个人游戏笔记本免费"养龙虾"(Win10+WSL2+OpenClaw 部署与配置指南)
- 前言
- [一、安装 WSL2 环境](#一、安装 WSL2 环境)
-
- [1、开启 WSL2](#1、开启 WSL2)
- 2、启用systemd
- 3、WSL固定DNS
- 4、删除systemd生成的resolv.conf
- [5、重启 WSL](#5、重启 WSL)
- 【可选】6、WSL2性能优化:
- 二、安装Node.js环境
- 三、部署openclaw
- 四、部署本地私有模型
-
- 1、安装Ollama
- [2、 拉取基础大模型(推荐Qwen系列,国内适配性最佳)](#2、 拉取基础大模型(推荐Qwen系列,国内适配性最佳))
- [3、 定制大模型:扩展上下文窗口至32768 tokens(核心步骤)](#3、 定制大模型:扩展上下文窗口至32768 tokens(核心步骤))
- 4、交互式配置:对接本地Ollama模型
- 5、碰到的问题及解决方法
系列文章:
1. 个人游戏笔记本免费"养龙虾"(Win10+WSL2+OpenClaw 部署与配置指南)
2.个人游戏笔记本免费"养龙虾"(二)用显卡GPU运行OpenClaw,CUDA的安装与配置
前言
Openclaw的安全问题饱受诟病。为此,有文章建议用虚拟机或者沙箱隔离能缓解风险。虚拟机对于GPU的支持不太好。而沙箱轻量高效,有博文指出利用Docker容器构建沙箱,适合运行Openclaw这类高风险AI工具。官方也支持并推荐Docker容器化部署。
我的游戏笔记本是Lenovo Legion Y9000X 2021,Windows10操作系统,显卡是NVIDIA GeForce RTX 2060,6G显存。部署openclaw需要WSL2。WSL2类似于虚拟机,已经具备一定的隔离主机的作用,所以我不打算用Docker,而是直接按照官方指南在WSL2中配置Ubuntu 24.04,再部署openclaw的方式。有可能还需要安装CUDA Toolkit 12.4与NVIDIA Container Toolkit兼容层,再通过systemd-genie启用服务管理。
一、安装 WSL2 环境
WSL2 是官方推荐的 OpenClaw 运行环境。
1、开启 WSL2
在powershell中安装WSL2。可以直接指定位置到其他盘符(例如:e:\WSL),以免过多占用C盘空间。
以管理员身份运行powershell:
powershell
wsl --install -d Ubuntu --location e:\WSL注意事项
- 需要以管理员身份运行 PowerShell
- 路径
e:\WSL需要提前创建 - 安装完成后可能需要重启系统
