ICLR 2025

摘要
视觉 - 语言模型(VLM)是处理和理解文本与图像的强大工具。本文以主流视觉语言模型 LLaVA 为研究对象,探究其语言模型模块中视觉词元的处理机制 。研究重点包括:目标信息的定位、视觉词元表征在各层中的演化规律,以及预测过程中的视觉信息融合机理。通过消融实验发现:移除专属目标词元后,模型的目标识别准确率下降超过 70% 。实验同时观察到:随着层数加深,视觉词元表征在词表空间中变得越来越可解释,说明视觉词元逐渐与图像内容对应的文本词元完成对齐。此外,我们发现模型会在最后一个词元位置,从优化后的表征中提取目标信息用于预测,这一过程与纯文本大模型在事实关联任务中的推理机制高度相似。上述发现揭示了视觉语言模型处理、融合视觉信息的内在规律,缩小了我们对语言模型与视觉模型认知之间的差距,也为构建更可解释、可控制的多模态系统奠定了基础。
1 引言
视觉语言模型(Vision-Language Models, VLMs)以图像和文本作为输入,并输出文本结果。这类模型已成为处理和理解图文信息的强大工具,广泛应用于视觉问答、图像描述等任务(Liu et al., 2023b; Li et al., 2023; Alayrac et al., 2022)。 在各类视觉语言模型架构中,**适配器(adapter)结构**因其简洁性,取得了当前最优的性能。这类模型由三部分构成:预训练图像编码器、预训练语言模型(LM)以及一个可学习的适配器网络。适配器负责将图像编码器的输出映射为软提示,输入到语言模型中(Merullo et al., 2022; Liu et al., 2023a; Liu et al., 2023b)。
尽管视觉语言模型应用广泛、潜力巨大,但相比于纯文本大语言模型,人们对其**内部工作机制仍然知之甚少**。目前,学界对语言模型的机理已有较深入理解(Elhage et al., 2021; Wang et al., 2023; Bricken et al., 2023),对视觉 Transformer 也有一定研究(Palit et al., 2023; Vilas et al., 2023; Pan et al., 2024)。但对于**两种模态共享表征空间**的视觉语言模型,相关机理研究仍存在明显空白。深入理解视觉语言模型,能够推动模型安全、鲁棒性和功能性的提升,类似于语言模型在模型编辑(Meng et al., 2022)、行为溯源(Arditi et al., 2024)等方向取得的进展。
