文章目录
- 背景
- Zerotier
-
-
- [`Unit` 区块:说明与依赖关系](#
[Unit]区块:说明与依赖关系) - [`Service` 区块:运行配置(核心)](#
[Service]区块:运行配置(核心)) - [`Install` 区块:安装行为](#
[Install]区块:安装行为)
- [`Unit` 区块:说明与依赖关系](#
-
- Tailscale
-
-
- [为什么 Linux 机器显示 `-`?](#为什么 Linux 机器显示
-?) - [为什么 Windows 机器显示 `active` 或 `offline`?](#为什么 Windows 机器显示
active或offline?) - 结论与回归到监控脚本本身
- [1. `Unit` 区块:定义模块的生命周期与依赖关系](#1.
[Unit]区块:定义模块的生命周期与依赖关系) - [2. `Service` 区块:定义进程的执行形态](#2.
[Service]区块:定义进程的执行形态) - [3. `Install` 区块:定义安装系统开机自动启动项的行为](#3.
[Install]区块:定义安装系统开机自动启动项的行为)
- [为什么 Linux 机器显示 `-`?](#为什么 Linux 机器显示
-
- 执行监控脚本并实时监督
背景
markdown
我目前需要在一个内网服务器上使用内网穿透,这样我就可以使用1个固定的ipv4,
然后在任何地方使用我自己的本地机器,比如说在vscode中,使用remotessh登入到内网服务器中,
然后借助算力。但是现在我遇到了一个问题,就是这些内网穿透的服务其实不是很稳定,
因为我没有付费去买国内的云主机,然后中转,我借助的这些是国外的,可能服务器在国外等原因,
导致有些时候服务器会断掉中断,就是我需要在client和server上都登入tailscale或zerotier然后,
有时候server端这些软件就会offline,结果我人在外面,然后内部机器无法访问、不好直接线下重启维护之类。 一个非常典型的需求,内网穿透工具因为网络波动或者长时间休眠,有可能会在服务端"掉线"。要实现后台长期稳定运行,经历关机重启等情况依然生效,最佳也是最鲁棒的方案是把监控脚本包装为 systemd 守护进程服务(Daemon Service)。相比 cron 定时任务,它能够实时监控状态并在服务Crash时自动拉起。
详情参考仓库:https://github.com/MaybeBio/Zerotier_Tailscale_Moniter
Zerotier
直接给出脚本,bash执行为主(也可以改成zsh)
shell
#!/bin/bash
# 配置部分
NETWORK_ID="填入我们的16位网络ID" # 填入我们的 ZeroTier Network ID
LOG_FILE="/var/log/zt-monitor.log" # 推荐放在系统级日志目录 /var/log 中
log_msg() {
echo "$(date '+%Y-%m-%d %H:%M:%S') - $1" >> "$LOG_FILE"
}
check_status() {
# 检查基础服务是否在线, online
local info_status=$(zerotier-cli info | awk '{print $5}')
# 检查是否加入了特定网络, ok
local list_status=$(zerotier-cli listnetworks | grep "$NETWORK_ID" | awk '{print $6}')
if [ "$info_status" = "ONLINE" ] && [ "$list_status" = "OK" ]; then
return 0 # 正常
else
return 1 # 异常
fi
}
log_msg "[INFO] ZeroTier Monitor 已启动..."
# 死循环,利用 sleep 实现周期性
while true; do
# 逻辑判断:如果连续两次检测都失败(间隔20秒),才执行重启
if ! check_status; then
sleep 20
if ! check_status; then
log_msg "[WARN] ZeroTier 状态异常,正在尝试重启服务..."
