文章目录
- [一、问题背景:为什么 Redis 单独搞不定这件事](#一、问题背景:为什么 Redis 单独搞不定这件事)
- [二、分页:为什么首选 ZSet](#二、分页:为什么首选 ZSet)
-
- [2.1 ZSet 的核心指令](#2.1 ZSet 的核心指令)
- [2.2 分页代码示例](#2.2 分页代码示例)
- [2.3 ZSet 相比 List 的优势](#2.3 ZSet 相比 List 的优势)
- [2.4 深翻页的隐藏代价](#2.4 深翻页的隐藏代价)
- [三、多条件模糊查询:基于 Hash 与 HSCAN](#三、多条件模糊查询:基于 Hash 与 HSCAN)
-
- [3.1 思路:把条件字段编码进 field](#3.1 思路:把条件字段编码进 field)
- [3.2 为什么坚决不用 `KEYS`](#3.2 为什么坚决不用
KEYS) - [3.3 模式匹配的局限](#3.3 模式匹配的局限)
- [3.4 渐进式扫描的代码模板](#3.4 渐进式扫描的代码模板)
- 四、组合方案:把分页和模糊查询拼在一起
-
- [4.1 总体思路](#4.1 总体思路)
- [4.2 数据结构设计](#4.2 数据结构设计)
- [4.3 关键代码](#4.3 关键代码)
- [4.4 这套方案带来的收益](#4.4 这套方案带来的收益)
- 五、生产环境必须考虑的工程问题
-
- [5.1 缓存膨胀:匹配串爆炸](#5.1 缓存膨胀:匹配串爆炸)
- [5.2 数据一致性:写入与索引怎么同步](#5.2 数据一致性:写入与索引怎么同步)
- [5.3 大 Key 风险](#5.3 大 Key 风险)
- [5.4 扫描期间的雪崩](#5.4 扫描期间的雪崩)
- [5.5 排序与稳定性](#5.5 排序与稳定性)
- 六、什么时候不该用这套方案
- [七、与 RediSearch 的对照](#七、与 RediSearch 的对照)
- 八、把方案串成一张工程图
- 九、结语
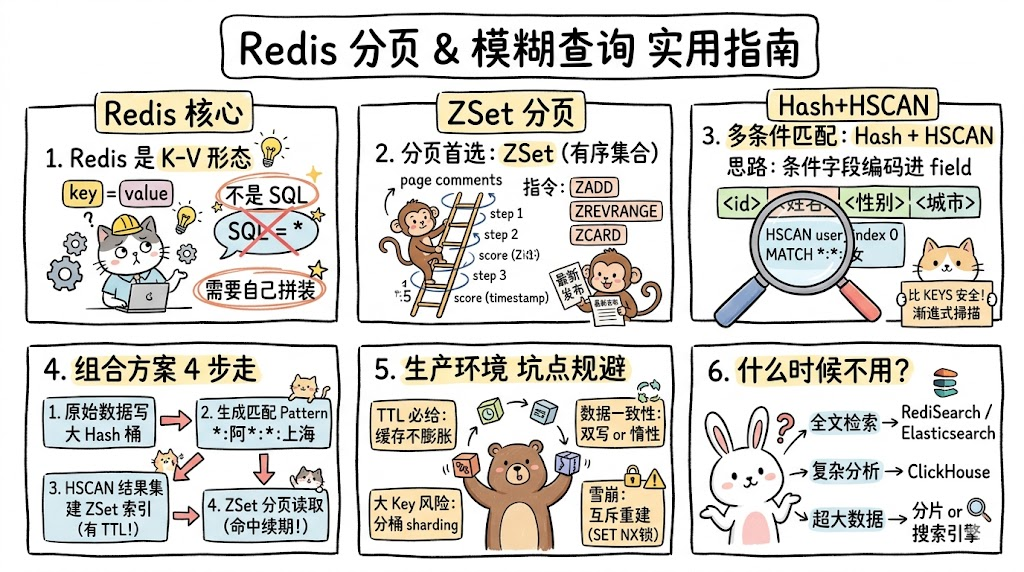
一、问题背景:为什么 Redis 单独搞不定这件事
在大多数业务里,分页和模糊查询本身是再普通不过的需求。挑出第 3 页、每页 20 条、姓"阿"的女性用户------放在 MySQL、Oracle 里,一行 SQL 就能解决。但当数据先落在 Redis 这种缓存层、甚至完全只存在于 Redis 里时,事情就没那么简单。
Redis 是一个 key-value 形态的内存数据库,原生指令围绕 GET/SET、List、Set、Hash、ZSet 展开,并没有提供类似 WHERE name LIKE '阿%' AND gender = '女' ORDER BY created_at DESC LIMIT 40, 20 的语义。要在 Redis 里同时满足"分页"和"多条件模糊匹配",必须自己用数据结构拼装。
通常会踩到这件事的业务场景有几类:
- 评论、动态、消息流这类时间线数据,热点都在缓存里
- 高并发写入的中间结果,先在 Redis 缓冲、稍后再持久化到数据库
- 实时统计类的看板,MySQL 扛不住的查询被前移到缓存
- 某些数据本身就不落库,例如临时排行榜、活动期间的会话数据
这些场景的共同特征是:数据要么暂时不在数据库里,要么放在数据库里也来不及查。下面要解决的,就是在这种约束下,怎么把分页和多条件模糊查询拼起来。
二、分页:为什么首选 ZSet
Redis 里能支撑"取第几页、每页几条"的结构有两个:List 和 ZSet。看似都能做,但 ZSet 几乎在所有场景都更合适。
2.1 ZSet 的核心指令
ZSet 全称 Sorted Set,即有序集合,每个元素同时绑定一个 score,集合按 score 自动排序。和分页相关的指令主要有这几个:
| 指令 | 作用 |
|---|---|
ZADD key score member |
写入元素并指定排序值 |
ZREVRANGE key start stop |
按 score 倒序取 start, stop 区间 |
ZRANGEBYSCORE key min max |
