如果说前面的梯度下降、牛顿法和 L-BFGS 是我们下山用的**"交通工具",那么 LLL-平滑(LLL-smooth) 和 μ\muμ-强凸(μ\muμ-strongly convex) 就是用来描述这座山"地形好坏"**的两个最关键的数学指标。
在机器学习和凸优化中,当我们想要从数学上证明一个算法"一定能收敛"且"收敛得多快"时,几乎全都依赖于这两个假设。
为了直观地理解,我们可以用一个"二次函数三明治"(Quadratic Sandwich)的比喻来刻画它们。
1. LLL-平滑 (LLL-smoothness):限制"最大弯曲程度"
通俗理解:这座山虽然有起伏,但绝对没有突然的悬崖峭壁或尖锐的刺。它的坡度(梯度)变化是非常平缓且受控的。
数学定义 :如果一个函数 f(x)f(x)f(x) 是 LLL-平滑的,意味着它的梯度是 Lipschitz 连续的,常数为 LLL:
∥∇f(x)−∇f(y)∥≤L∥x−y∥\|\nabla f(x) - \nabla f(y)\| \le L \|x - y\|∥∇f(x)−∇f(y)∥≤L∥x−y∥
几何意义(上界) :这意味着在函数上的任意一点 x0x_0x0,你都可以在它上面倒扣一个开口大小由 LLL 决定的二次函数(抛物面)。这个二次函数在 x0x_0x0 处与原函数相切,并且在所有地方都稳稳地压在原函数的上方 。
f(x)≤f(x0)+∇f(x0)T(x−x0)+L2∥x−x0∥2f(x) \le f(x_0) + \nabla f(x_0)^T(x - x_0) + \frac{L}{2}\|x - x_0\|^2f(x)≤f(x0)+∇f(x0)T(x−x0)+2L∥x−x0∥2
如果 LLL 很大,说明允许原函数弯曲得很厉害(很尖锐);如果 LLL 很小,说明原函数非常平缓。
2. μ\muμ-强凸 (μ\muμ-strong convexity):限制"最小弯曲程度"
通俗理解 :普通的"凸函数"只保证山谷像个碗,但碗底可能非常非常平坦(比如一个盘子),导致算法在碗底迷失方向。而"μ\muμ-强凸"保证了这个碗底有绝对明确的弧度,绝不是平的,只要你往下走,就一定会以极快的速度滑向唯一的最低点。
数学定义 :在普通的凸函数基础上,加上了一个由 μ\muμ 控制的二次项惩罚:
f(x)≥f(x0)+∇f(x0)T(x−x0)+μ2∥x−x0∥2f(x) \ge f(x_0) + \nabla f(x_0)^T(x - x_0) + \frac{\mu}{2}\|x - x_0\|^2f(x)≥f(x0)+∇f(x0)T(x−x0)+2μ∥x−x0∥2
几何意义(下界) :这意味着在函数上的任意一点 x0x_0x0,你都可以在它下面垫一个开口大小由 μ\muμ 决定的二次函数(抛物面)。这个二次函数在 x0x_0x0 处与原函数相切,并且在所有地方都稳稳地托住原函数的下方 。
如果 μ\muμ 很小,说明函数接近平坦;如果 μ\muμ 很大,说明函数像一个深深的漏斗。
3. "二次函数三明治"与条件数 κ\kappaκ
当一个函数同时满足 μ\muμ-强凸 和 LLL-平滑时,奇妙的事情发生了:对于曲线上的任意一点 x0x_0x0,整个函数 f(x)f(x)f(x) 都被完美地夹在两个二次函数之间:
下界 (由 μ 决定)≤f(x)≤上界 (由 L 决定)\text{下界 (由 } \mu \text{ 决定)} \le f(x) \le \text{上界 (由 } L \text{ 决定)}下界 (由 μ 决定)≤f(x)≤上界 (由 L 决定)
这时候,我们引入优化理论中最重要的一个指标------条件数(Condition Number,κ\kappaκ) :
κ=Lμ\kappa = \frac{L}{\mu}κ=μL
- 因为上界的弯曲程度必然大于等于下界,所以 κ≥1\kappa \ge 1κ≥1。
- 当 κ≈1\kappa \approx 1κ≈1 时 (即 L≈μL \approx \muL≈μ):这两个抛物面几乎重合,原函数的等高线是一个完美的圆 。此时,最简单的梯度下降法只需 1 步就能直接指望圆心(极小值)。
- 当 κ≫1\kappa \gg 1κ≫1 时 (即 LLL 很大,μ\muμ 很小):上界很窄,下界很宽。原函数的等高线是一个极其狭长的椭圆(就像我们上一节看到的 Rosenbrock 香蕉谷)。这时候梯度下降法会疯狂震荡,必须依靠像 L-BFGS 这样的高级算法或者动量(Momentum)机制来拯救。
4. 交互式可视化:调节你的"三明治"
为了真切地看到 LLL 和 μ\muμ 是如何"夹击"原函数的,生成了一个 1D 函数的交互式可视化组件。可以拖动点 x0x_0x0 观察上下界的移动,并调整 LLL 和 μ\muμ 的值来看看它们对边界松紧的影响。
