https://www.cnblogs.com/timlly/p/10631718.html

matlab,从来不知道这样的东西,...和python的关系--
大致上和py也挺像的,但py还是有一些反复写的.....,这样的库关系让代码不受待见
python的确可以做一样的事情,但现在gpt里也可以直接run python了,环境也不用自己配了。
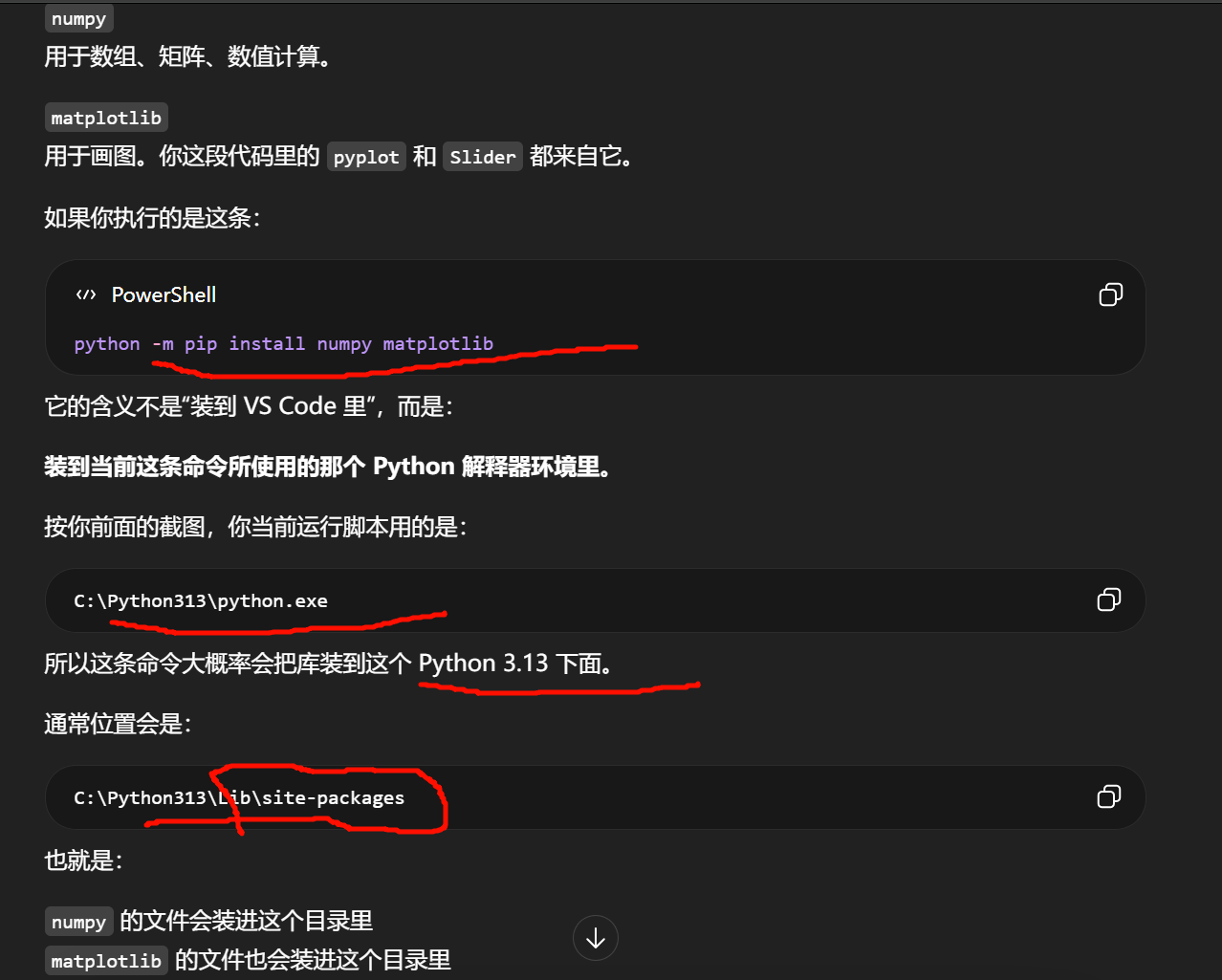
同时,有些可执行脚本会放到:
overflow-visible!
C:\Python313\Scripts
你可以把它理解成:
Lib\site-packages = Python 第三方库仓库
Scripts = 这个环境附带的一些命令工具
pip install ... 安装的是"当前 Python 环境的依赖",
不是"全电脑通用插件"。
你用哪个 python.exe 运行脚本
就用哪个 python.exe -m pip install ... 装库
matplotlib 很难稳定跑到 60 FPS,尤其在 Windows 和交互窗口里。
vscode
F5 运行并调试
Ctrl+F5 不调试直接运行
https://zhuanlan.zhihu.com/p/141595120
matlab转python,也很快,但里面运行起来的确如博主说的,很卡
python
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
def rotation_matrix(theta: float) -> np.ndarray:
c = np.cos(theta)
s = np.sin(theta)
return np.array([[c, -s], [s, c]], dtype=np.float64)
def rotate_about(points: np.ndarray, theta: float, center: np.ndarray) -> np.ndarray:
return rotation_matrix(theta) @ (points - center[:, None]) + center[:, None]
def build_geneva_geometry(a: float, r_nominal: float, r_pin: float, r_s: float, h: float):
center_geneva = np.array([a, 0.0], dtype=np.float64)
xy_geneva_1 = np.zeros((2, 183), dtype=np.float64)
xy_geneva_1[:, 0] = [a - r_nominal, -r_pin]
index = 1
for angle_deg in np.linspace(-90.0, 90.0, 181):
theta = np.deg2rad(angle_deg)
xy_geneva_1[:, index] = np.array(
[r_pin * np.cos(theta), r_pin * np.sin(theta)],
dtype=np.float64,
) + np.array([a - r_nominal + h - r_pin, 0.0], dtype=np.float64)
index += 1
xy_geneva_1[:, index] = [a - r_nominal, r_pin]
xy_geneva_2 = rotate_about(xy_geneva_1, np.pi / 2, center_geneva)
xy_geneva_3 = rotate_about(xy_geneva_2, np.pi / 2, center_geneva)
xy_geneva_4 = rotate_about(xy_geneva_3, np.pi / 2, center_geneva)
xy_geneva_circle_1 = np.zeros((2, 0), dtype=np.float64)
xy_geneva_circle_1 = np.column_stack((xy_geneva_circle_1, xy_geneva_1[:, -1]))
for angle_deg in np.linspace(-180.0, 180.0, 361):
alpha = np.deg2rad(angle_deg)
x = r_s * np.cos(alpha) - a
y = r_s * np.sin(alpha)
rotated = rotation_matrix(-np.pi / 4) @ np.array([x, y], dtype=np.float64)
rotated += center_geneva
if np.max(np.abs([rotated[0] - a, rotated[1]])) <= r_nominal:
xy_geneva_circle_1 = np.column_stack((xy_geneva_circle_1, rotated))
xy_geneva_circle_1 = np.column_stack((xy_geneva_circle_1, xy_geneva_4[:, 0]))
xy_geneva_circle_2 = rotate_about(xy_geneva_circle_1, np.pi / 2, center_geneva)
xy_geneva_circle_3 = rotate_about(xy_geneva_circle_2, np.pi / 2, center_geneva)
xy_geneva_circle_4 = rotate_about(xy_geneva_circle_3, np.pi / 2, center_geneva)
slots = [xy_geneva_1, xy_geneva_2, xy_geneva_3, xy_geneva_4]
arcs = [xy_geneva_circle_1, xy_geneva_circle_2, xy_geneva_circle_3, xy_geneva_circle_4]
return center_geneva, slots, arcs
def main():
a = 150.0
r = 150.0 * np.cos(np.pi / 4)
r_nominal = r
r_pin = 10.0
r_s = 75.0
h = 80.0
total_angle = 360 * 4
n = total_angle * 2 + 1
delta_theta_deg = 0.5
omega = 15 * 2 * np.pi / 60
delta_time = np.deg2rad(delta_theta_deg) / omega
circle_theta = np.deg2rad(np.linspace(0.0, 360.0, 361))
circle_pin = np.vstack((r_pin * np.cos(circle_theta) + r, r_pin * np.sin(circle_theta)))
motion_theta = np.deg2rad(np.linspace(0.0, total_angle, n))
xy_pin = np.vstack((r * np.cos(motion_theta), r * np.sin(motion_theta)))
xy_driver_plate = np.zeros((2, 273), dtype=np.float64)
arc_theta = np.deg2rad(np.linspace(45.0, 315.0, 271))
xy_driver_plate[:, 1:272] = np.vstack((r_s * np.cos(arc_theta), r_s * np.sin(arc_theta)))
center_geneva, slots, arcs = build_geneva_geometry(a, r_nominal, r_pin, r_s, h)
basis_center = center_geneva[:, None]
theta_geneva = np.zeros(n, dtype=np.float64)
delta_theta_geneva = 90.0
stop_theta_geneva = 0.0
frame_data = []
