摘要 :本文在 Decoder-only Transformer、LLaMA 架构、DeepSeek LLM、DeepSeekMoE 与 DeepSeek-V2 的基础上,系统介绍 DeepSeek-V3 的技术报告要点。V3 延续 Multi-head Latent Attention(MLA) 与 DeepSeekMoE 作为注意力与稀疏 FFN 的核心设计,并将规模提升到约 671B 总参数、每 token 约 37B 激活 ;在此基础上,论文强调三类与「规模化训练/推理」强相关的创新:无辅助损失的 MoE 负载均衡 、多 Token 预测(MTP)训练目标 、以及 FP8 混合精度 + DualPipe 等系统工程 。全文还概述预训练数据规模(14.8T token)、长上下文扩展(YaRN 至 128K)、对齐阶段(SFT / RL)与训练稳定性、算力统计(约 2.788M H800 GPU hours)。旨在帮助读者把 V3 定位成:在 V2 已验证的架构组件上继续放大规模,并用算法与系统 co-design 把成本与稳定性压到可工程复现的水平。
关键词:DeepSeek-V3;MLA;DeepSeekMoE;MoE;无辅助损失负载均衡;Multi-Token Prediction;FP8;DualPipe;大语言模型
论文 :DeepSeek-V3 Technical Report(DeepSeek-AI, 2024;arXiv:2412.19437)
💡 理解要点 :DeepSeek-V3 不是「另起炉灶换骨架」,而是在 Decoder-only + RMSNorm + Pre-Norm + SwiGLU + RoPE 的 LLaMA 风格骨干上,把 V2 已经验证的 MLA(省 KV cache) 与 DeepSeekMoE(省每 token 激活) 推到更大规模;新增的关键在于 MoE 路由负载均衡不再依赖辅助损失 、用 MTP 加厚监督信号 、以及 FP8 + 通信/流水线重叠 让超大 MoE 训练在工程上可负担且稳定。
1. 概述:DeepSeek-V3 在系列中的位置
如果把 DeepSeek LLM 看作「LLaMA 系稠密模型的深度与训练策略增强」,DeepSeekMoE 看作「稀疏 FFN 与专家专业化」,DeepSeek-V2 看作「MLA + DeepSeekMoE 的第一次大规模产品化」,那么 DeepSeek-V3 的核心叙事可以概括为一句话:
在 同一套架构语言 里继续扩总参数与数据规模,并用 负载均衡 / 训练目标 / 精度与并行系统 三块补丁,解决「更大 MoE 更难训、更难稳、更贵」的工程瓶颈。
单层数据流仍可理解为与 V2 同构:
RMSNorm → MLA(低秩 KV + 解耦 RoPE)→ 残差 → RMSNorm →(稠密 FFN 或 DeepSeekMoE)→ 残差。
与 V2 的差异主要体现在:更宽的隐藏维度与更深的层数 、MoE 宽度与路由策略升级 、以及 训练阶段引入 MTP 与无辅助损失均衡(详见后文)。
🔍 实际例子 :V2 常见公开配置约为 236B 总参数 / 21B 激活 ;V3 报告配置约为 671B 总参数 / 37B 激活。直观上,V3 把「专家库」与「总容量」做得更大,但每 token 仍只走一小部分专家,从计算上仍属于「大参数、中小激活」的路线。
2. 继承自 V2 的核心组件:MLA 与 DeepSeekMoE
§2.1 对 MLA 给出独立可读说明(只读本文也能建立正确直觉);§2.2 简述 DeepSeekMoE 在 V3 中的延续角色。若需要逐步推导、对比表与数值例子,可继续阅读 DeepSeek-V2 架构解析 §2--§4 与 DeepSeekMoE 架构解析。
2.1 MLA:推理侧 KV cache 仍是主战场
2.1.1 自回归推理里,瓶颈为什么常常是 K/V?
