云原生架构下,分布式系统的组件数量呈指数级增长,服务间的调用关系愈发复杂,传统基于预设阈值的监控体系,已无法应对分布式环境下"未知的未知"问题。可观测性作为云原生架构的核心能力,通过系统对外输出的三类核心数据,实现对系统内部状态的深度洞察,支撑故障快速定位、性能优化、容量规划等核心场景。
云原生可观测性的核心本质与整体架构
可观测性是控制论中的核心概念,被引入IT领域后,CNCF给出了明确的定义:可观测性是指通过系统外部输出的数据,理解和推断系统内部状态的能力,无需修改系统代码即可回答关于系统运行的任意问题。
传统监控与可观测性的核心差异清晰明确:
- 传统监控是"预设式"的,仅能回答"已知的已知"问题,比如CPU使用率是否超过阈值、接口错误率是否超标,需要提前定义监控指标和告警规则;
- 可观测性是"探索式"的,能够回答"未知的未知"问题,比如"为什么这个用户的请求在凌晨3点超时"、"订单支付失败的根因是什么",无需提前预设查询条件。
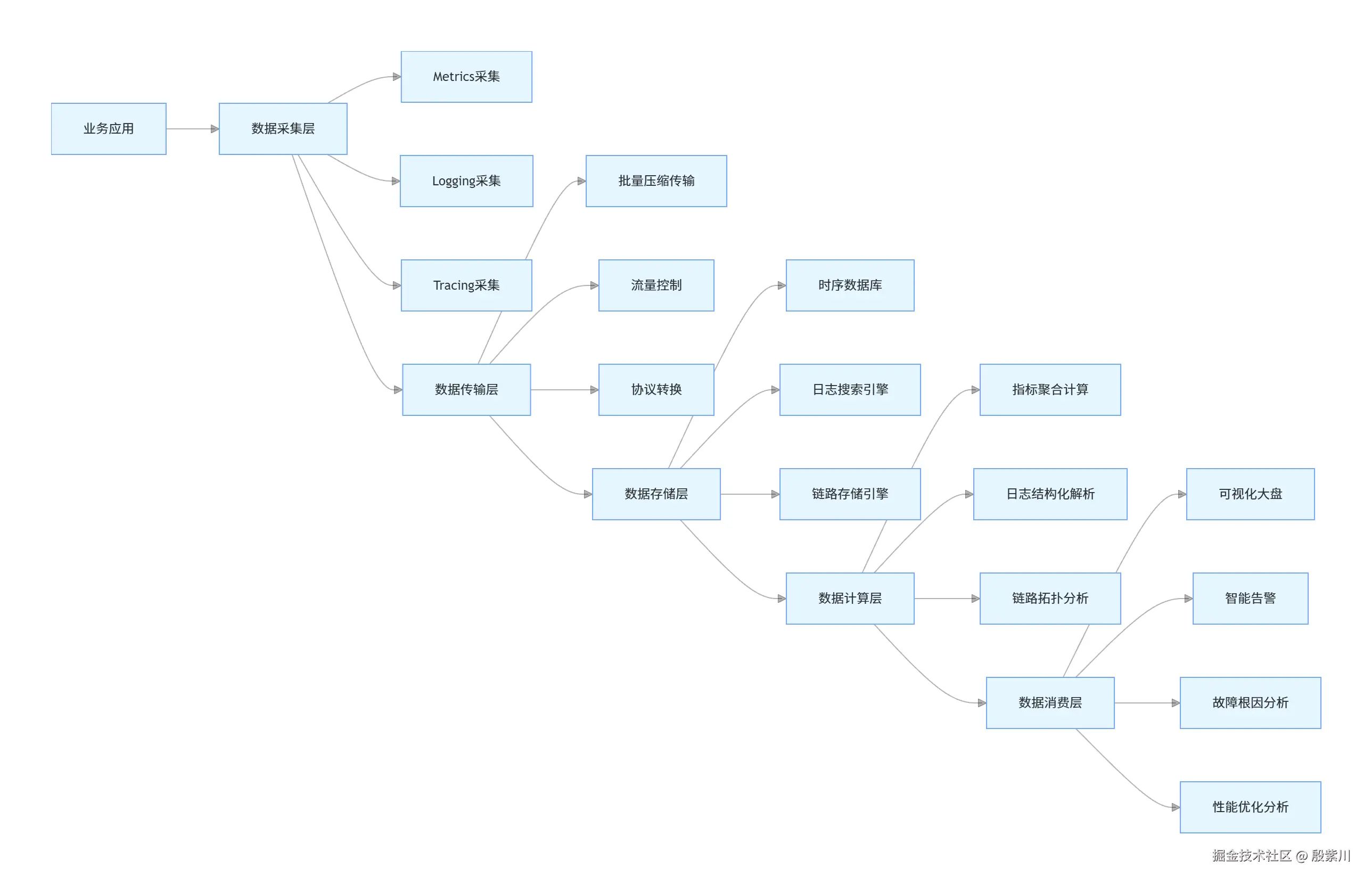
三大支柱并非互相替代的关系,而是互补协同的有机整体,各自承担不可替代的角色:
- Metrics:系统状态的"仪表盘",回答"发生了什么",用于宏观状态监控、告警触发;
- Logging:系统行为的"黑匣子",回答"为什么发生",用于事件详情查询、根因定位;
- Tracing:请求流转的"路线图",回答"在哪里发生",用于分布式调用路径还原、瓶颈定位。
Metrics:可观测性的宏观状态度量
2.1 Metrics的底层逻辑与核心定义
Metrics是对系统状态的聚合型数值度量,以时间序列的形式存储,核心特征是可聚合、低存储成本、支持实时统计与告警,是触发异常感知的第一入口。
时间序列数据的核心模型由四个要素构成,完全符合Prometheus与OpenTelemetry官方规范:
- 指标名称:标识度量的目标,比如
http_server_requests_seconds_count; - 标签集:键值对形式的维度信息,用于数据过滤与聚合,比如
status="200"、uri="/api/order"; - 时间戳:精确到毫秒的时间点,标识度量数据的采集时间;
- 度量值:浮点型数值,标识该时间点的系统状态。
2.2 Metrics的核心类型与适用边界
Metrics分为四大核心类型,不同类型的底层逻辑与适用场景完全不同,此处明确区分易混淆的类型边界。
2.2.1 Counter 计数器
- 底层逻辑:单调递增的数值型指标,仅能在服务重启时重置,无法手动减少;
- 核心适用场景:统计累计发生的事件数量,比如接口请求总量、错误请求总量、SQL执行总量;
- 核心特性:支持增量聚合,可跨实例、跨时间范围计算速率、累计值。
2.2.2 Gauge 仪表盘
- 底层逻辑:可任意增减的数值型指标,反映某个时间点的瞬时状态;
- 核心适用场景:统计当前的系统状态值,比如JVM堆内存使用率、活跃线程数、数据库连接池活跃连接数、Pod副本数;
- 核心特性:不支持速率计算,仅能反映瞬时状态,不可跨实例累加。
2.2.3 Histogram 直方图
- 底层逻辑:对观测值进行分桶统计,记录每个桶内的事件数量,同时记录事件总数与观测值总和;
- 核心适用场景:统计请求耗时、响应体大小等可量化的分布数据,计算P90、P99等分位数;
- 核心特性:分位数在服务端计算,支持跨实例、跨标签聚合,是分布式环境下统计分布数据的首选类型。
2.2.4 Summary 摘要
- 底层逻辑:在客户端直接计算分位数,记录观测值的分位数值、事件总数与观测值总和;
- 核心适用场景:需要精确分位数,且无需跨实例聚合的单实例场景;
- 核心特性:分位数在客户端计算,精度更高,但无法跨实例聚合,资源消耗高于Histogram。
核心易混淆点明确区分:
- Counter与Gauge的核心区别:Counter是累计值,关注事件的发生次数;Gauge是瞬时值,关注系统的当前状态,二者不可混用,用Gauge统计请求量会导致数据丢失,用Counter统计内存使用率无法反映真实状态。
- Histogram与Summary的核心区别:Histogram支持跨实例聚合,适合分布式环境;Summary分位数精度更高,但无法跨实例聚合,仅适合单实例场景。
2.3 Metrics的云原生架构设计
云原生环境下,Metrics的主流架构分为Pull与Push两种模式,核心差异与适用场景如下。
2.3.1 Pull模式
- 核心逻辑:Prometheus Server通过HTTP接口主动拉取业务应用暴露的Metrics数据;
