重点:
1. 深刻理解线程
2. 深刻理解虚拟地址空间
3. 了解线程概念,理解线程与进程区别与联系。
4. 学会线程控制,线程创建,线程终⽌,线程等待。
5. 了解线程分离与线程安全概念。
6. 掌握线程与进程地址空间布局
7. 理解LWP和原⽣线程库封装关系
0速查
1. 线程入口函数写法
cpp
写法:
void *thread_run(void *arg)
{
// 线程执行逻辑
return NULL;
}
函数类型:
void *(*start_routine)(void *)
参数是 void *arg,返回值是 void *。这个函数地址就是 pthread_create 的第三个参数。2. pthread_create
cpp
功能: 创建一个新的线程
原型:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
参数:
thread:输出型参数,返回线程 ID
attr:设置线程属性,传 NULL 表示默认属性
start_routine:线程启动后要执行的函数
arg:传给线程函数的参数
返回值: 成功返回 0;失败返回错误码。
cpp
例:
pthread_t tid;
int ret = pthread_create(&tid, NULL, thread_run, NULL);
if (ret != 0)
{
fprintf(stderr, "pthread_create error: %s\n", strerror(ret));
}
要记: pthread 系列函数一般直接看返回值,不是只看 errno。3. pthread_self
cpp
功能: 获取当前线程自己的 ID
原型:
pthread_t pthread_self(void);
写法:
pthread_t tid = pthread_self();
printf("tid = %lu\n", (unsigned long)tid);
记: pthread_t 是 pthread 库层面的线程 ID;对 Linux 当前 NPTL 实现来说,本质上像进程地址空间中的一个地址。4. pthread_exit
cpp
功能: 线程主动终止
原型:
void pthread_exit(void *value_ptr);
参数:
value_ptr:线程退出时带出去的返回值;不要指向局部变量
写法:
int *p = (int *)malloc(sizeof(int));
*p = 100;
pthread_exit((void *)p);
记: pthread_exit 或 return 返回的指针,必须指向全局区或 malloc 出来的内存,不能指向线程函数栈上的局部变量。5. pthread_cancel
cpp
功能: 取消一个执行中的线程
原型:
int pthread_cancel(pthread_t thread);
参数:
thread:目标线程 ID
返回值: 成功返回 0;失败返回错误码。
写法:
pthread_cancel(tid);6. pthread_join
cpp
功能: 等待线程结束
原型:
int pthread_join(pthread_t thread, void **value_ptr);
参数:
thread:线程 ID
value_ptr:接收线程返回值;不关心可传 NULL
返回值: 成功返回 0;失败返回错误码。
写法:
void *ret = NULL;
pthread_join(tid, &ret);
记:
线程 return → ret 里是线程函数返回值
线程 pthread_exit(x) → ret 里是 x
线程被 pthread_cancel → ret == PTHREAD_CANCELED
验证写法:
if (ret == PTHREAD_CANCELED)
{
printf("thread canceled\n");
}7. pthread_detach
cpp
功能: 分离线程,线程退出时自动释放资源
原型:
int pthread_detach(pthread_t thread);
参数:
thread:目标线程 ID
写法:
pthread_detach(tid);
pthread_detach(pthread_self());
记:
默认新线程是 joinable
joinable 线程退出后需要 pthread_join
