5.4 彻底搞懂 KV Cache:大模型推理提速的"空间换时间"魔法
在了解大语言模型(LLM)的底层逻辑时,你一定会频繁听到一个词------KV Cache 。
简而言之,KV Cache 是大模型推理性能优化的一个王牌技术。它能够在不影响任何计算精度的前提下,利用"空间换时间"的思想,大幅提升大模型的生成速度。
今天,我们就用最通俗的语言,彻底扒掉 KV Cache 的底裤,看看它到底是怎么工作的!
一、 痛点:如果不做优化,大模型有多"笨"?
要理解 KV Cache,首先得知道大模型(基于 Transformer Decoder 架构)是怎么说话的。大模型说话像挤牙膏一样,是"自回归"(Autoregressive)生成的:也就是根据前面的字,一个字一个字地往外吐。
举个例子:你想让模型补全"中国的首都",模型最终输出"是北京"。
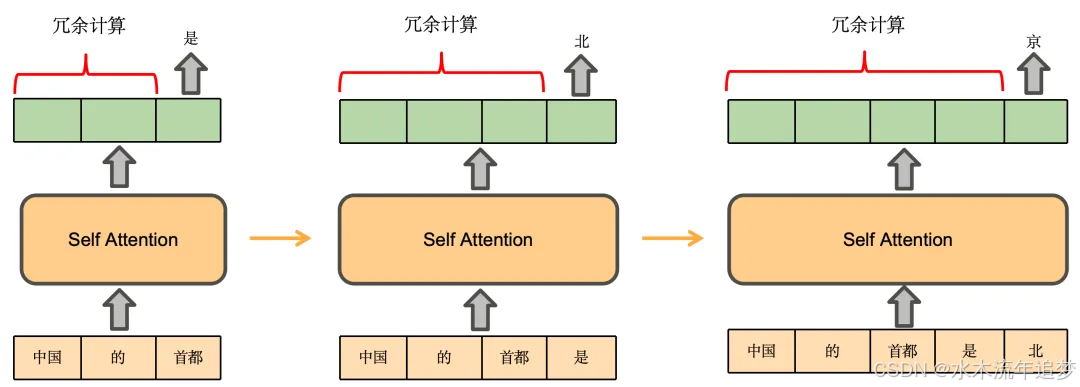
如果没有 KV Cache,大模型的脑回路是这样的:
- 第一步:输入"中国的首都"。模型通过 Attention 机制计算这 5 个字的注意力表示,预测出下一个字是"是"。
- 第二步 :将"是"拼接到原句,输入"中国的首都是"。模型重新计算这 6 个字的注意力表示,预测出下一个字是"北"。
- 第三步 :将"北"拼接到原句,输入"中国的首都是北"。模型再次重新计算这 7 个字的注意力表示,预测出"京"。
发现问题了吗? 在第三步预测"京"的时候,模型把"中国"、"的"、"首都"、"是"这些词的注意力矩阵又从头到尾重新算了一遍!这就好比你每写一个字,都要把整篇文章从头重读一遍,这产生了极大的冗余计算,极大地拖慢了推理速度。
二、 解法:KV Cache 闪亮登场
为了消灭这种冗余计算,科学家们想出了一个绝招:把之前算过的中间结果(Key 和 Value 矩阵)像写草稿一样存起来!
在注意力机制(Attention)中,每个 Token(词)都会生成三个向量:QQQ(Query)、KKK(Key)、VVV(Value)。
当我们预测第 3 个字时,我们实际上只需要:
- 当前字 的 Q3Q_3Q3
- 所有历史字+当前字 的 K1,K2,K3K_1, K_2, K_3K1,K2,K3
- 所有历史字+当前字 的 V1,V2,V3V_1, V_2, V_3V1,V2,V3
既然 K1,K2,V1,V2K_1, K_2, V_1, V_2K1,K2,V1,V2 在前面几步已经算过了,我们为什么不直接把它们缓存在显存里呢?这就是 KV Cache 的核心思想。
引入 KV Cache 后,大模型的推理被分为了极其清晰的两个阶段:
- 预填充阶段(Prefilling):这就好比"读题"。用户输入一大段 Prompt,模型并行处理所有词,一次性计算出它们的 K 和 V,并存入 Cache 中。
- 解码阶段(Decoding):这就好比"作答"。模型开始逐字生成。每次生成新词时,直接从 Cache 调取历史的 K 和 V,只计算当前新词的 Q、K、V。算完后,把新词的 K 和 V 也塞进 Cache 里,继续预测下一个词。
三、 进阶挑战:长文本导致显存"爆炸"怎么办?
