小罗碎碎念
在精准医疗的时代,病理是癌症诊断的"金标准",而AI是让这个金标准更精准、更普惠的核心工具。CytoSyn的出现,不是终点,而是一个全新的起点:未来,它或许能生成完整的全切片图像,能结合基因组、转录组数据生成对应的病理切片,能帮我们更早地发现癌症、更准确地判断预后,让每一个患者,都能享受到精准医疗带来的希望。
本文核心内容来自Owkin团队发布的技术报告《CytoSyn: a Foundation Diffusion Model for Histopathology》,核心作者为Thomas Duboudin、Xavier Fontaine等;

模型权重、训练数据集与合成样本已开源至Hugging Face平台:https://huggingface.co/Owkin-Bioptimus/CytoSyn/tree/main。
过去几年,计算病理领域迎来了爆发式发展。
基于自监督学习训练的基础特征提取器,靠着海量数字化病理切片,在细胞分割、肿瘤分型、生存分析等任务上,全面超越了传统有监督模型,成了病理医生的"智能读片助手"。
但这些"读片型"AI,随着时间的发展,很多缺点也暴露了出来:
- 它没法解决黑箱可解释性难题:你只能知道它判断了什么,却不知道它为什么这么判断,更无法做反事实推演------比如"如果这个组织没有炎症,切片会是什么样?";
- 它做不了天生的生成类任务:不同医院的染色剂、扫描仪差异巨大,同一份组织的切片色差能天差地别,AI直接"认不出来",而能统一染色风格、保留诊断信息的虚拟染色,是大部分读片模型无法直接实现的;
- 它破不了罕见病的数据魔咒:全球7000多种罕见病中,绝大多数可用病理切片不足百张,传统的旋转、缩放数据增强,根本创造不出有生物学多样性的新样本,AI连训练的基础数据都没有。
更尴尬的是,此前主流的图像生成扩散模型,全都是在自然图像上训练的"通用画师",擅长画风景、人物,却对病理切片完全水土不服------病理图像里一个细胞核的形态、一处腺体的排列,都藏着决定生死的诊断信息,通用模型根本抓不住这些细微却致命的细节。
就在这个行业困局下,全球医疗AI领军企业Owkin的研究团队,带来了CytoSyn------首个专为病理图像打造的开源潜扩散基础大模型。
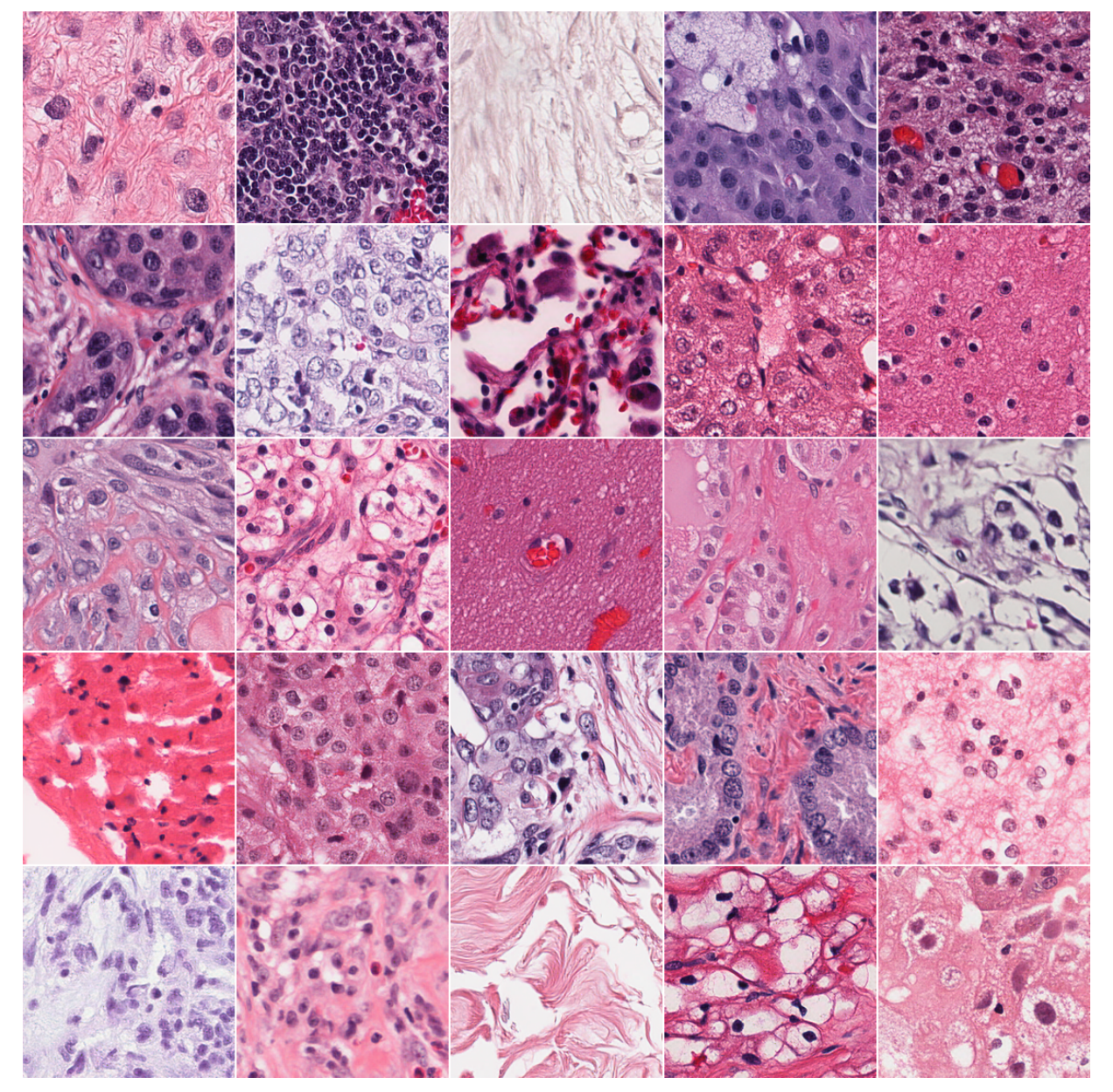
它不仅能生成高度逼真、符合生物学规律的H&E染色病理切片,还能在从未见过的疾病类型上保持顶尖性能,打破了传统病理AI的能力边界。
医学AI交流群
目前小罗全平台关注量120,000+,交流群总成员3000+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
科研服务
我们是一支由国内外顶尖高校硕博组成的科研团队,能够提供一系列医工交叉前沿的科研服务。
有兴趣的老师欢迎扫码与我们取得联系!
一、给病理AI装上"精准绘图引擎"
CytoSyn的核心突破,不是对通用扩散模型的简单微调,而是把整个架构从头到尾做了病理专属的定制化改造,让它从一个"什么都能画两笔的通用画师",变成了一个精通病理底层规律的"专业病理绘图师"。
在拆解它的设计之前,我们先用通俗的语言,搞懂两个核心概念:
扩散模型
你可以把它想象成一个"逆向还原游戏"。
先给一张清晰的病理切片,一步步往上面加噪点,直到变成满是雪花的黑屏;再让AI学习这个过程的逆操作------从黑屏雪花里,一步步去掉噪点,还原出清晰的病理切片。
在反复的还原中,AI就彻底学会了病理图像的所有底层规则:细胞该长什么样、组织该怎么排列、正常和病变的区别是什么。
潜扩散模型(LDM)
