前言
目前VLA + RL、世界动作模型 这两条主流技术路线所对应的巨大潜力,已经被越来越多的人认可
故我近期一直在关注这两条技术路线的发展,故而也关注到了本文要介绍的GigaWorld-Policy,有意思的是,今早朋友圈还看到星海图一领导转发了他们的一个世界动作模型工作《Fast-WAM: Do World Action Models Need Test-time Future Imagination?》,其最早于26年3.17提交到arxiv上
咋一看,和本文要介绍的GigaWorld-Policy(其最早于26年3.18提交到arxiv上)还挺相似的,比如
-
相同点在于
核心维度 GigaWorld-Policy 与 Fast-WAM 的共同点 核心痛点 均指出传统世界-动作模型(WAMs)在推理时迭代生成未来视频会引发极高的延迟,难以满足实时控制 核心解法 均采用了"训练用视频,推理去视频"的解耦思想:在++训练时利用未来视频动态提供监督,在推理时跳过或舍弃未来视频生成以提升速度++ 基础骨干 均选择建立在 Wan 2.2 5B 扩散 Transformer (DiT) 视频生成模型之上 训练目标 均采用流匹配(Flow Matching)来联合优化动作预测和未来视觉/视频预测 防作弊掩码 均设计了精密的注意力掩码(Attention Mask),允许未来视频预测参考当前动作,但严格禁止动作 token 关注未来视频 token,以防信息泄露 说白了,这种设计防止了预测的未来帧信息"泄露"到动作生成中,从而使得在推理时可以直接剥离视频分支,只解码动作 *且值得注意的是,*训练时也设置掩码,是为了逼"动作"凭真本事去考高分。虽然"动作"看不见未来,但只要它出了错,"预测未来"的任务就会跟着砸锅;为了不让总体任务砸锅,系统就会强行把"动作"掰正 -
当然,不同点则在于
核心维度 GigaWorld-Policy (打造最强系统) Fast-WAM (探究科学机制) 网络架构设计 单一共享架构 (Shared Transformer):将观察、状态、动作和未来视频打包在同一个序列中,共享所有的 Transformer 块 混合架构 (Mixture-of-Transformer, MoT):明确划分为两个分支,包含一个 Video DiT 和一个专属的 Action Expert DiT 推理阶段的定义 可选的生成 (Optional):默认关闭未来视频生成以降低延迟,但如果任务有需要,依然可以在推理时激活视频生成分支 纯粹的单次传递 (Single Forward Pass):彻底移除未来视频预测,仅进行单次前向传递提取当前潜层特征用于动作生成,不实例化任何未来视频 研究侧重点与 预训练依赖 侧重系统刷榜,高度依赖具身预训练:通过引入海量真实机器人和人类第一视角视频进行"课程预训练 (Curriculum Pre-training)",来暴力拉升模型的物理先验和任务成功率 侧重机制消融,刻意摒弃具身预训练 :通过严格的控制变量实验证明 WAM 的收益源于"训练目标"而非"推理生成",并强调其在无具身预训练 (Without embodied pretraining) 的情况下依然极具竞争力
更有意思的是,那之前博客内介绍过的DreamZero和本文要介绍的GigaWorld-Policy,又有何本质区别呢,为方便大家直透本质 一目了然,我用一个表格 总结下 这两模型的区别
