基于大数据的糖尿病数据分析可视化
1. 项目概述
本项目是一个基于大数据技术的糖尿病数据分析与可视化系统,旨在通过机器学习算法对糖尿病健康指标进行分析、预测,并提供直观的可视化展示。系统采用前后端分离架构,后端基于 Django 和 Django Rest Framework 构建,前端基于 Vue 3、TypeScript 和 Element Plus 开发。
2. 数据集 (Dataset)
系统主要使用 BRFSS 2015 (Behavioral Risk Factor Surveillance System) 数据集,包含以下三个主要数据表,用于模型训练和数据分析:
- Diabetes012HealthIndicatorsBRFSS2015: 包含糖尿病的三种状态(0: 无糖尿病, 1: 前期糖尿病, 2: 糖尿病)及相关健康指标。
- DiabetesBinaryHealthIndicatorsBRFSS2015: 二分类数据集(0: 无糖尿病, 1: 糖尿病),用于主要的风险预测模型训练。
- DiabetesBinary5050SplitHealthIndicatorsBRFSS2015: 经过 50/50 平衡处理的二分类数据集。
数据集特征分析
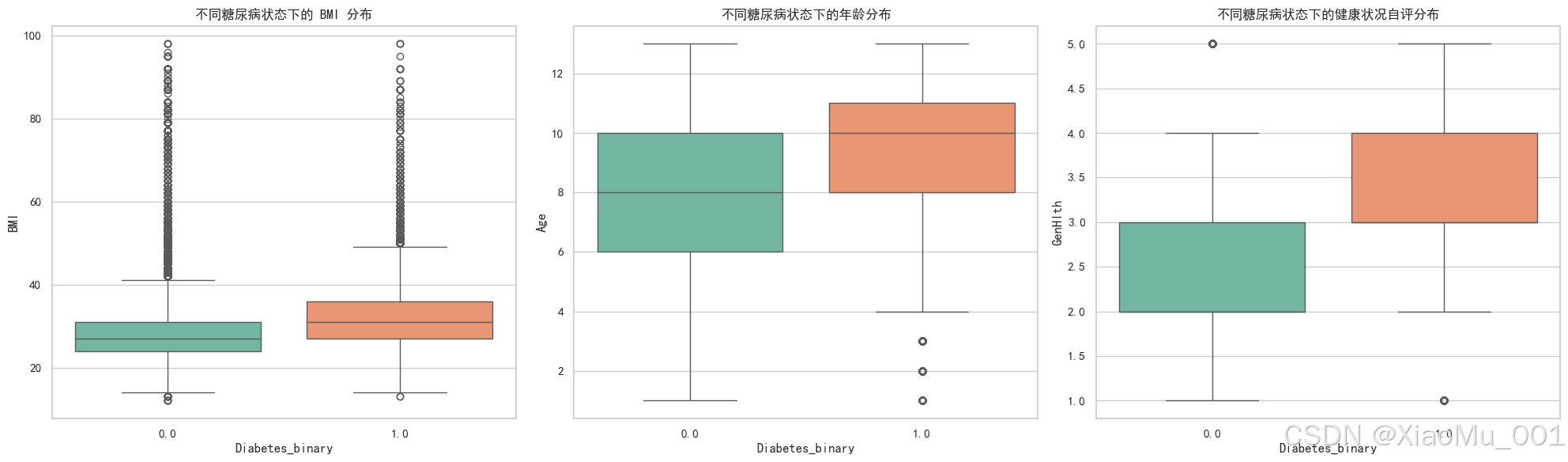
以下图表展示了数据集的特征相关性和分布情况:
-
特征相关性热力图 : 展示各特征之间的相关系数,帮助筛选对预测结果影响较大的特征。
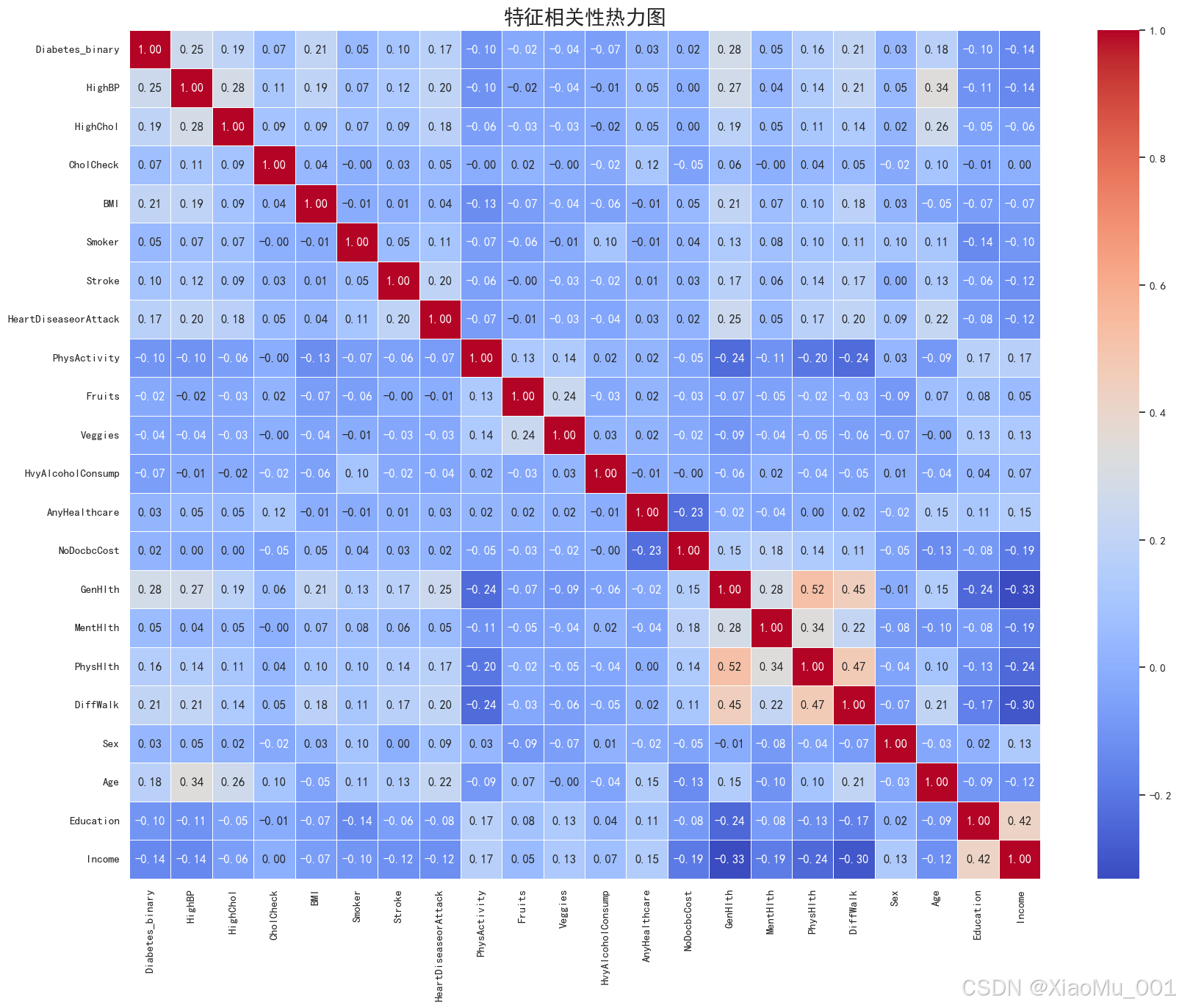
