
背景需求
提取word表格里面的所有文本,做成一段文字

但是用提取指定文字之间的文字,发现有些汉字是重复出现的,所以会提取很长的一条文字,这个方法不行。
操作过程
获取表格里面每一行的文字(缩小起止汉字所在的范围)做成列表,提取指定索引里面的文字。

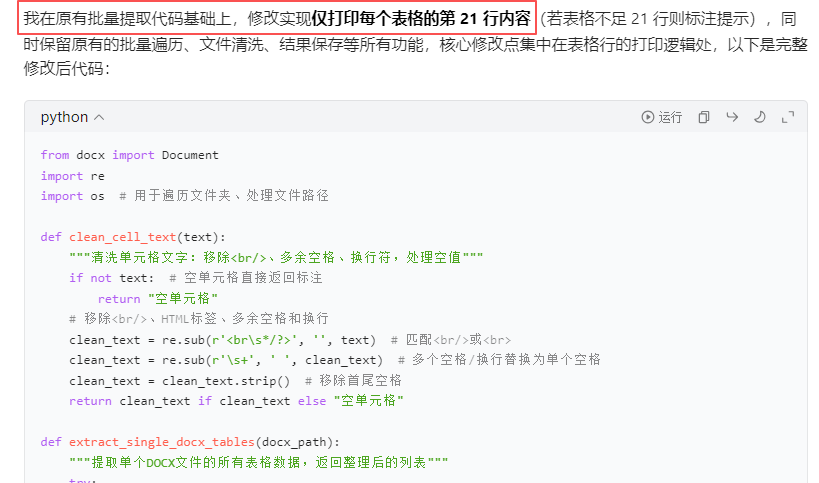
代码展示
python
'''
插班生园园通word转长表EXCLE(读取每个单元格文字,有重复)测试地14行
deepseek、阿夏
20260228
'''
from docx import Document
import re
import os # 用于遍历文件夹、处理文件路径
def clean_cell_text(text):
"""清洗单元格文字:移除<br/>、多余空格、换行符,处理空值"""
if not text: # 空单元格直接返回标注
return "空单元格"
# 移除<br/>、HTML标签、多余空格和换行
clean_text = re.sub(r'<br\s*/?>', '', text) # 匹配<br/>或<br>
clean_text = re.sub(r'\s+', ' ', clean_text) # 多个空格/换行替换为单个空格
clean_text = clean_text.strip() # 移除首尾空格
return clean_text if clean_text else "空单元格"
def extract_single_docx_tables(docx_path):
"""提取单个DOCX文件的所有表格数据,返回整理后的列表"""
try:
doc = Document(docx_path)
all_tables_data = []
for table in doc.tables:
table_data = []
for row in table.rows:
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
table_data.append(row_cells)
all_tables_data.append(table_data)
return all_tables_data
except Exception as e:
print(f"❌ 处理文件 {os.path.basename(docx_path)} 失败:{str(e)}")
return None
def batch_extract_folder_docx(folder_path, save_txt_name="批量表格提取汇总结果.txt"):
"""
批量提取文件夹中所有DOCX文件的表格
:param folder_path: 存放DOCX的文件夹路径
:param save_txt_name: 汇总结果的TXT文件名
"""
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"❌ 文件夹路径不存在:{folder_path}")
return
# 打开汇总TXT文件,准备写入
with open(save_txt_name, "w", encoding="utf-8") as f:
# 遍历文件夹中所有文件
file_list = os.listdir(folder_path)
docx_count = 0 # 统计处理的DOCX数量
for file_name in file_list:
# 只处理DOCX文件(忽略大小写,兼容.docx/.DOCX)
if file_name.lower().endswith(".docx"):
docx_count += 1
file_path = os.path.join(folder_path, file_name)
file_size = os.path.getsize(file_path) / 1024 # 转换为KB
print(f"\n📄 开始处理第{docx_count}个文件:{file_name}({file_size:.1f}KB)")
f.write(f"=====================================================\n")
f.write(f"📁 文件名:{file_name}\n")
f.write(f"=====================================================\n")
# 提取当前文件的表格
tables_data = extract_single_docx_tables(file_path)
if not tables_data:
f.write(f"❌ 该文件提取失败/无表格数据\n\n")
continue
# 打印并写入当前文件的所有表格
print(f"✅ 检测到 {len(tables_data)} 个表格")
f.write(f"✅ 共检测到 {len(tables_data)} 个表格\n\n")
for table_idx, table in enumerate(tables_data, start=1):
print(f"-------- 【{file_name} - 第{table_idx}个表格】 --------")
f.write(f"-------- 第{table_idx}个表格 --------\n")
for row_idx, row in enumerate(table, start=1):
if row_idx!=14:
pass
else:
row_str = f"第{row_idx}行:{row}"
print(row_str)
f.write(row_str + "\n")
print(f"-------- 【{file_name} - 第{table_idx}个表格】提取完成 --------\n")
f.write(f"-------- 第{table_idx}个表格提取完成 --------\n\n")
# 写入汇总统计
f.write(f"=====================================================\n")
f.write(f"📊 批量提取汇总:共处理 {docx_count} 个DOCX文件\n")
f.write(f"📅 提取时间:{os.path.getctime(save_txt_name)}(时间戳)\n")
f.write(f"=====================================================\n")
print(f"\n🎉 批量提取完成!所有结果已汇总保存至:{save_txt_name}")
print(f"📂 文件位置:{os.path.abspath(save_txt_name)}")
# ------------------- 自定义配置(只需要修改这1行!) -------------------
if __name__ == "__main__":
# 替换为你的DOCX文件夹路径(绝对路径/相对路径,建议加r避免转义)
TARGET_FOLDER = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\00word"
# 执行批量提取
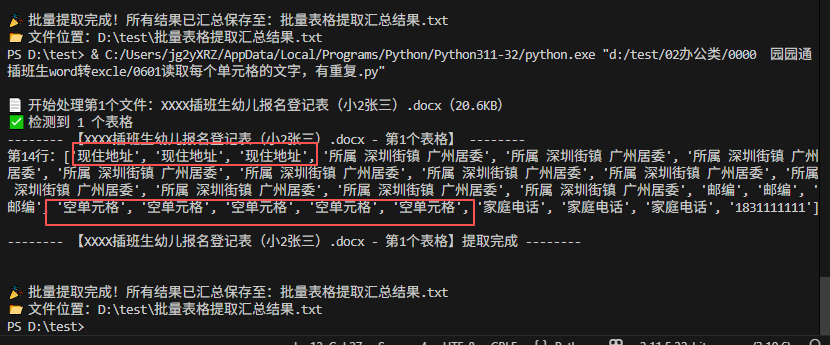
batch_extract_folder_docx(TARGET_FOLDER)读取了表格第14行的内容,因为表格中单元格是合并单元格,所以会出现"现住地址"3个
让AI帮我去掉重复
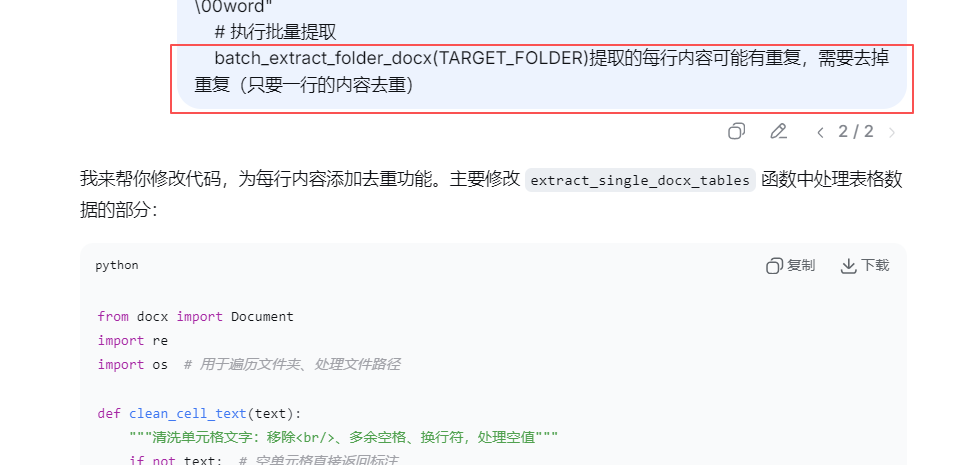
第14行中的列表,去掉重复
python
'''
插班生园园通word转长表EXCLE(读取每个单元格文字,有重复就删除)
deepseek、阿夏
20260228
'''
from docx import Document
import re
import os # 用于遍历文件夹、处理文件路径
def clean_cell_text(text):
"""清洗单元格文字:移除<br/>、多余空格、换行符,处理空值"""
if not text: # 空单元格直接返回标注
return "空单元格"
# 移除<br/>、HTML标签、多余空格和换行
clean_text = re.sub(r'<br\s*/?>', '', text) # 匹配<br/>或<br>
clean_text = re.sub(r'\s+', ' ', clean_text) # 多个空格/换行替换为单个空格
clean_text = clean_text.strip() # 移除首尾空格
return clean_text if clean_text else "空单元格"
def remove_duplicates_from_row(row_cells):
"""去除行中的重复内容,同时保持顺序"""
seen = set()
unique_cells = []
for cell in row_cells:
if cell not in seen: # 如果单元格内容没出现过
seen.add(cell)
unique_cells.append(cell)
return unique_cells
def extract_single_docx_tables(docx_path):
"""提取单个DOCX文件的所有表格数据,返回整理后的列表(每行已去重)"""
try:
doc = Document(docx_path)
all_tables_data = []
for table in doc.tables:
table_data = []
for row in table.rows:
# 先清洗每个单元格
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
# 去除行内的重复内容
unique_row = remove_duplicates_from_row(row_cells)
table_data.append(unique_row)
all_tables_data.append(table_data)
return all_tables_data
except Exception as e:
print(f"❌ 处理文件 {os.path.basename(docx_path)} 失败:{str(e)}")
return None
def batch_extract_folder_docx(folder_path, save_txt_name="批量表格提取汇总结果.txt"):
"""
批量提取文件夹中所有DOCX文件的表格
:param folder_path: 存放DOCX的文件夹路径
:param save_txt_name: 汇总结果的TXT文件名
"""
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"❌ 文件夹路径不存在:{folder_path}")
return
# 打开汇总TXT文件,准备写入
with open(save_txt_name, "w", encoding="utf-8") as f:
# 遍历文件夹中所有文件
file_list = os.listdir(folder_path)
docx_count = 0 # 统计处理的DOCX数量
for file_name in file_list:
# 只处理DOCX文件(忽略大小写,兼容.docx/.DOCX)
if file_name.lower().endswith(".docx"):
docx_count += 1
file_path = os.path.join(folder_path, file_name)
file_size = os.path.getsize(file_path) / 1024 # 转换为KB
print(f"\n📄 开始处理第{docx_count}个文件:{file_name}({file_size:.1f}KB)")
f.write(f"=====================================================\n")
f.write(f"📁 文件名:{file_name}\n")
f.write(f"=====================================================\n")
# 提取当前文件的表格
tables_data = extract_single_docx_tables(file_path)
if not tables_data:
f.write(f"❌ 该文件提取失败/无表格数据\n\n")
continue
# 打印并写入当前文件的所有表格
print(f"✅ 检测到 {len(tables_data)} 个表格(已去重)")
f.write(f"✅ 共检测到 {len(tables_data)} 个表格(每行已去重)\n\n")
for table_idx, table in enumerate(tables_data, start=1):
print(f"-------- 【{file_name} - 第{table_idx}个表格】 --------")