detached 线程退出后自动释放资源
joinable 和 detached 冲突,不能同时存在。8. 三种线程结束方式
方式 1:return
cpp
void *thread1(void *arg)
{
int *p = (int *)malloc(sizeof(int));
*p = 1;
return (void *)p;
}方式 2:pthread_exit
cpp
void *thread2(void *arg)
{
int *p = (int *)malloc(sizeof(int));
*p = 2;
pthread_exit((void *)p);
}方式 3:pthread_cancel
cpp
void *thread3(void *arg)
{
while (1)
{
sleep(1);
}
return NULL;
}第一章 Linux线程概念
1-1 什么是线程
• 在⼀个程序⾥的⼀个执⾏路线就叫做线程(thread)。更准确的定义是:线程是"⼀个进程内部 的控制序列"
• ⼀切进程⾄少都有⼀个执⾏线程
进程是资源的容器;线程是执行的载体
也就是:
- 进程负责"有啥资源"
- 线程负责"谁来跑这些代码"
所以一个进程里可以有多个线程,大家共享同一份进程资源,但各自有自己的执行现场。
• 线程在进程内部运⾏,本质是在进程地址空间内运⾏ 。线程不是独立拥有一整套资源,它是"借住"在进程里的。
比如一个进程有:
- 代码段
- 全局数据区
- 堆
- 打开的文件
- 映射区
那么这个进程里的多个线程,通常都能访问这些东西。所以线程的核心特点就是:共享资源、并发执行。
• 透过进程虚拟地址空间,可以看到进程的⼤部分资源,将进程资源合理分配给每个执⾏流,就形 成了线程执⾏流
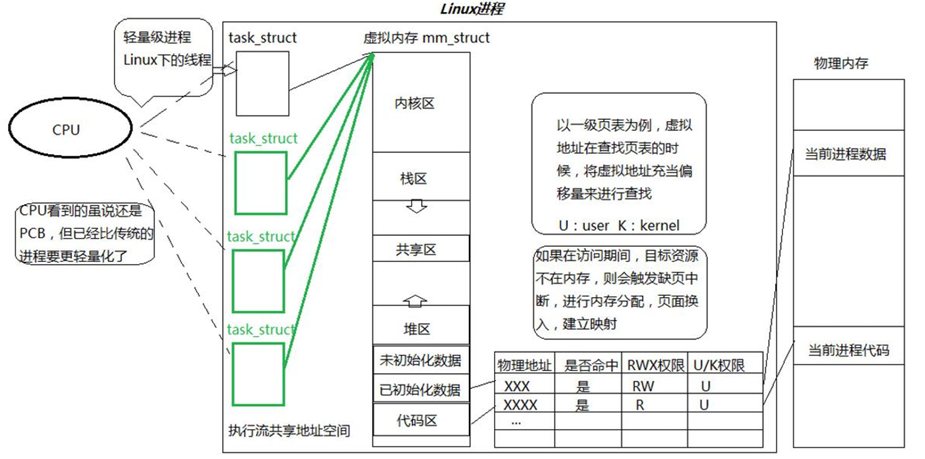
• 在Linux系统中,在CPU眼中,看到的PCB都要⽐传统的进程更加轻量化
在 Linux 系统中,CPU 眼中看到的 PCB 比传统进程更加轻量化。配图里把多个 task_struct 指向同一个虚拟内存 mm_struct,这就是 Linux 对线程/轻量级进程的典型处理方式。
即:多个执行流共享同一份地址空间,但内核里仍然用类似 task_struct 的结构管理它们。
理解:
- 在 Linux 内核里,并没有"线程"这种和"进程"完全不同的第二套实现
- Linux 更常见的做法是:线程本质上也是一种 task
- 只是这些 task 之间共享更多资源,比如地址空间、文件描述符表等
所以常说:Linux 线程 = 共享资源的轻量级进程
1-2 分⻚式存储管理
虚拟地址和页表的由来
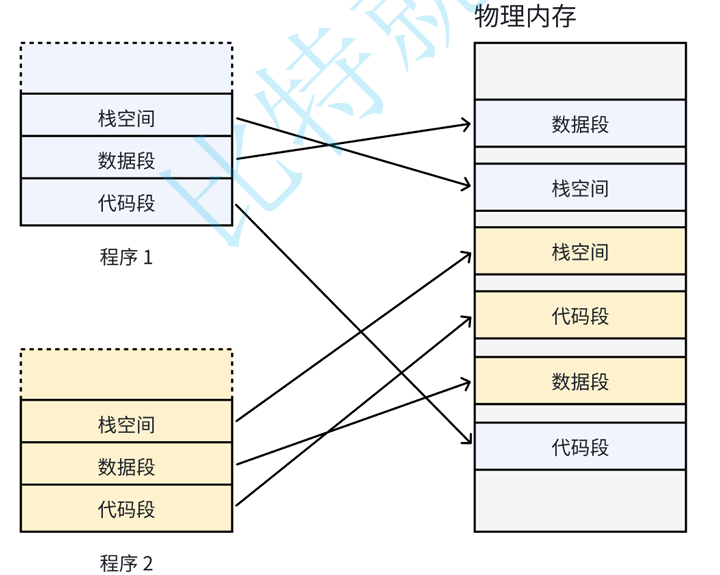
外部碎片问题:
如果没有虚拟内存和分页机制,那么每个程序在物理内存上都必须占连续空间。程序1和程序2的代码段、数据段、栈段都得直接映射到物理内存的连续区域。
这样会有什么问题
程序大小不一样,运行和退出时间不同,于是物理内存会被切成很多大小不一的碎片。比如:
- 程序 A 占 10MB
- 程序 B 占 20MB
- 程序 C 占 8MB
后来 B 退出了,中间就空出 20MB;再来个 25MB 的程序,明明总空闲内存可能够,但没有一块足够大的连续空间给它。这就是外部碎片问题。
**我们希望操作系统提供给⽤⼾的空间必须是连续的,但是物理内存最好不要连续。**此时虚 拟内存和分⻚便出现了,如下图所⽰:
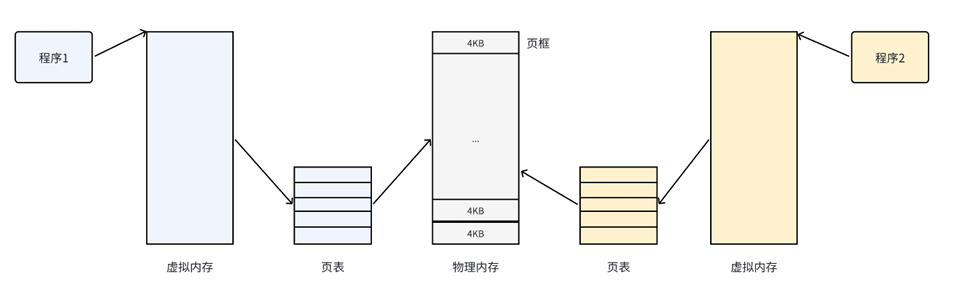
把物理内存按照⼀个固定的⻓度的⻚框进⾏分割,叫做物理⻚。每个⻚框包含⼀个物理⻚ (page)。⼀个⻚的⼤⼩等于⻚框的⼤⼩。⼤多数32 位 体系结构⽀持 4KB 的⻚,⽽ 64 位 体系结构一般会支持 8KB 的⻚。区分:
- 页框:物理内存上的存储单元(偏物理概念)
- 页:虚拟内存中的数据块,可以被装入任意页框,也可以在磁盘上(偏逻辑概念)
有了这种机制,CPU便并⾮是直接访问物理内存地址,⽽是通过虚拟地址空间来间接的访问物理内存 地址。所谓的虚拟地址空间,是操作系统为每⼀个正在执⾏的进程分配的⼀个逻辑地址,在32位机 上,其范围从0~4G-1。
意味着:
- 每个进程都"觉得"自己有 4GB 地址可用
- 但这并不等于真的占了 4GB 物理内存
- 真正用了哪些页,由页表决定