核心对比维度 DreamZero (世界动作模型) GigaWorld-Policy (以动作为中心的世界模型) 底层逻辑 (动力学范式) 逆动力学 (Inverse Dynamics) "为了达到预期的未来画面,我的关节应该怎么动?" 正向动力学 (Forward Dynamics) "如果我执行了这个动作,未来的物理世界会变成什么样?" 信息流向 (Attention Mask) 以图导动 动作 Token 被允许且必须"偷看"未来的视频 Token 以动推图 动作 Token 绝对不看未来;是未来视频 Token 去看动作 Token 视频生成的地位 (推理阶段) 不可或缺的"领航员" 实战推理时必须生成视频,没有视频画面的牵引,动作就无法准确生成 可随时丢弃的"辅助教练" 实战推理时可以完全关闭视频生成。视频预测仅作为训练时增强物理直觉的"附加题" 工程取舍与速度 (Inference) 算力负担重,靠极致优化续命 必须同时扛起生成视频和动作的计算量,依赖解耦噪声 (Flash)、KV Cache 等极致底层优化才压榨出 7Hz 的实时控制速度 主打轻量、无脑快 因为推理时砍掉了视频生成的巨大开销,纯解码动作,计算极度轻量,控制延迟极低(具有成倍的速度优势) 本质哲学 (一句话总结) 闭眼盲操是不靠谱的,必须先在脑海中清晰预演出未来的画面,肢体再严格跟着画面走 每次动手前都要脑补未来太慢了,要在训练时把物理规律化为直觉本能,实战时直接靠本能闪电反应
第一部分 GigaWorld-Policy: An Efficient Action-CenteredWorld--Action Model
1.1 引言与相关工作
1.1.1 引言
如原论文所说,近期,一些工作(Cen 等,2025;Chang 等,2025;Ni等,2025;Zhang 等,2025)尝试注入未来状态监督到现有的 VLA 框架中,通过预测未来的视觉观测,如图 2(a) 所示
-
然而,基于 VLM的 VLA 模型
Chen 等,2025;Cui 等,2025;Ding 等,2024, 2025;Li 等,2025;Team 等,2026;Tian 等,2025;Wang 等,2025;Wu 等,2025
通常是针对判别式推理而非高保真生成进行优化的,这使得利用这些额外损失来在预测动作中强制实现连续性和物理一致性变得并非易事 -
相比之下,近期工作将视频生成领域的世界模型(World Model, WM)
Liu et al., 2026;Podell et al., 2023; Wang et al., 2025; Ye et al., 2026引入到机器人策略学习中
Bi etal., 2025; Kim et al., 2026; Shen et al., 2025以进一步提升监督密度并改善可扩展性
而之所以利用视频生成具有吸引力,因为它在观测空间中提供了时间上高密度的监督信号,超越了稀疏的动作标签,同时还注入了从大规模视频数据中学习到的强时空先验
这类方法通常联合优化未来视觉动态和动作预测的目标,将未来观测预测与动作选择显式耦合,从而利用视频模型在表征和生成方面的能力来引导动作学习,如下图2(b--c)所示
然而,这些方法往往在推理阶段需要通过迭代采样来展开未来视频,导致高延迟
此外,视频预测中的误差还会传播到动作解码阶段,从而引发错误并削弱长时域控制性能,尤其是在早期的细微误差随时间累积放大的情况下