按 score 范围筛选 |
ZREM key member |
移除指定成员 |
ZCARD key |
返回集合元素总数,用于算 total |
业务里常见的做法是把时间戳作为 score,于是"最新发布"自然就是 ZREVRANGE key 0 -1,分页就是 ZREVRANGE key (page-1)*size page*size-1。这套语义和 SQL 里的 ORDER BY created_at DESC LIMIT ?, ? 几乎一一对应。
2.2 分页代码示例
用 Spring Data Redis 的 RedisTemplate 实现一个朴素分页接口:
java
public List<Comment> pageComments(String bizId, int page, int size) {
String key = "comments:" + bizId;
long start = (long) (page - 1) * size;
long end = start + size - 1;
Set<String> jsonSet = redisTemplate.opsForZSet()
.reverseRange(key, start, end);
if (jsonSet == null || jsonSet.isEmpty()) {
return Collections.emptyList();
}
return jsonSet.stream()
.map(json -> JSON.parseObject(json, Comment.class))
.collect(Collectors.toList());
}
public void addComment(String bizId, Comment c) {
String key = "comments:" + bizId;
redisTemplate.opsForZSet()
.add(key, JSON.toJSONString(c), c.getCreateTime().getTime());
}2.3 ZSet 相比 List 的优势
很多人会说"用 List 也能分页",做的方式无非是 LPUSH + LRANGE。但在生产环境里,List 一旦遇到下面任何一项,就开始难受:
- 乱序写入:List 只能按写入顺序排,业务里却经常出现"补录"、"修正时间戳"等需要重排序的情况
- 范围筛选 :想"取过去 24 小时内的评论",List 拿不到这个能力,ZSet 一个
ZRANGEBYSCORE就够 - 去重:ZSet 的 member 是唯一的,配合业务主键能避免重复插入;List 不去重,需要业务自己保证
唯一一种 List 更合适的场景是:允许重复 member、且不需要任何排序变更,比如纯粹的日志缓冲。除此之外,ZSet 几乎都是更好的选择。
2.4 深翻页的隐藏代价
ZSet 的 ZREVRANGE 表面上是 O(log N + M),但在 N 上千万、page 翻到几千页时,依然会拖慢响应。生产里通常会做两件事:
- 限制最大可翻页深度,比如最多 100 页,剩下的引导用户用筛选条件而不是无脑翻页
- 改成游标式分页 :把"上一页最后一条的 score"传回客户端,下一次直接
ZREVRANGEBYSCORE key (lastScore -inf LIMIT 0 size,避免 offset 越深越慢
游标分页的代码示例:
java
public List<Comment> pageByCursor(String bizId, Long lastScore, int size) {
String key = "comments:" + bizId;
double max = (lastScore == null) ? Double.POSITIVE_INFINITY : lastScore - 1;
Set<String> set = redisTemplate.opsForZSet()
.reverseRangeByScore(key, Double.NEGATIVE_INFINITY, max, 0, size);
// ...