本文聚焦视觉语言模型中的**语言模型模块**展开研究。以 LLaVA 1.5 7B 为例,语言模型部分占模型总参数量的 **95% 以上**。由于具备强大的推理能力,基于海量文本预训练的大语言模型,仍将是未来视觉语言模型的基础。因此,理解语言模型如何处理、融合视觉信息,对提升视觉语言模型的可解释性至关重要。 目前,视觉语言模型仍存在诸多待解问题。首先,输入到语言模型中的视觉表征本质尚不清晰:这些视觉输入属于**软提示**,并不对应常规文本词元,也无法按文本方式解读(Lester et al., 2021; Merullo et al., 2022),视觉信息如何编码在这些表征中仍未知。
其次,图像编码器特征图中的信息空间分布尚不明确:目标细节是局部集中分布,还是弥散在整个表征中,仍有待验证。
此外,语言模型处理视觉输入的内在机制也缺乏研究。图文之间存在显著的**模态鸿沟**(Jiang et al., 2024)。我们不清楚,现有针对纯文本处理的机理结论,是否同样适用于视觉语言模型中的视觉信息处理过程。 为探究视觉语言模型的视觉表征及其处理机制,本文选取主流开源模型 **LLaVA 1.5 7B** 作为研究对象(Liu et al., 2023a)。该模型以 CLIP 作为图像编码器、以 Vicuna 13B 作为语言模型,性能优异。同时,本文还在 LLaVA-Phi 和 Qwen2-VL(Wang et al., 2024)上进行了验证。实验围绕目标识别任务展开,主要贡献如下:
-
基于消融实验证明:物体信息**高度局部化**,集中分布在对应图像空间位置的词元上。
-
拓展原本用于语言模型的 **logit lens(对数透视)技术**,发现:尽管没有显式训练,语言模型中的视觉表征会逐层优化,逐渐对齐词表中可解释文本嵌入。
-
通过阻断词元之间的注意力流动发现:模型会在**中后层**从目标词元中提取物体信息,完成预测。 本文的研究为理解视觉语言模型的内部机理提供了初步基础,也为构建更具可解释性、可控性的多模态系统铺平了道路。
实验代码开源地址:https://github.com/clemneo/llava-interp。
2 基础知识(Background)