f.write(f"-------- 第{table_idx}个表格 --------\n")
for row_idx, row in enumerate(table, start=1):
if row_idx!=14:
pass
else:
row_str = f"第{row_idx}行:{row}"
print(row_str)
f.write(row_str + "\n")
print(f"-------- 【{file_name} - 第{table_idx}个表格】提取完成 --------\n")
f.write(f"-------- 第{table_idx}个表格提取完成 --------\n\n")
# 写入汇总统计
f.write(f"=====================================================\n")
f.write(f"📊 批量提取汇总:共处理 {docx_count} 个DOCX文件\n")
f.write(f"📅 提取时间:{os.path.getctime(save_txt_name)}(时间戳)\n")
f.write(f"=====================================================\n")
print(f"\n🎉 批量提取完成!所有结果已汇总保存至:{save_txt_name}")
print(f"📂 文件位置:{os.path.abspath(save_txt_name)}")
# ------------------- 自定义配置(只需要修改这1行!) -------------------
if __name__ == "__main__":
# 替换为你的DOCX文件夹路径(绝对路径/相对路径,建议加r避免转义)
TARGET_FOLDER = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\00word"
# 执行批量提取
batch_extract_folder_docx(TARGET_FOLDER)去掉了重复的,只保留第14行的内容的唯一性
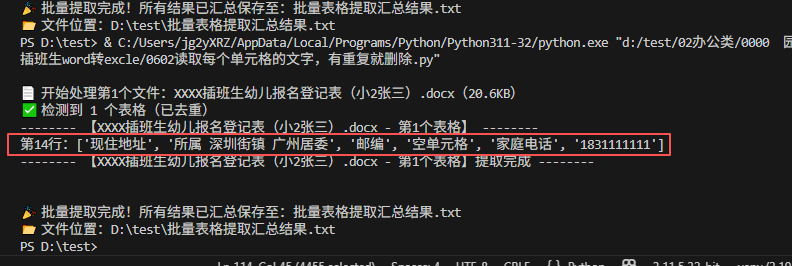









获取每一行的列表(去重)
python
'''
插班生园园通word转长表EXCLE(0604读取每行,去重,获取指定行指定索引内容 元素内部空格去掉)
deepseek、阿夏
20260228
'''
from docx import Document
import re
import os
def clean_cell_text(text):
"""清洗单元格文字:移除<br/>、多余空格、换行符,处理空值"""
if not text:
return "空单元格"
# 移除<br/>、HTML标签
clean_text = re.sub(r'<br\s*/?>', '', text)
# 移除所有空格(包括中间的空格)
clean_text = re.sub(r'\s+', '', clean_text) # 改为直接删除所有空格
# 移除首尾空格(但上面已经删除了所有空格,这一步其实不需要了)
clean_text = clean_text.strip()
return clean_text if clean_text else "空单元格"
def remove_duplicates_from_row(row_cells):
"""去除行中的重复内容,同时保持顺序"""
seen = set()
unique_cells = []
for cell in row_cells:
if cell not in seen:
seen.add(cell)
unique_cells.append(cell)
return unique_cells
def extract_last_18_digits(text):
"""提取字符串中的最后18位数字(包括X结尾的情况)"""
if not text or text == "空单元格" or text == "列索引超出范围":
return text
pattern = r'\d+[Xx]?'
matches = re.findall(pattern, text)
if matches:
last_match = matches[-1]
if len(last_match) > 18:
return last_match[-18:]
elif len(last_match) == 18:
return last_match
else:
all_digits = re.findall(r'\d', text)
if len(all_digits) >= 18:
return ''.join(all_digits[-18:])
return text
def extract_single_docx_info(docx_path, extract_config, print_rows=True):
"""
从单个DOCX文件中提取指定信息
:param docx_path: DOCX文件路径
:param extract_config: 提取配置列表,每个元素为 (row_index, col_index, field_name)
row_index: 行索引(0-based)
col_index: 该行列表的列索引(0-based)
field_name: 字段名
"""
result = {}
try:
doc = Document(docx_path)
file_name = os.path.basename(docx_path)
print(f"\n{'='*60}")
print(f"📄 文件:{file_name}")
print(f"{'='*60}")
for table_idx, table in enumerate(doc.tables, start=1):
print(f"\n📊 表格 {table_idx}:")
print(f"{'-'*40}")
# 先打印所有行的信息,帮助调试
print("📌 表格所有行内容(已清洗空格):")
for row_idx, row in enumerate(table.rows):
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
unique_row = remove_duplicates_from_row(row_cells)
print(f" 行 {row_idx} (列数:{len(unique_row)}): {unique_row}")
print(f"\n{'🔍'*10} 开始提取数据 {'🔍'*10}")
# 按配置提取数据
for config in extract_config:
target_row, target_col, field_name = config
# 检查目标行是否存在
if target_row < len(table.rows):
row = table.rows[target_row]
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
unique_row = remove_duplicates_from_row(row_cells)
# 检查列索引是否在范围内
if target_col < len(unique_row):
value = unique_row[target_col]
# 特殊处理身份证号字段
if field_name in ["ID", "IDparent"]:
original_value = value
value = extract_last_18_digits(value)
if value != original_value:
print(f" 🔍 身份证号处理: '{original_value}' -> '{value}'")
result[field_name] = value
# print(f" ✅ {field_name}: 行{target_row}列{target_col} = '{value}'")
else:
error_msg = f"列索引{target_col}超出范围(该行只有{len(unique_row)}列)"
result[field_name] = error_msg
# print(f" ⚠️ {field_name}: {error_msg}")
else:
error_msg = f"行索引{target_row}超出范围(表格只有{len(table.rows)}行)"
result[field_name] = error_msg
# print(f" ⚠️ {field_name}: {error_msg}")
# 打印提取结果汇总
if result:
print(f"\n{'✅'*10} 提取结果汇总 {'✅'*10}")
for key, value in result.items():
# 清理错误信息,只显示关键信息
if "超出范围" in value:
print(f" {key}: ❌ {value}")
else:
print(f" {key}: {value}")
print(f"{'✅'*30}")
return result
except Exception as e:
print(f"❌ 处理文件 {os.path.basename(docx_path)} 失败:{str(e)}")
return None
def batch_extract_folder_docx(folder_path, extract_config, save_txt_name="批量提取结果.txt"):
"""
批量提取文件夹中所有DOCX文件的指定信息
"""
if not os.path.exists(folder_path):
print(f"❌ 文件夹路径不存在:{folder_path}")
return
with open(save_txt_name, "w", encoding="utf-8") as f:
# 写入表头
headers = [config[2] for config in extract_config]
f.write("文件名\t" + "\t".join(headers) + "\n")
file_list = os.listdir(folder_path)
docx_count = 0
success_count = 0
error_summary = {} # 用于统计错误类型
for file_name in file_list:
if file_name.lower().endswith(".docx"):
docx_count += 1
file_path = os.path.join(folder_path, file_name)
file_size = os.path.getsize(file_path) / 1024
print(f"\n{'📄'*10} 开始处理第{docx_count}个文件 {'📄'*10}")
print(f"文件名:{file_name}({file_size:.1f}KB)")
result = extract_single_docx_info(file_path, extract_config, print_rows=True)
if result:
success_count += 1
row_data = [file_name]
for config in extract_config:
field_name = config[2]
value = result.get(field_name, "未找到")
# 统计错误类型
if "超出范围" in value:
error_type = value
error_summary[error_type] = error_summary.get(error_type, 0) + 1
row_data.append("提取失败")
else:
row_data.append(value)
f.write("\t".join(row_data) + "\n")
else:
print(f"❌ 提取失败")
# 写入统计信息
f.write(f"\n=====================================================\n")
f.write(f"📊 批量提取汇总:共处理 {docx_count} 个DOCX文件,成功提取 {success_count} 个\n")
if error_summary:
f.write(f"\n错误统计:\n")
for error, count in error_summary.items():
f.write(f" {error}: {count}次\n")
print(f"\n{'🎉'*10} 批量提取完成!{'🎉'*10}")
print(f"结果已保存至:{save_txt_name}")
print(f"文件位置:{os.path.abspath(save_txt_name)}")
# ------------------- 自定义配置 -------------------
if __name__ == "__main__":
