概述
键值对NoSQL,或者叫缓存数据库,如果你知道Redis、Memcached、Ehcache,就有些落后时代啦。事实上Memcached和Ehcache,已经落后于时代,新项目一般不太会有开发者考虑使用这两者。参考Redis系列之Ehcache、Memcached、Redis对比。
本文汇总一些旨在叫板(替代、篡位)Redis的开源项目,安装GitHub Star降序排列。
| 项目名称 | GitHub ⭐ | 开发语言 | 核心定位 | 许可证 |
|---|---|---|---|---|
| Dragonfly | ~30.2k | C++ | 现代高性能Redis/Memcached替代 | BSL1.1 |
| Valkey | ~25.2k | C | Redis官方Fork,真正开源 | BSD-3 |
| KeyDB | ~12.5k | C++ | 多线程RedisFork | BSD-3 |
| Garnet | ~11.8k | C# | 微软研究院出品高性能缓存 | MIT |
| DiceDB | ~10.7k | C | 支持查询订阅的低延迟KV引擎 | AGPL-3.0 |
| Redka | ~4.5k | Go | 用SQL(SQLite/PG)实现Redis | BSD-3 |
| ApacheKvrocks | ~4.3k | C++/Go | 基于RocksDB的低成本持久化KV | Apache-2.0 |
| PikiwiDB(Pika) | ~6.1k | C++ | 360出品大容量持久化Redis替代 | BSD-3 |
| Skytable | ~2.7k | Rust | 现代NoSQL,BlueQL查询语言 | AGPL-3.0 |
Dragonfly
官网,由曾任职谷歌、亚马逊,拥有丰富分布式数据库研发经验的Oded Poncz与Roman Gershman联合开源(GitHub,30.2K Star,1.2K Fork),核心聚焦Redis兼容的高性能内存存储,主打低延迟、高吞吐量的KV存储能力。
核心优势在于卓越性能。据官方基准测试,典型工作负载下性能是Redis的25倍,单服务器每秒可处理数百万请求,高并发场景下能高效响应、缩短系统时延;运行时内存消耗比Redis低30%,在资源有限服务器环境中,可依托相同硬件承载更多业务。
兼容Memcached和Redis协议,大幅降低技术迁移的成本与风险。
优势