- 云原生适配:原生支持Kubernetes服务发现,自动发现Pod、Service等资源的Metrics端点,无需手动配置;
- 核心优势:可校验数据来源、支持按需拉取、便于问题排查,无数据推送积压风险;
- 适用场景:Kubernetes集群内的服务、常驻运行的应用。
2.3.2 Push模式
- 核心逻辑:业务应用通过SDK将Metrics数据主动推送到中间网关,再由Prometheus Server从网关拉取数据;
- 核心优势:支持短生命周期的Job、离线任务、集群外的应用;
- 适用场景:定时任务、Serverless函数、边缘节点应用。
2.4 Metrics实战落地
2.4.1 项目依赖配置
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>observability-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>observability-demo</name>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>2.4.2 应用配置文件
yaml
spring:
application:
name: order-service
server:
port: 8080
management:
endpoints:
web:
exposure:
include: prometheus,health
metrics:
tags:
application: ${spring.application.name}
distribution:
percentiles-histogram:
http.server.requests: true2.4.3 自定义Metrics代码实现
kotlin
package com.example.observabilitydemo.controller;
import io.micrometer.core.annotation.Timed;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.DistributionSummary;
import io.micrometer.core.instrument.Gauge;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.atomic.AtomicInteger;
@RestController
@RequestMapping("/api/order")
public class OrderController {
private final Counter orderCreateCounter;
private final Counter orderFailCounter;
private final AtomicInteger activeOrderCount;
private final DistributionSummary orderAmountSummary;
public OrderController(MeterRegistry meterRegistry) {
this.orderCreateCounter = Counter.builder("order.create.total")
.description("订单创建总次数")
.register(meterRegistry);
this.orderFailCounter = Counter.builder("order.create.fail.total")
.description("订单创建失败总次数")
.register(meterRegistry);
this.activeOrderCount = new AtomicInteger(0);
Gauge.builder("order.active.count", activeOrderCount, AtomicInteger::get)
.description("当前活跃订单数")
.register(meterRegistry);
this.orderAmountSummary = DistributionSummary.builder("order.amount.summary")
.description("订单金额分布统计")
.publishPercentiles(0.5, 0.9, 0.99)
.register(meterRegistry);
}
@GetMapping("/create/{amount}")
