前言
AI, 人工智能(Artificial Intelligence) , 是指通过计算机系统模拟⼈类智能的技术, 通过这种技术, 他可以实现⼈类的认知和思维活动, 从而可以完成许多复杂的任务, 比如学习, 推理决策等. 本质就是通过算法和数据, 让机器具备类人能力.
随着科技的发展, AI 已逐渐成为我们⽣活的⼀部分, 在现代社会中的应⽤已经变得越来越⼴泛. 在日常生活活和⼯作中, 也能感受到AI给我们带来的便利性, 以及对我们⽣活的影响.
接下来,将学习AI相关的基本术语,以及在IDEA中接入DeepSeek模型
一.术语介绍
1.模型
模型旨在处理和⽣成信息的算法, 通常模仿⼈类的认知功能. 通过从⼤型数据集中学习模式和洞察, 这些模型可以进行预测、生成文本、图像或其他输出,从而增强各个行业的各种应用.
可理解为模型是一个"超级加工厂",这个工厂经过特殊训练,摸索出了特定的规律,学会了完成某个"特定的任务"
SpringAI 的作用,就是让我们在Java/Spring应用中,能方便的选择不同模型、构建与发送输入、接收并处理输出
2.LLM(Large Language Model)
大语言模型是人工智能中专门处理文本的一种类型,属于语言模型范畴
LLM的特点是规模庞大,在大量文本数据中进行训练,学习语言数据中的复杂模式,旨在理解和生成人类语言.
3.提示词
提示词是用户或者系统提供给大语言模型的指令或文本,用于引导模型生成特定的输出.
可以理解为模型的输入,无论是一个单词、一个问题、一段描述,还是结构化指令,都可视为提示词
从工程视觉来看,提示词分为用户提示词和系统提示词

4.词元(Tokens)
词元是大预言模型处理文本时最小的语义单位,用于将文本拆解为模型可理解的离散单元
词元通过分词器将⽂本拆分而来, 不同模型的分词规则不同, 同⼀个词在不同模型中可能被拆分成不同词元
模型的上下文窗口(如 128K)实际是词元数量限制,API 收费通常按词元数计费(词元≈成本)。词元数量越多,计算耗时与内存占用越高。因此在实际使用时,应尽量避免冗余词汇(如 "请""谢谢" 等礼貌用语),以降低成本、提升效率。
二.IDEA中接入deepseek
1.环境准备
需要保证JDK17+,SpringBoot 3.2+

2.准备工作
打开deepseek,进入API开放平台

首先进行充值(充值1元即可)
申请deepseekAPI key
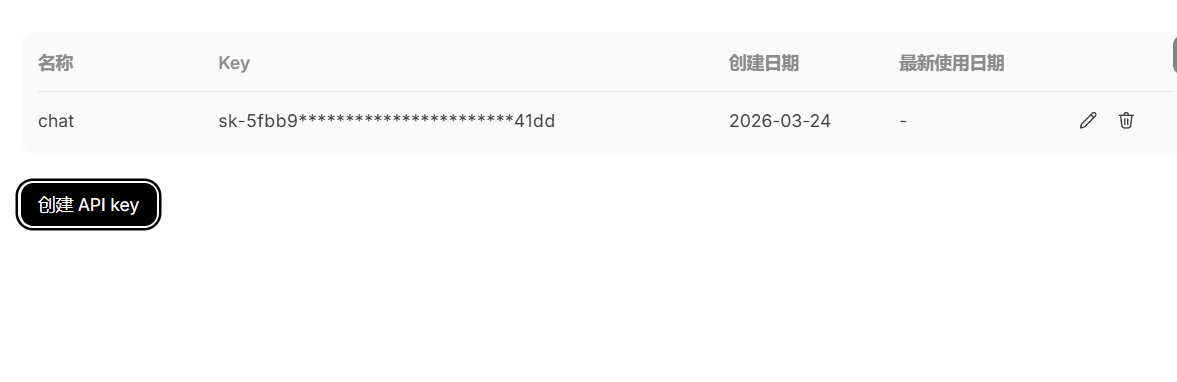 注意:一定要保存好API key,丢失将无法找回,也不要交给其他人!!!!!
