在 IsaacLab 基于 RSL-RL 库的强化学习(RL)Demo 中,我们最常接触到的往往是默认的 MLP(多层感知机)策略范式。然而,在探索机器人复杂步态和真实世界部署时,除了标准的 RslRlPpoActorCriticCfg 之外,RSL-RL 其实还为我们提供了更为强大的循环策略(Recurrent Policy)和蒸馏学习(Distillation)机制。
今天,作为本系列笔记的第一篇,我们就来深入聊聊如何通过 RNN(循环神经网络)让你的机器人拥有"记忆"。我们将从需求背景出发,剖析代码配置,深入底层原理,最后分享实机部署的干货与避坑指南。
一、 需求背景:为什么我们需要"记忆"?
在标准的强化学习设定中,我们通常假设环境是一个马尔可夫决策过程(MDP)。这意味着机器人当前状态(State)包含了做出最优决策所需的所有信息。如果是基于这种完美假设,一个普通的 MLP 网络足以建立从观测(Observation)到动作(Action)的映射。
然而,现实世界是残酷的。真实部署的机器人往往处于部分可观测马尔可夫决策过程(POMDP)中。
举个最直接的例子:你无法仅凭某一瞬间的关节位置和 IMU 姿态,就准确推断出机器人此时的速度、外部的推力大小,或者脚下地面的摩擦力系数。
为了解决"信息缺失"的问题,传统的做法是在观测项中加入历史帧(History Frames),比如把过去 5 帧的观测拼接在一起喂给网络,让它自己去推导变化率。但这种做法会导致输入维度爆炸,且对远期特征的捕捉能力极其有限。
这时候,RNN(循环神经网络)就该登场了。RNN 天生具备"记忆"能力,它能在内部维护一个隐藏状态(Hidden State),通过不断吸收当前观测来更新自己对世界整体状态的"内部认知"。有了这种隐式记忆,机器人面对复杂地形和外部干扰时,表现会更加鲁棒和从容。

二、 默认配置回顾:基础的 PPO 策略
在深入 RNN 之前,我们先来回顾一下 Lab 里 Demo 中最常见的超参数配置。相信各位炼丹师对这套基于标准 RslRlOnPolicyRunnerCfg 和 RslRlPpoAlgorithmCfg 的配置已经毫不陌生:
python
@configclass
class G1RoughPPORunnerCfg(RslRlOnPolicyRunnerCfg):
num_steps_per_env = 24
max_iterations = 3000
save_interval = 50
experiment_name = "g1_rough"
# 默认的 MLP 策略配置
policy = RslRlPpoActorCriticCfg(
init_noise_std=1.0,
actor_obs_normalization=False,
critic_obs_normalization=False,
actor_hidden_dims=[512, 256, 128],
critic_hidden_dims=[512, 256, 128],
activation="elu",