Transformer 基础结构 基于 Transformer 的自回归大语言模型(LLM)以一串输入词元为上下文,逐层计算表征,预测下一个词元(Vaswani et al., 2017)。虽然只基于**预测下一词**进行训练(Radford et al., 2019),但在各类 NLP 任务上都取得了顶尖效果(Brown et al., 2020)。 给定输入序列 ,模型输出词表 \\mathcal{V} 上的概率分布,用于预测 x_{n+1}。 每个词元 x_i 首先通过嵌入矩阵
,得到初始嵌入
。之后逐层经过**多头自注意力(MHSA)**和**前馈网络(FFN)**更新: h_i\^{l}=h_i\^{l-1}+a_i\^{l}+f_i\^{l} \\tag{1} 其中: - h_i\^{l}:第 l 层、第 i 个词元的表征; - a_i\^{l}:多头自注意力输出; - f_i\^{l}:前馈网络输出。 **多头自注意力**计算公式:
Q,K,V 由输入线性映射得到;M 为**因果掩码**:右上三角置为 -\\infty,保证每个位置只能看到前面和自己,满足自回归生成约束。多个注意力头输出拼接、线性映射后,得到最终注意力结果。 **前馈网络**包含两层线性变换和中间非线性激活:
其中 W_v\^{l},W_k\^{l},b_k\^{l},b_v\^{l} 为可学习参数,\\sigma 为非线性激活函数。 最后一层末尾词元表征 h_n\^{L},通过反嵌入矩阵 W_U 和 softmax,映射为词表概率分布,完成预测。
图像编码器视觉 Transformer(Dosovitskiy et al., 2021)沿用 Transformer 结构处理图像: 图像划分为固定大小 Patch、展平、线性嵌入,当作一串"视觉词元"输入。 区别: - 视觉编码器使用**双向注意力**(无因果掩码); - 一般包含一个特殊 class token,常用于分类; - 其余位置表征构成图像**特征图**。 在此基础上,CLIP(Radford et al., 2021)采用**图文对比预训练**,同时训练视觉 Transformer 和文本 Transformer,使匹配图文对的嵌入更接近。如今,CLIP 图像编码器广泛用于零样本分类、LLaVA 等主流多模态模型。