# 使用 root 执行,去掉 sudo 避免密码弹窗
systemctl restart zerotier-one
# 等待几秒钟让服务跑起来
sleep 30
zerotier-cli join "$NETWORK_ID"
log_msg "[INFO] ZeroTier 重启与 Join 指令已下发。"
fi
fi
# 每次检查间隔为 3 分钟 (180秒),可根据需调整
sleep 180
done下面这个圈出来的是我们的network id
需要先检查一下基础服务是否在线,也就是online与否
shell
zerotier-cli info
# zerotier-cli info | awk '{print $5}'
再检查一下是否加入特定的网络network,也就是ok与否,这个是重点,网络id就是前面提到的
shell
zerotier-cli listnetworks
# zerotier-cli listnetworks | grep "$NETWORK_ID" | awk '{print $6}'
只有online且加入了这个network id,才算是状态正常。
如果状态是正常的,我们就不用管理,如果不正常,我们就需要重新启动服务,
然后在启动服务之后我们再重新加入network id。
当然检测的时候我们需要检测2次, 通过双重验证避免误重启。
当然,有了这个直接shell脚本是不够的,毕竟脚本需要执行,我们可以一次性临时的手动执行,也可以变成系统级的后台进程任务一直运行。
所以我们需要再配套写1个.service文件,即linux系统中systemd(系统和服务管理器)的配置文件。
shell
[Unit]
Description=ZeroTier Connectivity Monitor Service
After=network-online.target zerotier-one.service
Wants=network-online.target
[Service]
Type=simple
ExecStart=/usr/bin/bash /data2/Zerotier_Tailscale_Moniter/Zerotier_Moniter/zt-monitor.sh
# 服务意外挂掉后自动重启
Restart=always
RestartSec=10
# 必须作为 root 用户运行,因为服务中有 systemctl restart 提权操作
User=root
Group=root
[Install]
WantedBy=multi-user.target这个 .service 文件是 Linux 系统中 systemd(系统和服务管理器)的配置文件。
要理解它的作用,我们可以把运行环境想象成一家公司:
- shell 脚本 (zt-monitor.sh) 是一名"巡检保安",他知道具体的巡检逻辑(怎么查状态、发现不对怎么重启系统)。但是,如果保安自己中暑晕倒了,或者公司大楼停电重启后他没来上班,那巡检机制就废了。
.service** 文件** 就是一张给"HR部门(systemd)"的雇佣合同和岗位说明书。它告诉系统:什么时候派这个保安上岗(开网后)、给他什么权限(Root 董事长权限)、如果他晕倒了怎么办(立即抢救让他继续干),以及公司重启后是不是马上叫他来上班(开机自启)。
简而言之,配合使用这个 .service 文件,我们的 Shell 脚本就从一个"手动执行的临时任务"变成了一个"系统级的后台守护进程(Daemon)"。
[Unit] 区块:说明与依赖关系
这里定义了服务的基础信息以及它的启动时机。
Description=ZeroTier Connectivity Monitor Service- 作用: 服务的简短描述。当我们使用
systemctl status zt-monitor.service查看状态时,终端里显示的就是这段人类可读的名字。
- 作用: 服务的简短描述。当我们使用
After=network-online.target zerotier-one.service- 作用: 设定启动顺序。它告诉系统,必须等系统的"网络完全连通 (
network-online.target)"并且"原生的 ZeroTier 核心服务 (zerotier-one.service)"启动之后,再启动咱们的监控脚本。 - 意义: 避免开机时网络还没初始化好,我们的脚本就急匆匆跑去检查网络,结果误判导致无限报错。
- 作用: 设定启动顺序。它告诉系统,必须等系统的"网络完全连通 (
Wants=network-online.target- 作用: 声明一种"弱依赖"关系。意思是我这个监控服务"希望"系统网络是在线状态。这通常与
After配合使用,确保网络组件准备就绪。
