本文将基于 ARM 架构的基础知识点,从指令集架构、核心寄存器、硬件功能单元、总线体系、存储系统、编译流程、工作模式与异常处理等进行拆解,同时搭配原理示意图帮助理解。
一、CPU 指令集架构的两大阵营:CISC 与 RISC 深度对比
指令集是 CPU 能够识别和执行的硬件指令的集合,是软件与硬件之间沟通的桥梁,直接决定了 CPU 的架构设计、硬件成本、功耗和性能表现。目前主流的 CPU 指令集分为两大体系:复杂指令集 CISC 和精简指令集 RISC,也是 ARM 架构的设计根基。
1.1 CISC(Complex Instruction Set Computer)复杂指令集计算机
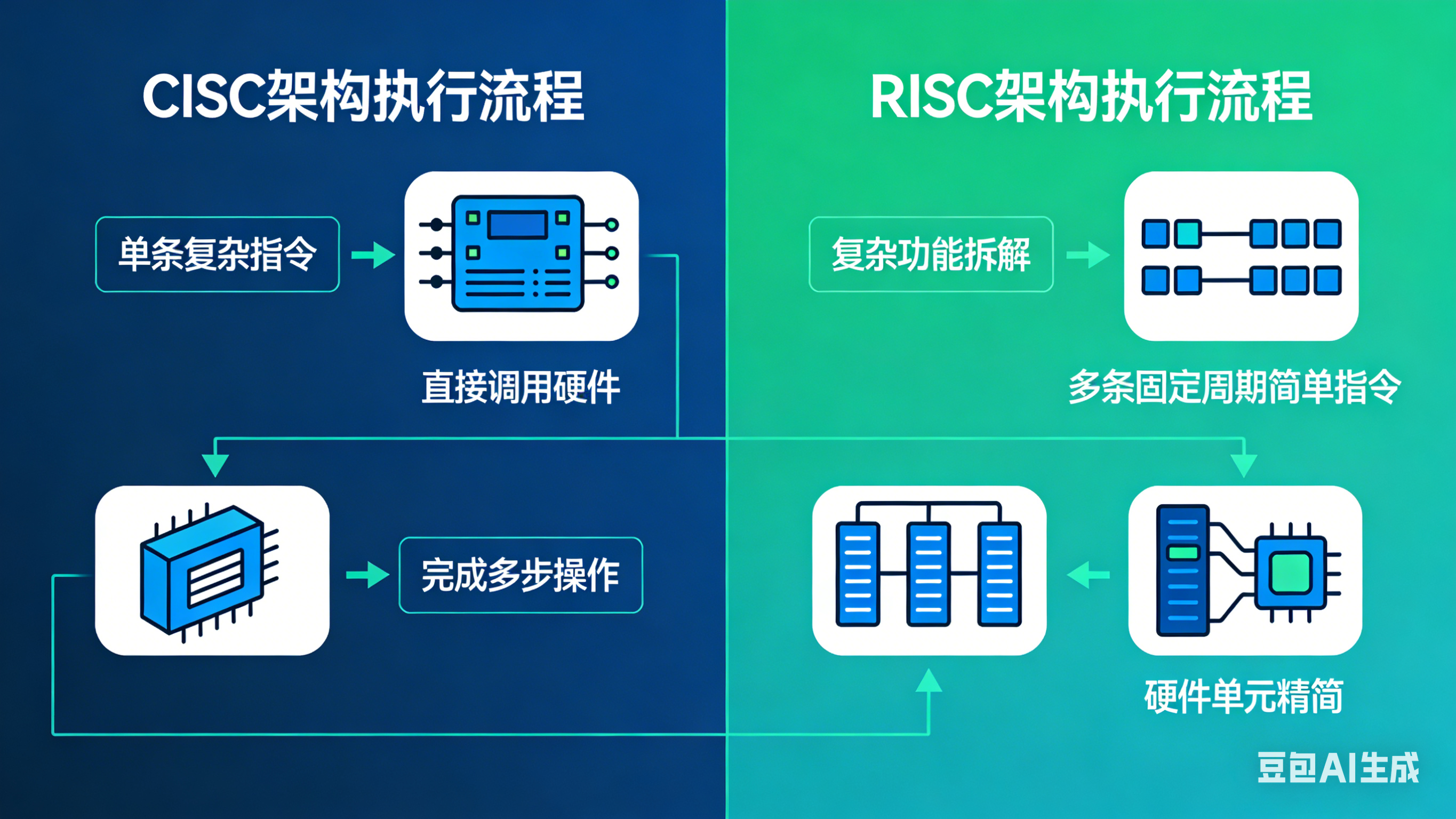
CISC 架构的核心设计思路,是通过丰富的、功能复杂的指令集,用单条指令完成多步操作,减少软件需要执行的指令数量,早期以提升编译效率为核心目标。
- 核心特点:芯片面积大、加工成本高、硬件结构复杂、体积大、功耗高;存在典型的2/8 效应------ 即 80% 的运行场景下,只使用到 20% 的指令,大部分复杂指令极少被用到。
- 典型应用:x86 架构 CPU,广泛用于台式机、笔记本电脑、服务器等对性能要求高、功耗约束相对宽松的设备。
1.2 RISC(Reduced Instruction Set Computer)精简指令集计算机
RISC 架构的核心设计思路,是摒弃复杂指令,只保留常用的、执行周期固定的简单指令,复杂功能通过多条简单指令组合实现,核心目标是降低硬件复杂度、优化功耗和体积。
- 核心特点:芯片面积小、加工成本低、功耗低、体积小,非常适合便携式、电池供电的嵌入式设备和移动终端。
- 典型应用:ARM 架构 CPU,是目前 RISC 架构最成功、应用最广泛的实现,覆盖了从低端微控制器到高端服务器的全场景。
1.3 CISC 与 RISC 核心差异对比
表格
| 对比维度 | CISC 复杂指令集 | RISC 精简指令集 |
|---|---|---|
| 设计理念 | 单条指令完成多步复杂操作 | 仅保留固定周期的简单指令,复杂功能拆分为多指令实现 |
| 指令周期 | 指令执行周期不固定,差异大 | 所有指令执行周期固定,多为单周期指令 |
| 硬件复杂度 | 硬件执行单元复杂,晶体管数量多 | 硬件执行单元精简,晶体管数量少 |
| 芯片面积与成本 | 芯片面积大,加工成本高 | 芯片面积小,加工成本低 |
| 功耗表现 | 功耗高,散热要求高 | 功耗极低,适合电池供电设备 |
| 代表架构 | x86 架构 | ARM 架构 |
| 核心应用场景 | 桌面 PC、服务器 | 嵌入式设备、移动终端、物联网 |
1.4 执行流程对比示意图
二、ARM 架构核心寄存器全解析
寄存器是 CPU 内核中最核心的高速存储单元,直接参与 CPU 的运算和指令执行,是 ARM 汇编开发、底层驱动开发的核心基础。ARM 架构的寄存器分为通用寄存器和专用系统寄存器,不同内核版本的寄存器数量不同:ARM9 内核共有 37 个寄存器,Cortex-A 系列内核共有 40 个寄存器。
2.1 ARM 通用寄存器组
ARM32 位架构下,通用寄存器包括 R0-R12,共 13 个通用寄存器,用于常规的算术运算、逻辑运算、数据暂存。函数调用时遵循 ATPCS 调用规则:R0-R3 用于传递函数入参和返回值,R4-R11 用于函数内的局部变量暂存,无特殊需求时函数内需要保护这些寄存器的值。
