Redis 做缓存时,最经典的读流程是:先查 Redis,命中直接返回;未命中再查 MySQL,然后把结果写回 Redis。
真正麻烦的是写操作。只要 MySQL 的数据变了,Redis 里的旧缓存就可能变成脏数据。所以"Redis 和 MySQL 双写一致性"本质上是在回答一个问题:数据库更新后,缓存到底怎么处理,才能尽量不读到旧数据?
一、先删缓存,还是先改数据库?
常见思路有两个:
- 先删除缓存,再修改数据库。
- 先修改数据库,再删除缓存。
先看"先删缓存,再改数据库"的问题:
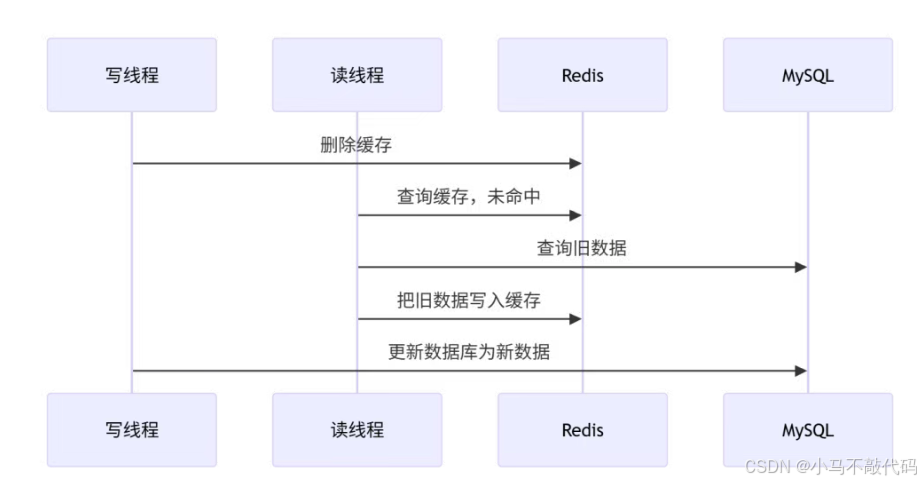
最终结果是 MySQL 已经是新数据,但 Redis 被读线程写回了旧数据,缓存和数据库不一致。
更推荐的基础方案是:先更新数据库,再删除缓存。
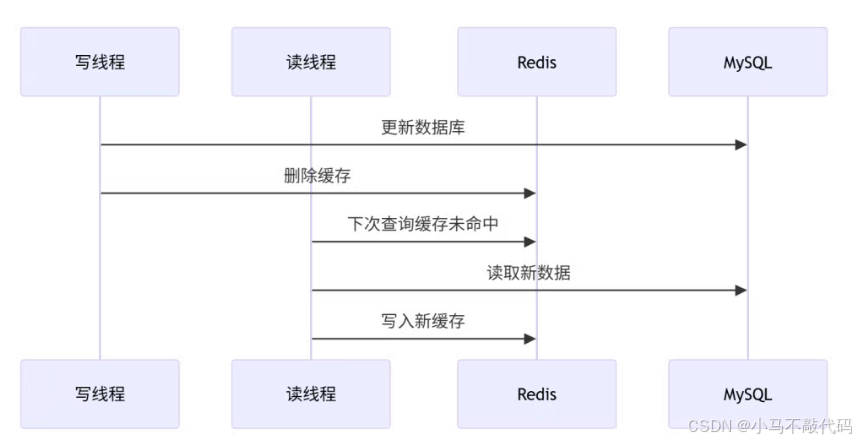
这并不能做到绝对强一致,但发生脏数据的概率更低,是工程里更常见的选择。
二、延迟双删
"延迟双删"。它的流程是:

为什么要删两次?
因为第一次删除是为了让后续读请求不能继续读旧缓存;第二次删除是为了兜住并发读线程把旧数据重新写回缓存的情况。
为什么要延迟?
