文章目录
- ceph分布式存储
- [第 1 章 Ceph 分布式存储 介绍](#第 1 章 Ceph 分布式存储 介绍)
-
- 存储中用户角色
- [Ceph 介绍](#Ceph 介绍)
-
- [Ceph 简介](#Ceph 简介)
- [Ceph 技术优势](#Ceph 技术优势)
- [Ceph 使用场景](#Ceph 使用场景)
- [Ceph 历史](#Ceph 历史)
- [上游 Ceph 版本](#上游 Ceph 版本)
- [企业版 Ceph 存储](#企业版 Ceph 存储)
-
- [Ceph 存储](#Ceph 存储)
- [Ceph 架构介绍](#Ceph 架构介绍)
-
- Ceph集群架构简介
-
- Ceph访问方式-简介
- Ceph存储后端组件-简介
- Ceph访问方式-详细
-
- [Ceph原生API(librados)](#Ceph原生API(librados))
- [Ceph块设备(RBD、librbd)](#Ceph块设备(RBD、librbd))
- Ceph对象网关(RADOS网关、librgw)
- Ceph文件系统(CephFS、libcephfs)
- 存储访问方式选择
- Ceph后端存储组件-详细
-
- Ceph监视器(MON)
- Ceph对象存储设备(OSD)
- Ceph管理器(MGR)
- Ceph元数据服务器(MDS)
- [集群映射(Cluster Map)](#集群映射(Cluster Map))
- [第 2 章 Ceph 分布式存储 部署](#第 2 章 Ceph 分布式存储 部署)
-
- [Ceph 集群安装介绍](#Ceph 集群安装介绍)
-
- [Ceph 集群安装方式](#Ceph 集群安装方式)
- [Ceph 集群 最小硬件规格](#Ceph 集群 最小硬件规格)
- [Ceph 服务端口](#Ceph 服务端口)
- [Cephadm 简介](#Cephadm 简介)
- [Cephadm 与其他服务交互](#Cephadm 与其他服务交互)
- [Cephadm 管理接口](#Cephadm 管理接口)
-
- [Ceph CLI 接口](#Ceph CLI 接口)
- [Ceph Dashboard 接口](#Ceph Dashboard 接口)
- [Ceph 集群安装过程](#Ceph 集群安装过程)
- [Ceph 集群组件管理](#Ceph 集群组件管理)
ceph分布式存储
第 1 章 Ceph 分布式存储 介绍
存储中用户角色
云存储用户角色
在一个比较大的云存储环境中,可能存在不同职责的存储用户。
存储管理员
存储管理员作为主要角色,执行以下任务:
- 安装、配置和维护 Ceph 存储集群。
- 对基础架构架构师进行有关 Ceph 功能和特性的培训。
- 告知用户有关 Ceph 数据表示和方法的信息,作为他们数据应用程序的选择。
- 提供弹性和恢复,例如复本、备份和灾难恢复方法。
- 通过基础架构即代码实现自动化和集成。
- 提供对数据分析和高级海量数据挖掘的访问。
存储操作员
- 存储操作员协助存储集群的日常操作,通常不如存储管理员经验丰富。
- 存储操作员主要使用 Ceph Dashboard GUI 来查看和响应集群警报和统计信息。
- 存储操作员还负责日常存储管理任务,例如更换故障存储设备。
其他存储相关的角色
其他直接使用 Ceph 的角色包括应用程序开发人员、项目经理和具有数据处理、数据仓库、大数据和类似应用程序需求的服务管理员。存储管理员经常与这些角色进行交流。定义这些关系有助于说明存储管理员职责,并阐明存储管理员范围的任务限制或边界。
- 云操作员,管理组织中的云资源,例如 OpenStack 或 OpenShift 基础设施。存储管理员与云操作员密切合作,维护 Ceph 集群。
- 自动化工程师,负责为常见的重复任务创建剧本。
- 应用程序开发人员(DevOps 开发人员),可以是原始代码开发人员、维护人员或其他负责应用程序正确部署和行为的云用户。存储管理员与应用程序开发人员协调以确保存储资源可用、设置配额并保护应用程序存储。
- 服务管理员,管理最终用户服务(不同于操作系统服务)。服务管理员具有与项目经理类似的角色,但针对的是现有的生产服务产品。
- 部署工程师(DevOps 工程师),在更大的环境中,专职人员与存储管理员和应用程序开发人员一起执行、管理和调整应用程序部署。
- 应用架构师,应用程序架构师可以在 Ceph 基础架构布局与资源可用性、扩展和延迟之间建立关联。这种架构专业知识可帮助存储管理员有效地设计复杂的应用程序部署。为了支持云用户及其应用程序,存储管理员必须了解资源可用性、扩展和延迟的这些相同方面。
- 基础架构架构师,存储管理员必须掌握存储集群的架构布局,才能管理资源位置、容量和延迟。 Ceph 集群部署和维护的基础架构架构师是存储管理员的主要信息来源。 基础架构架构师可能是云服务提供商员工或供应商解决方案架构师或顾问。
- 数据中心操作员,是较低 Ceph 存储基础设施层的角色,负责数据供应。数据中心操作员通常受雇于公共云服务提供商或私有数据中心云中组织的内部 IT 团队。
组织中用户角色
由于组织之间的人员配备、技能、安全性和规模不同,因此角色的实施通常不同。 尽管角色有时与个人相匹配,但用户通常会根据他们的工作职责承担多个角色。
- 在电信服务提供商和云服务提供商中,常见的角色是云操作员、存储操作员、基础架构架构师和云服务开发人员,通常只消费存储而不维护它们。
- 在银行、金融等需要安全、私有、专用基础架构的组织中,所有角色都由内部人员配备。 存储管理员、云操作员和基础架构架构师角色充当服务提供商并支持所有其他角色。
- 在大学和较小的实施中,技术支持人员可以承担所有角色。 一个人可能会承担存储管理员、基础架构架构师和云操作员角色。
Ceph 介绍
Ceph 简介
-
Ceph 是一款开源、分布式、软件定义存储 。
-
Ceph 具备极高的可用性、 扩展性和易用性, 用于存储海量数据。
-
Ceph 存储可部署在通用服务器上, 这些服务器的CPU可以是x86架构, 也可以是ARM架构。 Ceph 支持在同一集群内既有x86主机,又有ARM 主机。
软件定义 software-defined storage (SDS)
Ceph 技术优势
- 采用 RADOS 系统将所有数据作为对象, 存储在存储池中。
- 去中心化, 客户端可根据CRUSH算法自行计算出对象存储位置, 然后进行数据读写。
- 集群可自动进行扩展、 数据再平衡、 数据恢复等。
Ceph 使用场景
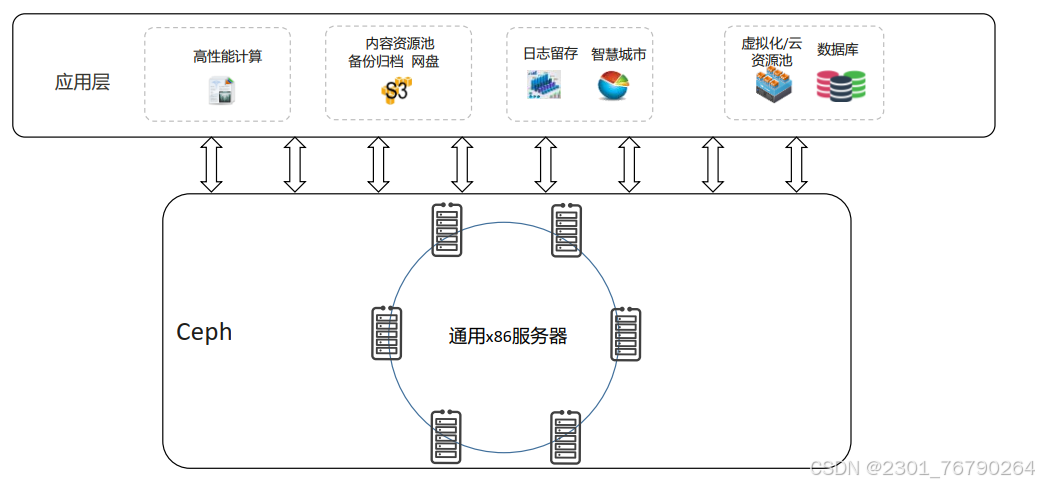
Ceph 历史
-
Ceph是圣克鲁兹加利福尼亚大学的 **Sage Weil 在2003年开发的,他的博士学位项目的一部分。**初始的项目原型是大约 40000 行 C++代码的 Ceph 文件系统,于 2006 年遵循 LGPL 协议(Lesser GUN Public License)开源。Ceph没有采用双重许可模式,也就不存在只针对企业版的特性。
-
2003-2007 年是Ceph的研究开发时期。在这期间,它的核心组件逐步形成,并且社区对项目的贡献开始逐渐变大。
-
2007年年末,Ceph已经越来越成熟,并开始等待孵化。
-
2012年4月,Sage Weil 在 DreamHost 的资助下成立了 Inktank 公司,主要目的是提供广泛的 Ceph 专业服务和技术支持。
-
2014年4月,Inktank 成为红帽大家庭的一员,Inktank Ceph Enterprise 也变为Ceph 存储。
-
此外,Ceph也与Linux内核、SUSE、OpenStack项目、CloudStack等项目进行了整合。一些公司将Ceph整合为存储设备产品的核心,如富士通的CD10000项目和SANDisk的InfiniFlash。
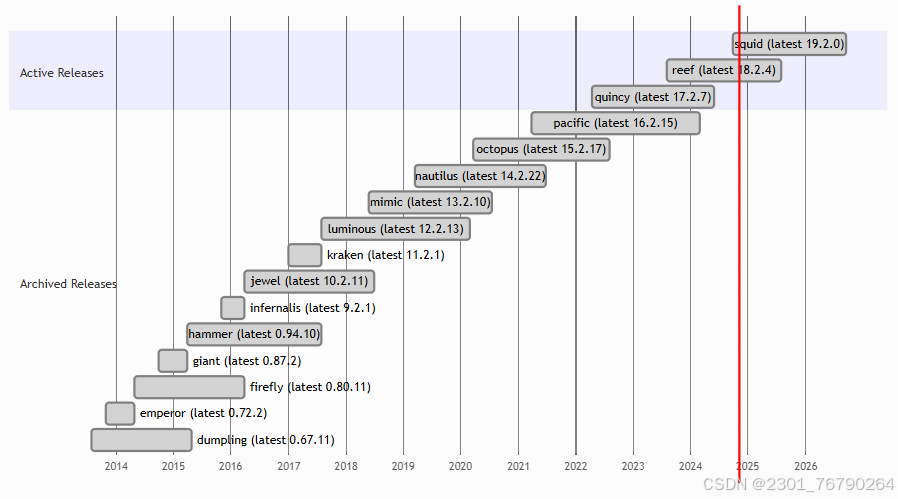
上游 Ceph 版本
参考链接: https://docs.ceph.com/en/latest/releases/
统计时间:2024-11
| Release code name | Version | LTS | Release date | Retirement date |
|---|---|---|---|---|
| Argonaut | 0.48.x | July 2012 | retired | |
| Bobtail | 0.56.x | January 2013 | retired | |
| Cuttlefish | 0.61.x | May 2013 | retired | |
| Dumpling | 0.67.x | Yes | August 2013 | May 2015 |
| Emperor | 0.72.x | November 2013 | May 2014 | |
| Firefly | 0.80.x | Yes | May 2014 | December 2015 |
| Giant | 0.87.x | October 2014 | May 2015 | |
| Hammer | 0.94.x | Yes | April 2015 | August 2017 |
| Infernalis | 9.2.x | November 2015 | April 2016 | |
| Jewel | 10.2.x | Yes | April 2016 | June 2018 |
| Kraken | 11.2.x | January 2017 | August 2017 | |
| Luminous | 12.2.x | Yes | August 2017 | January 2020 |
| Mimic | 13.2.x | Yes | June 2018 | April 2020 |
| nautilus | 14.2.x | Yes | March 2019 | June 2021 |
| octopus | 15.2.x | Yes | 2020-03-23 | 2022-06-01 |
| pacific | 16.2.x | Yes | 2021-03-31 | 2023-06-01 |
| Quincy | 17.2.x | Yes | 2022-04-19 | 2024-06-01 |
| Reef | 18.2.X | Yes | 2023-08-07 | 2025-08-01 |
| Squid | 19.2.X | Yes | 2024-09-26 | 2026-09-19 |
自Infernalis起,上游 Ceph 采用了新的版本号编号方案:每一稳定发行版主要版本号递增1。
- 2017年年底之前,上游CEPH项目每年发布两个稳定版本。
- 截止到Luminous版本,上游项目交替发布开发版本和长期稳定(LTS)版本。稳定版本发布后,将停止更新开发版本。红帽的RHCS产品与社区的LTS版本的CEPH生命周期一致。
- 从 Nautilus release (14.2.0)开始,每年 March 1st 发布一个稳定版本。稳定版本周期大概2年。
版本格式 x.y.z 说明:
-
x identifies the release cycle (e.g., 13 for Mimic).
