集上的F1@IoU=0.5达到78.4,相比SFT阶段提升了18.2,展示了GRPO在解决重复预测和大框错误上的有效性。
5.应用价值与展望
·Rex-Omni实现了高精度视觉定位与强语言理解的统一,在多种场景中具备广泛应用前景:在机器人领域,可用于复杂环境下的目标定位和操作;在UI交互领域,能实现基于自然语言的界面元素定位;在文档理解领域,可完成布局分析和OCR识别等任务。未来研究方向包括模型加速(量化、蒸馏等)、提升复杂场景下的定位精度以及拓展更多下游任务。Rex-Omni为构建下一代通用视觉感知系统提供了重要参考,展示了MLLM在视觉感知领域的巨大潜力。
📚 **论文原文:**https://arxiv.org/pdf/2510.12798
💻 **相关资源:**https://Rex-Omni.github.io
🎯 **核心亮点:**首个在通用视觉感知任务上全面比肩传统检测器的MLLM,SFT+GRPO两阶段训练解决MLLM定位精度和行为规范问题