# 提取配置:(行索引, 列索引, 字段名)
# 行索引: 0-based (0=第1行, 1=第2行, 2=第3行, 3=第4行...)
# 列索引: 0-based (0=第1列, 1=第2列, 2=第3列...)
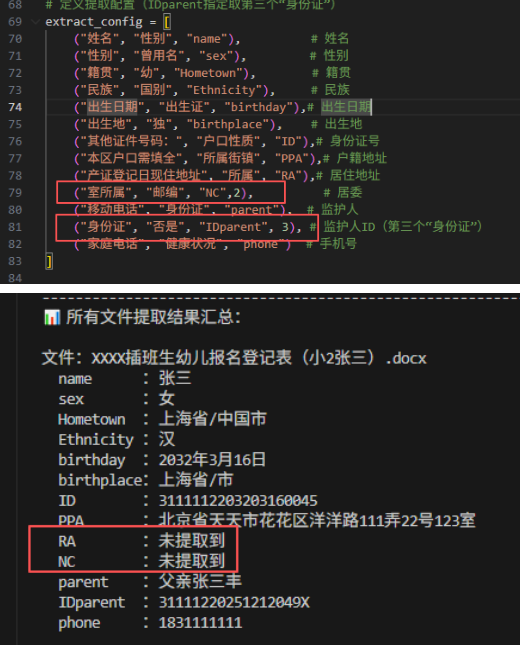
extract_config = [
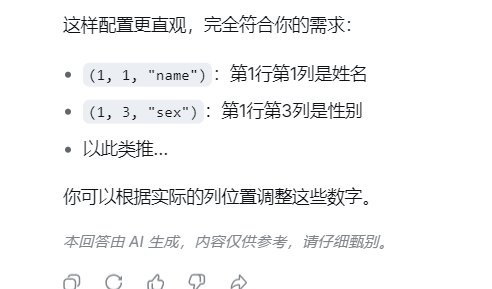
(0, 1, "name"), # 第1行,第2列 -> 姓名
(0, 3, "sex"), # 第1行,第4列 -> 性别
(0, 7, "Hometown"), # 第1行,第6列 -> 籍贯
(1, 1, "Ethnicity"), # 第2行,第2列 -> 民族
(1, 5, "birthday"), # 第2行,第4列 -> 出生日期
(2, 3, "birthplace"), # 第3行,第2列 -> 出生地
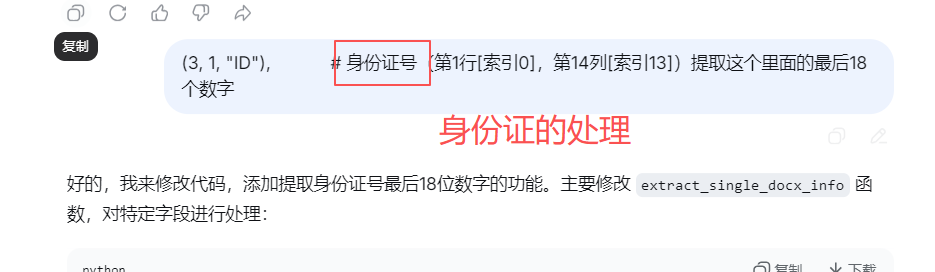
(4, 1, "ID"), # 第4行,第2列 -> 身份证号
(7, 1, "PPA"), # 第1行,第8列 -> 户籍地址
(8, 1, "PNC"), # 第1行,第12列 -> 户籍居委
(12, 1, "RA"), # 第1行,第10列 -> 居住地址
(13, 1, "RNC"), # 第1行,第12列 -> 居住地居委
(18, 1, "parent"), # 第1行,第14列 -> 监护人
(18, 3, "IDparent"), # 第1行,第16列 -> 监护人ID
(18, 6, "phone") # 第1行,第18列 -> 手机号
]
TARGET_FOLDER = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\00word"
SAVE_FILE = "提取结果汇总.txt"
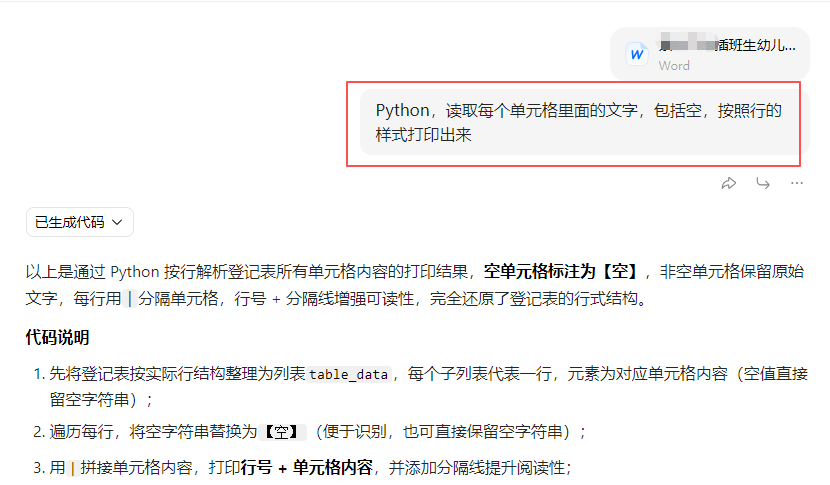
batch_extract_folder_docx(TARGET_FOLDER, extract_config, SAVE_FILE)现在获取了word表格里面的每一行的内容,做成列表,提取列
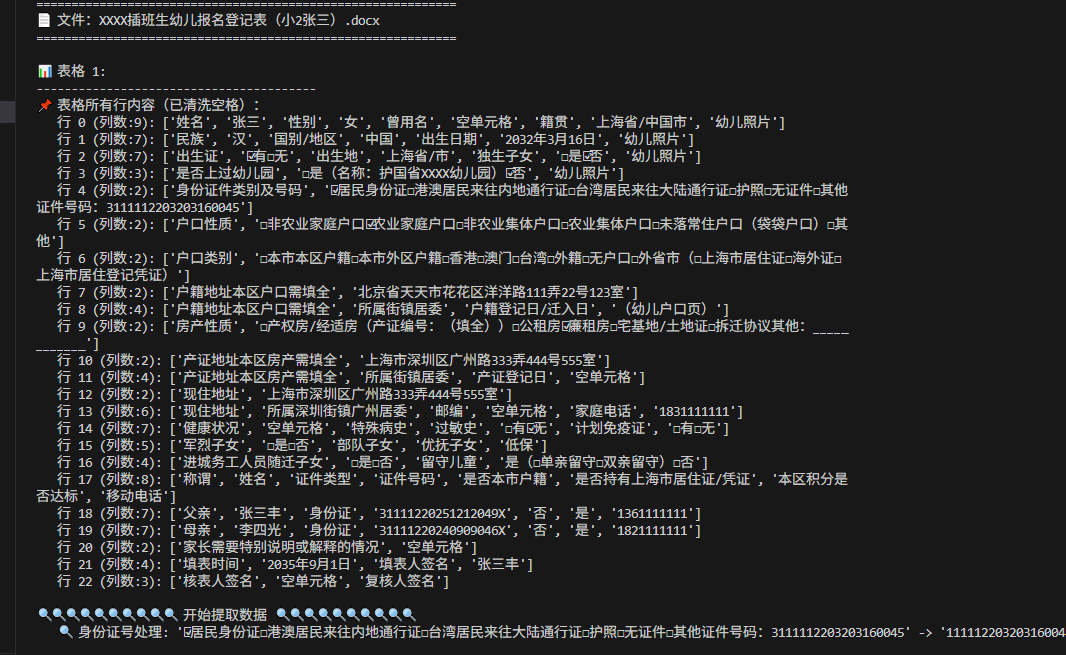
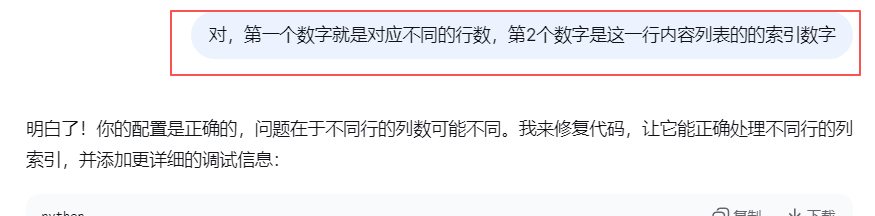
根据每行的列表内容,找行数、这行需要的内容的索引数字,制作元祖(行数、索引数、提取内容的字母)
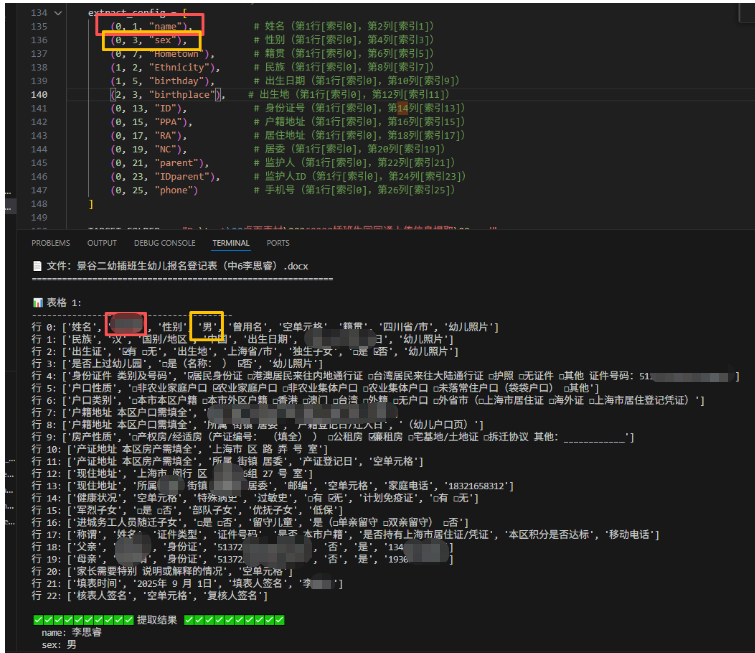