页表的作用
页表就是记录:虚拟页 → 物理页框 的映射关系。
CPU 访问地址时,不直接拿虚拟地址去读物理内存,而是先经过 MMU 查页表,找到真实物理地址,再访问内存。
总结⼀下,其思想是将虚拟内存下的逻辑地址空间分为若⼲⻚,将物理内存空间分为若⼲⻚框,通过 ⻚表便能把连续的虚拟内存,映射到若⼲个不连续的物理内存⻚。这样就解决了使⽤连续的物理内存 造成的碎⽚问题。
物理内存管理
一个 4GB 物理内存、4KB 页框的例子说明:一共会有 4GB / 4KB = 1048576 个页框。操作系统必须把这么多物理页管理起来,所以内核里有 struct page 这样的结构来描述物理页。
本想介绍struct page 的部分源码,但由于篇幅原因,没必要,知道就行了。这里解释一下flags、_mapcount、virtual 等字段。
1)为什么要有 struct page
因为操作系统要知道:
- 这个物理页在不在用
- 被谁映射了
- 是不是脏页
- 有没有锁
- 是否属于 slab
- 是否在 swap cache 中
内存管理不是只管"分不分配",而是要对每个物理页进行状态跟踪。
2)几个重要字段怎么理解
flags:表示页的状态位。
比如:
- 是否锁定
- 是否是脏页
- 是否已更新
- 是否在伙伴系统中
这本质上是"页的标签集合"。
_mapcount表示有多少页表项映射到这个物理页。
说白了就是:这个物理页被引用了多少次。如果一个物理页被多个虚拟地址映射,比如共享内存、写时拷贝等场景,这个值就很有意义。
virtual表示页在内核虚拟地址空间中的映射地址。 某些高端内存可能没有永久映射,所以这里可能是 NULL。
面试:Linux 使用 struct page 对物理页进行管理,每个物理页都对应一个描述结构,其中保存页状态、映射计数等信息,以支持页分配、回收、共享映射等机制。
⻚表
**页表中的每一个表项,指向一个物理页的开始地址。**在32位系统中,虚拟内存的最大空间是4GB,这是每一个用户程序都拥有的虚拟内存空间。既然需要让4GB的虚拟内存全部可用,那么页表中就需要能够表示这所有的4GB空间,那么就一共需要4GB/4KB = 1048576个表项。如下图所示:
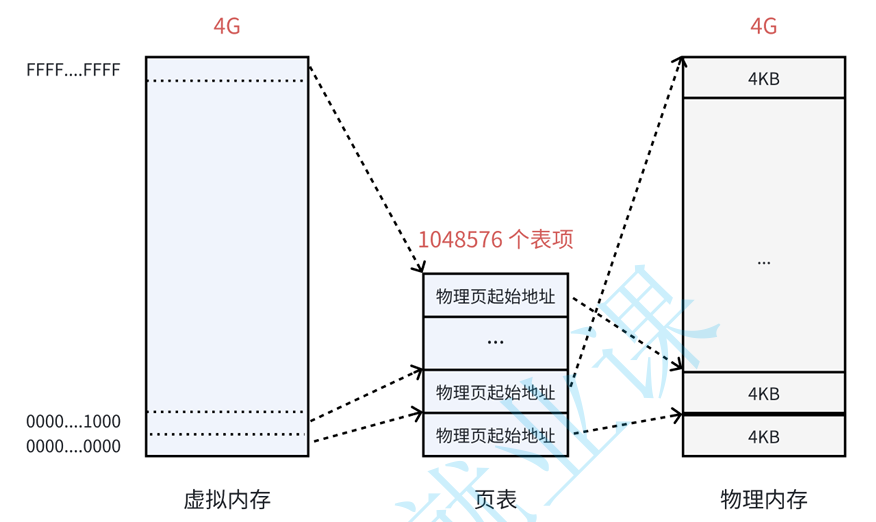
单级页表很大
算一遍你就明白了:
- 4GB 虚拟空间
- 每页 4KB
- 页数 =
4GB / 4KB = 1,048,576 - 每个页表项 4B
- 总页表大小 =
1,048,576 × 4B = 4MB
4MB 看起来不大,但问题在于:
- 对每个进程都要有页表
- 而且单级页表往往要求连续空间
- 很多进程并不会把 4GB 地址空间都用满
这就很浪费。
结论:
- 虚拟地址空间是连续的
- 物理页的映射可以是随机离散的
- 单级页表虽然能解决映射问题,但页表本身太大、太笨重
这也就是后面多级页表出现的原因。
页目录结构
解决需要⼤容量⻚表的最好⽅法是:把⻚表看成普通的⽂件,对它进⾏离散分配, 即对⻚表再分⻚, 由此形成多级⻚表的思想
以把这个单⼀⻚表拆分成 1024 个体积更⼩的映射表。如下图所⽰。这样⼀ 来,1024(每个表中的表项个数)*1024(表的个数),仍然可以覆盖 4GB 的物理内存空间。
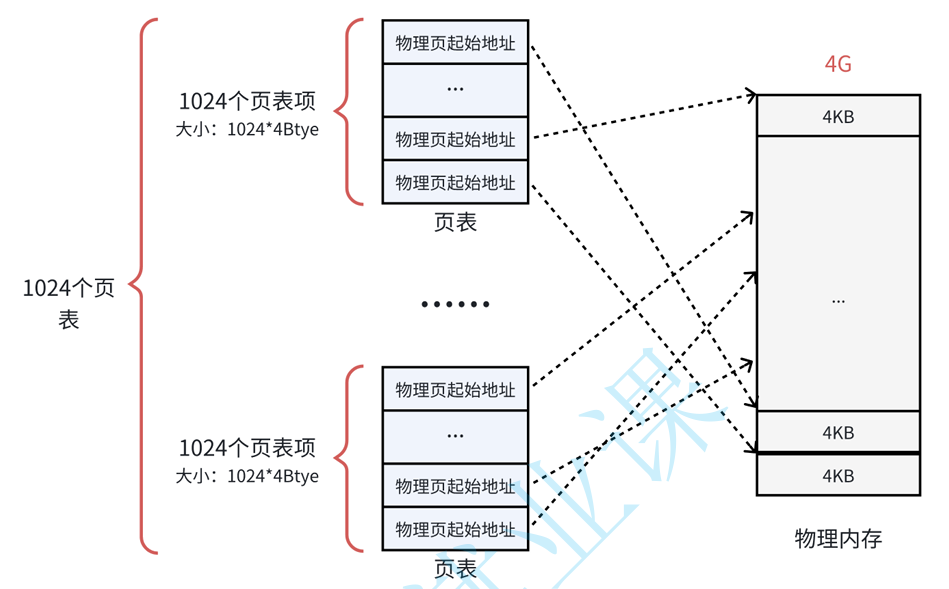
到⽬前为⽌,每⼀个⻚框都被⼀个⻚表中的⼀个表项来指向了,那么这 1024个页表也需要被管理起来。管理⻚表的表称之为⻚⽬录表,形成⼆级⻚表。
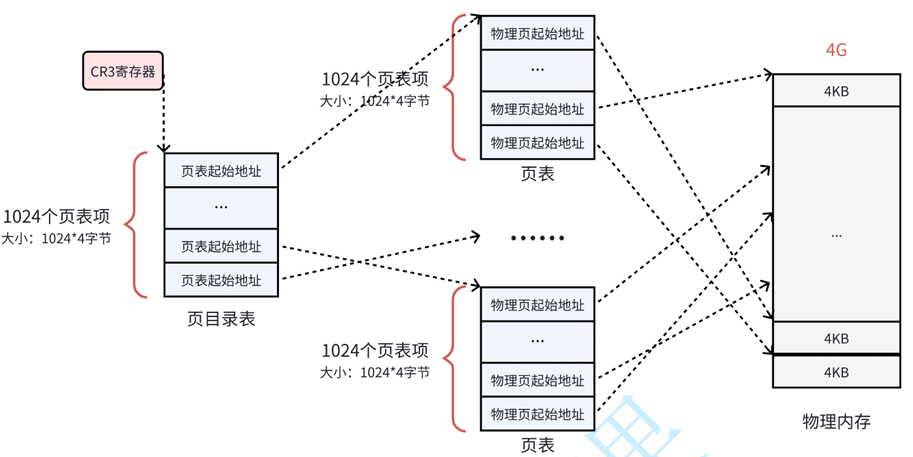
- 页目录表中的每个项,指向一个页表
- 页表中的每个项,指向一个物理页
- CR3 指向页目录表的起始地址
所以访问内存时要先找页目录,再找页表,再定位具体页内偏移。
和线程的关系:
线程共享的是进程地址空间,而地址空间的底层实现就是这套页表体系。所以:
- 同一进程的线程,共享同一套页目录 / 页表体系
- 不同进程的线程,通常对应不同地址空间,因此切换时页表基址会变
这也是为什么线程切换成本通常比进程切换低。
两级页表的地址转换
在 32 位、4KB 页的场景下,虚拟地址低 12 位是页内偏移,高 20 位用于查页表,再拆成 10 位一级页号 + 10 位二级页号。MMU 先通过 CR3 找页目录,再找页表,最后和页内偏移组合成物理地址。