@Timed(value = "order.create.time", description = "订单创建接口耗时")
public String createOrder(@PathVariable Long amount) {
orderCreateCounter.increment();
activeOrderCount.incrementAndGet();
orderAmountSummary.record(amount);
try {
if (amount <= 0) {
throw new IllegalArgumentException("订单金额不能小于等于0");
}
return "订单创建成功";
} catch (Exception e) {
orderFailCounter.increment();
return "订单创建失败";
} finally {
activeOrderCount.decrementAndGet();
}
}
}2.4.4 Prometheus采集配置
makefile
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "spring-boot-application"
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ["host.docker.internal:8080"]Logging:可观测性的事件详情还原
3.1 Logging的底层逻辑与核心定义
Logging是系统运行过程中产生的离散事件记录,每条日志对应一个完整的系统行为事件,附带时间戳、事件上下文、异常堆栈等信息,核心特征是完整、不可变、带上下文,是故障根因定位的核心依据。
12因素应用规范中明确要求,云原生应用应将日志以事件流的形式输出到标准输出与标准错误,不负责日志的存储与持久化,由基础设施统一处理日志的采集、传输、存储与检索,这是云原生日志架构的核心原则。
3.2 云原生日志的核心架构设计
云原生日志架构分为四个核心层级,实现日志的全链路处理。
3.2.1 日志生成层
业务应用负责生成结构化日志,核心要求是结构化、统一格式、带全链路上下文,避免非结构化的自由文本日志,非结构化日志无法实现高效的检索与聚合分析。
结构化日志的核心字段规范:
- 基础字段:timestamp、level、service、host、pid、thread;
- 链路字段:trace_id、span_id;
- 业务字段:user_id、order_id、biz_code;
- 事件字段:message、exception_stack。
3.2.2 日志采集层
负责从容器、节点、应用中采集日志流,主流采集工具为Fluent Bit与Fluentd,其中Fluent Bit资源占用更低,性能更高,是Kubernetes环境下的首选采集工具。
采集层的核心能力:
- 多源日志采集:支持容器日志、节点日志、文件日志、系统日志等多种数据源;
- 日志解析:支持JSON、正则、Grok等多种解析方式,将非结构化日志转换为结构化数据;
- 过滤与转换:支持日志字段的过滤、修改、enrichment,补充集群、节点、Pod等元数据。
3.2.3 日志传输层
负责将采集到的日志数据可靠传输到存储层,核心要求是高吞吐、低延迟、高可靠,主流方案分为两类:
- 直接传输:采集工具直接将日志写入存储引擎,适合中小规模场景;
- 缓冲传输:通过Kafka、Pulsar等消息队列作为缓冲层,适合大规模高并发场景,避免日志洪峰导致存储引擎崩溃。
3.2.4 日志存储与检索层
负责日志的持久化存储与快速检索,主流引擎为OpenSearch与Elasticsearch,基于倒排索引实现日志的全文检索与聚合分析,支持PB级别的日志数据存储。
3.3 Logging与Metrics的核心边界区分
二者的适用场景有明确的边界,不可混用:
- Metrics是聚合数据,适合宏观监控与告警,无法回答事件的具体上下文;
- Logging是离散事件数据,适合根因定位与详情查询,不适合做高频的实时统计与告警,存储与计算成本远高于Metrics。
核心原则:能用Metrics实现的统计与告警,绝对不要用Logging实现,避免不必要的资源浪费。
3.4 Logging实战落地
3.4.1 日志依赖配置
在原有pom.xml中新增依赖:
xml
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>8.0</version>
</dependency>3.4.2 Logback结构化日志配置