在 Decoder-only 的自回归生成中,第 t t t 步注意力可粗写成 s o f t m a x ( Q t K 1 : t ⊤ ) V 1 : t \mathrm{softmax}(Q_t K_{1:t}^\top)V_{1:t} softmax(QtK1:t⊤)V1:t。当前步的 Query Q t Q_t Qt 只依赖当前 token 的隐藏状态,算完即用,不必跨步保存 。但 历史位置的 K 1 : t K_{1:t} K1:t、 V 1 : t V_{1:t} V1:t 会在后续每一步再次被用到;工程上若每步重算整段前缀的 K/V,代价不可接受,因此必须在 GPU 上 缓存(KV cache) 已生成 token 在各层的 K/V。序列变长、batch 变大、层数变多时,KV cache 的显存占用与读写带宽往往先于「矩阵乘 FLOPs」成为部署瓶颈------这也是 GQA/MQA、以及 MLA 这类设计的出发点。
标准 MHA 下,每层、每个 token 需要为 n h n_h nh 个头各存一组 K、V;若每头维度为 d h d_h dh,则 仅 K+V 的元素个数 约为 2 n h d h 2 n_h d_h 2nhdh (再乘以层数 l l l 与已生成长度,即总 cache)。当 n h n_h nh、 d h d_h dh、 l l l 都很大时,这一项会非常快膨胀。
2.1.2 MLA 的核心想法:先压成「小本子」,再按需展开
Multi-head Latent Attention(MLA) 不把「完整的多头 K、V」直接当作缓存对象,而是为每个 token、每一层先算一个 更短的联合潜在向量 (可理解为「把 K、V 的共同信息先记在一张小卡片上」),推理时 主要缓存这张小卡片。
用 V2/V3 报告中的符号习惯(与 V2 文 §3 一致):对隐藏状态 h t \mathbf{h}_t ht 先做下投影得到
c t K V = W D K V h t ∈ R d c , \mathbf{c}_t^{KV} = W^{DKV}\mathbf{h}_t \in \mathbb{R}^{d_c}, ctKV=WDKVht∈Rdc,
其中 d c ≪ 2 n h d h d_c \ll 2 n_h d_h dc≪2nhdh (例如公开配置里常见 d c = 512 d_c=512 dc=512,而 2 n h d h 2n_h d_h 2nhdh 往往上万维量级)。需要参与注意力时,再通过上投影把 K、V 从潜在空间「展开」:
k t C = W U K c t K V , v t C = W U V c t K V . \mathbf{k}_t^C = W^{UK}\mathbf{c}_t^{KV},\quad \mathbf{v}_t^C = W^{UV}\mathbf{c}_t^{KV}. ktC=WUKctKV,vtC=WUVctKV.
推理缓存的主干 因此从「存满维 K、V」退化为 存 c t K V \mathbf{c}_t^{KV} ctKV (维度 d c d_c dc)。再借助矩阵乘法结合律,实现里常把 W U K , W U V W^{UK}, W^{UV} WUK,WUV 吸收到 Query 侧或输出投影侧,避免在每一步显式构造巨大的中间 K、V 张量------这与「只缓存 latent、算注意力时再与固定权重组合」的工程目标是同一件事的两面。
此外,为降低 训练 时激活显存,MLA 对 Query 也常用类似的 两阶段低秩形式 : c t Q = W D Q h t \mathbf{c}_t^Q = W^{DQ}\mathbf{h}_t ctQ=WDQht,再 q t C = W U Q c t Q \mathbf{q}_t^C = W^{UQ}\mathbf{c}_t^Q qtC=WUQctQ。它主要服务 训练内存 ,不改变「推理以 d c d_c dc 级缓存为主干」这一结论。
2.1.3 为什么需要「解耦 RoPE」:压缩与位置编码「抢同一个乘法顺序」
这一节把三件事讲清楚:(A) 普通 LLaMA 式 RoPE 在注意力里干什么 ;(B) MLA 说的「吸收投影」到底想省掉什么 ;© 为什么「整块 K 上做 RoPE」会和 (B) 冲突,从而必须解耦。
(A) 先复习:RoPE 出现在 Q、K 上,而且是「按位置旋转」
在 LLaMA 里,每一层、每个位置 t t t 会先算出线性投影后的 q t , k t \mathbf{q}_t,\mathbf{k}_t qt,kt,再在算 q t ⊤ k j \mathbf{q}_t^\top \mathbf{k}_j qt⊤kj 之前,对 q t \mathbf{q}_t qt 与 k j \mathbf{k}_j kj 各自施加与位置有关的旋转 (记为 R o P E ( ⋅ , t ) \mathrm{RoPE}(\cdot,t) RoPE(⋅,t)、 R o P E ( ⋅ , j ) \mathrm{RoPE}(\cdot,j) RoPE(⋅,j))。直觉上:注意力分数不再只由「内容向量」决定,而是由「旋转后的 内容向量」决定,从而分数里能编码 t t t 与 j j j 的相对位置。
(B) MLA 想做的「吸收投影」:尽量别在推理时「展开成满维 K」
上一小节说过:推理时我们最想缓存的是 c j K V \mathbf{c}_j^{KV} cjKV (维度 d c d_c dc),而不是每个头的满维 k j \mathbf{k}_j kj。理论上,注意力公式里会用到 q t ⊤ k j C \mathbf{q}_t^\top \mathbf{k}_j^C qt⊤kjC 这类内积,其中 k j C = W U K c j K V \mathbf{k}_j^C = W^{UK}\mathbf{c}_j^{KV} kjC=WUKcjKV。注意到
q t ⊤ ( W U K c j K V ) = ( W U K ⊤ q t ) ⊤ c j K V . \mathbf{q}_t^\top (W^{UK}\mathbf{c}_j^{KV}) \;=\; (W^{{UK}^\top}\mathbf{q}_t)^\top \mathbf{c}_j^{KV}. qt⊤(WUKcjKV)=(WUK⊤qt)⊤cjKV.
