RQ-VAE 的训练过程核心是端到端训练编码器、残差量化器(码本)、解码器,核心逻辑是「编码→多层残差量化→解码→损失回传」,全程围绕 "重构精度 + 量化稳定性" 优化,下面按工业界标准流程拆解,新手也能看懂。
一、训练核心目标
- 让解码器能精准重构输入(靠重建损失);
- 让残差量化器的码本稳定、不崩溃(靠多层承诺损失);
- 让编码器输出的隐向量能被逐层量化(残差逐步逼近 0)。
二、完整训练流程(Step by Step)
前置准备
- 初始化组件:编码器(Encoder)、L 层残差量化器(RQ,含 L 个码本)、解码器(Decoder);
- 超参设定:量化层数 L(常用 4/8/16)、码本大小 K(常用 256/1024)、承诺损失权重 β(0.251.0)、学习率(1e-41e-3);
- 数据准备:输入数据 x(如图像 / 文本 Embedding,归一化到合理范围)。
阶段 1:前向传播(核心计算)

关键细节:
- 每层量化时,通过「计算残差与码本的距离→选最近码字」得到 c_l*;
- 残差 r_l 会逐层缩小(理想情况 r_L≈0),保证量化损失极低。
阶段 2:损失计算(双核心损失)
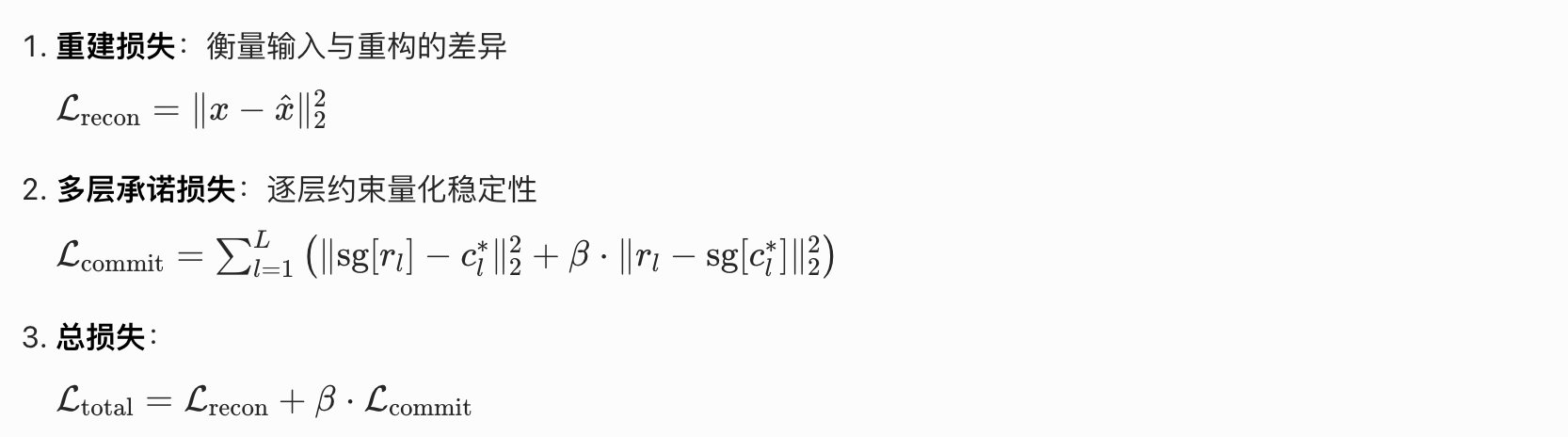
阶段 3:反向传播(梯度更新)
这是 RQ-VAE 训练的关键细节(新手最易踩坑):
- 梯度回传路径 1(更新 Encoder/Decoder):
总损失 → Decoder → z_q → Encoder(注意:c_l * 的梯度被sg\[\]截断,避免码本干扰 Encoder); - 梯度回传路径 2(更新码本):
承诺损失中的||sgr_l - c_l*||²项 → 仅更新第 l 层码本(r_l 的梯度被截断,避免 Encoder 干扰码本); - 优化器:Encoder/Decoder 用 AdamW,码本可单独用小学习率(如 1e-5)更新,防止码本震荡。
阶段 4:训练技巧(防码本崩溃 / 过拟合)

阶段 5:迭代与收敛监控
- 监控指标:
- 重建损失:逐步下降并稳定(如图像 MSE 从 1.0 降到 0.01 以下);
- 码本使用率:所有码字的使用频率≥1%(无码本崩溃);
- 残差大小:最后一层残差 r_L 的均值≈0(量化充分);
- 早停策略:当重建损失连续 10 个 epoch 无下降,或码本使用率稳定,停止训练。
三、训练 vs 推理的核心区别

四、极简 PyTorch 训练伪代码(核心逻辑)
go
# 初始化组件
encoder = Encoder()
decoder = Decoder()
rq = ResidualQuantizer(num_layers=8, codebook_size=256)
optimizer = AdamW(list(encoder.parameters()) + list(decoder.parameters()), lr=1e-4)
codebook_optimizer = AdamW(rq.codebooks.parameters(), lr=1e-5)
# 训练循环
for epoch in range(100):
for x in dataloader:
# 1. 前向传播
z = encoder(x)
z_q, r_list, c_star_list = rq(z) # 输出量化结果、各层残差、各层码字
x_hat = decoder(z_q)
# 2. 计算损失
recon_loss = F.mse_loss(x_hat, x)
commit_loss = 0.0
for r_l, c_l in zip(r_list, c_star_list):
# 逐层计算承诺损失
codebook_loss = torch.norm(r_l.detach() - c_l, p=2) **2
commit_loss_l = torch.norm(r_l - c_l.detach(), p=2)** 2
commit_loss += codebook_loss + 0.25 * commit_loss_l
total_loss = recon_loss + 0.25 * commit_loss
# 3. 反向传播
optimizer.zero_grad()
codebook_optimizer.zero_grad()
# 更新Encoder/Decoder
total_loss.backward(retain_graph=True)
optimizer.step()
# 更新码本(仅codebook_loss部分)
codebook_loss_total = sum([torch.norm(r.detach() - c, p=2)**2 for r,c in zip(r_list, c_star_list)])
codebook_loss_total.backward()
codebook_optimizer.step()
# 4. 监控指标
if step % 100 == 0:
print(f"Epoch {epoch}, Recon Loss: {recon_loss.item():.4f}, Commit Loss: {commit_loss.item():.4f}")总结
- RQ-VAE 训练核心是「编码→多层残差量化→解码→双损失回传」,重点是通过sg\[\]分离 Encoder 和码本的梯度更新;
- 训练关键是防码本崩溃(加均衡正则、预热训练),保证每层残差逐步收敛到 0;
- 推理时仅存储码字索引,大幅降低存储成本,这也是 RQ-VAE 比普通 VAE 更适合落地的核心原因。