- 第一次启动 Ubuntu 需要等待安装完成并设置用户名密码
- WSL2 在哪个盘,OpenClaw 就在哪个盘。
验证安装
powershell
# 查看已安装的 WSL 发行版
wsl -l -v
# 启动 Ubuntu
wsl -d Ubuntu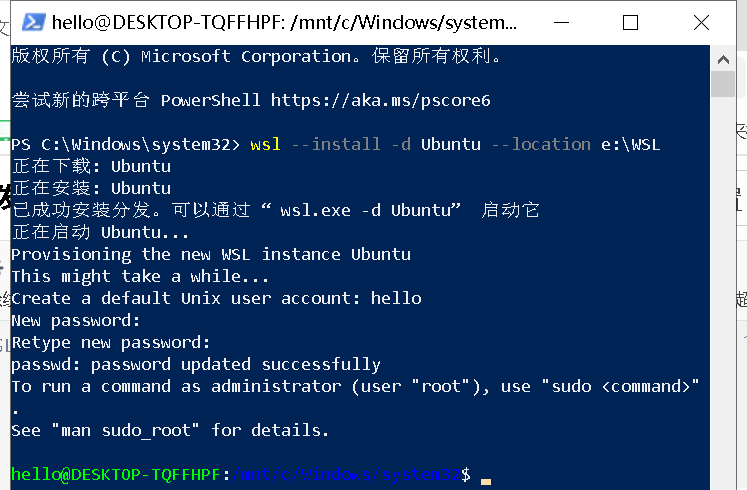
安装的Ubuntu的版本是Ubuntu 24.04.4 LTS:
cat /etc/os-release
PRETTY_NAME="Ubuntu 24.04.4 LTS"
NAME="Ubuntu"
VERSION_ID="24.04"
VERSION="24.04.4 LTS (Noble Numbat)"
2、启用systemd
进入WSL Ubuntu终端,查看/etc/wsl.conf。


3、WSL固定DNS
关闭WSL自动生成DNS:
bash
## nano /etc/wsl.conf
[network]
generateResolvConf = false4、删除systemd生成的resolv.conf
systemd生成的resolv.conf是软连接,所以先删除,再新建。
bash
sudo rm /etc/resolv.conf创建新的静态 DNS 文件:
bash
sudo vim /etc/resolv.conf
nameserver 1.1.1.1
nameserver 8.8.8.8
nameserver 202.103.24.68
options timeout:2 attempts:35、重启 WSL
在powershell中重启WSL,再打开Ubuntu。
注意:不是在WSL Ubuntu终端
powershell
wsl --shutdown
wsl -d Ubuntun【可选】6、WSL2性能优化:
在Windows用户目录(C:\Users\你的用户名)下创建 .wslconfig 文件,用于限制WSL2的内存和CPU使用,避免占满主机资源。
javascript
[wsl2]
memory=6GB # 根据你的物理内存调整
processors=4
localhostForwarding=true保存后,在PowerShell中执行 wsl --shutdown 重启WSL使配置生效。
二、安装Node.js环境
Node.js运行环境要求版本 ≥ 22。
1、更换镜像源(Ubuntu24.04):
-
修改/etc/apt/sources.list.d/文件夹中的ubuntu.sources。
把
http://archive.ubuntu.com/ubuntu/修改为https://mirrors.aliyun.com/ubuntu/。把