也就是说:只要把 Query 侧改写成先乘 W U K ⊤ W^{{UK}^\top} WUK⊤(或与 W U Q W^{UQ} WUQ 等合并成一次矩阵乘) ,就可以在算分数时 直接用缓存的 c j K V \mathbf{c}_j^{KV} cjKV ,而不必先把所有历史 j j j 的 k j C \mathbf{k}_j^C kjC 大张量算出来再存------这就是常说的把 W U K W^{UK} WUK 吸收进 Query 侧 (同理可对 W U V W^{UV} WUV 与输出投影做吸收)。这一步能成立的关键是:在内积里,W U K W^{UK} WUK 与 c j K V \mathbf{c}_j^{KV} cjKV 之间不再夹杂「与位置有关的非线性变换」 ,这样「历史一侧」真的只需要一份 与当前解码步 t t t 无关 的缓存内容。
© 冲突点:如果你对传统 k C \mathbf{k}^C kC 再做 RoPE,旋转会「卡在中间」
现在把 RoPE 加回来:假设你对 已经展开 的 key 做标准 RoPE,相当于用 R o P E ( W U K c j K V , j ) \mathrm{RoPE}(W^{UK}\mathbf{c}_j^{KV},\,j) RoPE(WUKcjKV,j) 参与内积。问题在于:R o P E ( ⋅ , j ) \mathrm{RoPE}(\cdot,j) RoPE(⋅,j) 不是「左乘一个与 W U K W^{UK} WUK 可交换的常数矩阵」 (一般情况下,旋转与任意线性层 不可交换 )。于是你很难把式子整理成「只动 Query、不动历史缓存 」的干净形式:为了在当前步 t t t 正确评分,历史缓存往往会被迫变成「还依赖当前正在算的那一步 RoPE/相对位置组合 」的东西,甚至出现论文里说的后果------对每个前缀位置 j j j,缓存无法保持「一份固定不变」的表示 ,推理时仍要反复重算 key,MLA 的 KV 压缩收益被抵消。
用一句更口语的话:你想把 W U K W^{UK} WUK「搬到」Query 那边去合并;但 RoPE 像一把插在中间的扳手,搬不过去。
(D) 解耦 RoPE:把「位置」从压缩 K 里拆出去,单独用一小段维度承担
解耦 RoPE 的策略是:不要把位置旋转施加在「从 c K V \mathbf{c}^{KV} cKV 展开的大块 k C \mathbf{k}^C kC」上 ;改为把注意力用的 Q、K 都拆成两段向量再拼接(论文中的写法与 V2 文 §3.3 一致):
- 内容段(无 RoPE) : q t , i C , k j , i C , v j , i C \mathbf{q}{t,i}^C,\mathbf{k}{j,i}^C,\mathbf{v}_{j,i}^C qt,iC,kj,iC,vj,iC 由低秩/潜在路径得到。对这一段,你仍然可以做上一小节的 矩阵吸收 ,让历史侧主要缓存 c j K V \mathbf{c}_j^{KV} cjKV。
- 位置段(有 RoPE) :单独引入维度很小的 q t , i R \mathbf{q}_{t,i}^R qt,iR 与 跨头共享 的 k j R \mathbf{k}_j^R kjR(维度 d h R d_h^R dhR,常见如 64),对它们施加 R o P E \mathrm{RoPE} RoPE。推理时对每个历史位置 额外缓存 k j R \mathbf{k}_j^R kjR(或其在 RoPE 后仍可按实现等价变换),其显存远小于存满维多头 K。