注意:一定要保存好API key,丢失将无法找回,也不要交给其他人!!!!!
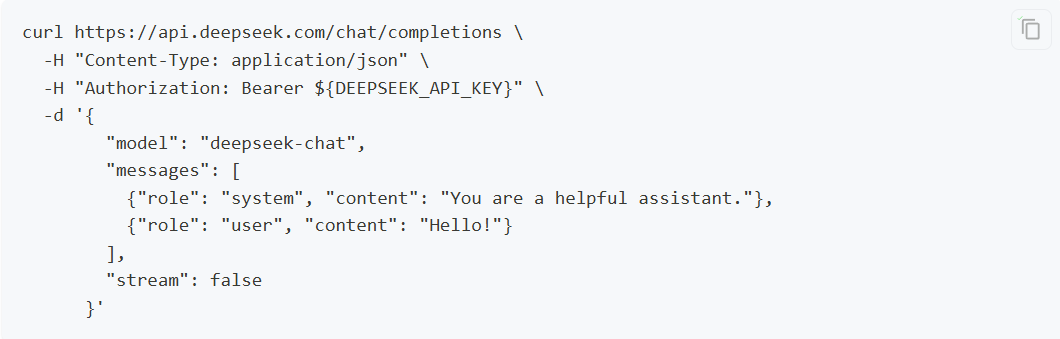
在接口文档中,我们可以看到调用模型的参数

3.项目初始化
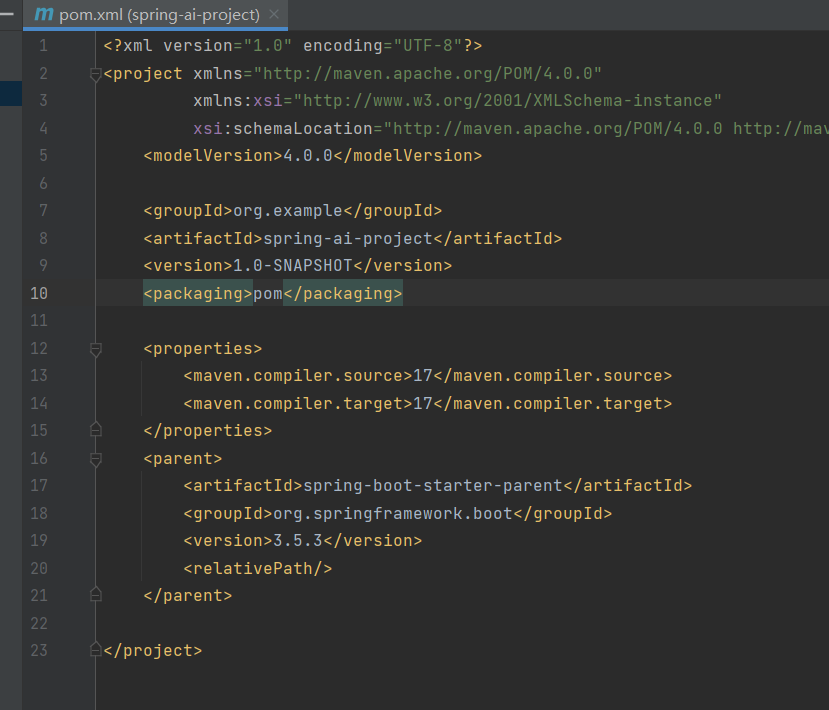
创建一个Maven项目