2.2 ARM 专用功能寄存器(R13-R15)
这三个寄存器是 ARM 架构中最核心的专用寄存器,每个都有不可替代的功能,也是嵌入式开发面试中的高频考点。
2.2.1 SP(R13):栈指针寄存器(Stack Pointer)
- 核心作用:专门用于管理 CPU 的栈内存区域,始终指向当前栈的栈顶位置。
- 工作原理:栈是内存中一段遵循 "先进后出(FILO)" 规则的存储区域,函数调用、中断异常发生时,会通过 SP 寄存器完成现场寄存器的入栈保护,函数返回 / 异常返回时完成出栈恢复。
- 关键特性:ARM 架构中,每个特权模式都有独立的 SP 寄存器,避免不同模式下的栈操作互相干扰。
2.2.2 LR(R14):链接寄存器(Link Register)
- 核心作用:专门用于存储函数调用或异常发生时的返回地址,是实现函数调用与返回、异常处理返回的核心。
- 工作原理:
- 当执行 BL/BLX 指令调用函数时,CPU 会自动将下一条指令的地址存入 LR 寄存器;
- 函数执行完成后,通过将 LR 寄存器的值赋值给 PC 寄存器,即可跳回函数调用的位置继续执行后续代码;
- 异常发生时,LR 寄存器会保存异常处理完成后的返回地址,用于异常返回。
2.2.3 PC(R15):程序计数器(Program Counter)
- 核心作用:本质是 CPU 的指令指针,始终指向当前正在执行指令的下一条指令的内存地址,决定了 CPU 的代码执行流向。
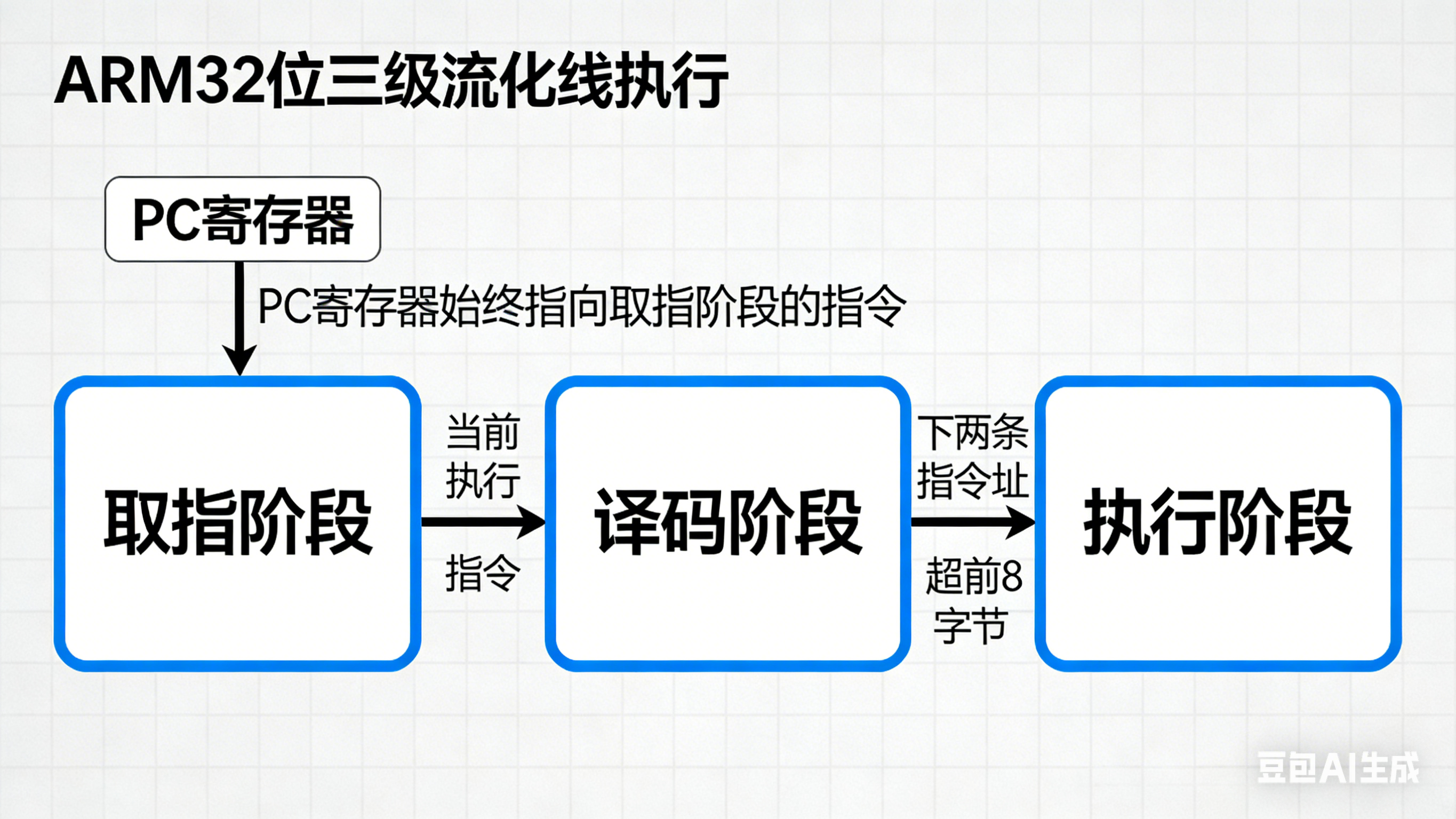
- 关键特性:ARM 架构下,CPU 采用三级流水线(取指、译码、执行),因此 PC 寄存器的值始终比当前正在执行的指令地址超前 8 个字节(32 位 ARM 状态下,每条指令 4 字节),这是汇编开发中必须注意的关键点。
- 开发应用:直接修改 PC 寄存器的值,即可实现代码的强制跳转,比如函数返回、异常向量跳转等。
2.3 三级流水线与 PC 寄存器对应关系示意图
时钟周期: T1 T2 T3 T4
指令 A: | 取指 | | 译码 | | 执行 |
指令 B: | 取指 | | 译码 | | 执行 |
指令 C: | 取指 | | 译码 | | 执行 |
PC 指针: 指向 A 指向 B 指向 C 指向 D
(取指地址) (取指地址) (取指地址) (取指地址)
2.4 程序状态寄存器:CPSR 与 SPSR
这两个寄存器用于管理和保存 CPU 的运行状态,是中断、异常处理的核心。
2.4.1 CPSR:当前程序状态寄存器(Current Program Status Register)
- 核心作用:全局唯一,实时保存 CPU 当前的运行状态,包括运算结果标志位、中断使能位、处理器工作模式、处理器状态(ARM/Thumb)等。
- 核心位域(32 位):
- 条件标志位:N(负号标志)、Z(零标志)、C(进位标志)、V(溢出标志),用于判断算术运算的结果,实现条件跳转;
- 中断控制位:I 位(IRQ 中断使能 / 禁止)、F 位(FIQ 中断使能 / 禁止);
- 模式位:M0-M4 位,决定 CPU 当前的工作模式(User、FIQ、IRQ 等);