-
y identifies the release type:
-
x.0.z - development releases (for early testers and the brave at heart)
-
x.1.z - release candidates (for test clusters, brave users)
-
x.2.z - stable/bugfix releases (for users)
-
-
z identifies the release number
企业版 Ceph 存储
Ceph 存储
-
Ceph 存储是一个企业级别的、软件定义的、支持数千客户端、存储容量 EB 级别的分布式数据对象存储,提供统一存储(对象、块和文件存储)。
-
**Ceph 存储与 Ceph 项目的关系,类似于RHEL与Fedora关系。**红帽定期将来自上游项目的最新变化整合到企业版、并提供专业支持。红帽对Ceph存储的改进也会以开源形式回馈到上游项目。
-
红帽为企业版Ceph 存储提供36个月支持,比上游支持长1年。
Ceph 架构介绍
Ceph集群架构简介
Ceph存储是一种分布式数据对象存储。这是一种企业级软件定义存储解决方案,可扩展至数以千计数据访问量在艾字节以上的客户端。Ceph旨在提供卓越的性能、可靠性和可扩展性。
Ceph采用模块化分布式架构,包含下列元素:
- 对象存储后端,称为RADOS(可靠的自主分布式对象存储)
- 与RADOS交互的多种访问方式
RADOS是一种自我修复、自我管理、基于软件的对象存储。
Ceph访问方式-简介
Ceph提供以下访问Ceph集群的方法:
-
Ceph原生API(librados)
-
Ceph块设备(RBD、librbd),也称为 RADOS块设备(RBD)镜像
-
Ceph对象网关(RADOSGW、librgw)
-
Ceph文件系统(CephFS、libcephfs)
Ceph存储后端组件-简介
- **监控器(MON)**维护集群状态映射。它们可帮助其他守护进程互相协调。
- **对象存储设备(OSD)**存储数据并处理数据复制、恢复和重新平衡。
- **管理器(MGR)**通过基于浏览器的仪表板和RESTAPI,跟踪运行时指标并公开集群信息。
- **元数据服务器(MDS)**存储CephFS使用的元数据(而非对象存储或块存储),以便客户端能够高效运行 POSIX命令。
这些守护进程可以扩展,以满足所部署的存储集群的要求。
下图描述了Ceph集群的四种数据访问方法、支持访问方式的库,以及管理和存储数据的底层Ceph组件。
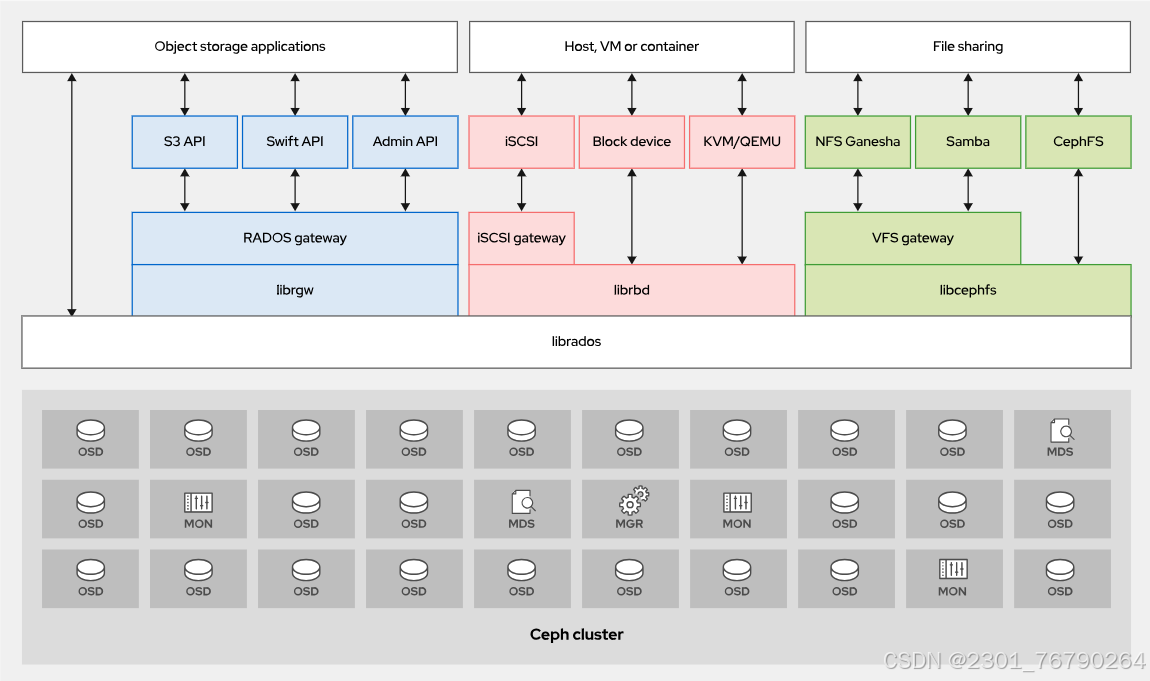
Ceph访问方式-详细
Ceph原生API(librados)
实施Ceph块设备、Ceph对象网关等其他Ceph接口的基础库为librados。librados库是原生C语言库,可以让应用直接与RADOS协作来访问Ceph集群存储的对象。也有类似的库适用于C++、Java、Python、Ruby、Erlang和 PHP。
为最大化性能,请编写软件以直接与librados配合使用。这种方式可以在改进Ceph环境中存储性能方面达到最佳效果。为了简化对Ceph存储的访问,您可以改为使用所提供的更高级访问方式,如ceph块设备、Ceph对象网关(RADOSGW)和CephFS。
Ceph块设备(RBD、librbd)
Ceph块设备(RADOS块设备或RBD)通过RBD镜像在Ceph集群内提供块存储。Ceph分散在集群不同的OSD中构成RBD镜像的个体对象。由于组成RBD的对象分布到不同的OSD,对块设备的访问自动并行处理。
RBD提供下列功能:
- Ceph集群中虚拟磁盘的存储
- Linux内核中的挂载支持
- QEMU、KVM和 OpenStack Cinder 的启动支持
Ceph对象网关(RADOS网关、librgw)
Ceph对象网关(RADOS网关、RADOSGW或RGW)是使用librados构建的对象存储接口。它使用这个库来与Ceph集群通信,并且直接写入到OSD进程。它通过RESTfulAPI为应用提供了网关,并且支持两种接口:Amazon S3和 OpenStack Swift。
Ceph对象网关提供扩展支持,它不限制部署的网关数量,而且支持标准的HTTP负载均衡器。Ceph对象网关包括以下用例:
- 镜像存储(例如,SmugMug和TumbIr)
- 备份服务
- 文件存储和共享(例如,Dropbox)
Ceph文件系统(CephFS、libcephfs)
Ceph文件系统(CephFS)是一种并行文件系统,提供可扩展的、单层级结构共享磁盘。红帽Ceph存储可为CephFS提供生产环境支持,包括快照支持。
Ceph元数据服务器(MDS)管理与CephFS中存储的文件相关联的元数据,包括文件访问、更改和修改时间戳。
存储访问方式选择
-
为了最大限度地提高性能,请编写用户的应用程序以直接使用 librados 。
-
如果想简化对Ceph存储的访问,也可以使用其他三种访问方式。
Ceph后端存储组件-详细
RADOS(Reliable ,Autonomic ,Distributed Object Store),即可靠的、自主的、分布式的对象存储,是Ceph存储系统的核心。Ceph的所有优秀特性都是由RADOS提供的 ,包括分布式对象存储、高可用性、高可靠性、没有单点故障、自我修复以及自我管理等。Ceph中的一切数据都以对象的形式存储,RADOS负责存储这些对象,而不考虑它们的数据类型。
Ceph监视器(MON)
- MON 必须就集群的状态达成共识 ,才能对外提供服务。
- Ceph 集群配置奇数个监视器,以确保监视器在对集群状态进行投票时可以建立法定人数。
- 要使 Ceph 存储集群正常运行和访问,必须有超过一半的已配置监视器正常工作。
- Ceph Monitor (MON) 是维护集群映射的守护进程。 集群映射是多个映射的集合,包含有关集群状态及其配置的信息。 Ceph 必须处理每个集群事件,更新相应的映射,并将更新后的映射复本到每个 MON 守护进程。
Ceph对象存储设备(OSD)
Ceph 对象存储设备 (OSD) 将存储设备连接到 Ceph 存储集群。 单个存储服务器可以运行多个 OSD 守护进程并为集群提供多个 OSD。
Ceph 客户端和 OSD 守护进程使用可扩展哈希下的受控复制 (CRUSH) 算法来高效地计算有关对象位置的信息,而不是依赖于中央查找表。
CRUSH映射
**CRUSH 将每个对象分配给一个放置组 (PG),也就是单个哈希存储桶, PG 将对象映射给多个OSD。**PG 是对象(应用层)和 OSD(物理层)之间的抽象层。 CRUSH 使用伪随机放置算法将对象分布在 PG 之间,并使用规则来确定 PG 到 OSD 的映射。 如果发生故障,Ceph 会将 PG 重新映射到不同的物理设备 (OSD) 并同步它们的内容以匹配配置的数据保护规则。
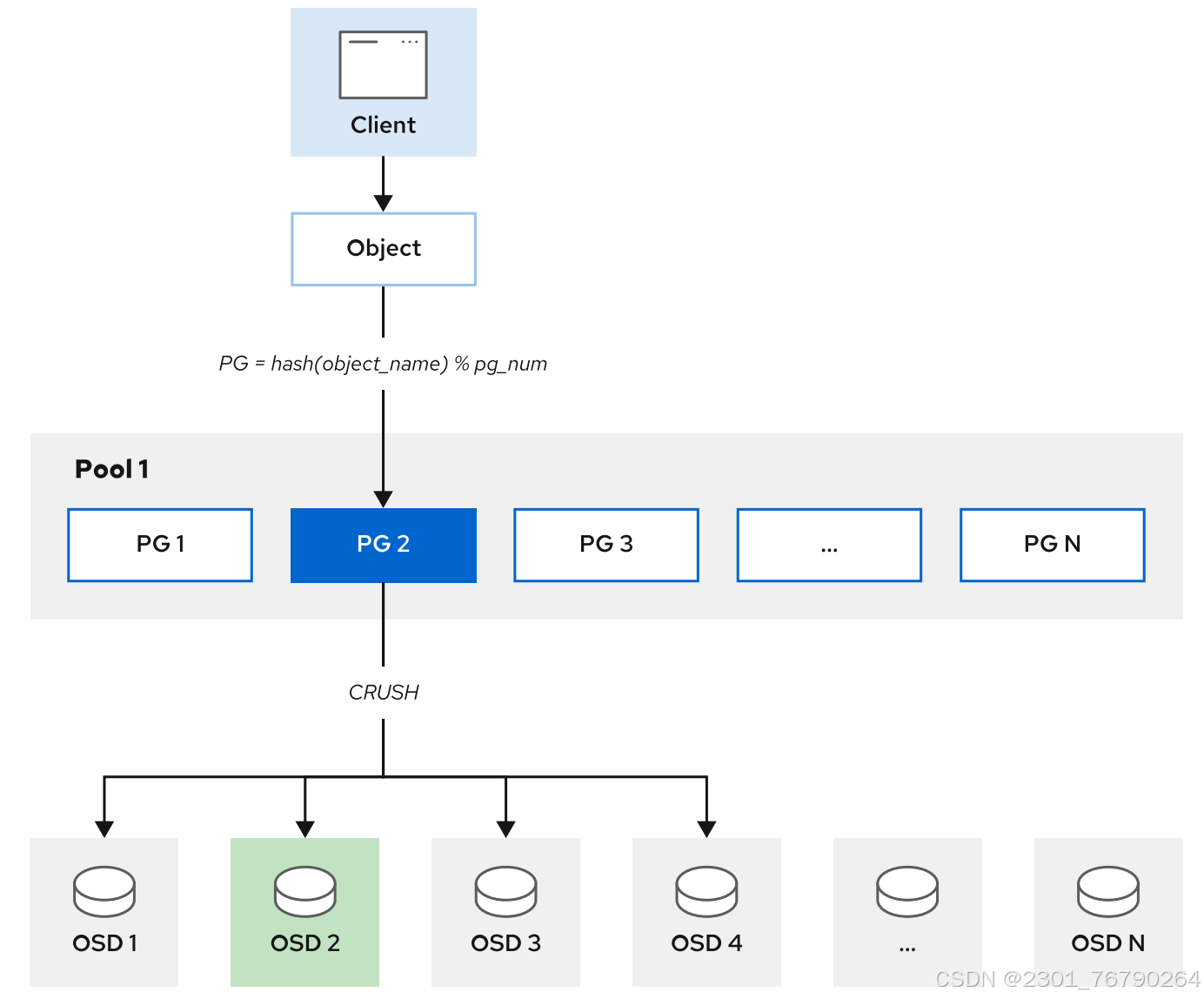
主要,次要OSD
与对象关联的多个OSD中,其中一个 OSD 是对象归置组的主 OSD,Ceph 客户端在读取或写入数据时总是联系主 OSD。 其他 OSD 是次要 OSD,在集群发生故障时确保数据的弹性可靠。
主要 OSD 功能:
- 服务所有 I/O 请求
- 复本和保护数据
- 检查数据一致性
- 重新平衡数据
- 恢复数据
次要 OSD 功能:
- 始终在主 OSD 的控制下行动
- 可以变为主 OSD
!WARNING
运行 OSD 的主机不得使用基于内核的客户端挂载 Ceph RBD 映像或 CephFS 文件系统。 由于内存死锁或之前会话上挂起的阻塞 I/O,挂载的资源可能会变得无响应。