图文模型融合方式Tsimpoukelli et al. (2021):训练图像编码器,使其输出可以直接送入**冻结 LLM**,实现多模态少样本推理。 - Merullo et al. (2022):图像编码器、语言模型全部冻结,**只训练一层线性映射(adapter)**,把图像特征对齐成文本模型可接受输入,奠定了现在主流的 **Adapter 架构 VLM**。在上述研究基础上,Liu 等人(2023b)提出了 LLaVA。该模型将 **CLIP ViT-L/14 图像编码器** 与 **Vicuna-13B 语言模型**相结合,并通过一层可训练的线性投影层(或提升性能的 MLP)完成模态对齐(Liu 等人,2023a)。关键在于,LLaVA 仅针对多轮图文对话任务进行微调,**没有在图文配对数据上进行下一词预测预训练**。这种设计既能充分复用视觉模型与语言模型的预训练能力,又能高效适配各类多模态任务。
2.1 符号定义
本节介绍 LLaVA 对图像和查询文本的处理流程。 **图像处理** 输入图像 I 首先被裁剪为正方形并缩放,随后划分为 576 个图像块。CLIP ViT-L/14 图像编码器 f_{\\text{CLIP}} 提取特征,得到特征图: 其中,N=576 为图像块数量,
为 CLIP 嵌入维度。 随后,适配器网络 A 将 CLIP 特征映射到语言模型输入空间,得到**视觉词元**:
我们将 E_A 称为视觉词元,以区分原始图像块词元。 **文本处理与融合输入** 对于文本输入,分词序列
经语言模型嵌入层映射为文本嵌入:
最终输入语言模型的完整序列为视觉嵌入与文本嵌入的拼接:
语言模型基于该序列进行自回归生成。
2.2 研究问题与假设
直观来看,适配器输出 E_A 应当编码图像信息。例如,若图像中存在汽车,适配器生成的词元理应与"汽车"的文本嵌入对齐。但实际上,适配器的输出属于**软提示**,直接通过词表解码无法得到任何语义信息(Merullo 等人,2022;Bailey 等人,2023)。
2.2.1 目标信息的局部分布
本文核心问题:**目标物体信息分布在哪些视觉词元中?** 现有研究存在两种对立假设:
-
**目标局部聚集假设** Joseph 和 Nanda(2024)发现,在传统视觉 Transformer 中,对应物体空间位置的词元,会在深层逐步对齐物体类别嵌入(无需额外训练)。这表明物体信息可能集中分布在图像对应位置的视觉词元中。但该结论仅适用于基于 ImageNet 训练的视觉 Transformer,不适用于 CLIP。
-