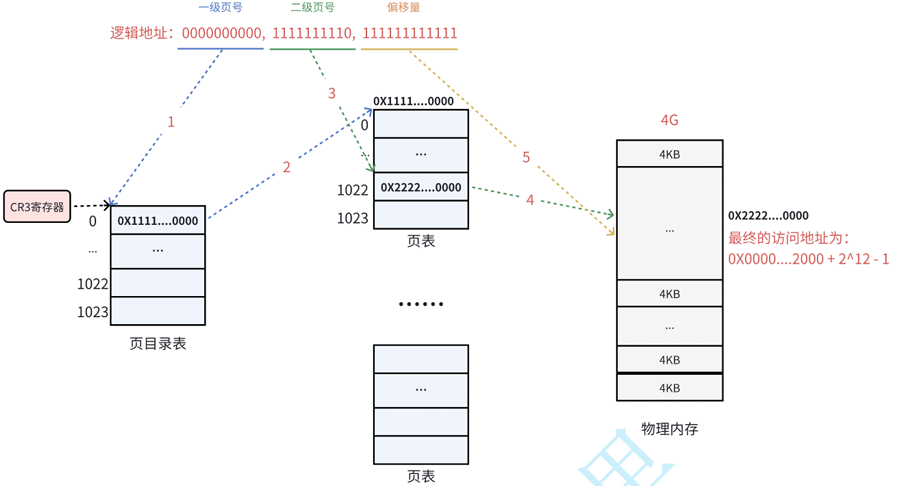
下⾯以⼀个逻辑地址为例。将逻辑地址( 0000000000,0000000001,11111111111 )转换为物 理地址的过程:
1. 在32位处理器中,采⽤4KB的⻚⼤⼩,则虚拟地址中低12位为⻚偏移,剩下⾼20位给⻚表,分成 两级,每个级别占10个bit(10+10)。
32 位虚拟地址:
- 高 10 位:页目录索引
- 中 10 位:页表索引
- 低 12 位:页内偏移
因为:
- 一个页 4KB = 2^12
- 所以偏移需要 12 位
- 剩下 20 位再拆成两级,各 10 位
2. CR3 寄存器 读取⻚⽬录起始地址,再根据⼀级⻚号查⻚⽬录表,找到下⼀级⻚表在物理内存中 存放位置。
四步:
- 从 CR3 拿到页目录表地址
- 用一级页号找到页表地址
- 用二级页号找到物理页框地址
- 加上 12 位页内偏移,得到最终物理地址
3. 根据⼆级⻚号查表,找到最终想要访问的内存块号。
4. 结合⻚内偏移量得到物理地址。
- 注:⼀个物理⻚的地址⼀定是 4KB 对⻬的(最后的 12 位全部为 0 ),所以其实只需要记录物理 ⻚地址的⾼20位即可。
6. 以上其实就是MMU的⼯作流程。MMU(MemoryManageUnit)是⼀种硬件电路,其速度很快, 主要⼯作是进⾏内存管理,地址转换只是它承接的业务之⼀。
总结⼀下:单级⻚表对连续内存要求⾼,于是引⼊了多级⻚表,但是多级⻚表也是⼀把双 刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。
有没有提升效率的办法呢?计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。 了新武器,江湖⼈称快表的 TLB (其实,就是缓存)。MMU 为了提升效率,会先查 TLB(快表)。如果 TLB 命中,直接得到物理地址;如果没命中,再去查页表,查到后再把映射关系写回 TLB。
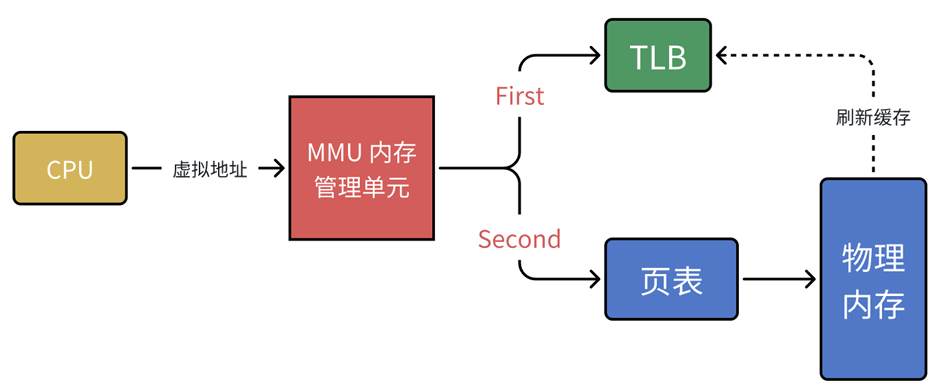
可以把 TLB 理解为:**页表映射关系的缓存。**这点非常非常关键,后面线程和进程切换时:
- 进程切换通常会影响页表、TLB
- 线程切换由于共享地址空间,TLB 影响相对更小
这就是线程切换更轻量的根本原因之一。
缺页异常
如果 CPU 给 MMU 一个虚拟地址,TLB 和页表都没法完成有效转换,或者权限不满足,就会产生缺页异常。CPU 会陷入内核,由 Page Fault Handler 处理。
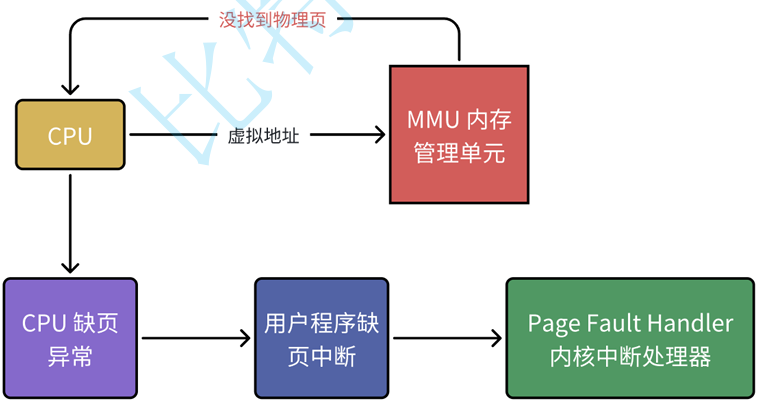
缺页本质是:当前虚拟地址对应的物理页还没准备好,或者当前访问不合法。
三种缺页
硬缺页(Major / Hard Page Fault)
物理内存里根本没有对应页,需要从磁盘读进来,再建立映射。这很慢,因为涉及 IO。
软缺页(Minor / Soft Page Fault)
物理页其实已经在内存里了,只是当前进程 / 线程的页表里还没有建立映射。只需补上映射,不需要磁盘 IO。
无效缺页(Invalid Page Fault)
比如:
- 访问越界地址
- 空指针解引用
- 没权限却硬访问
这类通常会导致段错误,比如 Segmentation Fault。
理解:
因为线程共享同一个地址空间,所以:
- 一个线程访问某地址导致缺页,本质是在这个进程地址空间里出问题
- 如果是非法访问,往往不是"只影响自己",而是可能把整个进程搞挂
- 这就是后面即将讲的:线程出异常,进程也可能一起崩
你看,前后就串起来了。
1-3 线程的优点
- 创建成本小
- 切换成本低
- 占用资源更少
- 能利用多核并行
- 能让 IO 等待和计算并行
- 适合计算密集型和 IO 密集型应用的优化
1-4 线程的缺点
- 性能损失
- 健壮性降低
- 缺乏访问控制
- 编程难度提高
1-5 线程异常
- 单个线程如果出现除零、野指针等崩溃,进程也会随着崩溃
因为线程共享:
- 地址空间
- 代码
- 数据
- 资源
而异常通常是进程级处理的。比如一个线程空指针解引用,内核给这个进程发 SIGSEGV,默认处理就是终止进程。
- 因为线程是进程的执行分支,线程异常会触发信号机制,最终终止进程,进程终止后所有线程都退出
面试常问
问:线程崩溃会不会只影响自己?