**典型的Ceph集群部署方案:为每个物理磁盘创建一个OSD守护进程。**OSD也支持以更灵活的方式部署OSD守护进程,比如每个磁盘、每个主机或者每个RAID卷创建一个OSD守护进程。
**如下图:**Ceph集群包涵3个Monitor,多个OSD服务器。其中一个OSD服务器提供5个OSD,每个OSD守护进程对应一个存储设备。各个存储设备使用文件系统格式化,目前仅支持XFS文件系统。XFS文件系统上默认启用扩展属性,用于存储有关内部对象状态、快照元数据和Ceph RADOS网关ACL的信息。
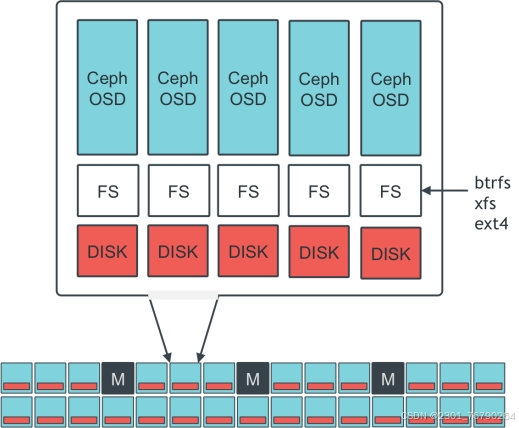
OSD日志 :每个OSD都有自己的OSD日志,OSD日志与文件系统日志无关,用于提升OSD操作写性能。**客户端的写请求常常是随机的,OSD进程按顺序将请求写入到日志。**这让主机文件系统有更多的时间来合并写操作,提高写效率,从而提高了性能。在所有OSD日志记录了写请求之后,CEPH集群通知客户端写入完成,然后将OSD日志的内容应用到后端文件系统。应用完成后,回收已经提交的日志请求,以回收日志存储设备上的空间。
-
当OSD或者存储服务器故障:如果日志未应用到文件系统,则根据日志将数据replay到文件系统;如果已经应用到后端文件系统,则根据复本恢复。
-
OSD日志最好配置为独立的、速度快的磁盘上,例如SSD,性能和写效率更好。
Ceph管理器(MGR)
- Ceph Manager(MGR)负责集群大部分数据统计。
- **如果集群中没有MGR,不会影响客户端I/O操作。**但是,将不能查询集群统计数据。为避免这种情形,建议为每个集群至少部署两个Ceph Managers,每个Managers运行在独立的失败域中。
- MGR 守护程序提供集中访问从集群收集的所有数据,并为存储管理员提供一个简单的 Web 仪表板。 MGR 守护进程还可以将状态信息导出到外部监控服务器,例如 Zabbix。
Ceph元数据服务器(MDS)
- Ceph 元数据服务器 (MDS) 管理 Ceph 文件系统 (CephFS) 元数据。
- MDS提供符合 POSIX 的共享文件系统元数据管理,包括所有权、时间戳和模式。
- MDS 使用 RADOS 存储元数据, 将文件 inode 映射到对象以及 Ceph 在树中存储数据的位置。
- 访问 CephFS 文件系统的客户端首先向 MDS 发送请求,MDS 提供客户端 获取文件内容所需的信息以便从正确的OSD获取文件内容。
集群映射(Cluster Map)
前面我们提到,MON维护集群映射。
Ceph 客户端和 OSD 通过集群映射确定数据存储位置。
五个映射表示集群拓扑,统称为集群映射。Ceph监控器守护进程维护集群映射。CephMON集群在监控器守护进程出现故障时确保高可用性。
集群映射有:
- 监视器映射(Monitor Map) , 包含集群的 fs id; 每个监视器(monitor)的位置、名称、地址和端口; 和地图时间戳。 fsid 是一个唯一的、自动生成的标识符 (UUID),用于标识 Ceph 集群。Ceph Monitor 守护进程维护集群映射。 使用 ceph mon dump 命令查看监视器图。
- OSD映射(OSD Map) , 包含集群的 fs id、池列表、复本大小、归置组编号、OSD 列表及其状态以及映射时间戳。 使用 ceph osd dump 命令查看 OSD 映射。
- 放置组映射(Placement Group Map) ,包含 PG 版本; 使用百分比; 每个归置组的详细信息,例如 PG ID、Up Set、Acting Set、PG 的状态、每个池的数据使用统计信息; 和地图时间戳。 使用 ceph pg dump 命令查看 PG Map 统计信息。
- CRUSH映射(CRUSH Map) , 包含存储设备列表、故障域层次结构(例如设备、主机、机架、行、房间)以及在存储数据时遍历层次结构的规则。 使用 ceph osd crush dump 命令查看 cursh Map 统计信息。
- 元数据服务器映射(MDS map) ,包含用于存储元数据的池、元数据服务器列表、元数据服务器状态和映射时间戳。 使用 ceph fs dump 命令查看 MDS 映射。
其他 map:
- Manager map ,包含 Manager 服务器列表、Manager 服务器状态和映射时间戳。 使用 ceph mgr dump 命令查看 MGR 映射。
- Service map ,包含RGW信息,如果集群中安装了RGW。 使用 ceph service dump 命令查看 rgw 统计信息。
第 2 章 Ceph 分布式存储 部署
Ceph 集群安装介绍
Ceph 集群安装方式
官方推荐部署方式:
- Cephadm:基于容器部署,支持 Octopus 及以后版本,部署完成后可通过命令行和图形界面进行ceph集群的管理。
- Rook:基于 kubernetes 部署,支持 Nautilus 及以后版本,部署完成后可通过命令行和图形界面进行ceph集群的管理,同时可通过 kubernetes 对组件所在 pod 进行管理。
其他部署方式:
- ceph-ansible,通过ansible进行ceph部署
- ceph-deploy,已经不再维护,不建议使用该方式部署
- DeepSea,通过salt进行ceph部署
- 手动部署
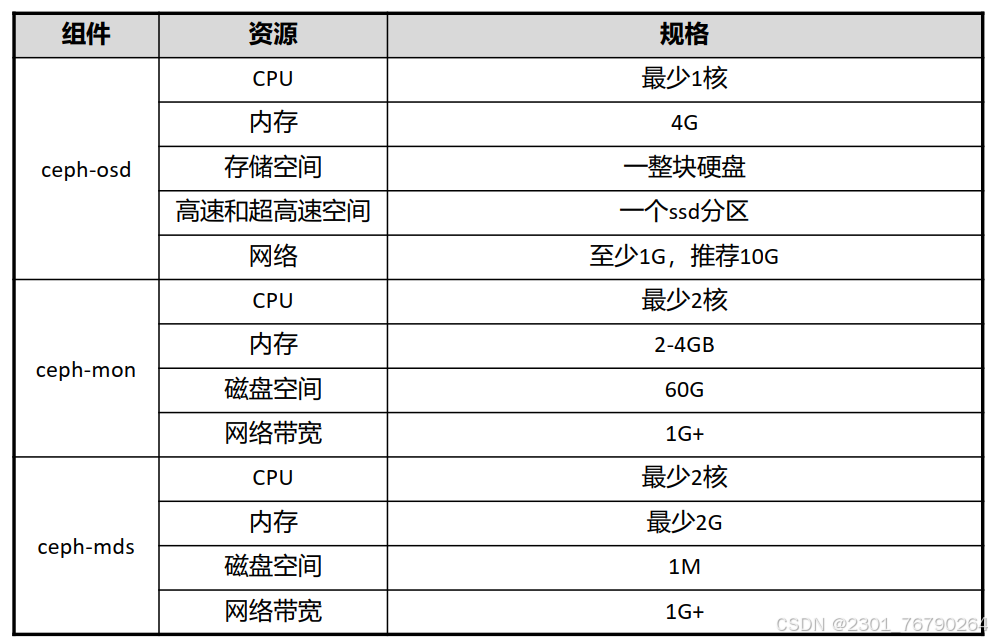
Ceph 集群 最小硬件规格
此处的最小硬件规格指的是在实际生产中的规格,实验手册中的规格会比此表中的规格小。
关于OSD的资源需注意:
- 每增加一个osd服务,就需要增加列出的资源。
- OSD的CPU资源最少是1核,后续根据带宽和IOPS进行调整,每200-500MB/s增加一核,或者每1000-3000IOPS增加一核。
- OSD的内存可以选择2G-4G,可以实现基本功能,但是会有卡顿。
Ceph 服务端口
| 服务 | 端口 | 描述 |
|---|---|---|
| MON | 6789、 3300 | 用于Ceph集群内部通信端口 |
| OSD | 6800-7300 | 每个osd占用四个端口,分别用于通过public网络与客户端和MON通信、 通过cluster网络或public网络与其他OSD数据通信、通过cluster网络或 public进行心跳数据包交换,其中用于心跳通信的端口需两个 |
| MDS | 6800-7300 | 用于与元数据服务器通信 |
| MGR | 8443 | 用于以SSL的方式登录ceph的图形化页面 |
| RESTful 管理模块 | 8003 | 用于以SSL的方式与RESTful管理模块通信 |
| Prometheus 管理模块 | 9283 | 用于与ceph的Prometheus插件通信 |
| Prometheus 告警管理 | 9093 | 用于与Prometheus的告警管理服务通信 |
| Prometheus 节点导出器 | 9100 | 用于与Prometheus节点导出器进程通信 |
| Grafana 服务器 | 3000 | 用于与Grafana服务通信 |
| RGW | 80 | 用于RADOSGW通信,如果client.rgw的配置为空, cephadm就使用默认 的80端口 |
| Ceph iSCSI 网关 | 9287 | 用于与ceph iSCSI网关通信 |
说明:
- 所有端口都是TCP协议。
- 在实验手册中,为了降低安装难度,直接关闭了firewalld及SELinux。
Cephadm 简介
-
Cephadm 是一个ceph全生命周期管理工具, 通过"引导( bootstrapping ) " 可创建一个包含一个MON和一个MGR的单节点集群, 后续可通过自带的编排接口进行集群的扩容、 主机添加、 服务部署。
-
Cephadm 使用容器部署 Ceph,大大降低了部署 Ceph 集群的复杂性和包依赖性。