for index, theta in enumerate(motion_theta):
driver_rot = rotation_matrix(theta)
circle_pin_temp = driver_rot @ circle_pin
driver_plate_temp = driver_rot @ xy_driver_plate
geneva_center_pin_vec = xy_pin[:, index] - center_geneva
if np.linalg.norm(geneva_center_pin_vec) <= r_nominal:
cos_theta_geneva = geneva_center_pin_vec[0] / np.linalg.norm(geneva_center_pin_vec)
theta_geneva[index] = np.rad2deg(np.arccos(np.abs(cos_theta_geneva)))
if xy_pin[1, index] < 0:
theta_geneva[index] = -theta_geneva[index] + delta_theta_geneva / 2 + stop_theta_geneva
else:
theta_geneva[index] = theta_geneva[index] + delta_theta_geneva / 2 + stop_theta_geneva
else:
theta_geneva[index] = theta_geneva[index - 1] if index > 0 else 0.0
stop_theta_geneva = theta_geneva[index]
geneva_theta = -np.deg2rad(theta_geneva[index] - delta_theta_geneva / 2)
geneva_rot = rotation_matrix(geneva_theta)
slots_temp = [geneva_rot @ (slot - basis_center) + basis_center for slot in slots]
arcs_temp = [geneva_rot @ (arc - basis_center) + basis_center for arc in arcs]
frame_data.append(
{
"driver_plate": driver_plate_temp,
"pin_line": np.array([[0.0, xy_pin[0, index]], [0.0, xy_pin[1, index]]], dtype=np.float64),
"pin_circle": circle_pin_temp,
"slots": slots_temp,
"arcs": arcs_temp,
}
)
omega_geneva = np.zeros(n, dtype=np.float64)
omega_geneva[0] = (theta_geneva[1] - theta_geneva[0]) / delta_time
omega_geneva[1:-1] = (theta_geneva[2:] - theta_geneva[:-2]) / (2 * delta_time)
omega_geneva[-1] = (theta_geneva[-1] - theta_geneva[-2]) / delta_time
fig, (ax_anim, ax_angle, ax_omega) = plt.subplots(3, 1, figsize=(8, 12))
fig.canvas.manager.set_window_title("09 Geneva Mechanism")
ax_anim.set_xlim(-150, 300)
ax_anim.set_ylim(-150, 150)
ax_anim.set_aspect("equal", adjustable="box")
ax_anim.grid(False)
ax_anim.set_title("Geneva Mechanism Animation")
ax_anim.plot([-120, 270], [0, 0], "-.k", linewidth=1)
ax_anim.plot([0, 0], [-120, 120], "-.k", linewidth=1)
ax_anim.plot(center_geneva[0], center_geneva[1], "o", markersize=5, markerfacecolor="black", markeredgecolor="black")
driver_plate_line, = ax_anim.plot([], [], "k", linewidth=2)
pin_line, = ax_anim.plot([], [], "k", linewidth=2)
pin_circle_line, = ax_anim.plot([], [], "k", linewidth=2)
slot_lines = [ax_anim.plot([], [], "k", linewidth=2)[0] for _ in range(4)]
arc_lines = [ax_anim.plot([], [], "k", linewidth=2)[0] for _ in range(4)]
ax_angle.plot(np.linspace(1, total_angle, n), theta_geneva - delta_theta_geneva / 2)
ax_angle.grid(True)
ax_angle.set_title("Geneva Angle vs Driver Angle")
ax_angle.set_xlabel("Driver angle (deg)")
ax_angle.set_ylabel("Geneva angle (deg)")
ax_omega.plot((np.linspace(1, total_angle, n) * np.pi / 180) / omega, omega_geneva)
ax_omega.grid(True)
ax_omega.set_title("Geneva Angular Velocity vs Time")
ax_omega.set_xlabel("Time (s)")
ax_omega.set_ylabel("Angular velocity (rad/s)")
def update(frame_index: int):
current = frame_data[frame_index]
driver_plate_line.set_data(current["driver_plate"][0], current["driver_plate"][1])
pin_line.set_data(current["pin_line"][0], current["pin_line"][1])
pin_circle_line.set_data(current["pin_circle"][0], current["pin_circle"][1])
for artist, points in zip(slot_lines, current["slots"]):
artist.set_data(points[0], points[1])
for artist, points in zip(arc_lines, current["arcs"]):
artist.set_data(points[0], points[1])
return [driver_plate_line, pin_line, pin_circle_line, *slot_lines, *arc_lines]
animation = FuncAnimation(
fig,
update,
frames=len(frame_data),
interval=50,
blit=False,
repeat=True,
cache_frame_data=False,
)
plt.tight_layout()
fig._animation = animation
plt.show()
if __name__ == "__main__":
main()https://www.disneyanimation.com/open-source/?