- 架构级性能碾压:Redis采用多线程IO+单线程执行命令的模式,高并发下仍存在锁竞争与上下文切换开销;Dragonfly基于优化的单线程事件循环模型,配合智能任务调度,高并发读写场景下吞吐量提升2-4倍,延迟降低50%以上,尤其在秒杀、高频计数等场景优势明显。
- 更优的资源利用率:Dragonfly优化内存管理机制,采用增量哈希、压缩存储等技术,相同数据量下内存占用比Redis低15%-30%,支持更大规模数据存储,且CPU利用率更均衡,避免Redis单线程CPU瓶颈问题。
- 原生高可用能力增强:二者均支持RDB持久化与主从复制,但Dragonfly优化主从同步效率,减少数据同步延迟与带宽占用;后续版本将完善原生集群功能,无需依赖第三方工具(如Redis Cluster)即可实现分布式部署。
- 无感知迁移体验:完全兼容Redis协议、数据结构及核心命令,现有Redis客户端(Lettuce、Jedis、Redisson)可直接复用,Spring Boot项目无需修改业务代码,仅需切换数据源地址。
对比
相同点
- 协议与命令:支持Redis绝大多数核心命令(String、Hash、List、Set、Sorted Set等),常用操作(SET、GET、HSET、LPUSH等)完全一致。
- 客户端适配:Spring Data Redis、Redisson等Java客户端可直接集成,无需引入专用客户端依赖。
- 部署与配置:默认端口(6379)、持久化方式(RDB)、主从架构配置与Redis兼容,运维成本低。
差异点
- 冷门命令支持:暂不支持Redis部分冷门命令(如DEBUG、MONITOR、BITOP部分子命令),生产环境需规避或替换为兼容方案。
- 持久化特性:目前仅支持RDB持久化,暂不支持AOF持久化(后续版本将补充),数据安全性要求极高的场景需结合主从复制使用。
- 集群功能:原生集群功能暂未稳定(截至最新版),大规模分布式场景建议先采用主从架构,待集群功能稳定后再升级。
- 性能特性:单实例性能上限更高,无需像Redis那样依赖分片即可支撑更高并发,中小规模场景可减少部署节点数量。
实战
包括服务部署和Spring Boot集成。
部署
支持多种方式:
- 命令行:适用于开发测试
- 安装包:如Windows平台,从GitHub Release页面下载
- Docker
bash
curl -fsSL https://dragonflydb.io/install.sh | bash
# 使用端口6379
sudo systemctl start dragonfly