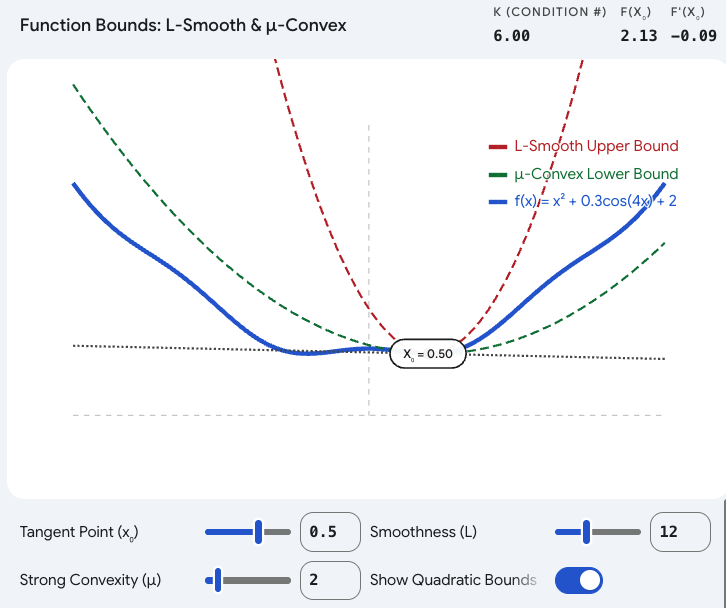
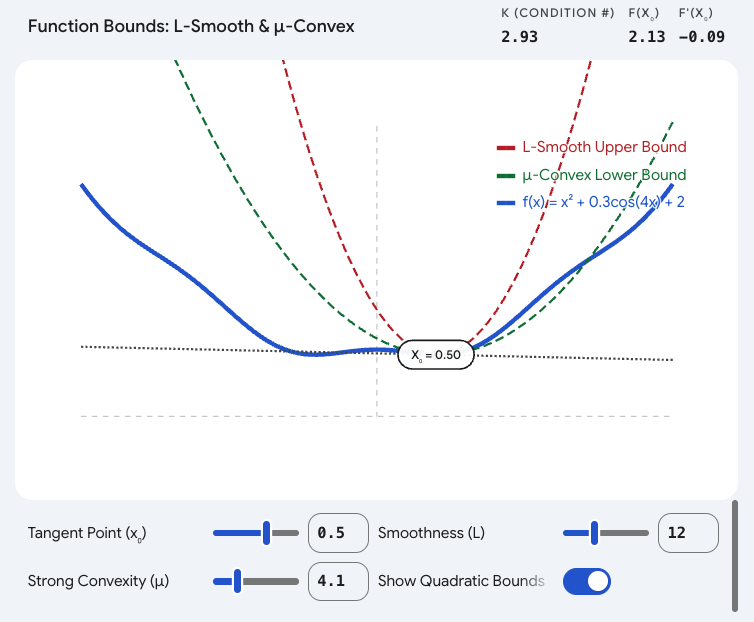
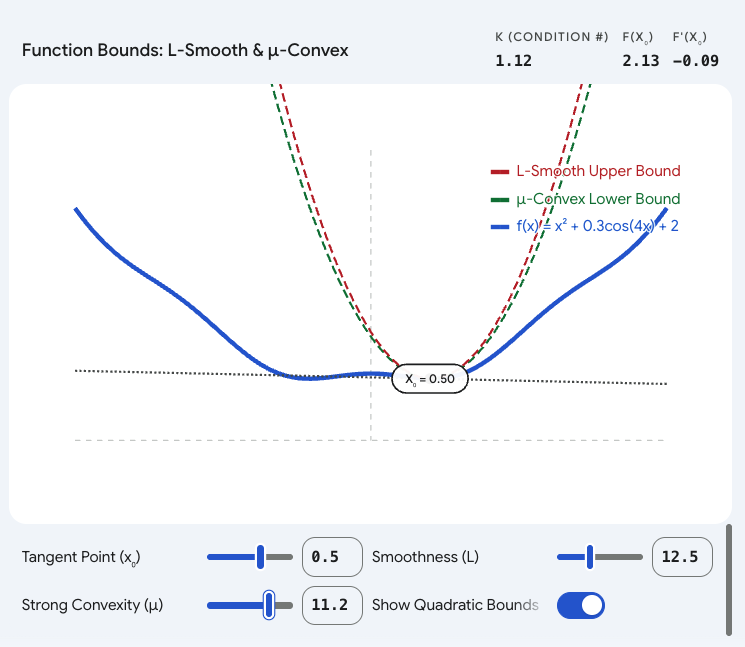
通过这个可视化,我们能明白为什么研究人员在设计优化算法时,总是力求证明他们的算法能在"有限的 κ\kappaκ 值"下快速收敛------因为 κ\kappaκ 就是地形恶劣程度的终极量化指标。
我们现在就褪去直观的比喻,穿上严谨的数学外衣,用形式化(Formal)的语言来彻底拆解这两个在优化理论中占据统治地位的假设。
在开始之前,我们假设目标函数 f:Rn→Rf: \mathbb{R}^n \rightarrow \mathbb{R}f:Rn→R 至少是一阶连续可导的。
1. 形式化定义:LLL-平滑 (LLL-Smoothness)
定义 :如果一个函数 f(x)f(x)f(x) 是 LLL-平滑的,意味着它的梯度 ∇f(x)\nabla f(x)∇f(x) 是 Lipschitz 连续 的,且 Lipschitz 常数为 L>0L > 0L>0。
数学公式 :对于定义域内的任意 x,y∈Rnx, y \in \mathbb{R}^nx,y∈Rn,都满足:
∥∇f(x)−∇f(y)∥≤L∥x−y∥\|\nabla f(x) - \nabla f(y)\| \le L \|x - y\|∥∇f(x)−∇f(y)∥≤L∥x−y∥
等价引理(下降引理 / 二次上界) :
由上述定义,通过泰勒展开和微积分基本定理,我们可以推导出一个在算法分析中极其常用的等价不等式:
f(y)≤f(x)+∇f(x)T(y−x)+L2∥y−x∥2f(y) \le f(x) + \nabla f(x)^T(y - x) + \frac{L}{2}\|y - x\|^2f(y)≤f(x)+∇f(x)T(y−x)+2L∥y−x∥2
解释:这表示函数 fff 在任意点 yyy 的值,永远不会超过在点 xxx 处展开的、曲率(二阶导)为 LLL 的二次函数。
2. 形式化定义:μ\muμ-强凸 (μ\muμ-Strong Convexity)
定义 :普通的凸函数只要求函数图像在切线之上。而 μ\muμ-强凸要求函数不仅在切线之上,还要在一个开口向上的抛物面之上。