}三、多条件模糊查询:基于 Hash 与 HSCAN
ZSet 解决了分页,但解决不了"按条件筛选"。要在 Redis 内部完成模糊匹配,目前业界最常见的做法是借助 Hash + HSCAN。
3.1 思路:把条件字段编码进 field
核心点是设计 Hash 的 field 命名规则,把所有可能参与模糊匹配的字段拼进去。例如用户数据,约定 field 形如:
java
<id>:<姓名>:<性别>写入示例:
java
HSET user_index "1001:阿强:男" "{...用户详情JSON...}"
HSET user_index "1002:阿琳:女" "{...用户详情JSON...}"
HSET user_index "1003:张伟:男" "{...用户详情JSON...}"查询时利用 HSCAN 的 MATCH 模式:
java
# 所有女性
HSCAN user_index 0 MATCH *:*:女 COUNT 1000
# 姓阿的全部
HSCAN user_index 0 MATCH *:阿*:* COUNT 1000
# id 前缀 100 的男性
HSCAN user_index 0 MATCH 100*:*:男 COUNT 1000HSCAN 是渐进式扫描,单次只返回一小部分,配合返回的 cursor 反复调用,直到 cursor 归零代表遍历结束。它比 KEYS 安全得多------不会阻塞 Redis 主线程。
3.2 为什么坚决不用 KEYS
新人很容易写出 KEYS *:阿*:* 这种代码。KEYS 是 阻塞式 的,会扫描全库,在生产环境上百万 key 的实例里,一次调用足以让整个 Redis 服务卡顿数秒,后果是所有读写请求一起阻塞,雪崩级的故障。所有线上代码都应当用 SCAN 系列指令(SCAN、HSCAN、SSCAN、ZSCAN)替代 KEYS 与 HGETALL 式全量遍历。
3.3 模式匹配的局限
HSCAN MATCH 用的是 glob 风格通配符:*、?、[]。这意味着:
- 它能做 前缀 / 后缀 / 包含 匹配
- 它做不了 真正的全文检索(分词、相关性排序、拼写纠错)
- 它做不了 多字段交集,只能在 field 名里把字段拼起来用通配符近似实现
如果业务方真正需要的是"在十万条描述里找语义相近的文本",那就别在原生 Redis 里硬刚,直接上 RediSearch、Elasticsearch 或者向量数据库。本文要谈的方案,针对的是中等规模(几万到几百万 key)、字段维度可枚举的过滤性查询。
3.4 渐进式扫描的代码模板
java
public List<String> scanByPattern(String hashKey, String pattern) {
List<String> matched = new ArrayList<>();
ScanOptions options = ScanOptions.scanOptions()
.match(pattern)
.count(1000)
.build();
try (Cursor<Map.Entry<Object, Object>> cursor =
redisTemplate.opsForHash().scan(hashKey, options)) {
while (cursor.hasNext()) {
Map.Entry<Object, Object> entry = cursor.next();
matched.add(entry.getKey().toString());
}
}
return matched;
}要注意 COUNT 只是 提示,不是返回上限。Redis 可能返回多于或少于这个值的元素,业务侧要做好"边扫边过滤"的心理预期。同时,扫描期间 Hash 内容可能发生变化,HSCAN 提供的是"弱一致"语义------不会漏掉一直存在的 field,但中途新增 / 删除的 field 可能返回也可能不返回,这点和 MySQL 的快照读完全不是一回事。
四、组合方案:把分页和模糊查询拼在一起
单独看,ZSet 解决分页、Hash + HSCAN 解决条件过滤。问题来了------HSCAN 的结果是 无序的,单次也只是部分结果,直接拿它做"取第 3 页 20 条"完全行不通。怎么办?