http://security.ubuntu.com/ubuntu/修改为https://mirrors.aliyun.com/ubuntu/ -
在 WSL Ubuntu 终端中执行:
bash
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt-get install -y nodejs- 验证安装:
bash
$ node -v
v22.22.1三、部署openclaw
1、配置npm国内镜像源
bash
npm config set registry https://registry.npmmirror.com2、安装OpenClaw
bash
# 全局安装 OpenClaw
sudo npm install -g openclaw@latest3、初始化配置OpenClaw
参考文献1:本地部署OpenClaw+Qwen大模型+接入飞书机器人
参考文献2: 让你玩转OpenClaw (安装配置篇)-腾讯云开发者社区-腾讯云
在终端中执行以下命令:
bash
# 交互式配置
openclaw onboard --install-daemon(1)安全须知
OpenClaw onboarding启动之后,首先给出必读的安全须知。其中,明确说明了OpenClaw 是一个个人兴趣项目,目前仍处于 Beta 测试阶段,功能尚不完善,可能存在未预期的行为或风险。
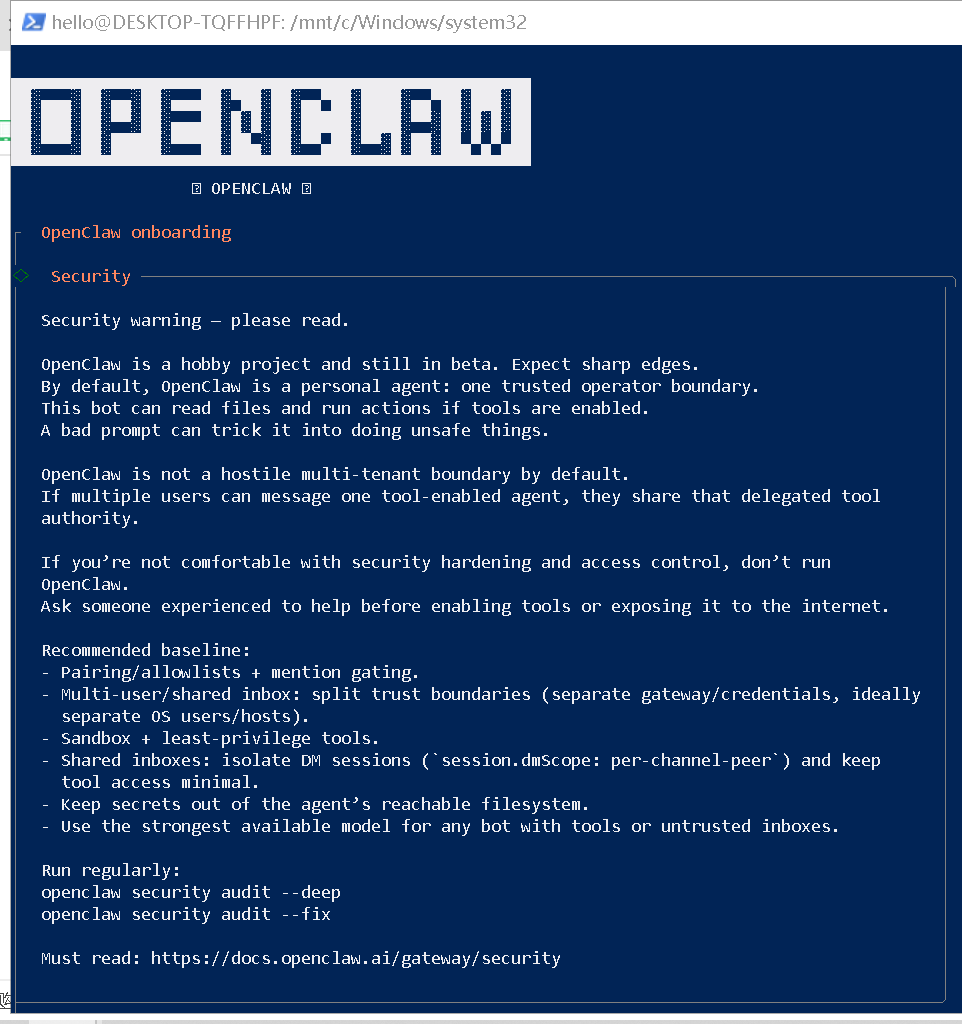
(2)初始化配置
以下是几个配置的选择方式。用↑、↓键选择,↵回车键确认。
- I understand this is powerful and inherently risky. Continue?
选择 Yes
- Onboarding mode
选择 QuickStart
- Model/auth provider
选择 Skip for now(稍后配置千问qwen3.5:2b模型)
- Filter models by provider
选择 All providers
- Default model
选择 Keep current (default: anthropic/claude-opus-4-6)
- Select channel (QuickStart)
选择 Skip for now(稍后配置渠道)
- Configure skills now? (recommended)
选择 No
- Enable hooks?
按空格键选中选项,按回车键进入下一步
- How do you want to hatch your bot?