在resources目录下创建logback-spring.xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<springProperty scope="context" name="applicationName" source="spring.application.name"/>
<appender name="JSON_CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeMdcKeyName>trace_id</includeMdcKeyName>
<includeMdcKeyName>span_id</includeMdcKeyName>
<includeMdcKeyName>user_id</includeMdcKeyName>
<includeMdcKeyName>order_id</includeMdcKeyName>
<customFields>{"service":"${applicationName}"}</customFields>
<timestampPattern>yyyy-MM-dd'T'HH:mm:ss.SSSXXX</timestampPattern>
<writeDurationAsNumber>true</writeDurationAsNumber>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="JSON_CONSOLE"/>
</root>
</configuration>3.4.3 业务日志打印代码实现
java
package com.example.observabilitydemo.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
private static final Logger log = LoggerFactory.getLogger(OrderService.class);
public void createOrder(Long orderId, Long userId, Long amount) {
MDC.put("order_id", orderId.toString());
MDC.put("user_id", userId.toString());
try {
log.info("开始创建订单");
if (amount <= 0) {
log.error("订单创建失败,金额非法: {}", amount);
throw new IllegalArgumentException("订单金额非法");
}
log.info("订单创建成功");
} finally {
MDC.remove("order_id");
MDC.remove("user_id");
}
}
}3.4.4 Fluent Bit采集配置
vbnet
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File parsers.conf
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
Parser docker
Refresh_Interval 10
Mem_Buf_Limit 5MB
Skip_Long_Lines On
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Merge_Log On
K8S-Logging.Parser On
K8S-Logging.Exclude Off
[OUTPUT]
Name opensearch
Match *
Host opensearch-cluster.default.svc
Port 9200
Index k8s-logs-%Y.%m.%d
Suppress_Type_Name On
Logstash_Format Off
Auto_Index OnTracing:可观测性的分布式路径还原
4.1 Tracing的底层逻辑与核心定义
分布式链路追踪的理论基础来自Google 2010年发布的Dapper论文,核心目标是还原单次用户请求在分布式系统中的完整流转路径,记录请求经过的每一个服务、组件、中间件的处理细节,解决分布式系统中"请求在哪里变慢了"、"故障发生在哪个环节"的核心问题。
OpenTelemetry规范中,链路追踪的核心数据模型如下:
- Trace:一条完整的请求链路,由全局唯一的TraceId标识,包含多个Span;