- 状态位:T 位,决定 CPU 运行在 ARM 状态(32 位指令)还是 Thumb 状态(16 位指令)。
2.4.2 SPSR:备份程序状态寄存器(Saved Program Status Register)
- 核心作用:异常发生时,自动备份当前 CPSR 寄存器的值,用于异常返回时恢复 CPU 的运行状态。
- 工作原理:ARM 架构中,每个异常模式都有独立的 SPSR 寄存器,避免多个异常同时发生时,CPSR 的备份值被覆盖。异常发生时,硬件自动将 CPSR 拷贝到对应异常模式的 SPSR 中;异常返回时,将 SPSR 的值恢复到 CPSR,还原异常发生前的 CPU 状态。
2.5 CPSR 与 SPSR 工作机制示意图
三、ARM 核心硬件功能单元深度解析
3.1 MMU:内存管理单元(Memory Management Unit)
MMU 是 Cortex-A 系列等高端 ARM 内核的核心硬件单元,是 Linux、Android 等操作系统能够运行的核心基础。
3.1.1 MMU 的核心作用
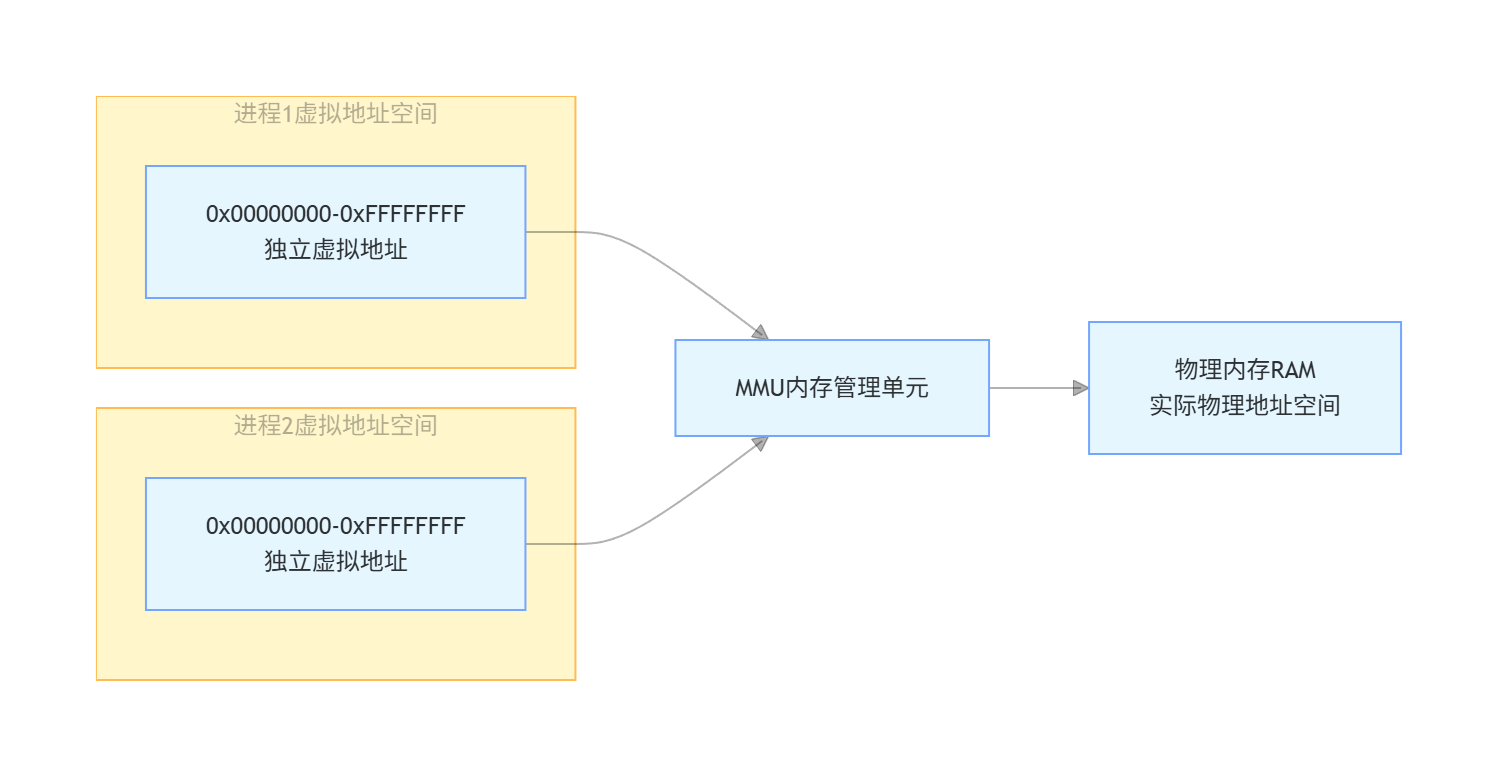
- 核心功能:实现虚拟内存地址到物理内存地址的映射,同时提供内存访问权限管理、内存缓存属性配置。
- 核心价值:
- 提升物理内存利用率:操作系统可以为每个进程分配独立的虚拟地址空间,进程之间互不干扰,实现内存的分时复用;
- 内存保护:通过地址映射和权限管理,防止进程非法访问其他进程或内核的内存空间,提升系统稳定性和安全性;
- 地址空间扁平化:让开发者无需关心物理内存的实际分布,只需要操作统一的虚拟地址,简化开发难度。
3.1.2 开发关键注意事项
在 ARM 裸机开发中,芯片上电启动的初期,必须关闭 MMU,同时需要打开指令缓存 I-Cache,关闭数据缓存 D-Cache。这是因为 MMU 关闭时,CPU 访问的是物理地址,地址映射是 1:1 的,保证启动代码的执行地址和链接地址一致,避免地址错乱。
3.2 MMU 地址映射示意图
3.3 Cache:高速缓存单元
Cache 是 CPU 内核与主存(RAM)之间的高速缓冲存储器,解决了 CPU 运算速度远快于主存读写速度的性能瓶颈,是提升 CPU 执行效率的核心单元。
3.3.1 Cache 的核心工作原理
CPU 读取数据 / 指令时,会先访问 Cache,如果 Cache 中存在需要的内容(缓存命中),则直接从 Cache 中高速读取,无需访问低速的主存;如果缓存未命中,再从主存中读取数据,同时将数据缓存到 Cache 中,保证后续访问的命中率。
3.3.2 I-Cache 与 D-Cache 的分类与区别
ARM 架构基于哈佛架构设计,将指令和数据分开存储和访问,因此 Cache 也分为独立的指令缓存和数据缓存:
- I-Cache(Instruction Cache):指令缓存,专门用于缓存 CPU 要执行的指令代码,只读属性,不存在数据一致性问题,芯片启动初期即可打开;
- D-Cache(Data Cache):数据缓存,专门用于缓存 CPU 运算过程中的数据,读写属性,存在缓存与主存的数据一致性问题,需要 MMU 开启后配合地址映射使用,裸机启动初期需要关闭。
3.3.3 冯・诺依曼架构与哈佛架构的核心区别
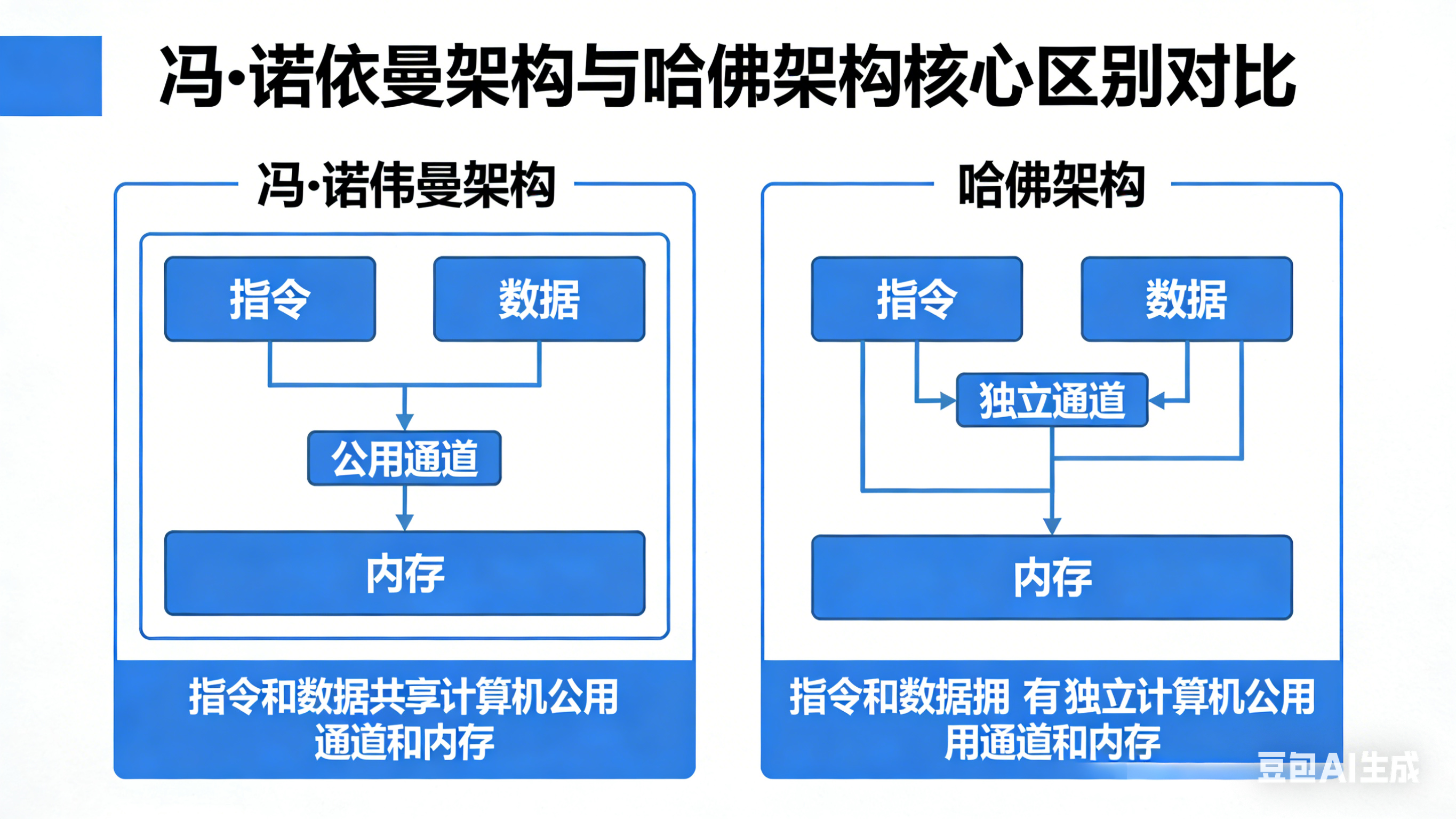