**寄存器词元承载全局信息假设** Darcet 等人(2024)在 CLIP 等视觉 Transformer 中发现了**寄存器词元**。这类背景词元具有极高模长,负责编码图像全局特征。据此推测,适配器架构的多模态模型可能主要依靠寄存器词元完成预测。 本文第 3 节将通过目标识别任务的消融实验,验证两种假设。
2.2.2 目标表征的处理机制
视觉词元与文本词元的处理方式存在差异:软提示与普通文本差异显著,且多模态模型存在天然的**模态鸿沟**(Jiang 等人,2024)。此外,LLaVA 仅基于视觉问答数据微调,未进行下一词预训练,这也会影响模型对视觉信息的处理方式。第 4.1 节将采用对数透视法(logit lens)观察视觉表征的逐层演化规律。 现有研究揭示了纯文本模型的信息处理机制:模型遵循**先提纯、后迁移**流程,先通过前馈层提纯主体信息,再通过注意力层迁移到末尾词元(Geva 等人,2023)。算术任务中也观察到类似规律,说明该机制具有通用性。 但多模态场景有所不同。Basu 等人(2024)发现,多模态模型可能**先在文本词元中汇总图像信息**,而非直接从视觉词元迁移到末尾。本文不研究事实关联任务,聚焦更简单的目标识别任务,在第 4.2 节分析视觉词元的信息流动规律。
3 映射视觉词元的表征探究
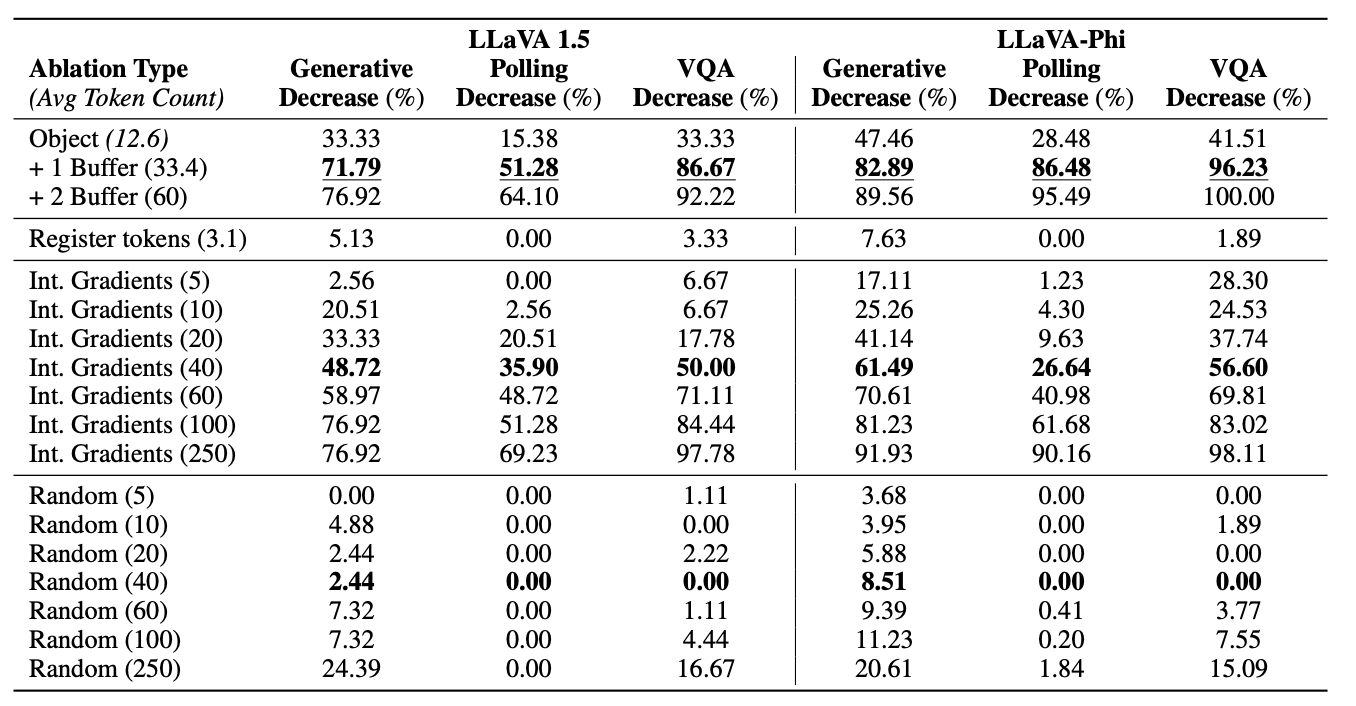
本节通过消融实验,验证物体信息是否集中在特定视觉词元中。通过消融部分词元,观察模型目标识别能力的下降程度,刻画物体信息的分布规律。
数据集 采用 COCO 检测数据集(Lin 等人,2014),并进行两步筛选以保证实验可靠性:
-
**筛选简单图像**:目标面积为 1000~2000 像素(占图像 2%~4%)、单个目标、标注物体少于 4 个;
-
**抑制幻觉干扰**:制作原图和目标加噪掩码图。仅保留"原图识别正确、掩码图识别失败"的样本,确保模型依赖真实视觉信息,而非上下文幻觉。 筛选后最终得到 **4318 张图像**。
实验方法 视觉词元集合为 。选定待消融词元集合
,采用**均值消融**:将目标词元替换为全局平均嵌入,保留模长、保证分布一致,消除特异性信息。 采用三种评估方式:
-
**生成式描述**:输入"描述这张图片",对比消融前后是否提及目标物体;
-
**二元判断**:输入"图中有 物体 吗?",对比消融前后回答是否从"是"变为"否";
-
**视觉问答**:选取 100 张图像设计无歧义问题,固定回答前缀,对比消融后的首生成词。
设置五类消融对照组:
-
**目标原位词元**:消融物体对应图像块的视觉词元;
-
