第一阶段:准备工作
1. 硬件确认
你需要一台带 NVIDIA 独立显卡 的电脑(显存 8G 以上,游戏本 / 设计本都行);
如果没有,用 CPU 也能跑,但训练会很慢(不建议,最好找个带显卡的)。
2. 软件安装(按顺序装)
(1)确认 Python 版本
打开命令行(CMD),输入:
python --version
- 装 Ultralytics YOLO(一键式 AI 工具)
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
(3)装 LabelImg(标注工具)
pip install labelImg -i https://pypi.tuna.tsinghua.edu.cn/simple
(4)验证安装成功
输入 yolo predict model=yolov8n.pt source=https://ultralytics.com/images/bus.jpg,如果能看到识别结果,说明 YOLO 装好了;
输入 labelImg,如果能打开一个画图软件,说明标注工具装好了
第二阶段:数据采集与标注
建一个规范的项目文件夹
在电脑里新建一个根文件夹,比如叫 D:\Person_Detect_Project\,然后按下面的结构建好子文件夹(复制文件夹名就行,别乱改):

二、核心第一步:准备教模型的教材(数据采集 + 标注)
这是最关键的一步,你教得越认真,模型认人越准 ,
1. 采集照片(拍你真实场景的无人机照片)
照片要求(直接决定模型效果,一定要按这个来):
- 数量 :至少 500 张起步,越多越好(1000 张以上效果会有质的飞跃)
- 内容 :必须是无人机真实拍的场景 (景区、园区、广场等),别用网上的室内照片,和你实际用的场景不匹配,训了也白训
- 多样性 :
*
*
* 不同高度:10 米、30 米、50 米高空拍的都要有(你平时飞多高就拍多高)
* 不同密度:1-2 个人、十几个人、上百人的密集人群都要有
* 不同环境:晴天、阴天、傍晚、逆光的场景都拍一点
* 不同角度:正拍、斜拍、俯拍都要有 - 格式 :统一用 JPG/PNG 格式,别用特殊格式
照片分配:
拍好的照片,80% 放进 images/train/ 文件夹,20% 放进 images/val/ 文件夹 。比如你拍了 500 张,400 张放 train,100 张放 val。
2. 标注照片(教模型 "这个东西是人")
这一步就是给模型划重点,你框得越准、越全,模型以后认人越准。
标注操作步骤(一步一步跟着做):
- 打开 CMD,输入 labelImg 打开标注工具
- 关键设置(一步都不能错):
- 点击左侧「Open Dir 」,选择你刚才建的 images/train/ 文件夹(打开要标注的照片)
- 点击左侧「Change Save Dir 」,选择 labels/train/ 文件夹(标注好的文件存在这里)
- 点击软件顶部的「PascalVOC 」,点一下切换成 「YOLO」 格式(必须改!不然模型读不了)
- 开始标注:
- 按键盘 W 键,鼠标会变成十字,把照片里的每一个人 都用框完整圈起来(哪怕只露一个头、半个身子,也要框)
- 框完之后,会弹出输入标签的框,统一输入 person (就写这个单词,别写中文、别写错,和官方模型的标签保持一致,你后面的代码不用改)
- 按 Ctrl+S 保存,按 D 键切到下一张,按 A 键回到上一张
- 全部标完 train 文件夹里的照片,再重复上面的步骤,把images/val/里的照片也标完,保存路径选labels/val/。
第 三 阶段 :一键训练你的专属模型(电脑自动跑,不用你管)
标注完了,剩下的事电脑自动做,你只需要复制粘贴代码,点一下运行就行。
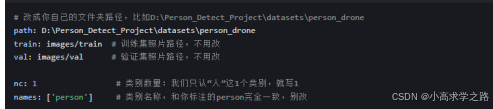
1.写数据集配置文件
在 train_code/ 文件夹里,新建一个文本文件,改名叫 person_drone.yaml,把下面的内容复制进去,路径改成你自己电脑的绝对路径 :
- 写一键训练代码
在 train_code/ 文件夹里,新建一个 Python 文件,叫 train_person.py,把下面的内容复制进去:
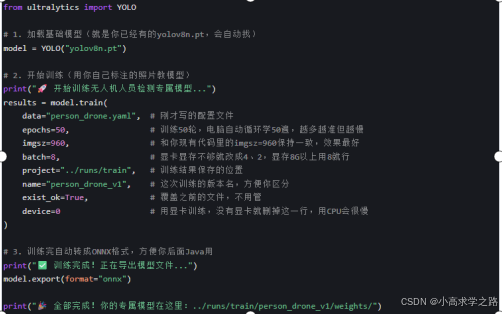
- 开始训练
1.打开 CMD,用cd命令进入到train_code/文件夹,比如:
cd D:\Person_Detect_Project\train_code
 运行训练代码:
运行训练代码:
2.python train_person.py