- 冯・诺依曼架构:指令和数据存放在同一片内存空间,共用一套地址总线和数据总线,结构简单,但指令和数据的访问存在总线竞争,无法并行读取,早期的 ARM 内核、x86 架构采用该设计;
- 哈佛架构:指令和数据分开存储在独立的内存空间,拥有独立的地址总线和数据总线,CPU 可以同时读取指令和读写数据,并行度更高,性能更强,现代 ARM 内核、DSP、MCU 均采用哈佛架构设计,也是 I-Cache 和 D-Cache 能够独立工作的基础。
3.4 两种架构对比示意图
四、ARM 总线架构全解析
总线是 CPU 内核与外设、存储器之间进行数据传输的 "高速公路",总线的设计直接决定了 SoC 的整体数据传输性能和外设扩展能力。
4.1 单总线通信与多总线通信的核心区别
表格
| 对比维度 | 单总线通信 | 多总线通信 |
|---|---|---|
| 硬件结构 | 单根 / 单组总线连接所有外设,结构简单 | 多组独立总线,通过桥接器互联,结构复杂 |
| 通信规则 | 同一时刻只能有一对设备占用总线,其他外设无法接入 | 不同总线可并行传输数据,同总线内分时复用 |
| 传输效率 | 总线竞争严重,传输效率低 | 无总线竞争,并行传输,效率极高 |
| 成本与布线 | 硬件成本低,布线难度小 | 硬件成本高,布线设计难度大 |
| 适用场景 | 外设少、速率要求低的简单系统 | 外设丰富、速率要求高的复杂 SoC 系统 |
4.2 AMBA 总线:AHB 高速总线与 APB 外设总线
现代 ARM SoC 芯片普遍采用 ARM 公司推出的 AMBA(Advanced Microcontroller Bus Architecture)总线协议,其中最核心的就是 AHB 高速总线和 APB 外设总线,组成经典的双总线架构。
4.2.1 AHB 总线(Advanced High-performance Bus):先进高性能总线
- 核心定位:系统高速总线,用于连接 CPU 内核与高速外设、高速存储器,是 SoC 的 "主干道"。
- 核心特点:高带宽、高时钟频率、支持流水线操作、支持突发传输,传输速率极高。
- 典型挂载外设:USB 高速接口、以太网网卡、DDR RAM/SRAM 内存、DMA 控制器、LCD 控制器等高速设备。
4.2.2 APB 总线(Advanced Peripheral Bus):先进外设总线
- 核心定位:低速外设总线,通过桥接器挂载在 AHB 总线上,用于连接低速、低带宽的外设,是 SoC 的 "分支小路"。
- 核心特点:低功耗、低带宽、结构简单、无流水线设计,时钟频率远低于 AHB 总线,降低系统功耗。
- 典型挂载外设:GPIO 通用输入输出口、UART 串口、I2C/SPI 总线、ADC/DAC、看门狗、定时器等低速外设。
4.3 AHB/APB 双总线拓扑结构图
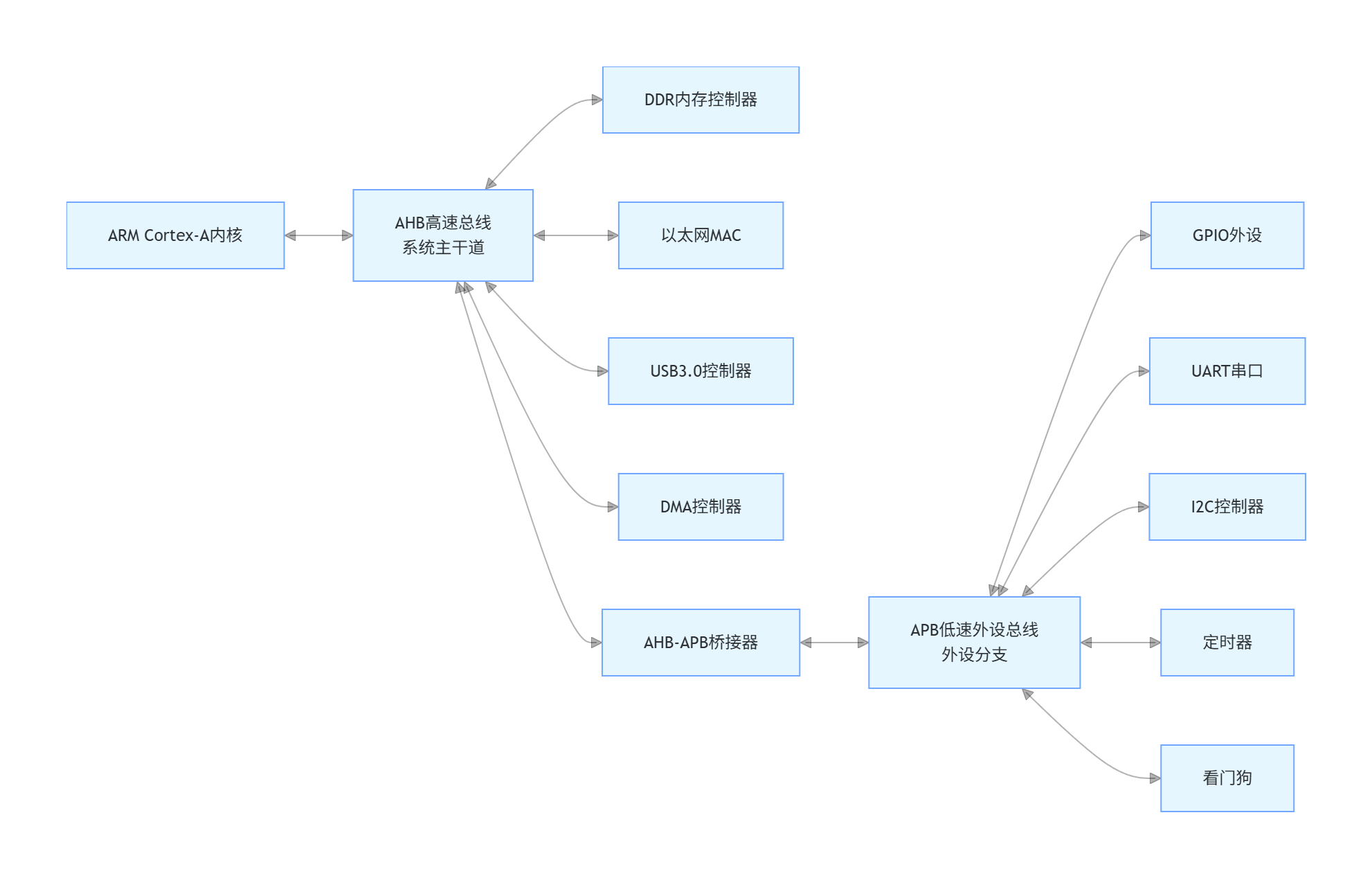
图注:ARM SoC 典型双总线架构,高速设备直接挂载在 AHB 总线,低速设备通过桥接器挂载在 APB 总线,实现高低速设备的隔离与并行传输。
五、ARM 存储体系全解析
嵌入式系统中,存储器是核心硬件组成,不同类型的存储器有着完全不同的特性、寻址方式和应用场景,是底层驱动开发必须掌握的知识点。
5.1 存储器的核心分类
