1.见一下流式传输
当我们进行传统的LLM调用时,终端会在等待响应时间过后给出我们最终的结果。当我们使用网页版AI调用大模型,再关闭思考模式时,其会给用户以字流的形式给出答案,而不是等待后直接给出所有答案。
这种字流的形式就是流式传输的一种最明显的特征。
python
import os
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model = "deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)
print(model.invoke("帮我写一份关于流式传输的知识的介绍1000字。").content)

2.stream()同步传输
在 LangChain 聊天模型中,可以使⽤其 .stream() ⽅法,来同步⽣成流式响应的效果。
python
import os
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model = "deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)
# print(model.invoke("帮我写一份关于流式传输的知识的介绍1000字。").content)
chunks = []
for chunk in model.stream("帮我讲一个50字的笑话。"):
chunks.append(chunk)
print(chunk.content,end = "|",flush = True) #刷新缓冲区使字在一行输出聊天模型的 .stream() ⽅法返回⼀个迭代器,该迭代器在⽣成输出时同步产⽣输出 消息块
那这个消息块chunk是什么?
调试发现,chunk是⼀个叫做 AIMessageChunk 的东西,它代表 AIMessage 的⼀部分,也就是消息块,这个消息块中的content字段就是LLM返回的信息。

3.astream()异步传输
对于流式传输我们一般会采用异步传输,让cpu资源在某个任务等待时得到充分的使用。
LangChain中的异步传输多为用户掌控传输的形式协议,所以采用的是协程的概念。利用asyncio 、 协程 和 事件循环三者结合实现异步的流式传输。
协程:
作为⼀种轻量级的并发编程模型,可以被视为⽤⼾态的"轻量级线程"。 与传统线程相⽐,协 程的核⼼优势在于其调度完全由⽤⼾空间掌控,避免了操作系统内核的频繁介⼊,从⽽显著降低了上 下⽂切换的开销。
协程是⼀个特殊的函 数,它可以在执⾏过程中暂停,并在稍后恢复执⾏。它⽤ async def 定义,并在需要暂停的地⽅使 ⽤ await 。
事件循环:
事件循环是 asyncio(Python 标准库中的模块,⽤于编写异步 I/O 操作的代码)的核⼼,你可以把它 想象成⼀个总调度员或⼀个⾼效的待办事项 (To-Do List) 管理员。
它的⼯作流程⾮常简单:
- 它维护着⼀个任务列表
- 它不断地循环检查每个任务:
a. 如果任务处于 "等待I/O" 状态,就暂停它,⽴即去执⾏下⼀个 已经 "就绪" 的任务。
b. 如果任务的等待时间到了或者 I/O 操作完成了,事件循环就恢复执⾏这个任务
python
import asyncio
# 定义协程
async def boil_water_async():
print("开始煮⽔...")
await asyncio.sleep(5) # 关键! await 表⽰"等待这个操作完成,但期间让事件循环去做别的事"
print("⽔开了!")
async def send_message_async():
print("开始发短信...")
await asyncio.sleep(2) # 同样,等待2秒,但让出控制权
print("短信发送成功!")