因为在主从数据库架构下,写入主库后,从库可能还没同步完成。如果读线程从从库读到了旧数据,并把旧数据写入 Redis,第二次延迟删除就能把这份脏缓存清掉。
延迟时间没有固定答案,通常要结合业务读写耗时、主从同步延迟来估计。它的缺点也很直接:代码耦合度高,而且仍然有短暂脏数据风险。
三、强一致场景:读写锁
如果业务对一致性要求很高,比如优惠券库存、余额、订单状态,就不能只依赖延迟双删。
这时可以使用 Redisson 的读写锁:
| 锁类型 | 作用 |
|---|---|
读锁 readLock |
多个读线程可以共享 |
写锁 writeLock |
写线程独占,会阻塞其他读写 |

读写锁的优点是强一致性更好;缺点是性能较低,因为写操作会阻塞读操作,适合一致性优先的关键业务。
四、最终一致场景:MQ 异步通知
如果业务可以接受短时间延迟一致,比如文章热点数据、商品详情页、首页推荐数据,就可以把缓存更新动作异步化。

这个方案的核心是"数据库写成功后发消息,缓存服务消费消息后更新缓存"。它降低了业务代码和缓存逻辑的耦合,但必须保证 MQ 的可靠性,否则消息丢失会导致缓存长期不一致。
五、无侵入方案:Canal 监听 binlog
Canal 的思路更进一步:业务服务只负责写 MySQL,不直接关心缓存。Canal 伪装成 MySQL 的从节点,监听 binlog,再通知缓存服务更新 Redis。

binlog 会记录 DDL 和 DML 语句,不记录 SELECT 这类查询语句。Canal 基于 MySQL 主从同步机制读取变更,因此对业务代码侵入较小。
六、生产级深度分析与 Java 代码示例
6.1 缓存更新策略的深层次权衡
上述方案的选择,本质上是 CAP 理论 在缓存场景下的具体体现:
- 强一致方案(读写锁) :选择了 C(一致性) 和 P(分区容错性) ,牺牲了部分 A(可用性)(写锁阻塞读)。
- 最终一致方案(MQ/Canal) :选择了 AP,通过异步和重试机制,在保证可用性的前提下,最终达到一致性。
另一个关键概念是 缓存模式(Cache-Aside Pattern) 。我们讨论的"先更新数据库,再删除缓存"正是此模式的写策略。其核心思想是:缓存不作为数据的权威来源,数据库才是。所有写操作都直接作用于数据库,缓存只是数据库的"快照视图",需要在数据库变更后失效或更新。
6.2 生产级 Java 代码示例:延迟双删与重试机制
单纯的"先更新数据库,再删除缓存"在分布式环境下并不可靠。删除缓存可能失败,导致脏数据长期存在。生产环境必须引入 重试机制 和 异步化。
以下是一个结合了线程池、异步任务和重试策略的生产级示例:
java
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Service
@Slf4j
@RequiredArgsConstructor
public class CacheConsistencyService {
private final StringRedisTemplate redisTemplate;
private final ItemRepository itemRepository; // 假设的JPA Repository
// 使用线程池执行异步删除任务
private final ExecutorService asyncDeleteExecutor = Executors.newFixedThreadPool(5);
/**
* 生产级更新方案:更新数据库 + 异步延迟双删(带重试)
* @param itemId 商品ID
* @param newStock 新库存
*/
@Transactional
public void updateItemStockWithRetry(Long itemId, Integer newStock) {
// 1. 更新数据库
itemRepository.updateStockById(itemId, newStock);
// 2. 第一次删除缓存(立即)
String cacheKey = "item:stock:" + itemId;
redisTemplate.delete(cacheKey);
log.info("第一次删除缓存成功,key: {}", cacheKey);
// 3. 提交数据库事务后,提交异步延迟删除任务
// 使用事务同步管理器,确保在数据库事务提交成功后才执行
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCommit() {
// 延迟双删的核心:异步执行第二次删除
asyncDeleteExecutor.submit(() -> {
try {
// 延迟一段时间,等待主从同步及可能的脏读完成
TimeUnit.MILLISECONDS.sleep(500); // 延迟时间,根据业务调整
// 第二次删除前,可以再次检查数据库最新值,但通常直接删除
redisTemplate.delete(cacheKey);
log.info("延迟双删第二次删除成功,key: {}", cacheKey);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("延迟双删任务被中断", e);
// 删除失败,进入重试队列
sendToRetryQueue(cacheKey);
} catch (Exception e) {
log.error("延迟双删第二次删除失败,key: {}", cacheKey, e);
sendToRetryQueue(cacheKey);
}
});
}
}
);
}
/**
* 将删除失败的任务发送到重试队列(例如RocketMQ/Kafka)