数学公式 :对于定义域内的任意 x,y∈Rnx, y \in \mathbb{R}^nx,y∈Rn,且常数 μ>0\mu > 0μ>0,满足:
f(y)≥f(x)+∇f(x)T(y−x)+μ2∥y−x∥2f(y) \ge f(x) + \nabla f(x)^T(y - x) + \frac{\mu}{2}\|y - x\|^2f(y)≥f(x)+∇f(x)T(y−x)+2μ∥y−x∥2
等价的一阶导数形式 :
(∇f(x)−∇f(y))T(x−y)≥μ∥x−y∥2(\nabla f(x) - \nabla f(y))^T(x - y) \ge \mu \|x - y\|^2(∇f(x)−∇f(y))T(x−y)≥μ∥x−y∥2
解释:这意味着随着 xxx 和 yyy 的距离拉开,它们的梯度方向必须以至少 μ\muμ 的速率发生偏转(即函数必须保持一定的弯曲程度,不能变得平坦)。
3. 为什么需要有这样的假设?
在理论计算机科学和最优化数学中,如果你不给函数加上约束,算法的表现是无法被数学证明的。这两个假设分别锁死了一个方向的极端情况。
为什么需要 LLL-平滑?(为了限制步伐,保证"必定下降")
- 对抗梯度爆炸 :如果没有 LLL-平滑假设,函数的梯度可能会在极短的距离内发生剧烈突变(例如接近绝对值函数 y=∣x∣y = |x|y=∣x∣ 在原点的情况,或者极度震荡的函数)。
- 确保学习率的存在 :在梯度下降 xt+1=xt−α∇f(xt)x_{t+1} = x_t - \alpha \nabla f(x_t)xt+1=xt−α∇f(xt) 中,如果你不知道梯度变化有多快,你就不知道学习率 α\alphaα 该设多小。有了 LLL-平滑的二次上界定理,我们可以严格证明:只要学习率 α≤1L\alpha \le \frac{1}{L}α≤L1,函数值 f(x)f(x)f(x) 就一定会严格单调下降,绝不会因为步子迈得太大而跨过极小值导致发散。
为什么需要 μ\muμ-强凸?(为了指明终点,保证"必定到达且迅速")
- 消除平坦区域(鞍点/平缓山谷) :普通的凸函数可以是完全平坦的(比如盘子的底部)。在完全平坦的区域,梯度 ∇f(x)=0\nabla f(x) = 0∇f(x)=0,算法会停滞不前,或者收敛速度无限慢。μ>0\mu > 0μ>0 强行规定了函数有一个明确的最低点 x∗x^*x∗。