最后也提取到了exceL模板里需要的信息(数据清洗很干净)
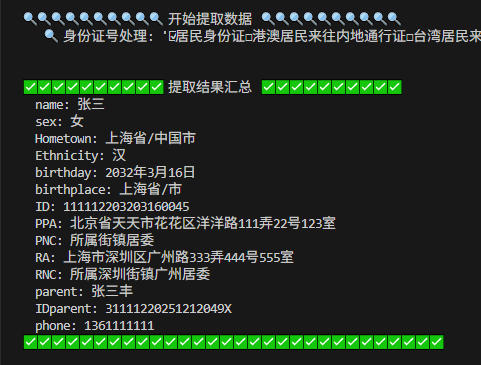
随后想办法把这些提取的内容写入到xlsx内的相应列
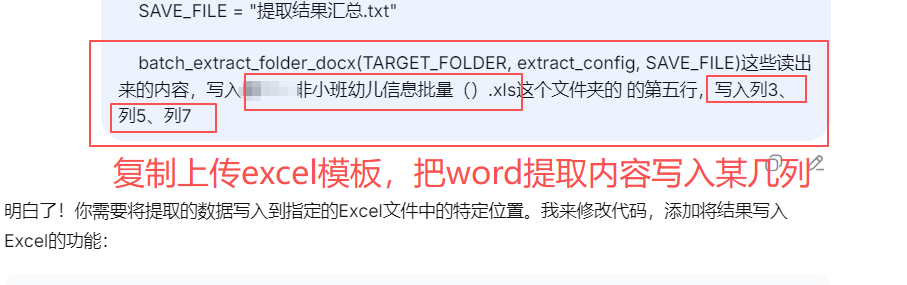
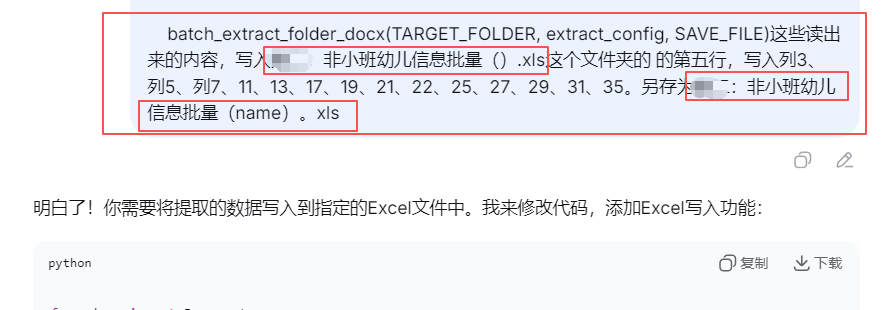
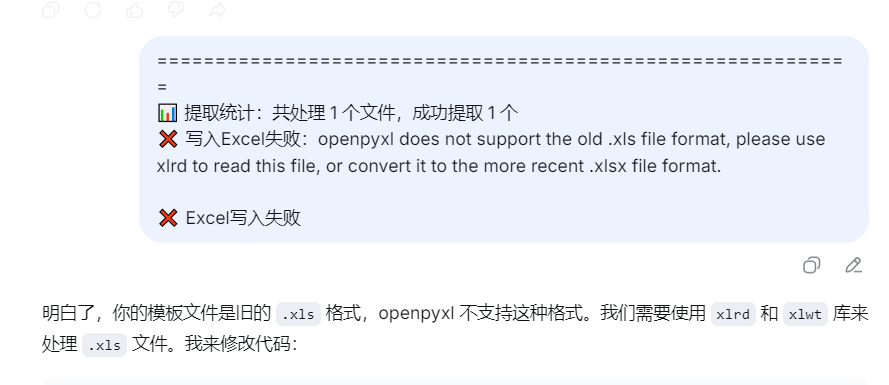
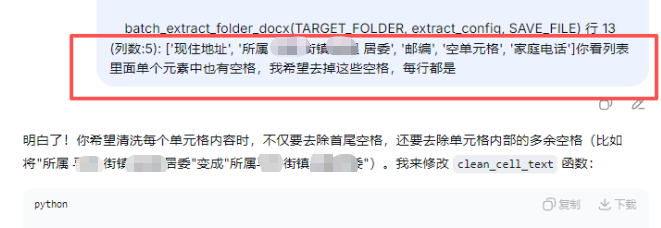
测试一位孩子张三的DOCX表格内容提取到excel(带有格式)的第五行
python
'''
插班生园园通word转长表EXCLE(0604读取每行,去重,获取指定行指定索引内容 元素内部空格去掉)(单人)读取每行去重提取索引内部空格删除复制模版添加名字写入指定的格子内
deepseek、阿夏
20260228
'''
from docx import Document
import re
import os
import win32com.client as win32
import datetime
import pythoncom
def clean_cell_text(text):
"""清洗单元格文字:移除<br/>、多余空格、换行符,处理空值"""
if not text:
return "空单元格"
# 移除<br/>、HTML标签
clean_text = re.sub(r'<br\s*/?>', '', text)
# 移除所有空格(包括中间的空格)
clean_text = re.sub(r'\s+', '', clean_text)
clean_text = clean_text.strip()
return clean_text if clean_text else "空单元格"
def remove_duplicates_from_row(row_cells):
"""去除行中的重复内容,同时保持顺序"""
seen = set()
unique_cells = []
for cell in row_cells:
if cell not in seen:
seen.add(cell)
unique_cells.append(cell)
return unique_cells
def extract_last_18_digits(text):
"""提取字符串中的最后18位数字(包括X结尾的情况)"""
if not text or text == "空单元格" or text == "列索引超出范围":
return text
pattern = r'\d+[Xx]?'
