从零开始理解 ResNet(上):为什么 CNN 需要"残差连接"?

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 ✨ 数据即知识,压缩即智能
书接上回:
上一篇我们讲了 CNN。CNN 的核心思想是通过 卷积核局部扫描、参数共享、层次化特征提取 来理解图像。
但当我们继续往下学时,一个新问题马上出现: 既然 CNN 越深越能提取复杂特征,那是不是把网络一直加深就可以了?
ResNet 的故事,正是从这个问题开始的。
目录
- [从零开始理解 ResNet(上):为什么 CNN 需要"残差连接"?](#从零开始理解 ResNet(上):为什么 CNN 需要“残差连接”?)
-
- [一、从 CNN 到 ResNet:网络越深真的越好吗?](#一、从 CNN 到 ResNet:网络越深真的越好吗?)
- 二、深层网络的现实问题:不是越深越好训
- 三、什么是退化问题?
- [四、ResNet 的核心思路:不要直接学完整答案,而是学"修正量"](#四、ResNet 的核心思路:不要直接学完整答案,而是学“修正量”)
- 五、什么叫"残差"?
- 六、用作文修改理解残差学习
- [七、shortcut connection:给信息开一条"近路"](#七、shortcut connection:给信息开一条“近路”)
- [八、shortcut connection 为什么有用?](#八、shortcut connection 为什么有用?)
- [九、从"爬楼梯"理解 ResNet](#九、从“爬楼梯”理解 ResNet)
- [十、为什么 ResNet 不是简单"作弊"?](#十、为什么 ResNet 不是简单“作弊”?)
- [十一、ResNet 到底解决了什么?](#十一、ResNet 到底解决了什么?)
- 十二、上篇总结
一、从 CNN 到 ResNet:网络越深真的越好吗?
在 CNN 中,不同层通常会学习不同层次的视觉特征。
浅层更关注:
text
边缘
颜色变化
亮暗对比
简单纹理中间层进一步组合这些低级特征:
text
角点
局部形状
叶脉纹理
病斑边缘更深层则可能学到更抽象的语义信息:
text
叶片区域
病害区域
目标部件
类别相关特征所以,一个很自然的想法是:
如果网络越深,能学到越复杂的特征,那是不是只要不断加深 CNN 就可以提升效果?
这个想法有道理,但实际训练中并不总是成立。
二、深层网络的现实问题:不是越深越好训
理论上,更深的网络表达能力更强。
但是实际训练时,研究者发现:如果只是简单地把普通卷积层一层层堆上去,网络加深以后,效果不一定变好,甚至可能变差。
更关键的是,这种变差并不只是过拟合。
过拟合通常表现为:
训练集效果很好
测试集效果不好
但深层普通网络有时会出现另一种现象:
训练集误差也变高
测试集误差也变高
这说明模型不是"记得太多",而是连训练集都没有很好地学会。
这个问题被称为:
退化问题,Degradation Problem
三、什么是退化问题?