拼接 后再做注意力:例如把 q t , i = q t , i C ; q t , i R \mathbf{q}{t,i}=\\mathbf{q}_{t,i}\^C;\\mathbf{q}_{t,i}\^R qt,i=qt,iC;qt,iR、 k j , i = k j , i C ; k j R \mathbf{k}{j,i}=\\mathbf{k}_{j,i}\^C;\\mathbf{k}_j\^R kj,i=kj,iC;kjR(注意 k j R \mathbf{k}_j^R kjR 对各头共享),用统一尺度(如除以 d h + d h R \sqrt{d_h+d_h^R} dh+dhR )做 softmax。这样,「大头」的内容相似度 主要由可吸收的 q C − k C \mathbf{q}^C\!-\!\mathbf{k}^C qC−kC 部分承担;相对位置 由 很小的 RoPE 子空间 里的 q R − k R \mathbf{q}^R\!-\!\mathbf{k}^R qR−kR 内积提供------两者职责分离,因此可以同时保留 RoPE 的相对位置能力 与 MLA 的 KV 压缩 + 吸收。
🔍 实际例子 :若没有解耦,你只能二选一:要么 为省缓存强行做吸收但位置编码「变形」、实现极别扭甚至不成立;要么 放弃吸收、回到「每个位置存满维 K」的高缓存路线。解耦是用 多缓存 d h R d_h^R dhR 维的一小条 换来 主体仍只存 d c d_c dc 的折中,而 d h R ≪ 2 n h d h d_h^R \ll 2n_h d_h dhR≪2nhdh。
代价小结 :推理时除了 c t K V \mathbf{c}_t^{KV} ctKV,还要缓存 RoPE 支路对应的 key 分量 (论文记为 k t R \mathbf{k}_t^R ktR,维度 d h R d_h^R dhR),因此总缓存才是前文写的 d c + d h R d_c + d_h^R dc+dhR ,而不是只有 d c d_c dc。
我们看一下论文中对 MLA 优化的相关描述:



综合起来:每层、每个 token 需要持久化到 KV cache 的量 ,从 MHA 侧常见的 2 n h d h 2 n_h d_h 2nhdh(K、V 全头存满)降到约
d c + d h R d_c + d_h^R dc+dhR
个元素量级(具体拼接与尺度归一化见 V2 论文公式)。在典型配置下,这比 MHA 小一个数量级以上,同时实证上又能保持接近甚至不弱于 MHA 的表现------这与单纯 GQA「砍 KV 头数」的折衷路线不同:MLA 是结构化的低秩分解 + 位置信息分流。
2.1.4 放到 DeepSeek-V3 里:不是「为了新而新」,而是服务更长上下文与更高吞吐
DeepSeek-V3 在更大宽度(如 hidden 7168)、更深(61 层)与 128K 级别上下文 的设定下,若仍采用标准 MHA,KV cache 与带宽压力会被同步放大。V3 继承 MLA ,说明团队把「把 KV cache 压下来 」视为与「把每 token 激活压下来(MoE) 」同等重要的横向扩展前提。换言之:V3 没有用回到 MHA/GQA 来换规模;相反,它把 MLA 当作长上下文服务与高 batch 推理的基础组件之一。
💡 理解要点 :记住三句话即可------(1) 自回归推理主要缓存 K/V ;(2) MLA 用 c K V \mathbf{c}^{KV} cKV 把 K/V 信息压缩到 d c d_c dc ;(3) 解耦 RoPE 用一小块 k R \mathbf{k}^R kR 单独承担位置旋转,避免与低秩吸收「打架」。最终缓存量级约为 d c + d h R d_c+d_h^R dc+dhR 每层每 token。
2.2 DeepSeekMoE:仍然坚持「细粒度 + 共享专家」的语言
DeepSeekMoE 的两条经验------细粒度专家切分 与共享专家隔离 ------在 V3 仍是 MoE 层的语义基础:共享专家承载更「通用」的变换,路由专家承担更「分化」的子空间拟合。V2 中与之配套的 设备受限路由 、训练期 token dropping 等工程手段,在 V3 报告语境里让位于更强的 路由均衡机制 与 训练系统优化(见 §4、§5)。