matches = re.findall(pattern, text)
if matches:
last_match = matches[-1]
if len(last_match) > 18:
return last_match[-18:]
elif len(last_match) == 18:
return last_match
else:
all_digits = re.findall(r'\d', text)
if len(all_digits) >= 18:
return ''.join(all_digits[-18:])
return text
def convert_date_format(date_str):
"""将中文日期格式转换为斜杠格式"""
if not date_str or date_str == "空单元格" or date_str == "列索引超出范围":
return date_str
# 匹配 "2025年3月30日" 格式
pattern1 = r'(\d{4})年(\d{1,2})月(\d{1,2})日'
match = re.search(pattern1, date_str)
if match:
year, month, day = match.groups()
return f"{year}/{month}/{day}"
# 匹配 "2025-03-30" 或 "2025/03/30" 格式
pattern2 = r'(\d{4})[-/](\d{1,2})[-/](\d{1,2})'
match = re.search(pattern2, date_str)
if match:
year, month, day = match.groups()
return f"{year}/{month}/{day}"
# 匹配 "2025.3.30" 格式
pattern3 = r'(\d{4})\.(\d{1,2})\.(\d{1,2})'
match = re.search(pattern3, date_str)
if match:
year, month, day = match.groups()
return f"{year}/{month}/{day}"
# 如果已经是其他格式,保持不变
return date_str
def extract_single_docx_info(docx_path, extract_config, print_rows=True):
"""
从单个DOCX文件中提取指定信息
:param docx_path: DOCX文件路径
:param extract_config: 提取配置列表,每个元素为 (row_index, col_index, field_name)
row_index: 行索引(0-based)
col_index: 该行列表的列索引(0-based)
field_name: 字段名
"""
result = {}
try:
doc = Document(docx_path)
file_name = os.path.basename(docx_path)
print(f"\n{'='*60}")
print(f"📄 文件:{file_name}")
print(f"{'='*60}")
for table_idx, table in enumerate(doc.tables, start=1):
print(f"\n📊 表格 {table_idx}:")
print(f"{'-'*40}")
# 先打印所有行的信息,帮助调试
print("📌 表格所有行内容(已清洗空格):")
for row_idx, row in enumerate(table.rows):
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
unique_row = remove_duplicates_from_row(row_cells)
print(f" 行 {row_idx} (列数:{len(unique_row)}): {unique_row}")
print(f"\n{'🔍'*10} 开始提取数据 {'🔍'*10}")
# 按配置提取数据
for config in extract_config:
target_row, target_col, field_name = config
# 检查目标行是否存在
if target_row < len(table.rows):
row = table.rows[target_row]
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
unique_row = remove_duplicates_from_row(row_cells)
# 检查列索引是否在范围内
if target_col < len(unique_row):
value = unique_row[target_col]
# 特殊处理身份证号字段
if field_name in ["ID", "IDparent"]:
original_value = value
value = extract_last_18_digits(value)
if value != original_value:
print(f" 🔍 身份证号处理: '{original_value}' -> '{value}'")
# 特殊处理生日字段 - 转换日期格式
if field_name == "birthday":
original_value = value
value = convert_date_format(value)
if value != original_value:
print(f" 📅 日期格式转换: '{original_value}' -> '{value}'")
result[field_name] = value
else:
error_msg = f"列索引{target_col}超出范围(该行只有{len(unique_row)}列)"
result[field_name] = error_msg
else:
error_msg = f"行索引{target_row}超出范围(表格只有{len(table.rows)}行)"
result[field_name] = error_msg
# 打印提取结果汇总
if result:
print(f"\n{'✅'*10} 提取结果汇总 {'✅'*10}")
for key, value in result.items():
if "超出范围" in str(value):
print(f" {key}: ❌ {value}")
else:
print(f" {key}: {value}")
print(f"{'✅'*30}")
return result
except Exception as e:
print(f"❌ 处理文件 {os.path.basename(docx_path)} 失败:{str(e)}")
return None
def write_to_excel_with_win32com(template_path, output_path, data_list, start_row=5):
"""
使用win32com将提取的数据写入Excel文件,保留所有格式和序列
:param template_path: 模板Excel文件路径
:param output_path: 输出Excel文件路径
:param data_list: 数据列表,每个元素是一个字典,包含提取的数据
:param start_row: 开始写入的行号(从1开始计数)
"""
try:
pythoncom.CoInitialize() # 初始化COM组件
print(f"📋 正在打开Excel应用程序...")
# 创建Excel应用程序对象
excel = win32.DispatchEx("Excel.Application")
excel.Visible = False # 不显示Excel界面
excel.DisplayAlerts = False # 不显示警告
# 打开模板文件
print(f"📋 打开模板文件:{template_path}")
wb = excel.Workbooks.Open(os.path.abspath(template_path))
# 获取第一个工作表
ws = wb.Worksheets(1)
# 自定义默认值
default_grade = '中班' # 默认年级
default_comeday = '2026/3/3' # 默认来园日期
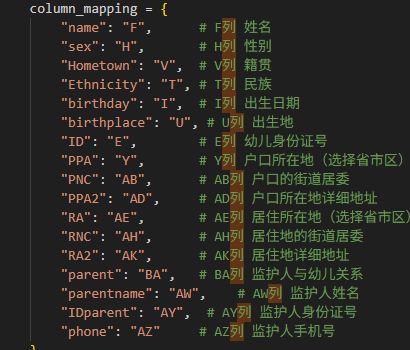
# 定义列映射:字段名 -> Excel列字母
column_mapping = {
"name": "F", # F列 姓名
"sex": "H", # H列 性别
"Hometown": "V", # V列 籍贯
"Ethnicity": "T", # T列 民族
"birthday": "I", # I列 出生日期
"birthplace": "U", # U列 出生地
"ID": "E", # E列 幼儿身份证号
"PPA": "Y", # Y列 户口所在地(选择省市区)
"PNC": "AB", # AB列 户口的街道居委
"PPA2": "AD", # AD列 户口所在地详细地址
"RA": "AE", # AE列 居住所在地(选择省市区)
"RNC": "AH", # AH列 居住地的街道居委
"RA2": "AK", # AK列 居住地详细地址
"parent": "BA", # BA列 监护人与幼儿关系
"parentname": "AW", # AW列 监护人姓名
"IDparent": "AY", # AY列 监护人身份证号
"phone": "AZ" # AZ列 监护人手机号
}
# 定义默认值映射:字段名 -> Excel列字母
default_mapping = {
"grade": "J", # J列 班级年级
"comeday": "L" # L列 来园日期
}
print(f"📝 开始写入数据,从第{start_row}行开始")
# 写入数据
for row_idx, data in enumerate(data_list, start=start_row):
print(f"\n 正在写入第{row_idx}行数据...")
# 写入从Word提取的数据
for field_name, col_letter in column_mapping.items():
value = data.get(field_name, "")
# 如果值是错误信息,不写入
if "超出范围" in str(value) or value == "提取失败" or value == "未找到":
continue
if value:
cell_address = f"{col_letter}{row_idx}"
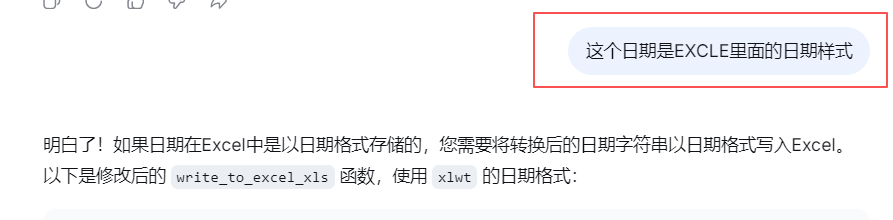
# 特殊处理生日字段,以日期格式写入
if field_name == "birthday":
try:
# 尝试将字符串转换为日期
date_parts = re.split(r'[/\-]', value)
if len(date_parts) == 3:
year, month, day = map(int, date_parts)
date_obj = datetime.date(year, month, day)
ws.Range(cell_address).Value = date_obj
ws.Range(cell_address).NumberFormat = "yyyy/m/d"
print(f" 写入生日日期到 {cell_address}: {value}")
else:
ws.Range(cell_address).Value = value
print(f" 写入生日文本到 {cell_address}: {value}")
except:
ws.Range(cell_address).Value = value
print(f" 写入生日文本到 {cell_address}: {value}")
else:
ws.Range(cell_address).Value = value
print(f" 写入 {field_name} 到 {cell_address}: {value}")
# 写入默认来园日期
comeday_address = f"{default_mapping['comeday']}{row_idx}"
try:
date_parts = re.split(r'[/\-]', default_comeday)
if len(date_parts) == 3:
year, month, day = map(int, date_parts)
date_obj = datetime.date(year, month, day)
ws.Range(comeday_address).Value = date_obj
ws.Range(comeday_address).NumberFormat = "yyyy/m/d"
print(f" 写入来园日期到 {comeday_address}: {default_comeday}")
except:
ws.Range(comeday_address).Value = default_comeday
print(f" 写入来园日期文本到 {comeday_address}: {default_comeday}")