- 作用: 声明一种"弱依赖"关系。意思是我这个监控服务"希望"系统网络是在线状态。这通常与
[Service] 区块:运行配置(核心)
这里定义了脚本具体的执行方式、生命周期和权限。
Type=simple- 作用: 定义服务类型为
simple。这意味着 systemd 只要成功执行了ExecStart指定的命令,就认为该服务已经成功启动了。 - 意义: 非常适合配合我们在 Shell 脚本里写的
while true死循环。因为脚本跑起来后不会主动退出,会一直占用主进程,systemd 就会一直盯着它。
- 作用: 定义服务类型为
ExecStart=/bin/bash /data2/Zerotier_Tailscale_Moniter/Zerotier_Moniter/zt-monitor.sh- 作用: 这是服务启动时真正执行的核心命令。
- 意义: 注意,在 systemd 中通常必须使用绝对路径。这里明确指定用 bash 解释器去执行我们存放在硬盘里的那个 Shell 脚本。
Restart=always- 作用: 崩溃恢复机制(不死鸟属性)。
- 意义: 如果我们的监控脚本因为内存不足被系统杀了,或者因为代码 Bug 意外退出了,systemd 只要发现它不在了,就会无条件地自动将它重新拉起。保证了极高的鲁棒性。
RestartSec=10- 作用: 重启间隔时间。
- 意义: 如果脚本刚拉起来就报错退出,为了防止它一秒钟内重启几千次导致 CPU 被占满,这里规定每次挂掉后,系统等待 10 秒钟再尝试重新执行它。
User=root和Group=root- 作用: 权限指定。明确要求以
root(系统最高管理员)的身份和用户组来运行这个脚本。 - 意义: 这就解释了为什么后台运行不会报
authtoken.secret权限不足的错误。因为脚本在检测异常时包含了systemctl restart zerotier-one这个关停和启动系统级服务的命令,普通用户执行这个命令会弹出交互式弹窗要求输密码(在后台就直接卡死了),使用root运行一切都畅通无阻。
- 作用: 权限指定。明确要求以
[Install] 区块:安装行为
这个区块只有在我们执行 sudo systemctl enable zt-monitor.service(设置开机自启)时才会被读取。
WantedBy=multi-user.target- 作用: 定义在系统的哪个运行级别下激活它。
- 意义:
multi-user.target是 Linux 系统正常的非图形界面多用户运行模式(我们平时 SSH 连上去的状态)。这行配置的意思是:当系统正常开机并进入多用户状态时,把咱们这个监控服务"挂接"进去,跟着系统一起自动运行,从而实现开机自启动。
Tailscale
参考:https://tailscale.com/download/linux
首先我们同样先查看一下设备的基础服务情况,
shell
tailscale status可以看到列出了所有的节点

因为我们只需要查看本机,在服务器端就是检查服务器本身的链接情况是否在线等。
这个时候,我们一般的小白策略就是,直接用grep,看看有没有ipv4,以及后面这个active或offline?
但是问题来了,为什么我们的windows是offline或active,但是linux服务器是-?
为什么 Linux 机器显示 -?
在 Tailscale 的架构中,tailscale status 命令输出的并非是所有机器当前的绝对在线状态,而是"以当前机器为视角,它与其他机器的连接状态"以及"当前机器自身的状态"。
qwlabbioinfo** 是我们当前正在执行命令的本机 (Self)**- 我们在
qwlabbioinfo上查询状态,对于自己,Tailscale 不会去计算"我和我自己是否建立了打洞连接(active)",因为这毫无意义。 - 因此,对于"本机 (Self)",它的最后一列状态永远显示为
-(表示 N/A 或不适用)。
- 我们在
pcdh** 是一台目前和我们没有数据通信的被动机器 (Idle Peer)**- Tailscale 采用的是按需建立连接 (On-demand P2P) 的机制。
- 即使
pcdh这台 Linux 机器在线且网络畅通,只要我们的qwlabbioinfo现在没有尝试ping它、没在连接它的 SSH,也没有任何数据包交互,Tailscale 认为"我们俩现在不需要建立直连通道"。 - 对于这种在线但处于休眠/未连接 状态的对等节点 (Peer),它不会显示
active,而是显示-(有些版本会显示 idle,当前的 CLI 版本简化成了-)。
为什么 Windows 机器显示 active 或 offline?
