
导读
少样本工业异常检测是一个实际痛点:产线上往往只有几张正常样品图片,却需要检出各种未知缺陷。现有方法为此设计了复杂的记忆库、提示学习、多阶段训练等流程,部署门槛高,品类切换成本大。
埃因霍温理工大学的研究团队提出了一个反直觉的方案------SubspaceAD:用冻结的 DINOv2-G 提取 patch 特征,再用 PCA 拟合正常样本的低维子空间,推理时仅计算重建残差即可定位异常。整个方法无需训练、无需记忆库、无需提示调优,每个品类模型存储不到 1MB,新品类上线只需拍 1 张正常样品照片即可完成部署,适合多品种、频繁换线的制造场景。在 1-shot 设定下,SubspaceAD 在 MVTec-AD 上达到图像级 AUROC 98.0%、像素级 AUROC 97.6%,在 VisA 上达到图像级 93.3%、像素级 98.3%,在 1-shot 设定下超越此前的记忆库方法、重建方法和 VLM 方法。
目录
[二、DINOv2 + PCA:一个极简但有效的方案](#二、DINOv2 + PCA:一个极简但有效的方案)
[2.1 特征提取](#2.1 特征提取)
[2.2 PCA 子空间建模](#2.2 PCA 子空间建模)
[2.3 推理与异常定位](#2.3 推理与异常定位)
[2.4 工业部署优势](#2.4 工业部署优势)
[三、1-shot 即达 SOTA:两大基准大幅领先](#三、1-shot 即达 SOTA:两大基准大幅领先)
[3.1 主实验:1/2/4-shot 对比](#3.1 主实验:1/2/4-shot 对比)
[3.2 Batched 0-shot:无参考图像的极端场景](#3.2 Batched 0-shot:无参考图像的极端场景)
[4.1 特征聚合策略](#4.1 特征聚合策略)
[4.2 骨干网络规模](#4.2 骨干网络规模)
[4.3 PCA 解释方差阈值 τ](#4.3 PCA 解释方差阈值 τ)
[4.4 图像分辨率](#4.4 图像分辨率)
论文标题:SubspaceAD: Training-Free Few-Shot Anomaly Detection via Subspace Modeling
**作者:**Camile Lendering, Erkut Akdag, Egor Bondarev
**机构:**AIMS Group, Department of Electrical Engineering, Eindhoven University of Technology
**代码:**https://github.com/CLendering/SubspaceAD
一、少样本异常检测为什么越来越复杂?
工业巡检中,异常样本稀缺是常态。现有少样本异常检测方法大致分为三类:
| 类别 | 代表方法 | 核心思路 | 局限 |
|---|---|---|---|
| 重建类 | FastRecon、Transfusion | 学习只重建正常样本,异常区域重建失败 | 需要训练、超参调优,易过度泛化 |
| 记忆库类 | PatchCore、AnomalyDINO | 存储正常 patch 特征,推理时近邻匹配 | 需存储数千至百万级 patch 描述子,推理开销大 |
| VLM 类 | WinCLIP、PromptAD、IIPAD | 利用 CLIP 等模型的文本提示检测异常 | 依赖提示调优或辅助数据,遵循"一类一提示"范式 |
这三类方法性能不断提升,但复杂度也在攀升:数据增强、多阶段训练、辅助损失、大规模记忆库层层叠加。与此同时,DINOv2 等视觉基础模型已经能提取高质量的稠密特征。SubspaceAD 的核心问题是:有了足够好的特征表示,还需要这些复杂流程吗?