- 易失性存储器:掉电后数据完全丢失,读写速度极快,用于程序运行时的数据和指令暂存,典型代表:RAM(随机存取存储器),比如 SRAM、DDR SDRAM。
- 非易失性存储器:掉电后数据不会丢失,用于长期存储程序代码、用户数据,典型代表:ROM、Nor Flash、Nand Flash、EEPROM。
5.2 Nor Flash 与 Nand Flash 的核心区别
这是嵌入式系统中最常用的两种非易失性 Flash 存储器,核心差异集中在寻址方式和性能特性上:
表格
| 特性维度 | Nor Flash | Nand Flash |
|---|---|---|
| 寻址能力 | 支持字节级随机寻址,每一个字节都有独立的地址,地址总线与数据总线分离 | 不支持字节级随机寻址,只能以固定块(Page/Block)为单位进行读写和擦除,典型块大小 512Byte/2KB |
| 读性能 | 随机读速度极快,支持 XIP(芯片内执行),程序可直接在 Nor Flash 中运行 | 随机读速度慢,连续读速度快,适合批量数据存储 |
| 写 / 擦除性能 | 擦除速度慢,最小擦除单位为扇区(一般 64KB) | 擦除速度极快,最小擦除单位为块,适合频繁写入数据 |
| 容量与成本 | 容量小(1MB-128MB),单位容量成本高 | 容量大(128MB - 几 TB),单位容量成本极低 |
| 应用场景 | 嵌入式系统启动代码(Bootloader)、固件程序存储 | 用户数据存储、固态硬盘、U 盘、存储卡 |
5.3 典型 EEPROM:AT24C02
AT24C02 是典型的 I2C 接口 EEPROM,容量为 2048bit(256Byte),支持字节级随机读写,掉电数据不丢失,常用于存储设备的配置参数、校准数据等小容量非易失性数据存储。
5.4 寻址方式对比示意图
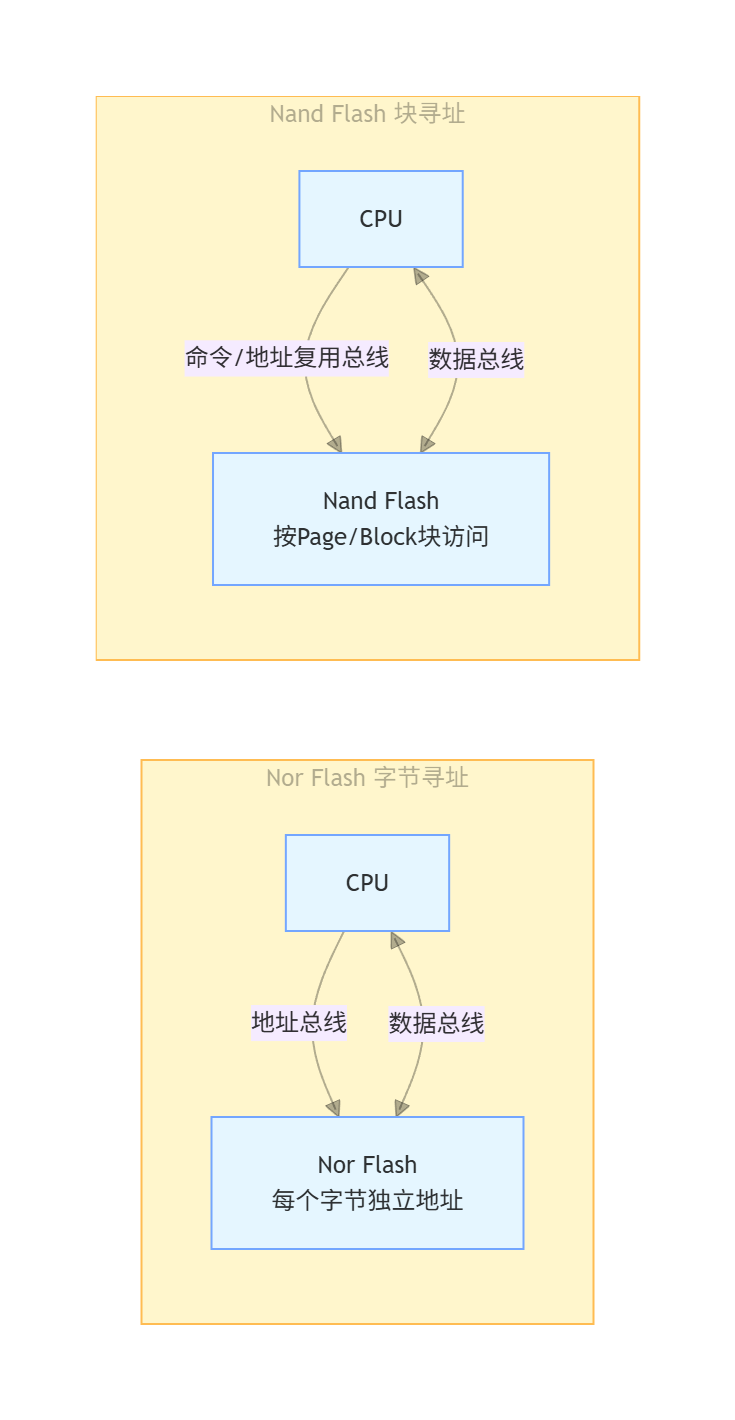
六、ARM 指令集移位操作深度解析
移位操作是 ARM 汇编中最基础、最常用的运算操作,分为算术右移 ASR、逻辑右移 LSR、循环右移 ROR,不同的移位操作适用场景完全不同,也是嵌入式开发中的高频考点。
ARM32 位架构中,移位操作的对象是 32 位二进制数,下面分别拆解每种移位的原理、适用场景和计算示例。
6.1 ASR:算术右移(Arithmetic Shift Right)
- 核心定义:专门针对 ** 有符号数(signed int)** 的右移操作,移位时最高位(符号位)保持不变,始终补符号位,移出的最低位进入 CPSR 的 C 标志位。
- 核心原理:有符号数的最高位是符号位,0 代表正数,1 代表负数,算术右移时补符号位,保证移位前后数值的符号不变,相当于数学中的 "除以 2 的 n 次方"。
- 计算示例:
-
有符号负数
signed int i = 0xFFFFFFFF;(十进制 - 1),执行i >>= 1;(ASR 右移 1 位)二进制原码:1111 1111 1111 1111 1111 1111 1111 1111算术右移 1 位后:1111 1111 1111 1111 1111 1111 1111 1111(最高位补 1,符号位不变),结果仍为 - 1。 -
有符号正数