sudo systemctl status dragonfly
# 基于Docker
docker run -v dragonfly-data:/data --name dragonfly -d docker.dragonflydb.io/dragonflydb/dragonfly
docker run -p 6379:6379 -v dragonfly-data:/data --name dragonfly -d docker.dragonflydb.io/dragonflydb/dragonfly --requirepass my_password指向/etc/dragonfly/dragonfly.conf配置文件。
Spring Boot
引入依赖
xml
<!-- Spring Data Redis核心(自带Lettuce客户端) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>application.yml配置文件示例:
yaml
spring:
redis:
host: 127.0.0.1
port: 6379
password: my-password
database: 0 # 支持0-15共16个数据库
lettuce: # Lettuce客户端连接池配置
pool:
max-active: 16
max-idle: 8
max-wait: 3000ms
shutdown-timeout: 1000ms示例:
java
@Service
public class DragonflyService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void setKey(String key, String value, long expire) {
stringRedisTemplate.opsForValue().set(key, value, expire, TimeUnit.HOURS);
}
public String getKey(String key) {
return stringRedisTemplate.opsForValue().get(key);
}
public void saveUser(String userId, Map<String, String> userInfo) {
stringRedisTemplate.opsForHash().putAll("user:" + userId, userInfo);
}
public Map<Object, Object> getUser(String userId) {
return stringRedisTemplate.opsForHash().entries("user:" + userId);
}
}Valkey
官网,Linux基金会(LF Projects)主导的开源(GitHub,25.2K Star,1.1K Fork)跨平台
亮点:
- 完全兼容Redis协议与客户端,平滑无缝迁移
- 支持可扩展的插件系统(新数据结构、访问模式)
- 支持Cluster、Sentinel高可用、TLS、RDMA等特性
- 社区活跃,AWS、Google Cloud等云厂商背书
KeyDB
官网,开源(GitHub,12.5K Star,652 Fork)。Redis的高性能分支,专注于多线程,内存效率和高吞吐量。还具有仅在Redis Enterprise中可用的功能,如Active Replication,FLASH存储支持、直接备份到AWS S3。官方文档。
KeyDB与Redis协议,模块和脚本保持完全兼容性,包括脚本和事务的原子性保证。由于KeyDB与Redis开发保持同步,KeyDB是Redis功能的超集,可用KeyDB取代现有Redis。
在相同的硬件上,KeyDB每秒可执行的查询数量是Redis两倍,延迟却降低60%。Active-Replication简化热备用故障转移,可轻松地在副本上分配写操作,并使用基于TCP的简单负载平衡/故障转移。
基准测试数据参考官方。
技术原理
线程模型
KeyDB将redis原来的主线程拆分成主线程和worker线程。每个worker线程都是io线程,负责监听端口,accept请求,读取数据和解析协议。如图所示:
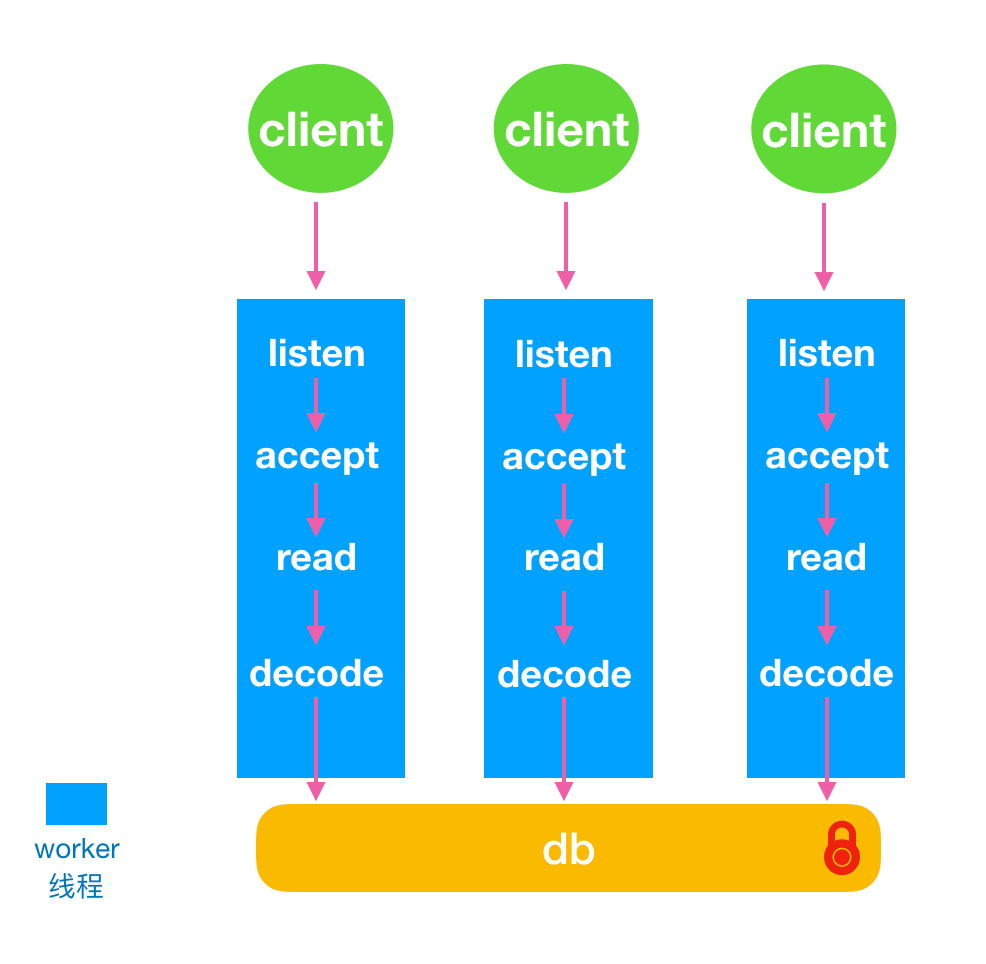
KeyDB使用SO_REUSEPORT特性,多个线程可以绑定监听同个端口。
每个worker线程做CPU绑核,读取数据也使用SO_INCOMING_CPU特性,指定cpu接收数据。
解析协议之后每个线程都会去操作内存中的数据,由一把全局锁来控制多线程访问内存数据。
主线程其实也是一个worker线程,包括了worker线程的工作内容,同时也包括只有主线程才可以完成的工作内容。在worker线程数组中下标为0的就是主线程。
主线程的主要工作在实现serverCron:
- 处理统计
- 客户端链接管理
- db数据的resize和reshard
- 处理aof
- replication主备同步
- cluster模式下的任务
链接管理
在redis中所有链接管理都是在一个线程中完成的。在KeyDB设计中,每个worker线程负责一组链接,所有的链接插入到本线程的链接列表中维护。链接的产生、工作、销毁必须在同个线程中。每个链接新增一个字段用来表示链接属于哪个线程接管。
c
int iel; /* the event loop index we're registered with */KeyDB维护三个关键的数据结构做链接管理:
clients_pending_write:线程专属的链表,维护同步给客户链接发送数据的队列clients_pending_asyncwrite:线程专属的链表,维护异步给客户链接发送数据的队列clients_to_close:全局链表,维护需要异步关闭的客户链接
分成同步和异步两个队列,是因为redis有些联动api,比如pub/sub,pub之后需要给sub的客户端发送消息,pub执行的线程和sub的客户端所在线程不是同一个线程,为了处理这种情况,KeyDB将需要给非本线程的客户端发送数据维护在异步队列中。
同步发送的逻辑比较简单,都是在本线程中完成,以下图来说明如何同步给客户端发送数据
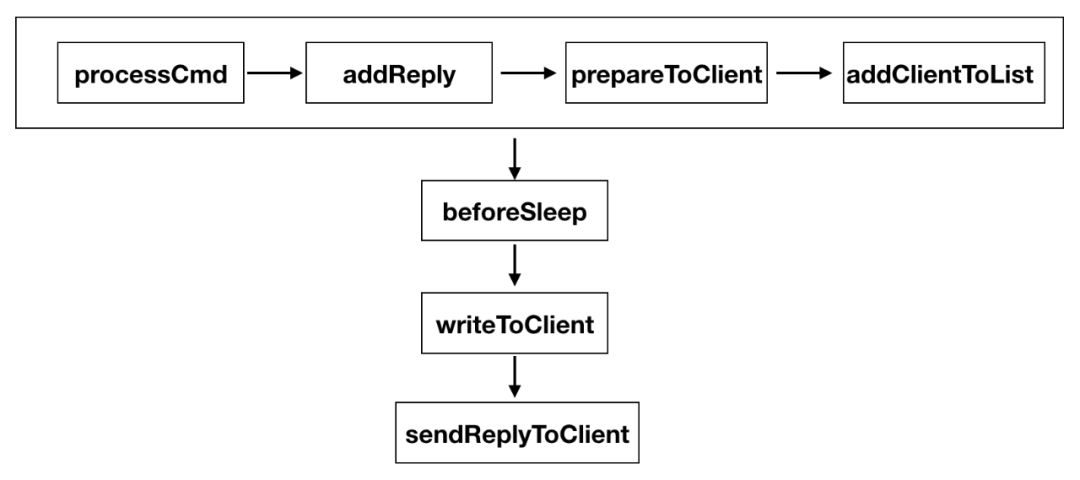
一个链接的创建、接收数据、发送数据、释放链接都必须在同个线程执行。异步发送涉及到两个线程之间的交互。KeyDB通过管道在两个线程中传递消息:
c
int fdCmdWrite; //写管道
int fdCmdRead; //读管道本地线程需要异步发送数据时,先检查client是否属于本地线程,非本地线程获取到client专属的线程ID,之后给专属的线程管到发送AE_ASYNC_OP::CreateFileEvent的操作,要求添加写socket事件。专属线程在处理管道消息时将对应的请求添加到写事件中: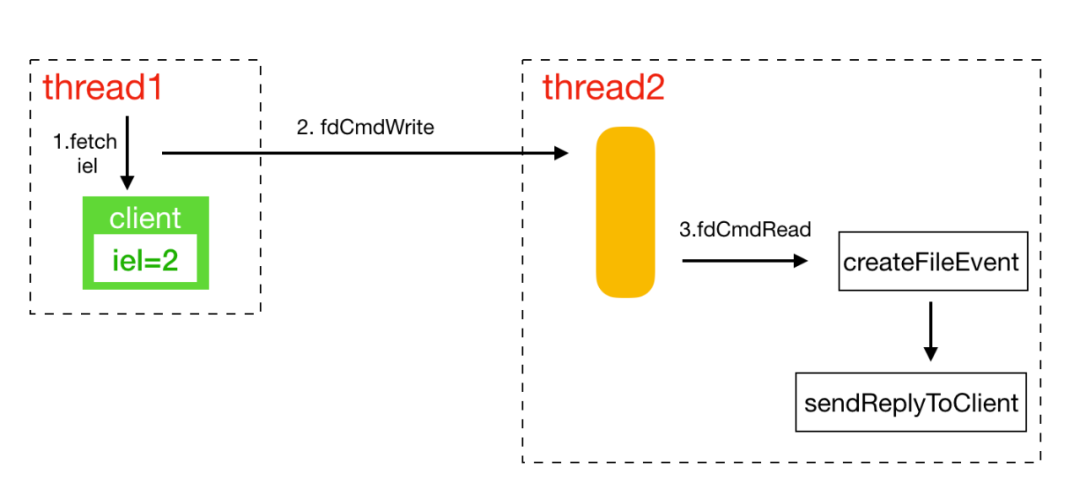
Redis有些关闭客户端的请求并非完全是在链接所在的线程执行关闭,所以得维护一个全局的异步关闭链表。
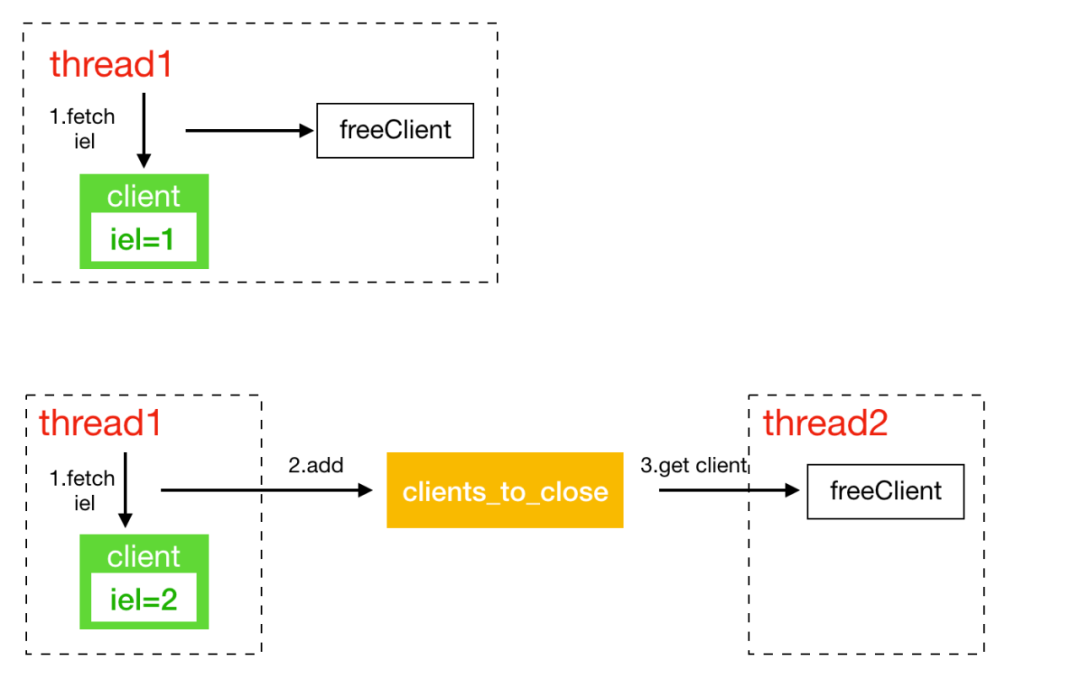
锁机制
KeyDB实现一套类似spinlock的锁机制FastLock,主要数据结构有:
c
struct ticket {