https://www.cnblogs.com/timlly/p/10631718.html
这个引用,gpu gem 看到过很多次了,这个siggraph Course也不知道是什么

的确每个slide和Course note里都有很多东西,能把这些引用都带上,。
https://renderwonk.com/publications/s2010-shading-course/
课程评审材料还特别强调,要让"来自不同专业背景的 jury"能看懂课程结构和收获,这本身就说明它面向的是跨背景、跨层次受众,而不是单纯 beginner 教学。
Courses 往往是专题拼装,不是单讲师长课。一个 topic 往往会拆成多个子块,由不同讲者分别负责。这样做的优点是每一段都由更贴近该子方向的一线人来讲,信息密度高;缺点就是统一叙事、统一术语、统一前置知识铺垫往往没那么强,所以看起来会像"几个人轮流做 mini-talk"。这不是你错觉,而是 conference tutorial 常见形态。
SIGGRAPH 本身是跨行业社区,不是单一学科课堂。官方一直把它定位成覆盖 research、development、creativity、production 等多个面向的 interdisciplinary educational experience。这样的会议环境下,course 设计天然更像"把不同视角的人拉到一个专题里",而不是按教科书逻辑从基础定义一路讲到习题。
https://www.cnblogs.com/timlly/p/11098212.html
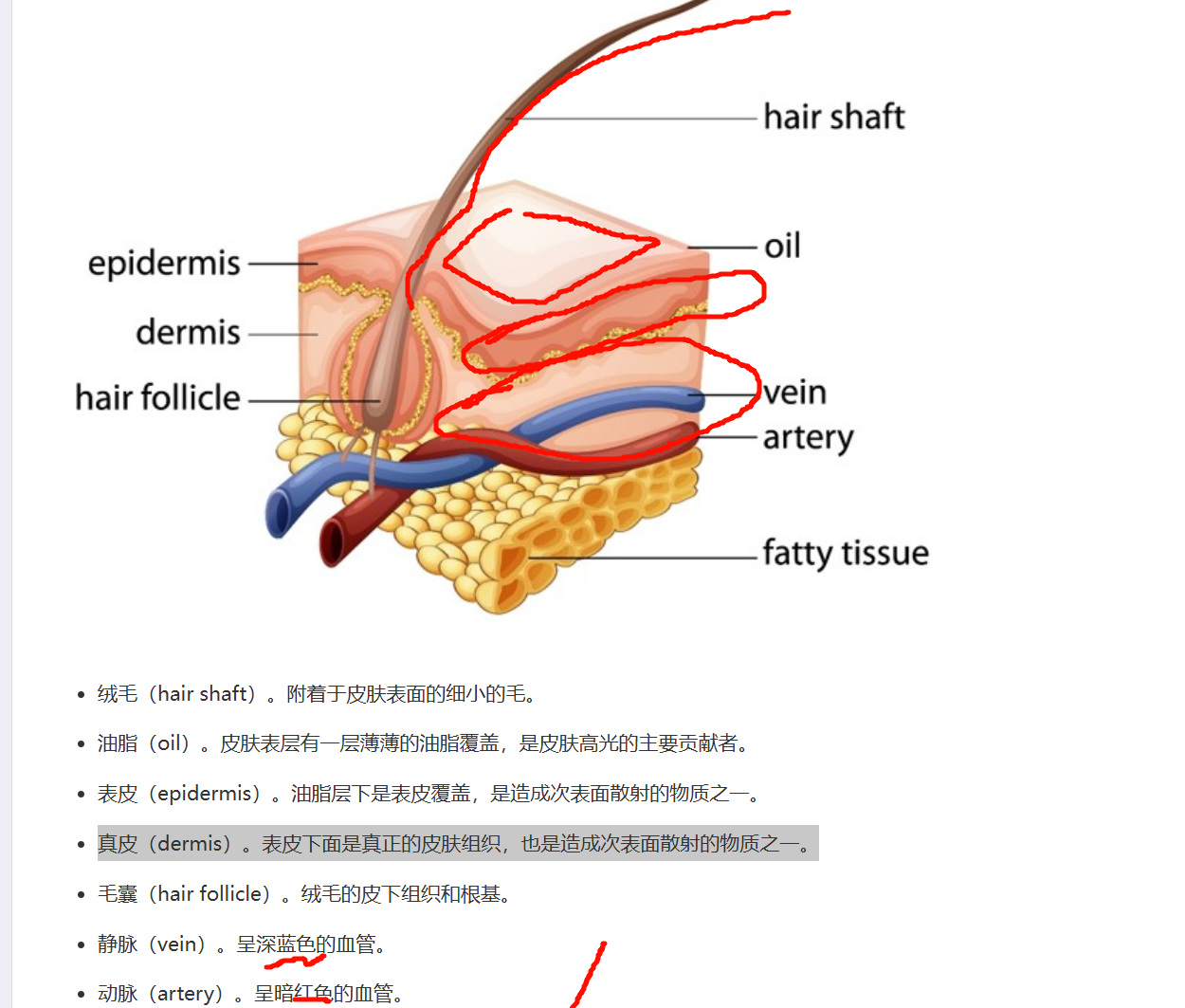
皮肤高光的主要贡献者。
油脂(oil)。
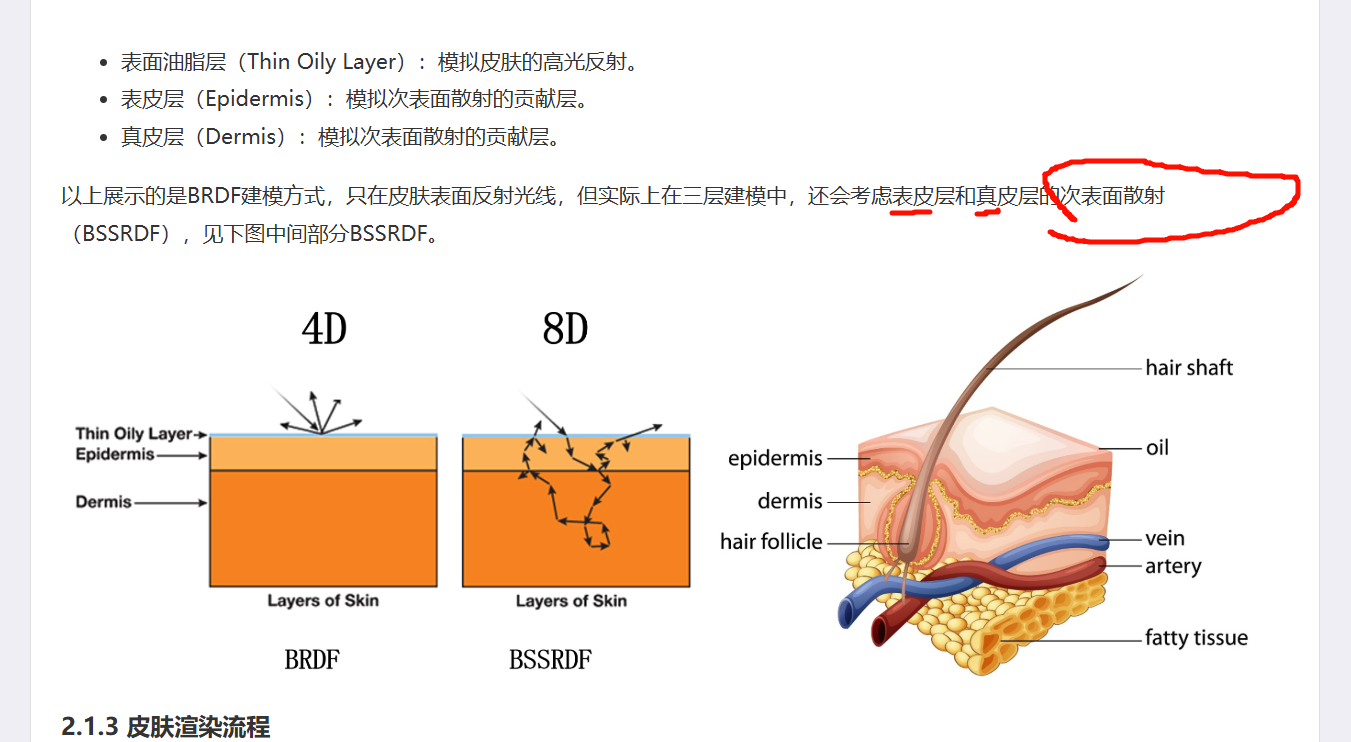
表皮(epidermis)。油脂层下是表皮覆盖,是造成次表面散射的物质之一。
"屏幕上的数值,并不等于你眼睛感受到的亮度。"
也就是:
RGB 数值和视觉亮度,不是线性对应的。
你可以把图拆开理解。
左右两边的竖条区域,其实不是纯灰。
它们是由很多黑白细线组成的:
黑 = 0
白 = 255
因为黑白线一半一半,远一点看时,你眼睛会把它平均掉,感觉成一个"中间灰",平均值大约是 127.5。
中间有两个纯色矩形:
上面的矩形数值是 128
下面的矩形数值是 187
作者让你退远看,是为了让你把左右两边的黑白线"看成一整块灰"。
这时候你会发现:
左右两边那种"黑白平均后的灰",看起来更接近下面那个 187 的灰块,
而不是更接近上面那个 128 的灰块。
这就是作者想表达的关键:
虽然左右两边平均数值是 127.5,和 128 非常接近,
但视觉上它却不像 128,反而更像 187。
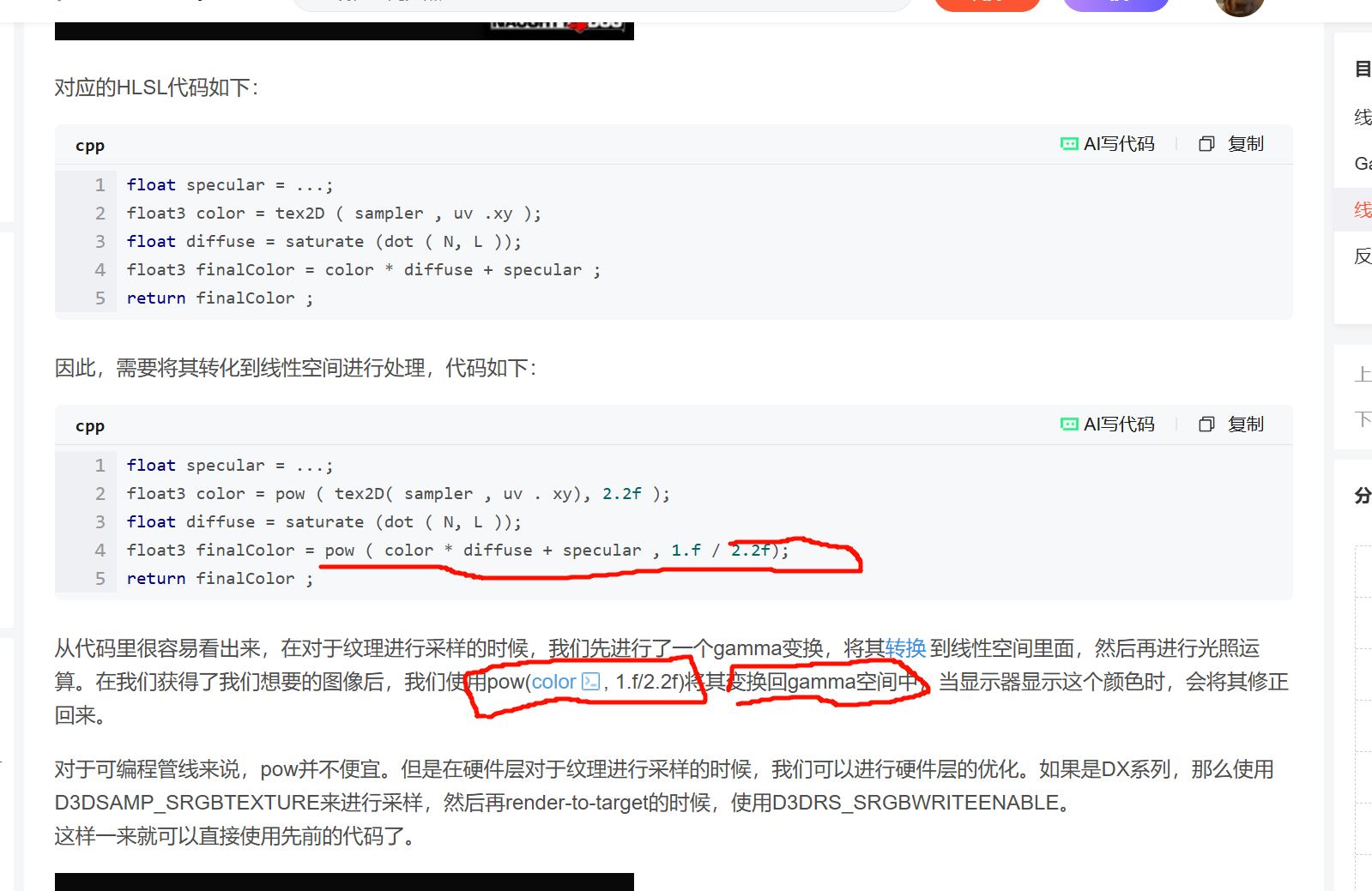
因此在显示器上所显示出来的效果就是Gamma空间,换句话说,大多数的美术人员都是工作在Gamma空间下的。
这个校正在大多数显示器或者 游戏引擎 中都是以pow(x, 2.2)的形式存在。
根据不同的显示器Gamma曲线可能也有不同,例如Mac的显示器的Gamma曲线为1.8.