*/
private void sendToRetryQueue(String cacheKey) {
// 这里可以集成消息队列,发送一个延迟消息
// 例如:rocketMQTemplate.sendDelay("CACHE_DELETE_RETRY_TOPIC", cacheKey, 5, TimeUnit.SECONDS);
log.warn("缓存删除失败,已放入重试队列,key: {}", cacheKey);
// 简单示例:使用一个内存队列,由后台线程重试
RetryQueueHolder.addToRetryQueue(cacheKey);
}
/**
* 更通用的更新方法:先更新数据库,再删除缓存(带异步重试)
*/
public void updateItem(Long itemId, Item newItem) {
// 1. 更新数据库
itemRepository.save(newItem);
// 2. 异步删除缓存,失败重试
String cacheKey = "item:detail:" + itemId;
deleteCacheWithRetry(cacheKey, 3); // 最大重试3次
}
private void deleteCacheWithRetry(String key, int maxRetries) {
asyncDeleteExecutor.submit(() -> {
int retryCount = 0;
while (retryCount < maxRetries) {
try {
Boolean result = redisTemplate.delete(key);
if (Boolean.TRUE.equals(result)) {
log.info("缓存删除成功,key: {}", key);
return;
}
} catch (Exception e) {
log.warn("缓存删除失败,准备重试,key: {}, 重试次数: {}", key, retryCount, e);
}
retryCount++;
try {
// 指数退避重试
TimeUnit.MILLISECONDS.sleep(100 * (long) Math.pow(2, retryCount));
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
break;
}
}
log.error("缓存删除重试{}次后仍失败,key: {}", maxRetries, key);
sendToRetryQueue(key);
});
}
}
// 简单的重试队列持有类
class RetryQueueHolder {
private static final BlockingQueue<String> RETRY_QUEUE = new LinkedBlockingQueue<>();
static {
// 启动一个后台线程处理重试
new Thread(() -> {
while (true) {
try {
String key = RETRY_QUEUE.take();
// 这里可以重新调用删除逻辑,或发送告警
System.err.println("处理重试删除: " + key);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}).start();
}
public static void addToRetryQueue(String key) {
RETRY_QUEUE.offer(key);
}
}代码要点解析:
- 事务一致性 :使用
TransactionSynchronizationManager.registerSynchronization确保缓存删除操作在数据库事务提交成功之后执行,避免事务回滚导致缓存被误删。 - 异步化:使用独立线程池执行缓存删除,避免阻塞主业务线程,提升响应速度。
- 延迟双删实现 :在
afterCommit回调中提交一个延迟任务,实现第二次删除。 - 重试机制:对删除操作进行指数退避重试,并将最终失败的任务送入重试队列,防止因网络抖动导致的单次失败。
- 可观测性:通过日志记录关键步骤,便于问题排查。
6.3 读写锁的进阶用法与 Redisson 最佳实践
对于强一致性场景,直接使用读写锁可能成为性能瓶颈。Redisson 提供了更丰富的分布式锁和对象,例如 RReadWriteLock。生产环境中,还需要考虑锁的粒度、超时时间和看门狗机制。
java
import org.redisson.api.RLock;
import org.redisson.api.RReadWriteLock;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
import java.util.concurrent.TimeUnit;
@Service
@RequiredArgsConstructor
public class InventoryServiceWithLock {
private final RedissonClient redissonClient;
private final InventoryRepository inventoryRepository;
/**
* 使用读写锁保证库存扣减的强一致性
*/
public boolean deductStockWithLock(Long itemId, Integer quantity) {
String lockKey = "inventory_lock:" + itemId;
RReadWriteLock rwLock = redissonClient.getReadWriteLock(lockKey);