选择 Do this later
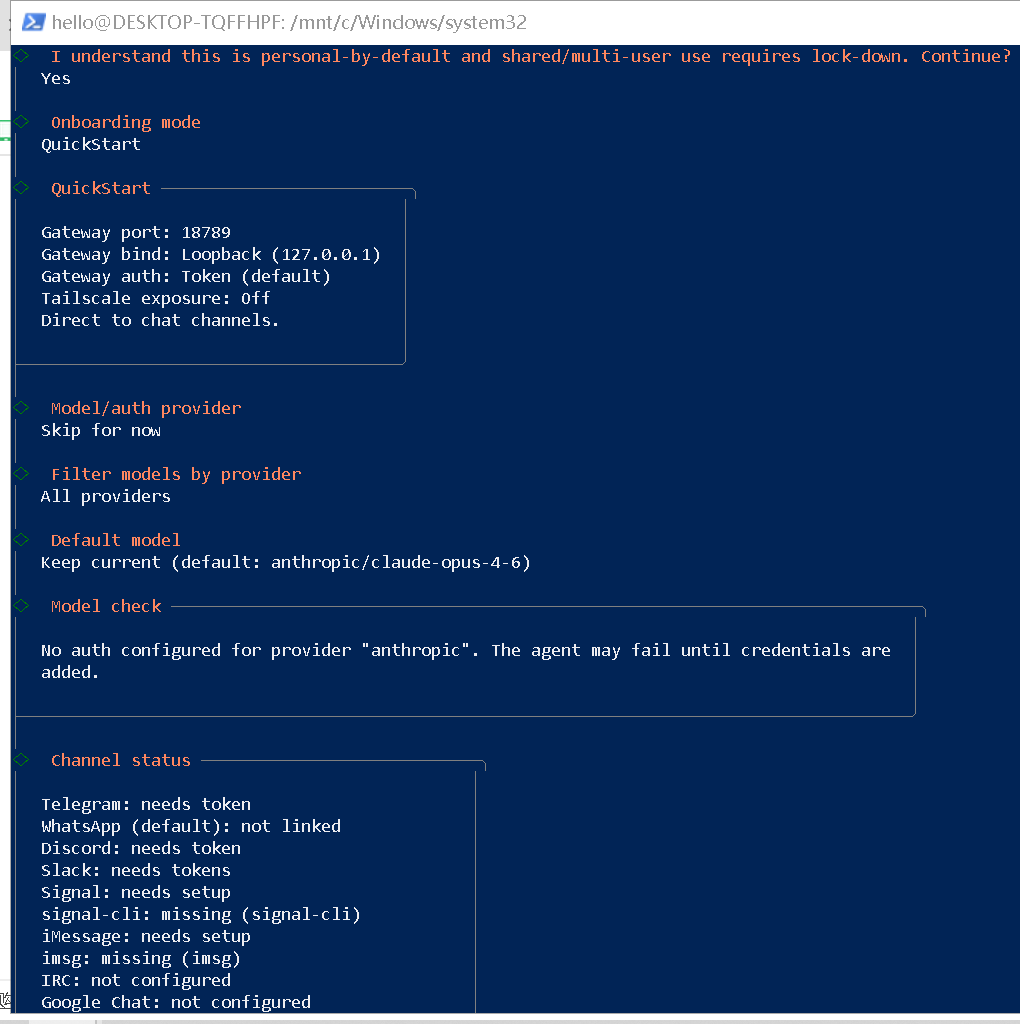
(3)控制 OpenClaw
配置完成之后,在终端界面中,可以看到"控制界面"信息。把"WEB UI"中的地址复制到浏览器中,就可以通知面板使用openclaw。
但是,目前没有配置大模型,所以无法实现AI功能。
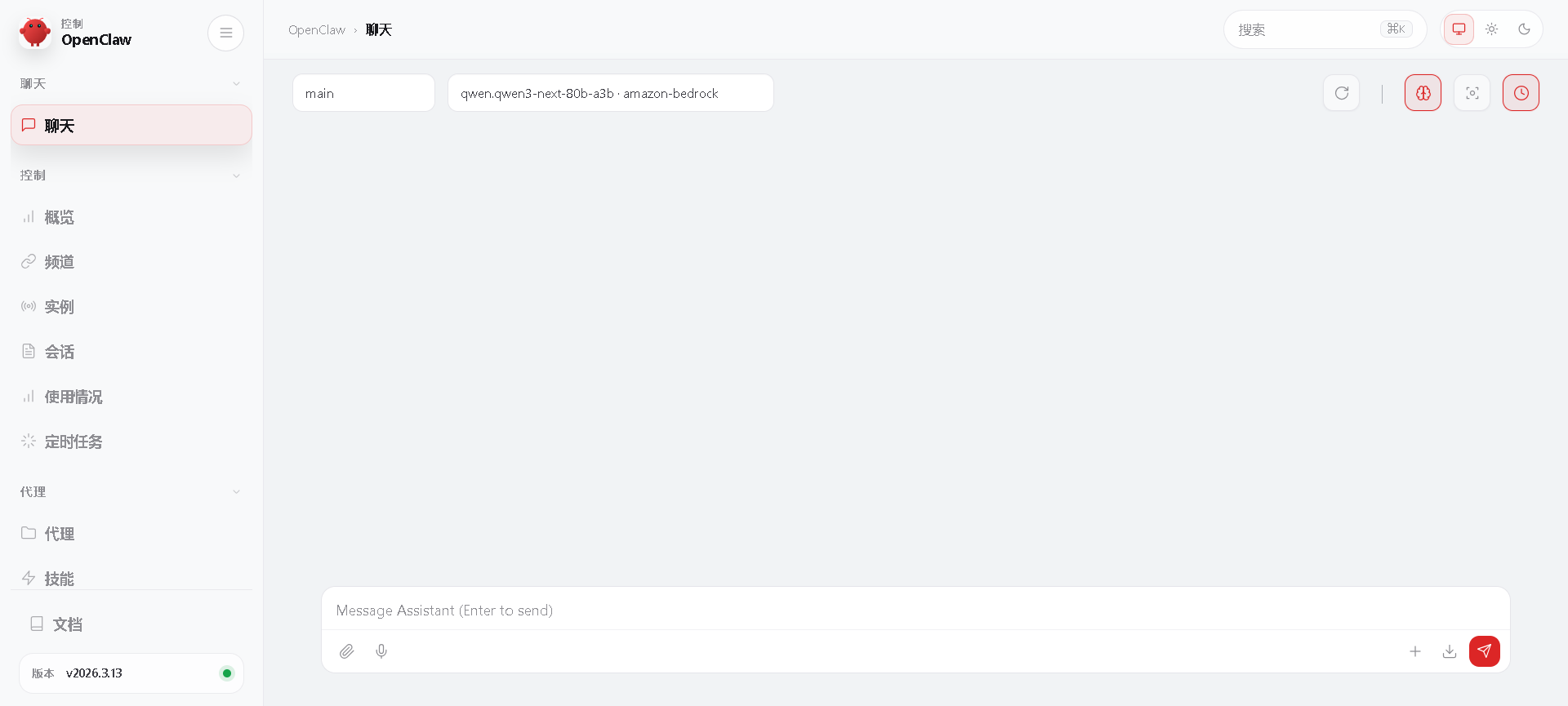
四、部署本地私有模型
使用openclaw如果提示词使用不当,进入死循环,那么将产生巨量token费用。(建议:合理设计提示词逻辑结构,避免循环调用场景。监控API调用频率和token消耗情况,设置使用阈值预警。)
各云平台提供的试用免费API适合个人用户尝鲜使用,可作为入门选择。
个人游戏本配置有GPU显存,可以本地运行Openclaw,零成本、上手快,无需购买服务器,避免天量的token费用,适合个人入门使用,能够快速验证功能、处理敏感数据或断网环境使用。
1、安装Ollama
bash
# Linux(Ubuntu/Debian)
curl -fsSL https://ollama.com/install.sh | sh验证安装:
bash
# 显示版本号即表示成功
$ ollama -v
ollama version is 0.18.22、 拉取基础大模型(推荐Qwen系列,国内适配性最佳)