4.1 总体思路
业内比较成熟的做法可以归纳为四步:
- 数据写入:所有原始数据按"条件编码 field"写到一张大 Hash 里
- 条件转匹配串 :把用户传入的多条件请求,转成一个统一格式的匹配串,例如
*:阿*:女 - 结果集索引:以匹配串本身作为 ZSet 的 key,第一次查询时用 HSCAN 把所有命中 field 写进这个 ZSet,并给 ZSet 设过期
- 分页读取:后续相同条件的请求直接走 ZSet 分页,不再扫描 Hash
整体流程画出来就是这样:
#mermaid-svg-m6M2woO735gZJE9m{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-m6M2woO735gZJE9m .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-m6M2woO735gZJE9m .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-m6M2woO735gZJE9m .error-icon{fill:#552222;}#mermaid-svg-m6M2woO735gZJE9m .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-m6M2woO735gZJE9m .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-m6M2woO735gZJE9m .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-m6M2woO735gZJE9m .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-m6M2woO735gZJE9m .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-m6M2woO735gZJE9m .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-m6M2woO735gZJE9m .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-m6M2woO735gZJE9m .marker{fill:#333333;stroke:#333333;}#mermaid-svg-m6M2woO735gZJE9m .marker.cross{stroke:#333333;}#mermaid-svg-m6M2woO735gZJE9m svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-m6M2woO735gZJE9m p{margin:0;}#mermaid-svg-m6M2woO735gZJE9m .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-m6M2woO735gZJE9m .cluster-label text{fill:#333;}#mermaid-svg-m6M2woO735gZJE9m .cluster-label span{color:#333;}#mermaid-svg-m6M2woO735gZJE9m .cluster-label span p{background-color:transparent;}#mermaid-svg-m6M2woO735gZJE9m .label text,#mermaid-svg-m6M2woO735gZJE9m span{fill:#333;color:#333;}#mermaid-svg-m6M2woO735gZJE9m .node rect,#mermaid-svg-m6M2woO735gZJE9m .node circle,#mermaid-svg-m6M2woO735gZJE9m .node ellipse,#mermaid-svg-m6M2woO735gZJE9m .node polygon,#mermaid-svg-m6M2woO735gZJE9m .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-m6M2woO735gZJE9m .rough-node .label text,#mermaid-svg-m6M2woO735gZJE9m .node .label text,#mermaid-svg-m6M2woO735gZJE9m .image-shape .label,#mermaid-svg-m6M2woO735gZJE9m .icon-shape .label{text-anchor:middle;}#mermaid-svg-m6M2woO735gZJE9m .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-m6M2woO735gZJE9m .rough-node .label,#mermaid-svg-m6M2woO735gZJE9m .node .label,#mermaid-svg-m6M2woO735gZJE9m .image-shape .label,#mermaid-svg-m6M2woO735gZJE9m .icon-shape .label{text-align:center;}#mermaid-svg-m6M2woO735gZJE9m .node.clickable{cursor:pointer;}#mermaid-svg-m6M2woO735gZJE9m .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-m6M2woO735gZJE9m .arrowheadPath{fill:#333333;}#mermaid-svg-m6M2woO735gZJE9m .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-m6M2woO735gZJE9m .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-m6M2woO735gZJE9m .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-m6M2woO735gZJE9m .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-m6M2woO735gZJE9m .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-m6M2woO735gZJE9m .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-m6M2woO735gZJE9m .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-m6M2woO735gZJE9m .cluster text{fill:#333;}#mermaid-svg-m6M2woO735gZJE9m .cluster span{color:#333;}#mermaid-svg-m6M2woO735gZJE9m div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-m6M2woO735gZJE9m .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-m6M2woO735gZJE9m rect.text{fill:none;stroke-width:0;}#mermaid-svg-m6M2woO735gZJE9m .icon-shape,#mermaid-svg-m6M2woO735gZJE9m .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-m6M2woO735gZJE9m .icon-shape p,#mermaid-svg-m6M2woO735gZJE9m .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-m6M2woO735gZJE9m .icon-shape .label rect,#mermaid-svg-m6M2woO735gZJE9m .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-m6M2woO735gZJE9m .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-m6M2woO735gZJE9m .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-m6M2woO735gZJE9m :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 是
否
用户请求
条件 + 分页参数
生成条件匹配串
Redis 中是否存在
同名 ZSet?
