JVM字符串常量池:位置、创建流程、对象个数与 intern
- 字符串常量池是什么?解决的是什么问题?
- [常量池的位置:JDK 6/7/8+ 的常见理解](#常量池的位置:JDK 6/7/8+ 的常见理解)
- 先搞懂两种"创建字符串"的差别
-
- 字面量:直接走常量池复用
- [new String("abc"):堆上再来一份](#new String("abc"):堆上再来一份)
- 常见写法到底创建几个字符串对象?
-
- 同样字面量多次出现
- [new String("123") 出现多次](#new String("123") 出现多次)
- [new String("a" + "b")](#new String("a" + "b"))
- ["a" + "b"](#"a" + "b")
- [str1 + str2:运行期拼接,默认不会进常量池](#str1 + str2:运行期拼接,默认不会进常量池)
- [new String("ab") + "ab";](#new String("ab") + "ab";)
- [new String("ab") + new String("ab")](#new String("ab") + new String("ab"))
- [new String("ab") + new String("cd");](#new String("ab") + new String("cd");)
- intern():让"等值字符串"指向池里的那一个
- 参考
在 Java 里,String 无处不在:JSON、SQL、日志、配置......字符串创建频繁,如果每次都分配新对象,会带来明显的内存与 GC 压力。于是 JVM/类加载体系为 字符串字面量 提供了一个"复用池"------字符串常量池(String Intern Pool)。
字符串常量池是什么?解决的是什么问题?
可以把字符串常量池理解为:对"可复用字符串"的缓存表。
- 当 class 文件里出现字符串字面量(例如
"abc"),JVM 在加载/运行过程中会确保池里有一份对应的字符串对象; - 后续再次用到同样字面量时,直接复用池中的那一个引用,避免重复分配。
它能成立有一个关键前提:String 不可变 。一旦某个 "abc" 被多个地方复用,也不会出现"你改了我也跟着变"的数据竞争问题。
常量池的位置:JDK 6/7/8+ 的常见理解
很多资料会把"方法区/永久代/元空间/堆"混在一起说。这里给一个更实用的记忆方式(以 HotSpot 为主):
- JDK 6:字符串常量池常被认为在"永久代"(方法区的一种实现)里