-
cephadm 软件包安装在集群第一个节点中,该节点充当引导节点。Cephadm 是部署新集群时启动的第一个守护程序,同时也是管理器守护程序 (MGR) 中的一个模块。
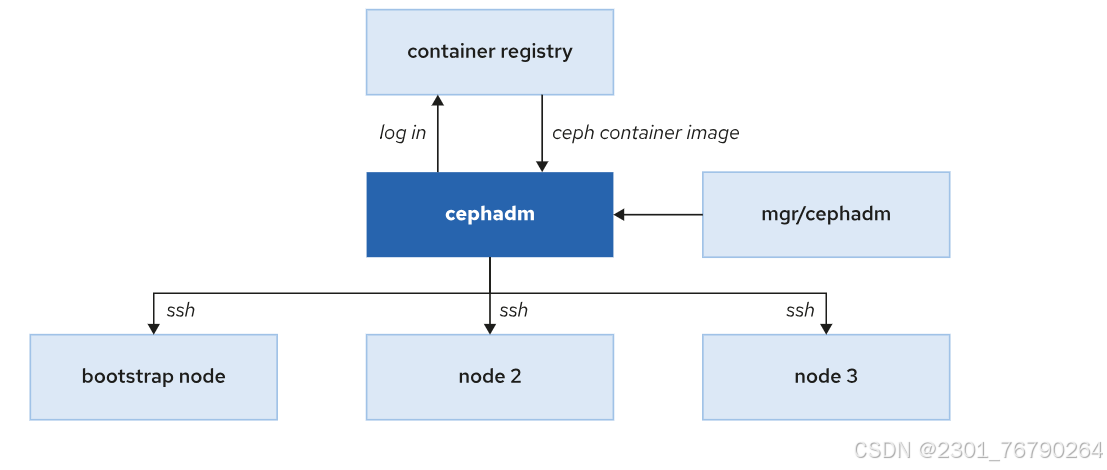
Cephadm 与其他服务交互
-
Cephadm 登录容器注册表来拉取 Ceph 镜像并在使用该镜像的节点上部署服务。
-
Cephadm 使用 SSH 连接,向集群添加新主机、添加存储或监控这些主机。
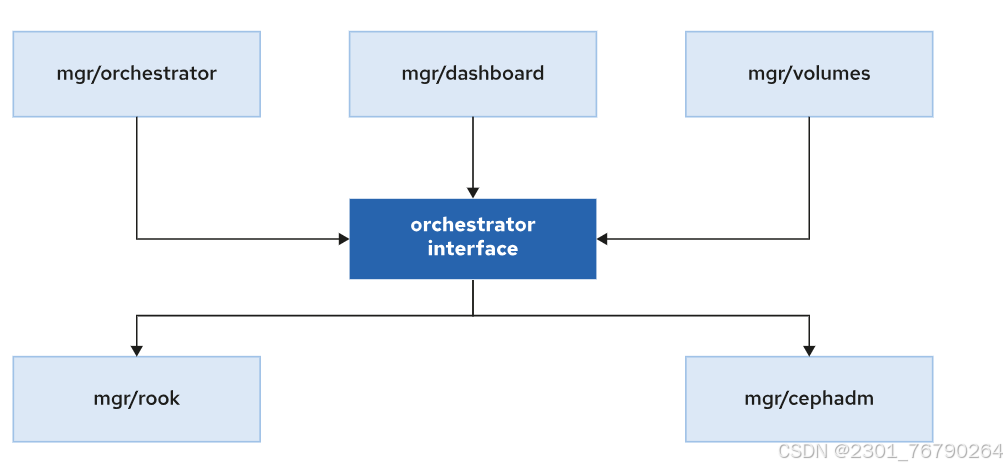
Cephadm 管理接口
Ceph 使用容器化部署,首先创建一个最小的集群,只有一个主机(引导节点)和两个守护进程(监视器和管理器守护进程)。
Ceph 提供两个管理接口:Ceph CLI 和 Dashboard GUI,用于配置 Ceph 守护进程和服务以及扩展或收缩集群。
cephadm 工具与 Ceph Manager 编排模块交互,Ceph Manager Orchestrator 再与其他组件交互:
Ceph CLI 接口
cephadm shell 命令启动一个容器化版本的 shell,容器中安装了所有必需的 Ceph 包。该命令应该只在引导节点中运行,因为在引导集群时只有该节点可以访问 /etc/ceph 中的管理密钥环。
实际情况,在集群中其他节点也可以执行,例如ceph1。
bash
[root@ceph1 ~]# cephadm shell
Inferring fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
Using recent ceph image quay.io/ceph/ceph@sha256:f15b41add2c01a65229b0db515d2dd57925636ea39678ccc682a49e2e9713d98
[ceph: root@ceph1 /]# 还可以通过容器化的 shell 直接运行命令:cephadm shell -- command。
bash
[root@ceph1 ~]# cephadm shell -- ceph status
Inferring fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
Using recent ceph image quay.io/ceph/ceph@sha256:f15b41add2c01a65229b0db515d2dd57925636ea39678ccc682a49e2e9713d98
cluster:
id: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1.laogao.cloud,ceph2,ceph3 (age 12m)
mgr: ceph2.oetbal(active, since 11m), standbys: ceph1.laogao.cloud.zoqmbt, ceph3.npaxvt
osd: 9 osds: 9 up (since 12m), 9 in (since 3w)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 1 active+clean为了操作方便,可以直接在物理主机执行ceph命令,需要安装ceph-common软件包。
bash
[root@ceph1 ~]# dnf install -y ceph-common
[root@ceph1 ~]# ceph statusCeph Dashboard 接口
Ceph Dashboard GUI 是一个基于 Web 的应用程序,用于监视和管理集群。 Ceph Dashboard GUI 得到了增强,可通过此界面执行许多集群任务,比 Ceph CLI 更直观的方式提供集群信息。
与 Ceph CLI 一样,Dashboard GUI Web 是 ceph-mgr 守护进程的一个模块。 默认情况下,Ceph 在创建集群时将 Dashboard GUI 部署在引导节点,并使用 TCP 端口 8443。
Ceph Dashboard GUI 提供以下功能:
- 用户和角色管理,用户可以创建具有多个权限和角色的不同用户帐户。
- 单点登录,仪表板 GUI 允许通过外部身份提供者进行身份验证。
- 审计,用户可以将仪表板配置为记录所有 REST API 请求。
- 安全,默认情况下,仪表板使用 SSL/TLS 来保护所有 HTTP 连接。
Ceph Dashboard GUI 还实现了集群管理和监控功能:
- 管理功能
- 使用 CRUSH 地图查看集群层次结构
- 启用、编辑和禁用管理器模块
- 创建、删除和管理 OSD
- 管理 iSCSI
- 管理池
- 监控功能
- 检查整体集群健康状况
- 查看集群中的主机及其服务
- 查看日志
- 查看集群警报
- 检查集群容量
下图显示了仪表板 GUI 的状态屏幕,可以快速查看一些重要的集群参数,例如集群状态、集群中的主机数量或 OSD 数量。
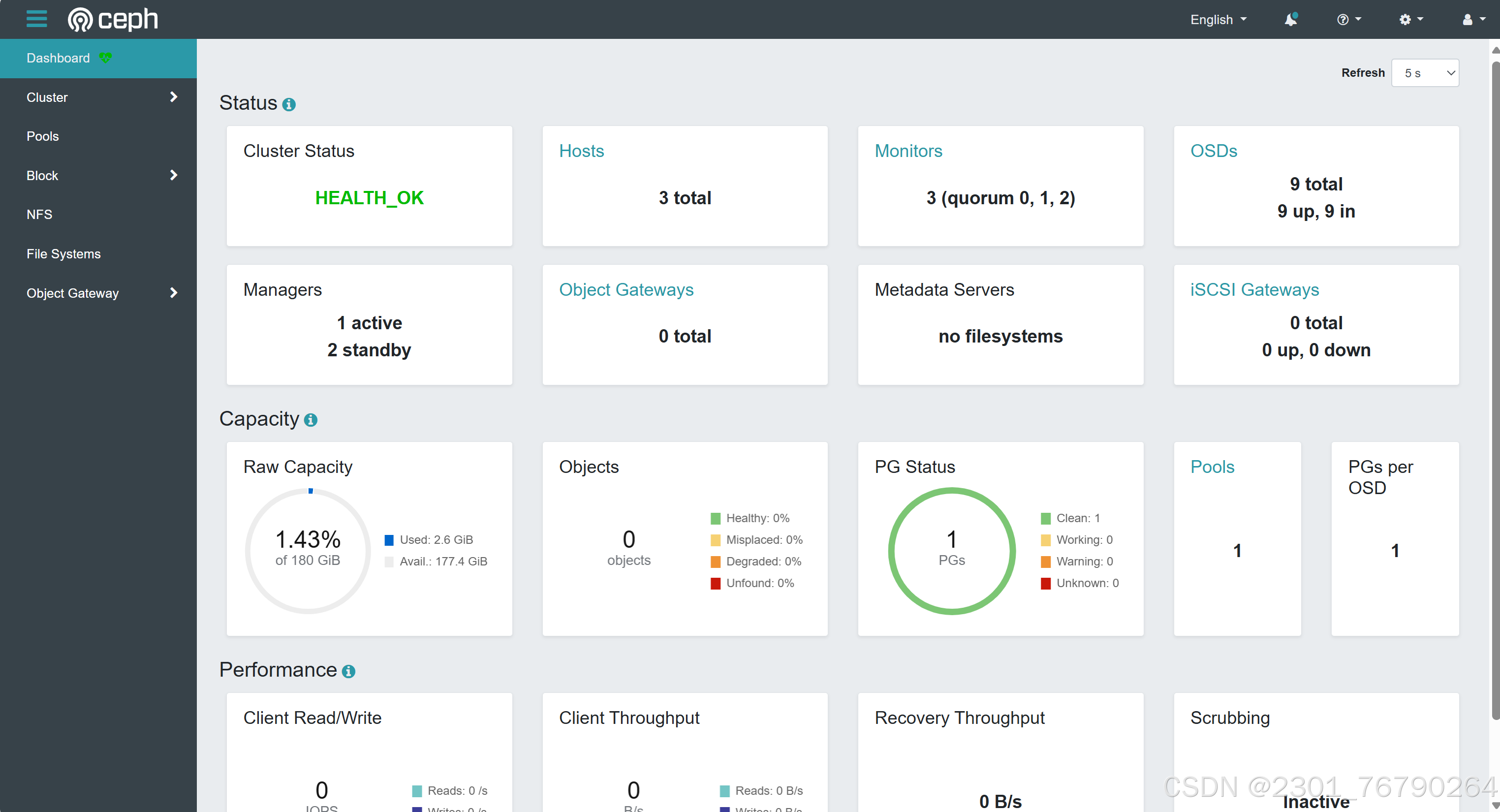
Ceph 集群安装过程
Ceph 集群环境说明
部署方法:cephadm
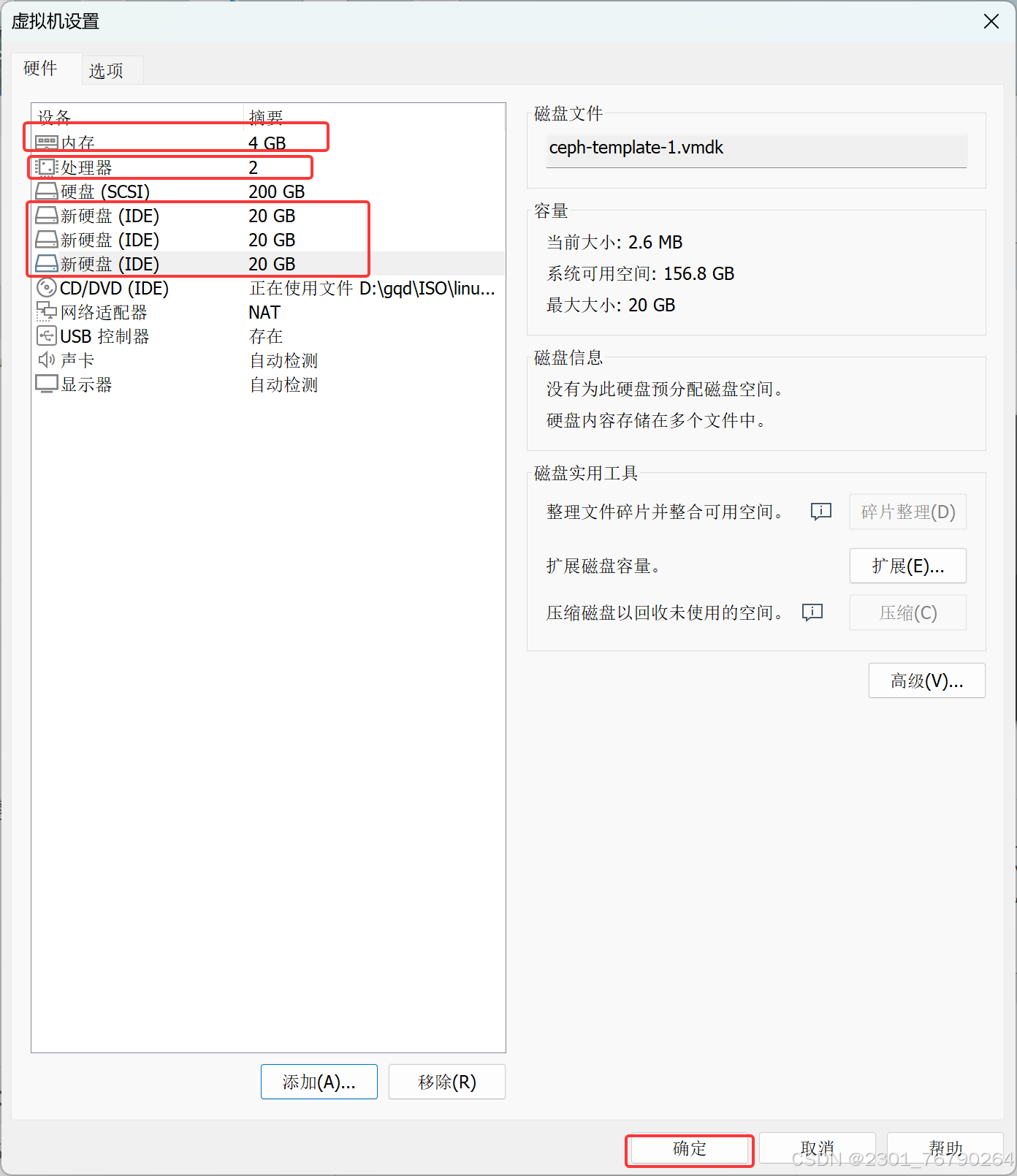
操作系统:Centos Stream 8(最小化安装)
硬件配置:2 cpu、4G memory、1个系统盘+3个20G数据盘
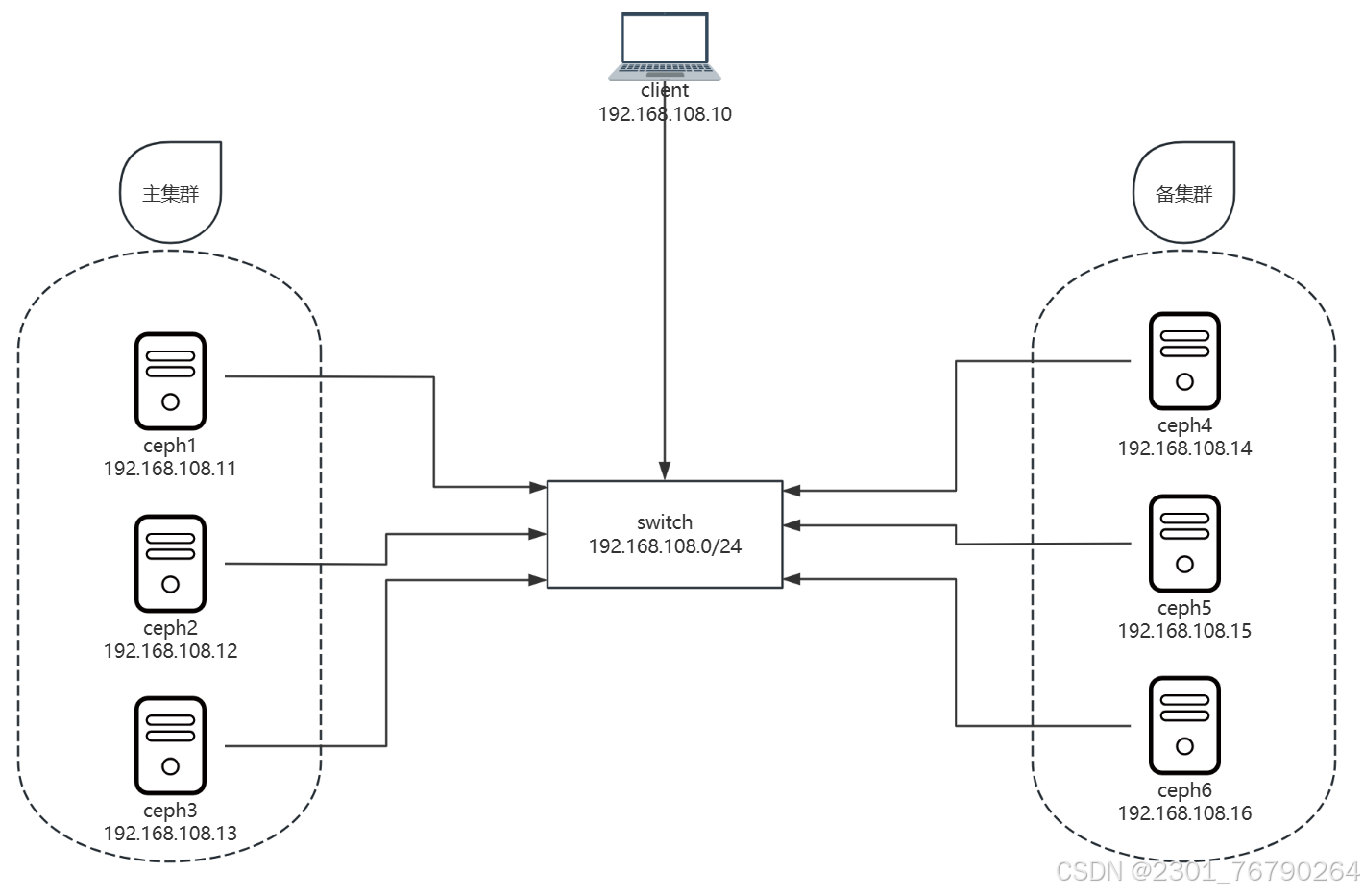
本教材共使用7台虚拟机:
- 客户端:client
- 主集群:ceph1、ceph2、ceph3
- 备集群:ceph4、ceph5、ceph6
| 主机名 | IP 地址 | 角色 |
|---|---|---|
| client.laogao.cloud | 192.168.108.10 | 客户端节点 |
| ceph1.laogao.cloud | 192.168.108.11 | 主集群-ceph 节点 |
| ceph2.laogao.cloud | 192.168.108.12 | 主集群-ceph 节点 |
| ceph3.laogao.cloud | 192.168.108.13 | 主集群-ceph 节点 |
| ceph4.laogao.cloud | 192.168.108.14 | 备集群-ceph 节点 |
| ceph5.laogao.cloud | 192.168.108.15 | 备集群-ceph 节点 |
| ceph6.laogao.cloud | 192.168.108.16 | 备集群-ceph 节点 |
网络拓扑如下图所示:
准备虚拟机模板
基于CentOS-Stream-8-template模板克隆出ceph-template
根据实验硬件要求,更改ceph-template硬件配置。
bash
# 1 配置主机名解析
[root@localhost ~]# cat >> /etc/hosts << EOF
###### ceph ######
192.168.108.10 client.laogao.cloud client
192.168.108.11 ceph1.laogao.cloud ceph1
192.168.108.12 ceph2.laogao.cloud ceph2
192.168.108.13 ceph3.laogao.cloud ceph3
192.168.108.14 ceph4.laogao.cloud ceph4
192.168.108.15 ceph5.laogao.cloud ceph5
192.168.108.16 ceph6.laogao.cloud ceph6
EOF