gpd-win-max2** 显示 **active; direct ...- 这表示我们的服务器 (
qwlabbioinfo) 正在和这台 Windows 机器进行数据通信。 - 当然现实就是:我当前就是用这台名为
gpd-win-max2的 Windows 电脑上的 VS Code / SSH,通过 Tailscale 的 IP (100.x.x.x) 远程连接在qwlabbioinfo上下达指令! - 因为有持续的 SSH 数据流,Tailscale 建立了真实的 P2P 直连通道(direct),并开始统计收发数据包(tx/rx),所以它显示为
active。
- 这表示我们的服务器 (
gpdwinmini** 和tx6-pro显示 **offline- 这意味着 Tailscale 的中央控制服务器(Coordination Server / DERP server)明确报告这两台机器已经断开了与控制平面的连接(比如它们关机了,或者 Tailscale 客户端被关掉了,当然我这里就是单纯的这两台机器没有打开tailscale windows客户端)。
结论与回归到监控脚本本身
因为这种"按需连接"的特性,我们不能 指望通过检查列表里有没有 active 来判断服务器自己是不是正常在线。
- 如果服务器深夜挂机,没有任何外部机器去连它,哪怕它的网络全通、Tailscale 运行完美,它看自己是
-,看别人也全是-或者offline。 - 只有当别人去连它时,由于对端发起请求,隧道被打通,才会临时冒出一个
active。
所以我们的检测逻辑是检查ipv4,就是确保本机拿到了专属ip,
shell
tailscale ip -4可以参考官网:
https://tailscale.com/download/linux
另外真正需要解析自身本机的运行状态,需要
shell
tailscale status --json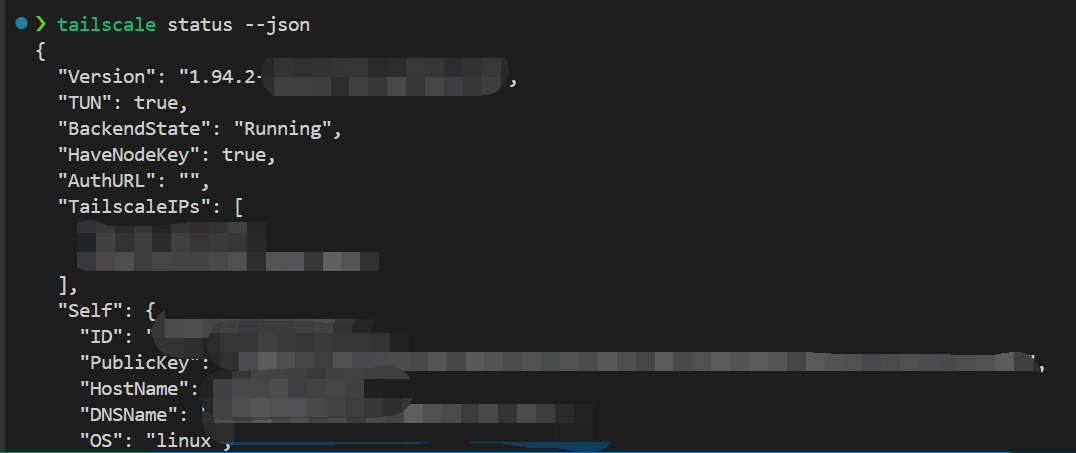
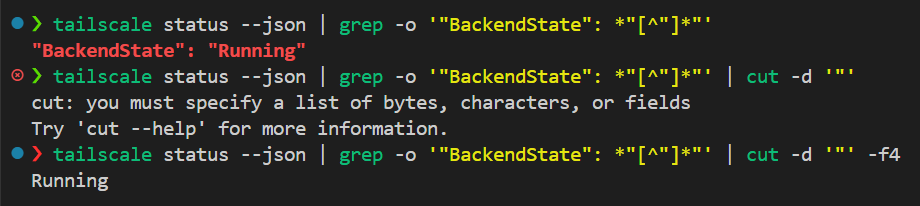
我们需要查看这个后端状态

如果running就不需要修改,如果不是那么就重启,然后在
shell
tailscale up简单来说,我们现在的整体监控脚本就是:
shell
#!/bin/bash
# ==========================================
# Tailscale 连接状态守护脚本
# 说明: 此服务器已在后台禁用了Key Expiry(密钥过期)
# ==========================================
LOG_FILE="/var/log/ts-monitor.log"
log_msg() {
echo "$(date '+%Y-%m-%d %H:%M:%S') - $1" >> "$LOG_FILE"
}
check_ts_status() {
# 如果 tailscale 服务完全挂了或者掉线,ip 命令会返回错空或报错
local ts_ip=$(tailscale ip -4 2>/dev/null)
# 检查是否成功获取到了100开头的 Tailscale IP
if ! echo "$ts_ip" | grep -qE "^100\.[0-9]+\.[0-9]+\.[0-9]+$"; then
return 1 # 没获取到合法IP,认为已断线
fi
# 获取真正的自身状态 (通过 tailscale status --json 解析)
# BackendState 正常时应为 "Running"
local backend_state=$(tailscale status --json 2>/dev/null | grep -o '"BackendState": *"[^"]*"' | cut -d'"' -f4)
if [ "$backend_state" != "Running" ]; then
return 1 # 状态不是 Running,可能是 Stopped(下线) 或 NeedsLogin 或其它异常
fi
return 0
}
log_msg "[INFO] Tailscale Monitor 已启动..."