3.然后你就可以去休息了!
- 显卡好的话,1-2 小时就训完了;用 CPU 的话会很慢,建议找个带 NVIDIA 显卡的电脑。
- 训的过程中,电脑会自动打印进度,不用管它,别关窗口就行。
四、核心第三步:测试你的模型,看认人准不准
训练完成后,会在 runs/train/person_drone_v1/weights/ 文件夹里,生成 2 个核心文件:
· best.pt:这就是你自己训出来的专属模型 (整个流程的核心成果,识别最准的版本)
· last.pt:最后一轮训练的模型,不用管,用 best.pt 就行
现在我们来测试一下,这个模型比官方的好多少:
- 在train_code/里新建一个test_model.py,复制下面的代码
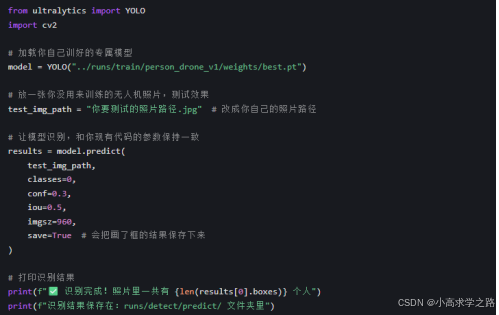
2.运行这个文件,打开生成的结果照片,看看模型是不是把所有的人都框出来了,有没有漏检、误检
五、核心第四步:替换到你现有的 server.py 里,直接用
测试没问题,就可以把你原来的官方模型,换成你自己训的专属模型了,只需要改 1 行代码 !
1. 复制模型文件
把训好的 best.pt 复制到你server.py所在的文件夹里,改个好记的名字,比如 person_drone_v1.pt。
2. 修改你的 server.py 代码
只需要改加载模型的那一行,把原来的:

改成你自己的模型文件:

其他代码完全不用动
你原来的classes=0、conf=0.3这些参数都不用改,因为我们标注的标签就是person,和官方的类别序号完全兼容,改完直接运行就行,识别效果会比原来的官方模型好很多!
- 怎么让模型越来越准?
如果发现模型在某些场景认不准(比如逆光、特别密集的人群),就按这个流程优化:
- 把这些认错 / 漏认的照片收集起来;
- 用 LabelImg 把这些照片标注好;
- 把新的照片和标注文件,加到train/文件夹里;
- 重新运行训练代码,把版本名改成person_drone_v2;
- 训完用新的best.pt替换旧的模型就行。
投喂的高质量场景照片越多,模型对你的业务场景适配度越高,识别就越准
小白常见问题避坑
- 训练的时候报错 "显存不足" :把训练代码里的batch=8改成batch=4,甚至batch=2,越小越省显存。
- 标注完了训练找不到文件 :检查 yaml 里的路径是不是绝对路径,标注格式是不是 YOLO,标签名是不是person。
- 模型识别还是不准 :先看是不是标注漏标、错标了,再补更多对应场景的照片,重新训。
- 训好的模型拷到别的电脑能用吗 :完全可以,把best.pt文件拷过去,改一下路径就能用,不用联网。