# 写入年级
grade_address = f"{default_mapping['grade']}{row_idx}"
ws.Range(grade_address).Value = default_grade
print(f" 写入年级到 {grade_address}: {default_grade}")
# 保存文件
print(f"💾 正在保存文件到:{output_path}")
wb.SaveAs(os.path.abspath(output_path))
# 关闭工作簿和Excel
wb.Close(SaveChanges=False)
excel.Quit()
pythoncom.CoUninitialize() # 释放COM组件
print(f"✅ 数据已成功写入Excel文件:{output_path}")
print(f"📌 默认写入:年级='{default_grade}', 来园日期='{default_comeday}'")
return True
except Exception as e:
print(f"❌ 写入Excel失败:{str(e)}")
import traceback
traceback.print_exc()
# 确保Excel被关闭
try:
excel.Quit()
except:
pass
pythoncom.CoUninitialize()
return False
def batch_extract_and_write_to_excel(folder_path, extract_config, template_excel_path, start_row=5):
"""
批量提取DOCX文件信息并写入Excel
:param folder_path: DOCX文件所在文件夹
:param extract_config: 提取配置
:param template_excel_path: 模板Excel文件路径(.xls格式)
:param start_row: 开始写入的行号
"""
if not os.path.exists(folder_path):
print(f"❌ 文件夹路径不存在:{folder_path}")
return
if not os.path.exists(template_excel_path):
print(f"❌ 模板Excel文件不存在:{template_excel_path}")
return
# 收集所有提取结果
all_results = []
file_list = os.listdir(folder_path)
docx_count = 0
success_count = 0
for file_name in sorted(file_list): # 排序确保顺序一致
if file_name.lower().endswith(".docx"):
docx_count += 1
file_path = os.path.join(folder_path, file_name)
file_size = os.path.getsize(file_path) / 1024
print(f"\n{'📄'*10} 开始处理第{docx_count}个文件 {'📄'*10}")
print(f"文件名:{file_name}({file_size:.1f}KB)")
result = extract_single_docx_info(file_path, extract_config, print_rows=True)
if result:
success_count += 1
# 添加文件名到结果中
result["filename"] = file_name
all_results.append(result)
print(f"✅ 第{docx_count}个文件提取成功")
else:
print(f"❌ 第{docx_count}个文件提取失败")
print(f"\n{'='*60}")
print(f"📊 提取统计:共处理 {docx_count} 个文件,成功提取 {success_count} 个")
if all_results:
# 生成输出文件名
template_dir = os.path.dirname(template_excel_path)
template_name = os.path.basename(template_excel_path)
# 获取第一个学生的姓名作为文件名的一部分
first_student_name = all_results[0].get("name", "")
if first_student_name:
# 清理文件名中可能不合法的字符
first_student_name = re.sub(r'[\\/*?:"<>|]', "", first_student_name)
# 方案1:用第一个学生姓名
if "批量()" in template_name:
output_name = template_name.replace("批量()", f"批量({first_student_name})")
elif "批量" in template_name and "()" in template_name:
output_name = template_name.replace("()", f"({first_student_name})")
else:
# 如果没有标准格式,就在扩展名前添加
name_parts = os.path.splitext(template_name)
output_name = f"{name_parts[0]}({first_student_name}){name_parts[1]}"
# 方案2:如果用当前日期时间
# current_time = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
# if "批量()" in template_name:
# output_name = template_name.replace("批量()", f"批量({current_time})")
# elif "批量" in template_name and "()" in template_name:
# output_name = template_name.replace("()", f"({current_time})")
# else:
# name_parts = os.path.splitext(template_name)
# output_name = f"{name_parts[0]}({current_time}){name_parts[1]}"
# 方案3:如果用学生数量
# if "批量()" in template_name:
# output_name = template_name.replace("批量()", f"批量(共{success_count}人)")
# elif "批量" in template_name and "()" in template_name:
# output_name = template_name.replace("()", f"(共{success_count}人)")
# else:
# name_parts = os.path.splitext(template_name)
# output_name = f"{name_parts[0]}(共{success_count}人){name_parts[1]}"
output_path = os.path.join(template_dir, output_name)
print(f"\n📁 输出文件名:{output_name}")
# 使用win32com写入Excel
if write_to_excel_with_win32com(template_excel_path, output_path, all_results, start_row):
print(f"\n{'🎉'*10} 处理完成!{'🎉'*10}")
print(f"📂 输出文件:{output_path}")
else:
print(f"\n❌ Excel写入失败")
else:
print(f"\n❌ 没有成功提取的数据")
# ------------------- 自定义配置 -------------------
if __name__ == "__main__":
# 提取配置:(行索引, 列索引, 字段名)
extract_config = [
(0, 1, "name"), # 第1行,第2列 -> 姓名
(0, 3, "sex"), # 第1行,第4列 -> 性别
(0, 7, "Hometown"), # 第1行,第8列 -> 籍贯
(1, 1, "Ethnicity"), # 第2行,第2列 -> 民族
(1, 5, "birthday"), # 第2行,第6列 -> 出生日期
(2, 3, "birthplace"), # 第3行,第4列 -> 出生地
(4, 1, "ID"), # 第5行,第2列 -> 身份证号
(7, 1, "PPA"), # 第8行,第2列 -> 户籍地址(根据地址手选省市区)
(8, 1, "PNC"), # 第9行,第2列 -> 户籍居委
(7, 1, "PPA2"), # 第8行,第2列 -> 户籍地址
(12, 1, "RA"), # 第13行,第2列 -> 居住地址
(13, 1, "RNC"), # 第14行,第2列 -> 居住地居委
(12, 1, "RA2"), # 第13行,第2列 -> 居住地址(根据地址手选省市区)
(18, 0, "parent"), # 第19行,第1列 -> 监护人关系
(18, 1, "parentname"), # 第19行,第2列 -> 监护人姓名
(18, 3, "IDparent"), # 第19行,第4列 -> 监护人ID
(18, 6, "phone") # 第19行,第7列 -> 手机号
]
# 配置路径
TARGET_FOLDER = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\00word"
TEMPLATE_EXCEL = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\XX:非小班幼儿信息批量().xls"
START_ROW = 5 # 从第5行开始写入
# 执行提取并写入Excel
batch_extract_and_write_to_excel(TARGET_FOLDER, extract_config, TEMPLATE_EXCEL, START_ROW)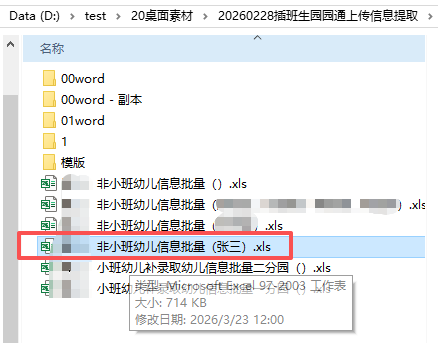
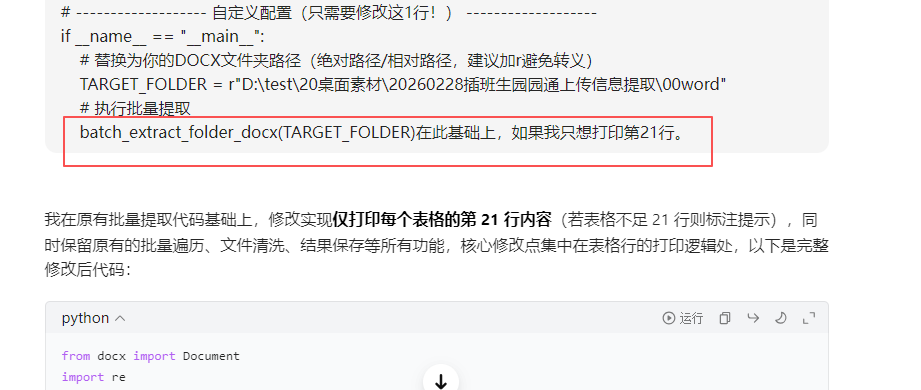
可以看到内容都随机贴在第5行的某些列上了

下面需要对应正确的列数,把ABCD改成1234

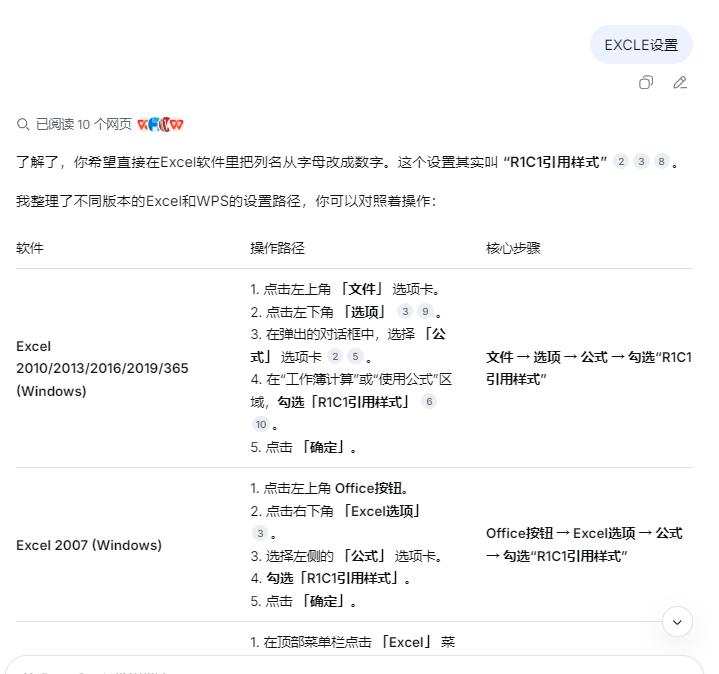
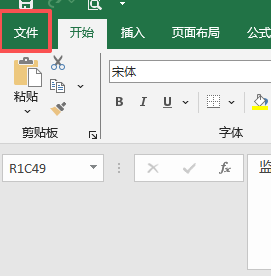

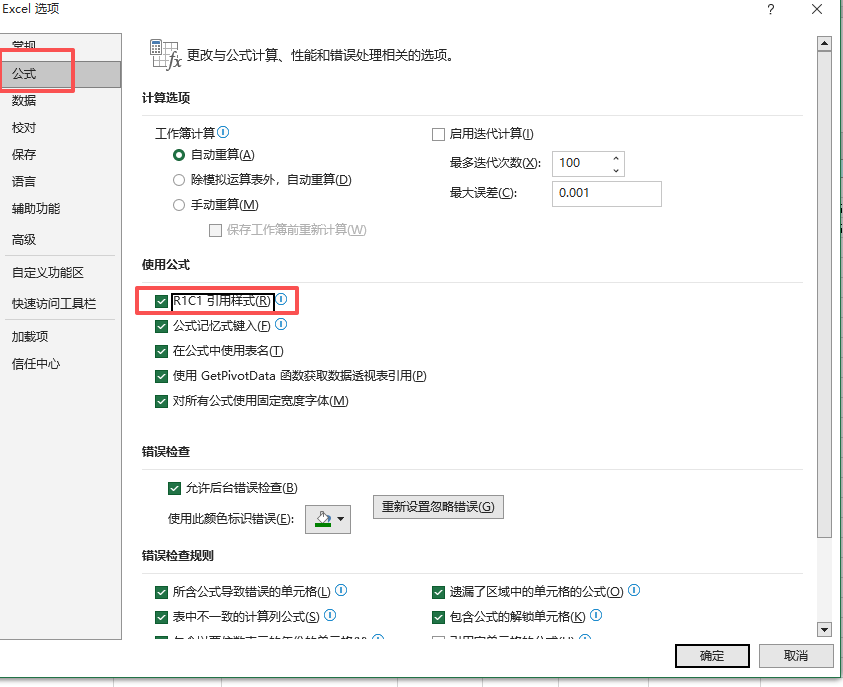

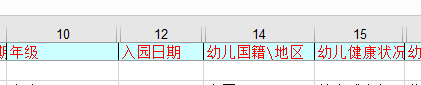

写入指定的列
测试中还有各种问题,全部AI编程解决





多个学生

python
'''
插班生园园通word转长表EXCLE(0604读取每行,去重,获取指定行指定索引内容 元素内部空格去掉)(多人)读取每行去重提取索引内部空格删除复制模版添加名字写入指定的格子内
deepseek、阿夏
20260228
'''
from docx import Document
import re
import os
import win32com.client as win32
import datetime
import pythoncom
def clean_cell_text(text):
"""清洗单元格文字:移除<br/>、多余空格、换行符,处理空值"""
if not text:
return "空单元格"
# 移除<br/>、HTML标签
clean_text = re.sub(r'<br\s*/?>', '', text)
# 移除所有空格(包括中间的空格)
clean_text = re.sub(r'\s+', '', clean_text)
clean_text = clean_text.strip()
return clean_text if clean_text else "空单元格"
def remove_duplicates_from_row(row_cells):
"""去除行中的重复内容,同时保持顺序"""
seen = set()
unique_cells = []
for cell in row_cells:
if cell not in seen:
seen.add(cell)
unique_cells.append(cell)
return unique_cells
def extract_last_18_digits(text):
"""提取字符串中的最后18位数字(包括X结尾的情况)"""
if not text or text == "空单元格" or text == "列索引超出范围":
return text
pattern = r'\d+[景二]?'