为了解决这些局限,来自的研究者提出了 GigaWorld-Policy,这是一种以动作为中心且高效的 World--Action 模型

具体而言,GigaWorld-Policy 并非让动作预测过度依赖显式的视频生成,而是将++未来视觉动态++作为推理信号和高密度监督源加以利用
-
且GigaWorld-Policy 被实现为一个因果序列模型,在因果掩码下对动作 token 和未来视觉 token 进行表征
在训练过程中,模型学习从当前的观察情境预测未来的动作序列,同时学习一个动作条件下的视觉动态模型,该模型在给定相同的当前观察以及预测的动作的情况下,预测未来的视觉观察,从而将动作学习与明确的二维像素级状态演变相结合
这两类学习信号在同一个模型中共同优化,使得未来视觉动力学能够对动作的合理性起到正则化作用,并提供显著更稠密的监督信号,从而提升学习效率
-
关键在于,在推理阶段,显式的未来视频预测是可选的:++模型可以在"仅动作"模式下运行++,直接输出控制指令,而无需展开长序列的视频 token
这样的设计大幅降低了计算和内存开销,避免了长时间视觉展开带来的误差累积,并实现了低延迟的闭环控制,如图 2(d) 所示

且为了获得更强的预训练权重,作者采用课程式训练流程
- 在任何任务特定监督之前,先从多样化视频源中注入物理先验
GigaWorld-Policy 以大规模网络视频基础模型(Wan et al., 2025)作为初始化 - 然后在具身化、机器人中心的数据上继续预训练,这些数据将真实机器人录制与大规模自我视角的人类视频相结合,从而提升其对具身特定视角与交互动力学的鲁棒性
- 最后,作者在目标机器人的轨迹数据上对模型进行后训练,使其对图像、语言与动作进行对齐,从而在目标机器人的控制接口与状态分布下,专门优化用于指令条件的动作预测
1.1.2 相关工作
首先,对于面向机器人视频生成的世界模型
-
最新的 world model 研究进展
Li 等,2025;Ni 等,2025;Wang 等,2025;Zhao 等,2025提升了机器人视频生成与预测的能力
Chen 等,2025;Dong 等,2025;Liu 等,2025;Ni 等,2025;Wang 等,2025;Zhou 等,2024
其核心目标是学习一种生成模型,用以刻画环境的时间演化过程,从而实现对未来视觉序列的预测 -
Pandora(Xiang 等,2024)提出了一种混合自回归--扩散的世界模型,该模型在生成视频的同时,还支持通过自由文本动作进行实时控制
FreeAction(Kim 等,2025)在基于扩散的机器人视频生成中显式利用连续动作参数,通过使用按动作缩放的无分类器引导来更好地控制运动强度
-
GigaWorld-0-video(Team 等,2025)是一个高保真世界模型数据引擎,能够合成时间上一致的高质量 2D 视频序列,并对外观和场景布局进行细粒度控制
部分方法(Chen 等,2025)还探索显式视频世界模型,其目标是构建结构化且可操控的三维场景表示
Liu 等,2024, 2025
Ni 等,2025
Wang 等,2025Aether(Team 等,2025)通过联合优化四维动态重建、动作条件视频预测和目标条件视觉规划,实现了几何感知的统一世界建模
然而,大多数现有工作主要致力于提升视频世界模型的逼真度、一致性和可控性,却在很大程度上忽视了如何将通用视频生成器适配为以动作为中心的模型,从而在严格的时延约束下直接支持策略学习