)
algorithm = RslRlPpoAlgorithmCfg(
value_loss_coef=1.0,
use_clipped_value_loss=True,
clip_param=0.2,
entropy_coef=0.008,
num_learning_epochs=5,
num_mini_batches=4,
learning_rate=1.0e-3,
schedule="adaptive",
gamma=0.99,
lam=0.95,
desired_kl=0.01,
max_grad_norm=1.0,
)在上面的代码中,网络仅仅是一个纯前馈的 MLP ([512, 256, 128])。每一帧的观测进去,每一帧的动作出来,它们之间毫无羁绊,犹如一个患有"重度失忆症"的特工。
三、 策略配置探索:一键切换 RNN 范式
在 source/isaaclab_rl/isaaclab_rl/rsl_rl 目录下,我们可以看到框架为我们封装了不同的配置类文件,主要是 rl_cfg.py 和 distillation_cfg.py。
当我们翻阅基础的 rl_cfg.py 时会发现,对于 Runner 和 Algorithm,官方并没有提供太多花里胡哨的可选项,基本就是沿用标准的 RslRlOnPolicyRunnerCfg 和 RslRlPpoAlgorithmCfg。
但是,玄机藏在 Policy 的配置上。
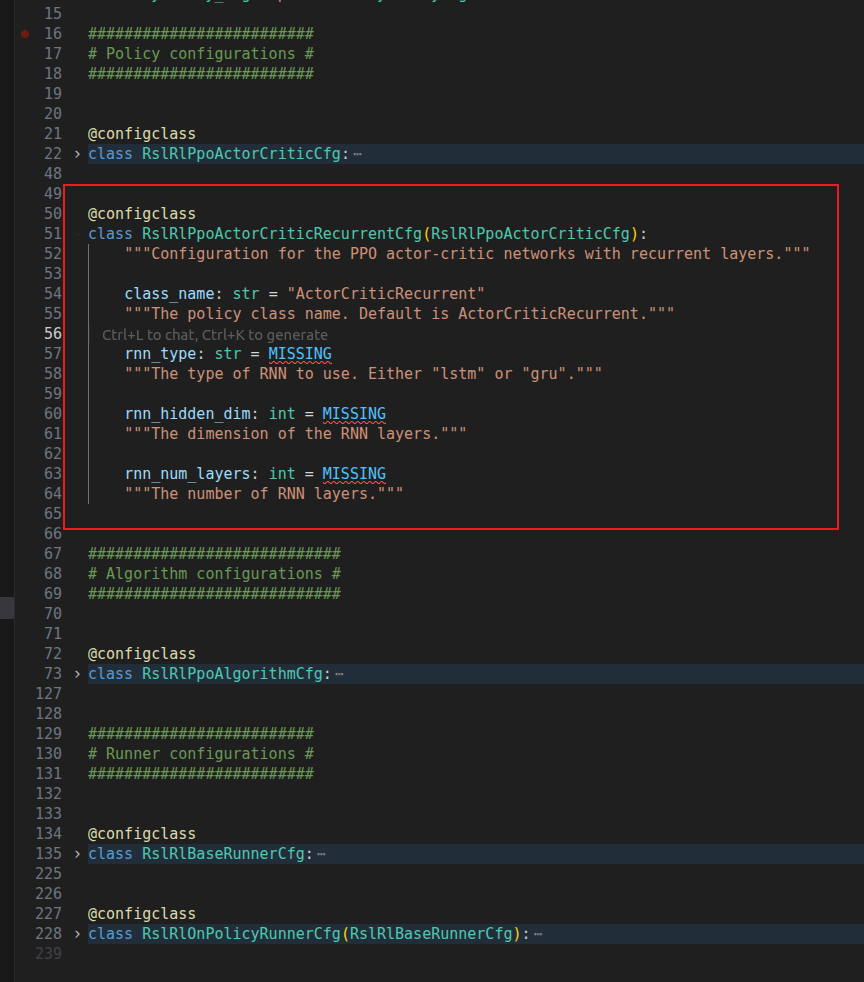
除了刚才提到的标准 RslRlPpoActorCriticCfg 之外,这里还有一个名为 RslRlPpoActorCriticRecurrentCfg 的配置类可以直接调用。顾名思义,这就是为循环神经网络准备的。
要想让你的机器人长出脑子(记忆),只需在配置中指定 rnn_type 及其网络维度即可。你可以将 Demo 里的 Policy 部分直接替换为如下结构,其他参数原封不动,即可开启 RNN 训练范式:
python
policy = RslRlPpoActorCriticRecurrentCfg(
init_noise_std=1.0,
actor_obs_normalization=False,
critic_obs_normalization=False,
actor_hidden_dims=[512, 256, 128],
critic_hidden_dims=[512, 256, 128],
activation="elu",
# =======================
# 以下为 RNN 专属附加配置
# =======================
rnn_type="lstm", # 循环网络类型,通常为 'lstm' 或 'gru'
rnn_hidden_dim=256, # 隐藏层维度
rnn_num_layers=2, # 循环网络的层数
)就这么简单!框架在底层已经为你处理好了所有繁杂的数据流。
四、 深度解析:到底什么是 RNN?