- Span:链路中的最小操作单元,代表一次完整的操作,比如一次HTTP请求、一次SQL执行、一次RPC调用,由全局唯一的SpanId标识,包含ParentSpanId标识父Span,构建父子关系;
- SpanContext:Span的上下文信息,包含TraceId、SpanId、TraceFlags、TraceState,用于跨服务、跨进程传递链路信息;
- Span Event:Span内的事件记录,用于标记操作过程中的关键节点,比如异常抛出、缓存命中;
- Span Attribute:Span的属性信息,键值对形式,用于补充操作的上下文,比如HTTP状态码、SQL语句、数据库地址。
4.2 分布式链路追踪的云原生架构设计
云原生环境下,链路追踪的架构分为五个核心层级。
4.2.1 链路埋点层
负责在业务代码中注入链路追踪的逻辑,分为两种埋点方式:
- 无侵入式埋点:通过Java Agent、字节码增强等技术,自动为框架、中间件注入埋点逻辑,无需修改业务代码,是云原生环境下的首选方式;
- 手动埋点:通过SDK手动创建Span、添加事件与属性,用于自定义业务操作的链路追踪。
4.2.2 采样层
负责控制链路数据的采集量,高并发分布式系统中,全量采集链路数据会带来极高的存储与计算成本,采样是平衡观测能力与资源成本的核心手段,主流采样策略分为两类:
- 前置采样:在链路生成前决定是否采样,比如概率采样,按固定比例采集链路,资源消耗最低,是最常用的采样策略;
- 尾部采样:在链路完整生成后,根据链路的特征决定是否采样,比如仅采集错误链路、耗时超过阈值的链路,观测精度更高,但资源消耗更高。
4.2.3 传输层
负责将采集到的链路数据传输到后端存储,OpenTelemetry规范中,统一使用OTLP协议传输链路数据,支持gRPC与HTTP两种传输方式,实现跨厂商的兼容。
4.2.4 存储层
负责链路数据的持久化存储与检索,主流存储方案分为两类:
- 开源方案:Jaeger、Zipkin、Elasticsearch;
- 商业方案:Datadog、New Relic、阿里云ARMS。
4.2.5 分析与可视化层
负责链路数据的拓扑分析、检索与可视化,核心能力包括:
- 链路详情查询:通过TraceId查询完整的链路详情,查看每个Span的耗时、属性、事件;
- 服务拓扑分析:自动生成服务间的调用拓扑图,直观展示服务依赖关系;
- 性能瓶颈分析:统计每个服务、接口的平均耗时、错误率、P99耗时,定位性能瓶颈。
4.3 Tracing与Metrics、Logging的核心边界区分
三者的核心价值形成完整的互补闭环:
- Metrics告诉你系统有异常,Tracing告诉你异常发生在哪个环节,Logging告诉你异常的具体原因;
- Tracing的核心价值是还原分布式系统的调用路径,解决跨服务的故障定位与性能瓶颈问题,无法替代Metrics的宏观监控能力,也无法替代Logging的事件详情还原能力。
4.4 Tracing实战落地
4.4.1 无侵入式Agent接入
OpenTelemetry Java Agent实现零代码修改的全链路埋点,支持Spring Boot、Dubbo、MySQL、Redis等主流框架与中间件的自动埋点,启动命令如下:
ini
java -javaagent:opentelemetry-javaagent-1.39.0.jar \
-Dotel.service.name=order-service \
-Dotel.traces.exporter=jaeger \
-Dotel.exporter.jaeger.endpoint=http://jaeger:14250 \
-Dotel.logs.exporter=none \
-Dotel.metrics.exporter=none \
-jar observability-demo-0.0.1-SNAPSHOT.jar4.4.2 自定义链路埋点代码实现
java
package com.example.observabilitydemo.service;
import io.opentelemetry.api.OpenTelemetry;
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.Tracer;
import io.opentelemetry.context.Scope;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.stereotype.Service;
@Service
public class PaymentService {