# 2 关闭 SELinux
[root@localhost ~]# sed -ri 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
# 3 关闭防火墙
[root@localhost ~]# systemctl disable firewalld --now
# 4 配置yum仓库
[root@localhost ~]# cat << 'EOF' > /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/centos-vault/8-stream/storage/x86_64/ceph-pacific
enabled=1
gpgcheck=0
EOF
# 5 安装基础软件包
[root@localhost ~]# dnf install -y bash-completion vim lrzsz unzip rsync sshpass tar
# 6 配置时间同步
[root@localhost ~]# dnf install -y chrony
[root@localhost ~]# systemctl enable chronyd --now
# 7 安装 cephadm
[root@localhost ~]# dnf install -y cephadm
[root@localhost ~]# cephadm --help
usage: cephadm [-h] [--image IMAGE] [--docker] [--data-dir DATA_DIR]
[--log-dir LOG_DIR] [--logrotate-dir LOGROTATE_DIR]
[--sysctl-dir SYSCTL_DIR] [--unit-dir UNIT_DIR] [--verbose]
[--timeout TIMEOUT] [--retry RETRY] [--env ENV]
[--no-container-init]
{version,pull,inspect-image,ls,list-networks,adopt,rm-daemon,rm-cluster,run,shell,enter,ceph-volume,zap-osds,unit,logs,bootstrap,deploy,check-host,prepare-host,add-repo,rm-repo,install,registry-login,gather-facts,exporter,host-maintenance,disk-rescan}
...
Bootstrap Ceph daemons with systemd and containers.
positional arguments:
{version,pull,inspect-image,ls,list-networks,adopt,rm-daemon,rm-cluster,run,shell,enter,ceph-volume,zap-osds,unit,logs,bootstrap,deploy,check-host,prepare-host,add-repo,rm-repo,install,registry-login,gather-facts,exporter,host-maintenance,disk-rescan}
sub-command
version get ceph version from container
pull pull the default container image
inspect-image inspect local container image
ls list daemon instances on this host
......
# 安装 cephadm 的时候,会自动安装官方推荐的容器引擎 podman
[root@localhost ~]# rpm -q podman
podman-4.9.4-0.1.module_el8+971+3d3df00d.x86_64
# 8 提前下载镜像
[root@localhost ~]# podman pull quay.io/ceph/ceph:v16
[root@localhost ~]# podman pull quay.io/ceph/ceph-grafana:8.3.5
[root@localhost ~]# podman pull quay.io/prometheus/node-exporter:v1.3.1
[root@localhost ~]# podman pull quay.io/prometheus/alertmanager:v0.23.0
[root@localhost ~]# podman pull quay.io/prometheus/prometheus:v2.33.4
# 准备配置主机脚本
[root@localhost ~]# cat > /usr/local/bin/sethost <<'EOF'
#/bin/bash
hostnamectl set-hostname ceph$1.laogao.cloud
nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.108.1$1/24 ipv4.gateway 192.168.108.2 ipv4.dns 192.168.108.2
init 0
EOF
[root@localhost ~]# chmod +x /usr/local/bin/sethost关机虚拟机,并打快照。
准备集群节点
使用完全克隆方式,克隆出其他虚拟机,并配置主机名和IP地址。
bash
#ceph1到ceph6按以下修改
[root@localhost ~]# sethost 1 #ceph1用1,ceph2到ceph6分别为2-6
#client做以下修改
[root@localhost ~]# hostnamectl set-hostname client.laogao.cloud
[root@localhost ~]# nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.108.10/24 ipv4x.gateway 192.168.108.2 ipv4.dns 192.168.108.2Ceph 集群初始化
Ceph 初始化
bash
[root@ceph1 ~]# cephadm bootstrap --mon-ip 192.168.108.11 --allow-fqdn-hostname --initial-dashboard-user admin --initial-dashboard-password laogao@123 --dashboard-password-noupdate选项说明:
- --mon-ip 192.168.108.11,指定 monitor ip。
- --allow-fqdn-hostname,指定允许使用长名称。当主机名是长名称时,初始化时必须使用该参数。
- --initial-dashboard-user admin,指定 Web UI 登录的管理员账户。
- --initial-dashboard-password laogao@123,指定 Web UI 登录的管理员账户对应密码。
- --dashboard-password-noupdate,指定不要更新 Web UI 登录密码。
输出信息如下:
yaml
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman (/usr/bin/podman) version 4.9.4 is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