ZREVRANGE 直接分页
HSCAN 扫描 Hash
收集命中 field
ZADD 写入新 ZSet
设置 TTL
根据 field 回查 Hash
取 value 反序列化
返回分页结果
4.2 数据结构设计
以一个用户检索场景为例:
java
# 原始数据,HASH 类型
KEY user_index
FIELD <id>:<姓名>:<性别>:<城市>
VALUE {"id":1001,"name":"阿强","gender":"男","city":"上海", ...}
# 结果集索引,ZSET 类型
KEY user_index:query:*:阿*:*:上海
MEMBER <id>:<姓名>:<性别>:<城市>
SCORE 排序字段(注册时间、id 等)ZSet 的 key 由业务前缀 + 匹配串拼成,方便统一管理;member 直接复用 Hash 的 field,回查时 HGET user_index <field> 即可。
4.3 关键代码
java
public PageResult<User> queryUsers(UserQuery q, int page, int size) {
String pattern = buildPattern(q); // 例如 "*:阿*:*:上海"
String zsetKey = "user_index:query:" + pattern;
Boolean exists = redisTemplate.hasKey(zsetKey);
if (Boolean.FALSE.equals(exists)) {
rebuildIndex(zsetKey, pattern); // 第一次查询,构建索引
} else {
redisTemplate.expire(zsetKey, Duration.ofMinutes(10)); // 命中则续期
}
long start = (long) (page - 1) * size;
long end = start + size - 1;
Set<String> fields = redisTemplate.opsForZSet()
.reverseRange(zsetKey, start, end);
if (fields == null || fields.isEmpty()) {
return PageResult.empty();
}
List<Object> values = redisTemplate.opsForHash()
.multiGet("user_index", new ArrayList<>(fields));
List<User> users = values.stream()
.filter(Objects::nonNull)
.map(v -> JSON.parseObject(v.toString(), User.class))
.collect(Collectors.toList());
Long total = redisTemplate.opsForZSet().zCard(zsetKey);
return new PageResult<>(users, total);
}
private void rebuildIndex(String zsetKey, String pattern) {
ScanOptions options = ScanOptions.scanOptions()
.match(pattern).count(1000).build();
try (Cursor<Map.Entry<Object, Object>> cursor =
redisTemplate.opsForHash().scan("user_index", options)) {
while (cursor.hasNext()) {
Map.Entry<Object, Object> entry = cursor.next();
String field = entry.getKey().toString();
double score = extractScore(field); // 解析 field 拿排序值
redisTemplate.opsForZSet().add(zsetKey, field, score);
}
}
redisTemplate.expire(zsetKey, Duration.ofMinutes(10));
}4.4 这套方案带来的收益
- 第一次查询:付出一次 HSCAN 全量扫描的代价(O(N)),其余完全走 ZSet,复杂度 O(log N + M)
- 后续查询:所有翻页都是 ZSet 命中,HSCAN 不再触发
- 统计 total :
ZCARD一次拿到符合条件总数,前端可以直接做分页器 - 支持排序:把任意可数值化的字段作为 score 即可,比如时间戳、热度、价格
五、生产环境必须考虑的工程问题
简单跑通 demo 是一回事,把这套机制扛在线上是另一回事。下面这些点必须在落地前想清楚。
5.1 缓存膨胀:匹配串爆炸
每一个独特的查询条件都会产生一个 ZSet。前端筛选项一多,组合数能轻松上万:
java
*:阿*:*:上海
*:阿*:*:北京
*:阿*:女:上海
*:阿*:男:上海
... 共 N×M×K 组如果对每一种都建一个 ZSet 永久保留,Redis 内存很快会被吃光。常见的几条治理思路:
- 必给 TTL:每个查询索引 ZSet 都设置过期时间(比如 5~30 分钟),冷查询自动消失