给这个游戏加了个"高效buff"。
先通过一个叫VAE(变分自编码器)的工具,把高清病理切片压缩成一张小尺寸的"特征图纸",所有核心生物学信息都浓缩在这张图纸里;然后在图纸上做扩散还原,最后再用VAE把图纸还原成高清大图。
这样不仅大幅降低了算力消耗,还能更精准地控制生成图像的核心特征。
CytoSyn的所有创新,都围绕着"让生成的病理图不仅看着像,更要在生物学上100%正确"这个核心目标,分三步完成了全链路的定制化设计。
第一步:打造病理专属的"图像翻译官"
论文里明确指出,此前的病理生成模型(比如行业标杆PixCell),用的都是Stable Diffusion里预训练好的VAE。
这个VAE是在海量自然图像上训练的,就像一个只会翻译日常用语的翻译官,你让它翻译病理领域的"专业术语",必然会丢三落四------它会把细胞核形态、腺体结构这些对诊断至关重要的细节,当成"无关信息"直接丢掉。
而CytoSyn做的第一个关键改造,就是用海量病理切片,从头训练了一个专属的SD-VAE模型。
这个VAE从诞生起,就只看病理切片、只学病理图像的特征,就像一个专门培养的病理专业翻译官,能精准地把病理切片里的每一个关键诊断信息,完整压缩到"特征图纸"里,再丝毫不差地还原出来,从根源上保证了生成图像的细节准确性。
第二步:给AI找个"资深病理导师"
如果说专属VAE保证了画出来的图"看着像病理切片",那这一步的改造,就保证了画出来的图"在生物学上是对的"。
传统的潜扩散模型,训练时只有一个目标:还原的图和原图越像越好。
但病理切片不一样,哪怕两张图看着几乎一模一样,只要其中一张的细胞形态有细微错误,在诊断上就是天差地别。
所以CytoSyn基于REPA-E架构,做了一个核心创新:给AI找了一个"资深病理导师"------专门在病理数据上训练的自监督模型H0-mini。
这个H0-mini,是目前病理领域性能顶尖、同时又足够轻量化的特征提取器,就像一个有着几十年经验的病理专家,一眼就能看出切片里的核心生物学特征,判断它是否符合病理规律。
这个"导师"在CytoSyn里承担了两个核心功能,也是模型最核心的创新点:
表征对齐约束
在AI训练的每一步,生成的中间特征,都必须和H0-mini提取的原图特征做相似度对齐。
简单说,就是AI每画一笔,都要让导师检查,确保它画的每一个细胞、每一处组织,都符合病理的底层规律,不能乱画。
这就让AI不仅学会了"画得像",更学会了"画得对"。
特征条件引导
用H0-mini提取的参考图全局特征,作为生成的引导条件。
就像你给导师看一张参考切片,导师把这张切片的核心病理特征(比如是肺腺癌还是结肠腺癌,有没有炎症、坏死)告诉你,AI就照着这些特征来画,既能生成和参考图完全不同的新切片,又能100%保留核心的诊断信息。
论文实验显示,这种引导方式下,生成切片和参考图的特征余弦相似度最高可达0.91,几乎完全一致。
第三步:适配病理场景的"细节优化"
除了核心架构的改造,CytoSyn还针对病理领域的实际使用场景,做了一系列细节优化,每一处都踩中了行业的痛点:
固定生成224×224尺寸的切片
目前病理领域几乎所有的特征提取器、下游AI模型,输入的标准尺寸都是224×224,而此前的模型大多生成256×256的图像,使用时必须裁剪、缩放,极易丢失关键细胞细节。
CytoSyn直接生成标准尺寸的图像,拿来就能用,完全无需额外处理。
给VAE加上EMA(指数移动平均)
训练时给VAE的权重做平滑的移动平均,推理时用这个平均后的权重,就像给AI的"翻译官"加了稳定器,生成的图像质量更稳定,不会出现忽好忽坏的情况。
适配高效采样策略