RLock writeLock = rwLock.writeLock();
try {
// 尝试获取写锁,最多等待3秒,锁持有时间10秒(看门狗会自动续期)
if (writeLock.tryLock(3, 10, TimeUnit.SECONDS)) {
try {
// 1. 查数据库最新库存
Inventory inventory = inventoryRepository.findById(itemId).orElseThrow();
if (inventory.getStock() < quantity) {
return false; // 库存不足
}
// 2. 更新数据库
inventory.setStock(inventory.getStock() - quantity);
inventoryRepository.save(inventory);
// 3. 删除或更新缓存(在写锁保护下,读请求被阻塞,所以可以安全更新)
String cacheKey = "inventory:stock:" + itemId;
// 方案A:直接删除缓存,让后续读请求回源到已更新的数据库
// redisTemplate.delete(cacheKey);
// 方案B:同步更新缓存为最新值(更激进的一致性)
// redisTemplate.opsForValue().set(cacheKey, inventory.getStock().toString());
// 这里选择删除,遵循Cache-Aside模式
redissonClient.getBucket(cacheKey).delete();
return true;
} finally {
writeLock.unlock();
}
} else {
// 获取锁失败,可能是系统繁忙或死锁
log.error("获取库存写锁失败,itemId: {}", itemId);
throw new RuntimeException("系统繁忙,请稍后重试");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("操作被中断", e);
}
}
/**
* 读库存(使用读锁)
*/
public Integer getStockWithLock(Long itemId) {
String lockKey = "inventory_lock:" + itemId;
RReadWriteLock rwLock = redissonClient.getReadWriteLock(lockKey);
RLock readLock = rwLock.readLock();
readLock.lock(); // 读锁是共享的,不会阻塞其他读请求
try {
// 1. 先查缓存
String cacheKey = "inventory:stock:" + itemId;
String cachedStock = (String) redissonClient.getBucket(cacheKey).get();
if (cachedStock != null) {
return Integer.parseInt(cachedStock);
}
// 2. 缓存未命中,查数据库
Inventory inventory = inventoryRepository.findById(itemId).orElseThrow();
// 3. 写回缓存
redissonClient.getBucket(cacheKey).set(inventory.getStock().toString());
return inventory.getStock();
} finally {
readLock.unlock();
}
}
}生产级考量:
- 锁粒度:锁的 key 应尽可能细粒度(如按商品ID),避免锁住整个库存表。
- 锁超时 :必须设置合理的
tryLock等待时间和锁自动释放时间,防止死锁。 - 看门狗 :Redisson 的锁默认有看门狗机制(
lockWatchdogTimeout),会自动续期,防止业务执行时间过长导致锁过期。 - 缓存更新策略 :在写锁保护下,可以选择 删除缓存 或 同步更新缓存。前者更简单,遵循 Cache-Aside;后者能避免后续一次缓存穿透,但需要确保更新缓存的操作绝对可靠。
6.4 基于消息队列的最终一致性架构
对于 MQ 方案,生产环境的核心是保证消息的 可靠性投递 和 幂等消费。
java
// 生产者端:在数据库事务提交后发送消息
@Service
@RequiredArgsConstructor
public class CacheUpdateProducer {
private final RocketMQTemplate rocketMQTemplate;
@Transactional
public void updateProduct(Product product) {
// 1. 更新数据库
productRepository.save(product);
// 2. 发送缓存失效消息(事务消息确保一致性)
String topic = "CACHE_INVALIDATE_TOPIC";
String cacheKey = "product:detail:" + product.getId();
Message<String> message = MessageBuilder.withPayload(cacheKey)
.setHeader(MessageConst.PROPERTY_DELAY_TIME_LEVEL, "2") // 可选:延迟消息,模拟延迟双删