虽然配置很简单,但作为专业工程师,我们必须做到"知其然,更知其所以然"。
RNN(Recurrent Neural Network,循环神经网络) 与传统前馈神经网络(MLP/CNN)最大的区别在于,它的网络节点之间存在环状(Recurrent)连接 。
打个直白的物理比方:MLP 就像是一个流水线上的质检员,看一个零件(观测)敲一个章(动作),零件之间毫不相干;而 RNN 就像是一个在读连载小说的读者,他在读当前这一页(当前帧观测)的时候,脑子里还保留着上一页的剧情记忆(Hidden State, 隐藏状态)。
在数学上,RNN 的当前输出不仅取决于当前的输入 xtx_txt,还取决于上一个时间步传过来的隐藏状态 ht−1h_{t-1}ht−1。正是这种机制,使得 RNN 拥有了处理时间序列数据的天然优势。对于机器人而言,这意味着它可以隐式地从时序序列中"感受"到速度、加速度、外力甚至是不可见的摩擦力。
五、 LSTM 与 GRU 的恩怨情仇
在我们的配置项中,rnn_type 有两个常客:LSTM 和 GRU。这两者都是为了解决基础 RNN 中臭名昭著的"梯度消失"和"梯度爆炸"问题而诞生的变体。它们各自有什么门道呢?
1. LSTM (Long Short-Term Memory,长短期记忆网络)
LSTM 堪称循环神经网络界的老大哥。它设计了一个非常精妙的"细胞状态(Cell State, CtC_tCt)",就像一条贯穿整个时间链条的传送带,信息可以很容易地在上面无损传递。
为了控制信息的增删,LSTM 引入了三个"门(Gates)":
- 遗忘门(Forget Gate): 决定上一时刻的记忆有哪些已经没用了,需要丢弃。
- 输入门(Input Gate): 决定当前时刻的新观测中,有哪些是有价值的,需要被记录到细胞状态中。
- 输出门(Output Gate): 根据更新后的细胞状态,决定当前时刻要对外输出什么隐藏状态(hth_tht)。
在强化学习部署中,LSTM 需要同时维护传递两个状态矩阵:h_in(隐藏状态)和 c_in(细胞状态)。
2. GRU (Gated Recurrent Unit,门控循环单元)
GRU 是 LSTM 的年轻后辈,主打一个"轻量化与高效"。研究人员发现 LSTM 虽然强大,但三个门加上两个状态向量,计算开销有点大。
于是 GRU 进行了大刀阔斧的合并:
- 状态合并: 它将细胞状态(Cell State)和隐藏状态(Hidden State)合并为了单一的隐藏状态 hth_tht。
- 门控合并: 它只有两个门------重置门(Reset Gate) 和 更新门(Update Gate) 。
- 重置门决定如何将新输入与之前的记忆结合(忽略多少过去的记忆)。
- 更新门则直接取代了 LSTM 中遗忘门和输入门的作用,一揽子决定保留多少旧记忆、吸纳多少新信息。
区别与选择:
从参数量上看,GRU 因为少了一个门,参数比 LSTM 少约 25%,训练速度更快,推理时的计算延迟也更低。在很多机器人的强化学习任务中,GRU 和 LSTM 的最终表现往往不相上下。但在某些需要捕捉极长时间跨度依赖的任务中,LSTM 的表现通常更加稳定。在 RSL-RL 中,lstm 通常是作为默认和首选的稳妥方案。
六、 源码实现机制大揭秘
当我们选用 RslRlPpoActorCriticRecurrentCfg 后,RSL-RL 在底层其实是实例化了一个带有 Memory 模块的网络架构(比如 ActorCriticRecurrent 类)。
在它的内部机制中:
- 环境送来的
obs(无论 Actor 还是 Critic)首先会被送入一个专门处理时序的Memory模块(底层的 PyTorchnn.LSTM或nn.GRU)。 Memory模块在处理当前帧时,会自动提取保存在内部的hidden_states进行计算,并将输出的特征向量映射到配置的rnn_hidden_dim维度(例如 256 维)。- 随后,这个 256 维的"浓缩记忆特征"才会被送入后续的 MLP(如
[512, 256, 128])计算,最终输出动作(Action)或价值评估(Value)。
在 PPO 更新时(BPTT):
需要特别注意的是,带有 RNN 的 PPO 训练比普通 PPO 要复杂得多。普通的 PPO 可以把收集到的经验打乱(Shuffle)后直接塞进网络;但 RNN 必须保证时序的连贯性。因此,RSL-RL 底层会将数据按照轨迹(Trajectory)切分成一个个固定长度的序列块,使用沿时间反向传播(BPTT, Backpropagation Through Time) 来计算梯度。这也是为什么使用 RNN 往往会稍微增加训练时的显存和时间开销的原因。
七、 实机部署指南:C++ 工程师必读
当你在仿真中大获成功,高高兴兴把模型导出为 ONNX 格式交给下游的 C++ 部署工程师时,他们可能会满头大汗地跑来找你:"这模型不对啊,怎么要求这么多输入?"