signed int i = 0x7FFFFFFF;(32 位有符号数最大值),执行i >>= 1;(ASR 右移 1 位)二进制原码:0111 1111 1111 1111 1111 1111 1111 1111算术右移 1 位后:0011 1111 1111 1111 1111 1111 1111 1111(最高位补 0,符号位不变),结果为原数除以 2。
-
6.2 LSR:逻辑右移(Logical Shift Right)
- 核心定义:专门针对 ** 无符号数(unsigned int)** 的右移操作,移位时最高位固定补 0,移出的最低位进入 CPSR 的 C 标志位。
- 核心原理:无符号数没有符号位,所有位都是数值位,逻辑右移时统一补 0,相当于无符号数的 "除以 2 的 n 次方"。
- 计算示例:无符号数
unsigned int i = 0xFFFFFFFF;(十进制 4294967295),执行i >>= 1;(LSR 右移 1 位)二进制原码:1111 1111 1111 1111 1111 1111 1111 1111逻辑右移 1 位后:0111 1111 1111 1111 1111 1111 1111 1111(最高位补 0),结果为原数除以 2。
6.3 ROR:循环右移(Rotate Right)
- 核心定义:循环移位操作,移位时将移出的最低位,同时补到最高位,形成闭环的循环,移出的位同时会进入 CPSR 的 C 标志位。
- 核心原理:不区分有符号数和无符号数,所有位参与循环,不会丢失任何二进制位,常用于数据校验、位操作、加密算法等场景。
- 计算示例:32 位数
unsigned int i = 0xFFFFFFFE;(二进制1111 1111 1111 1111 1111 1111 1111 1110),执行 ROR 循环右移 1 位移出的最低位是 0,循环补到最高位,结果为:0111 1111 1111 1111 1111 1111 1111 1111(0x7FFFFFFF)。
6.4 三种右移操作位变化示意图

七、ARM 程序编译全流程拆解
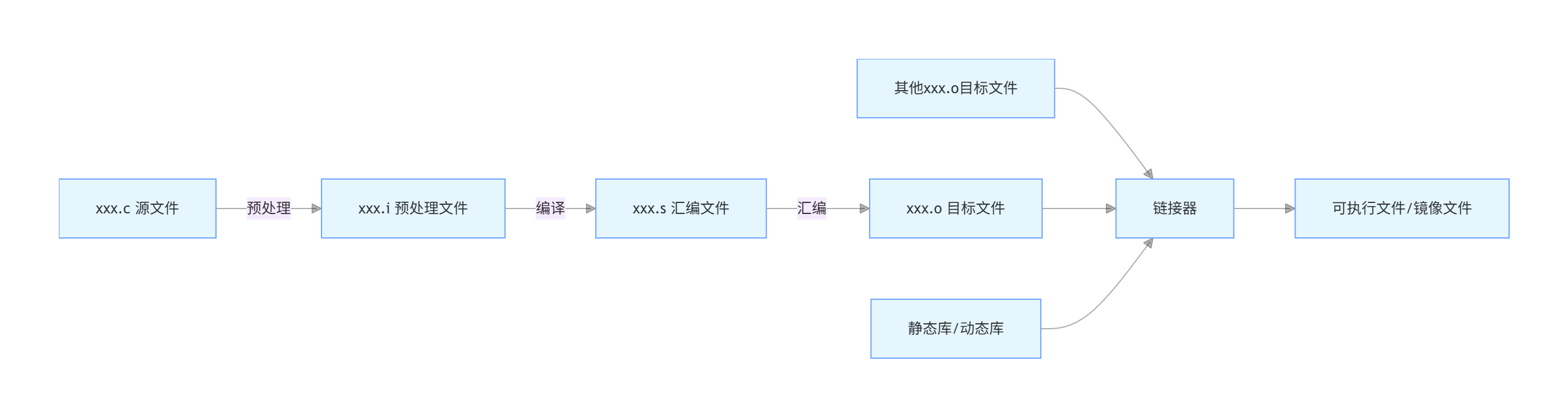
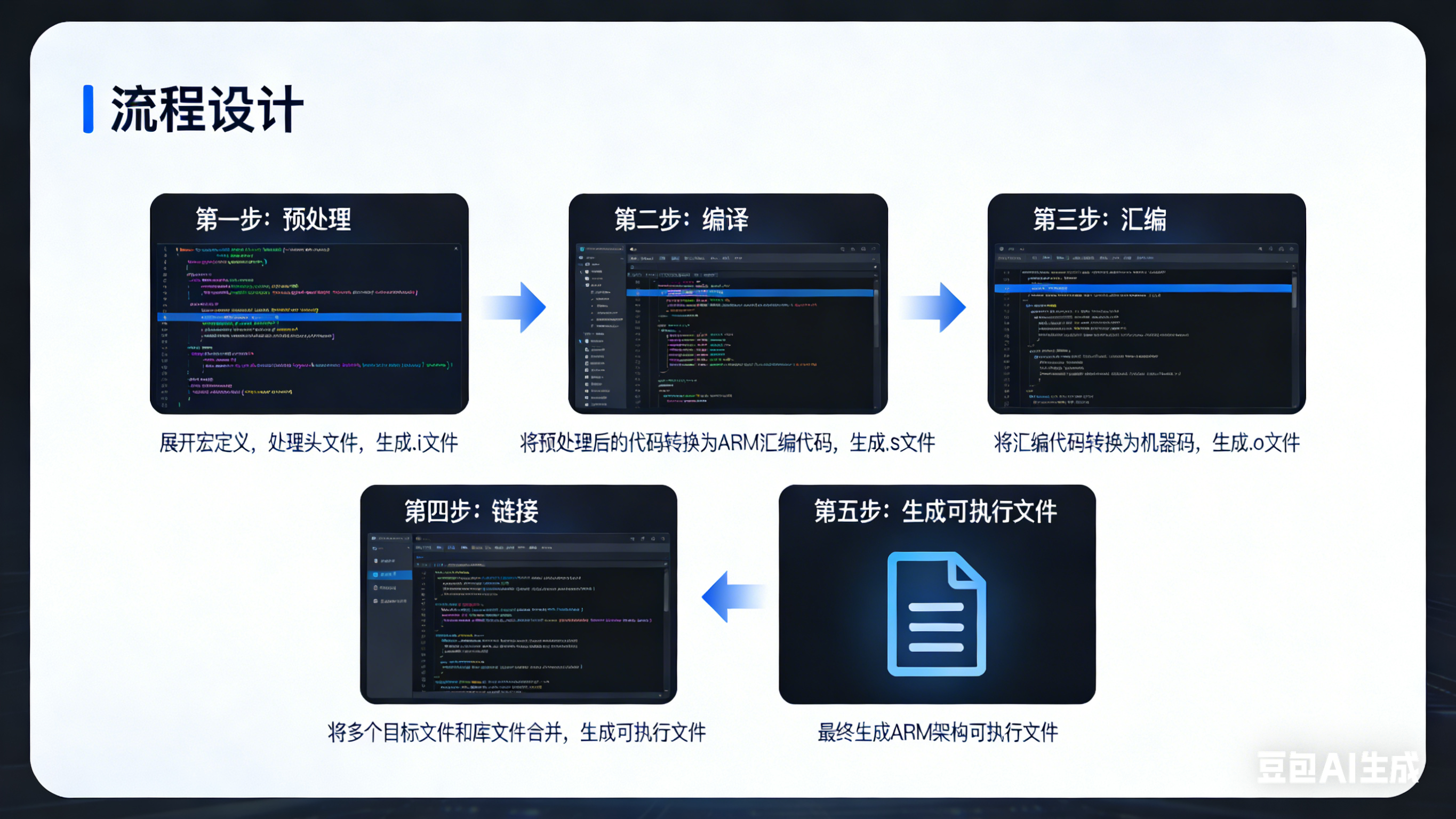
我们编写的 C 语言 / 汇编代码,需要经过完整的编译流程,才能转化为 ARM CPU 能够直接执行的二进制机器码,整个流程分为 4 个核心阶段,每个阶段都有明确的处理逻辑和输出文件。
7.1 阶段 1:预处理(Preprocessing)
- 输入文件:C 语言源文件(xxx.c)
- 输出文件:预处理后的文件(xxx.i)
- 核心处理操作:
- 头文件展开:将 #include 包含的头文件内容,完整展开到当前 C 文件中;
- 宏定义替换:将代码中所有的宏定义(#define),替换为对应的实际内容;
- 条件编译处理:根据 #ifdef、#ifndef、#if 等条件编译指令,保留符合条件的代码,剔除不符合条件的代码;
- 注释删除:删除代码中的所有单行注释(//)和多行注释(/* */)。
7.2 阶段 2:编译(Compilation)
- 输入文件:预处理后的 xxx.i 文件
- 输出文件:汇编语言文件(xxx.s)
- 核心处理操作:编译器对预处理后的 C 代码进行词法分析、语法分析、语义分析、代码优化,最终将 C 语言代码转化为对应的 ARM 汇编代码,这是整个编译流程中最核心的阶段。