图注:颜色越深代表相关性越强,用于特征选择参考。
-
关键特征与糖尿病的关系 : 分析高血压、BMI 等关键指标与糖尿病确诊率的关系。
-
类别特征分析 :
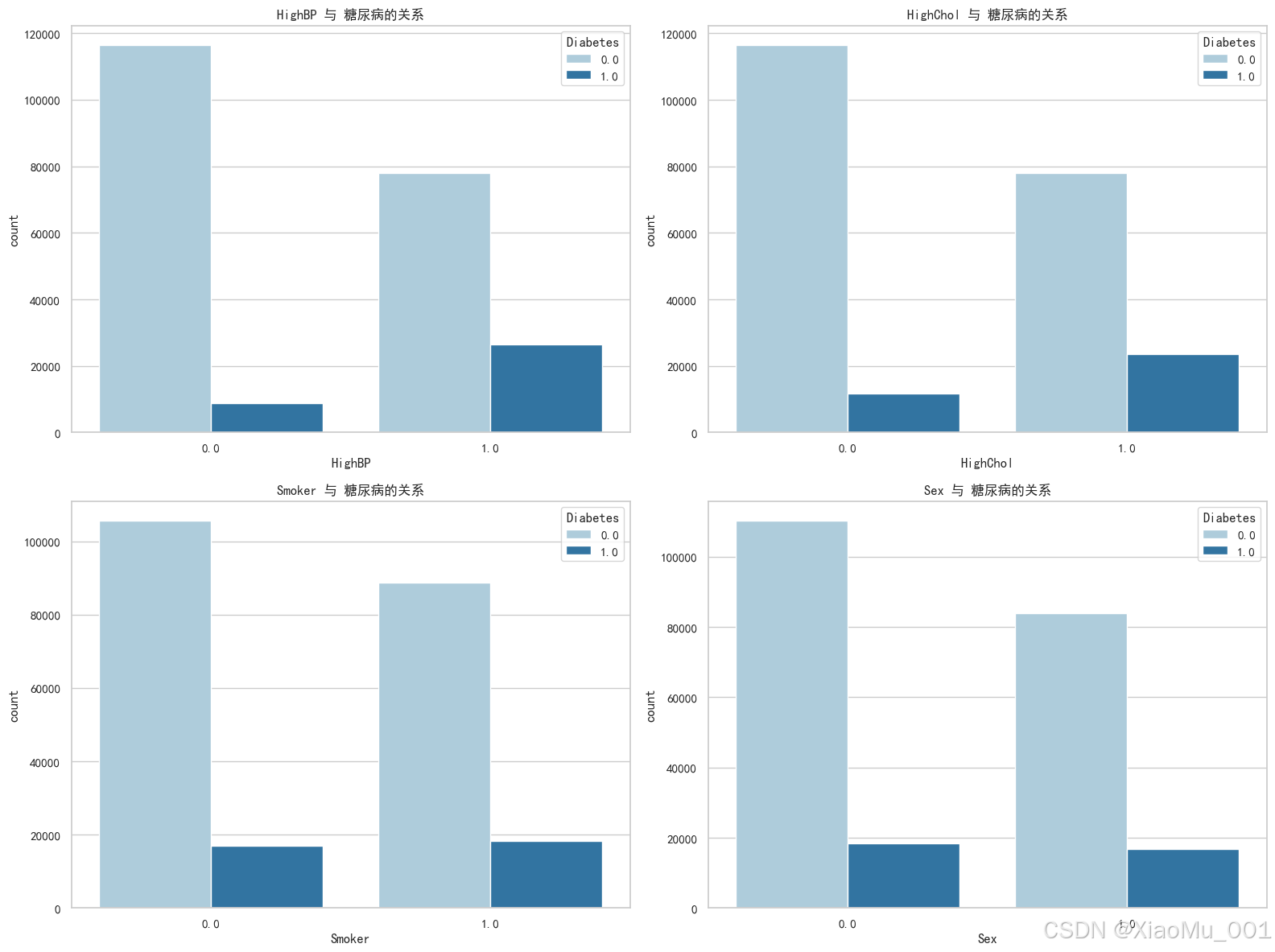
-
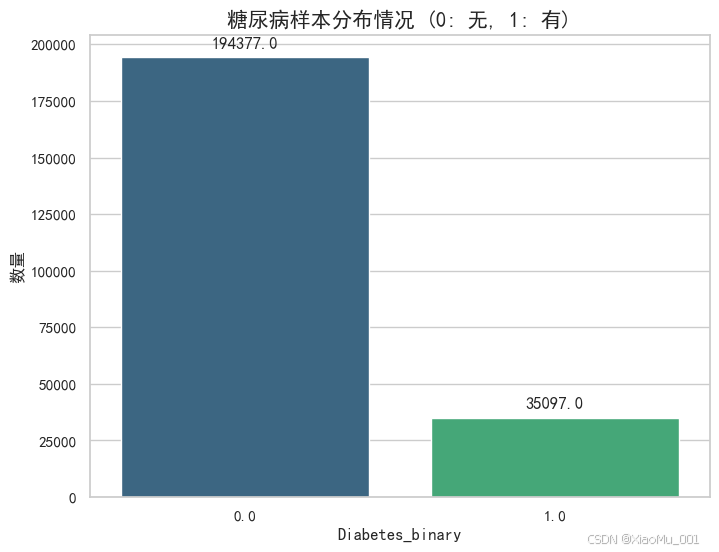
糖尿病分布情况 :
3. 算法与模型 (Algorithm & Model)
3.1 核心算法:随机森林 (Random Forest)
系统采用 随机森林分类器 (RandomForestClassifier) 作为核心预测算法。随机森林是一种集成学习方法,通过构建多个决策树并取其投票结果(分类问题)来提高预测准确率和防止过拟合。
3.2 模型训练流程
核心代码位于 System/Backend/App/services/model_service.py:
-
数据加载 : 从数据库
DiabetesBinaryHealthIndicatorsBRFSS2015表中读取数据。 -
数据预处理 :
- 去除无关列(如
id)。 - 确保所有特征为数值类型。
- 处理缺失值(填充 0)。
- 去除无关列(如
-
数据集划分 : 使用
train_test_split将数据划分为训练集 (80%) 和测试集 (20%)。 -
模型构建 :
pythonclf = RandomForestClassifier(n_estimators=100, random_state=42) clf.fit(X_train, y_train) -