private static final Logger log = LoggerFactory.getLogger(PaymentService.class);
private final Tracer tracer;
public PaymentService(OpenTelemetry openTelemetry) {
this.tracer = openTelemetry.getTracer("com.example.observabilitydemo.service.PaymentService");
}
public void processPayment(Long orderId, Long userId, Long amount) {
Span paymentSpan = tracer.spanBuilder("processPayment")
.setAttribute("order_id", orderId)
.setAttribute("user_id", userId)
.setAttribute("amount", amount)
.startSpan();
try (Scope scope = paymentSpan.makeCurrent()) {
MDC.put("trace_id", Span.current().getSpanContext().getTraceId());
MDC.put("span_id", Span.current().getSpanContext().getSpanId());
log.info("开始处理支付");
paymentSpan.addEvent("支付校验开始");
if (amount > 10000) {
throw new RuntimeException("支付金额超过限额");
}
paymentSpan.addEvent("支付校验完成");
log.info("支付处理完成");
} catch (Exception e) {
paymentSpan.recordException(e);
log.error("支付处理失败", e);
throw e;
} finally {
paymentSpan.end();
MDC.remove("trace_id");
MDC.remove("span_id");
}
}
}4.4.3 Jaeger服务部署配置
less
version: '3.8'
services:
jaeger:
image: jaegertracing/all-in-one:1.58.0
container_name: jaeger
ports:
- "16686:16686"
- "14250:14250"
environment:
- COLLECTOR_OTLP_ENABLED=true
- LOG_LEVEL=info三大支柱的融合架构与协同闭环
5.1 三大支柱的核心串联纽带:TraceId
TraceId是串联Metrics、Logging、Tracing的核心纽带,实现三大支柱的数据完全打通:
- 链路追踪中,一条完整的Trace对应唯一的TraceId,贯穿整个请求的全生命周期;
- 日志打印时,将TraceId写入MDC,每条日志都携带当前请求的TraceId;
- 指标统计时,将TraceId作为标签加入异常指标,实现异常指标到链路的直接跳转。
5.2 可观测性的故障排查闭环
完整的故障排查流程,是三大支柱协同的核心价值,流程如下:
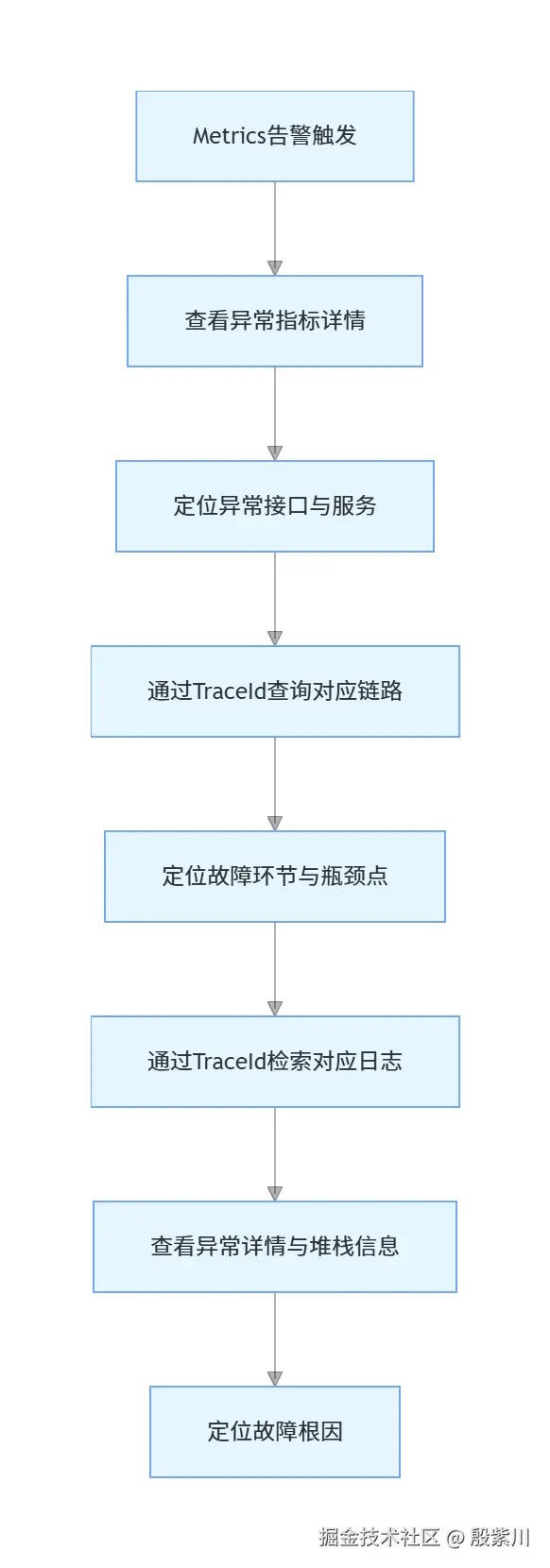
5.3 云原生可观测的统一标准:OpenTelemetry
OpenTelemetry是CNCF孵化的毕业项目,是当前云原生可观测领域的事实标准,统一了Metrics、Logging、Tracing三大支柱的采集规范、数据模型与传输协议,核心价值在于:
- 厂商无关:统一的API与SDK,避免厂商锁定,可自由切换后端的可观测平台;
- 全信号统一:一套SDK实现Metrics、Logging、Tracing的统一采集,避免多套SDK的冲突与资源消耗;
- 自动埋点:提供丰富的自动埋点能力,支持主流的框架、中间件、数据库,无需修改业务代码;
- 多语言支持:支持Java、Go、Python、JavaScript等所有主流开发语言。
总结
可观测性是云原生分布式系统的核心能力,Metrics、Logging、Tracing三大支柱不是互相替代的关系,而是互补协同的有机整体。 Metrics作为宏观监控的入口,实现异常的快速感知;Tracing作为分布式路径的还原工具,实现故障环节的快速定位;Logging作为事件详情的记录载体,实现根因的精准定位。