- 提供强制的吸引力 :它在数学上保证了距离最优解的误差与梯度的范数成正比(即 ∥∇f(x)∥2≥2μ(f(x)−f(x∗))\|\nabla f(x)\|^2 \ge 2\mu(f(x) - f(x^*))∥∇f(x)∥2≥2μ(f(x)−f(x∗)),这被称为 PL 不等式)。这意味着只要你还没到终点,梯度就绝对不会消失为 0,总有一个足够大的力量把你往最优解拉。
终极威力:指数级收敛(Linear Convergence)
当一个函数同时满足 LLL-平滑和 μ\muμ-强凸时,整个优化问题就被关进了一个完美的数学牢笼里(条件数 κ=L/μ\kappa = L/\muκ=L/μ)。
在这种完美的假设下,数学家可以严格证明,普通的梯度下降法的误差会以**几何级数(在优化中称为线性收敛)**缩减:
∥xt−x∗∥2≤(1−μL)t∥x0−x∗∥2\|x_t - x^*\|^2 \le \left(1 - \frac{\mu}{L}\right)^t \|x_0 - x^*\|^2∥xt−x∗∥2≤(1−Lμ)t∥x0−x∗∥2
这意味着,每多迭代一步,误差就会稳稳地按比例 (1−μ/L)(1 - \mu/L)(1−μ/L) 缩小。如果没有这两个假设,普通的梯度下降通常只能达到极其缓慢的次线性收敛(例如 O(1/t)O(1/t)O(1/t))。
为了将这种"严丝合缝的数学约束"直观化,可以通过下面的交互组件,滑动参数 LLL 和 μ\muμ,观察这两个二次函数边界是如何把目标函数死死"夹"在中间的。
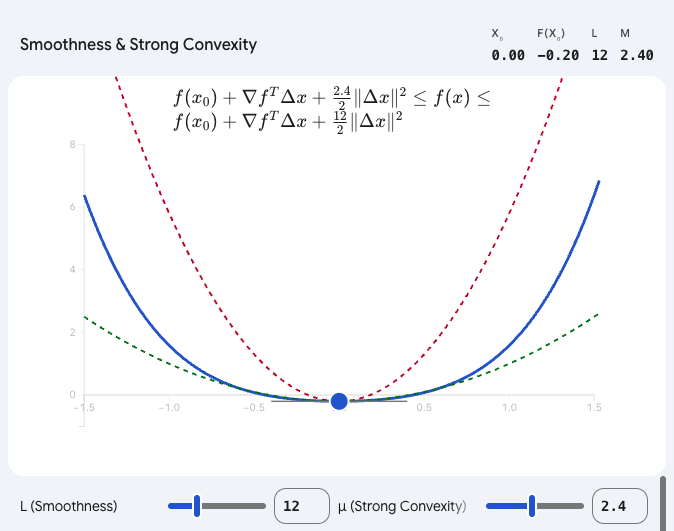
理解了这两个假设,你就掌握了阅读顶级机器学习会议(如 NeurIPS, ICML)中优化算法理论证明的钥匙。你想看看我是如何利用这两个不等式,用简单的几行代数推导,严格证明出梯度下降法的收敛速度公式的吗?
1. 我们想证明什么?
简单来说,是为了给梯度下降法(Gradient Descent)开具一张"法律效力级别的保证书"。
在深度学习或机器学习中,我们经常是"试探性"地调参,跑一跑看能不能收敛。但在纯数学和优化理论中,数学家们不能靠"试",他们需要严谨地回答两个问题:
- 它一定会走到谷底吗?(会不会在一个地方无限打转,或者直接发散?)
- 如果能走到,到底需要走多少步?(收敛速度有多快?)