Verifying IP 192.168.108.11 port 3300 ...
Verifying IP 192.168.108.11 port 6789 ...
Mon IP `192.168.108.11` is in CIDR network `192.168.108.0/24`
Mon IP `192.168.108.11` is in CIDR network `192.168.108.0/24`
Internal network (--cluster-network) has not been provided, OSD replication will default to the public_network
Pulling container image quay.io/ceph/ceph:v16...
Ceph version: ceph version 16.2.15 (618f440892089921c3e944a991122ddc44e60516) pacific (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting public_network to 192.168.108.0/24 in mon config section
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 9283 ...
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to /etc/ceph/ceph.pub
Adding key to root@localhost authorized_keys...
Adding host ceph1.laogao.cloud...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph1.laogao.cloud:8443/
User: admin
Password: laogao@123
Enabling client.admin keyring and conf on hosts with "admin" label
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/en/pacific/mgr/telemetry/
Bootstrap complete.输出信息说明
Dashboard 登录信息
yaml
Ceph Dashboard is now available at:
URL: https://ceph1.laogao.cloud:8443/
User: admin
Password: laogao@123客户端访问方法
bash
Enabling client.admin keyring and conf on hosts with "admin" label
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell启用遥测
发送匿名数据给社区,以改善Ceph。
yaml
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on访问 dashboard
登录

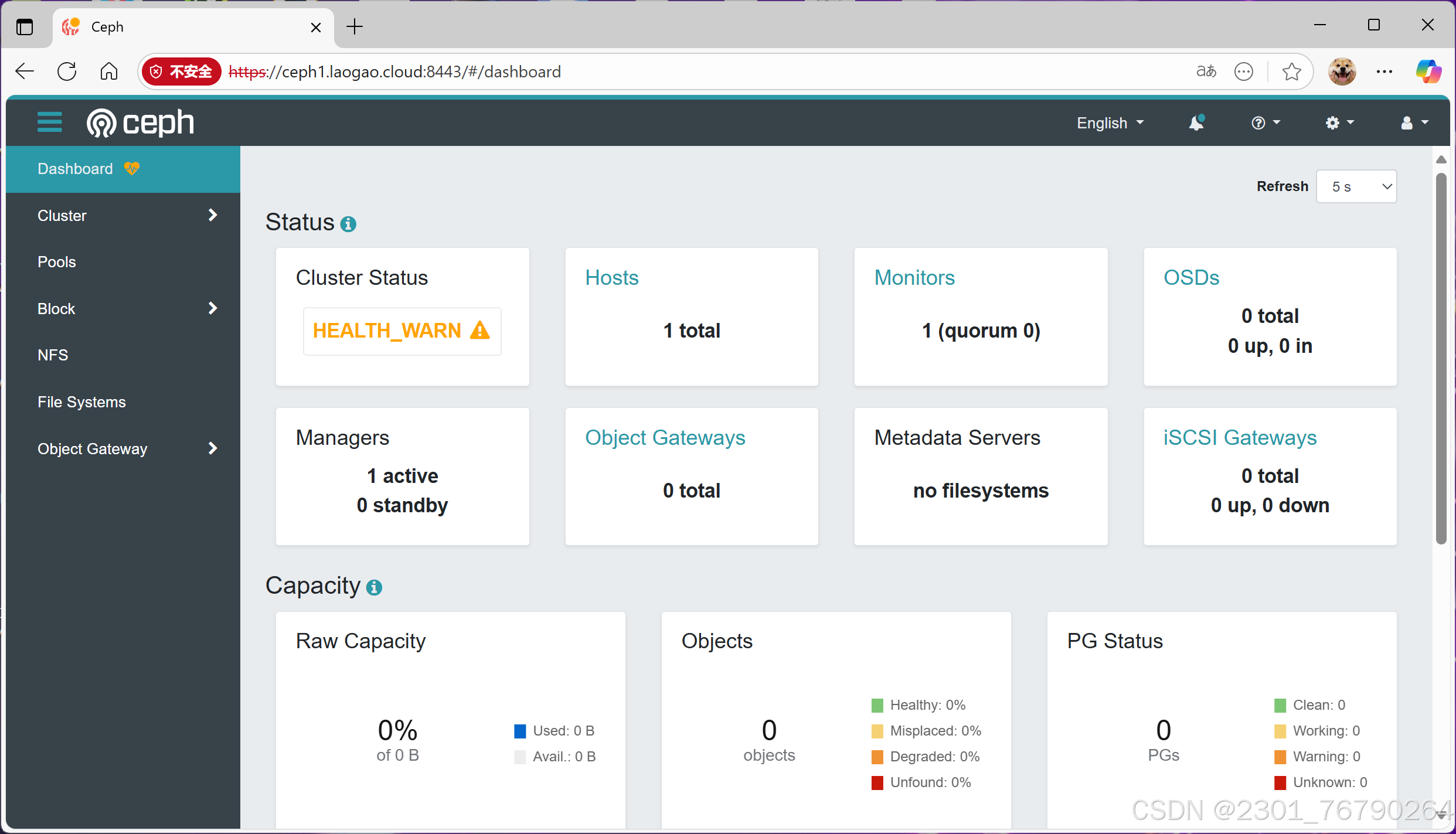
添加节点
添加节点过程:
- Ceph采用共享秘钥进行身份验证, 使用命令"ceph cephadm get-pub-key" 获取到主机接入集群时所需的ssh 公钥。
- 获取到公钥后, 使用该公钥实现对节点的免密ssh管理。
- 使用命令"ceph orch host add" 添加主机。
bash
# 为了配置方便,我们在ceph1上安装ceph客户端工具 ceph-common
[root@ceph1 ~]# dnf install -y ceph-common
# 获取集群公钥
[root@ceph1 ~]# ceph cephadm get-pub-key > ~/ceph.pub
# 推送公钥到其他节点
[root@ceph1 ~]# ssh-copy-id -f -i ~/ceph.pub root@ceph2.laogao.cloud
[root@ceph1 ~]# ssh-copy-id -f -i ~/ceph.pub root@ceph3.laogao.cloud
# 添加节点
[root@ceph1 ~]# ceph orch host add ceph2.laogao.cloud
Added host 'ceph2.laogao.cloud' with addr '192.168.108.12'
[root@ceph1 ~]# ceph orch host add ceph3.laogao.cloud
Added host 'ceph3.laogao.cloud' with addr '192.168.108.13'
[root@ceph1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1.laogao.cloud 192.168.108.11 _admin
ceph2.laogao.cloud 192.168.108.12
ceph3.laogao.cloud 192.168.108.13
3 hosts in cluster
# 等待自动部署服务到其他节点,部署完成后效果如下:
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 8m ago 9m count:1
crash 3/3 8m ago 9m *
grafana ?:3000 1/1 8m ago 9m count:1
mgr 2/2 8m ago 9m count:2
mon 3/5 8m ago 9m count:5
node-exporter ?:9100 3/3 8m ago 9m *
prometheus ?:9095 1/1 8m ago 9m count:1
# crash 3/3个
# mgr 2/2个
# mon 3/5个
# node-exporter 3/3个部署 mon 和 mgr
bash
# 禁用 mon 和 mgr 服务的自动扩展功能
[root@ceph1 ~]# ceph orch apply mon --unmanaged=true
[root@ceph1 ~]# ceph orch apply mgr --unmanaged=true
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 56s ago 12m count:1
crash 3/3 57s ago 12m *
grafana ?:3000 1/1 56s ago 12m count:1
mgr 2/2 57s ago 3s <unmanaged>
mon 3/5 57s ago 8s <unmanaged>
node-exporter ?:9100 3/3 57s ago 12m *
prometheus ?:9095 1/1 56s ago 12m count:1
# mon 和 mgr 的 PLACEMENT 状态为 <unmanaged>
# 配置主机标签,ceph2 和 ceph3 添加标签" _admin"
[root@ceph1 ~]# ceph orch host label add ceph2.laogao.cloud _admin
Added label _admin to host ceph2.laogao.cloud
[root@ceph1 ~]# ceph orch host label add ceph3.laogao.cloud _admin
Added label _admin to host ceph3.laogao.cloud