**目标+邻域词元**:增加 1 邻距、2 邻距周边词元;
-
**寄存器词元**:消融模长超出均值 2 倍标准差的全局词元;
-
**随机词元**:随机消融等量词元(基础基线);
-
**高梯度词元**:基于积分梯度算法,消融贡献最高的词元(强基线)。
实验结果 实验结果如表 1 所示。消融**目标原位词元**会显著降低模型的目标识别能力。在消融数量相同的情况下,该组的性能下降幅度远大于梯度基线和随机基线。这证明:**物体信息高度集中在对应空间位置的视觉词元中**。该结论在三种实验设置、LLaVA-1.5 和 LLaVA-Phi 两个模型中均成立。
4 视觉信息处理机制探究
4.1 基于嵌入空间分析残差信息流
视觉词元位置的表征在各层中是如何演化的? 为回答这一问题,本文采用**对数透视法(logit lens)**(Nostalgebraist, 2020):对每一层、每个词元位置的激活值,通过反嵌入矩阵进行解码。形式上,对于第 l 层、第 i 个词元的隐状态 ,利用反嵌入矩阵
将其映射到词表概率分布,并取对数概率最高的词元。本文在 LLaVA 1.5 上开展实验。
**实验结果** 我们发现:在深层中,每个视觉词元位置的激活值,解码出来的词元能够描述该视觉块原本对应的物体类别。
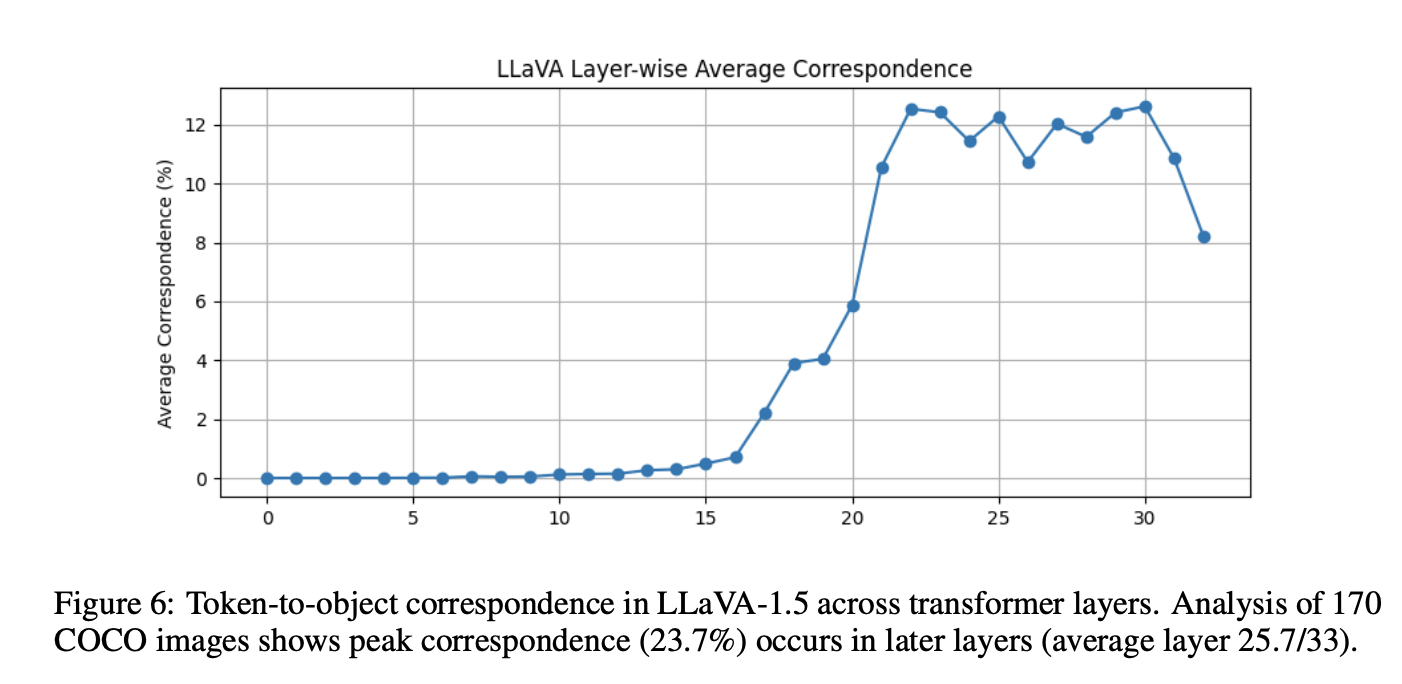
 图 3 给出若干示例,更多例子见交互式演示。 为量化该现象,本文选取 170 张 COCO 验证集图像,目标面积在 20000~30000 像素之间(约占图像宽度的 1/2、高度的 1/3)。
图 3 给出若干示例,更多例子见交互式演示。 为量化该现象,本文选取 170 张 COCO 验证集图像,目标面积在 20000~30000 像素之间(约占图像宽度的 1/2、高度的 1/3)。
实验表明:在效果最优层中,平均有 **23.7%** 的目标块视觉词元能够解码为正确物体类别。最优层平均出现在**第 25.7 层**(共 33 层),说明**中后层**更容易形成最强的物体--词元对齐关系(见图 6)。
