为了生成高分辨率的高质量图像,Ho等人(2021)提出使用由多个分辨率递增的扩散模型组成的pipeline。pipeline模型之间的噪声调节增强 Noise conditioning augmentation 对最终图像质量至关重要,这需要对每个超分辨率模型 的条件输入
进行数据增强,条件噪声有助于减少pipeline设置中的累积误差。U -Net是扩散建模中用于生成高分辨率图像的常用模型架构。
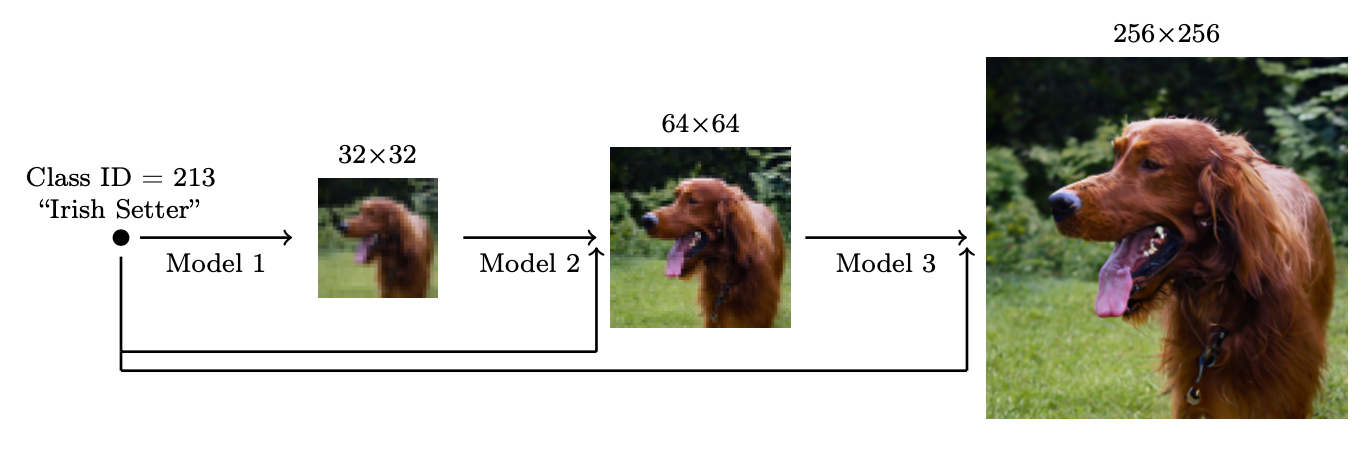
图 1. 由多个分辨率递增的扩散模型组成的级联pipeline
研究发现最有效的噪声方法是在低分辨率下应用高斯噪声,在高分辨率下应用高斯模糊。此外,研究还探索了两种条件增强方法,这两种方法只需对训练过程进行少量修改。需要注意的是,条件噪声仅应用于训练阶段,而不应用于推理阶段。
- 截断条件增强会在步骤早期停止扩散过程,这适用于低分辨率图像。
- 非截断条件增强会运行完整的低分辨率逆过程直到步骤 0,然后通过
其进行破坏,然后将
两阶段扩散模型unCLIP (Ramesh 等人,2022)大量利用 CLIP 文本编码器来生成高质量的文本引导图像。给定一个预训练的 CLIP 模型以及扩散模型 的配对训练数据
, 其中,
是一张图片,如果是对应的标题,我们可以分别计算 CLIP 文本嵌入
和图像嵌入
,unCLIP并行学习两个模型:
- 先验模型
- 解码器
这两个模型能够实现条件生成,因为:
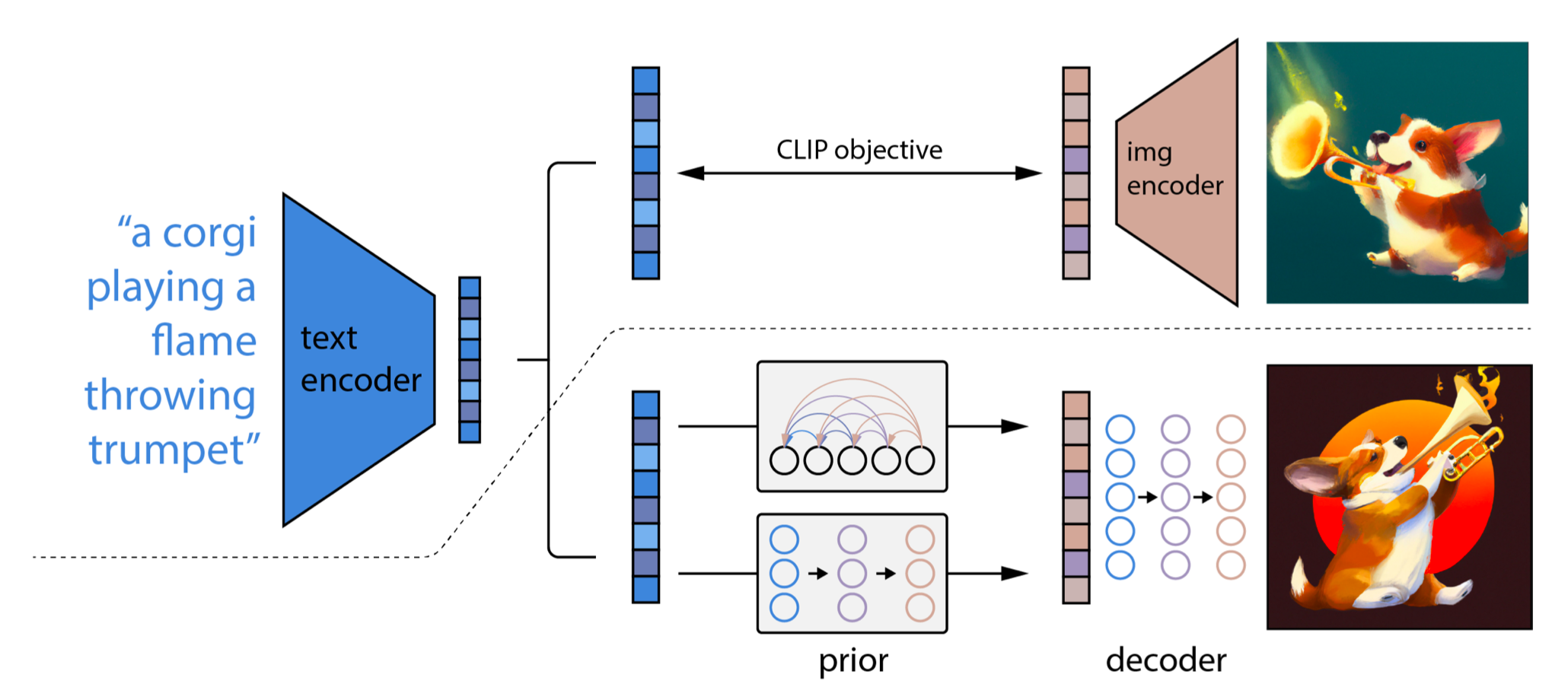
