主成分分析 (Principal Component Analysis,简称PCA) 是最常用的一种降维方法。先考虑这样一个问题:++对于正交属性空间中的样本点,如何用一个超平面对所有样本进行恰当的表达?++
<什么是正交属性空间?是指属性方向相互垂直、属性向量之间内积为零(无冗余信息)的正交关系构成的向量空间 (常用于降维、特征提取和数据压缩)。
PCA核心逻辑的直观理解: 通过"正交变换"将原始属性映射到正交属性空间,在此正交属性空间找到最大化方差方向的主成分(正交基,彼此正交,避免特征冗余)。
主成分(正交基)是对原始属性的线性组合 (即在超平面上的投影 W*xi),且满足如下所述的"最近重构性"和"最大可分性",实现对样本的高效降维。例如,将高维数据投影到正交基上,用少数维度捕捉数据的主要信息,同时减少计算复杂度。 >
若存在这样的超平面,那么它应具有这样的性质:
最近重构性:样本点到这个超平面的距离都尽可能近 (投影误差最小,保留原始数据的主要信息);
最大可分性:样本点在这个超平面上的投影能尽可能分开。
有趣的是,基于最近重构性和最大可分性,能分别得到主成分分析的两种等价推导。
25.1 主成分分析(PCA)的推导与优化目标
假定数据样本进行了中心化,即Σ(i)xi=0;
将维度降低到d'<d,低维坐标系为 {w1, w2, ..., wd'),其中++wi是标准正交基向量,||wi||2=1 且wiᵀwj=0 (i≠j,内积为零)++ <xi与wi是相同的维度d>,
++则样本点xi在低维坐标系的投影为 zi=(zi1, zi2, ..., zid'),其中 zij=wjᵀxi,是样本xi在低维坐标系下第j维的坐标(投影)++ ,若基于zi重构xi,则会得到 xi* = Σ(j=1,d')zijwj = zi1w1 + zi2w2 + ... + zid'wd'
因为zij=wjᵀxi
Σ(j=1,d')zijwj = Σ(j=1,d')(wjᵀxi)wj = Σ(j=1,d')wj(wjᵀxi) = (Σ(j=1,d')wjwjᵀ)xi = WWᵀxi
<WWᵀ → d'个d×d相加,WWᵀxi → d×d·d维列向量 → d维列向量 → xi*>
考虑全部样本集,原样本xi与基于投影点zi重构的样本xi*之间距离的总和为 Σ(i=1,m)||xi*-xi||^2
= Σ(i=1,m) ||(Σ(j=1,d')zijwj) - xi||^2 = Σ(i=1,m) ||WWᵀxi - xi||^2
||WWᵀxi - xi||^2 = (WWᵀxi - xi)ᵀ(WWᵀxi - xi) = ||WWᵀxi||^2 -2xiᵀWWᵀxi + ||xi||^2
||WWᵀxi||^2 = (WWᵀxi)ᵀ(WWᵀxi) = xiᵀWWᵀWWᵀxi = xiᵀWWᵀxi <WᵀW=I>
所以有 Σ(i=1,m)||xi*-xi||^2 = Σ(i=1,m)xiᵀWWᵀxi -2xiᵀWWᵀxi + const
= Σ(i=1,m)(-xiᵀWWᵀxi) + const
Σ(i=1,m)xiᵀWWᵀxi =?= tr(Wᵀ(Σ(i=1,m)xixiᵀ)W)
Σ(i=1,m)||xi*-xi||^2 ∝ -tr(Wᵀ(Σ(i=1,m)xixiᵀ)W)
其中W=(w1, w2, ..., wd)。根据最近重构性,Σ(i=1,m)||xi*-xi||^2 应被最小化,考虑到wj是标准正交基,Σ(i)xixiᵀ是协方差矩阵,
则有 min(W) -tr(WᵀXXᵀW) s.t. WᵀW=I ,这就是主成分分析的优化目标。
从最大可分性出发,能得到主成分分析的另一种解释。样本xi在新空间的超平面上的投影是Wᵀxi,应使所有样本的投影尽可能分开,如图直观所示 :
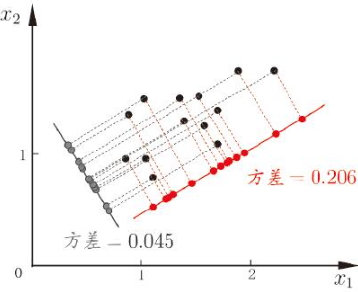
则应该使投影后样本的方差最大化,投影后样本的"方差"是 Σ(i)WᵀxixiᵀW
于是优化目标可写为 max(W) tr(WᵀXXᵀW) s.t. WTW=I,与 min(W) -tr(WᵀXXᵀW) 等价。
25.2 主成分分析(PCA)的求解与算法
PCA也可看作是逐一选取方差最大方向,即先对协方差矩阵 Σ(i)xixiᵀ 做特征值分解,取最大特征值λ1*对应的特征向量w1*;
再对Σ(i)xixiᵀ-λ1*w1*w1*ᵀ做特征值分解,取最大特征值对应的特征向量w2* ......
由W各分量正交及 Σ(i=1,m)xixiᵀ=Σ(j=1,d)λjwjwjᵀ可知,++上述逐一选取方差最大方向的做法与直接选取d'个最大特征值对应的特征向量等价++。
++所以,只需对协方差矩阵 Σ(i)xixiᵀ 进行特征值分解,将求得的特征值排序:λ1≥λ2≥...≥λd,取前d'个最大特征值对应的特征向量构成W*=(w1*, w2*, ..., wd'*)。这就是主成分分析的解++。
因此,PCA算法可描述如下:

25.3 PCA 协方差矩阵特征值分解
以下通过一个具体的二维数据实例,直观演示PCA中协方差矩阵特征值分解及逐一选取方差最大方向构成主成分矩阵的过程:
- 选取3个二维样本点,中心化后数据如下 (均值已归零) :
- 计算协方差矩阵 Σ:
- 协方差矩阵 Σ 特征值分解:
由特征方程 det(Σ−λI)=0 可得:
解得特征值:
λ1 = 1.5,λ2 = 0.5
解得对应的特征向量:
λ1 = 1.5 : (Σ-1.5)v1 = 0 得
λ1 = 0.5 : (Σ-0.5)v2 = 0 得
协方差矩阵 Σ 特征值分解结果:
- 逐一选取方差最大方向:
步骤1:取最大特征值 λ1=1.5 对应的特征向量
计算剩余协方差矩阵 R:
步骤2:对剩余协方差矩阵 R 特征值分解
解得特征值 λ=0.5 (对应 w2*=v2) 和 λ=0 (无效)。
- 即等价于直接取d'=2个最大特征值对应的特征向量构成主成分矩阵 W* = w1\*, w2\*
这就是主成分分析的解,即样本在新空间实现投影降维的"超平面"。
PCA仅需保留W*与样本的均值向量 (保存样本的均值向量是为了通过向量减法对新样本同样进行中心化) 即可通过简单的向量减法和矩阵-向量乘法(W*ᵀxi)将新样本投影至低维空间实现降维。
显然,低维空间与原始高维空间必有不同,因为对应于最小的d-d'个特征值的特征向量被舍弃了,这是降维导致的结果。但舍弃这部分信息往往是必要的:
一方面,舍弃这部分信息之后能使样本的采样密度增大,这正是降维的重要动机;另一方面,当数据受到噪声影响时,最小的特征值所对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到去噪的效果。