- 命中续期:用户翻页时刷新 TTL,热查询自动保活
- 限制匹配维度:约定允许的查询字段集合,把"完全自由组合"收敛成"有限可枚举"
- 匹配串归一化 :相同语义的查询要生成同一个 key,例如统一字段顺序、统一大小写、统一空缺位用
*而不是空字符串
5.2 数据一致性:写入与索引怎么同步
ZSet 索引是基于"快照时刻的 Hash 内容"生成的。新数据写入 Hash 后,老的 ZSet 是不知道的------它依然会返回旧的分页结果。两条主流路线:
方案 A:双写
写入 Hash 的同时,遍历当前活跃的查询 ZSet,把新数据按 glob 规则补进去。
java
public void addUser(User u) {
String field = buildField(u);
redisTemplate.opsForHash()
.put("user_index", field, JSON.toJSONString(u));
// 找到所有可能匹配该用户的活跃索引,补一条
ScanOptions opts = ScanOptions.scanOptions()
.match("user_index:query:*").count(500).build();
try (Cursor<byte[]> cursor =
redisTemplate.executeWithStickyConnection(
c -> c.scan(opts))) {
while (cursor.hasNext()) {
String key = new String(cursor.next());
String pattern = key.substring("user_index:query:".length());
if (matchGlob(field, pattern)) {
redisTemplate.opsForZSet().add(key, field, u.getCreateTime());
}
}
}
}这个方案保证了实时性,但写入开销随活跃索引数线性增长,而且要自己实现 glob 匹配,代码量不小。
方案 B:定时重建 / 惰性失效
不去维护增量,索引到期自动清理;下次查询命中时再用 HSCAN 重建一次。实现简单,开销小,代价是用户可能在 TTL 内看不到新数据。
实战经验上,评论、商品筛选这一类不要求强实时的列表,惰性失效就够;聊天列表、实时排行榜这类核心写入面,需要双写。两种方案也可以结合:高优先级字段做双写,长尾查询做惰性。
5.3 大 Key 风险
把全量数据塞进一张 Hash,单 key 体积可能上 GB。一旦 Redis 触发 RDB 持久化或者主从同步,单个大 key 的序列化会显著卡 IO,严重时还会让从库追不上主库,触发全量重同步。规避手段:
- 分桶 :按 id 哈希到 N 张 Hash,例如
user_index:0~user_index:15,HSCAN 时并发扫各桶 - 限制 field 数量:每张 Hash 不超过百万级 field
- 不要盲目调大 hash-max-ziplist-entries:默认上限是有原因的,超过后内存与 CPU 都会跳变到更糟的状态
5.4 扫描期间的雪崩
高并发场景下,如果某个热门查询的 ZSet 同时过期,可能瞬间有几十个请求一起触发 HSCAN,把 Redis CPU 打满。
应对手段:
- 互斥重建 :用
SET NX+ 短 TTL 抢锁,只允许一个线程触发重建,其他线程短暂等待或降级返回上一次结果 - 逻辑过期:ZSet 本体不设 TTL,而是把过期时间存进 ZSet 自身的一个 member 或附带的 String key,到期由后台线程异步刷新
- 预热:对已知热门组合(如默认排序、默认筛选)在系统启动或后台任务里主动构建索引
互斥重建的最小实现:
java
private void rebuildWithLock(String zsetKey, String pattern) {
String lockKey = zsetKey + ":lock";
Boolean got = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", Duration.ofSeconds(30));
if (Boolean.TRUE.equals(got)) {
try {
rebuildIndex(zsetKey, pattern);
} finally {
redisTemplate.delete(lockKey);
}
} else {
// 没抢到锁:短暂等待让其他线程把索引建好,再走读路径
sleepBackoff();
}
}5.5 排序与稳定性
ZSet 按 score 排序,score 相同时按 member 字典序排。如果业务的 score 是毫秒时间戳,同一毫秒插入两条记录会出现顺序不稳定。可以:
- 复合 score :
score = timestamp * 1000 + sequence,把次序揉进 score - 避免相等:分布式 ID 自带单调性,本身就能当 score
六、什么时候不该用这套方案
工程上没有银弹。下面几种情况,直接放弃 Hash + HSCAN,换更专业的工具:
- 真·全文检索:要分词、要相关性打分、要拼写纠错------上 RediSearch / Elasticsearch
- 高维聚合 :要