通常回答:
不一定。在线程共享进程资源的模型下,像段错误、非法内存访问这类致命异常通常会导致整个进程终止,因此进程内所有线程都会退出。
1-6 线程用途
- 合理使用多线程,可以提高 CPU 密集型程序执行效率
- 合理使用多线程,可以提高 IO 密集型程序的用户体验
1)CPU 密集型场景
比如:
- 图像处理
- 数值计算
- 搜索排序
- 编译任务
前提是任务可拆分,且核数足够。
2)IO 密集型场景
比如:
- 聊天服务器
- Web 服务
- 文件上传下载
- GUI 程序后台任务
一个线程等 IO,另一个线程继续响应业务或界面。
第二章 Linux 进程 VS 线程
2-1 进程和线程
- 进程是资源分配的基本单位
- 线程是调度的基本单位
这是面试高频原话。
1)资源分配的基本单位
为什么是进程?因为通常资源挂在进程上:
- 地址空间
- 打开的文件
- 信号处理方式
- 工作目录
- 身份信息
2)调度的基本单位
为什么是线程?因为真正上 CPU 跑的,是具体的执行流。调度器决定"下一刻哪个执行流占 CPU",这个执行流就是线程。
3)线程自己也有私有数据
线程私有部分:
- 线程 ID
- 一组寄存器
- 栈
- errno
- 信号屏蔽字
- 调度优先级
要能理解这些为什么必须私有:
寄存器必须私有: 否则线程一切换,执行现场就乱了。
栈必须私有: 函数调用、局部变量、返回地址都靠栈保存。
errno 必须私有: 不然线程 A 调库函数出错,线程 B 一覆盖,A 就读错了。
信号屏蔽字、调度优先级私有: 因为线程可能有不同的调度和信号处理需求。
2-2 进程的多个线程共享
进程和线程的关系:
同一进程的多个线程共享同一地址空间,因此共享:
- 代码段
- 数据段
- 堆
- 文件描述符表
- 信号处理方式
- 当前工作目录
- 用户 ID 和组 ID
1)共享代码段
一个函数定义一次,所有线程都能调用。
2)共享全局 / 静态数据
全局变量天生就是同一份。这也是线程安全问题的根源之一。
3)共享堆
malloc 出来的内存,理论上进程内所有线程都能访问。
4)共享文件描述符表
一个线程打开的文件,另一个线程也能用那个 fd。
5)共享当前工作目录、身份信息
因为这些本来就是进程级概念。
2-3 关于进程线程的问题
如何看待之前学习的单进程?------具有一个线程执行流的进程。
这句话非常适合你用来"升级旧知识"。以前你学的单进程程序,其实不是"没有线程",而是:
**只有一个线程的进程。**重新理解成:
- 一个进程
- 一个主线程
- 这个主线程独占执行流
第三章 Linux 线程控制
这一章是最落地、最像面试和写代码会直接用到的一章。前两章已经知道了:
- 线程是进程里的执行流
- 线程共享进程的大部分资源
- Linux 里线程和轻量级进程关系很深
那这一章开始,正式进入**"怎么创建线程、怎么结束线程、怎么回收线程、怎么让线程自己释放资源"**。也就是从"理解概念"进入"会写代码、会分析行为"。包含 5 个小节:POSIX 线程库、创建线程、线程终止、线程等待、分离线程。
3-1 POSIX 线程库
- 线程相关函数大多以
pthread_开头 - 需要包含头文件
<pthread.h> - 链接线程库时要使用
-lpthread选项
1)本质
Linux 里我们平常写多线程,不是直接操作内核线程,而是通过 pthread 库来操作。
也就是说平时写的:
cpp
pthread_create(...)
pthread_join(...)
pthread_exit(...)这些都不是"CPU 原生命令",也不是你直接在操纵 task_struct。
而是:
- 你调用 用户层线程库接口
- 线程库再去调用底层系统能力
- 最终让内核创建 / 管理轻量级进程(LWP)
要建立一个意识:
平时写线程代码,首先面对的是 POSIX 线程编程接口 ,也就是
pthread这一套 API。
2)POSIX 是什么
POSIX 可以先简单理解成:**一套可移植的操作系统接口标准。**它规定了很多系统编程接口的行为,比如:
- 文件操作
- 进程控制
- 信号
- 线程
所以 pthread 不是 Linux 独创的随意接口,而是遵循 POSIX 标准的线程接口。
3)链接时要加 -lpthread
你写了头文件,只是告诉编译器"这些函数长什么样";但真正链接的时候,还得把线程库代码链接进来。
gcc test.c -lpthread:把 pthread 库链接进最终可执行程序。
把"头文件"和"链接库"分清:
#include <pthread.h>:解决声明问题-lpthread:解决实现问题
Linux 下常用 POSIX 线程库进行多线程编程,线程相关函数大多以
pthread_开头,使用时需要包含<pthread.h>,并在链接阶段链接线程库。
3-2创建线程
cpp
功能:创建⼀个新的线程
原型:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *
(*start_routine)(void*), void *arg);
参数:
thread:返回线程ID
attr:设置线程的属性,attr为NULL表⽰使⽤默认属性
start_routine:是个函数地址,线程启动后要执⾏的函数
arg:传给线程启动函数的参数
返回值:成功返回0;失败返回错误码参数 void *(*start_routine)(void *)
这是最容易看晕的地方。它表示:**线程启动后要执行的函数地址。**并且这个函数的签名必须长这样:
void *func(void *arg)
也就是说:
- 参数只能收一个
void * - 返回值也是一个
void *
理解设计意图:
- 参数统一用
void *,方便传任意类型地址 - 返回值统一用