同时,解码出的词元往往比基础物体类别**更加细粒度**。例如在图 3a 中,模型不仅识别出毛衣(swe),还能解码出菱形(diam)、十字(cross)等纹理特征。 部分情况下,解码结果还会出现**其他语言**。例如图 3c 中,对应位置解码出中文、韩文的"年""月"。已有研究表明,面向多语言的 LLaMA 在对数透视下中间激活通常偏向英文词元(Wendler et al., 2024),因此该现象具有一定特殊性。 总体而言,对数透视法在多模态模型中依然有效,这一点出人意料。该方法之所以适用于纯文本自回归模型,是因为模型经过下一词预训练,隐状态会逐层逼近最终预测词元的嵌入。但 LLaVA 仅在多模态任务上微调,并无图文预训练。实验有效说明:**Transformer 在词表空间激活语义概念来构建预测**(Geva et al., 2022)这一规律,同样适用于仅做多模态微调的多模态模型。
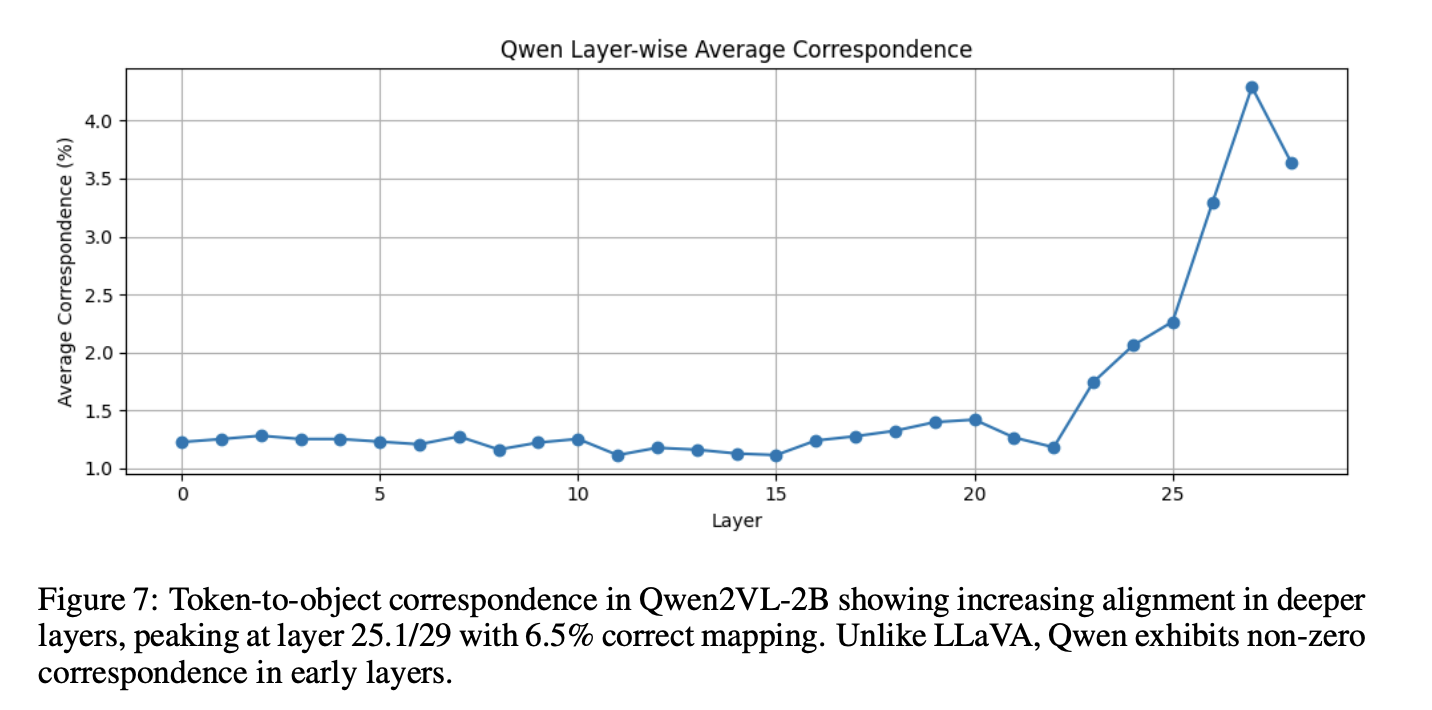 **其他模型验证** 为验证泛化性,本文在 **Qwen2VL-2B** 上重复对数透视实验。分析 253 张 COCO 图像发现:最优层平均有 **6.5%** 的视觉词元对齐正确物体;最优层出现在第 25.1 层(共 29 层),与 LLaVA 的**中后层最优规律一致**(见图 7)。 区别在于:Qwen2VL 在浅层已有一定对齐效果,原因可能是其交叉注意力适配器比 LLaVA 的简单 MLP 适配器初始映射更好。两类模型都呈现"越深层、对齐越强",证明逐层提纯是适配器类多模态模型的共性规律。
**其他模型验证** 为验证泛化性,本文在 **Qwen2VL-2B** 上重复对数透视实验。分析 253 张 COCO 图像发现:最优层平均有 **6.5%** 的视觉词元对齐正确物体;最优层出现在第 25.1 层(共 29 层),与 LLaVA 的**中后层最优规律一致**(见图 7)。 区别在于:Qwen2VL 在浅层已有一定对齐效果,原因可能是其交叉注意力适配器比 LLaVA 的简单 MLP 适配器初始映射更好。两类模型都呈现"越深层、对齐越强",证明逐层提纯是适配器类多模态模型的共性规律。
**案例分析:全局特征** 部分背景词元会意外出现全局信息,例如表示物体数量的数字(见图 3d)。消融这些词元后,模型描述不变,对数透视中的数字仍然存在。说明这类全局特征**更多来自语言模型自身推理**,而非原始视觉信息。这也解释了:为什么基于 CLIP 的多模态模型,分类能力往往弱于原生 CLIP(Zhang et al., 2024)。
**潜在应用** 该对齐规律几乎无需额外计算,即可得到粗略分割图,具备落地价值。例如,Liu 等人(2024)通过增强视觉词元注意力抑制幻觉。我们推测:定向聚焦关键物体词元,可进一步提升去幻觉效果,相关探索留作未来工作。
4.2 追踪注意力流动