相较之下,作者将视频生成器视为策略初始化,并提出了一种以动作为中心的训练方案,使主干网络与机器人的观测以及基于动作条件的动力学实现对齐
其次,对于用于机器人控制的世界--动作模型
-
世界--动作模型(World--Action Models,WAM)(Bi 等,2025;Kim 等,2026;Shen 等,2025;Wang 等,2025)基于视频生成范式,旨在在统一框架下预测机器人的动作以及未来的视觉动态
通过对条件于动作的未来观测进行建模,WAM 为策略学习提供了密集的时间监督信号以及一个通过学习得到的预测先验,从而对策略学习起到正则化作用 -
如图 2(b) 所示

VideoVLA(Shen 等,2025)直接将视频生成模型作为预训练权重,探索如何将大规模视频生成模型转化为机器人操作模型,采用多模态扩散 Transformer 联合建模视频、语言与动作模态,从而同时预测机器人动作与未来视觉结果Motus(Bi 等,2025)提出了一个统一的世界模型,该模型利用现有的通用预训练模型和丰富且可共享的运动信息,引入 Mixture-of-Transformer(MoT)架构来融合三个专家模块,并采用类似 UniDiffuser 的调度器,以支持在不同建模模式之间灵活切换
-
相比之下,如图 2(c) 所示,Mimic-video(Pai 等,2025)采用两阶段流程:

首先利用互联网规模的预训练视频骨干网络预测未来视觉观测
然而,这些方法在推理阶段生成未来视频时通常都需要迭代式的扩散采样,这会引入显著的延迟,从而限制其实时部署能力
同时,对显式视频预测的过度依赖也可能较为脆弱:像素级预测对随机性和可观测性非常敏感,且在长时间范围内,小的视觉预测误差会不断累积,从而削弱所学习动力学在生成鲁棒动作时的实用价值
1.2 GigaWorld-Policy的完整方法论
1.2.0 问题表述与方法概述
如原论文所述,作者将机器人操作建模为一个序列决策任务
- 在每个时间步
- 在这些输入的条件下,策略预测长度为
首先,对于视觉-语言-动作策略
- 大多数现有的 VLA 策略都是通过模仿学习进行训练,用于在给定观测、机器人状态以及语言指令的条件下建模并采样一个动作片段:
- 分布
在这一范式中,学习完全由来自示范的动作监督驱动,在观测空间中没有任何显式监督
而对于作者的方法,其不同于只对动作分布建模的方法
作者采用一种世界建模视角,学习在执行一个动作片段后视觉观测如何演化
作者将他们的方法实现为一个统一的模型,用于参数化两个互补的条件分布
-
对于基于示教的动作建模
模型学习在给定观测、机器人状态和语言的条件下对一个动作片段进行采样:
在这里,
-
对于视觉前馈动态建模
在给定相同的上下文和预测的动作条件信号的情况下,模型学习对未来观测序列进行采样 ,从而捕捉视觉观测的演化过程:
其中
1.2.1 GigaWorld-Policy 的架构
如图 3 所示
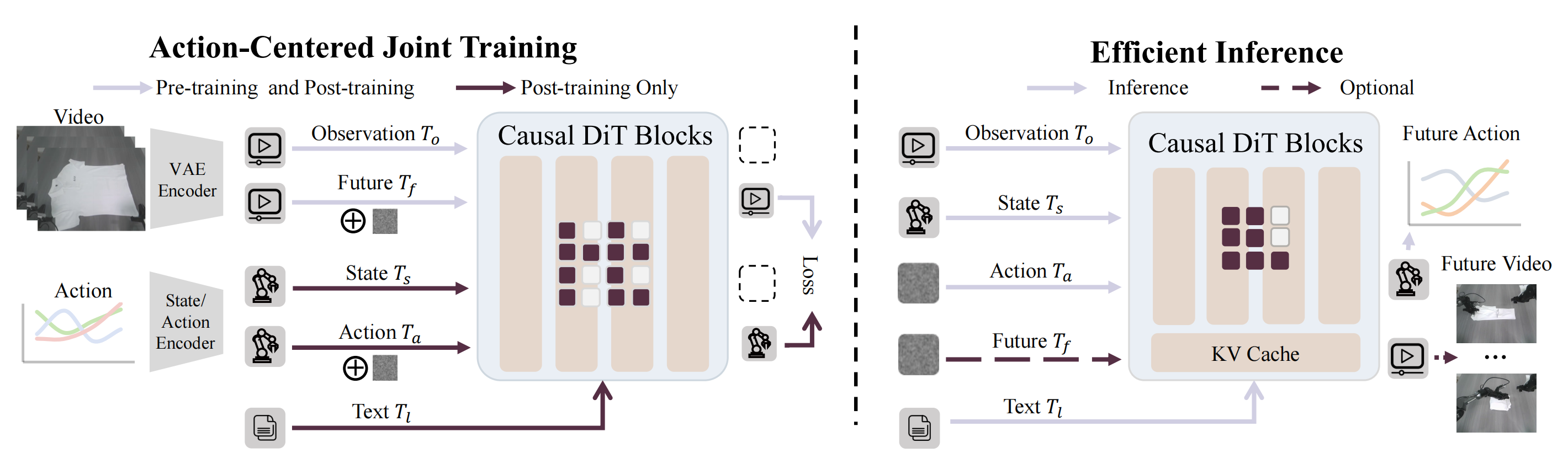
GigaWorld-Policy 采用了一个参数规模为 50 亿的扩散 Transformer(Wan 等,2025),该模型通过以动作为中心的目标进行预训练,用作机器人操作的"世界--动作"(World--Action)模型
通过拼接多视角输入,该框架能够在多视角间进行一致的联合推理,并采用因果掩码机制统一动作生成和视觉动态建模
// 待更