void *,方便线程退出时带回结果
所以线程入口函数必须长得像这样:
cpp
void *rout(void *arg)
{
// 线程执行逻辑
return NULL;
}返回值为什么不是 -1
强调错误检查。传统很多函数是:
- 成功返回
0 - 失败返回
-1 - 再设置全局
errno
但 pthread 系列函数不一样:出错时不会设置全局 errno,而是直接把错误码作为返回值返回。
这点非常重要。
cpp
if (pthread_create(...) == -1)
这是错的。
cpp
正确思路是:
int ret = pthread_create(...);
if (ret != 0) {
// ret 本身就是错误码
}检查 pthread 函数是否出错,优先看返回值,不要指望全局 errno。
pthread_self() 是什么
cpp
pthread_t pthread_self(void);
它的意思是:获取"当前调用这个函数的线程"的线程标识。
比如在线程函数里调用:
pthread_self()
拿到的就是当前这个线程自己的 pthread_t。这个函数很常用,因为很多线程内部逻辑需要知道"我是谁"。
pthread_t 和 LWP 到底什么关系
pthread_self得到的是 pthread 库维护的、进程内唯一标识- 它的作用域是进程级
- 内核真正识别的是系统全局唯一的线程 ID
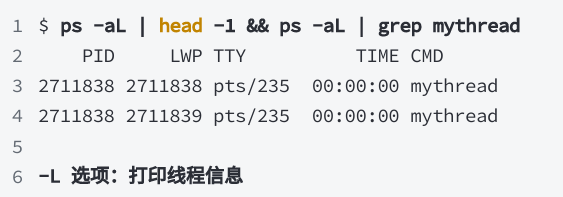
- 用
ps -aL可以看到线程信息,其中LWP才是真正的线程 ID
pthread_self得到的这个值,实际上是虚拟地址空间上的一个地址,通过这个地址可以找到线程的基本信息,比如线程 ID、线程栈、寄存器等属性。
这句话你得慢慢消化。先区分两种"线程ID"
第一种:库层线程 ID
- 类型:
pthread_t - 用途:pthread 库操作线程时使用
- 作用域:进程内
第二种:内核层线程 ID
- 你在
ps -aL里看到的是LWP - 这是内核调度真正识别的轻量级进程 ID
所以别把二者混为一谈。
为什么主线程的 PID 和某个 LWP 相同
ps -aL 示例中,有一行 PID == LWP,说明那就是主线程。
这可以这样理解:
- 整个进程有一个进程 ID(PID)
- 线程也有自己的轻量级进程 ID(LWP)
- 主线程通常那个 LWP 和 PID 相同
- 其他线程的 LWP 不同,但 PID 一样,因为它们属于同一进程
其他线程的栈在哪里
- 主线程的栈在通常的栈区
- 其他线程的栈在共享区 / 映射区里
必须掌握的面试点
问:pthread_create 返回什么?
答:
成功返回 0,失败返回错误码,不通过全局 errno 报错。
问:线程入口函数为什么必须是 void *(*)(void *)?
答:
因为 pthread 接口把线程参数和返回结果都统一抽象成
void *,便于传递任意类型地址和线程退出结果。
问:pthread_t 是不是内核线程 ID?
答:
不是。
pthread_t属于 pthread 库层面的线程标识,而ps -aL看到的LWP才是真正内核层线程 ID。
3-3 线程终止
如果只想终止某个线程,而不是整个进程,有三种方式:
- 线程函数
return - 线程自己调用
pthread_exit - 一个线程调用
pthread_cancel终止另一个线程
第一种方式:线程函数直接 return
线程函数 return 只结束该线程;main return 结束整个进程。
第二种方式:pthread_exit
主动让当前线程结束,并带出一个退出结果。
原型:
cpp
void pthread_exit(void *value_ptr);
注意:
value_ptr 不要指向局部变量
它没有返回值
线程结束时无法返回给它自己这个调用者为什么 value_ptr 不能指向局部变量
这是一个超级高频坑。
比如你这样写:
cpp
void *worker(void *arg)
{
int x = 10;
pthread_exit(&x); // 错误
}为什么错?因为 x 在当前线程栈上。线程一退出,这个栈上的局部变量就失效了。其他线程之后再通过 pthread_join 拿这个指针,拿到的是悬空地址。
pthread_exit或return返回的指针,必须指向全局区或者malloc分配的内存,不能指向线程函数栈上的空间。
所以正确做法通常是:
- 返回全局对象地址
- 或返回堆上
malloc出来的地址
第三种方式:pthread_cancel
原型:
cpp
int pthread_cancel(pthread_t thread);含义是:一个线程请求取消同一进程中的另一个线程。
注意这个措辞是"请求取消",你先不要把它粗暴理解成"立刻一刀砍死"。先掌握这个接口的用途即可:
- 参数是目标线程 ID
- 成功返回
0 - 失败返回错误码
三种线程终止方式对比记忆
方式一:线程函数 return
最自然,函数跑完就退出。
方式二:pthread_exit
更明确地表达"我现在主动结束,并带出退出值"。
方式三:pthread_cancel
其他线程干预当前线程,让它结束。
3-4 线程等待
为什么需要线程等待:
- 已退出线程的空间没有被释放
- 新创建的线程不会复用刚退出线程的地址空间
cpp
功能:等待线程结束
原型
int pthread_join(pthread_t thread, void **value_ptr);
参数:
thread:线程ID
value_ptr:它指向⼀个指针,后者指向线程的返回值
返回值:成功返回0;失败返回错误码1)为什么一定要有 pthread_join
这是这一章最重要的理解点之一。很多人以为:线程函数结束了,线程不就没了吗?