- JDK 7 起 :字符串常量池迁移到堆(更便于 GC、避免永久代容易 OOM)
- JDK 8 起 :永久代移除,类元数据转到元空间(本地内存);但字符串常量池仍在堆这一点延续
结论:现代 Java(JDK 8/11/17/21...)里, 基本可以按"字符串常量池在堆上"来理解 。参考原文也按这个脉络展开。https://www.cnblogs.com/Andya/p/14067618.html
先搞懂两种"创建字符串"的差别
字面量:直接走常量池复用
java
String a = "abc";
String b = "abc";
System.out.println(a == b); // true(同一份池对象)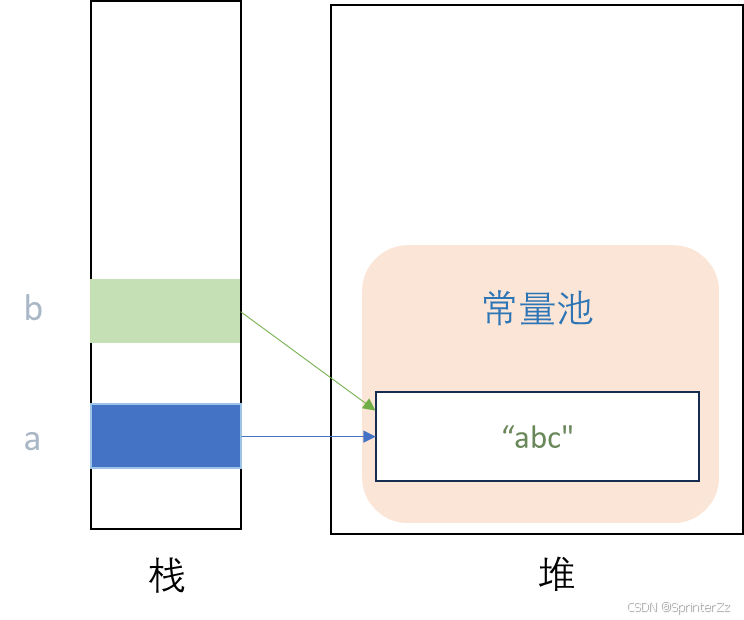
因为 "abc" 是字面量,a 和 b 指向同一个池中对象。
new String("abc"):堆上再来一份
java
String a = "abc";
String b = new String("abc");
System.out.println(a == b); // false
System.out.println(a.equals(b)); // true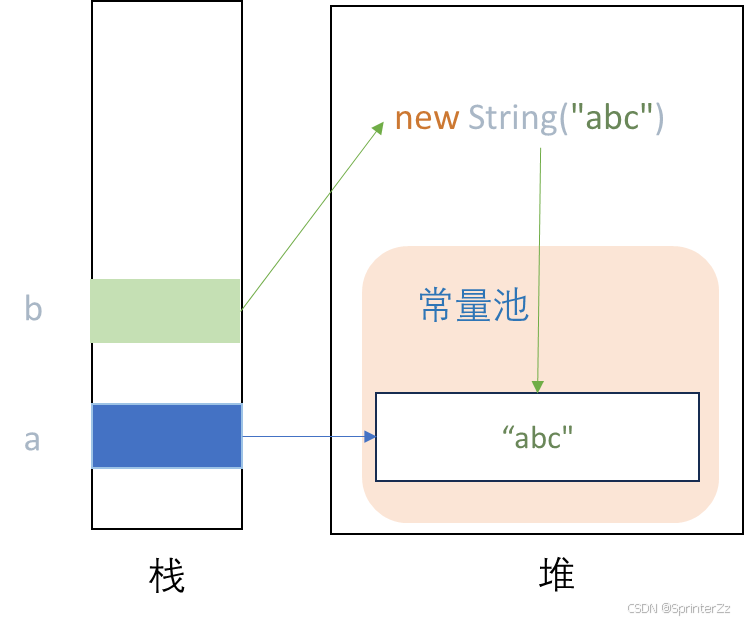
这里至少涉及两层含义:
"abc"这个字面量:在池里(如果之前没有则放进去)new String("abc"):堆上再 new 一个新对象 ,内容来自池中的"abc"
常见写法到底创建几个字符串对象?
同样字面量多次出现
java
String s1 = "123";
String s2 = "123";
String s3 = "123";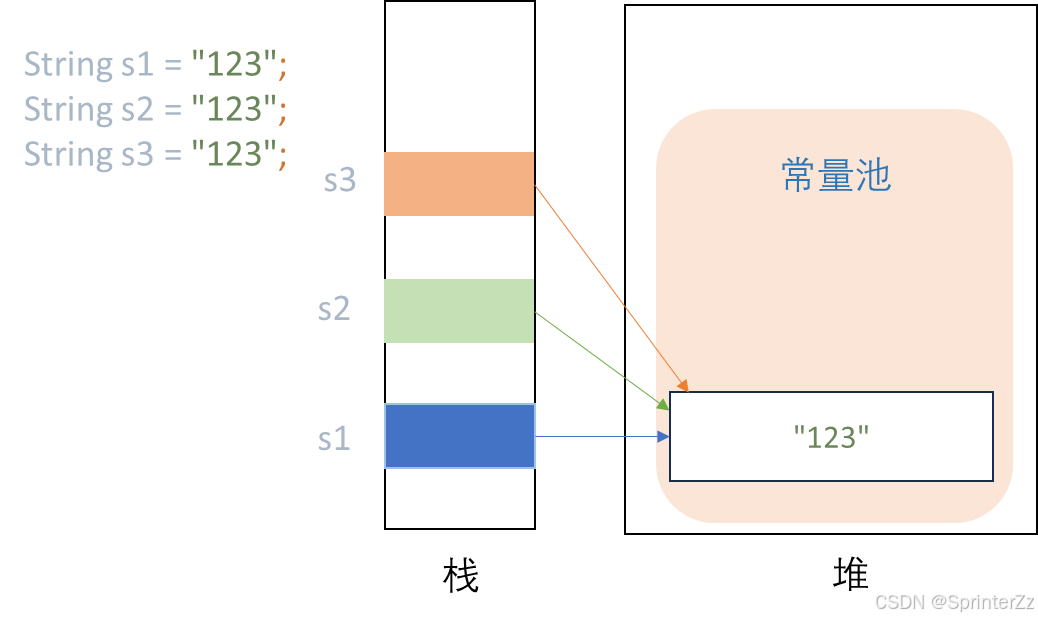
- 池里 :1 个(
"123") - 堆上 :0个(没有
new String/ 运行期拼接)
new String("123") 出现多次
java
String s4 = new String("123");
String s5 = new String("123");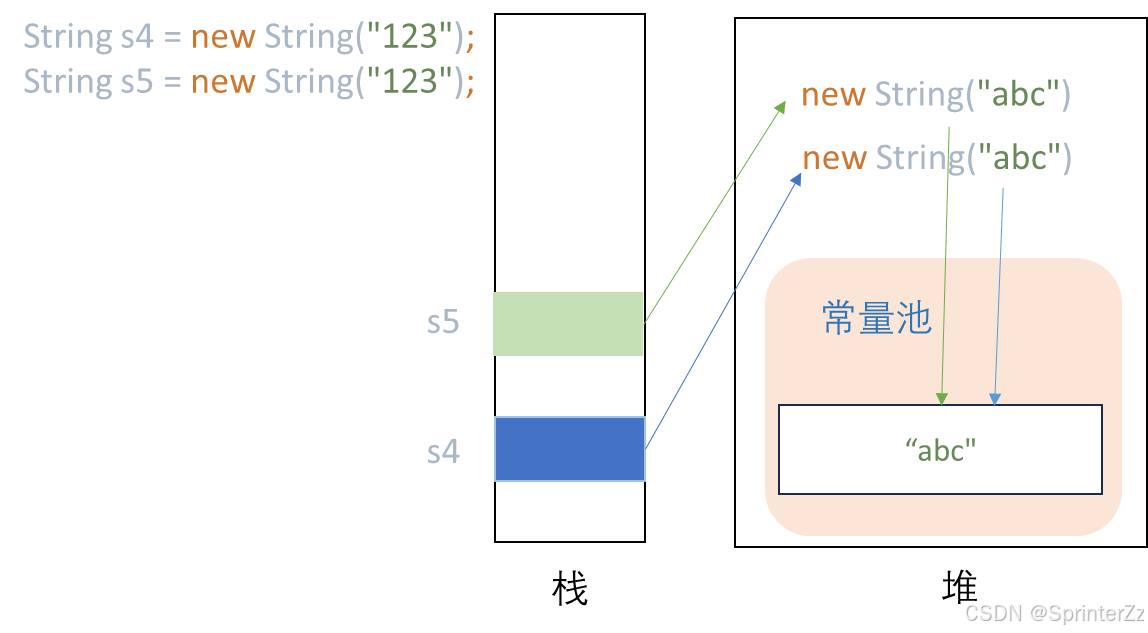
- 池里 :1 个(
"123") - 堆上 :2个(
new String("123")+new String("123"))
new String("a" + "b")
java