3. 模型规模与公开配置:V2 → V3 一眼对照
技术报告给出的最醒目数字是 671B / 37B。下表把读者在 V2 文中已经熟悉的量级与 V3 做并排对照(MoE 细节以报告与开源配置描述为主;不同实现口径下可有微小出入)。
| 项目 | DeepSeek-V2(报告量级,见 V2 文) | DeepSeek-V3(报告 / 常见开源配置口径) |
|---|---|---|
| 总参数 | 约 236B | 约 671B |
| 每 token 激活 | 约 21B | 约 37B |
| 层数 | 60 | 61(常见开源配置) |
| 隐藏维度 d d d | 5120 | 7168 |
| 注意力 | MLA( n h , d h , d c , d c ′ , d h R n_h,d_h,d_c,d_c',d_h^R nh,dh,dc,dc′,dhR 等见 V2) | 仍 MLA ;低秩秩与解耦 RoPE维度常与 V2 同量级 (如 d c = 512 d_c=512 dc=512、 d c ′ = 1536 d_c'=1536 dc′=1536、 d h R = 64 d_h^R=64 dhR=64、每头 128 维等,具体以实现为准) |
| MoE(路由侧规模感) | 160 路由专家;每 token 激活 6 个路由专家 + 2 共享 | 256 路由专家;每 token 共 8 个专家参与(常见描述为 1 共享 + 7 路由 或等价实现口径) |
| 专家 FFN 中间维 | 1536(V2 文) | 2048 (常见开源配置 moe_intermediate_size) |
| 浅层是否 MoE | 除第一层外 MoE | 常见实现:前 k k k 层稠密 (如 first_k_dense_replace=3),其后为 MoE |
| 词表 | --- | 常见 129280(约 128K 级别 BPE) |
💡 理解要点 :V3 的「变大」不只是层数与宽度,也包括 路由专家池从 160 扩到 256 、每 token 激活专家数从 6(路由)+2(共享)演化为 8 总激活(实现上常表现为更高并行宽度与更大路由空间)。
4. MoE 路由:无辅助损失负载均衡(Auxiliary-Loss-Free)
4.1 传统做法在规模化时的痛点
MoE 训练里,如果路由长期「偏科」,会出现少数专家过载、多数专家闲置:算力浪费、通信热点、甚至数值不稳定。常见缓解是加 辅助平衡损失 (V2 文中也讨论了多类均衡项)。但辅助损失本质是「在主任务之外再强加约束」,系数难调:太强会伤害语言建模质量,太弱又拦不住崩塌。
4.2 V3 的方向:用「动态偏置」做批内均衡,而不是加 loss 项
DeepSeek-V3 报告提出 无辅助损失的负载均衡 :核心直觉是,在路由打分(logits)上为每个专家维护一项 可随统计更新的偏置(bias) ,根据 观测到的负载 动态调整,使得在一个训练 batch 的时间尺度上,各专家的利用率更接近均匀,从而 不再需要把均衡目标写进总损失的辅助项。
💡 理解要点 :可以把辅助损失想象成「用罚款逼车辆均匀上每条高速」;无辅助损失均衡更像「根据拥堵实时调整收费站价格」,目标仍是均衡,但 减少对主任务梯度的直接拉扯。
4.3 与「专家专业化」的关系(读论文图表时的提示)
报告中的对比实验指出:相比强依赖辅助损失的路由,无辅助损失均衡 往往对应 更鲜明的领域/任务负载模式 (更「像」专家在分化)。这与 DeepSeekMoE 最初追求「减少知识混杂」的动机是一致的,只是 V3 把「均衡手段」从 loss 迁移到了 路由动态机制。
5. 训练目标:多 Token 预测(MTP)
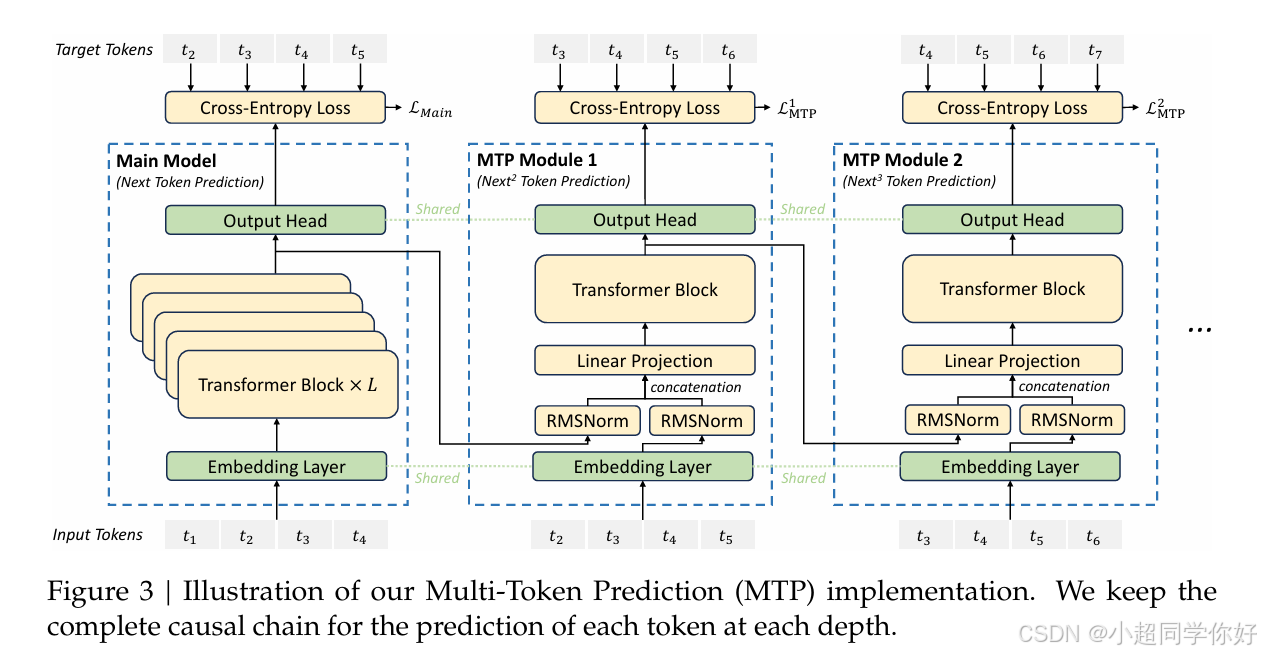