7.3 阶段 3:汇编(Assembly)
- 输入文件:汇编代码文件(xxx.s)
- 输出文件:目标文件(xxx.o,ELF 格式)
- 核心处理操作:汇编器将汇编代码逐条翻译为对应的 ARM 二进制机器指令,生成可重定位的目标文件。目标文件中已经是二进制机器码,但是其中的全局变量、外部函数调用的地址还没有完成最终的地址分配,无法直接执行。
7.4 阶段 4:链接(Linking)
- 输入文件:多个 xxx.o 目标文件、静态库(.a)、动态库(.so)
- 输出文件:可执行文件(ARM Linux 下为 ELF 格式可执行文件,裸机开发为 bin/hex 镜像文件)
- 核心处理操作:
- 地址与空间分配:为所有目标文件的代码段、数据段分配统一的虚拟地址空间,确定最终的运行地址;
- 符号解析与重定位:解析所有全局变量、外部函数的符号引用,完成地址重定位,将符号引用替换为实际的内存地址;
- 库文件链接:将静态库的代码直接链接到可执行文件中,或确定动态库的调用关系,最终生成 CPU 可以直接加载执行的可执行文件。
7.5 编译全流程示意图
八、ARM 处理器工作模式与异常处理机制
ARM 架构的工作模式和异常处理机制,是嵌入式操作系统移植、中断驱动开发、异常故障定位的核心基础,也是 ARM 架构的核心特性。
8.1 ARM 处理器的 7 种工作模式
ARM32 位架构定义了 7 种工作模式,除了 User 模式外,其余 6 种均为特权模式。特权模式可以自由访问系统所有资源,切换 CPU 的工作模式,而 User 模式是非特权模式,访问资源受到严格限制。
表格
| 工作模式 | 英文全称 | 模式类型 | 核心说明 |
|---|---|---|---|
| User(用户模式) | User Mode | 非特权模式 | 大部分应用程序、用户任务运行在该模式,无法直接访问硬件资源和修改模式,必须通过系统调用进入特权模式 |
| FIQ(快速中断模式) | Fast Interrupt Request Mode | 特权模式 | 高优先级快速中断触发时进入该模式,用于处理高速、实时性要求高的中断,拥有独立的寄存器组,减少现场保护的开销 |
| IRQ(普通中断模式) | Interrupt Request Mode | 特权模式 | 低优先级普通中断触发时进入该模式,用于处理常规的外设中断,是嵌入式开发中最常用的中断模式 |
| Supervisor(管理模式) | Supervisor Mode | 特权模式 | CPU 复位、软中断指令(SWI/SVC)执行时进入该模式,是操作系统内核运行的核心模式,Linux 系统的系统调用最终会进入该模式 |
| Abort(中止模式) | Abort Mode | 特权模式 | 内存存取异常发生时进入该模式,比如访问非法内存地址、读写权限错误,用于处理内存异常,实现虚拟内存的缺页中断 |
| Undef(未定义指令模式) | Undefined Instruction Mode | 特权模式 | CPU 执行到未定义、无法识别的指令时进入该模式,用于处理非法指令异常,可实现协处理器的软件仿真 |
| System(系统模式) | System Mode | 特权模式 | 使用和 User 模式完全相同的寄存器组,但是拥有特权权限,用于操作系统内核的任务处理,避免使用异常模式的寄存器导致异常嵌套问题 |