在 LLL-平滑和 μ\muμ-强凸这两个"完美地形"假设下,我们需要严丝证明:梯度下降法不仅一定会收敛,而且是以一种极度可控、极其高效的方式收敛。
这个证明之所以堪称经典,是因为它完美地展示了数学的对称美:LLL-平滑(上限)保证了每次迭代"能下降多少",而 μ\muμ-强凸(下限)保证了"距离终点还有多远"。两者一夹击,收敛速度的公式就自然而然地流淌出来了。
我们这就用最简洁的代数步骤,来推导目标函数值 f(xt)f(x_t)f(xt) 到最优值 f(x∗)f(x^*)f(x∗) 的距离是如何成比例缩小的。
证明如下:
前提准备
假设我们在使用标准的梯度下降法(Gradient Descent):
xt+1=xt−η∇f(xt)x_{t+1} = x_t - \eta \nabla f(x_t)xt+1=xt−η∇f(xt)
其中 η\etaη 是学习率。为了保证不迈过头,我们取 LLL-平滑允许的最大安全学习率:η=1L\eta = \frac{1}{L}η=L1。
第一步:利用 LLL-平滑(证明"每走一步,函数值必定下降")
根据 LLL-平滑的等价二次上界公式,我们将 xt+1x_{t+1}xt+1 也就是 (xt−η∇f(xt))(x_t - \eta \nabla f(x_t))(xt−η∇f(xt)) 代入进去:
f(xt+1)≤f(xt)+∇f(xt)T(xt+1−xt)+L2∥xt+1−xt∥2f(x_{t+1}) \le f(x_t) + \nabla f(x_t)^T (x_{t+1} - x_t) + \frac{L}{2}\|x_{t+1} - x_t\|^2f(xt+1)≤f(xt)+∇f(xt)T(xt+1−xt)+2L∥xt+1−xt∥2
把 xt+1−xt=−η∇f(xt)x_{t+1} - x_t = -\eta \nabla f(x_t)xt+1−xt=−η∇f(xt) 替换进去:
f(xt+1)≤f(xt)−η∥∇f(xt)∥2+L2η2∥∇f(xt)∥2f(x_{t+1}) \le f(x_t) - \eta \|\nabla f(x_t)\|^2 + \frac{L}{2} \eta^2 \|\nabla f(x_t)\|^2f(xt+1)≤f(xt)−η∥∇f(xt)∥2+2Lη2∥∇f(xt)∥2
代入我们的安全学习率 η=1L\eta = \frac{1}{L}η=L1:
f(xt+1)≤f(xt)−1L∥∇f(xt)∥2+12L∥∇f(xt)∥2f(x_{t+1}) \le f(x_t) - \frac{1}{L} \|\nabla f(x_t)\|^2 + \frac{1}{2L} \|\nabla f(x_t)\|^2f(xt+1)≤f(xt)−L1∥∇f(xt)∥2+2L1∥∇f(xt)∥2
f(xt+1)≤f(xt)−12L∥∇f(xt)∥2f(x_{t+1}) \le f(x_t) - \frac{1}{2L} \|\nabla f(x_t)\|^2f(xt+1)≤f(xt)−2L1∥∇f(xt)∥2
接着,我们在不等式两边同时减去全局最优解的值 f(x∗)f(x^*)f(x∗),得到进度公式 :
f(xt+1)−f(x∗)≤f(xt)−f(x∗)−12L∥∇f(xt)∥2------ (式 1)f(x_{t+1}) - f(x^*) \le f(x_t) - f(x^*) - \frac{1}{2L} \|\nabla f(x_t)\|^2 \quad \text{------ (式 1)}f(xt+1)−f(x∗)≤f(xt)−f(x∗)−2L1∥∇f(xt)∥2------ (式 1)
【直观含义】:这一步证明了,只要梯度 ∥∇f(xt)∥\|\nabla f(x_t)\|∥∇f(xt)∥ 不为0,我们距离最优解的误差就一定会减少。
第二步:利用 μ\muμ-强凸(证明"只要还没到终点,梯度就足够大")
根据 μ\muμ-强凸的下界公式,对于任意的点 yyy 和当前的迭代点 xtx_txt,都有:
f(y)≥f(xt)+∇f(xt)T(y−xt)+μ2∥y−xt∥2f(y) \ge f(x_t) + \nabla f(x_t)^T(y - x_t) + \frac{\mu}{2}\|y - x_t\|^2f(y)≥f(xt)+∇f(xt)T(y−xt)+2μ∥y−xt∥2
注意看不等式的右边,这是一个关于 yyy 的二次函数。我们可以通过配方法(或者对 yyy 求导等于0),轻易求出这个二次函数的最小值在 y−xt=−1μ∇f(xt)y - x_t = -\frac{1}{\mu}\nabla f(x_t)y−xt=−μ1∇f(xt) 时取得。
把这个最小值的条件代回右边,得到右边的最小可能值:
f(y)≥f(xt)−12μ∥∇f(xt)∥2f(y) \ge f(x_t) - \frac{1}{2\mu} \|\nabla f(x_t)\|^2f(y)≥f(xt)−2μ1∥∇f(xt)∥2
既然这个不等式对任何 yyy 都成立,那么对于全局最低点 y=x∗y = x^*y=x∗ 自然也成立:
f(x∗)≥f(xt)−12μ∥∇f(xt)∥2f(x^*) \ge f(x_t) - \frac{1}{2\mu} \|\nabla f(x_t)\|^2f(x∗)≥f(xt)−2μ1∥∇f(xt)∥2
稍微移项整理一下,我们就得到了著名的 PL 不等式 (Polyak-Lojasiewicz Inequality) :
∥∇f(xt)∥2≥2μ(f(xt)−f(x∗))------ (式 2)\|\nabla f(x_t)\|^2 \ge 2\mu (f(x_t) - f(x^*)) \quad \text{------ (式 2)}∥∇f(xt)∥2≥2μ(f(xt)−f(x∗))------ (式 2)
【直观含义】:这一步证明了,你当前距离最优解有多远(右边),你的脚下就至少有多陡(左边)。它打破了"平坦区域"的幻想。
第三步:合体!见证奇迹的时刻
现在,我们把【式 2】(梯度的下界)无情地代入到【式 1】(下降的进度)中。
把 ∥∇f(xt)∥2\|\nabla f(x_t)\|^2∥∇f(xt)∥2 替换掉:
f(xt+1)−f(x∗)≤f(xt)−f(x∗)−12L2μ(f(xt)−f(x∗))f(x_{t+1}) - f(x^*) \le f(x_t) - f(x^*) - \frac{1}{2L} \left 2\\mu (f(x_t) - f(x\^\*)) \\rightf(xt+1)−f(x∗)≤f(xt)−f(x∗)−2L12μ(f(xt)−f(x∗))
提取公因式 (f(xt)−f(x∗))(f(x_t) - f(x^*))(f(xt)−f(x∗)):
f(xt+1)−f(x∗)≤(1−μL)(f(xt)−f(x∗))f(x_{t+1}) - f(x^*) \le \left(1 - \frac{\mu}{L}\right) (f(x_t) - f(x^*))f(xt+1)−f(x∗)≤(1−Lμ)(f(xt)−f(x∗))
Q.E.D.(证明完毕)
小结
只需这寥寥几步,我们就得到了优化理论中最核心的结论:
每一次迭代,当前误差都会乘以一个严格小于 1 的因子 (1−μL)\left(1 - \frac{\mu}{L}\right)(1−Lμ) 。
如果我们将条件数记为 κ=Lμ\kappa = \frac{L}{\mu}κ=μL,这个因子就是 (1−1κ)\left(1 - \frac{1}{\kappa}\right)(1−κ1)。
- 这意味着误差在以指数级(几何级数)衰减!在优化领域,这被称为线性收敛(Linear Convergence)。
- 如果山谷非常狭长(κ\kappaκ 很大,比如 1000),每次误差只会缩小 (1−0.001)=0.999(1 - 0.001) = 0.999(1−0.001)=0.999,你需要走很多步。
- 如果山谷是个完美的圆碗(κ=1\kappa = 1κ=1),那么因子变为 (1−1)=0(1 - 1) = 0(1−1)=0,一步直接收敛到最优解!
这个优美的证明框架是现代机器学习算法分析的基石。
上面证明的最后那个公式体现了什么?