线程虽然退出了,但它占用的一些资源并没有立刻释放。
所以如果你不回收它,这些资源会残留在进程地址空间里。你可以类比进程里的"僵尸进程"思路来理解,虽然线程不是完全同一种机制,但那个"执行流已经结束,资源信息还需要被回收 "的味道很像。所以 pthread_join 的作用有两个:
- 等待目标线程结束
- 回收目标线程相关资源,并拿到它的退出结果
pthread_join 会发生什么
调用该函数的线程将挂起等待,直到
thread对应线程终止。
也就是说,谁调用 pthread_join,谁就阻塞。例如主线程写:
cpp
pthread_join(tid, &ret);那么主线程会停在这里,直到 tid 对应线程结束。这个行为直接影响并发执行流程。
不同退出方式,对应拿到的结果有什么不同
情况一:目标线程通过 return 退出
value_ptr 里存放的是线程函数的返回值。
情况二:目标线程被别人 pthread_cancel
value_ptr 里存放的是常量 PTHREAD_CANCELED。
情况三:目标线程自己调用 pthread_exit
value_ptr 里存放的是传给 pthread_exit 的参数。
情况四:你不关心返回值
可以直接传 NULL。
样例代码
三个线程函数:
thread1:return一个堆上整数1thread2:pthread_exit一个堆上整数2thread3:一直循环,后面被pthread_cancel
主线程分别对它们 pthread_create + pthread_join。
运行结果显示:
thread1回收后得到1thread2回收后得到2thread3被取消后得到PTHREAD_CANCELED

这一节最容易错的点
错误一:线程退出了就不用管了
错。没 join,资源还在。
错误二:返回局部变量地址
错。线程栈失效后就是野指针。
错误三:把 pthread_join 当成普通查询函数
错。它会阻塞调用者,直到目标线程结束。
3-5 分离线程
- 默认新线程是
joinable - 线程退出后需要
pthread_join - 否则无法释放资源,可能造成系统泄漏
- 如果不关心线程返回值,可以让系统在线程退出时自动释放资源
接口:
cpp
int pthread_detach(pthread_t thread);1)什么叫 joinable
默认情况下,新线程是"可等待"的,也就是 joinable。
意思就是:
- 线程退出后,不会立刻把所有资源都自动清掉
- 需要另一个线程来
pthread_join - 这样既能拿退出结果,也能完成资源回收
这是默认模型。
2)为什么会有 detach
因为并不是所有线程你都关心它的返回值。例如有些后台线程:
- 写日志
- 发心跳
- 后台清理
- 异步处理一些不需要主线程拿结果的任务
这种线程如果你还专门去 join,反而麻烦。如果不关心线程返回值,join 就成了一种负担,这时可以告诉系统:线程退出时自动释放资源。这就是 detach 的意义。
3)pthread_detach 到底干了什么
它的本质是把线程改成:**分离状态(detached)**一旦这个线程将来退出:
- 系统自动回收线程资源
- 你不能再用
pthread_join等它拿结果了
所以 detach 的核心代价是:
省掉了手动 join,但也放弃了 join 取回退出值的能力。
4)线程可以怎么分离
方式一:线程组内其他线程分离目标线程
pthread_detach(tid);
方式二:线程自己分离自己
pthread_detach(pthread_self());
后者很常见,表示:我这个线程从一开始就声明:别等我了,我结束时自己自动回收。
5)为什么 joinable 和 detached 冲突
joinable和分离是冲突的,一个线程不能既是 joinable 又是分离的。
很好理解。因为:
- joinable:表示将来要有人来 join 我
- detached:表示将来不用 join,我自己退出自己清理
这两种资源管理策略互相排斥。所以一旦线程 detach 了,就不要再想着 pthread_join 它。
6)课件示例
示例里,线程函数一开始就:
pthread_detach(pthread_self());
然后主线程:
- 创建线程
sleep(1),确保子线程先完成分离- 再执行
pthread_join(tid, NULL)
结果是:
pthread_join失败- 程序打印
"pthread wait failed"
这个例子就是专门证明:
一个已经分离的线程,不能再 join。
为什么要 sleep(1)?:"很重要,要让线程先分离,再等待。"
因为如果你不等一下,主线程也许还没等子线程 detach 成功,就先跑到 join 了,那实验现象就不稳定了。
7)什么时候该用 detach
适合 join 的线程
- 你关心线程执行结果
- 你需要知道它什么时候结束
- 你需要严格控制线程生命周期
适合 detach 的线程
- 你不关心返回值
- 你只想让它干完活自己消失
- 它更像后台任务
8)小结
默认线程是 joinable;不 join 就可能资源不回收;detach 后自动回收,但不能再 join。
第三章总结
真正要掌握的,不是把几个函数名背下来,而是把线程生命周期串起来:
第一阶段:创建
用 pthread_create 创建线程,指定入口函数和参数;成功返回 0,失败返回错误码,不靠全局 errno。
第二阶段:运行
主线程和新线程并发执行;pthread_self() 拿到的是 pthread 库层线程标识,不等于 ps -aL 里的 LWP。
第三阶段:终止
线程可以通过 return、pthread_exit、pthread_cancel 三种典型方式结束。主线程从 main 返回则意味着整个进程退出。
第四阶段:回收
默认线程是 joinable,需要 pthread_join,否则资源不会自动完全释放。pthread_join 还能拿到线程退出值。
第五阶段:分离
不关心返回值时,可以 pthread_detach,让线程退出后自动回收资源;但分离后不能再 join。
第四章 线程 ID 及进程地址空间布局
第 3 章你已经知道了:
pthread_create能创建线程pthread_self()能拿到线程"ID"ps -aL能看到LWP- 主线程和子线程的栈位置不一样
但你当时很容易只是"记住现象",没真正吃透。这一章就是专门把这些问题掰开:
pthread_t到底是什么- 它和
LWP到底什么关系 - 为什么说
pthread_t本质上像一个地址 - 线程在进程地址空间里到底怎么摆放
- 主线程栈和子线程栈为什么不一样
4-1 pthread_create 产生的线程 ID,到底是不是"真正线程 ID"
pthread_create会产生一个线程 ID,存到第一个参数指向的位置- 但这个线程 ID,和前面说的"线程 ID"不是一回事
- 前面讲的线程 ID 属于进程调度范畴
pthread_create第一个参数里的那个 ID,属于 NPTL 线程库范畴
这句话特别重要。先说结论
Linux 里至少有两层"线程标识":
第一层:内核调度层线程 ID
这是内核真正认识的线程号。
也就是用:ps -aL看到的那个 LWP。这个东西是内核调度器拿来区分线程的,因为线程本质上是轻量级进程,是操作系统调度的最小单位之一。前面讲的线程 ID 是"进程调度的范畴"。