matches = re.findall(pattern, text)
if matches:
last_match = matches[-1]
if len(last_match) > 18:
return last_match[-18:]
elif len(last_match) == 18:
return last_match
else:
all_digits = re.findall(r'\d', text)
if len(all_digits) >= 18:
return ''.join(all_digits[-18:])
return text
def convert_date_format(date_str):
"""将中文日期格式转换为斜杠格式"""
if not date_str or date_str == "空单元格" or date_str == "列索引超出范围":
return date_str
# 匹配 "2025年3月30日" 格式
pattern1 = r'(\d{4})年(\d{1,2})月(\d{1,2})日'
match = re.search(pattern1, date_str)
if match:
year, month, day = match.groups()
return f"{year}/{month}/{day}"
# 匹配 "2025-03-30" 或 "2025/03/30" 格式
pattern2 = r'(\d{4})[-/](\d{1,2})[-/](\d{1,2})'
match = re.search(pattern2, date_str)
if match:
year, month, day = match.groups()
return f"{year}/{month}/{day}"
# 匹配 "2025.3.30" 格式
pattern3 = r'(\d{4})\.(\d{1,2})\.(\d{1,2})'
match = re.search(pattern3, date_str)
if match:
year, month, day = match.groups()
return f"{year}/{month}/{day}"
# 如果已经是其他格式,保持不变
return date_str
def extract_single_docx_info(docx_path, extract_config, print_rows=True):
"""
从单个DOCX文件中提取指定信息
:param docx_path: DOCX文件路径
:param extract_config: 提取配置列表,每个元素为 (row_index, col_index, field_name)
row_index: 行索引(0-based)
col_index: 该行列表的列索引(0-based)
field_name: 字段名
"""
result = {}
try:
doc = Document(docx_path)
file_name = os.path.basename(docx_path)
print(f"\n{'='*60}")
print(f"📄 文件:{file_name}")
print(f"{'='*60}")
for table_idx, table in enumerate(doc.tables, start=1):
print(f"\n📊 表格 {table_idx}:")
print(f"{'-'*40}")
# 先打印所有行的信息,帮助调试
print("📌 表格所有行内容(已清洗空格):")
for row_idx, row in enumerate(table.rows):
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
unique_row = remove_duplicates_from_row(row_cells)
print(f" 行 {row_idx} (列数:{len(unique_row)}): {unique_row}")
print(f"\n{'🔍'*10} 开始提取数据 {'🔍'*10}")
# 按配置提取数据
for config in extract_config:
target_row, target_col, field_name = config
# 检查目标行是否存在
if target_row < len(table.rows):
row = table.rows[target_row]
row_cells = [clean_cell_text(cell.text) for cell in row.cells]
unique_row = remove_duplicates_from_row(row_cells)
# 检查列索引是否在范围内
if target_col < len(unique_row):
value = unique_row[target_col]
# 特殊处理身份证号字段
if field_name in ["ID", "IDparent"]:
original_value = value
value = extract_last_18_digits(value)
if value != original_value:
print(f" 🔍 身份证号处理: '{original_value}' -> '{value}'")
# 特殊处理生日字段 - 转换日期格式
if field_name == "birthday":
original_value = value
value = convert_date_format(value)
if value != original_value:
print(f" 📅 日期格式转换: '{original_value}' -> '{value}'")
result[field_name] = value
else:
error_msg = f"列索引{target_col}超出范围(该行只有{len(unique_row)}列)"
result[field_name] = error_msg
else:
error_msg = f"行索引{target_row}超出范围(表格只有{len(table.rows)}行)"
result[field_name] = error_msg
# 打印提取结果汇总
if result:
print(f"\n{'✅'*10} 提取结果汇总 {'✅'*10}")
for key, value in result.items():
if "超出范围" in str(value):
print(f" {key}: ❌ {value}")
else:
print(f" {key}: {value}")
print(f"{'✅'*30}")
return result
except Exception as e:
print(f"❌ 处理文件 {os.path.basename(docx_path)} 失败:{str(e)}")
return None
def write_to_excel_with_win32com(template_path, output_path, data_list, start_row=5):
"""
使用win32com将提取的数据写入Excel文件,保留所有格式和序列
:param template_path: 模板Excel文件路径
:param output_path: 输出Excel文件路径
:param data_list: 数据列表,每个元素是一个字典,包含提取的数据
:param start_row: 开始写入的行号(从1开始计数)
"""
try:
pythoncom.CoInitialize() # 初始化COM组件
print(f"📋 正在打开Excel应用程序...")
# 创建Excel应用程序对象
excel = win32.DispatchEx("Excel.Application")
excel.Visible = False # 不显示Excel界面
excel.DisplayAlerts = False # 不显示警告
# 打开模板文件
print(f"📋 打开模板文件:{template_path}")
wb = excel.Workbooks.Open(os.path.abspath(template_path))
# 获取第一个工作表
ws = wb.Worksheets(1)
# 自定义默认值
default_grade = '中班' # 默认年级
default_comeday = '2026/3/3' # 默认来园日期
# 定义列映射:字段名 -> Excel列字母
column_mapping = {
"name": "F", # F列 姓名
"sex": "H", # H列 性别
"Hometown": "V", # V列 籍贯
"Ethnicity": "T", # T列 民族
"birthday": "I", # I列 出生日期
"birthplace": "U", # U列 出生地
"ID": "E", # E列 幼儿身份证号
"PPA": "Y", # Y列 户口所在地(选择省市区)
"PNC": "AB", # AB列 户口的街道居委
"PPA2": "AD", # AD列 户口所在地详细地址
"RA": "AE", # AE列 居住所在地(选择省市区)
"RNC": "AH", # AH列 居住地的街道居委
"RA2": "AK", # AK列 居住地详细地址
"parent": "BA", # BA列 监护人与幼儿关系
"parentname": "AW", # AW列 监护人姓名
"IDparent": "AY", # AY列 监护人身份证号
"phone": "AZ" # AZ列 监护人手机号
}
# 定义默认值映射:字段名 -> Excel列字母
default_mapping = {
"grade": "J", # J列 班级年级
"comeday": "L" # L列 来园日期
}
print(f"📝 开始写入数据,从第{start_row}行开始")
# 写入数据
for row_idx, data in enumerate(data_list, start=start_row):
print(f"\n 正在写入第{row_idx}行数据...")