答案是不需要。
二、DINOv2 + PCA:一个极简但有效的方案
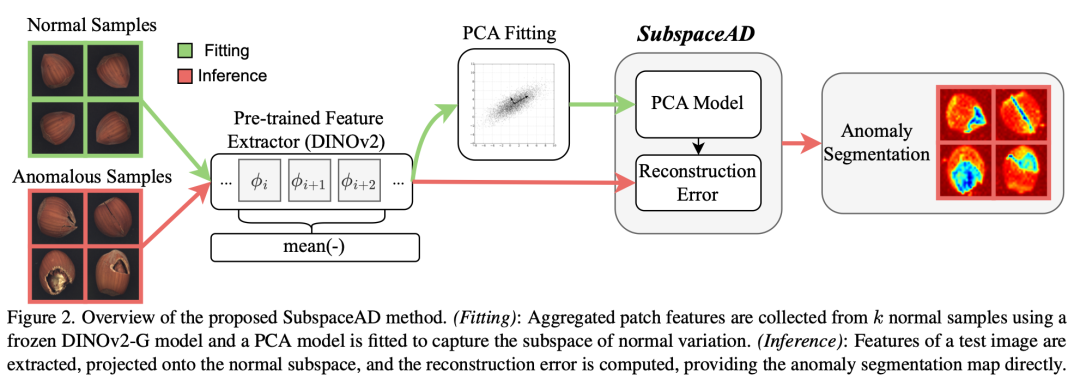
SubspaceAD 的方法分为两个阶段:拟合(Fitting)和推理(Inference)。

图片来源于原论文
2.1 特征提取
使用冻结的 DINOv2-G(ViT-G/14 with Registers)作为特征提取器。每张图像被切分为 14×14 的 patch,每个 patch 产生一个 1536 维的特征向量。
关键设计:不使用最后一层特征,而是对中间层(第 22--28 层)的 patch token 取平均。原因在于:
-
最深层倾向于将局部细节压缩为类别级抽象,丢失空间细节
-
中间层兼具语义信息和结构信息
-
多层平均能稳定协方差估计,减少单层噪声
对 k 张正常图像各施加 Na=30 次随机旋转增强(0°--345°),得到 k×31 张图像的全部 patch 特征集合 X_normal。
2.2 PCA 子空间建模
对 X_normal 计算均值 μ 和协方差矩阵 Σ,取前 r 个主成分(解释方差阈值 τ=0.99),得到正交基矩阵 C ∈ R^{D×r}。
核心假设:正常 patch 特征分布在一个低维线性子空间附近,异常区域的特征偏离这个子空间。这是一个经典的统计学原理------异常即为主成分子空间的离群点。
2.3 推理与异常定位
对测试图像的每个 patch 特征 x_p:
-
投影:x_proj = μ + CC^T(x_p − μ)
-
异常分数:S(x_p) = ‖x_p − x_proj‖²(重建残差)
-
图像级聚合 :取异常分数最高的 top 1% patch 均值(TVaR统计量)
-
像素级可视化:双线性上采样 + 高斯平滑(σ=4)
整个推理过程:672×672 图像在单卡 H100 上约 300ms,其中 DINOv2 前向传播占 270ms,PCA 投影和打分仅需 30ms。模型存储仅需均值向量 μ 和基矩阵 C,每个类别不到 1MB。
2.4 工业部署优势
从工程落地角度看,SubspaceAD 相比现有方法有明显的部署优势:
| 对比维度 | 记忆库类(PatchCore等) | VLM 类(PromptAD等) | SubspaceAD |
|---|---|---|---|
| 新品类上线 | 需采集大量正常样本构建记忆库 | 需设计/训练品类专属提示 | 拍1张正常图,秒级PCA拟合即可上线 |
| 模型存储 | 需存储数千至百万级patch描述子 | 依赖完整VLM权重 | 每品类 <1MB(均值+基矩阵) |
| 训练成本 | 部分方法需微调 | 需提示调优或适配训练 | 零训练,无GPU训练开销 |
| 推理依赖 | 大规模近邻搜索 | VLM前向+提示编码 | DINOv2前向+矩阵乘法 |
| 超参调优 | 核心集大小、近邻数等 | 提示模板、学习率等 | 仅方差阈值τ,且对τ不敏感 |
对于产线频繁切换品类的场景(如电子元器件多品种混线生产),SubspaceAD 的"拍照即部署"特性意味着:换一个品类只需要采集 1--4 张正常样本、运行一次 PCA 拟合(耗时可忽略),无需重新训练模型或重建记忆库。
三、1-shot 即达 SOTA:两大基准大幅领先