GROUP BY出销量榜、要做时间窗口聚合------上 ClickHouse / Druid - 强一致 + 复杂事务:还是回 MySQL / PostgreSQL,加合理的索引
- 超大数据量(亿级及以上):单机 Redis 扛不动这种规模的 HSCAN 全表扫描,要么分片、要么转专业搜索引擎
判断标准其实只有一个:业务真正需要的查询语义,Redis 用通配符 + 集合能不能近似表达。能,就用这套方案;不能,就别勉强。
七、与 RediSearch 的对照
Redis 官方近几年大力推 RediSearch(现在叫 Redis Query Engine),它能在 Redis 上原生支持二级索引、全文检索、向量检索、范围聚合。功能上比手撕 Hash + HSCAN 强一个数量级:
| 维度 | 手撕方案(Hash + ZSet) | RediSearch |
|---|---|---|
| 部署门槛 | 原生 Redis 即可 | 需要加载模块 |
| 多字段过滤 | 通配符近似 | 原生 AND / OR / NOT |
| 全文检索 | 不支持 | 支持,含分词、模糊、相关性 |
| 排序与分页 | 自行维护 ZSet | 内置 SORTBY、LIMIT |
| 内存开销 | 索引 ZSet 可控但易膨胀 | 二级索引常驻,开销可观 |
| 改造成本 | 应用层全量自研 | 客户端切到 FT.* 指令 |
如果团队能控制 Redis 部署形态(自建,或云厂商提供模块支持),直接用 RediSearch 会更稳。但仍有大量场景受限于"只能用原生 Redis"------某些云上的标准版实例、共享托管、合规限制等等------这时本文的方案就有了用武之地。
八、把方案串成一张工程图
最后用一张相对完整的架构图收尾,便于落地时对照:
#mermaid-svg-e5eKG4A4LYYa9GEp{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-e5eKG4A4LYYa9GEp .error-icon{fill:#552222;}#mermaid-svg-e5eKG4A4LYYa9GEp .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-e5eKG4A4LYYa9GEp .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-e5eKG4A4LYYa9GEp .marker{fill:#333333;stroke:#333333;}#mermaid-svg-e5eKG4A4LYYa9GEp .marker.cross{stroke:#333333;}#mermaid-svg-e5eKG4A4LYYa9GEp svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-e5eKG4A4LYYa9GEp p{margin:0;}#mermaid-svg-e5eKG4A4LYYa9GEp .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp .cluster-label text{fill:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp .cluster-label span{color:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp .cluster-label span p{background-color:transparent;}#mermaid-svg-e5eKG4A4LYYa9GEp .label text,#mermaid-svg-e5eKG4A4LYYa9GEp span{fill:#333;color:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp .node rect,#mermaid-svg-e5eKG4A4LYYa9GEp .node circle,#mermaid-svg-e5eKG4A4LYYa9GEp .node ellipse,#mermaid-svg-e5eKG4A4LYYa9GEp .node polygon,#mermaid-svg-e5eKG4A4LYYa9GEp .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-e5eKG4A4LYYa9GEp .rough-node .label text,#mermaid-svg-e5eKG4A4LYYa9GEp .node .label text,#mermaid-svg-e5eKG4A4LYYa9GEp .image-shape .label,#mermaid-svg-e5eKG4A4LYYa9GEp .icon-shape .label{text-anchor:middle;}#mermaid-svg-e5eKG4A4LYYa9GEp .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-e5eKG4A4LYYa9GEp .rough-node .label,#mermaid-svg-e5eKG4A4LYYa9GEp .node .label,#mermaid-svg-e5eKG4A4LYYa9GEp .image-shape .label,#mermaid-svg-e5eKG4A4LYYa9GEp .icon-shape .label{text-align:center;}#mermaid-svg-e5eKG4A4LYYa9GEp .node.clickable{cursor:pointer;}#mermaid-svg-e5eKG4A4LYYa9GEp .