上周,全球人工智能与加速计算领域的顶级盛会------NVIDIA GTC 2026 在美国圣何塞圆满举行。连续六年稳居 Gartner 数据库魔力象限"领导者"象限的阿里云瑶池数据库,再次以中国自研数据库代表身份闪耀国际舞台。阿里云资深副总裁、数据库产品事业部负责人李飞飞率队,携多项AI领域前沿技术成果,亮相大会。
通过专题演讲、闭门研讨及深度对话,团队系统展示了阿里云瑶池数据库在支持推理缓存加速、模型推理及智能体(Agent)应用等方面的核心能力,向全球开发者与行业伙伴彰显了中国自研数据库在AI浪潮下的硬核创新实力与全球化技术视野。此次亮相也有力呼应了李飞飞在2025年9月云栖大会所言:"数据与AI大模型的开放融合是大势所趋。面向 Agentic AI 时代,阿里云瑶池数据库正加速迈向新阶段------从云原生数据底座向'AI 就绪'的多模态数据底座全面演进。"

专题演讲:基于全局 KV Cache 存储系统的高效 LLM 推理加速方案
阿里云瑶池数据库团队持续深耕 KVCache 技术,致力于打破大模型推理中的"显存墙",最大化计算与存储资源利用率,为 AI 时代的数据基础设施注入全新动能。目前,阿里云瑶池数据库融合高性能内存数据库 Tair 与云原生数据库 PolarDB 的核心优势,双擎驱动支持 KVCache 能力,构建起面向 AI 原生的智能数据底座。

在 GTC 2026 专题论坛上,阿里云数据库产品事业部资深技术总监张为发表了题为《基于全局 KV Cache 存储系统的高效 LLM 推理加速方案》的主题演讲。他指出,随着大模型参数规模持续攀升,推理阶段的显存压力已成为制约模型部署效率与运营成本的关键瓶颈------尤其在高并发、低延迟的智能体(Agent)应用场景中,性能与可扩展性挑战日益凸显。
针对这一挑战,张为以阿里云 Tair KVCache 为例,系统分享了如何将数据库领域多年沉淀的数据缓存管理能力,创新应用于大模型推理中的 KV Cache 管理。通过将 KV Cache 从计算层解耦并下沉至高性能分布式缓存系统,Tair 实现了与推理引擎、底层硬件及上层应用的深度协同,构建起一套高效的"存算协同"架构。该方案不仅显著缓解显存压力,更大幅提升 LLM 推理吞吐与响应效率,为 AI 原生时代的大规模模型落地提供了坚实的数据基础设施支撑。
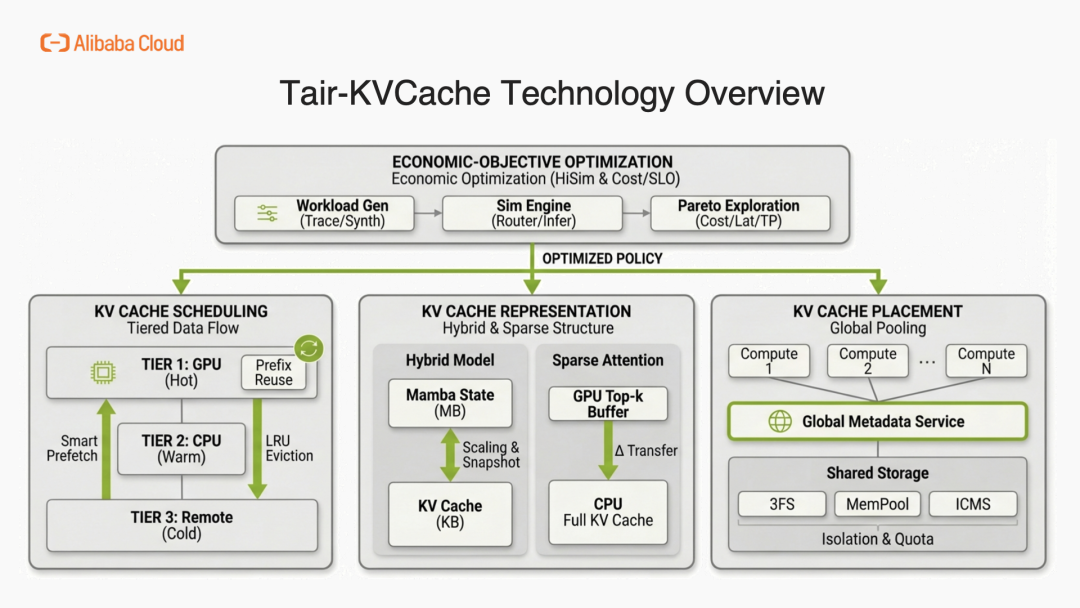
回顾过去一年的技术演进,阿里云数据库 Tair 深度融入开源生态,与合作伙伴共同补齐了 KVCache 解决方案的关键拼图。针对推理链路中的核心痛点,从分层调度、模型支持、存储优化、全局管理及算法创新进行了系统性优化:
KV Cache Scheduling:实现了一套全面的分层数据流方案,利用高度智能的预取技术和基数树前缀复用,在极"热"的 GPU 显存、"温"的 CPU 主机内存以及"冷"的远端存储层之间,实现缓存块的动态路由。
KV Cache Representation:随着注意力机制结构的演进,Tair KVCache 从底层重新设计了内存池,以支持 Mamba 与 Transformer 结合等复杂的混合架构,以及高效的稀疏注意力结构,确保不浪费任何一字节的显存资源。
**KV Cache Placement:**Tair KVCache 正在实现彻底告别孤岛式的单机本地存储,迈向真正的全局池化。通过采用超高速共享存储后端(如 DeepSeek 的 3FS 分布式文件系统),并配合强大的全局元数据服务,实现了真正的存算分离。
**Economic-Objective Optimization:**Tair KVCache 在整套架构之上构建了一个支持多级 KV Cache 模拟的高保真仿真引擎。该引擎持续探索多维帕累托前沿,主动平衡计算成本、存储成本、Token 延迟以及系统吞吐量,从而让我们能够实时应用经济效益最优的管理策略。
此前,业界 KVCache 方案往往局限于单一环节(如仅优化引擎或仅做存储),缺乏统一标准、全局管理及效果评估手段,导致落地困难、成本不可控。
阿里云数据库 Tair KVCache 深度融入开源生态,联合 SGLang 共建 HiCache 以及混合模型架构适配;与阿里巴巴集团 RTP-LLM 开源共建 KVCM 全局池化;与阿里云服务器团队以 3FS 为基座实现高性能远端存储落地;联合 NVIDIA 推出 HiSim 仿真器,将评估成本降低39万倍并精准预测 ROI;与通义实验室联合推出 VLCache 缓存复用框架,显著降低多模态场景显存占用与计算成本.....这一系列成果标志着 Tair KVCache 已从单一缓存组件演进为全链路打通、定义 AI 时代性能边界的存储基础设施,首次实现了从引擎调度、存储底座、元数据管理、仿真评估到算法优化的全链路覆盖。
不仅如此,Tair KVCache 还补齐了行业在标准化、可观测性及经济性评估上的缺失环节,联合清华、字节跳动、腾讯云、华为等业内伙伴,共同推动 KVCache 服务化标准的制定,为 Agent 时代的大模型推理提供了坚实、完整的基础设施底座。
NVIDIA GTC大会汇聚了全球顶尖的AI科学家、工程师与产业领袖,每一个受邀 Session 都经过严苛筛选。这次入选,不仅是对阿里云瑶池数据库在 AI 推理基础设施领域多年积累的高度认可,更标志着中国云计算厂商在全球 AI 底层技术话语权上迈出了关键一步。