while true; do
if ! check_ts_status; then
sleep 10
# 连续两次检测失败,确认状态异常,执行抢救逻辑
if ! check_ts_status; then
log_msg "[WARN] Tailscale 状态异常,正在尝试重启并重新连接..."
# 1. 强行重启底层守护进程
systemctl restart tailscaled
sleep 20
# 2. 尝试重新连接
# 不使用 Auth Key,直接拉起保存的本地配置。
# --timeout=30s 是极重要的核心保护机制:防止脚本永久死锁
tailscale up --timeout=30s
log_msg "[INFO] Tailscale 已完成重启流程。"
fi
fi
# 周期性扫描间隔,默认 3 分钟
sleep 180
done然后同样,我们在配套shell脚本的同时需要一个service,
shell
[Unit]
Description=ZeroTier Connectivity Monitor Service
After=network-online.target zerotier-one.service
Wants=network-online.target
[Service]
Type=simple
ExecStart=/usr/bin/bash /data2/Zerotier_Tailscale_Moniter/Zerotier_Moniter/zt-monitor.sh
# 服务意外挂掉后自动重启
Restart=always
RestartSec=10
# 必须作为 root 用户运行,因为服务中有 systemctl restart 提权操作
User=root
Group=root
[Install]
WantedBy=multi-user.target1. [Unit] 区块:定义模块的生命周期与依赖关系
properties
[Unit]
# 服务的简短描述,主要用于 systemctl status 时的提示信息
Description=Tailscale Connectivity Monitor Service- 解释 :就像是在任务管理器的名字。当我们使用
systemctl status ts-monitor.service时,终端上展示出来的文本介绍就是这里的文字。
properties
# 启动顺序控制:确保在系统网络联通 (network-online) 以及 tailscaled 服务启动之后,再启动本监控
After=network-online.target tailscaled.service- 解释 :由于我们的脚本依赖于 Tailscale 进程本身以及可用的互联网。如果这俩没启动我们就去检测,只会满篇报错。所以要求 systemd 必须等待 网络及
tailscaled.service启动后,再启动此监控。
properties
# 声明软依赖网络服务。配合 After 使用,确保启动时网络已初步准备就绪
Wants=network-online.target- 解释 :
Wants是一个相对"宽松"的依赖关系。我们表达了自己想要系统网络服务,但就算网络模块坏了,系统还是会尝试启动我们(这点有别于Requires=的强绑定强自杀机制),非常适合我们这种"为了修复网络问题而生"的监控脚本。
2. [Service] 区块:定义进程的执行形态
properties
[Service]
# simple 模式表示 ExecStart 启动的进程就是该服务的主进程。
Type=simple- 解释 :systemd 里面有很多模式。比如有的程序启动后主进程会自己退出、留下子进程在后台(