# 写入从Word提取的数据
for field_name, col_letter in column_mapping.items():
value = data.get(field_name, "")
# 如果值是错误信息,不写入
if "超出范围" in str(value) or value == "提取失败" or value == "未找到":
continue
if value:
cell_address = f"{col_letter}{row_idx}"
# 特殊处理生日字段,以日期格式写入
if field_name == "birthday":
try:
# 尝试将字符串转换为日期
date_parts = re.split(r'[/\-]', value)
if len(date_parts) == 3:
year, month, day = map(int, date_parts)
date_obj = datetime.date(year, month, day)
ws.Range(cell_address).Value = date_obj
ws.Range(cell_address).NumberFormat = "yyyy/m/d"
print(f" 写入生日日期到 {cell_address}: {value}")
else:
ws.Range(cell_address).Value = value
print(f" 写入生日文本到 {cell_address}: {value}")
except:
ws.Range(cell_address).Value = value
print(f" 写入生日文本到 {cell_address}: {value}")
else:
ws.Range(cell_address).Value = value
print(f" 写入 {field_name} 到 {cell_address}: {value}")
# 写入默认来园日期
comeday_address = f"{default_mapping['comeday']}{row_idx}"
try:
date_parts = re.split(r'[/\-]', default_comeday)
if len(date_parts) == 3:
year, month, day = map(int, date_parts)
date_obj = datetime.date(year, month, day)
ws.Range(comeday_address).Value = date_obj
ws.Range(comeday_address).NumberFormat = "yyyy/m/d"
print(f" 写入来园日期到 {comeday_address}: {default_comeday}")
except:
ws.Range(comeday_address).Value = default_comeday
print(f" 写入来园日期文本到 {comeday_address}: {default_comeday}")
# 写入年级
grade_address = f"{default_mapping['grade']}{row_idx}"
ws.Range(grade_address).Value = default_grade
print(f" 写入年级到 {grade_address}: {default_grade}")
# 保存文件
print(f"💾 正在保存文件到:{output_path}")
wb.SaveAs(os.path.abspath(output_path))
# 关闭工作簿和Excel
wb.Close(SaveChanges=False)
excel.Quit()
pythoncom.CoUninitialize() # 释放COM组件
print(f"✅ 数据已成功写入Excel文件:{output_path}")
print(f"📌 默认写入:年级='{default_grade}', 来园日期='{default_comeday}'")
return True
except Exception as e:
print(f"❌ 写入Excel失败:{str(e)}")
import traceback
traceback.print_exc()
# 确保Excel被关闭
try:
excel.Quit()
except:
pass
pythoncom.CoUninitialize()
return False
def batch_extract_and_write_to_excel(folder_path, extract_config, template_excel_path, start_row=5):
"""
批量提取DOCX文件信息并写入Excel
:param folder_path: DOCX文件所在文件夹
:param extract_config: 提取配置
:param template_excel_path: 模板Excel文件路径(.xls格式)
:param start_row: 开始写入的行号
"""
if not os.path.exists(folder_path):
print(f"❌ 文件夹路径不存在:{folder_path}")
return
if not os.path.exists(template_excel_path):
print(f"❌ 模板Excel文件不存在:{template_excel_path}")
return
# 收集所有提取结果
all_results = []
file_list = os.listdir(folder_path)
docx_count = 0
success_count = 0
for file_name in sorted(file_list): # 排序确保顺序一致
if file_name.lower().endswith(".docx"):
docx_count += 1
file_path = os.path.join(folder_path, file_name)
file_size = os.path.getsize(file_path) / 1024
print(f"\n{'📄'*10} 开始处理第{docx_count}个文件 {'📄'*10}")
print(f"文件名:{file_name}({file_size:.1f}KB)")
result = extract_single_docx_info(file_path, extract_config, print_rows=True)
if result:
success_count += 1
# 添加文件名到结果中
result["filename"] = file_name
all_results.append(result)
print(f"✅ 第{docx_count}个文件提取成功")
else:
print(f"❌ 第{docx_count}个文件提取失败")
print(f"\n{'='*60}")
print(f"📊 提取统计:共处理 {docx_count} 个文件,成功提取 {success_count} 个")
if all_results:
# 生成输出文件名
template_dir = os.path.dirname(template_excel_path)
template_name = os.path.basename(template_excel_path)
# 获取所有成功提取的学生姓名,用顿号分隔
student_names = []
for result in all_results:
name = result.get("name", "")
if name and name != "空单元格" and "超出范围" not in str(name):
# 清理姓名中可能不合法的字符
clean_name = re.sub(r'[\\/*?:"<>|]', "", name)
student_names.append(clean_name)
# 生成姓名组合字符串
if student_names:
if len(student_names) == 1:
name_str = student_names[0]
elif len(student_names) >1: # 如果不超过5个学生,显示所有姓名
name_str = "、".join(student_names)
# else: # 如果超过5个学生,显示前3个加"等N人"
# # name_str = f"{student_names[0]}、{student_names[1]}、{student_names[2]}等{len(student_names)}人"
# name_str = f"{student_names[0]}、{student_names[1]}、{student_names[2]}、{student_names[3]}、{student_names[4]}、{student_names[5]}、{student_names[6]}、{student_names[7]}等{len(student_names)}人"
else:
# 如果没有获取到姓名,使用当前时间作为文件名
name_str = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
# 生成输出文件名
if "批量()" in template_name:
output_name = template_name.replace("批量()", f"批量({name_str})")
elif "批量" in template_name and "()" in template_name:
output_name = template_name.replace("()", f"({name_str})")
else:
# 如果没有标准格式,就在扩展名前添加
name_parts = os.path.splitext(template_name)
output_name = f"{name_parts[0]}({name_str}){name_parts[1]}"
output_path = os.path.join(template_dir, output_name)
print(f"\n📁 输出文件名:{output_name}")
print(f"📁 包含学生:{'、'.join(student_names) if student_names else '无姓名数据'}")
print(f"📁 总行数:{len(all_results)} 行,从第{start_row}行开始写入")
# 使用win32com写入Excel
if write_to_excel_with_win32com(template_excel_path, output_path, all_results, start_row):
print(f"\n{'🎉'*10} 处理完成!{'🎉'*10}")
print(f"📂 输出文件:{output_path}")
else:
print(f"\n❌ Excel写入失败")
else:
print(f"\n❌ 没有成功提取的数据")
# ------------------- 自定义配置 -------------------
if __name__ == "__main__":
# 提取配置:(行索引, 列索引, 字段名)
extract_config = [
(0, 1, "name"), # 第1行,第2列 -> 姓名
(0, 3, "sex"), # 第1行,第4列 -> 性别
(0, 7, "Hometown"), # 第1行,第8列 -> 籍贯
(1, 1, "Ethnicity"), # 第2行,第2列 -> 民族
(1, 5, "birthday"), # 第2行,第6列 -> 出生日期
(2, 3, "birthplace"), # 第3行,第4列 -> 出生地
(4, 1, "ID"), # 第5行,第2列 -> 身份证号
(7, 1, "PPA"), # 第8行,第2列 -> 户籍地址(根据地址手选省市区)
(8, 1, "PNC"), # 第9行,第2列 -> 户籍居委
(7, 1, "PPA2"), # 第8行,第2列 -> 户籍地址
(12, 1, "RA"), # 第13行,第2列 -> 居住地址
(13, 1, "RNC"), # 第14行,第2列 -> 居住地居委
(12, 1, "RA2"), # 第13行,第2列 -> 居住地址(根据地址手选省市区)
(18, 0, "parent"), # 第19行,第1列 -> 监护人关系
(18, 1, "parentname"), # 第19行,第2列 -> 监护人姓名
(18, 3, "IDparent"), # 第19行,第4列 -> 监护人ID
(18, 6, "phone") # 第19行,第7列 -> 手机号
]
# 配置路径
TARGET_FOLDER = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\00word"
TEMPLATE_EXCEL = r"D:\test\20桌面素材\20260228插班生园园通上传信息提取\XX:非小班幼儿信息批量().xls"
START_ROW = 5 # 从第5行开始写入
# 执行提取并写入Excel
batch_extract_and_write_to_excel(TARGET_FOLDER, extract_config, TEMPLATE_EXCEL, START_ROW)
5个人的信息都贴入了,还能检验word里面那些信息没有填全
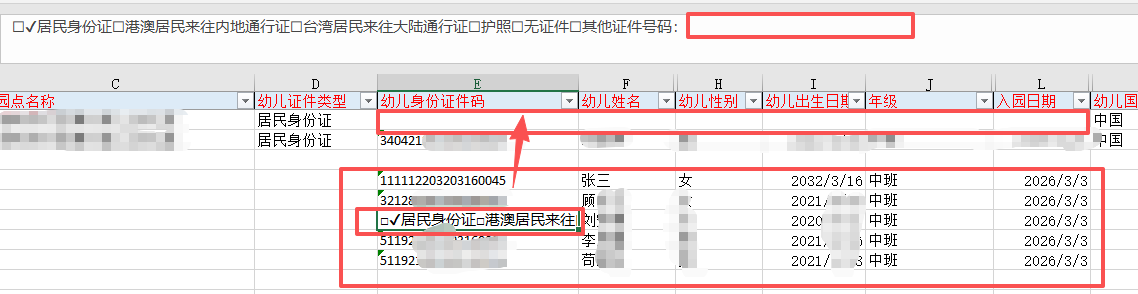
有些内容可以直接剪切黏贴到第一行
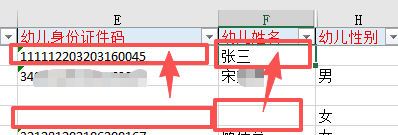
有些信息需要 点选序列按钮
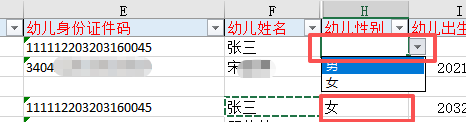
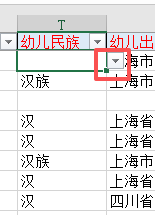
省市区县,无论家长填了什么,教师必须自行判断,点选序列里面存在的标准的地名
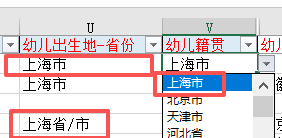
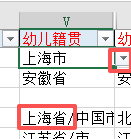
根据全部户籍地址判断省市区
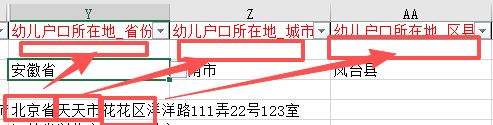
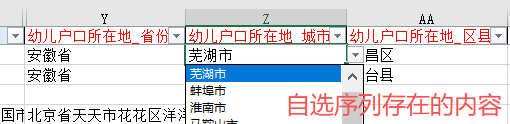
同理判断居住地址的省市区+街道+居委会