在游戏中常用的sRGB也与Gamma曲线相接近。
很多时候可以通过Gamma校正来对图像进行一些操作。例如当图像太亮,则可以使用使用pow(x, 2.2)的修正来让它变得正常一些。
显示器将图片调亮了,那么存储在硬盘中的图像比起显示器中的图像要暗一些。
这样就解释了没有经验的打印店老板所打印的美术作品有时会偏暗的原因。
正因为这个原因,大多数的商业照相机都内置了Gamma校正 ------ 通过将图像存储在Gamma空间中,当传感器接收到 光 照的时候,摄像机会使用pow(x, 1/2.2)再进行量化。因此储存的图像要比真实场景更亮一些,只是在显示在显示器的时候,这个差值会被修正。
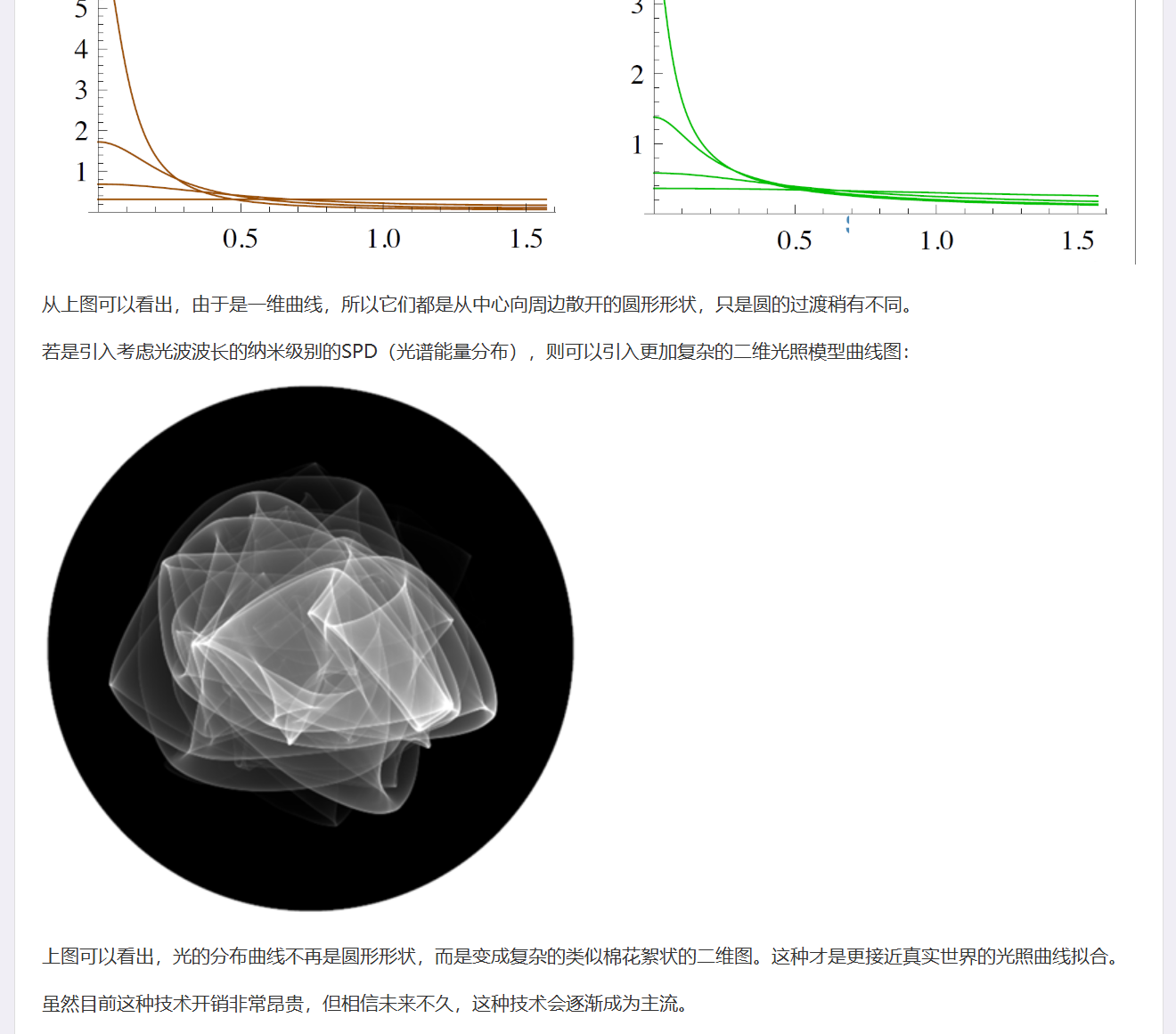
在亮处的地方颜色的衰减比较快,在暗处的地方颜色的衰减比较慢,整体上看起来非常柔和。另一方面,色彩的偏移非常明显,尤其在Specular高光那里尤其明显。、
https://blog.csdn.net/noahzuo/article/details/51542607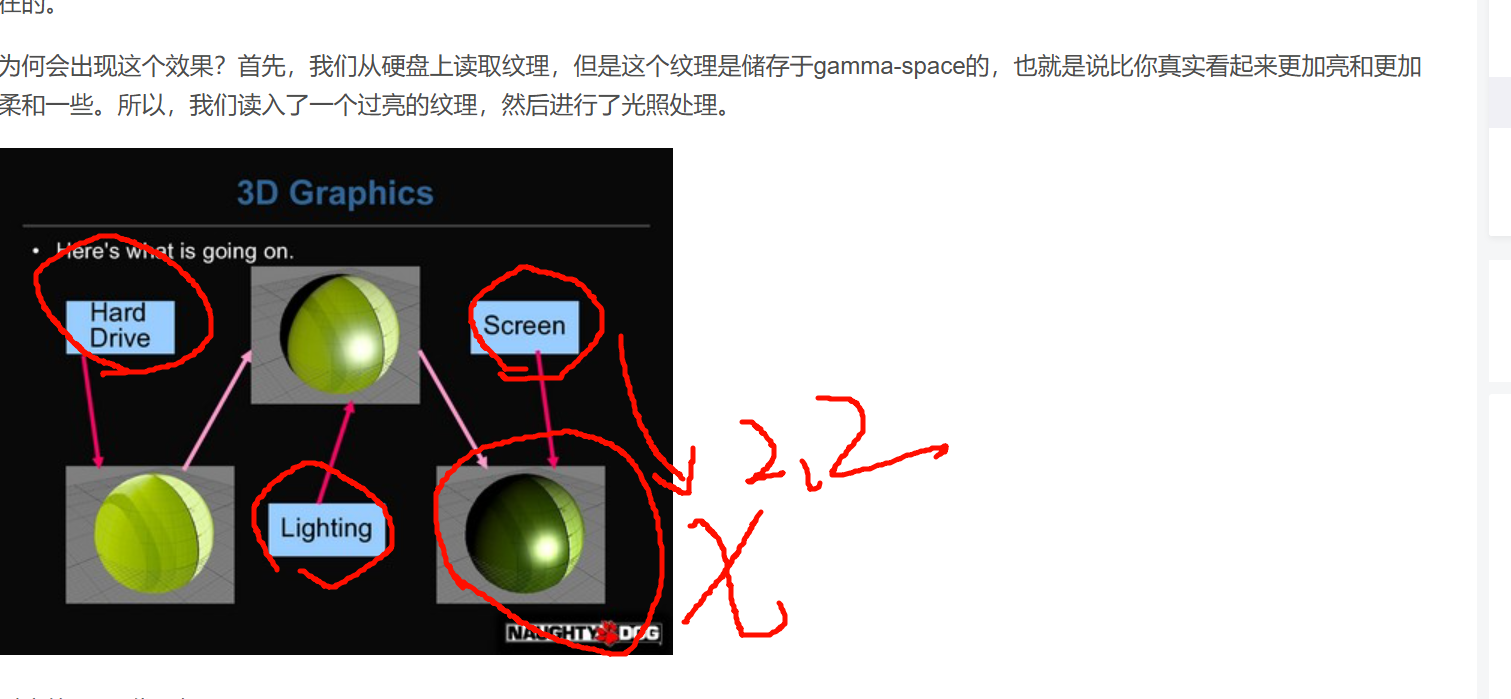
如果这张图片是"颜色贴图 / BaseColor / Albedo / UI 颜色图"这类用于显示颜色 的纹理,磁盘里通常就是按 sRGB / gamma 编码 存的。
这时候导入引擎时 开启 sRGB,意思是:
"这张纹理文件里的数值不是线性光能值,而是 gamma 编码后的显示值。采样时请先帮我转回 linear,再参与运算。"
磁盘里的图片:sRGB / gamma 编码
导入纹理:勾选 sRGB