修改父工程pom.xml文件,引入依赖
创建子模块,并引入依赖
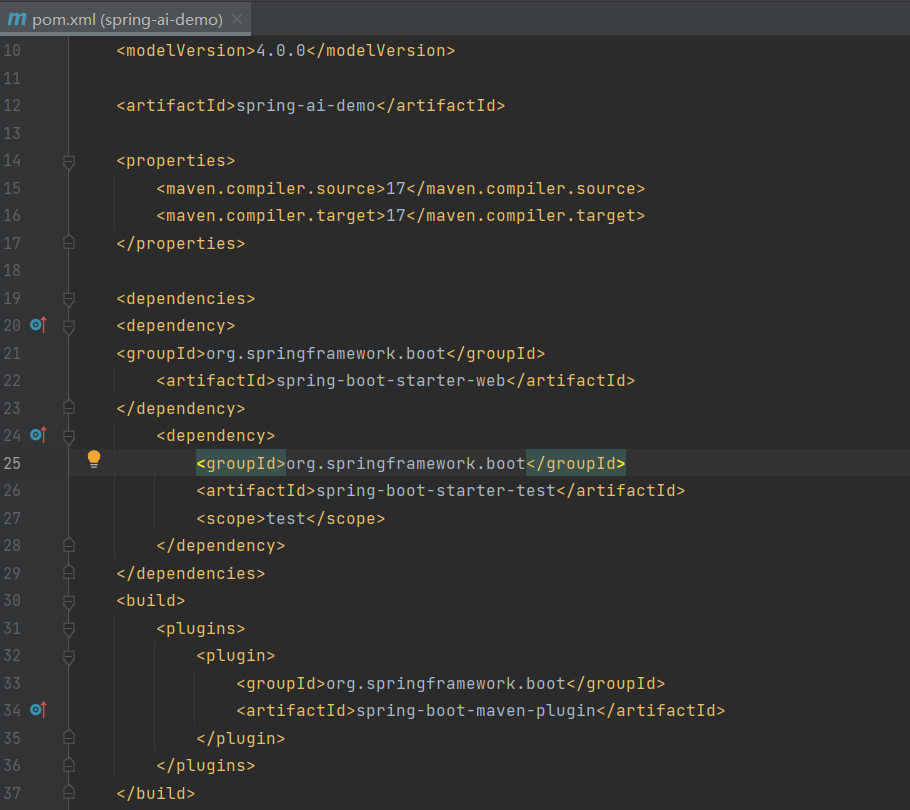
创建启动类
加入SpringAi的依赖

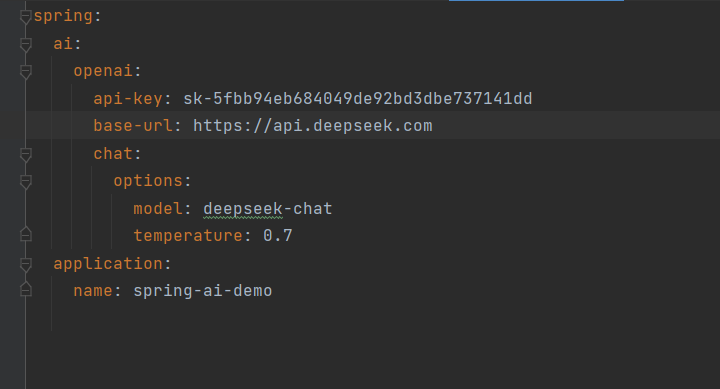
在application.yml中配置API密钥