async def main():
# 创建两个任务,并交给事件循环去调度
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
# 等待两个任务都完成
await task1
await task2
# 它负责创建事件循环,并将第⼀个协程(主程序)放⼊其中运⾏。
asyncio.run(main())LangChain可以使⽤ .astream() ⽅法,来异步⽣成流式响应的效果,这专为⾮阻塞⼯作流程⽽设计。可以在 异步代码中使⽤它来实现相同的实时流式处理⾏为。
python
from langchain_openai import ChatOpenAI
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 异步调⽤
async def async_stream():
print("=== 异步调⽤ ===")
async for chunk in model.astream("讲⼀个50字的笑话"):
print(chunk.content, end="|", flush=True)
import asyncio
asyncio.run(async_stream())4.自定义流式输出
前面我们知道LangChain可以将多个组件链起来进行封装使用,当时我们提到过一个输出解析器组件StrOutputParser,它能自动从 AIMessageChunk 中提取内容字段,为 我们提供模型返回的令牌。
我们可以在此基础上自定义输出格式,使流式输出更符合我们的要求。
sream返回的是一个迭代器,我们可以操作该迭代器进行自定义的消息块处理并输出。比如前面的案例的流式输出是一个字token输出,我们可以让其按照一句话一句话进行输出
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from typing import Iterator, List
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出解析器
parser = StrOutputParser()
# 定义⽣成器
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input:
buffer += chunk
while "。" in buffer:
# 只要缓冲区中包含句号,就找到第⼀个句号的位置
stop_index = buffer.index("。")
# 将句号之前的内容(去除⾸尾空格)作为⼀个句⼦放⼊列表中并产出
yield [buffer[:stop_index].strip()]
# 更新缓冲区,保留句号之后的内容
buffer = buffer[stop_index + 1:]
# 产出剩余没有。的字符串
yield [buffer.strip()]
# 定义链
chain = model | parser | split_into_list
for chunk in chain.stream("写⼀份关于爱情的歌词,需要5句话,每句话⽤句号分割"):
print(chunk, end="|", flush=True)5.流式传输原理
LangChain流式传输的完整流程与底层协议
- langchain-openai 包通过集成 OpenAI Python SDK,提供了⼀个 HTTP 客⼾端。
- 因此,⽀持 LangChain 向 OpenAI 的 API 发起Http调⽤请求。
- 若希望发起流式传输请求,则需在请求中加⼊ stream=True ,向 OpenAI 说明以 SSE 协议进⾏ 流式返回。
- LangChain 接收 OpenAI 的 SSE 格式的响应,并将其转换为 LangChain ⾃封装的消息格式,如 AIMessageChunk 消息。这样就可以以统⼀的⽅式处理来⾃不同模型提供商(OpenAI, Anthropic等)的流式响应。
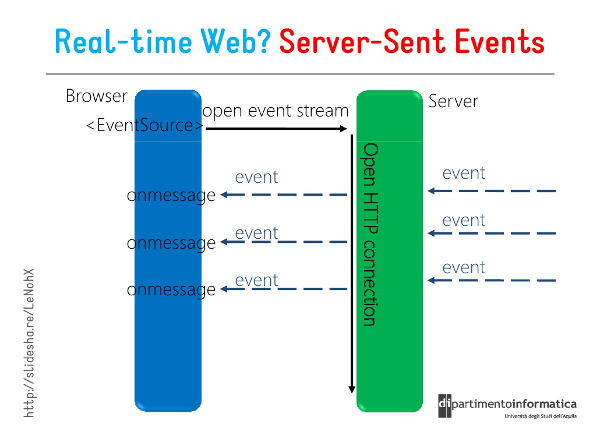
SSE协议
对与客户端与服务端双方的通信常见的两种协议形式:HTTP和WebSocket。
Http无状态协议,当客户端请求来临服务端回复后链接就断开了,无法支持一个请求多次流式回复的单向通信需求。
WebScoket可以实现客户端与服务端的长链接,但这个链接需要服务端进行维护,会占据资源。
基于这个,LangChain等流式传输底层采用的协议为SSE。
SSE(Server-Sent Events)是⼀种基于 HTTP 的轻量级实时通信协议,服务器向客⼾端声明,接下来要发送的是流消息(streaming),这时客⼾端不会关闭连接,会⼀直等待服务器发送过来新的数据流浏览器可以通过内置的 EventSource API 接收并处理这些实时事件。
SSE优势特点:
•
基于 HTTP 协议
复⽤标准 HTTP/HTTPS 协议,⽆需额外端⼝或协议,兼容性好且易于部署。
•
单向通信机制
SSE 仅⽀持服务器向客⼾端的单向数据推送,客⼾端通过普通 HTTP 请求建⽴连接后,服务器可持续
发送数据流,但客⼾端⽆法通过同⼀连接向服务器发送数据。
•
⾃动重连机制
⽀持断线重连,连接中断时,浏览器会⾃动尝试重新连接(⽀持 retry 字段指定重连间隔)。
•
⾃定义消息类型
客⼾端发起请求后,服务器保持连接开放,响应头设置 Content-Type: text/event/stream ,标识为事件流格式,持续推送事件流。