[root@ceph1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1.laogao.cloud 192.168.108.11 _admin
ceph2.laogao.cloud 192.168.108.12 _admin
ceph3.laogao.cloud 192.168.108.13 _admin
3 hosts in cluster
# 将 mon 和 mgr 组件部署到具有_admin标签的节点上
[root@ceph1 ~]# ceph orch apply mon --placement="label:_admin"
Scheduled mon update...
[root@ceph1 ~]# ceph orch apply mgr --placement="label:_admin"
Scheduled mgr update...
#观察现象
[root@ceph1 ~]# ceph orch ls | egrep 'mon|mgr'
mgr 3/3 2m ago 14s label:_admin
mon 3/3 2m ago 28s label:_admin
[root@ceph1 ~]# ceph orch ps | egrep 'mon|mgr'
部署 OSD
bash
# 将所有主机上闲置的硬盘添加为 OSD
[root@ceph1 ~]# ceph orch apply osd --all-available-devices
Scheduled osd.all-available-devices update...验证
查看集群中部署的服务
bash
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 3s ago 15m count:1
crash 3/3 4s ago 15m *
grafana ?:3000 1/1 3s ago 15m count:1
mgr 3/3 4s ago 2m label:_admin
mon 3/3 4s ago 2m label:_admin
node-exporter ?:9100 3/3 4s ago 15m *
osd.all-available-devices 9 4s ago 25s *
prometheus ?:9095 1/1 3s ago 15m count:1部分输出说明:
- RUNNING:服务的运行状态,前一个数字表示当前运行的服务数量,后一个数字表示系统根据策略或配置推荐的服务部署数量。
- PLACEMENT :为服务编排器部署服务时提供的参数,编排器可根据该参数判断服务所部署的节点,常见的 placement 包括:
- 具体节点名称,例如:
--placement=ceph2 - 标签,例如:
--placement="label:mylabel" - 数量,例如:
--placement="3 host1 host2 host3" unmanaged,表示服务不自动部署。通过设置--unmanaged为true打开该功能,设置为false关闭该功能>
- 具体节点名称,例如:
查看集群状态
bash
[root@ceph1 ~]# ceph -s
cluster:
id: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1.laogao.cloud,ceph2,ceph3 (age 6m)
mgr: ceph1.laogao.cloud.zoqmbt(active, since 15m), standbys: ceph2.oetbal, ceph3.npaxvt
osd: 9 osds: 9 up (since 30s), 9 in (since 45s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 1 active+clean命令
ceph -s对应的长命令为ceph --status。
输出包含:MON、 MGR及OSD的状态,包括数量、位置及运行时间。
集群的健康状态可分为:
- HEALTH_OK:表示健康状态良好
- HEALTH_WARN:表示集群存在告警,需进行排查处理后,可转为HEALTH_OK
- HEALTH_ERR:表示集群存在比较严重的错误,需要立即处理
查看集群 osd 结构
bash
[root@ceph1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000查看集群组件
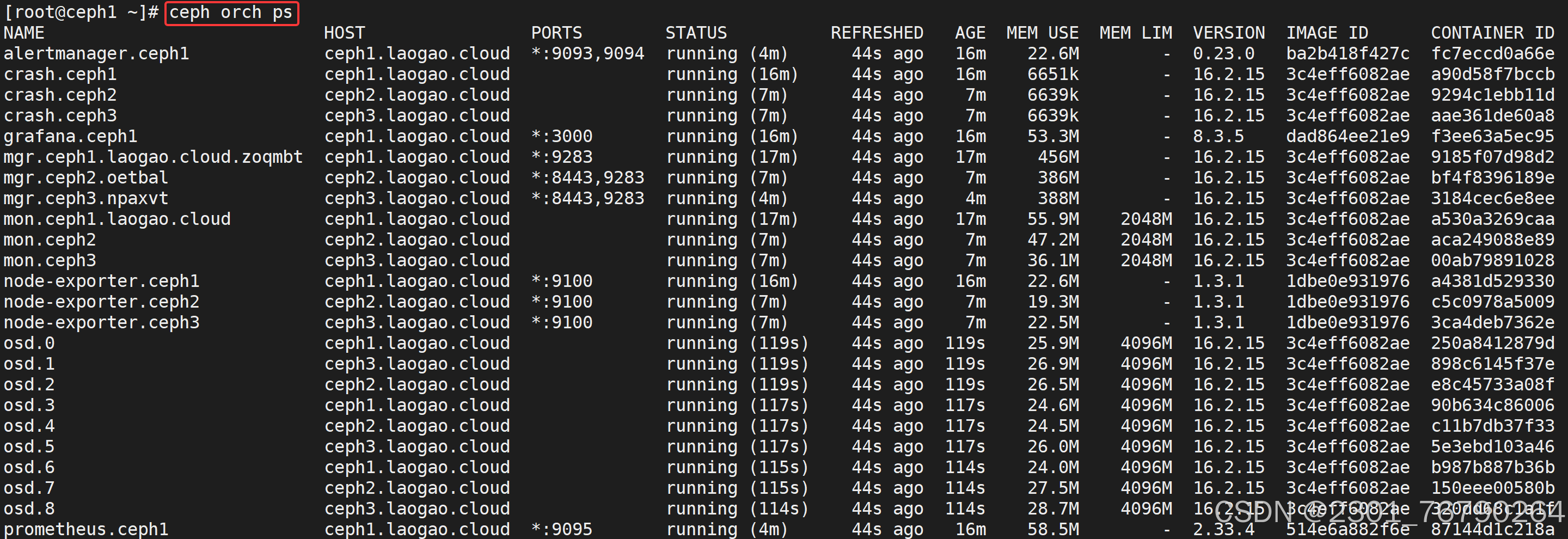
集群中运行的主要组件:
- mgr,ceph 管理程序
- monitor,ceph 监视器
- osd,ceph 对象存储进程
- rgw,ceph 对象存储网关
其他组件:
- crash,崩溃数据收集模块
- prometheus,监控组件
- grafana,监控数据展示dashboard
- alertmanager,prometheus告警组件
- node_exporter,prometheus节点数据收集组件
查询出服务的具体情况后, 可对指定服务进一步操作:
- 使用命令
ceph orch daemon start|stop|restart|redeploy|reconfig <service_name>对指定服务进行启动、停止、重启等操作。 - 使用命令
ceph orch daemon rm <service_name> [--force]可删除指定服务。
!TIP
这时关闭所有ceph存储节点。并打快照,便于后续做实验。
Ceph 集群组件管理
ceph orch 命令
ceph orch 命令与编排器模块交互,编排器模块是ceph-mgr的插件,与外部编排服务交互。
ceph orch 命令支持多个外部编排器:
- host:物理节点
- service type:服务类型,如nfs, mds, osd, mon, rgw, mgr, iscsi
- Service:逻辑服务
- Daemon:进程
cephadm使用的特殊标签:
- _no_schedule:不在此类标签的节点上部署或调度任何服务。
- _no_autotune_memory:不对此类标签的节点进行内存调优。
- _admin:自动将ceph.conf和ceph.client.admin.keyring发送到此类标签的节点上。
禁用服务自动扩展
Ceph 集群服务自动扩展功能,会自动部署ceph组件到存储节点。如果想手动管理 ceph 服务,则需要禁用 ceph 服务自动扩展功能。
bash
# 查看 mon 服务
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/3 90s ago 8m label:_admin
# 禁用 mon 服务自动扩展
[root@ceph1 ~]# ceph orch apply mon --unmanaged=true
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/5 118s ago 4s <unmanaged>
# 启用 mon 服务自动扩展
[root@ceph1 ~]# ceph orch apply mon --unmanaged=false
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/5 2m ago 4s count:5
# 通过标签部署 mon 服务
[root@ceph1 ~]# ceph orch apply mon --placement="label:_admin"
Scheduled mon update...