模型评估: 使用准确率 (Accuracy) 和分类报告 (Classification Report) 评估模型表现。
-
模型保存 : 使用
joblib将训练好的模型保存为media/diabetes_model.pkl。
3.3 模型评估结果
-
混淆矩阵 : 展示模型在测试集上的预测结果(真阳性、假阳性、真阴性、假阴性)。
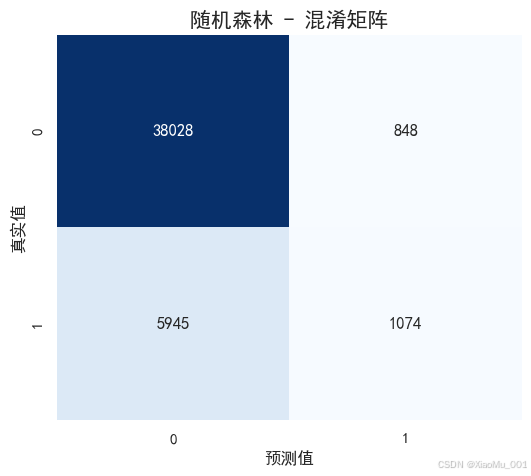
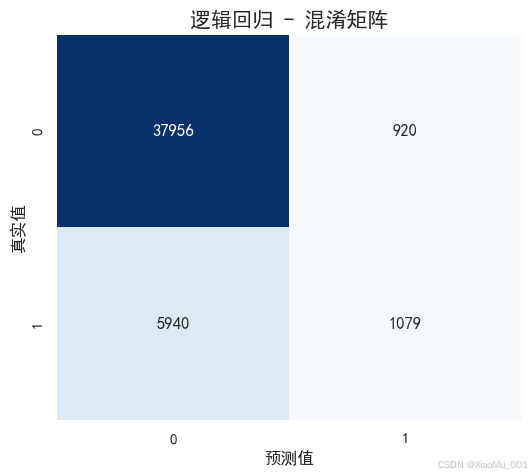
图注:对比随机森林与逻辑回归的表现,随机森林通常具有更高的准确率。
-
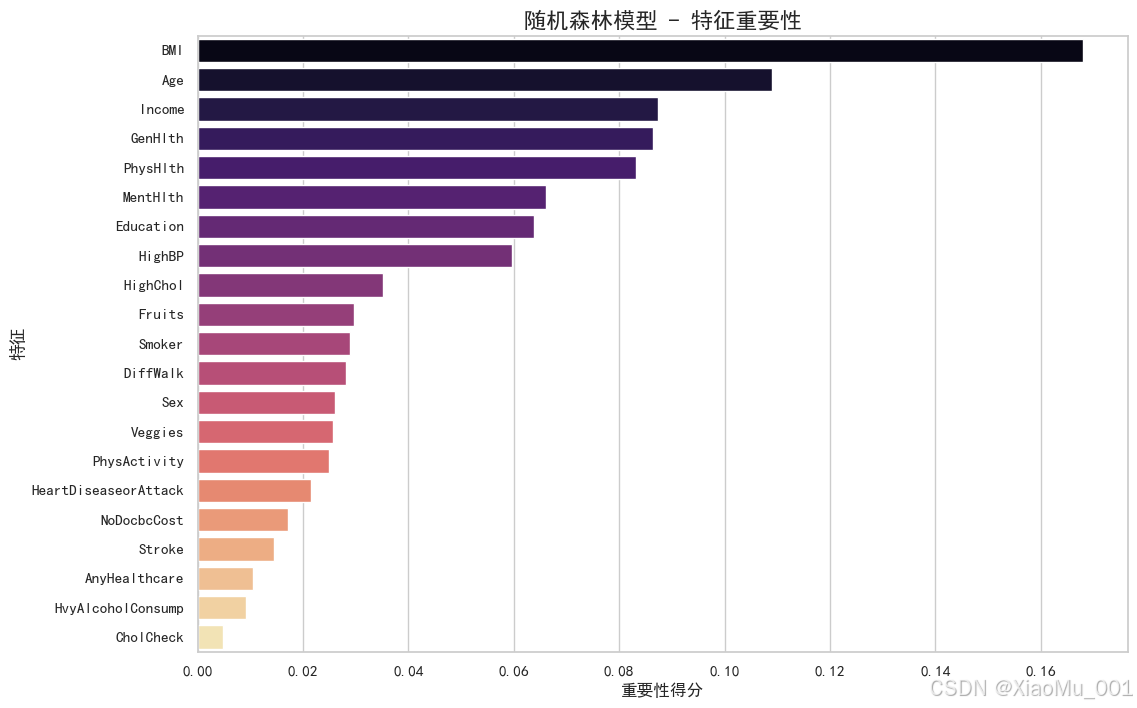
特征重要性 : 展示模型认为最重要的特征(如 BMI, Age, Glucose 等)。
-
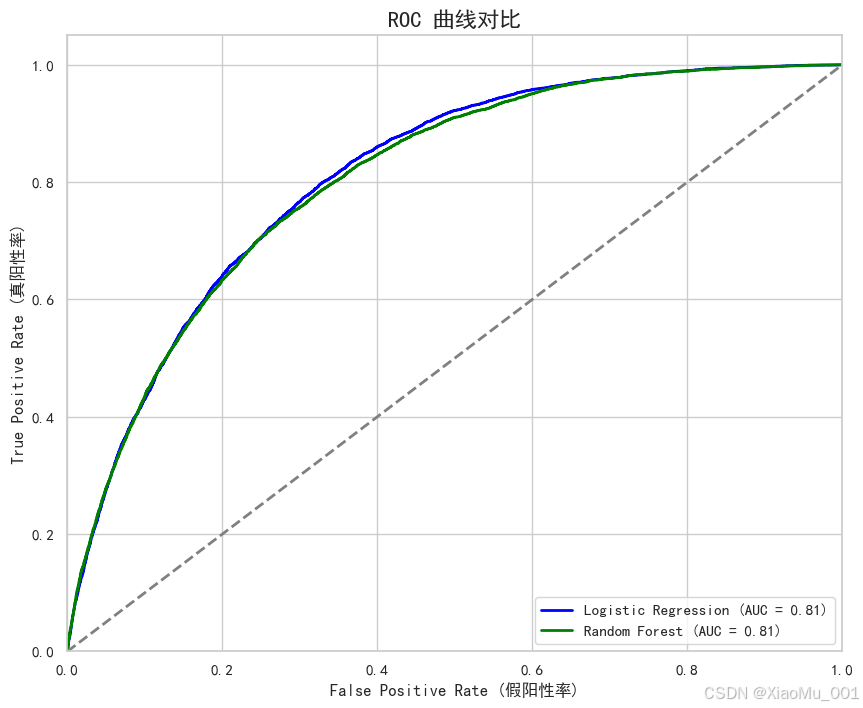
ROC 曲线对比 :
4. 数据库设计 (Database Design)
数据库采用 SQLite (开发环境) 或 MySQL (生产环境),通过 Django ORM 管理。
4.1 核心数据表结构
1. 用户信息表 (Profile)
| 字段名 | 类型 | 长度 | 非空 | 唯一 | 默认值 | 说明 |
|---|---|---|---|---|---|---|
| id | Integer | - | 是 | 是 | Auto | 主键 |
| username | CharField | 255 | 否 | 是 | '' | 用户名 |
| password | CharField | 255 | 否 | 否 | '' | 密码 |
