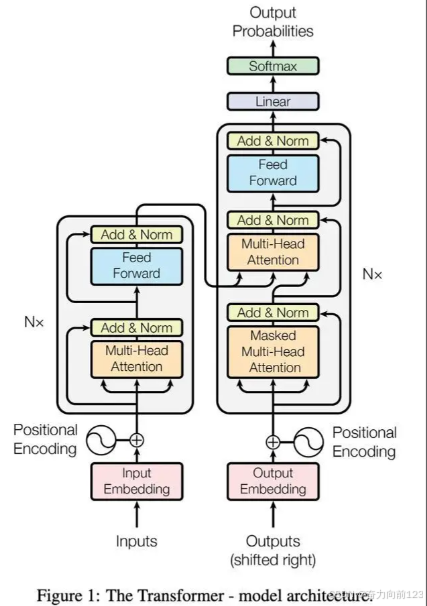
要实现Transformer模型,我们可以使用PyTorch框架,因为它提供了丰富的张量操作和自动微分功能,适合构建深度学习模型。以下是一个完整的Transformer实现,包括编码器、解码器、注意力机制等核心组件:
1、导入必要的库
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math2、实现位置编码
python
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 预计算位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe) # 注册为缓冲区,不参与参数更新
def forward(self, x):
# x: (batch_size, seq_len, d_model)
seq_len = x.size(1)
x = x + self.pe[:, :seq_len, :]
return x3、实现Scaled Dot-Product Attention
python
class ScaledDotProductAttention(nn.Module):
def __init__(self, dropout=0.1):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
# q: (batch_size, num_heads, seq_len_q, d_k)
# k: (batch_size, num_heads, seq_len_k, d_k)
# v: (batch_size, num_heads, seq_len_v, d_v)
# mask: (batch_size, 1, 1, seq_len_k) 或 (batch_size, 1, seq_len_q, seq_len_k)
d_k = q.size(-1)
# 计算注意力分数: Q·K^T / sqrt(d_k)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
# 应用掩码
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 归一化注意力分数
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 注意力加权和
output = torch.matmul(attn_weights, v)
return output, attn_weights4、实现多头注意力
python
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_k = d_model // num_heads
self.num_heads = num_heads
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention(dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
# q, k, v: (batch_size, seq_len, d_model)
batch_size = q.size(0)
# 线性变换并分多头
q = self.W_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = self.W_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = self.W_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 应用注意力
output, attn_weights = self.attention(q, k, v, mask)
# 拼接多头结果
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
# 最终线性变换
output = self.W_o(output)
return output, attn_weights5、实现前馈网络
python
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# x: (batch_size, seq_len, d_model)
x = self.dropout(F.relu(self.fc1(x)))
x = self.fc2(x)
return x6、实现编码器层
python
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# x: (batch_size, seq_len, d_model)
# 自注意力子层
attn_output, _ = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 前馈子层
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x7、实现解码器层
python
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.masked_self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.encoder_decoder_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
# x: (batch_size, tgt_seq_len, d_model)
# enc_output: (batch_size, src_seq_len, d_model)
# 掩码自注意力子层(防止关注未来位置)
attn_output, _ = self.masked_self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 编码器-解码器注意力子层
attn_output, _ = self.encoder_decoder_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
# 前馈子层
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x8、实现完整的Transformer模型
python
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8, num_layers=6, d_ff=2048, dropout=0.1):
super(Transformer, self).__init__()
# 编码器
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 解码器
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 输出层
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, src, tgt, src_mask, tgt_mask):
# src: (batch_size, src_seq_len)
# tgt: (batch_size, tgt_seq_len)
# 编码器前向传播
src_emb = self.dropout(self.pos_encoding(self.encoder_embedding(src)))
enc_output = src_emb
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
# 解码器前向传播
tgt_emb = self.dropout(self.pos_encoding(self.decoder_embedding(tgt)))
dec_output = tgt_emb
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
# 输出层
output = self.fc_out(dec_output)
return output9、使用示例(简单的序列到序列任务)
python
def create_mask(src, tgt, pad_idx=0):
# 源序列掩码(掩盖填充位置)
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2) # (batch_size, 1, 1, src_seq_len)
# 目标序列掩码(掩盖填充位置和未来位置)
tgt_seq_len = tgt.size(1)
tgt_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(3) # (batch_size, 1, tgt_seq_len, 1)
# 上三角掩码(防止关注未来位置)
nopeak_mask = torch.triu(torch.ones(1, tgt_seq_len, tgt_seq_len), diagonal=1).bool()
tgt_mask = tgt_mask & ~nopeak_mask # (batch_size, 1, tgt_seq_len, tgt_seq_len)
return src_mask, tgt_mask
# 示例用法
if __name__ == "__main__":
# 超参数
src_vocab_size = 1000
tgt_vocab_size = 1000
d_model = 512
num_heads = 8
num_layers = 3
d_ff = 2048
dropout = 0.1
batch_size = 2
src_seq_len = 10
tgt_seq_len = 8
# 创建模型
model = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, dropout)
# 生成随机输入
src = torch.randint(1, src_vocab_size, (batch_size, src_seq_len)) # 源序列
tgt = torch.randint(1, tgt_vocab_size, (batch_size, tgt_seq_len)) # 目标序列
# 创建掩码
src_mask, tgt_mask = create_mask(src, tgt)
# 前向传播
output = model(src, tgt, src_mask, tgt_mask)
print("Output shape:", output.shape) # 期望: (batch_size, tgt_seq_len, tgt_vocab_size)代码说明
- 位置编码:使用正弦和余弦函数生成位置信息,注入到词嵌入中。
- 注意力机制:实现了Scaled Dot-Product Attention和多头注意力,处理序列间的依赖关系。
- 编码器:由多层自注意力和前馈网络组成,处理输入序列。
- 解码器:由掩码自注意力(防止关注未来位置)、编码器-解码器注意力和前馈网络组成,生成输出序列。
- 完整模型:整合编码器、解码器和输出层,实现端到端的序列到序列转换。
运行要求
- Python 3.6+
- PyTorch 1.6+