在上一篇笔记中,我们探讨了如何利用 RNN(循环神经网络)让机器人拥有"隐式记忆",从而在部分可观测的环境中更好地生存。然而,强化学习的上限往往受限于机器人自身能获取的信息。如果机器人的传感器天生就少,或者获取的信息噪声极大,单靠 RNN 自己去"悟",往往收敛极慢,甚至容易陷入局部最优。
为了打破这种物理上的信息壁垒,学术界和工业界引入了蒸馏学习(Distillation) 。在强化学习结合机器人控制的领域,它通常与 不对称 Actor-Critic (Asymmetric Actor-Critic) 和 特权信息学习 (Learning from Privileged Information) 概念绑定。
今天,我们将深入剖析 IsaacLab 中的 distillation_cfg.py 范式,从理论机制到代码配置,再到环境构造的诀窍,以及目前底层库的一个大坑。
一、 需求背景:为什么我们需要蒸馏?

想象一下,你在仿真环境(Isaac Sim)中训练机器人。在仿真器里,你是"上帝"。你可以轻易获取机器人脚底与地面的精确摩擦力系数、可以获取未来地形的高程图(Heightmap)、可以知道机器人质心的绝对线速度、甚至每个关节施加的精确外部干扰力。
如果把这些"上帝视角"的数据(特权信息,Privileged Information)全部喂给神经网络,机器人会学得飞快,步态异常稳健。但现实是残酷的:当这台机器人真正落地到物理世界时,它只有有限的传感器(比如 IMU 和关节编码器),它根本"看"不到摩擦力,也"看"不到高程图。
这就引出了一个矛盾:拥有特权信息的模型性能极高,但无法实机部署;只能依赖本体感知(Proprioception)的模型可以实机部署,但极难训练且性能孱弱。
蒸馏范式(Teacher-Student Paradigm) 就是为了解决这个矛盾而生的。它的核心思想是:先让一个拥有"上帝视角"的教师模型(Teacher)学成归来,然后再由这位全知全能的老师,手把手地教导一个只能看到本体传感器的学生模型(Student),最后让学生模型自己去实战微调。
二、 蒸馏范式的理论机制与底层拆解
在这个范式下,我们一般分为三步走,每一步的算法范式和优化目标都有着本质的区别。
第一步:教师模型训练 (Teacher Training)
- 范式:标准强化学习 (PPO)。
- 输入 :本体感知数据 + 大量特权信息(高程图、摩擦力、质量分布等)。
- 环境设置:极端复杂的环境、极大的域随机化(Domain Randomization, DR)。
- 理论:由于教师拥有上帝视角,面对极端复杂的环境也能轻易找到最优解。这一步的目标是榨干仿真器的潜力,得到一个在任何恶劣物理条件下都能稳健行走的"完美策略"。
第二步:蒸馏克隆 (Distillation)
- 范式:监督学习 (Supervised Learning, 行为克隆 Behavior Cloning)。
- 输入 :
- Teacher 网络:依然输入特权信息。
- Student 网络:只输入本体感知数据。
- 理论 :这是最核心的一步。此时强化学习的环境奖励(Reward)被完全抛弃,取而代之的是均方误差(MSE Loss)。仿真环境依然在运行,但只是为了生成轨迹数据 。
在每一个时间步,环境同时提供全量观测(给 Teacher)和受限观测(给 Student)。Teacher 根据全量观测输出一个完美的动作 AteacherA_{teacher}Ateacher;Student 根据受限观测输出一个猜测动作 AstudentA_{student}Astudent。
算法通过计算 MSE(Ateacher,Astudent)MSE(A_{teacher}, A_{student})MSE(Ateacher,Astudent) 并反向传播,强迫学生去模仿老师的行为。在这个过程中,学生模型实际上是在学习如何"通过本体感知去隐式推断那些它看不见的特权信息"。
第三步:学生模型微调 (Student Finetuning)
- 范式:标准强化学习 (PPO)。
- 输入:仅本体感知数据。
- 理论 :虽然学生在第二步中极力模仿老师,但监督学习(行为克隆)存在固有的"协变量偏移(Covariate Shift)"问题------一旦学生在实机中产生了一点点误差,就可能进入一个老师从未遇到过的状态,从而导致彻底崩溃。
因此,第三步我们需要让学生"断奶"。加载第二步蒸馏得到的网络权重作为初始基线,重新在环境中开启 PPO 强化学习。让学生在没有老师指导的情况下,通过与环境的真实交互和 Reward 试错,修正自己的动作,从而获得真正的鲁棒性。
三、 算法配置详解:手把手教你写 Cfg
为了直观展示这三个步骤的配置差异,这里我不使用继承,而是为你提供完全展开、独立完整 的三个 Runner 配置类。请注意仔细观察它们 policy 和 algorithm 的不同。
1. 教师模型配置 (Teacher Runner Cfg)
这是最基础的 PPO 训练,重点在于给足网络容量和训练时间。
python
from isaaclab.utils import configclass
from isaaclab_rl.rsl_rl import RslRlOnPolicyRunnerCfg, RslRlPpoActorCriticCfg, RslRlPpoAlgorithmCfg
@configclass
class Teacher_PPORunnerCfg(RslRlOnPolicyRunnerCfg):
num_steps_per_env = 24
max_iterations = 50000 # 教师模型需要见多识广,迭代次数要够多
save_interval = 500