为理解视觉信息在语言模型内部如何被处理和融合,本文探究关键信息在网络中的流动路径。具体来说,我们考察:模型是直接从相关视觉词元提取信息,还是先聚合多个视觉词元的信息,再传输到最终输出词元。
实验方法 采用 Geva 等人(2023)提出的注意力阻断方法(attention knockout)。该方法在模型不同层中,选择性阻断某些词元之间的注意力连接,从而判断哪些连接对物体识别最重要。具体步骤如下:
(1) 给定输入和目标层 ℓ,在多头自注意力(MHSA)子层中人工阻断指定注意力路径:将对应注意力掩码置为负无穷:Mrcℓ+1,j=−∞, ∀j∈1,H其中 Mℓ+1,j 表示第 ℓ+1 层、第 j 个注意力头的掩码;r,c 为需要阻断注意力的两个词元下标。
(2) 在多组连续层区间内进行阻断实验,包括:浅层(第 1--10 层)、浅中层(第 5--14 层)、中层(第 11--20 层)、中深层(第 15--24 层)、深层(第 21--31 层)。
(3) 对每组层区间,在三种情形下阻断注意力,并观察正确词元的准确率与预测概率下降幅度:
(i) 从目标词元及其邻域词元 → 最终词元;
(ii) 从所有非目标词元 → 最终词元;
(iii) 从除最后一行外的所有视觉词元 → 最后一行视觉词元。
实验基于 LLaVA 1.5,在本文构建的 100 张图像视觉问答(VQA)数据集上开展。
实验发现
实验结果见表 2。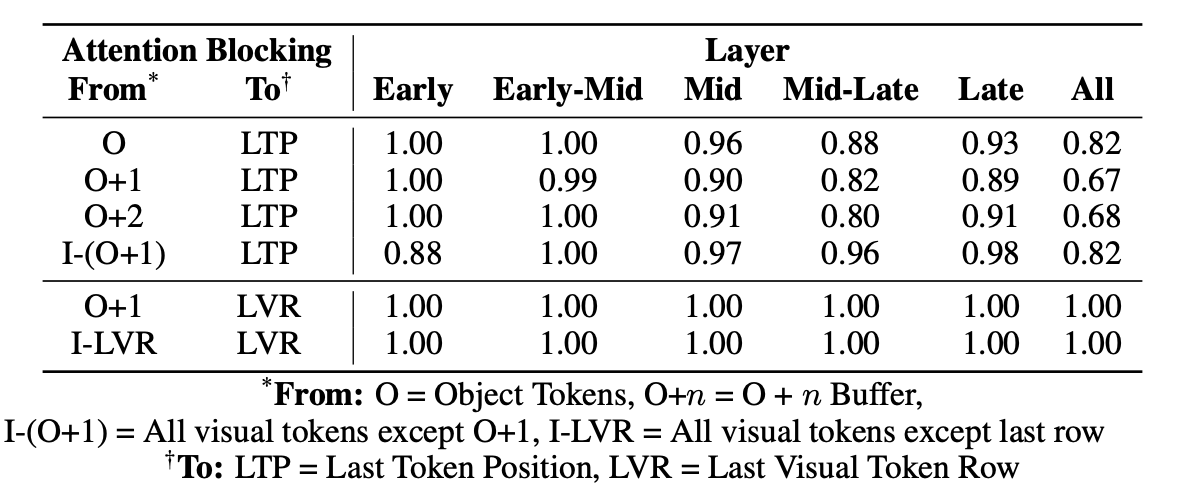
结果表明:在中深层 阻断「目标词元(及其邻域)→ 最终词元」的注意力,会导致性能显著下降。说明模型在后期直接从目标视觉词元提取物体信息 。在浅层 阻断「非目标词元 → 最终词元」的注意力,也会造成一定性能下降。说明更广范围的图像上下文信息,在模型浅层被处理和融合。
有趣的是:阻断「普通视觉词元 → 最后一行视觉词元」的注意力,对性能几乎没有影响。这与 Basu 等人(2024)的结论相反:他们认为模型会先在最后一行视觉词元汇总图像信息,再用于生成。而本文表明:至少在目标识别任务中,模型并不依赖这一步汇总过程。
在其他模型上验证
为验证结果不只适用于 LLaVA‑1.5,本文在 LLaVA‑Phi‑3 上补充实验。不再使用固定分层,而是采用长度为 10 层的滑动窗口,得到更细粒度结果。