.build();
rocketMQTemplate.sendMessageInTransaction(topic, message, null);
}
}
// 消费者端:监听并删除缓存,保证幂等性
@Service
@RocketMQMessageListener(topic = "CACHE_INVALIDATE_TOPIC", consumerGroup = "CACHE_INVALIDATE_GROUP")
@Slf4j
public class CacheInvalidateConsumer implements RocketMQListener<String> {
private final StringRedisTemplate redisTemplate;
// 使用Redis或本地缓存记录已处理的消息ID,实现消费幂等
private final Cache<String, Boolean> processedMessageCache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10000)
.build();
@Override
public void onMessage(String cacheKey) {
// 幂等检查:模拟基于消息唯一ID(此处用cacheKey简化)
if (processedMessageCache.getIfPresent(cacheKey) != null) {
log.info("消息已处理,跳过,key: {}", cacheKey);
return;
}
try {
Boolean deleted = redisTemplate.delete(cacheKey);
log.info("消费消息,删除缓存{},结果: {}", cacheKey, deleted);
// 标记为已处理
processedMessageCache.put(cacheKey, true);
} catch (Exception e) {
log.error("消费消息删除缓存失败,key: {}", cacheKey, e);
// 消息重试机制由RocketMQ自身保障
throw new RuntimeException(e); // 抛出异常,触发重试
}
}
}关键设计:
- 事务消息:确保数据库更新和消息发送的原子性(要么都
七、方案对比与选型指南
| 方案 | 一致性强度 | 性能影响 | 复杂度 | 适用场景 | 生产级考量 |
|---|---|---|---|---|---|
| 先更新DB,再删除缓存 | 最终一致(概率低) | 低 | 低 | 对一致性要求不苛刻的普通业务 | 必须配合重试机制,防止删除失败 |
| 延迟双删 | 最终一致(概率更低) | 中(有延迟) | 中 | 主从架构,对短暂不一致敏感的业务 | 延迟时间需压测确定,代码耦合,需异步化 |
| 读写锁 (Redisson) | 强一致 | 高(写锁阻塞读) | 高 | 库存、余额、秒杀等强一致性场景 | 注意锁粒度、超时、看门狗,避免死锁和性能瓶颈 |
| MQ 异步通知 | 最终一致(可靠) | 低(异步) | 中 | 文章、商品详情等可接受秒级延迟的场景 | 保证消息可靠投递与幂等消费,监控消息堆积 |
| Canal (CDC) | 最终一致(可靠) | 低(异步,无业务侵入) | 高 | 架构清晰,希望业务与缓存解耦的大型系统 | 部署和维护成本高,需保证Canal集群高可用 |
选型决策树:
- 业务是否要求强一致?
- 是 → 选择 读写锁。评估性能压力,考虑锁粒度优化。
- 否 → 进入第2步。
- 业务架构是否复杂,希望解耦?
- 是 → 选择 Canal (如果团队有运维能力)或 MQ 异步通知。
- 否 → 进入第3步。
- 是否有主从延迟问题?
- 是 → 选择 延迟双删(配合异步重试)。
- 否 → 选择 先更新DB,再删除缓存(必须带重试)。
八、总结与最佳实践
- 没有银弹:缓存一致性方案是权衡的艺术,需要在一致性、性能、复杂度之间取得平衡。
- 重试是必须的:任何涉及网络的操作(删除缓存、发送消息)都必须有重试机制,最好配合死信队列或报警。
- 监控与对账:建立缓存与数据库的定期对账任务,及时发现不一致并告警。监控缓存命中率、删除失败率、消息延迟等关键指标。
- 降级策略:在缓存系统或一致性组件(如Canal、MQ)故障时,要有降级方案(如直接读库),保证核心业务流程可用。
- 代码抽象 :将缓存更新/失效的逻辑抽象成统一的组件或切面(AOP),避免业务代码中散落着各种
redisTemplate.delete(),便于维护和切换方案。
面试点睛:当被问到"如何保证Redis和MySQL双写一致性"时,可以按以下层次回答:
- 先摆出核心矛盾:介绍Cache-Aside模式下的写策略选择(先删缓存还是先更新数据库)。
- 分层阐述方案 :从简单的"先更新数据库,再删除缓存"开始,谈到其缺陷,引出延迟双删 来应对并发场景和主从延迟。然后区分场景:对强一致需求,介绍分布式读写锁 ;对最终一致且希望解耦,介绍MQ异步通知 和Canal监听binlog。
- 体现生产思维 :强调任何方案在生产环境都必须配套重试、监控、降级机制。可以简要提及你在项目中如何实现重试(如线程池、Spring Retry)和幂等(如Redis setnx、消息唯一ID)。
- 总结与选型:最后给出一个清晰的选型建议表格,并说明你会根据业务的一致性要求、团队技术栈和运维能力来做出选择。
通过以上深度分析和生产级代码示例,你不仅理解了各种方案的理论,也掌握了如何将它们落地到真实的Java项目中。记住,架构设计离不开具体的业务上下文,最好的方案永远是最适合当前业务发展阶段的那一个。