退化问题可以这样理解:
网络加深后,按理说能力应该更强;
但实际训练时,更深的普通网络训练误差反而更高。
这件事很反直觉。
假设一个 20 层网络已经能做得不错,那么一个 56 层网络理论上至少可以这样做:
text
前 20 层照常工作;
后面 36 层什么都不改变,只负责把信息原样传下去。也就是说,更深的网络至少应该能模拟浅层网络。
但是在普通深层 CNN 中,让后面几十层自动学会"什么都不做",并不是一件容易的事。
这就是 ResNet 要解决的关键问题:
普通深层网络很难自动学会恒等映射。这句话目前听起来好像很难理解,没事我们换个说法
也就是说,它很难学会:"如果这一层暂时没必要改变特征,那就让信息原样通过。"
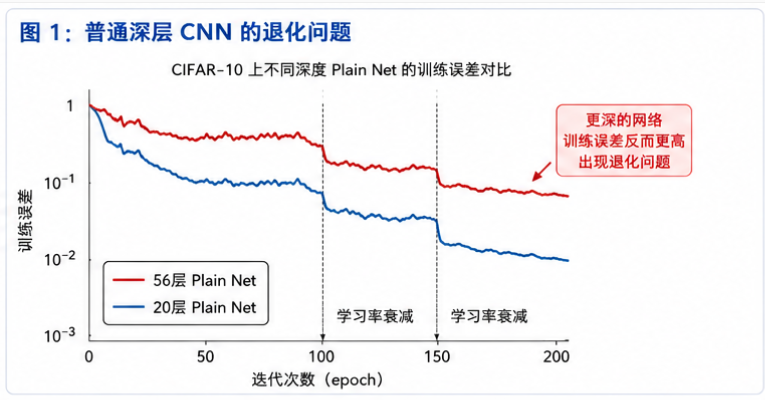
图 1:普通 CNN 简单堆深后,训练误差可能不降反升,这就是退化问题。
配图画法:
画两条训练误差曲线:浅层 Plain Net 曲线逐渐下降;更深 Plain Net 曲线反而更高。下方标注:"更深不等于更好训"。
四、ResNet 的核心思路:不要直接学完整答案,而是学"修正量"
普通 CNN 中,若干层网络要直接学习一个目标映射:
text
H(x)意思是:
text
输入 x
经过几层网络
直接得到目标输出 H(x)ResNet 换了一个角度。
它不要求网络直接学习完整的 H(x),而是让网络学习:
text
F(x) = H(x) - x最后再把输入 x 加回来:
H(x) = F(x) + x
这里:
text
x:原来的输入
F(x):残差,也就是需要修改的部分
F(x) + x:最终输出所以 ResNet 的核心不是"多加几层",而是改变了网络要学习的目标。
五、什么叫"残差"?
"残差"这个词听起来比较数学,其实可以理解成:
残差 = 原始输入距离目标输出还差多少。
如果目标输出是 H(x),原始输入是 x,那么残差就是:
text
F(x) = H(x) - x这就像写作文的时你已经写了一个初稿,而当你修改的时候不会让你从头再写一遍,而是告诉你:
text
这里改一点;
那里补一点;
这个地方删一点;
整体结构保留。这时你要学的不是"从零写完整答案",而是"如何修改已有答案"。
六、用作文修改理解残差学习
直接学习 H(x),像是:
text
把原文全部删掉,从头重写一篇文章。学习 F(x),像是:
text
保留原文,只修改需要改的地方。显然,第二种更容易。
ResNet 的直觉也是这样:
普通 CNN:每个模块都试图重新生成新特征。
ResNet:每个残差块只需要学习"在原有特征上应该改什么"。也就是把之前学到的特征直接拼接到下一层
这就是残差学习更容易优化的一个重要原因。
七、shortcut connection:给信息开一条"近路"
ResNet 中最醒目的结构就是:
text
shortcut connection也叫:
text
skip connection中文可以理解为:
抄近道连接
它的作用是让输入 x 不必完全经过中间卷积层,而是可以直接绕过去,参与最后的相加。
残差块可以简化为:
text
输入 x
│
├──────────────┐
↓ │
若干卷积层得到 F(x) │
↓ │
└──── F(x) + x ←┘最终输出是:
text
y = F(x) + x这条 shortcut 看起来只是多了一条线,但它改变了深层网络的信息流动方式。
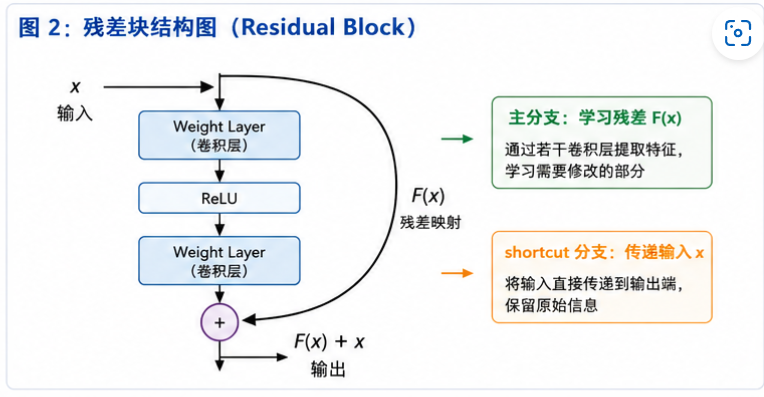
图 2:残差块通过 shortcut connection 把输入直接加到输出上,让网络学习 F(x) 而不是直接学习 H(x)。
八、shortcut connection 为什么有用?