8.2 异常向量表
异常向量表是 ARM 异常处理的核心,本质是一个固定地址的数组,数组中的每个元素存放的是一条跳转指令,跳转到对应异常的中断服务函数(异常处理函数)。
- 异常向量表的位置:一般位于 CPU 的启动地址(0x00000000 或 0xFFFF0000),每个异常占据 4 个字节的空间,正好存放一条跳转指令。
- 工作原理:当某个异常发生时,CPU 会自动将 PC 寄存器设置为异常向量表中对应异常的地址,执行跳转指令,跳转到对应的异常处理函数中。
8.3 ARM 异常处理完整流程
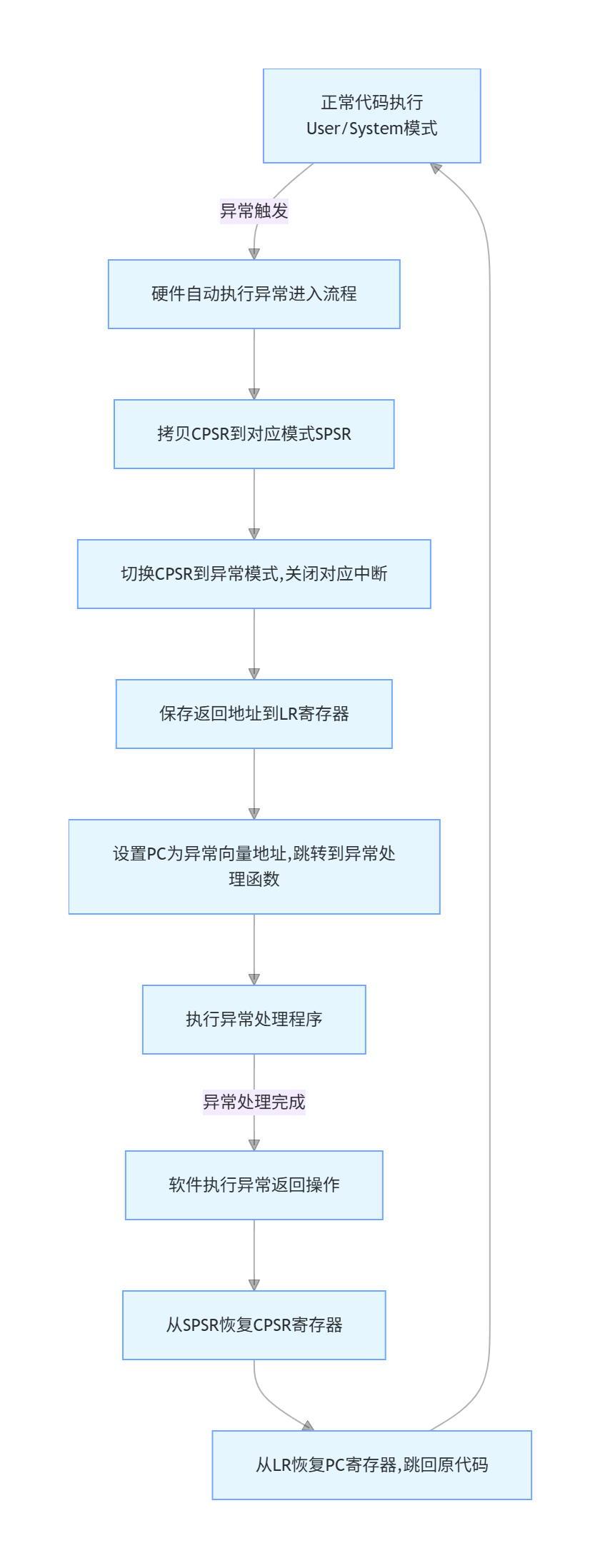
ARM 异常处理分为异常进入(异常触发)和异常返回两个阶段,核心的现场保护操作由硬件自动完成,软件只需要实现异常处理函数即可。
8.3.1 异常发生时,硬件自动执行的操作
- 状态备份:将当前的 CPSR 寄存器的值,完整拷贝到对应异常模式的 SPSR 寄存器中,备份 CPU 运行状态;
- 模式切换:修改 CPSR 寄存器的模式位,将 CPU 切换到对应的异常模式,同时切换到 ARM 指令状态,根据异常类型关闭对应的中断;
- 地址保存:将异常返回地址,保存到对应异常模式的 LR 寄存器中,用于异常返回;
- 跳转执行:将 PC 寄存器设置为异常向量表中对应异常的地址,执行跳转指令,进入异常处理函数。
8.3.2 异常返回时,软件需要执行的操作
异常处理函数执行完成后,需要通过指令完成以下操作,回到异常发生前的执行状态:
- 恢复程序状态:将对应异常模式的 SPSR 寄存器的值,恢复到 CPSR 寄存器中,还原异常发生前的 CPU 状态、工作模式、中断使能状态;
- 恢复执行地址:将 LR 寄存器的值,恢复到 PC 寄存器中,跳回异常发生前的代码位置,继续执行后续指令。
8.4 异常处理完整执行流程图
九、经典 ARM 内核与指令集版本对应
ARM 架构的发展经历了多个版本迭代,不同的 ARM 内核对应不同的 ARM 指令集架构版本,也是芯片选型、开发环境搭建的核心依据。
9.1 ARM 指令集架构版本演进
ARM 指令集架构从 armv1 发展到最新的 armv9,其中嵌入式开发中最常用的版本为 armv4、armv7、armv8:
- armv1-armv3:早期架构,已淘汰,仅用于早期的 ARM1 内核;
- armv4:经典 ARM9 内核采用的架构,代表芯片 S3C2440,是嵌入式入门的经典芯片;
- armv7:Cortex-A/R/M 系列内核采用的架构,32 位架构的巅峰,代表芯片 i.MX6ULL(Cortex-A7 内核),是目前工业嵌入式领域的主流芯片;
- armv8/armv9:最新的 64 位 ARM 架构,支持 32 位兼容模式,代表芯片 Exynos4412(Cortex-A8 内核),用于高端嵌入式、移动端、服务器领域。
9.2 经典芯片与内核、指令集对应关系
表格
| 经典芯片型号 | CPU 内核 | 对应 ARM 指令集版本 | 寄存器数量 |
|---|---|---|---|
| S3C2440 | ARM920T | armv4 | 37 个 |
| i.MX6ULL | Cortex-A7 | armv7 | 40 个 |
| Exynos4412 | Cortex-A8 | armv8 | 40 个 |