"空间换时间"听起来很美好,但代价是极度消耗显存(空间) 。
当用户输入一篇几万字的小说时,KV Cache 的体积会随上下文长度线性暴增,不仅吃光显存,还会增加延迟。更要命的是,一旦输入长度超出了模型预训练的极限,模型就会开始胡言乱语。
为了解决长文本的 KV Cache 难题,学术界提出了几套主流方案:
- Window Attention(窗口注意力) :只缓存最近 LLL 个词的 KV,太老的词直接丢掉。缺点是如果丢掉了开头的关键信息,模型性能会断崖式下跌。
- Sliding Window w/ Re-computation(滑动窗口+重计算) :丢掉老的 KV,但需要用到时再临时重新算。缺点是计算复杂度太高(O(TL2)O(TL^2)O(TL2)),非常慢。
- ✨ StreamingLLM(当下热门解法) :这个方法非常聪明。它发现大模型极其依赖开头的前几个词(称为 Attention Sink 注意力沉淀 )。于是,它在 Cache 中永远保留开头的 4 个 Token,同时用滑动窗口保留最近的 Token。结合相对位置编码(如 RoPE),它能让大模型极其稳定、顺滑地处理无限长的文本!
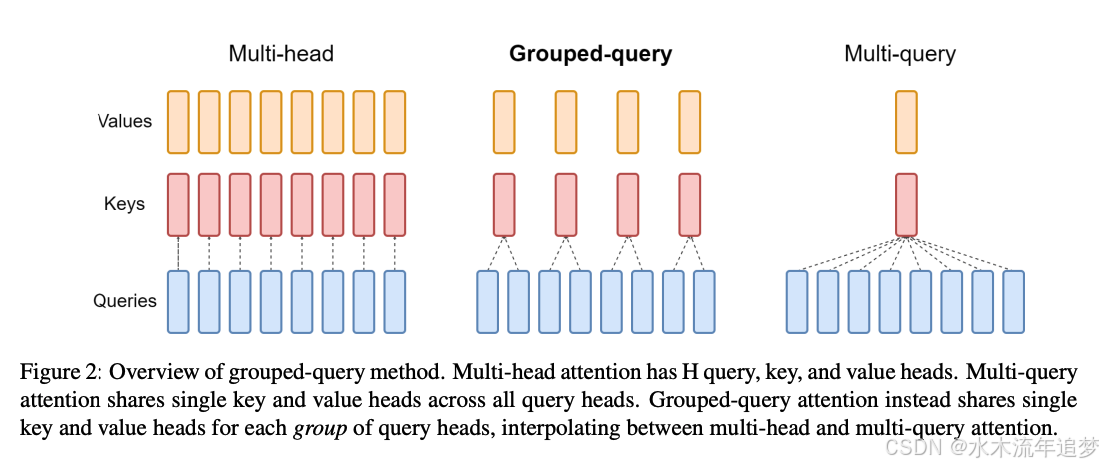
除此之外,架构层面也演进出了 MQA (Multi-Query Attention) 和 GQA (Grouped-Query Attention) ,它们通过让多个 QQQ 共享同一组 KKK 和 VVV,从源头上大幅削减了 KV Cache 的参数量和显存占用。
四、 极简代码实战:如何手写 KV Cache?
对于想要看懂代码的同学,这里有一段剥离了复杂外壳的 PyTorch 伪代码,为你清晰展示 KV Cache 的工作流:
python
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, args):
super().__init__()
# ...省略线性层初始化...
# 1. 【初始化 KV 缓存】
# 在显存中预先开辟一块空地,用来存历史的 Key 和 Value
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x, start_pos, freqs_cis, mask):
bsz, seqlen, _ = x.shape
# 2. 计算当前输入 Token 的 Q, K, V
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
# ...省略维度Reshape和位置编码(RoPE)的代码...
# 3. 【更新缓存】
# 将当前新算出来的 Key 和 Value 塞进缓存里对应的位置 (start_pos)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
# 4. 【提取所有历史和当前的 KV】
# 把从第 0 个位置到当前位置的所有 K 和 V 全部拿出来参与计算!
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# ...维度调整...
# 5. 计算最终的 Attention 分数
# 用当前的 Q,去和所有的 keys 点积,最后乘上 values
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values)
return self.wo(output) # 返回最终结果通过这段代码可以看出,KV Cache 并没有改变原本大模型的计算逻辑,它仅仅是增加了一个 self.cache_k 和 self.cache_v 作为"记事本",避免了每次都要重新计算 keys 和 values。
这就是大模型能做到"对答如流"的底层加速魔法!