Shader 采样后:自动得到 linear 值
在线性空间做光照、混合、插值
最后输出到屏幕时:再做一次 linear -> sRGB/gamma
所以你说的"开着 sRGB 就可以",如果前提是这张图本来就是给人看的颜色图,那基本就是对的。
"linear -> sRGB/gamma" 这一步通常是 GPU/渲染管线在输出阶段做的,不是显示器替你把线性值自动变成 gamma。
现实里的显示链路整体上接近一个非线性响应,所以大家约定用 sRGB/gamma 编码 来存储和传输"最终给显示看的图像"。
最后写回 LDR 显示目标时,GPU/图形 API 会把 linear 再编码成 sRGB 。
显示器收到的是这种"适合显示链路"的非线性编码值,然后显示出来。
GPU 往显示链路送出的,通常已经是编码后的 sRGB/gamma 风格值;显示器不是替你做一次标准的 linear->gamma 编码,而是按自己的电光响应把输入码值变成实际亮度。
可以把显示器理解成"物理发光设备",不是"颜色空间转换器"。
如果是 HDR / 浮点 RT
中间过程往往保持 linear,不会立刻 sRGB encode。
等到最后 tone mapping + display mapping 那一步,才转成最终显示格式。
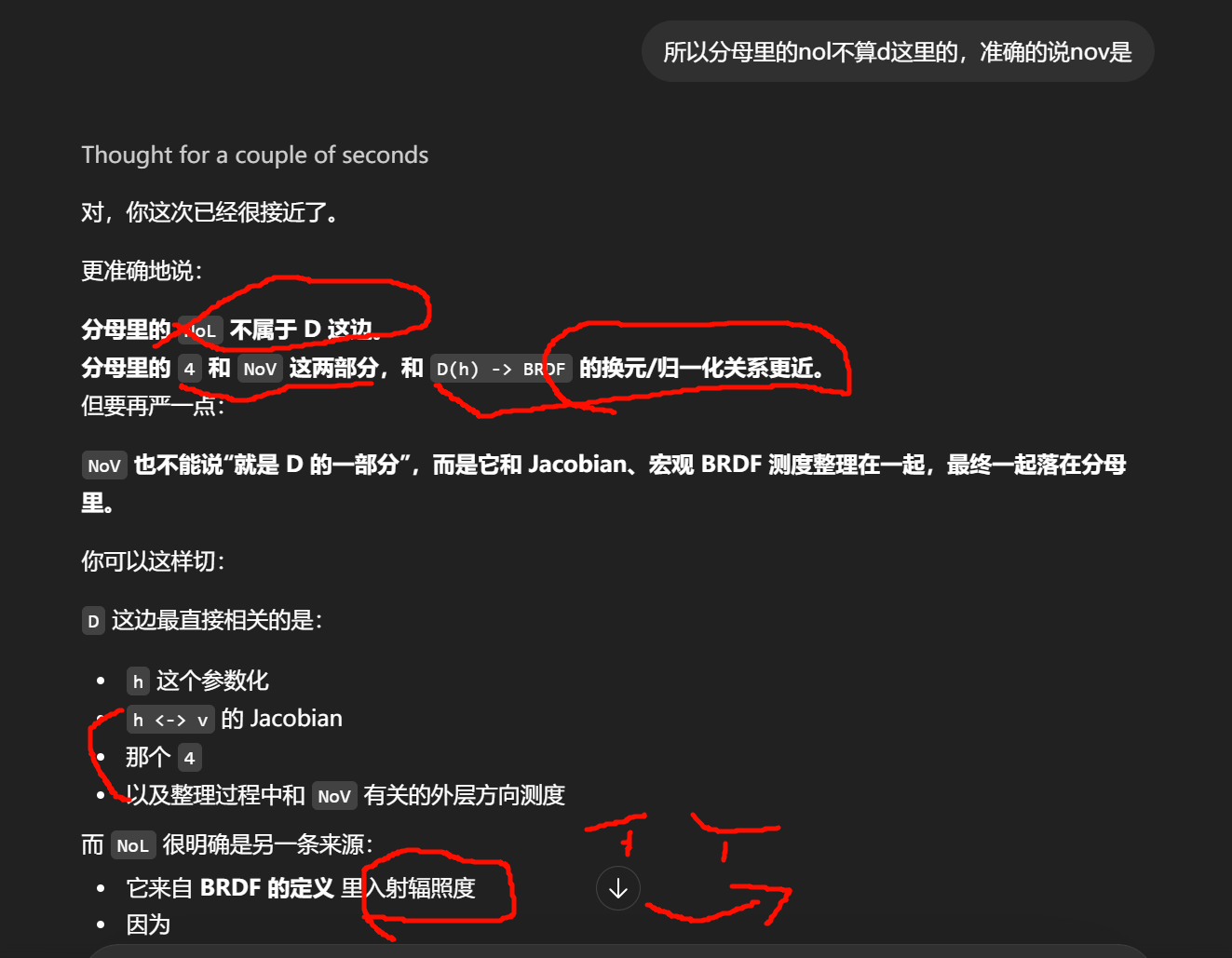
最后一次对dgf/4(nov)·(nol)发起冲锋
你可以这样分层:
D:有多少微表面朝着合适方向
F:这些微表面在该角度会反多少
G:这些微表面会不会被遮挡/阴影掉
这三项都在回答:
"微表面自己会发生什么?"