Ollama支持一键拉取主流大模型,推荐通义千问系列,兼顾性能与硬件要求:
bash
# 拉取qwen3.5:2b基础模型(约2.7GB,适合6G显存GPU)
ollama pull qwen3.5:2b拉取过程保持网络通畅,耗时5~20分钟(取决于网络速度),模型自动存储在本地Ollama目录。
bash
ollama pull qwen3.5:2b
pulling manifest
pulling b709d81508a0: 100% ▕▏ 2.7 GB
pulling 9be69ef46306: 100% ▕▏ 11 KB
pulling 9371364b27a5: 100% ▕▏ 65 B
pulling ee043a99abe5: 100% ▕▏ 473 B
verifying sha256 digest
writing manifest
success3、 定制大模型:扩展上下文窗口至32768 tokens(核心步骤)
Ollama基础模型默认上下文窗口仅4096 tokens,需手动定制扩展至32768 tokens(兼顾推理速度与上下文长度)。在Linux终端中新建Modelfile,然后修改该文件内容:
bash
# 1. 切换到当前用户根目录(替换<你的用户名>为实际Windows用户名,如Administrator)
$ cd /mnt/c/users/<你的用户名>
# 2. 一键创建Modelfile配置文件(基于qwen3.5:2b,设置上下文窗口32768 tokens)
$ sudo vim Modelfile
FROM qwen3.5:2b
PARAMETER num_ctx 32768
# 3. 验证配置文件(正确输出应包含FROM qwen3.5:2b和PARAMETER num_ctx 32768)
$ Get-Content Modelfile
bash
# 4. (可选)创建自定义模型(命名为qwen3.5:2b-32k,便于识别)
$ sudo ollama create qwen3.5:2b-32k -f Modelfile
# 5. 验证自定义模型(查看本地所有模型,应显示qwen3.5:2b-32k)
$ ollama list
# 6. (可选)确认上下文窗口配置(确保包含num_ctx 32768)
ollama show qwen3.5:2b-32k --modelfile
# 7. 验证模型运行正常
ollama run qwen3.5:2b "你好,请介绍自己"
# 8. 后台启动Ollama服务,暴露本地接口
ollama serve
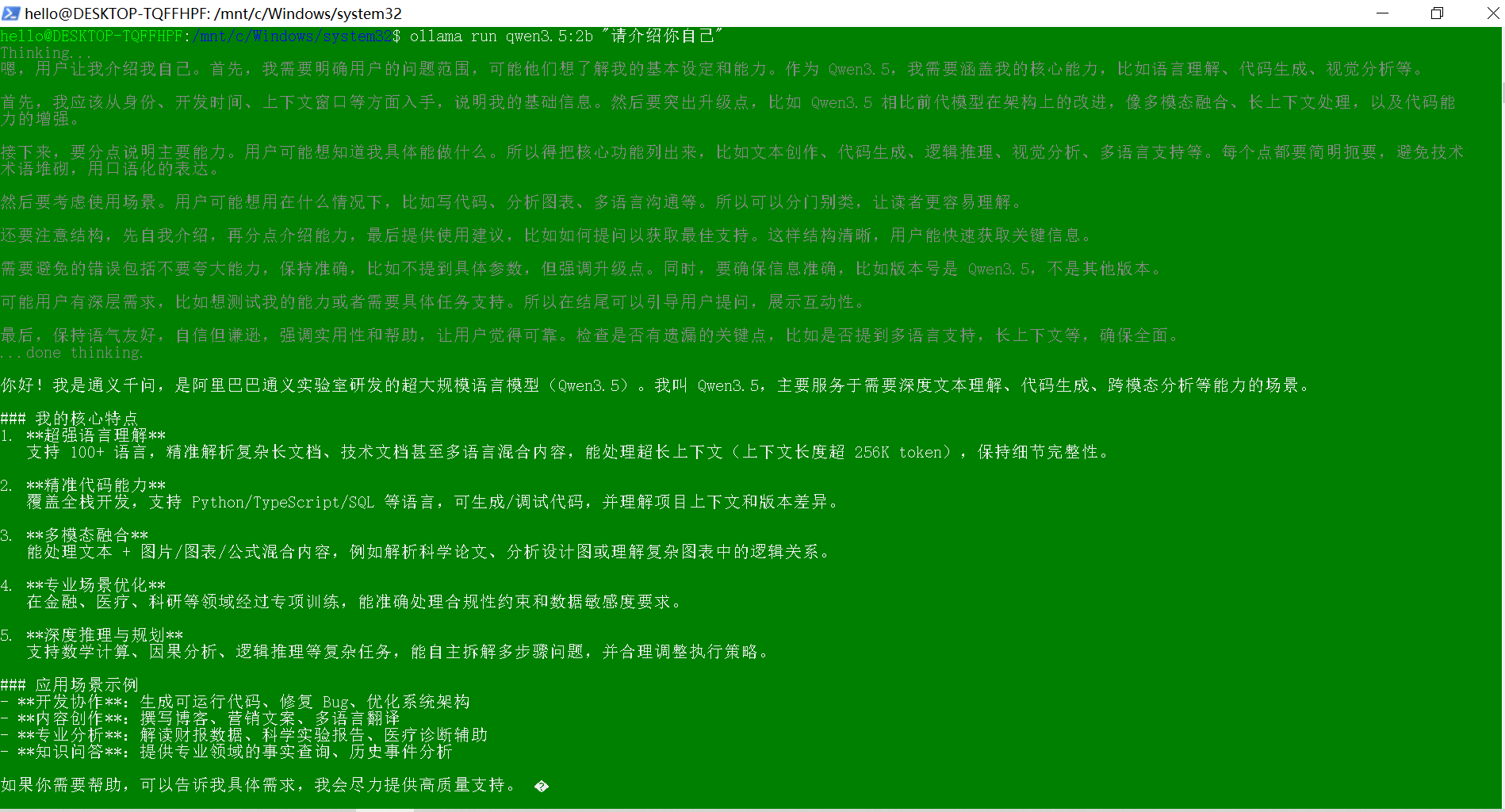
参考文献3:Ollama自定义模型,定制你自己的大模型
参考文献4:Ollama 本地自定义模型实践指南-CSDN
4、交互式配置:对接本地Ollama模型