采用SiT-XL/2扩散Transformer搭配Euler-Maruyama采样,哪怕是低步数采样,也能生成高质量图像,兼顾了生成速度和质量,让普通科研团队也能轻松使用。
二、CytoSyn性能到底如何?
论文里用了超过4万GPU小时的算力,做了极其全面的基准测试、跨领域泛化测试,还和目前行业唯一的开源病理扩散大模型PixCell做了深度对标,所有结果都证明:CytoSyn是目前病理生成领域的新标杆。
基准测试
为了全面验证模型的性能,团队用了TCGA数据库里10622张诊断用全切片图像,覆盖32种不同的癌症类型,提取了4000万到1.08亿个224×224的切片瓦片,训练了不同版本的模型。
同时,团队专门设计了两个验证集:val-in(和训练集同切片的无重叠瓦片)和val-out(完全未见过的新切片的瓦片),用来测试模型最容易踩坑的"切片级过拟合"问题。
更重要的是,团队没有只用传统的Inception V3计算指标,而是用了6种病理领域顶尖的专属特征提取器(包括HOptimus-0、Virchow 2、UNI2-h等)------只有病理专属模型,才能识别出生成图像里细微的生物学错误,评估标准远比通用模型严苛。
实验结果验证了模型的实力:
顶尖的真实度与多样性
性能最优的CytoSyn-v2模型,在val-out验证集上,用UNI2-h计算的弗雷歇距离(FD,衡量生成图像与真实图像的分布差异,数值越小越好)仅为15.1,Inception V3的FD低至3.9;
同时,精确率和召回率分别达到0.96和0.99,几乎拉满,说明生成的图像不仅和真实图像几乎无差异,还完整覆盖了真实数据的所有多样性,没有出现模式崩溃。
几乎无切片级过拟合
val-in和val-out集上的余弦相似度完全一致,均为0.80,说明模型没有死记硬背训练集的切片特征,而是真正学到了病理图像的通用规律,泛化能力极强。
反常识的行业发现
把训练数据从4000万瓦片扩大到1.08亿经过严格质控的瓦片,模型性能没有明显提升,甚至有轻微下降。
这说明CytoSyn在4000万瓦片时,就已经学到了H&E病理图像的核心底层规律,无需靠无限堆数据提升性能,对算力有限的科研团队极为友好。
跨领域泛化
一个模型是不是真正的"基础大模型",关键看它在从未见过的场景里,还能不能保持性能。
论文里专门做了一个极具挑战性的分布外(OOD)测试:用炎症性肠病(IBD)的切片数据测试模型。
- 首先,CytoSyn的训练数据全是肿瘤相关切片,从未见过炎症性肠病的非肿瘤切片;
- 其次,IBD切片来自完全不同的医院,用的是奥林巴斯扫描仪,而训练用的TCGA切片大多用徕卡设备,染色剂、扫描参数完全不同。
但实验结果让人惊艳:CytoSyn-v2在IBD数据集上,Inception V3的FD仅为8.6,这个数值甚至超过了PixCell在训练分布内的性能;而对标模型PixCell,在同样的数据集上FD高达26.7,是CytoSyn的3倍多。同时,CytoSyn的特征余弦相似度保持在0.73以上,远高于PixCell的0.49。
这意味着,CytoSyn真的学会了病理图像的通用生物学逻辑,而不是死记硬背肿瘤切片的样子。
哪怕是完全未见过的疾病类型、完全不同的扫描染色条件,它也能生成符合病理规律的高质量切片------这才是"基础大模型"真正的核心价值。
和行业标杆PixCell的正面PK
在CytoSyn之前,PixCell是病理生成领域唯一的开源基础大模型,也是公认的行业标杆。论文里完成了行业首个跨机构的病理扩散模型深度对标,不仅比出了性能高低,更挖出了整个领域长期忽略的核心问题。
团队先梳理了两个模型的核心差异:
- PixCell采用传统潜扩散架构,使用冻结的自然图像预训练VAE,用6.8亿参数的UNI2-h做引导;
- 而CytoSyn采用REPA-E架构,从头训练的病理专属VAE,仅用8600万参数的H0-mini做引导和对齐,推理时的显存需求远低于PixCell,更轻量化。
而在对标中,团队发现了一个有趣的现象:扩散模型的性能和评估指标,对图像尺寸、压缩格式这些看似不起眼的预处理细节,极其敏感。
最初直接用CytoSyn的验证流程测试PixCell,它的Inception FD高达61.5,和论文公布的数值差了一个数量级;但当团队把图像尺寸对齐到256×256,把验证集和引导图像都换成和PixCell训练时一致的JPEG格式(质量70),PixCell的FD直接降到了5.5,和原论文结果几乎一致。
这个发现的意义,甚至超过了性能对比本身:整个病理生成领域,此前都忽略了预处理细节对结果的巨大影响,导致不同团队的研究结果根本无法复现------你觉得你的模型好,可能只是因为你的预处理流程不一样,而不是模型真的更优秀。
CytoSyn的这项研究,给整个领域建立了更严谨、更可复现的评估标准。
而在所有预处理细节完全对齐之后,CytoSyn-v2的性能依然全维度超过PixCell:
- val-out集上,CytoSyn的Inception FD是3.9,PixCell是5.5;
- OOD的IBD数据集上,CytoSyn的FD是8.6,PixCell是26.7,差距巨大。
这证明,CytoSyn的架构创新带来的性能提升是实打实的,绝非靠预处理细节"刷分"。
三、CytoSyn给病理AI带来的无限可能
CytoSyn的出现,绝不仅仅是多了一个能画病理切片的AI模型,它给整个计算病理领域打开了一扇全新的大门,解决了很多此前根本无法解决的行业痛点。
首先,它打破了罕见病病理研究的"数据魔咒"。
罕见病难研究、难治疗的核心,就是病例太少,可用病理切片连AI训练的零头都不够。
而CytoSyn可以基于仅有的少量罕见病切片,生成大量符合生物学规律的新样本,给AI训练提供足够的"弹药",让罕见病的病理AI研发从不可能变成可能。
其次,它解决了病理AI临床落地的最大拦路虎:域偏移问题。
目前的病理AI,在训练医院的数据上准确率能到99%,但换一家医院、换个扫描仪,准确率就直接掉到60%以下,根本无法临床落地。
而CytoSyn可以实现"虚拟染色",把不同医院、不同设备生成的切片,转换成统一标准的风格,同时100%保留核心诊断信息,让AI不管拿到哪个医院的切片,都能准确识别,真正从实验室走向临床。
第三,它给病理AI的"黑箱问题"提供了全新解决方案。
现在的病理AI,医生只能知道它判断患者是癌症,却不知道它为什么这么判断,这也是临床医生不敢完全信任AI的核心原因。
而CytoSyn可以实现反事实生成,医生可以直接提问:"如果这个肿瘤里没有TP53基因突变,切片会变成什么样?",AI就能生成对应的切片,让医生直观看到AI的判断依据,把"黑箱"变成"白箱"。
第四,它解决了病理数据共享的隐私难题。
病理切片包含大量患者隐私信息,跨医院、跨国家的数据共享受到严格的合规限制,极大拖慢了全球研究进度。
而CytoSyn生成的合成病理数据,完全不包含任何患者隐私,可以自由共享、自由使用,让全球科研人员都能用上高质量的病理数据,加速癌症、罕见病的研究进程。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!
除以上全职岗位外,团队也正在招聘实习生/分析师(兼职)/讲师(兼职),欢迎医工交叉方向的优秀硕博,投递个人简历到团队邮箱:lxltx2025@163.com