experiment_name = "g1_rough_distillation" # 记住这个名字,后面要用
empirical_normalization = True
policy = RslRlPpoActorCriticCfg(
init_noise_std=1.0,
actor_obs_normalization=True,
critic_obs_normalization=True,
actor_hidden_dims=[512, 256, 128], # 教师网络的容量
critic_hidden_dims=[512, 256, 128],
activation="elu",
)
algorithm = RslRlPpoAlgorithmCfg(
value_loss_coef=1.0,
use_clipped_value_loss=True,
clip_param=0.2,
entropy_coef=0.01,
num_learning_epochs=5,
num_mini_batches=4,
learning_rate=5.0e-4,
schedule="adaptive",
gamma=0.99,
lam=0.95,
desired_kl=0.01,
max_grad_norm=1.0,
)2. 蒸馏模型配置 (Distillation Runner Cfg)
此时 Runner 和 Algorithm 变为了 Distillation 专用类,并且采用了上一章节介绍的RNN。这里的核心机制是监督学习。
python
from isaaclab_rl.rsl_rl import RslRlDistillationRunnerCfg, RslRlDistillationAlgorithmCfg, RslRlDistillationStudentTeacherRecurrentCfg
@configclass
class Distillation_RunnerCfg(RslRlDistillationRunnerCfg):
num_steps_per_env = 24
max_iterations = 20000
save_interval = 200
run_name = "distillation"
# 【核心注意】:这里的 experiment_name 必须指向教师模型所在的文件路径层级!
# RSL-RL 底层会根据这个路径去加载老师的权重 checkpoint。
experiment_name = "g1_rough_distillation"
empirical_normalization = True
# 使用蒸馏专用的 Policy 配置
policy = RslRlDistillationStudentTeacherRecurrentCfg(
# 学生网络的结构(我们这里让学生带有 RNN 记忆)
student_hidden_dims=[512, 256, 128],
rnn_type="lstm",
rnn_hidden_dim=256,
rnn_num_layers=2,
# 老师网络的结构(必须和上一步训练的一模一样)
teacher_hidden_dims=[512, 256, 128],
teacher_recurrent=False, # 强烈建议老师用纯 MLP,坑在文末解释
activation="elu",
init_noise_std=0.1, # 蒸馏时噪声通常设小一点
student_obs_normalization=True,
teacher_obs_normalization=True,
)
# 算法变成了监督学习算法
algorithm = RslRlDistillationAlgorithmCfg(
num_learning_epochs=5,
gradient_length=5, # BPTT的序列长度
learning_rate=1e-3,
loss_type="mse", # 均方误差,让学生的动作无限逼近老师
)3. 学生微调配置 (Student Finetune Runner Cfg)
蒸馏结束后,我们得到了一个有模有样的学生网络权重。接下来恢复到 PPO 训练,让它自己"磨炼"。
python
@configclass
class Student_Finetune_PPORunnerCfg(RslRlOnPolicyRunnerCfg):
num_steps_per_env = 24
max_iterations = 20000
save_interval = 200
run_name = "student_finetune"
# 同样,为了加载上一步蒸馏好的权重,需要指定到正确的路径
experiment_name = "g1_rough_distillation"
empirical_normalization = True
# 策略配置退化为普通的带有 RNN 的 PPO 策略,因为老师已经离开了
policy = RslRlPpoActorCriticRecurrentCfg(
init_noise_std=0.1, # 初始噪声不要太大,因为已经有一个好的基线了
actor_hidden_dims=[512, 256, 128],
critic_hidden_dims=[512, 256, 128],
actor_obs_normalization=True,
critic_obs_normalization=True,
activation="elu",
rnn_type="lstm",
rnn_hidden_dim=256,
rnn_num_layers=2,
)