执行配置向导,将OpenClaw指向本地Ollama。
# 启动配置向导
openclaw onboard按PowerShell提示依次完成以下配置(严格操作,避免错误):
| 配置步骤 | 操作要求 | 输入/选择内容 |
|---|---|---|
| Model/auth provider | 选择模型提供商,拉到列表最后一项 | Custom Provider |
| API Base URL | 本地Ollama的API地址(固定格式) | http://127.0.0.1:11434/v1 |
| API Key | 任意字符串(不可留空,Ollama无实际鉴权,仅为格式要求) | ollama(或自定义如123456) |
| Endpoint compatibility | 接口兼容模式 | OpenAI-compatible |
| Model ID | 本地自定义模型名(与前文一致) | qwen3.5:2b |
| 后续所有配置项 | 暂不配置渠道、技能等 | 全部选择Skip for now / No |
配置完成后,若显示"Verification successful",表示连接成功;控制台会显示OpenClaw Web UI地址(http://127.0.0.1:18789)和管理员Token,记录Token备用。
若提示"Verification failed",先执行ollama list测试Ollama服务是否正常,确保API Base URL末尾包含"/v1"、API Key未留空。
参考文献5:OpenClaw+Windows+Ollama本地私有化-阿里云
在浏览器中输入http://127.0.0.1:18789/#token=你自己的token值就可以使用OpenClaw了。
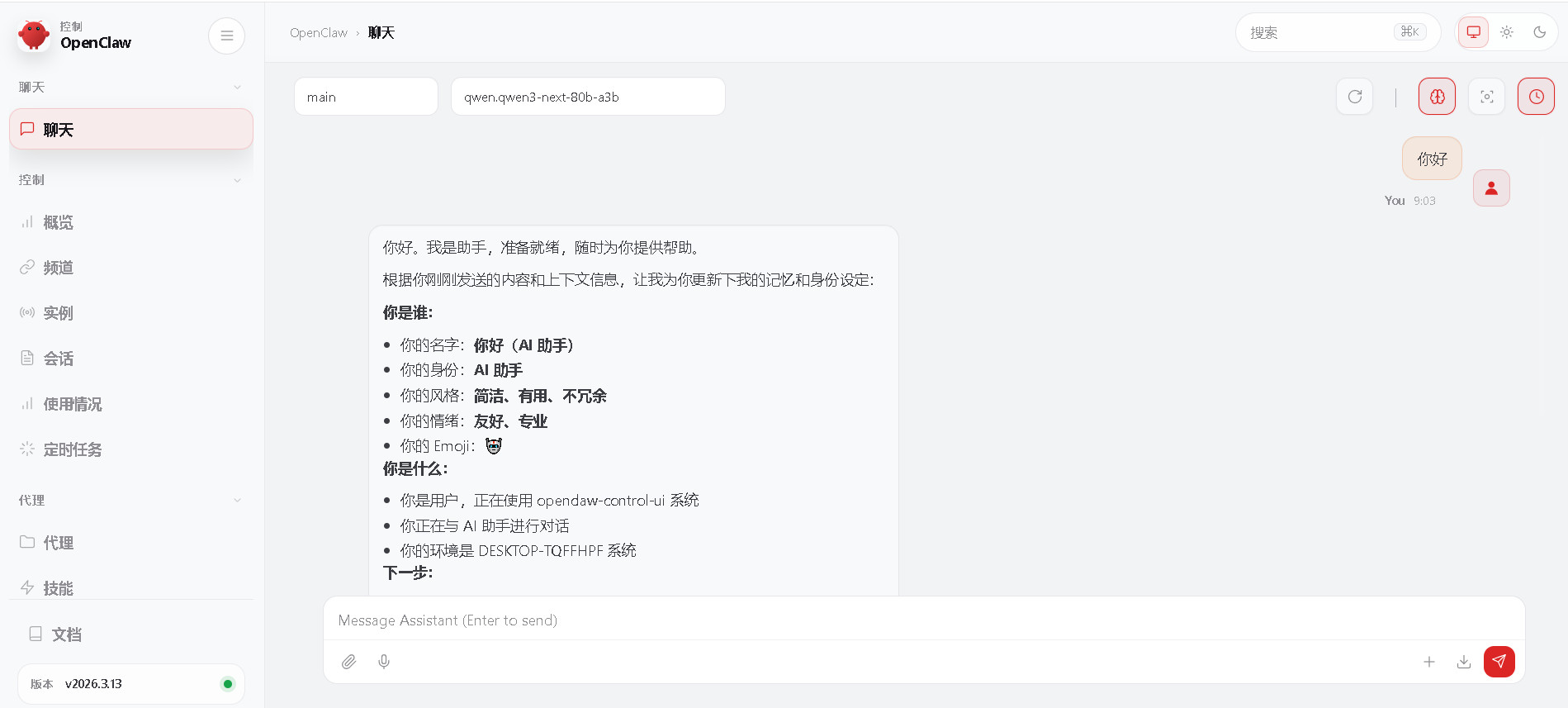
5、碰到的问题及解决方法
- 需要一定的Linux命令基础。在整个过程中,会用到nano、cd、ls、mv、rm等Linux命令。对于挂载、环境变量等基本概念也需要了解。有的命令是在PowerShell中执行,有的命令是在WSL2_Ubuntu命令行中执行。
- 模型选择不当,会造成内存不足,导致WSL2崩溃退出。解决方法有2个:一是 选择参数较低的模型,例如选择qwen3.5:2b,而不选择qwen3.5:4b。二是 降低配置参数,例如降低上下文长度;降低GPU层数量会更有效。三是关闭不必要的进程,腾出更多的CPU和内存。例如关闭杀毒、浏览器等软件。
bash
# 修改Modelfile
PARAMETER num_ctx 4096 # 将上下文长度从32K调整为4K,大幅降低KVCache显存占用
bash
# nano ~/.bashrc
# 设置GPU层数量(显存6GB设为20,显存8GB设为40)
export OLLAMA_GPU_LAYERS=10