MTP(Multi-Token Prediction) 不是把 Transformer「换成另一种结构」,而是在 预训练的损失函数旁边,多加几份「往未来多看一步」的作业 。下面分四层说明:(1) 标准 next-token 到底在教什么 ;(2) 为什么说监督「薄」 ;(3) MTP 多出来的作业长什么样 ;(4) 推理时还要不要它。
5.1 先对齐基准:因果 LM 在位置 i i i 只背「下一格」
在 Decoder-only 里,模型看到前缀 x ≤ i x_{\le i} x≤i,输出对 x i + 1 x_{i+1} xi+1 的分布。训练时在这个位置只算 一个交叉熵损失:
L main ( i ) = − log p θ ( x i + 1 ∣ x ≤ i ) . \mathcal{L}{\text{main}}(i) = -\log p\theta(x_{i+1}\mid x_{\le i}). Lmain(i)=−logpθ(xi+1∣x≤i).
你可以把它想成填空题:句子读到第 i i i 个字,老师只判你对不对 下一个字 ;再往后的字 ( x i + 2 , x i + 3 , ... x_{i+2},x_{i+3},\ldots xi+2,xi+3,...)在这一步 不会 直接给你扣分或加分------它们会在 下一轮 、以 「位置 i + 1 i+1 i+1 的下一字」 的身份分别出现。于是:每个位置对「更远未来」的梯度,是间接、滞后、分散地传回来的。
💡 理解要点 :不是「模型学不会长程依赖」,而是 优化目标在每一步只钉死一个 token ;超大模型参数很多时,有人会担心「每一步的有效约束不够密」,MTP 就是往这个目标里 人为加约束。
5.2 「监督太薄」到底指什么?
这里的「薄」可以读成两层意思(不必和论文逐字对应,但有助于直觉):
- 每个位置的「即时错题」只有一道 :在当前隐藏状态 h i \mathbf{h}_i hi 上,主损失只强迫它服务好 一个离散决策(下一个词 ID)。
- 对「局部连贯性」的显式要求偏弱 :像「成语第四个字」「代码右括号」「诗句押韵」这类 连跳两步 的模式,标准 LM 当然最终能学到,但信号主要来自 多次 one-step 预测的叠加,而不是在同一步里直接对「第二步、第三步」施压。
MTP 的想法很直白:在同一个 h i \mathbf{h}_i hi 附近,多挂几个「老师也看 i + 2 i+2 i+2、 i + 3 i+3 i+3...」的判分器 ,让表示层在预训练阶段就更频繁地面对 多步自洽 的要求。
5.3 MTP 在训练里「多做了什么」:不止预测 x i + 1 x_{i+1} xi+1
记主模型(完整 Transformer 堆叠 + 词嵌入)在位置 i i i 的顶层表示为 h i \mathbf{h}_i hi。主任务不变 :仍用 h i \mathbf{h}i hi 经语言模型头(LM head)去拟合 x i + 1 x{i+1} xi+1。
MTP 额外做的事 是:在 已知真值 x i + 1 , x i + 2 , ... x_{i+1}, x_{i+2}, \ldots xi+1,xi+2,... 的前提下(训练时有 Teacher Forcing),再构造一条 向未来延伸的预测链。DeepSeek-V3 报告里的实现要点可以概括为:
-
串行(链式)深度,而不是「在同一层并行开三个 softmax」的简单多塔
- 先用主模型负责「第一步」: → x ^ i + 1 \rightarrow \hat{x}_{i+1} →x^i+1。
- 第一个 MTP 模块在 因果上合法的信息 条件下,再往前推一步:例如把 h i \mathbf{h}_i hi 与 真值 x i + 1 x_{i+1} xi+1 的嵌入 (或等价变换后的向量)送入一个 浅层 Transformer 块 ,得到用于预测 x i + 2 x_{i+2} xi+2 的表示。
- 若有更深 MTP,则继续:用再下一 token 的嵌入与上一步输出,预测 x i + 3 x_{i+3} xi+3......