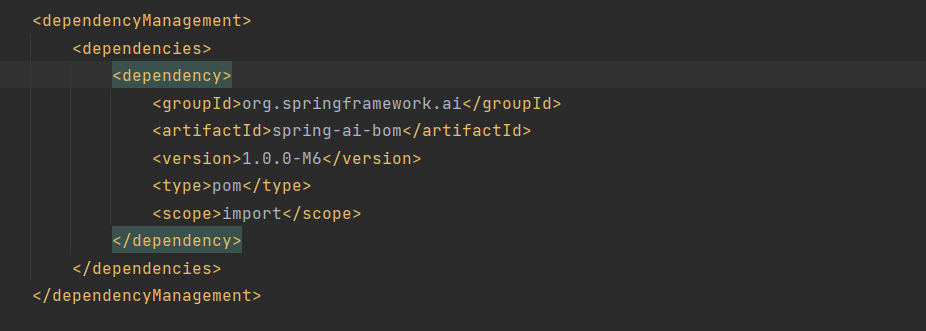
引入模型
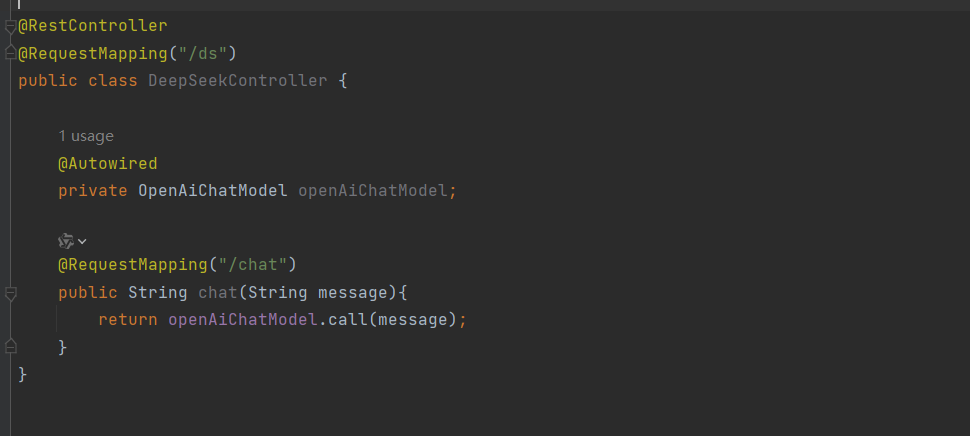
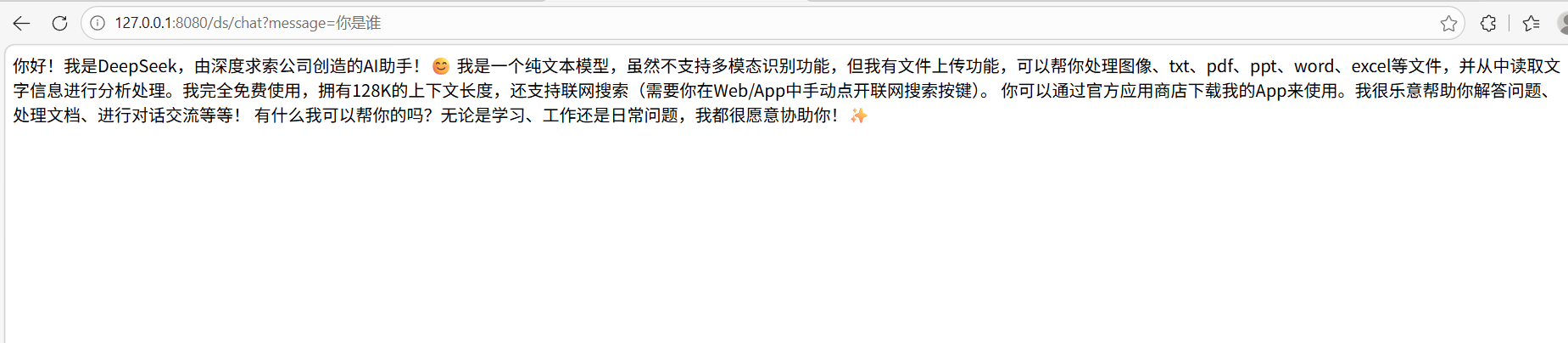
运行程序,进行接口访问
如需引入其它模型,通过修改配置文件即可.