uint16_t m_active; //解锁+1
uint16_t m_avail; //加锁+1
};
struct fastlock {
volatile struct ticket m_ticket;
volatile int m_pidOwner; //当前解锁的线程id
volatile int m_depth; //当前线程重复加锁的次数
};使用原子操作__atomic_load_2,__atomic_fetch_add,__atomic_compare_exchange来通过比较m_active=m_avail判断是否可获取锁。fastlock提供两种获取锁的方式:
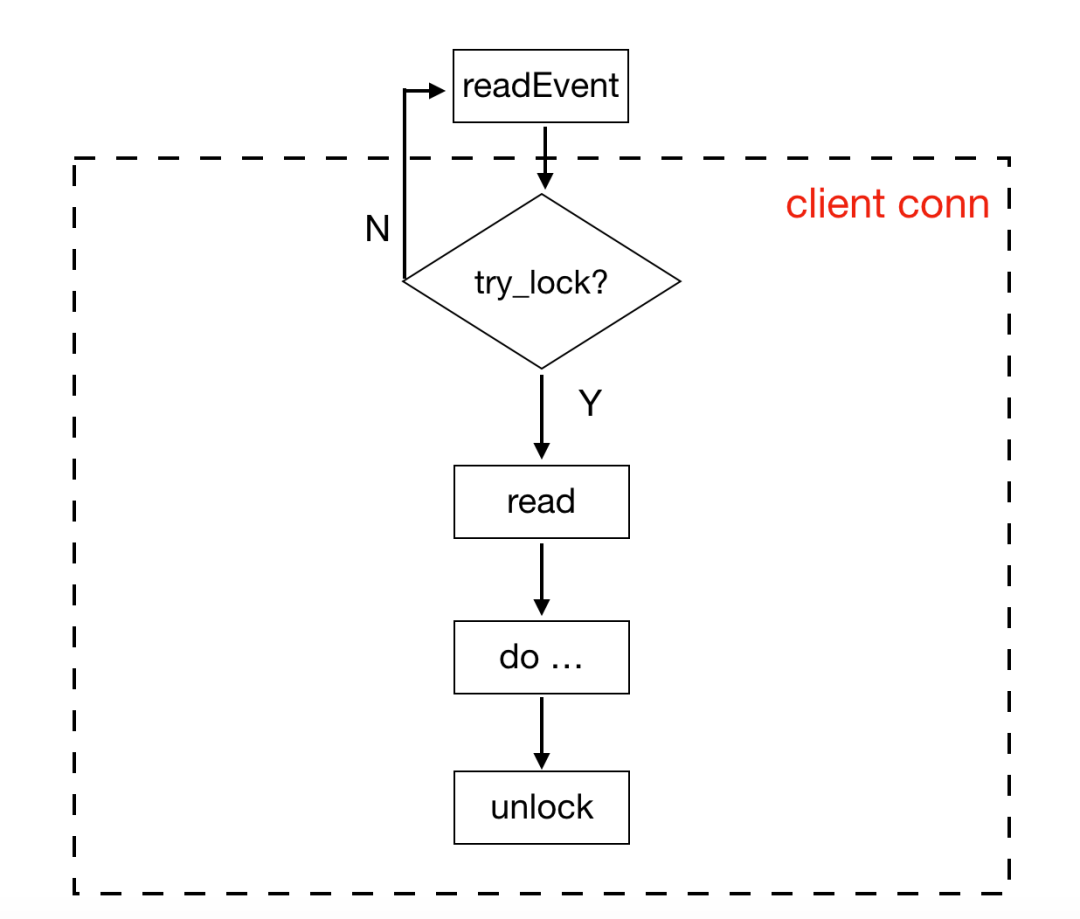
try_lock:一次获取失败,直接返回lock:忙等,每1024*1024次忙等后使用sched_yield主动交出cpu,挪到cpu的任务末尾等待执行。
在KeyDB中将try_lock和事件结合起来,来避免忙等的情况发生。每个客户端有一个专属的lock,在读取客户端数据之前会先尝试加锁,如果失败,则退出,因为数据还未读取,所以在下个epoll_wait处理事件循环中可以再次处理。
KeyDB实现多活机制,每个replica可设置成可写非只读,replica之间互相同步数据:
- 每个replica有个uuid标志,用来去除环形复制
- 新增加rreplay API,将增量命令打包成rreplay命令,带上本地的uuid
- key,value加上时间戳版本号,作为冲突校验,如果本地有相同的key且时间戳版本号大于同步过来的数据,新写入失败。采用当前时间戳向左移20位,再加上后44位自增的方式来获取key的时间戳版本号。
命令
Garnet
微软研究院开源(GitHub,11.8K Star,646 Fork)跨平台基于.NET技术栈,官方文档。
核心亮点:
- 使用RESP协议,兼容所有现有Redis客户端,如
StackExchange.Redis - 超低延迟:P99.9<300μs(Azure加速网络环境)
- 三级存储引擎Tsavorite:内存→SSD→云存储
- 高并发小批量场景下吞吐量优于同类开源缓存
- 支持Lua脚本、集群分片、TLS、模块扩展(C#编写)
DiceDB
官网,开源(GitHub,10.7K Star,1.4K Fork)
核心亮点:
- 基于Valkey构建的低延迟键值存储引擎