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-e5eKG4A4LYYa9GEp .arrowheadPath{fill:#333333;}#mermaid-svg-e5eKG4A4LYYa9GEp .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-e5eKG4A4LYYa9GEp .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-e5eKG4A4LYYa9GEp .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-e5eKG4A4LYYa9GEp .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-e5eKG4A4LYYa9GEp .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-e5eKG4A4LYYa9GEp .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-e5eKG4A4LYYa9GEp .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-e5eKG4A4LYYa9GEp .cluster text{fill:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp .cluster span{color:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-e5eKG4A4LYYa9GEp .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-e5eKG4A4LYYa9GEp rect.text{fill:none;stroke-width:0;}#mermaid-svg-e5eKG4A4LYYa9GEp .icon-shape,#mermaid-svg-e5eKG4A4LYYa9GEp .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-e5eKG4A4LYYa9GEp .icon-shape p,#mermaid-svg-e5eKG4A4LYYa9GEp .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-e5eKG4A4LYYa9GEp .icon-shape .label rect,#mermaid-svg-e5eKG4A4LYYa9GEp .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-e5eKG4A4LYYa9GEp .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-e5eKG4A4LYYa9GEp .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-e5eKG4A4LYYa9GEp :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 查询路径
是
否
业务查询
标准化匹配串
ZSet 是否存在?
ZSet 续期
抢分布式锁
HSCAN 构建 ZSet
设置 TTL
ZREVRANGE 分页
HMGET 回查 value
反序列化 + 返回
写入路径
是
否
业务写入
计算 field
id:name:gender:city
HSET user_index
是否启用双写?
SCAN 活跃 ZSet
命中则 ZADD
直接结束
按这张图把读写两条链路都实现一遍,再补上 TTL、互斥锁、监控埋点,就能在中等规模业务里稳定跑起来。
九、结语
回到最初的问题------Redis 单纯靠内置指令做不到"分页 + 多条件模糊查询"。但当把 Hash 当作主存储、HSCAN 当作过滤器、ZSet 当作结果集缓存 这三件事拼起来,再叠上 TTL、双写或惰性失效、互斥重建等若干工程手段,就能在原生 Redis 上凑出一套足够实用的方案。
它不是最优雅的,也不是性能上限------RediSearch、Elasticsearch、向量数据库都会比它强。它的价值在于:不依赖任何额外模块,只用 Redis 原生能力,就能服务相当一部分中等规模的业务查询场景。在受限环境下,这种"用基础原语拼接出复杂语义"的能力,恰恰是后端工程师区别于 API 调用员的关键。
理解了思路之后,落地时只需要回答三个问题:
- 我的条件字段能否枚举?能枚举,就能编码进 field。
- 我的数据规模能否承受全量 HSCAN?能承受,方案就成立。
- 我的业务能否容忍 TTL 级别的延迟?能容忍,惰性失效就够用;不能容忍,就上双写。
这三个问题问清楚,剩下的就只是写代码。