| name | CharField | 255 | 否 | 否 | '' | 姓名 |
| role_id | ForeignKey | - | 否 | 否 | 1 | 关联 Role 表 |
2. 糖尿病二分类指标表 (DiabetesBinaryHealthIndicatorsBRFSS2015)
用于模型训练的主要数据表。
| 字段名 | 类型 | 长度 | 非空 | 索引 (db_index) | 说明 |
|---|---|---|---|---|---|
| Diabetes_binary | CharField | 255 | 否 | True | 糖尿病状态 (0/1) |
| HighBP | CharField | 255 | 否 | True | 高血压 |
| HighChol | CharField | 255 | 否 | True | 高胆固醇 |
| BMI | CharField | 255 | 否 | True | 身体质量指数 |
| Sex | CharField | 255 | 否 | True | 性别 |
| Age | CharField | 255 | 否 | True | 年龄 |
| Income | CharField | 255 | 否 | True | 收入 |
| GenHlth | CharField | 255 | 否 | True | 总体健康状况 |
| ... | ... | ... | ... | ... | (共 22 个字段) |
3. 患者信息表 (Patient)
| 字段名 | 类型 | 长度 | 非空 | 说明 |
|---|---|---|---|---|
| name | CharField | 255 | 否 | 姓名 |
| id_card_hash | CharField | 255 | 否 | 身份证号(Hash脱敏) |
| gender | CharField | 10 | 否 | 性别 |
| age | Integer | - | 否 | 年龄 |
4. 就诊记录表 (VisitRecord)
| 字段名 | 类型 | 长度 | 非空 | 说明 |
|---|---|---|---|---|
| patient_id | ForeignKey | - | 是 | 关联 Patient 表 |
| visit_date | DateTime | - | 是 | 就诊时间 |
| diagnosis | TextField | - | 否 | 诊断结果 |
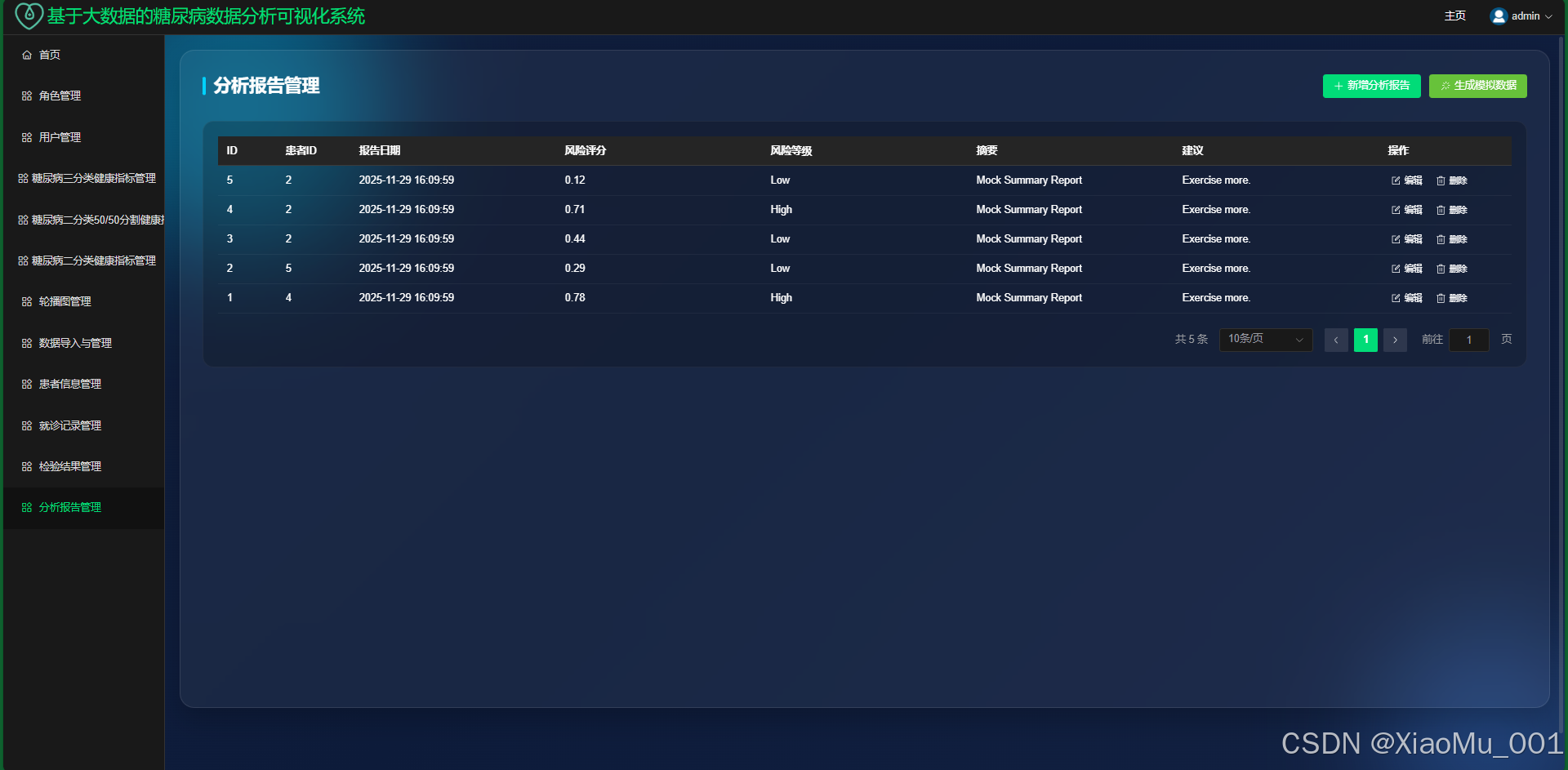
5. 分析报告表 (AnalysisReport)
| 字段名 | 类型 | 长度 | 非空 | 说明 |
|---|---|---|---|---|
| patient_id | ForeignKey | - | 是 | 关联 Patient 表 |
| report_type | CharField | 255 | 是 | 报告类型 |
| content | JSONField | - | 否 | 结构化报告数据 |
5. 系统架构 (System Architecture)