没错,普通的 MLP 模型,输入只有 obs,输出只有 actions。
但如果你的 rnn_type="lstm" 且 rnn_num_layers=2,你的 ONNX 模型图将会发生本质改变。
输入节点要求:
obs:当前帧的观测向量。h_in:输入的隐藏状态,维度通常为[num_layers, batch_size, rnn_hidden_dim],在你的配置下就是[2, 1, 256]。c_in:输入的细胞状态,维度同上[2, 1, 256]。(注:如果是 GRU,则只有h_in没有c_in)。
输出节点要求:
actions:网络给出的动作指令。h_out:更新后的隐藏状态。c_out:更新后的细胞状态。
部署逻辑避坑伪代码:
在 C++ 的推理循环中,必须要妥善管理好这些记忆张量:
cpp
// 1. 初始化阶段:必须分配全 0 的内存给 h 和 c
float h_state[2][1][256] = {0.0f};
float c_state[2][1][256] = {0.0f};
// 2. 控制循环
while(robot_is_running) {
float obs[OBS_DIM] = get_sensors();
// 准备输入字典
inputs = {"obs": obs, "h_in": h_state, "c_in": c_state};
// 运行 ONNX 推理
outputs = onnx_session.run(inputs);
// 提取动作并发送给底层控制器
send_to_motors(outputs["actions"]);
// 3. 关键步骤:用 h_out 和 c_out 覆盖旧的 h_state 和 c_state
// 为下一帧的推理做准备
h_state = outputs["h_out"];
c_state = outputs["c_out"];
}
// 4. 注意事项:如果机器人跌倒重置,必须把 h_state 和 c_state 重新清零!八、 避坑指南:RNN 与"观测历史帧"的取舍
这是许多新手在配置环境时最容易踩进去的深坑:在引入 RNN 的同时,依然在观测组里保留了历史帧(History Frames)。
请各位炼丹师千万注意:既然已经是带记忆的循环网络了,观测项里就不需要再配置历史帧了!
在普通 MLP 训练中,因为网络没有记忆,我们往往需要把 ttt, t−1t-1t−1, t−2t-2t−2... 的观测堆叠起来(比如 5 帧历史)喂给网络,这是在人为制造"伪记忆"。
但当你切换到 RNN 时,网络本身就已经在时间维度上对特征进行了提炼。此时再塞入 5 帧历史观测,不仅构成了严重的信息冗余,还会直接导致 RNN 输入维度暴增,增加模型拟合的难度。
实验数据打脸现场:
经过亲测对比,在完全相同的环境中:
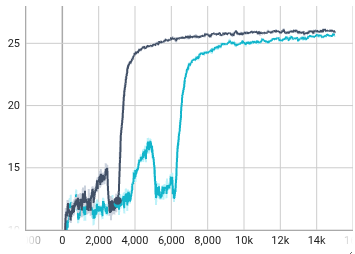
- 黑色曲线: 纯当前帧观测(无历史帧)+ RNN 策略。
- 蓝色曲线: 5 帧观测历史拼接 + RNN 策略。
我们发现,加入历史帧后(蓝色线),训练前期的收敛速度明显变慢 。网络需要在庞杂且冗余的数据中苦苦搜寻真正的有效特征,导致样本效率下降。虽然最终经过漫长的训练,综合奖励和无历史项基本持平,但浪费了大量算力。
更致命的是在实机部署测试 中:由于加入了历史序列,模型对传感器的噪声累积和通信延迟变得更加敏感,部署效果略差于无历史帧的纯净版本。
一句话总结:用 RNN,请务必去掉环境观测中的 history_length 配置!让 RNN 做它该做的事。
九、 总结与预告
经过大量综合测试与实机验证,在相同的训练环境配置和难度下,我们明确发现:RNN 范式(循环策略)的整体表现是显著优于普通 PPO(MLP)配置的。 它展现出了更强大的地形适应性、更丝滑的步态过渡,以及在面对未建模外部干扰时惊人的鲁棒性。
当然,RNN 也带来了模型体积变大、推理有极小延迟增加、部署逻辑变复杂等轻微副作用,但对于四足/双足机器人这种高度非线性的动态系统而言,这点代价绝对是物超所值的。