String s6 = new String("a" + "b");new String("a" + "b") 在编译期 会把 "a" + "b" 常量折叠 成 "ab",等价于:new String("ab")
- 池里 :1 个(
"ab") - 堆上 :1 个(
new String("ab"))
"a" + "b"
java
String s7 = "a" + "b";"a" + "b" 是编译期常量表达式 ,会被常量折叠为 "ab",等价于new String("ab")
- 池 :1 个(
"ab") - 堆 :0 个(没有
new String/ 运行期拼接)
str1 + str2:运行期拼接,默认不会进常量池
java
String s8= "ab";
String s9 = "cd";
String s10 = s8 + s9;- 池 :2 个(
"ab"、"cd") - 堆 :1 个(运行期拼接结果
str3,内容为"abcd",默认不进池)
【补充】:运行期拼接过程中还会在堆上临时创建 1 个 StringBuilder 对象 (以及其内部数组等),但它不属于"字符串常量池"。它会在 toString() 时创建新的结果 String 对象 (例如 "abcd")。
new String("ab") + "ab";
java
String s11 = new String("ab") + "ab";- 池 :1 个(
"ab") - 堆 :2 个(
new String("ab")1 个 + 运行期拼接结果"abab"1 个)
new String("ab") + new String("ab")
- 池 :1 个(
"ab") - 堆 :3 个(两个
new String("ab")+ 运行期拼接结果"abab")
new String("ab") + new String("cd");
- 池 :2 个(
"ab"、"cd") - 堆 :3 个(
new String("ab")+new String("cd")+ 运行期拼接结果"abcd")
intern():让"等值字符串"指向池里的那一个
java
String x = new String("123"); // 堆对象
String y = x.intern(); // 返回池中对应对象的引用
System.out.println(y == "123"); // true理解一句话就够了:intern() 返回"常量池中等内容字符串"的引用;如果池里没有,可能把当前字符串(或其等价表示)放进去,再返回池引用。
参考
- 原文:
https://www.cnblogs.com/Andya/p/14067618.html