Django+Vue
6. 界面与功能详解 (Features & Interfaces)
6.1 登录与注册
用户通过账号密码登录系统,支持新用户注册。
6.2 后台主页
展示系统概览,包括快捷入口和系统状态。
6.3 数据管理
管理员可以对糖尿病数据集进行增删改查操作,支持批量导入导出。
-
二分类数据管理 :
-
三分类数据集管理 :
-
数据导入导出 :

6.4 患者与医疗管理
-
患者信息管理 : 录入和维护患者基本信息。
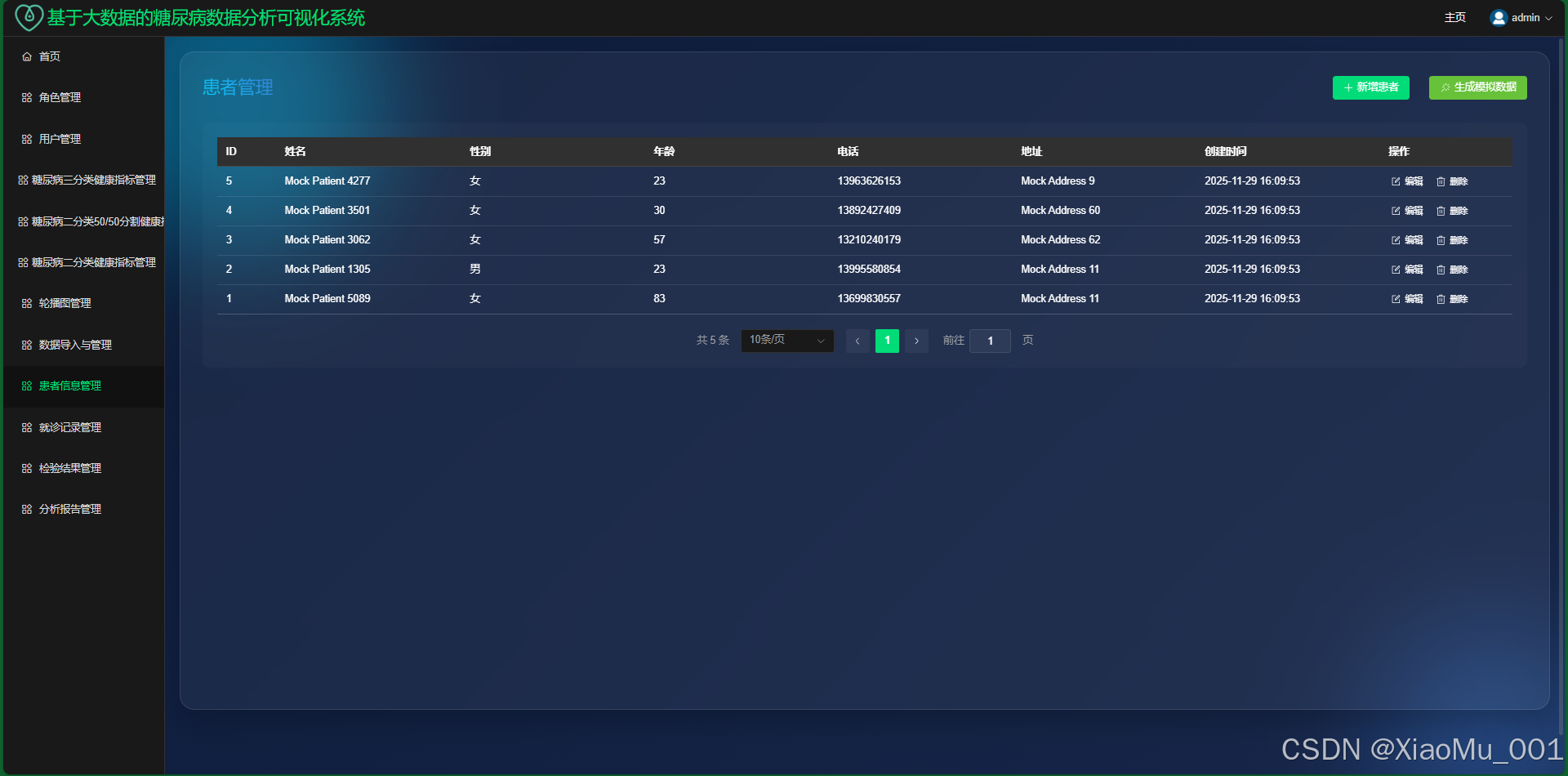
-
就诊记录 : 记录患者的就诊历史、诊断结果和医嘱。
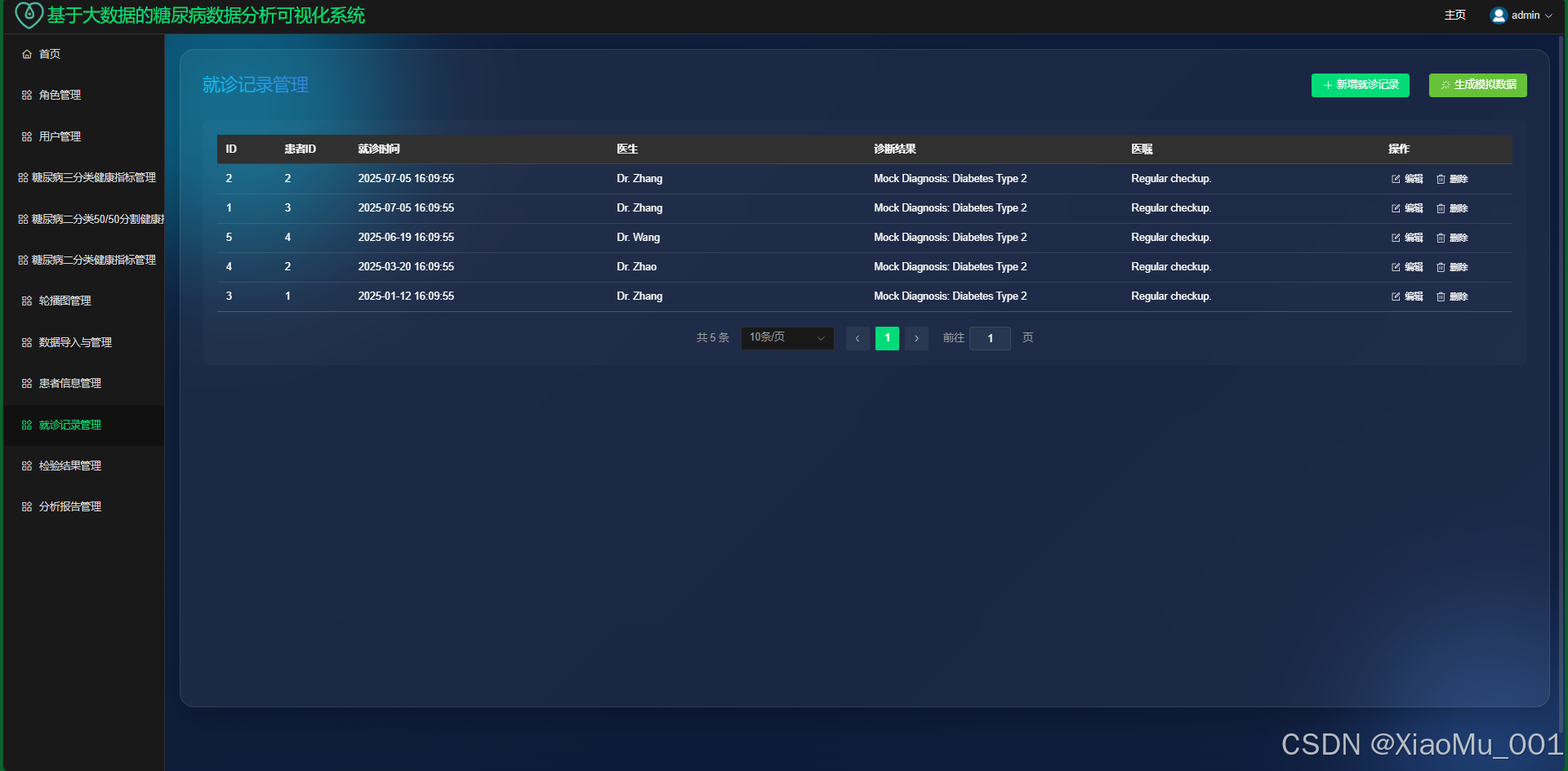
-
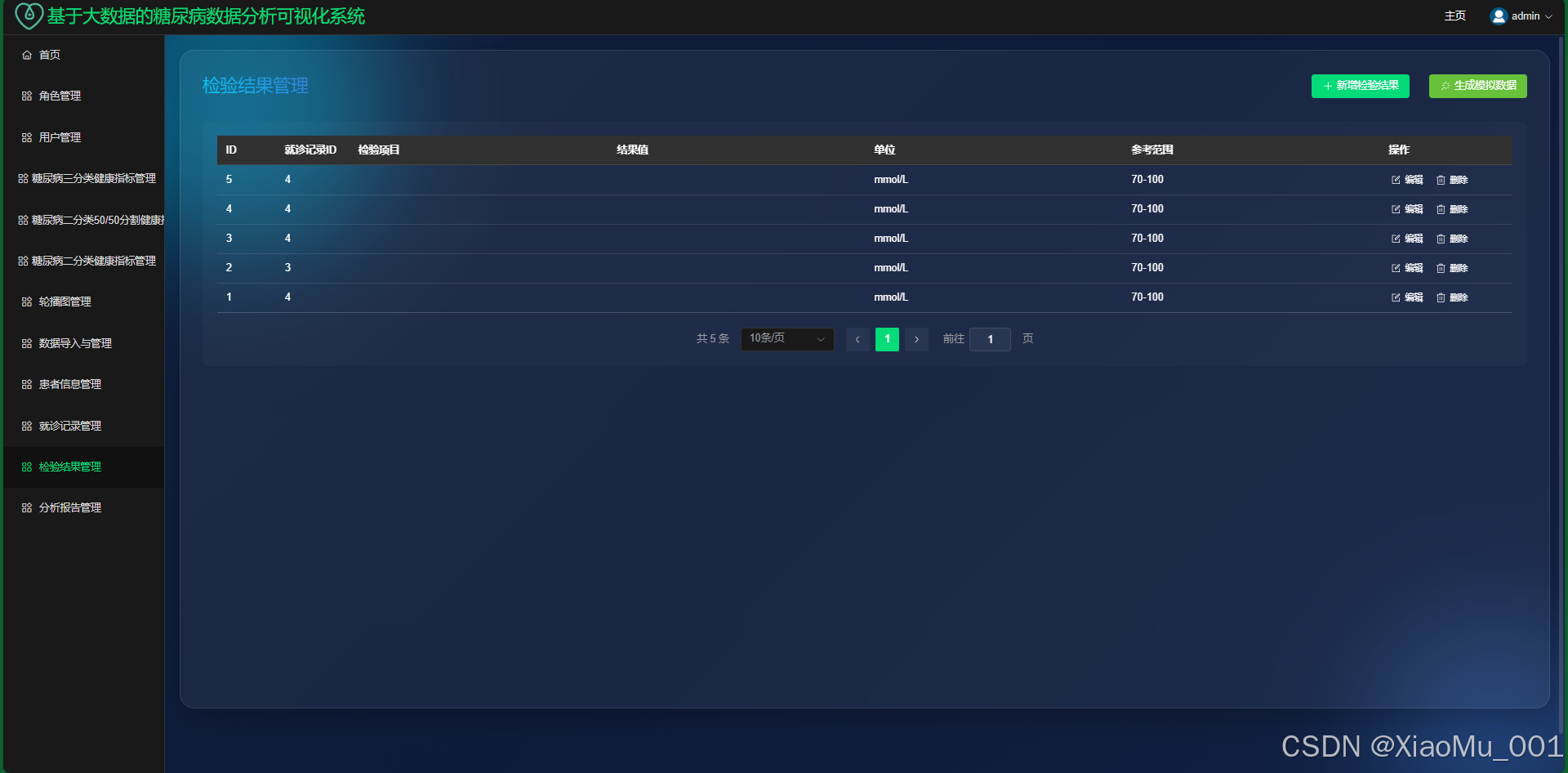
检测结果 : 记录实验室检查项目及结果(如血糖、HbA1c)。
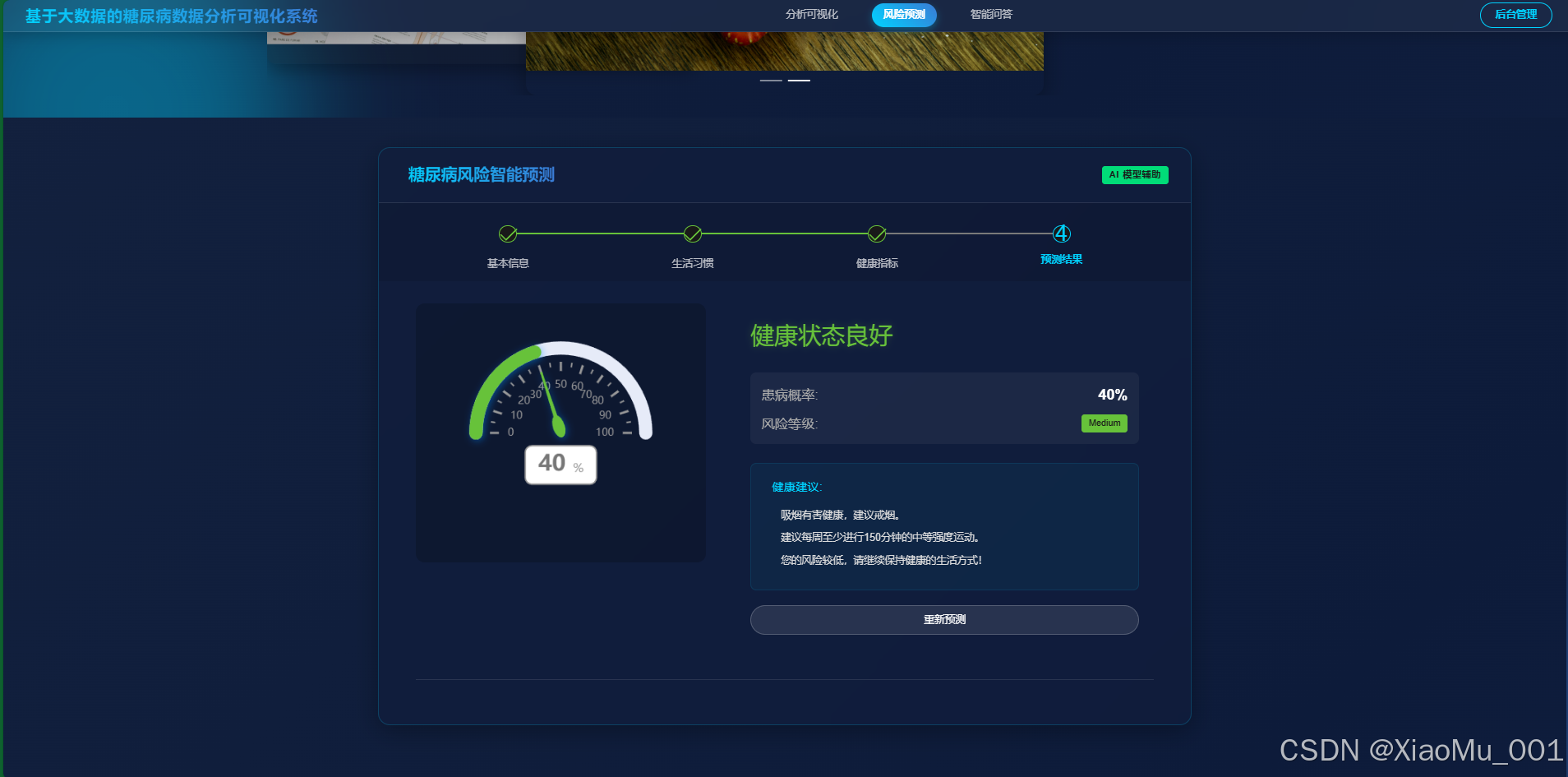
6.5 风险预测 (核心功能)
基于训练好的随机森林模型,用户输入健康指标(如 BMI、血压、年龄等),系统实时计算患糖尿病的风险概率。
-
信息填写 :
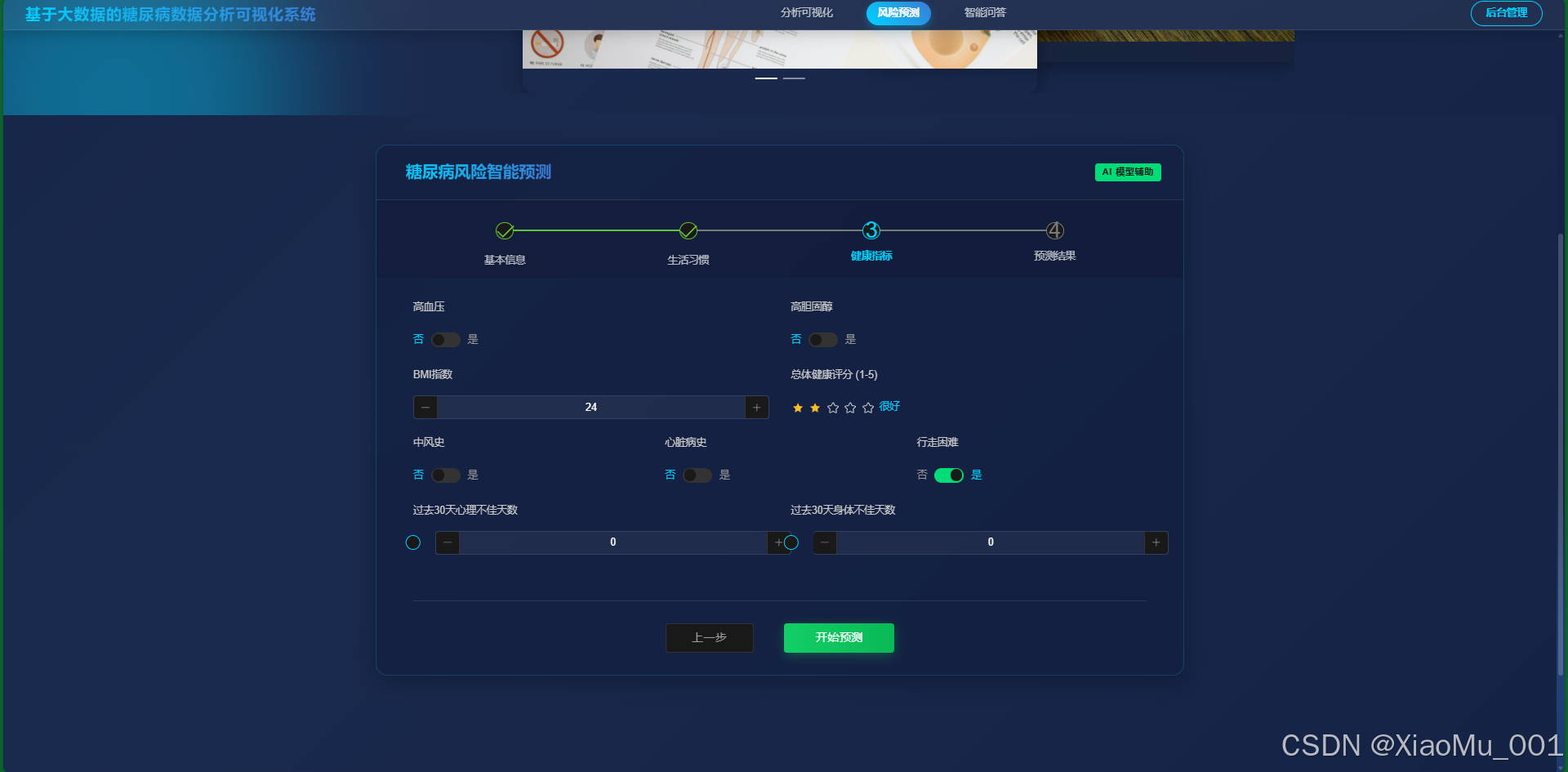
-
结果查看 :
6.6 数据分析与可视化
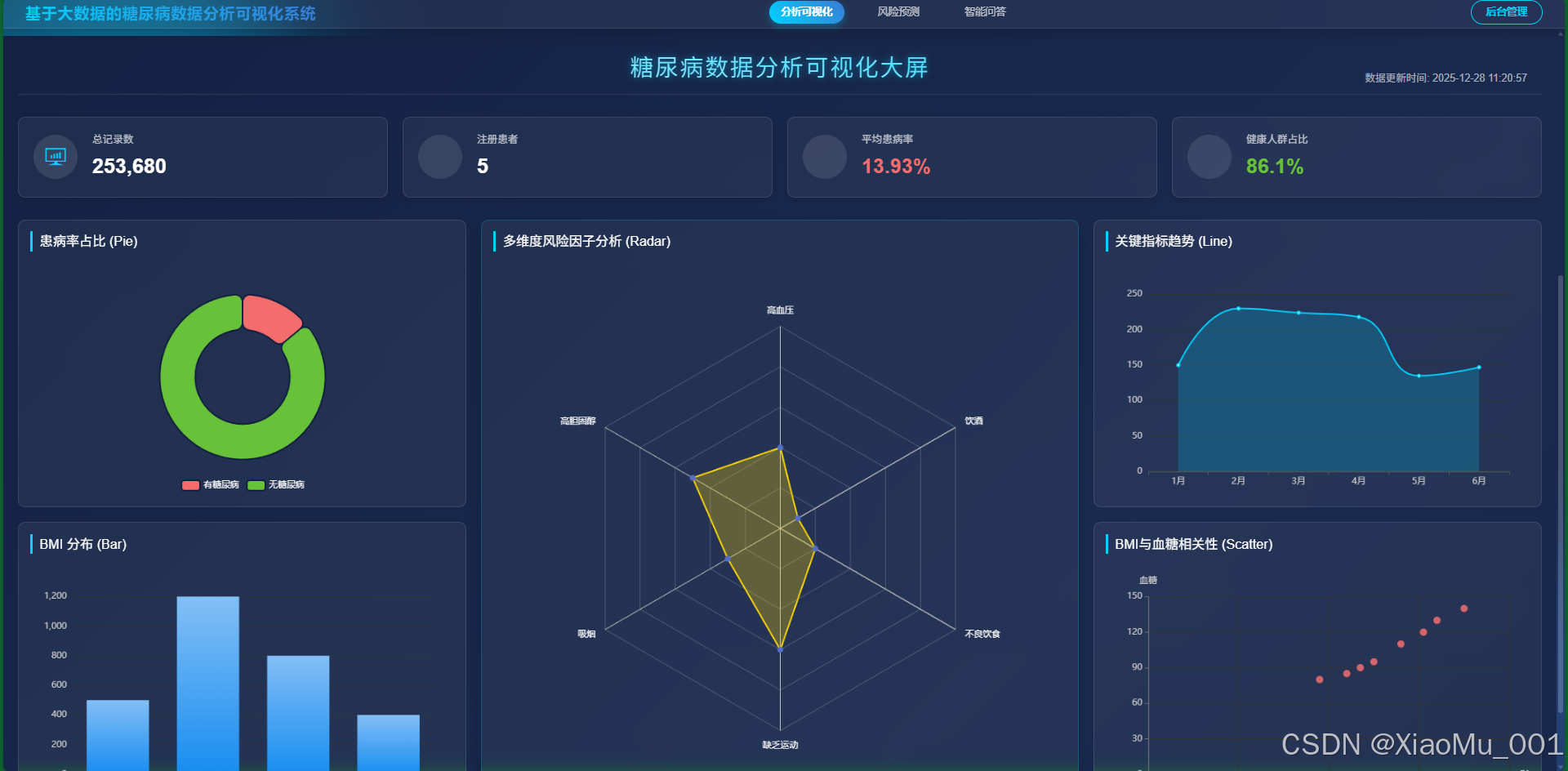
利用 ECharts 对数据库中的海量健康数据进行多维度可视化分析,生成图表。
-
分析可视化 :
-
分析报告 : 生成并查看详细的数据分析报告。