分母在回答:"这些发生在微表面的事,换算到宏观表面、单位入射辐照度、单位出射方向下,应当怎么算才物理一致?"
所以你的这句话:
这个分母是这些规则统一的共同影响属性?
我会改成更准确的版本:
它不是 D/F/G 的共同"效果项",而是把 D/F/G 放进 BRDF 定义后必须满足的共同"归一化/几何换算项"。
也就是说:
-
D/F/G 决定高光"长什么样、强多少、会不会被挡"
-
分母决定"这种结果以 BRDF 的形式表达时,量纲、角度关系、能量关系是不是对的"
Jacobian 可以先把它理解成:"变量换了以后,面积/体积/概率密度要怎么跟着改的换算系数。"
它不是图形学专属词,是数学里做"变量替换"时的标准工具。
最直白的例子:
你有一条线段,用变量 xxx 表示。
现在改用另一个变量 uuu:
x=2ux = 2ux=2u
那 uuu 增加一点点 dududu,对应的 xxx 不是增加同样多,而是:
dx=2 dudx = 2\,dudx=2du
这里这个 2,就是最简单的一维 Jacobian。
意思就是:
"你虽然只是换了个变量名,但这个变量空间里的'一点点长度',在另一个空间里其实不是一样大,所以积分、密度、概率都要乘这个比例。"
放到二维更容易看出它为什么重要。
假设你有平面坐标 (x,y)(x,y)(x,y),换成极坐标 (r,θ)(r,\theta)(r,θ):
x=rcosθ,y=rsinθx = r\cos\theta,\quad y = r\sin\thetax=rcosθ,y=rsinθ
这时候面积元不是:
dx dy=dr dθdx\,dy = dr\,d\thetadxdy=drdθ
而是:
dx dy=r dr dθdx\,dy = r\,dr\,d\thetadxdy=rdrdθ
这里多出来的那个 rrr,本质上就是 Jacobian。
为什么会多一个 rrr?
因为在极坐标里,θ\thetaθ 变化同样一点点,半径越大,扫出来的弧长越大,面积当然也越大。
所以变量换了,面积密度也必须跟着换。
所以 Jacobian 的核心用途就是:
当你把"某个量的分布"从一种参数表示,换到另一种参数表示时,保证积分结果不变。
比如:
-
概率密度换变量
-
面积元、体积元换坐标
-
方向分布换参数
-
图形学里从 hhh 空间换到 l,vl,vl,v 空间
都要用 Jacobian。
为什么会冒出那个 4?
因为你最开始描述的是:
"微表面法线朝向 hhh 的分布"
也就是 D(h)D(h)D(h)
但最后 BRDF 要写成:
"给定入射方向 lll 和观察方向 vvv,反射是多少"
这里就发生了变量替换:
从"用微表面朝向 hhh 描述"
换成
"用方向 l,vl,vl,v 描述"
一旦换变量,密度就不能直接照搬,必须乘上对应的 Jacobian。
那个推导最后整理出来,就会落到分母里的那一整套,包括你一直追的那个 4。
所以你现在可以把 Jacobian 暂时记成一句很工程的话:
"我换了描述变量后,为了让同一个物理量不变,必须补上的缩放系数。"
再给你一个特别适合图形学的直觉:
你原来在一个坐标系里看,1 平方厘米就是 1 平方厘米。
但换个扭曲过的坐标系后,屏幕上看着同样一个小格子,对应真实空间可能不是同样大。
Jacobian 就是在告诉你:
"这个小格子到底被拉伸了多少、压缩了多少。"
-
D(h) 本来是"微表面法线分布"
-
它的定义域是在 half-vector / 微表面法线方向 hhh 这个空间里
-
但最终 BRDF 要写成 l,v,nl, v, n 的函数
-
所以当你把 "按 hh 分布的密度" 转成 "按 l,vl,v表达的 BRDF" 时,要做变量变换
-
这个变换里冒出来的 Jacobian,最后会和分母一起形成那一项
-
所以你会感觉 4 很像是从 D 那边带出来的
这个直觉基本是对的。
BRDF想知道的,D里要表示的东西,不是同一个
D 不是在描述"方向 v 上有多少能量",D 描述的是"法线朝向 hh 的微面有多少"。
但 BRDF 想知道的是:
"已知 l,往 v 方向反多少?"
所以中间要翻译:
"法线空间里的一个小区域 dωhd\omega_h"
对应到
"观察方向空间里的一个小区域 dωvd\omega_v"
到底差多少?
这个"差多少",就是 Jacobian 在管的事。
现在最关键的几何关系是:
h=l+v∣l+v∣h = \frac{l+v}{|l+v|}
也就是说,hh 是 ll 和 vv的中间方向。
但注意,这不是普通的"平均一下"。因为 hh 还受镜面反射约束:
只有法线正好朝 hh 的微面,才会把 ll 反到 vv。
所以一个很小的 vv 变化,不会对应同样大小的 hh 变化。
vv 空间和 hh 空间的"格子大小"不一样。
所以你把"按 hhh 计的分布密度"换成"按 vvv 计的反射密度"时,必须补这个比例。
分母只和D有关系,那为什么不塞到D里?
D 本身有独立定义和归一化条件。
D 是 normal distribution function,本质上是在说:
"单位宏观表面面积上,微表面法线朝各个方向是怎么分布的。"
它不是"最终高光强度函数",而是一个法线方向分布密度 。
所以它自己要满足自己的归一化规则,比如那种:
∫ΩD(h) (n⋅h) dωh=1\int_{\Omega} D(h)\,(n\cdot h)\,d\omega_h = 1∫ΩD(h)(n⋅h)dωh=1
这个条件的意思是:
所有微表面的投影面积加起来,要对应回宏观表面的面积。
所以 D 是一个很"干净"的对象:
它只负责"微面法线统计"。
如果你把分母里那些和 BRDF 定义有关的换算全塞进 D,D 就不再是纯粹的 NDF 了。
它会从"法线分布函数"变成"某种掺了方向换元和投影项的混合物"。这样概念就脏了。
如果你把分母塞回 D,就会出现问题:
你写出来一个所谓的 "D'":
D′=D4(n⋅l)(n⋅v)D' = \frac{D}{4(n\cdot l)(n\cdot v)}
那这个 D' 就++已经不是 normal distribution function 了++ 。
因为它现在依赖的不只是 h h,还依赖 ll 和 vv。
原本的 D 是:
D(h)D(h)D(h)
只描述法线朝向分布。
但你塞完以后,D' 变成:
D′(h,l,v)D'(h,l,v)
那它就不再是"distribution of normals"了。
它其实已经偷偷把 BRDF 的方向依赖也吞进去了。
这在数学上当然能"写",但在概念上就不好了。
你当然可以把整个式子重新命名成一个大函数:
S(l,v,h)=D(h)F(l,h)G(l,v,h)4(n⋅l)(n⋅v)S(l,v,h)=\frac{D(h)F(l,h)G(l,v,h)}{4(n\cdot l)(n\cdot v)}S(l,v,h)=4(n⋅l)(n⋅v)D(h)F(l,h)G(l,v,h)
然后写成:
fr=Sf_r = Sfr=S
数学上完全没问题。
但这样你失去了拆分模型的意义。你再也看不出:
-
哪部分是分布
-
哪部分是 Fresnel
-
哪部分是 masking
-
哪部分是测度归一化
所以不是不能"塞",而是:
一旦塞进去,D 就不再叫 D 了。
这才是关键。
你这问题其实和物理里很多"为什么不并项"是一样的。
可以并,但并完以后会失去结构信息。
再给你一个很贴切的类比。
假设你有:
"速度 = 路程 / 时间"
你问:既然时间总在分母,为什么不把它塞进"路程"里,定义一个新路程?