这样每一跳都 显式依赖「已经落地的那一步 token」 ,避免「一眼看到未来却假装没看到」的信息泄漏,也 保留自回归结构的可解释性。
-
与主模型共享词嵌入与输出头
报告强调 MTP 模块 复用同一套 token embedding 与 LM head 。直觉上:「词长什么样」与「词表怎么打分」只有一套 ;MTP 只是在主模型给出的语境表示之上,用 额外的浅层计算 去模拟 「再往后想一步」 的过程。参数更省,也让辅助任务与主任务 强制对齐在同一语义空间里。
-
总损失 = 主损失 + 各深度辅助损失
对每个样本位置,除了 L main ( i ) \mathcal{L}{\text{main}}(i) Lmain(i),还对 MTP 各深度加 L mtp ( 1 ) ( i ) , L mtp ( 2 ) ( i ) , ... \mathcal{L}{\text{mtp}}^{(1)}(i), \mathcal{L}_{\text{mtp}}^{(2)}(i), \ldots Lmtp(1)(i),Lmtp(2)(i),...(具体权重与深度数以论文为准)。反向传播时,主塔与 MTP 塔一起更新(含共享的 embedding / head)。

🔍 实际例子 :设 i i i 在句子「人工智能__」处。主损失只问:横线上 第一个 词该不该是「的」。MTP 可能在同一次 forward 里再问:若第一个词 真是 「的」,那 下一个 词更该是「发展」还是「蛋糕」?这些额外问题都 绑在同一个前缀表示 h i \mathbf{h}_i hi 附近 ,逼 h i \mathbf{h}_i hi 不仅「接得上一个词」,还 预留出可延续的轨迹。
5.4 为什么强调「串行模块」而不是随便多几个并行头?
一种 朴素想法 是:在 h i \mathbf{h}i hi 上同时接三个线性层,分别 softmax 出 x i + 1 , x i + 2 , x i + 3 x{i+1},x_{i+2},x_{i+3} xi+1,xi+2,xi+3。问题在于:
- 因果性与信息流 : x i + 2 x_{i+2} xi+2 的合理预测,在生成任务里本应依赖「 x i + 1 x_{i+1} xi+1 具体是哪个 token」;若完全不经过「先确定/先看到 x i + 1 x_{i+1} xi+1」的路径,模型容易学到 数据集里的捷径相关 (尤其是训练时用 teacher forcing 暴露真值时,更要用 显式链式结构 把「第 2 步依赖第 1 步」写进计算图)。
- 与自回归推理一致 :推理时是 一步一步 吐 token;链式 MTP 在训练时模拟的,正是 「在给定上一步结果后,再往前滚一步」 的过程,和部署时的使用方式更同构。
V3 报告选择 浅层 Transformer 块串接 (配合共享 embedding/head),就是在 加厚监督 与 不破坏因果叙事 之间折中。
5.5 推理侧:MTP 常常是「训练期的配角」
预训练结束后,最简部署 往往只保留 主 Transformer + LM head ,拆掉 MTP 模块 ------因为自回归生成本来只需要「下一步分布」。此时 MTP 的作用已经 固化进主网络权重(训练时的多任务正则)。
另一条路是 投机解码(speculative decoding) :用 小模型或浅层 先草稿多个 token,再由大模型并行验证。MTP 塔因为 已经在学「多步前瞻」 ,理论上可改写成 草稿生成器 ,与主模型 共享词表与部分参数 ,降低草稿-主模型不一致带来的浪费。是否在产品里启用,属于 工程与延迟权衡,不改变「主干架构仍是标准 Decoder」这一事实。
💡 一句话收束 :MTP = 训练时多判几步未来 token,用串行浅模块 + 共享嵌入/头,把监督加厚;推理可以只用主塔,也可以把 MTP 当草稿用。
6. 训练系统:FP8 混合精度与 DualPipe(为何能「省小时数」)
6.1 FP8:把大头 GEMM 压到 8bit,但保留关键高精度路径
DeepSeek-V3 在报告中给出了可复现的大规模 FP8 混合精度训练 方案:核心思想是 矩阵乘(GEMM)尽量 FP8 ,但对 embedding、输出头、归一化、某些敏感算子 保留更高精度;并通过 细粒度缩放 (如对激活分 tile、对权重分 block)配合 高精度累加 控制量化误差。论文给出与 BF16 对照的训练误差量级(相对差异很小),用于论证 FP8 不是噱头而是可规模化默认。
🔍 实际例子:同样的集群拓扑下,FP8 让矩阵乘吞吐显著提高,同时降低激活缓存与部分通信压力;再叠加 MoE 的稀疏激活,才能把「671B 这种量级」的训练拉到论文披露的 GPU hours 区间。