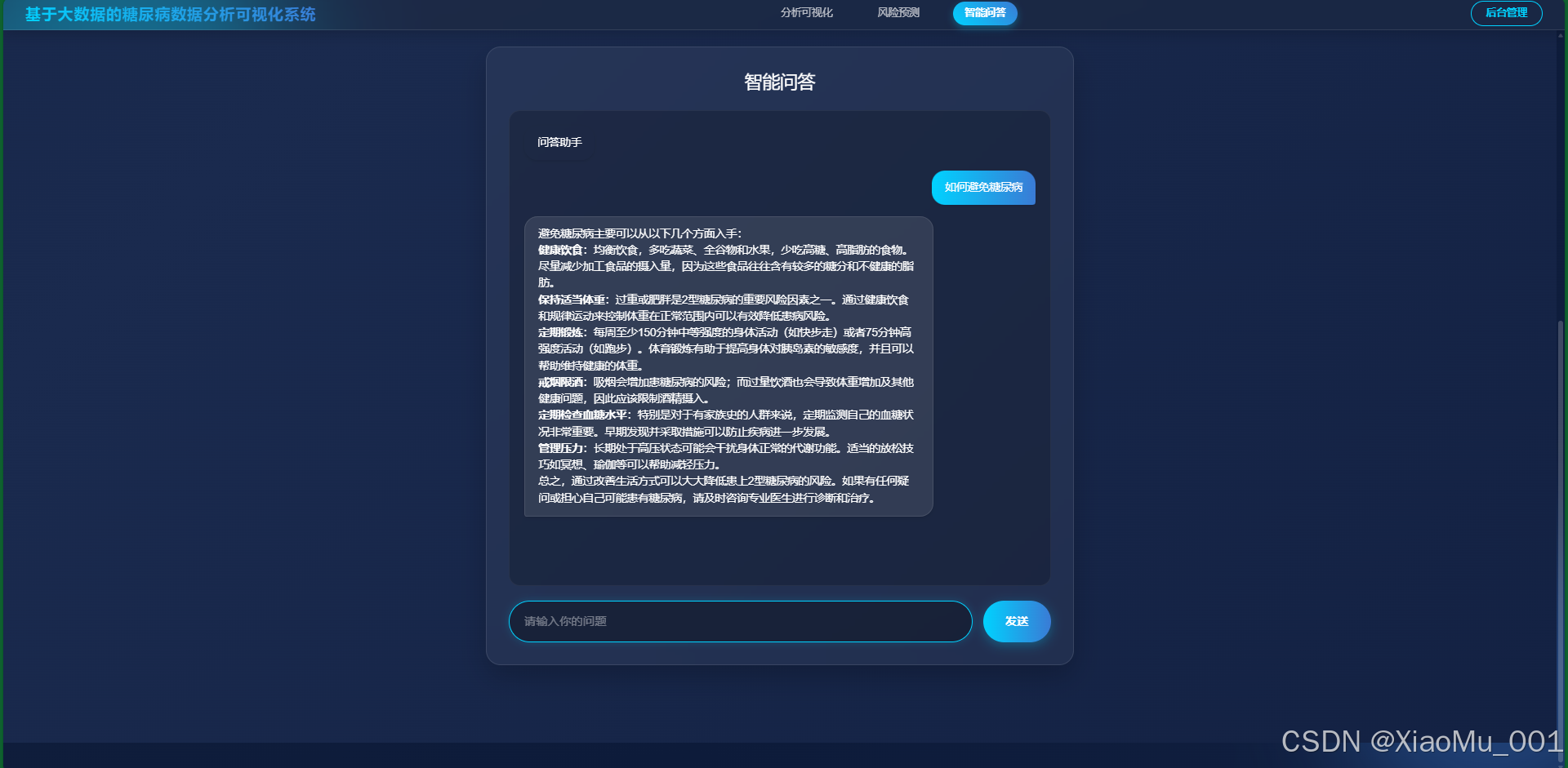
6.7 智能问答
集成 OpenAI 接口,提供关于糖尿病健康知识的智能问答服务。
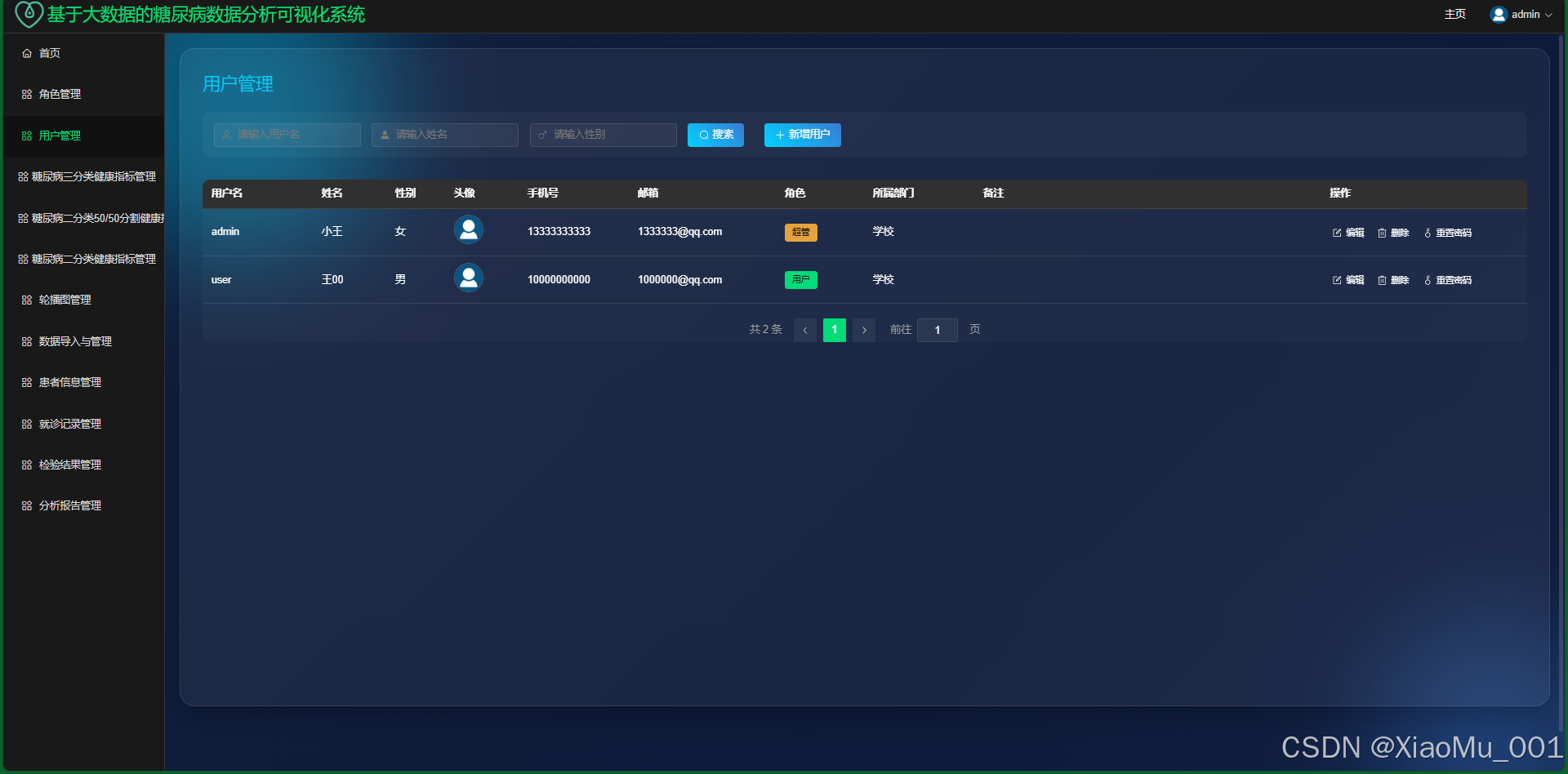
6.8 个人中心与用户管理
-
个人中心 : 用户修改个人信息、密码等。
-
用户管理 : 管理员管理系统用户及权限。
7. 技术实现详解 (Technical Implementation)
7.1 前端性能优化:异步组件加载
为了解决页面跳转卡顿和白屏问题,系统采用了 Vue 3 的 defineAsyncComponent 结合自定义加载策略。
核心代码 (src/router/route.ts):
typescript
const loadComponent = (loader: any) => defineAsyncComponent({
loader,
loadingComponent: AsyncLoading, // 自定义 Loading 组件
delay: 0, // 立即显示 Loading,消除点击后的等待感
timeout: 30000
});原理 :
将路由组件的加载设为异步,并将 delay 设置为 0。这意味着一旦用户点击菜单,系统立即渲染 loadingComponent,而不是等待网络请求或 JS 解析完成。这消除了用户点击后"没反应"的糟糕体验。
7.2 动态路由与权限控制
系统根据用户角色动态生成路由表。在 src/router/controlroutes.ts 中,通过递归遍历后端返回的菜单树,将其转换为 Vue Router 路由配置。
核心代码:
typescript
if (item.component) {
// 动态导入组件
item.component = defineAsyncComponent({
loader: modules[item.component], // 从 import.meta.glob 获取
loadingComponent: AsyncLoading,
delay: 0
});
}7.3 后端数据查询优化
针对千万级/百万级数据表,我们在 models.py 中为常用查询字段(如 Diabetes_binary, HighBP, BMI 等)添加了 db_index=True 索引,显著提升了过滤和排序的查询速度。
python
class DiabetesBinaryHealthIndicatorsBRFSS2015(models.Model):
Diabetes_binary = models.CharField(..., db_index=True)
HighBP = models.CharField(..., db_index=True)
# ...7.4 机器学习模型服务
封装 ModelService 类,实现模型的单例加载(避免每次请求重新加载模型文件)和预测逻辑。使用 joblib 进行序列化存储,确保模型加载速度和预测一致性。
8. 总结
本项目成功构建了一个集数据管理、机器学习预测、可视化分析于一体的糖尿病健康管理平台。通过前后端分离架构和多种优化手段,保证了系统在大数据量下的稳定性和流畅性。