当然可以。
你可以定义:
"有效路程 = 路程 / 时间"
那公式就变成:
"速度 = 有效路程"
数学上没毛病。
但"有效路程"已经不是原来的路程了,它把时间因素偷吃进去了,物理意义变脏了。
这里也是一样。
l和v是brdf的特权,
为什么 D 的归一化要写成 ∫D(h)(n⋅h)dωh=1 而不是单纯∫D(h)dωh=1
因为 D 不是"法线方向出现概率"那么简单,它更准确地说是:
单位宏观表面面积上,微表面朝向分布的面积密度。
这里真正要守恒的是 微表面的投影面积,不是"方向个数"。
如果只是普通概率分布,当然很自然会想:
"所有方向加起来总概率应该是 1,所以直接 ∫ D ( h ) d ω h = 1 \int D(h)d\omega_h=1 ∫D(h)dωh=1 不就好了?"
但微表面模型不是在数"有多少个法线方向标签",
而是在数:
"朝向 h h h 的微表面,投影回宏观表面后,占了多少面积份额。"
这就必须乘一个投影项:
n ⋅ h n\cdot h n⋅h
因为一个微表面虽然真实面积一样,但它斜着摆时,投影到宏观表面法线方向上的面积会变小。
这和 Lambert 那套 foreshortening 是同一个几何事实。
你可以把它想成很多小瓷砖贴在一个大平面上:
-
如果一块小瓷砖正对着宏观法线 n n n,它的投影面积最大
-
如果一块小瓷砖斜得很厉害,它虽然真实面积没变,但投影到大平面上的"覆盖份额"更小
而宏观表面模型关心的是:
这些微表面的投影面积加起来,能不能正好还原成那块宏观表面。
 、
、
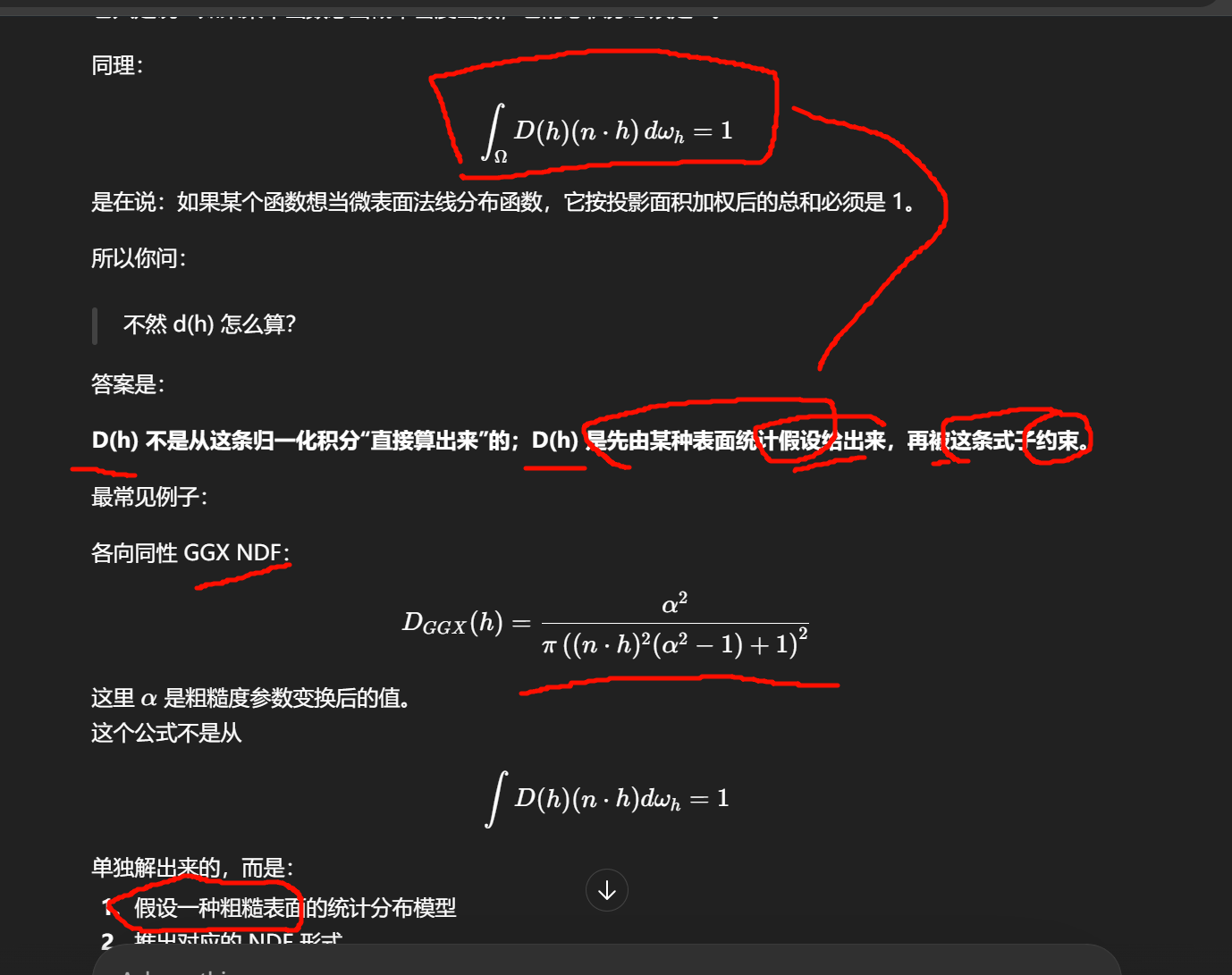
也就是说,这条积分更像"验收标准"。
-
D 的形状从哪里来?
从表面粗糙统计模型来,比如 Beckmann、GGX。
-
这个积分式干什么?
用来保证这个 D 是一个合法、归一化的 NDF。
所以统计模型可以换,但是jacobian的brdf部分都是完全相同的处理方式
这是你怎么假设表面的微观粗糙统计:
-
Beckmann
-
GGX / Trowbridge-Reitz
-
各向同性 / 各向异性
-
甚至别的 NDF
这些都在回答:
小面的法线到底怎么分布?