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/3 3m ago 15s label:_admin删除服务
以 crash 服务为例。
bash
# 禁用服务自动扩展
[root@ceph1 ~]# ceph orch apply crash --unmanaged=true
[root@ceph1 ~]# ceph orch ls crash
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
crash 3/3 3m ago 5s <unmanaged>
# 查看服务中实例
[root@ceph1 ~]# ceph orch ps | grep crash
crash.ceph1 ceph1.laogao.cloud running (5m) 4m ago 24m 6639k - 16.2.15 3c4eff6082ae 5aea4634442b
crash.ceph2 ceph2.laogao.cloud running (5m) 4m ago 15m 6639k - 16.2.15 3c4eff6082ae 51d5f1e1d75c
crash.ceph3 ceph3.laogao.cloud running (4m) 4m ago 15m 6647k - 16.2.15 3c4eff6082ae 406b2a7b9d93
# 删除特定实例
[root@ceph1 ~]# ceph orch daemon rm crash.ceph1
Removed crash.ceph1 from host 'ceph1.laogao.cloud'
[root@ceph1 ~]# ceph orch ps | grep crash
crash.ceph2 ceph2.laogao.cloud running (9m) 8m ago 19m 6639k - 16.2.15 3c4eff6082ae 51d5f1e1d75c
crash.ceph3 ceph3.laogao.cloud running (8m) 8m ago 19m 6647k - 16.2.15 3c4eff6082ae 406b2a7b9d93
# 删除服务
[root@ceph1 ~]# ceph orch rm crash
Removed service crash
[root@ceph1 ~]# ceph orch ls crash #这里需要快点查看
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
crash 1/3 <deleting> 50s <unmanaged>
[root@ceph1 ~]# ceph orch ls crash
No services reported部署服务
使用 ceph 的编排器部署服务, 有两种方式:
-
apply 方式:定义了服务状态,由编排器根据参数自动寻找合适的节点进行服务部署。
语法:
ceph orch apply <service_type> [--placement=<placement_string>] [--unmanaged]例如:
ceph orch apply crash和ceph orch apply mon --placement="label:_admin"。 -
daemon add 方式:根据命令中的参数,直接进行服务部署。
语法:
ceph orch daemon add <daemon_type> <placement>
命令orch apply osd [--all-available-devices]将节点上的所有可用设备配置为OSD。
删除 OSD
确定 OSD 和设备关系
bash
[root@ceph1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1 #主机ceph1下的硬盘
0 hdd 0.01949 osd.0 up 1.00000 1.00000 #看不出来osd.0对应哪块磁盘
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000
# 获取集群id
[root@ceph1 ~]# ceph -s | grep id
id: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
# 登录到ceph1上确认osd.0使用的块设备
[root@ceph1 ~]# ls -l /var/lib/ceph/2faf683a-7cbf-11f0-b5ba-000c29e0ad0e/osd.0/block
lrwxrwxrwx 1 ceph ceph 93 Aug 19 14:01 /var/lib/ceph/2faf683a-7cbf-11f0-b5ba-000c29e0ad0e/osd.0/block -> /dev/ceph-c92942fb-f959-4255-b8e6-751fab70fa79/osd-block-2ed79b2f-d825-4829-b4b0-59879d2ad99c
# 59879d2ad99c是块设备名称最后一串字符
[root@ceph1 ~]# lsblk | grep -B1 59879d2ad99c
sdb 8:16 0 20G 0 disk
└─ceph--c92942fb--f959--4255--b8e6--751fab70fa79-osd--block--2ed79b2f--d825--4829--b4b0--59879d2ad99c 253:4 0 20G 0 lvm
# 确认osd.0对应sdb脚本实现
bash[root@ceph1 ~]# vim /usr/local/bin/show-osd-device
bash#!/bin/bash # author laogao # date 2025-08-19 # Description 确认 osd 和 device 之间对应关系 # usage 在ceph node 上执行 cluster_id=$(ceph -s|grep id |awk '{print $2}') cd /var/lib/ceph/${cluster_id} for osd in osd.* do device_id=$(ls -l $osd/block | awk -F '-' '{print $NF}') device=/dev/$(lsblk |grep -B1 ${device_id} |grep -v ${device_id} | awk '{print $1}') echo $osd : $device done
bash[root@ceph1 ~]# chmod +x /usr/local/bin/show-osd-device执行效果
bash[root@ceph1 ~]# show-osd-device osd.0 : /dev/sdb osd.3 : /dev/sdc osd.6 : /dev/sdd
使用编排删除
示例:删除 osd.0
bash
# 禁用 osd 服务自动扩展
[root@ceph1 ~]# ceph orch apply osd --all-available-devices --unmanaged=true
[root@ceph1 ~]# ceph orch ls osd
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
osd.all-available-devices 9 7m ago 6s <unmanaged>
# 删除 osd.0
[root@ceph1 ~]# ceph orch osd rm 0
Scheduled OSD(s) for removal
# 删除device上数据
[root@ceph1 ~]# ceph orch device zap ceph1.laogao.cloud /dev/sdb --force #看osd0管理的是/dev/sdb还是啥
zap successful for /dev/sdb on ceph1.laogao.cloud
# 确认结果
[root@ceph1 ~]# ceph orch device ls
[root@ceph1 ~]# ceph orch device ls | grep ceph1.*sdb
ceph1.laogao.cloud /dev/sdb hdd 20.0G Yes 72s ago
[root@ceph1 ~]# lsblk
[root@ceph1 ~]# lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 20G 0 disk
# 添加回来
[root@ceph1 ~]# ceph orch apply osd --all-available-devices
#RUNNING重新变为9
[root@ceph1 ~]# ceph orch ls osd
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
osd.all-available-devices 9 6m ago 29s *手动删除过程
bash
# 停止 ceph1 中的 osd
[root@ceph1 ~]# ceph orch daemon stop osd.0
Scheduled to stop osd.0 on host 'ceph1.laogao.cloud'
[root@ceph1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1
0 hdd 0.01949 osd.0 down 1.00000 1.00000 #查看osd.0 down了
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000
# 待 osd 停止后,删除 osd 进程
[root@ceph1 ~]# ceph orch daemon rm osd.0 --force #可以ps aux|grep osd.0观察
Removed osd.0 from host 'ceph1.laogao.cloud'
# 从 crush map 中剔除 osd
[root@ceph1 ~]# ceph osd out 0
marked out osd.0.
# 从 crush map 中删除 osd
[root@ceph1 ~]# ceph osd crush rm osd.0
removed item id 0 name 'osd.0' from crush map
# 执行下面的命令将会自动标记为out,并且从crush map中删除,最后删除osd相关文件。
[root@ceph1 ~]# ceph osd rm 0
removed osd.0
# 删除device上数据
[root@ceph1 ~]# ceph orch device zap ceph1.laogao.cloud /dev/sdb --force
zap successful for /dev/sdb on ceph1.laogao.cloud
# 确认结果
[root@ceph1 ~]# ceph orch device ls|grep 'ceph1.*sdb'
ceph1.laogao.cloud /dev/sdb hdd 20.0G Yes 10s ago
# 添加回来
[root@ceph1 ~]# ceph orch apply osd --all-available-devices删除主机
从集群中删除主机流程:
- 禁用集群所有服务自动扩展
- 查看待删除主机上当前运行的服务
- 停止待删除主机上的所有服务
- 删除主机上的所有服务
- 删除osd在CRUSH中的映射
- 擦除osd盘中的数据
- 从集群中删除主机
示例:删除 ceph2
首先,禁用集群中所有ceph服务自动扩展,进制自动部署osd。
bash
[root@ceph1 ~]# for service in $(ceph orch ls |grep -v -e NAME -e osd| awk '{print $1}');do ceph orch apply $service --unmanaged=true;done
[root@ceph1 ~]# ceph orch apply osd --all-available-devices --unmanaged=true其次,删除主机上运行的服务。
bash
# 查看ceph2上运行的daemon
[root@ceph1 ~]# ceph orch ps |grep ceph2 |awk '{print $1}'
crash.ceph2
mgr.ceph2.oetbal
mon.ceph2
node-exporter.ceph2
osd.2
osd.4
osd.7
# 删除相应 daemon
[root@ceph1 ~]# for daemon in $(ceph orch ps |grep ceph2 |awk '{print $1}');do ceph orch daemon rm $daemon --force;done
# 手动清理crush信息
[root@ceph1 ~]# ceph osd crush rm osd.2
[root@ceph1 ~]# ceph osd crush rm osd.4
[root@ceph1 ~]# ceph osd crush rm osd.7
[root@ceph1 ~]# ceph osd crush rm ceph2
[root@ceph1 ~]# ceph osd rm 2 4 7
# 清理磁盘数据
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdb --force
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdc --force
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdd --force然后,删除主机。
bash
[root@ceph1 ~]# ceph orch host rm ceph2
[root@ceph1 ~]# ceph orch host ls #查看现象ceph2被移除
HOST ADDR LABELS STATUS
ceph1.laogao.cloud 192.168.108.11 _admin
ceph3.laogao.cloud 192.168.108.13 _admin
2 hosts in cluster最后,删除ceph2中相应ceph遗留文件。
bash
[root@ceph2 ~]# rm -rf /var/lib/ceph
[root@ceph2 ~]# rm -rf /etc/ceph /etc/systemd/system/ceph*
[root@ceph2 ~]# rm -rf /var/log/ceph实验完成后,恢复环境。
恢复环境-还原快照
d=true;done
root@ceph1 \~# ceph orch apply osd --all-available-devices --unmanaged=true
**其次**,删除主机上运行的服务。
```bash
# 查看ceph2上运行的daemon
[root@ceph1 ~]# ceph orch ps |grep ceph2 |awk '{print $1}'
crash.ceph2
mgr.ceph2.oetbal
mon.ceph2
node-exporter.ceph2
osd.2
osd.4
osd.7
# 删除相应 daemon
[root@ceph1 ~]# for daemon in $(ceph orch ps |grep ceph2 |awk '{print $1}');do ceph orch daemon rm $daemon --force;done
# 手动清理crush信息
[root@ceph1 ~]# ceph osd crush rm osd.2
[root@ceph1 ~]# ceph osd crush rm osd.4
[root@ceph1 ~]# ceph osd crush rm osd.7
[root@ceph1 ~]# ceph osd crush rm ceph2
[root@ceph1 ~]# ceph osd rm 2 4 7
# 清理磁盘数据
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdb --force
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdc --force
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdd --force然后,删除主机。
bash
[root@ceph1 ~]# ceph orch host rm ceph2
[root@ceph1 ~]# ceph orch host ls #查看现象ceph2被移除
HOST ADDR LABELS STATUS
ceph1.laogao.cloud 192.168.108.11 _admin
ceph3.laogao.cloud 192.168.108.13 _admin
2 hosts in cluster最后,删除ceph2中相应ceph遗留文件。
bash
[root@ceph2 ~]# rm -rf /var/lib/ceph
[root@ceph2 ~]# rm -rf /etc/ceph /etc/systemd/system/ceph*
[root@ceph2 ~]# rm -rf /var/log/ceph实验完成后,恢复环境。
恢复环境-还原快照