我们来把这个公式 f(xt+1)−f(x∗)≤(1−μL)(f(xt)−f(x∗))f(x_{t+1}) - f(x^*) \le \left(1 - \frac{\mu}{L}\right) (f(x_t) - f(x^*))f(xt+1)−f(x∗)≤(1−Lμ)(f(xt)−f(x∗)) 像解剖一样拆开来看:
- f(xt)−f(x∗)f(x_t) - f(x^*)f(xt)−f(x∗) :这是你当前所处位置的高度,距离真正的谷底高度,也就是**"当前的误差(Error)"**。
- f(xt+1)−f(x∗)f(x_{t+1}) - f(x^*)f(xt+1)−f(x∗):这是你往前迈了一步之后,距离真正的谷底高度,也就是**"下一步的误差"**。
- (1−μL)\left(1 - \frac{\mu}{L}\right)(1−Lμ) :这是一个缩水比例(打折系数) 。因为 L≥μ>0L \ge \mu > 0L≥μ>0,所以这个括号里的数字永远是一个 介于 0 到 1 之间的小数。
【大白话翻译】 :
这个公式体现的是一种**"按比例强制缩水"的机制。它告诉你,无论你现在离谷底有多远,只要你迈出一步,你的误差就会 至少被打上一个 (1−μL)\left(1 - \frac{\mu}{L}\right)(1−Lμ) 的折扣**。
举个具体的数字例子:
假设一座山的曲率参数是 L=10L = 10L=10,μ=1\mu = 1μ=1。
那么缩水比例就是 (1−110)=0.9\left(1 - \frac{1}{10}\right) = 0.9(1−101)=0.9。
- 如果你当前距离谷底的高度(误差)是 1000 米。
- 走一步后,你的误差最多只剩 1000×0.9=9001000 \times 0.9 = 9001000×0.9=900 米。
- 再走一步,最多只剩 900×0.9=810900 \times 0.9 = 810900×0.9=810 米。
- 走了 10 步后,误差剩 1000×(0.9)10≈3481000 \times (0.9)^{10} \approx 3481000×(0.9)10≈348 米。
- 走了 100 步后,误差剩 1000×(0.9)100≈0.021000 \times (0.9)^{100} \approx 0.021000×(0.9)100≈0.02 米。
3. 这个公式在理论上的三大重要意义
- 揭示了"线性收敛"的本质 :
在优化领域,像上面这种"每步打个固定折扣"(呈现指数级衰减)的收敛速度,被称为线性收敛(Linear Convergence)。这是一种非常非常优秀的收敛速度。只要地形满足条件,梯度下降法就具有这种令人安心的指数级衰减能力。 - 解释了为什么"峡谷地形"极难优化 :
我们之前提到过条件数 κ=Lμ\kappa = \frac{L}{\mu}κ=μL。
如果地形极度狭长恶劣(比如 L=1000,μ=1L=1000, \mu=1L=1000,μ=1),那么缩水比例就是 (1−0.001)=0.999\left(1 - 0.001\right) = 0.999(1−0.001)=0.999。这意味着你每走一步,误差只减少了千分之一。此时,普通的梯度下降法就像蜗牛爬行一样慢,这就从数学上解释了为什么在复杂的神经网络中,我们需要更高级的优化器。 - 完美地形(κ=1\kappa=1κ=1)下的一步登天 :
如果地形是一个完美的圆碗(L=μL = \muL=μ),那么缩水比例 (1−μL)=0\left(1 - \frac{\mu}{L}\right) = 0(1−Lμ)=0。公式变成了:下一步的误差 ≤0\le 0≤0。这意味着,普通的梯度下降法只需要 1步,就能精准命中靶心,误差瞬间归零!
总结一下,这个公式就像是梯度下降法的"车速表",它用最简洁的代数关系,把**地形的恶劣程度(LLL 和 μ\muμ)与算法的收敛速度(打折比例)**完美地绑定在了一起。
深度学习中常用的动量(Momentum)机制 ,能把这个缩水比例强行从 (1−μL)\left(1 - \frac{\mu}{L}\right)(1−Lμ) 压缩到更小的 (1−μL)\left(1 - \sqrt{\frac{\mu}{L}}\right)(1−Lμ ),从而实现大幅度加速