forking)。而我们的 bash 脚本自己内部有个死循环(while true),它会一直霸占当前命令行。这时候Type=simple是最匹配的,告诉 systemd:"我直接启动这个脚本就好,它不死,服务就一直处于 active 运行状态"。
properties
# 核心启动命令:使用 bash 解释器绝对路径,执行我们的监控脚本。
ExecStart=/bin/bash /data2/Zerotier_Tailscale_Moniter/Tailscale_Moniter/ts-monitor.sh- 解释 :这个就是灵魂所在。systemd 里面写路径极其严格,不能用相对路径,也不能轻易用一些简写环境变量,所以我们必须用绝对地址来指定 bash 解释去运行绝对地址的
.sh文件。
properties
# 当脚本意外退出、被 Kill 掉或者崩溃时,系统会始终自动重新启动该脚本
Restart=always- 解释 :这是将 shell 脚本变为"守护进程"的核心。如果脚本因为异常中断抛错退出了,或者被人把
bash指令用kill命令杀了,systemd 马上探测到并立即把它拉起来。
properties
# 在尝试重新启动前需要等待 10 秒。
RestartSec=10- 解释 :极其关键的安全保护机制 。如果我们的脚本不小心少写了一个括号(比如语法错误),脚本一启动瞬间就会崩溃。如果设置了
Restart=always,脚本会一秒钟重启上千次把系统 CPU 炸满。有了这 10 秒,错误后重启会强制休息冷却(Cooldown),让系统有喘息时间。
properties
# 指定执行脚本的用户角色与用户组
User=root
Group=root- 解释 :因为脚本里有很多需要高级权限的命令(比如
systemctl restart tailscaled这个属于系统级指令,不给 Root 是无法调用重启网络网卡的;tailscale up也需要向服务器请求修改路由表规则)。只有用root和root组挂载,它才能够顺畅执行。
3. [Install] 区块:定义安装系统开机自动启动项的行为
properties
[Install]
# 开机自启挂载点:当执行 systemctl enable 时,会把此服务加入到 multi-user.target 之中
WantedBy=multi-user.target- 解释 :这行在平时不起作用,唯一产生作用是在我们敲下
systemctl enable ts-monitor时。它会建立一个快捷方式软链接,放入multi-user.target.wants文件夹下。 - 什么是
multi-user?这就是 Linux 启动完成、可以多用户登录进文字命令行的那个状态(相当于日常使用的正常运行级别Runlevel 3)。
执行监控脚本并实时监督
接下来 对这两个脚本:
shell
# 1. 赋予脚本执行权限
chmod +x /data2/Zerotier_Tailscale_Moniter/Zerotier_Moniter/zt-monitor.sh
chmod +x /data2/Zerotier_Tailscale_Moniter/Tailscale_Moniter/ts-monitor.sh
# 2. 复制(或软链接)服务文件到系统的 systemd 目录
sudo cp /data2/Zerotier_Tailscale_Moniter/Zerotier_Moniter/zt-monitor.service /etc/systemd/system/
sudo cp /data2/Zerotier_Tailscale_Moniter/Tailscale_Moniter/ts-monitor.service /etc/systemd/system/
# 3. 重新加载系统服务并启动
sudo systemctl daemon-reload
sudo systemctl start zt-monitor.service