6.2 DualPipe:用调度把「算力等通信」吃掉
超大 MoE 在专家并行(EP)下会有大量 all-to-all 通信;流水线并行(PP)又会引入 bubble。V3 报告用 DualPipe 描述一种 前向/反向切分与重叠 的策略:把通信尽量藏到计算窗口里,降低流水线空泡与同步等待。
💡 理解要点 :V3 的性价比不只来自模型公式,也来自 把 EP/PP/DP 的组合调度做到接近硬件极限 ;读技术报告时建议把 Figure 5--8(通信重叠与 FP8 算子)与架构图同等重视。
7. 数据、长上下文与对齐:从 14.8T 预训练到 SFT / RL
7.1 预训练数据
报告披露预训练语料约 14.8T token,并强调数据多样性与质量过滤;实现细节(去重、配比、数学/代码增密等)以论文数据章节为准。
7.2 长上下文:YaRN 扩到 128K
与 V2 类似,V3 使用 YaRN 做上下文外推;报告描述从较短上下文训练出发,经阶段化扩展至 128K ,并在 NIAH(Needle In A Haystack)等长上下文检索测试上给出结果。解耦 RoPE 的 key 部分通常是长度外推的关键切入点(见 V2 文 §6 的思路延续)。
7.3 对齐:SFT + RL,并引入 R1 蒸馏叙事
后训练阶段包含 监督微调(SFT) 与 强化学习(RL) ;报告中还描述了从 DeepSeek-R1 系列蒸馏推理数据、用 GRPO 等算法做偏好优化的路径。对架构读者而言,记住结论即可:V3 的聊天/推理表现不仅来自预训练骨架,也来自后训练配方。
8. 训练成本与稳定性:论文给出的「工程结论」
报告给出全链路训练约 2.788M H800 GPU hours ,并强调训练过程 未出现不可恢复的损失尖峰、未进行回滚式重启 。在公开论文里,这种「稳定性声明」与 FP8、DualPipe、路由均衡是一组互证:大规模训练首先得能跑完。
💡 理解要点 :当你把 V3 与某些闭源模型对比时,除了 benchmark,也可以对比 披露的训练稳定性与系统方法是否可迁移------这往往决定社区能否复现「同方向增益」。
9. 与 V2 / 典型开源 MoE 的对比(概念表)
| 维度 | DeepSeek-V2 | DeepSeek-V3 | 典型「GShard 式」MoE(对照) |
|---|---|---|---|
| 注意力 | MLA | MLA | 多为 MHA/GQA |
| MoE 专家组织 | 共享 + 细粒度路由 | 共享 + 更多路由专家 + 组约束路由 (实现上常见 n_group / topk_group) |
粗粒度 top- K K K |
| 负载均衡 | 多类辅助损失 + 工程策略 | 无辅助损失 的动态偏置均衡(主叙事) | 常见辅助损失 |
| 训练目标 | 以 next-token 为主 | next-token + MTP | 多为 next-token |
| 精度系统 | 以 BF16 叙述为主(以论文为准) | FP8 混合精度 + 细粒度缩放 | 视项目而定 |
10. 小结与相关文档
- DeepSeek-V3 在 Decoder-only 骨架上延续 MLA + DeepSeekMoE :把 总参数与专家池 做大,同时把 每 token 激活 控制在约 37B 量级,继续走「推理可服务、训练可负担」的路线。
- 无辅助损失负载均衡 把「均衡」从 loss 项 挪到 路由动态机制 ,是 V3 相对 V2 在 MoE 训练算法 上最醒目的差异点之一。
- MTP 从 优化问题 侧加厚监督;FP8 + DualPipe 从 系统 侧降低小时数与提升稳定性;YaRN 与后训练配方决定 长上下文与对话能力 的产品化上限。
相关文档:
- Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算
- Transformer 12. LLaMA 架构介绍以及与 Transformer 架构对比
- Transformer 13. DeepSeek LLM 架构解析
- Transformer 14. DeepSeekMoE 架构解析
- Transformer 15. DeepSeek-V2 架构解析
论文 :DeepSeek-V3 Technical Report. arXiv:2412.19437
代码与权重入口 (报告链接):https://github.com/deepseek-ai/DeepSeek-V3