algorithm = RslRlPpoAlgorithmCfg(
value_loss_coef=1.0,
use_clipped_value_loss=True,
clip_param=0.2,
entropy_coef=0.01,
num_learning_epochs=5,
num_mini_batches=4,
# 【微调关键】:学习率一定要调低!比如从 5e-4 降到 1e-4。
# 否则一开始极容易把蒸馏好的权重"洗掉"导致步态崩溃。
learning_rate=1.0e-4,
schedule="adaptive",
gamma=0.99,
lam=0.95,
desired_kl=0.01,
max_grad_norm=1.0,
)四、 环境构造的诀窍:特权与妥协
仅仅有算法配置是不够的,IsaacLab 中对于这三个步骤的环境 (EnvCfg) 设置有着极深的门道。
1. 教师环境 (TeacherEnvCfg)
- 观测 (Observations) :火力全开。在
TeacherObservationsCfg中,我们不仅放入基本的本体感受,还要把雷达扫描 (height_scan)、甚至精确的脚底接触力 (feet_contact_forces) 全都塞进去。 - 环境随机化 (Domain Randomization) :无限放大。让摩擦力从冰面到柏油路随机,给机器人施加巨大的推力,极大地扰动质量分布。因为老师能"看见"这些干扰,所以再大的随机化它都能学会应对策略。
2. 蒸馏环境 (DistillationEnvCfg)
- 观测 (Observations) :在这个环境里,我们必须同时提供两套观测字典:
policy: 也就是学生能看到的观测。teacher: 之前老师看到的特权观测(必须和第一步一模一样!否则加载权重会报错)。
- 环境随机化:保持和教师一致的高强度。我们要在这个极端环境中采集数据。
3. 学生微调环境 (StudentEnvCfg)
- 观测 :恢复到只有
policy(本体观测)和critic(价值评估观测)。把teacher组彻底删掉。 - 环境随机化 :适当减弱 。学生毕竟没有全知视角,如果微调时的域随机化还像老师那么变态,它很可能会被逼疯导致策略退化。适当降低随机范围,让它平稳落地。

五、 避坑警告:底层库的 RNN 教师 Bug
在上面的蒸馏配置中,你可能会好奇:为什么学生用了 RNN,而老师却设置了 teacher_recurrent=False?难道老师不能也是 RNN 吗?
理论上是可以的,但在 RSL-RL 目前的底层源码中(尤其是处理 student_teacher_recurrent.py 时),存在一个极其致命的 Bug。
如果你设置 teacher_recurrent=True,底层的初始化逻辑会出错。具体来说,代码会首先使用教师观测维度(比如 316 维)实例化一个 RNN Memory,然后它会把 num_teacher_obs 这个变量强行覆盖为 RNN 的输出维度(比如 256 维) 。
然而,紧接着在初始化教师的观测归一化层 EmpiricalNormalization 时,它直接拿了被覆盖后的 256 维去初始化。
这导致的结果是:当你加载教师模型 Checkpoint 时,由于 Checkpoint 里的归一化层是正确的 316 维,而当前构建的网络归一化层是错误的 256 维,控制台会直接抛出 RuntimeError: size mismatch for _mean 等崩溃信息。
解决方案 :
在官方修复此 Bug 之前,最稳妥的方案是:教师模型一律使用标准的纯 MLP 结构(加入多帧历史观测来弥补时序),而学生模型使用 RNN 结构。
如果你非要老师也用 RNN,就必须手动深入 conda 环境下的 RSL-RL 库,修改 student_teacher_recurrent.py,用一个临时变量保存原始维度去初始化 Normalizer。
六、 部署指南:洗尽铅华呈素姿
当你辛辛苦苦跑完了长达数天的"三步走"训练,终于拿到了绿色的 policy.onnx。当你把它交给下游的 C++ 部署工程师时,他们需要特别编写什么复杂的逻辑吗?
完全不需要!
从推理的视角来看,经过微调后的最终学生模型,就是一个普普通通的策略网络。它的输入依然只有纯净的 obs,如果加入了RNN,则依旧以加入维持循环状态所需的 h_in 和 c_in。它的输出依然是干脆利落的 actions(外加 h_out, c_out)。
蒸馏过程中的那些"特权信息"、高程图扫描、教师网络的权重残骸,在导出 ONNX 的那一刻已经被彻底剥离、灰飞烟灭了。C++ 工程师只需要按照我们在上一篇《RNN 策略篇》中提供的伪代码正常推理即可。这就是蒸馏范式的优雅之处:过程极其繁复,结果却无比清爽。
七、 测试数据与效果总结
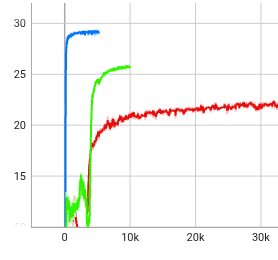
图注:红色曲线为教师模型(Teacher)训练过程;蓝色曲线为蒸馏模型(Distillation)MSE Loss 过程;绿色曲线为学生模型(Student Finetune)的微调奖励回升过程。
现阶段效果总结:
实事求是地说,就我们目前的测试样本和有限的算力而言,这套冗长繁杂的三步走蒸馏范式,并没有展现出比"精调直接训练的 RNN"具有决定性的、压倒性的优势。
蒸馏链条过长带来了成倍的时间成本,超参数调节(尤其是蒸馏和微调的无缝衔接)也更加玄学。目前来看,除非面对的是极为受限的感知环境或极具挑战性的高动态任务(如纯盲眼过梅花桩),否则对于常规步态任务,我们暂时对其投入产出比持保留意见。
未来,随着训练样本的增加和对特权信息边界的更深入探索,我们或许能找到让蒸馏真正大放异彩的奇点。