sudo systemctl start ts-monitor.service
# 4. 最重要的一步:设置开机自启
sudo systemctl enable zt-monitor.service
sudo systemctl enable ts-monitor.service
部署完成后,系统会在后台自动运行这些监控服务,把日志记录到 /var/log/zt-monitor.log 和 /var/log/ts-monitor.log。我们可以随时使用 tail -f /var/log/zt-monitor.log 来检查脚本的工作情况


当然,查看日志毕竟是一般脚本监督的下策,我们还可以用其他的方法,比如说:
部署完成后,我们可以使用 systemd 提供的自带工具来全方位检查这些监控脚本的运行状态和实时输出日志。主要有以下两种方法:
方法一:查看服务当前的整体状态(最常用)
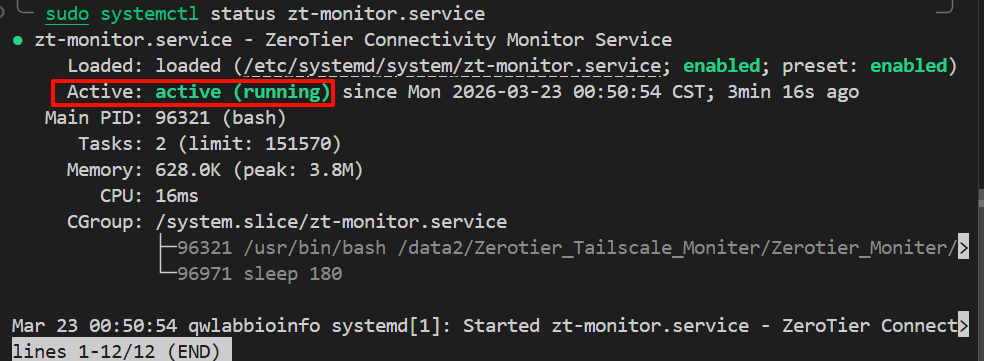
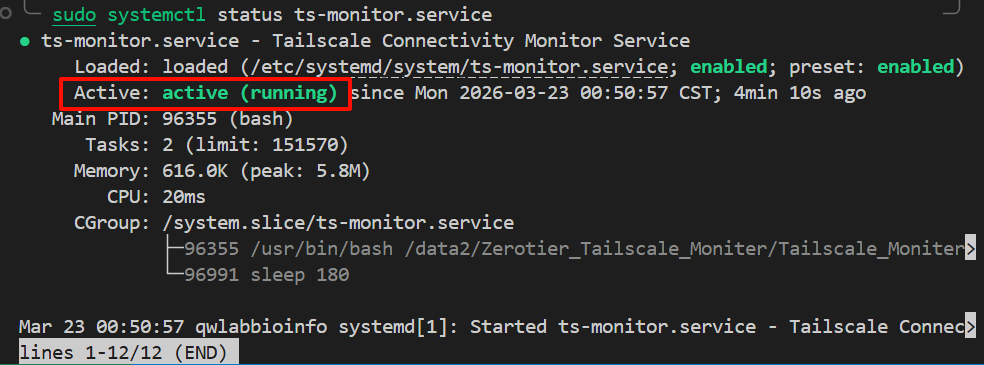
使用 systemctl status 命令可以查看服务是否处于运行状态,以及最近的几条输出日志。
ZeroTier 监控服务:
bash
sudo systemctl status zt-monitor.serviceTailscale 监控服务:
bash
sudo systemctl status ts-monitor.service如何判断是否正常?
在输出的结果中,重点查看 Active: 这一行:
- 正常运行 :显示
Active: active (running),并且有绿色的高亮。这说明我们的while true死循环在后台正在稳稳地跑着。 - 异常崩溃 :如果显示
Active: failed或activating (auto-restart),说明脚本执行出错崩溃了,systemd 正在尝试重启它。此时我们需要看下方附带的最近几行 Error Log 来排查问题。
方法二:查看脚本的实时滚动日志(排障与监控必看)
因为我们在 .sh 脚本里写了很多 echo(比如"Tailscale is connected." 或 "ZeroTier is offline, trying to reconnect..."),这些输出都会被系统级的日志收集器 journald 自动捕获。
我们可以使用 journalctl 命令来查看这些日志。
查看 ZeroTier 的实时日志:
bash
sudo journalctl -u zt-monitor.service -f查看 Tailscale 的实时日志:
bash
sudo journalctl -u ts-monitor.service -f参数解释:
-u:指定查看哪个 Unit(服务)的日志。-f:(follow) 像tail -f一样,实时滚动显示最新日志。当我们的脚本每隔几十秒进行一次echo输出时,屏幕上就会马上刷出新的一行。
(提示:按键盘上的 Ctrl + C 可以退出日志的实时滚动查看模式)
__

进阶:如何查看过去某段时间的完整日志?
如果我们想看看昨晚服务器有没有断开过连接,可以去掉 -f 参数,或者加上时间条件:
bash
# 查看某个服务所有的历史日志(可以使用键盘上下键或 PageUp/PageDown 翻动)
sudo journalctl -u ts-monitor.service
# 只看今天的日志
sudo journalctl -u ts-monitor.service --since today
# 只看最近 50 条日志
sudo journalctl -u ts-monitor.service -n 50通过这几个命令,我们就可以随时精确掌控这两个"网络保镖"在后台的工作情况了