3.1 主实验:1/2/4-shot 对比
在 MVTec-AD 和 VisA 两个标准基准上的完整对比(单位:%):
MVTec-AD(1-shot):
| 方法 | 类型 | 图像 AUROC | 图像 AUPR | 像素 AUROC | PRO |
|---|---|---|---|---|---|
| SPADE | 记忆库 | 81.0 | 90.6 | 91.2 | 83.9 |
| PatchCore | 记忆库 | 83.4 | 92.2 | 92.0 | 79.7 |
| WinCLIP | VLM | 93.1 | 96.5 | 95.2 | 87.1 |
| PromptAD | VLM | 94.6 | 97.1 | 95.9 | 87.9 |
| IIPAD | VLM | 94.2 | 97.2 | 96.4 | 89.8 |
| AnomalyDINO | 记忆库 | 96.6 | 98.2 | 96.8 | 92.7 |
| SubspaceAD | PCA | 98.0 | 99.0 | 97.6 | 93.7 |
VisA(1-shot):
| 方法 | 类型 | 图像 AUROC | 图像 AUPR | 像素 AUROC | PRO |
|---|---|---|---|---|---|
| SPADE | 记忆库 | 79.5 | 82.0 | 95.6 | 84.1 |
| PatchCore | 记忆库 | 79.9 | 82.8 | 95.4 | 80.5 |
| WinCLIP | VLM | 83.8 | 85.1 | 96.4 | 85.1 |
| PromptAD | VLM | 86.9 | 88.4 | 96.7 | 85.1 |
| IIPAD | VLM | 85.4 | 87.5 | 96.9 | 87.3 |
| AnomalyDINO | 记忆库 | 87.4 | 89.0 | 97.8 | 92.5 |
| SubspaceAD | PCA | 93.3 | 93.2 | 98.3 | 93.4 |
在 VisA 上,SubspaceAD 的图像级 AUROC 比此前最优的 AnomalyDINO 高出 +5.9% 。
随着 shot 数增加,SubspaceAD 保持领先。4-shot 时,MVTec-AD 图像级 AUROC 达 98.4%,VisA 达 94.5%。
3.2 Batched 0-shot:无参考图像的极端场景
SubspaceAD 还支持 batched 0-shot 设定------直接用整个测试集拟合 PCA(假设大部分 patch 为正常):
| 方法 | MVTec-AD | VisA |
|---|---|---|
| WinCLIP | 91.8 | 78.1 |
| AnomalyCLIP | 91.5 | 82.1 |
| MuSc | 97.8 | 94.1 |
| AnomalyDINO | 94.2 | 90.7 |
| SubspaceAD | 96.6 | 97.7 |
在 VisA 上以 97.7% 大幅领先 MuSc(94.1%)达+3.6%。
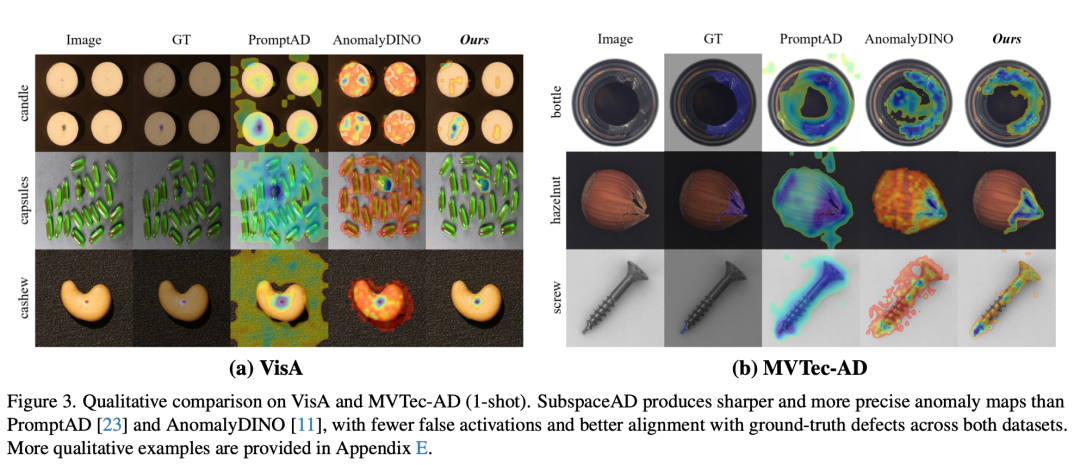
图片来源于原论文
四、消融实验:哪些设计选择最关键?