shortcut connection 至少有三个重要作用。
| 作用 | 直观理解 |
|---|---|
| 更容易学习恒等映射 | 如果某个残差块暂时没必要改变特征,只要让 F(x) 接近 0,输出就接近 x |
| 保留原始信息 | 输入信息不会被后续卷积层完全覆盖,而是可以直接参与输出 |
| 改善梯度传递 | 反向传播时,梯度有了一条更直接的回传路径 |
用一句话概括:
shortcut 让深层网络不再必须一层层重新总结信息,而是有了更顺畅的信息通道。
九、从"爬楼梯"理解 ResNet
普通深层 CNN 像是从一楼爬到很高的楼层。
每一层都必须一级一级走:
text
1 楼 → 2 楼 → 3 楼 → 4 楼 → ...如果中间某一层走偏了,后面的层都会受到影响。
ResNet 像是在楼梯不同楼层之间的电梯,让你可以直接到达目标楼层。
这些通道不能直接让你飞到终点,但可以让信息更顺畅地跨层流动。
也就是说:
普通 CNN 是"层层传递";ResNet 是"层层传递 + 适当抄近道"。
这使得网络变深以后,信息不至于在漫长的层间传递中逐渐丢失。
十、为什么 ResNet 不是简单"作弊"?
有同学可能会想:
text
既然输入可以直接绕过去,那网络是不是没有认真学习?不是。
shortcut 不是让网络跳过学习,而是让网络可以选择:
text
需要修改的地方,交给 F(x) 学;
不需要修改的地方,允许 x 直接保留。这更像是一种灵活机制。
如果当前特征已经不错,残差块可以少改。
如果当前特征还不够好,残差块就可以学习更多修正量。
所以 ResNet 不是偷懒,而是把学习目标从:
text
重新构造全部特征变成了:
text
在已有特征上做有效修正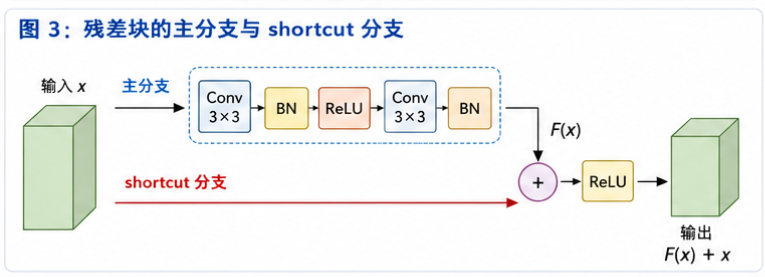
十一、ResNet 到底解决了什么?
现在我们可以回答一个核心问题:
ResNet 到底解决了什么?
它主要解决的是:
text
深层 CNN 难以优化的问题更具体地说:
第一, 普通深层网络加深后可能出现退化问题。
第二, ResNet 让网络学习残差 F(x),而不是直接学习完整映射 H(x)。
第三, shortcut connection 让输入 x 可以直接参与输出。
第四, 当某些层暂时不需要改变特征时,只需要让 F(x) 接近 0,输出就接近 x。
**第五,**残差连接让信息流和梯度流更加顺畅。
十二、上篇总结
这一篇讲清了 ResNet 出现的原因。
普通 CNN 简单堆深以后,可能出现退化问题。
ResNet 的解决思路是:
text
不直接学习 H(x)
而是学习 F(x) = H(x) - x
最后输出 F(x) + x这就像:
text
不要每次从头重写答案;
而是在已有答案上不断修正。