图 2. unCLIP模型的架构图
unCLIP遵循两阶段图像生成过程:
- 给定一段文本
- 扩散或自回归先验处理此 CLIP 文本嵌入以构建图像先验,然后构建扩散解码器。该解码器能够根据先验信息生成图像。它还可以根据给定的图像输入生成图像变体,同时保持图像的风格和语义。
Imagen (Saharia 等人,2022 )并未采用 CLIP 模型,而是使用预训练的大型语言模型(即冻结的 T5-XXL 文本编码器)对文本进行编码以生成图像。通常情况下,更大的模型尺寸可以带来更好的图像质量和文本-图像对齐效果。他们发现,T5-XXL 和 CLIP 文本编码器在 MS-COCO 数据集上的性能相近,但在 DrawBench(包含 11 个类别的提示语集)上,人工评估更倾向于 T5-XXL。
当应用无分类器指导时,增加这可能会导致更好的图像-文本对齐,但图像保真度下降。他们发现这是由于训练集和测试集不匹配造成的,也就是说,因为训练数据保持在范围内测试数据也应如此。本文介绍了两种阈值策略:
- 静态阈值:剪辑预测
- 动态阈值:在每个采样步骤中,如果截取预测结果并除以,计算作为某个百分位绝对像素值;
Imagen 修改了 U-Net 中的几个设计,使其成为高效的 U-Net。
- 将模型参数从高分辨率块转移到低分辨率块,方法是为较低分辨率添加更多残差锁定;
- 按缩放
- 为了提高前向传播的速度,反转下采样(移到卷积之前)和上采样操作(移到卷积之后)的顺序。
研究进一步发现,噪声调节增强、动态阈值和高效的 U-Net 对图像质量至关重要,但文本编码器大小的缩放比 U-Net 大小更重要。