4.1 特征聚合策略
| 策略 | MVTec-AD I-AUROC | MVTec-AD PRO | VisA I-AUROC | VisA PRO |
|---|---|---|---|---|
| Mean-pool(中间7层,22-28) | 98.4 | 94.2 | 94.5 | 94.1 |
| Mean-pool(最后7层,34-40) | 98.2 | 92.3 | 91.9 | 90.3 |
| Concat(中间7层) | 98.6 | 94.2 | 93.8 | 93.1 |
| 仅最后一层 | 97.5 | 91.4 | 89.1 | 88.3 |
仅用最后一层特征在 VisA 上 I-AUROC 掉至 89.1%,中间层平均策略比最后层平均高出 +2.6%(VisA I-AUROC)。
4.2 骨干网络规模
DINOv2 从 ViT-S 到 ViT-G 的性能单调递增,验证了更强的基础特征直接增强 PCA 子空间建模效果。
4.3 PCA 解释方差阈值 τ
τ 在 0.95--0.99 范围内性能稳定。但 τ=1.00 时性能崩溃(MVTec-AD I-AUROC 从 98.0% 骤降至 45.3%),因为保留全部方差等于不做降维,丧失了"异常在残差子空间中"这一核心机制。
4.4 图像分辨率
672px 在两个数据集上均为最优分辨率。VisA 对分辨率更敏感(高分辨率收益更明显),MVTec-AD 从 448px 起即相对稳定。
图片来源于原论文
五、总结与工业部署展望
SubspaceAD 提出了一个极其简洁的少样本异常检测方案:冻结 DINOv2-G 提取中间层 patch 特征 → PCA 拟合正常子空间 → 重建残差作为异常分数。无需训练、无需记忆库、无需提示调优,模型存储不到 1MB,单张图像推理约 300ms。
方法的核心洞察是:当视觉基础模型的特征质量足够好时,经典的统计方法就能胜过复杂的深度学习流程。这与近年来异常检测领域不断"加法"的趋势形成对比------越来越多的模块、损失函数和训练策略被堆叠上去,但 SubspaceAD 证明了"做减法"同样可以达到 SOTA。
从工业部署角度看,SubspaceAD 的价值不仅在于精度领先,更在于它将异常检测系统的部署复杂度降到了极低水平:无需 GPU 训练、无需大规模数据采集、无需专业算法工程师调参,产线工程师拍几张正常样品照片即可完成品类上线。对于多品种、小批量、频繁换线的制造场景,这种"即拍即用"的特性具有直接的工程价值。
值得注意的局限:方法强依赖 DINOv2-G 的特征质量(换用 ViT-S 性能明显下降),DINOv2-G 本身是一个较大的模型(约 1.1B 参数),对边缘设备的推理能力有一定要求。此外,PCA 假设正常特征分布在线性子空间附近,对某些非线性分布模式可能不够灵活。