- 查询订阅(QWATCH):实时响应数据变化,面向现代实时应用设计
dicedb-spill模块:透明地将被驱逐的键持久化到磁盘(RocksDB后端)- 分层存储:内存与磁盘间自动数据分层,支持超出内存的工作集
- 完全兼容Valkeyj及Redis客户端、工具及SDK
PikiwiDB
360(奇虎)开源(GitHub,6.1K Star,1.2K Fork),现捐献至OpenAtom开放原子开源基金会。
核心亮点:
- 完全兼容Redis协议,支持String/Hash/List/ZSet/Set/Geo/HyperLogLog/Stream等
- 冷热数据分层:热数据缓存、全量数据持久化(RocksDB引擎)
- 支持数百GB级数据量,相比Redis大幅降低服务器资源消耗
- 99.9% GET/SET响应时间小于2ms
- 支持Codis集群模式(弹性扩缩容)
Redka
开源(GitHub,4.5K Star,130 Fork)
核心亮点:
- 用SQL(SQLite或PG)重新实现Redis核心功能的独特思路
- 数据无需全部载入内存,适合资源受限环境
- 支持ACID事务,提供SQL视图便于数据分析与报告
- 两种使用方式:独立服务器(兼容Redis客户端)或Go模块内嵌
- 支持字符串、列表、集合、哈希、有序集合等核心数据结构
- 适合替代Redis测试容器,简化本地开发与集成测试
Apache Kvrocks
官网,开源(GitHub,4.3K Star,618 Fork)
核心亮点:
- Apache顶级项目,由携程捐献,国内生产验证充分
- 基于RocksDB存储引擎,完全兼容Redis协议
- 核心目标:降低内存成本,提升存储容量,节省60%~80%成本
- 支持命名空间,类似Redis
SELECT但隔离更彻底 - 支持异步复制(类似 MySQL binlog)、Redis Sentinel高可用
- 集中式集群管理,可通过任何Redis集群客户端访问
- 支持Linux/macOS,x86_64、ARM、RISC-V架构
Skytable
官网,开源(GitHub,2.7K Star,91 Fork)
核心亮点:
- 纯Rust实现,内存安全保障
- 独特的BlueQL查询语言(基于SQL,防注入攻击)
- 不是Redis兼容协议,而是重新设计的现代NoSQL范式
- 多线程异步I/O+AOF存储引擎,支持延迟持久化事务
- 强制参数化查询,内置安全最佳实践
- 支持Spaces(类似Database)、复杂数据类型与集合