第二层:pthread 库层线程 ID
这就是 pthread_t。这是线程库给你暴露出来的"句柄",供你在用户态代码里操作线程:
pthread_joinpthread_cancelpthread_detachpthread_self
这些 API 都围绕 pthread_t 工作。线程库后续操作,就是根据这个 ID 来操作线程。
4-2 为什么 pthread_t 不是 LWP
这个问题你必须真懂,不然一到面试就开始混。
1)内核视角
内核要调度线程,它需要的是一个系统级、全局可识别 的标识。这个标识体现在 LWP 上。
你可以理解成:
对内核来说,线程首先是一个被调度的执行实体。
所以它关心的是:
- 这个线程的内核 task 信息
- 调度状态
- 寄存器上下文
- 内核栈
- 轻量级进程 ID
2)线程库视角
pthread 库给用户提供 API,它不希望你直接操纵内核内部对象。所以库自己维护了一套线程描述信息。
于是它给你一个 pthread_t,本质上像个"引用/句柄/定位入口"。你拿着它,pthread 库就能找到这个线程对应的线程控制信息,然后进一步完成:
- 等待
- 分离
- 取消
- 取返回值
所以:
pthread_t更接近"库内部线程描述符的引用"
LWP更接近"内核真正调度的线程号"
4-3 pthread_t 为什么会"本质上是一个地址"
对 Linux 目前的 NPTL 实现而言,
pthread_t类型的线程 ID,本质就是一个进程地址空间上的一个地址。
1)别把"地址"理解成随便一个变量地址
这里不是说:"线程 ID 就等于某个普通整型变量的地址"。
而是说:
pthread 库内部会为线程维护一个描述线程的数据结构,
pthread_t在当前实现里,本质上就是这个描述对象的地址或者可由此定位到它。
你可以把它想成:pthread_t tid;这个 tid 在当前实现下,很像是指向某个线程描述块的入口。
2)为什么设计成地址很合理
因为线程库后续要操作线程,必须找到线程相关的数据:
- 线程的属性
- 线程栈
- 线程局部存储
- 退出结果
- 分离状态
- 对应内核线程信息
如果 pthread_t 本身就能定位到这个线程描述结构,那线程库做事就方便了。
所以前面说,pthread_self() 得到的值,实际上是虚拟地址空间上的一个地址,通过这个地址,可以找到线程的基本信息,比如线程 ID、线程栈、寄存器等属性。
这就连起来了:
- 第 3 章讲现象
- 第 4 章讲本质
4-4 进程地址空间里,线程到底怎么分布
- 这部分必须慢慢讲。
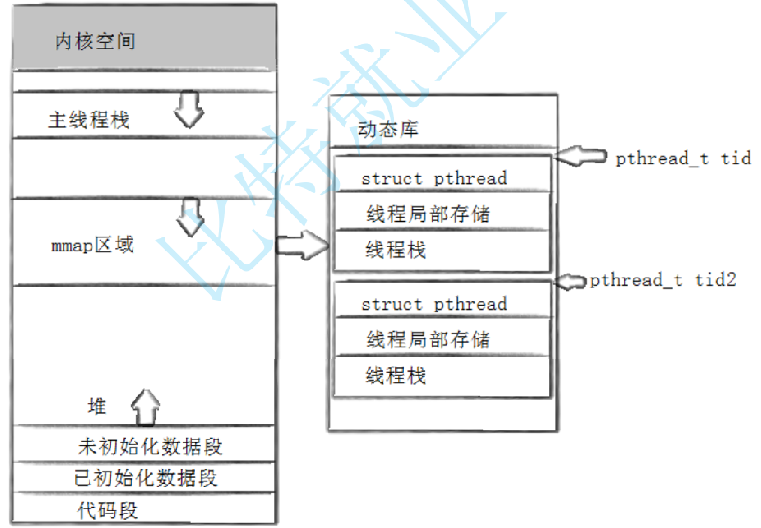
先说整个进程地址空间的大致布局一个典型进程的虚拟地址空间,大致理解成:
- 低地址:代码段
- 往上:已初始化数据段
- 再往上:未初始化数据段
- 再往上:堆(向上增长)
- 再往上:文件映射区 / 共享区 /
mmap区 - 高地址附近:主线程栈(向下增长)
- 更高:内核空间
这个结构不是线程专属,是整个进程本来就有的虚拟地址空间布局。
线程加入后,发生了什么
当一个进程只有主线程时:
- 主线程就在
main那条执行流上运行 - 主线程栈就是平常函数调用用的那个栈
当你 pthread_create 创建子线程时:
- 进程不会重新生成一个新地址空间
- 而是在同一个进程地址空间里,再给子线程准备一块独立的线程运行区域
这块区域通常就在:
mmap区 / 文件映射区 / 共享区
里面会放子线程自己的那套东西。
4-5 主线程栈和子线程栈,为什么位置不一样
这是面试和理解源码都很关键的点。
主线程栈
主线程本质上是进程启动时就天然存在的那条执行流。它的栈就是大家熟悉的进程栈,也就是 main 及其调用链用的那块栈空间。
- 对 Linux 进程或者主线程,简单理解就是
main函数的栈空间 - 它在
fork时会被继承,写时拷贝 - 而且它可以动态增长
- 超出上限才会栈溢出报段错误
所以主线程栈的特点是:
- 传统
- 天然
- 靠近高地址
- 向下增长
- 具备一定动态扩展特性
子线程栈
- 子线程的栈不再是那种普通意义上动态向下生长的进程栈
- 而是事先固定下来的
- 一般由
pthread_create在文件映射区/共享区中创建 - 底层使用
mmap分配出来
也就是说:
子线程栈不是"系统默认送你的那块主栈",而是 pthread 库额外给你映射出的一块内存。
这块内存的特点是:
- 固定大小
- 一般在
mmap区 - 属于线程私有使用
- 不是主线程那种天然进程栈
默认大小一般是 8MB。所以你以后要形成一个正确画面:
- 主线程栈:原生进程栈
- 子线程栈 :pthread 库
mmap出来的独立栈
4-6 为什么说子线程栈"原则上私有,但实际上别人也能访问"
- 子线程的 stack 是在进程地址空间中 map 出来的一块内存区域
- 原则上是线程私有的
- 但是同一个进程的所有线程共享地址空间
- 如果愿意,其他线程还是可以访问到的,所以一定要注意
理解
"私有"说的是设计语义和使用约定:
- 这块栈是给某个线程自己函数调用、局部变量、返回地址使用的
- 正常程序设计里,别的线程不该碰它
但"共享地址空间"意味着:
- 只要拿到了那个地址
- 理论上别的线程也可以读写那块内存
因为线程之间没有像进程那样的地址空间隔离。所以真正准确的话是:
线程栈是"逻辑上私有",不是"物理上不可见"。
这也是多线程危险的来源之一。你乱传指针、越界写内存、拿着别的线程栈上地址乱用,都可能把程序弄崩。
第 3 章你看到的是接口层现象
pthread_createpthread_selfpthread_joinpthread_detach
第 4 章你看到的是地址空间和实现层本质
pthread_t不等于LWPpthread_t在当前 NPTL 下本质像一个地址- 主线程栈在普通栈区
- 子线程栈在
mmap/ 共享区 - 同一个进程所有线程共享虚拟地址空间,但每个线程保留自己那份栈和寄存器信息
第五章 线程封装
怎么把前面学的 pthread 接口,封装成一个像样的 C++ 类。
给了一个 Thread.hpp 和 main.cc 的例子,核心目的是让你把:
- 创建线程
- 启动线程
- join / detach
- 线程命名
这些功能对象化。
待完成
第六章 附录:源码阅读,理解线程
待整理
1)pthread_create 背后的主流程图
pthread_create -> 分配 pd/stack -> 保存 start_routine/arg -> 返回 pthread_t(pd) -> create_thread -> clone
2)两句最关键源码
这两句非常值得摘:
pd->start_routine = start_routine;*newthread = (pthread_t)pd;
这两句直接对应:
- 用户函数被保存到线程描述对象里
pthread_t本质上像个地址
3)线程栈怎么来的
- 主线程栈:进程原生栈,可动态增长
- 子线程栈:
pthread_create底层通过mmap在映射区分配,通常固定大小,默认一般是 8M 左右,不能像主线程栈那样自然扩展。
4)线程库和内核分工
- 线程库负责:属性、tcb、线程栈、API 封装
- 内核负责:通过
clone真正创建和调度线程
这正是第六章最后想让你明白的。