这篇主要讲一下数据的储存。数据抓取下来了,之前都是用 txt 保存,或者用其他一些方式保存,但更多的时候我们不会这样去保存的。一般保存的话,我们会储存到数据库当中,或者储存表格。储存数据的时候又会有很多方法,有时候是列表数据,有时候是字典数据,这两个分别都用什么方法来储存到表格中去,这就是本篇要介绍的。数据抓取下来了,之后好好地存储进表格当中,而不是随便找一个 txt 文件去存。
储存有各种方式,不同的数据在储存的时候略有差别。先介绍列表存储。
列表存储
pandas 存法
先定义一个列表,这个是整理出来的数据。这个 data 数据包含了名字,年龄,所在地,性别这些信息。这种数据我们想存成表格数据的话,我们应该怎么来做?
python
data = [
['冒冒', 30, '上海', '男'],
['丫丫', 20, '上海', '女'],
['老倪', 19, '长春', '女'],
['老刘', 10, '上海', '女'],
['华华', 8, '济南', '女']
]需要引入一下 Pandas。为什么要这样写嘞?简写。也不是非得要这样写。功能是,每次我们要 pandas.上什么,就可以用 pd.上。这东西就相当于给它起了个别名。
python
import pandas as pd但是这个 pandas 不是一个内建库,用之前需要安装。pandas 对版本也没有特别严格的要求,装镜像源就可以。如果之前没有配置三方库的镜像源,直接使用这个代码下载的就会快一些。
bash
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple这个库引入进来之后,接下来我们去保存刚刚的列表。
原生数据转换
如果我们想用 pandas 去操作这个列表的话,第一件事就是必须要把它转化成 pandas 可以操作的对象。所有的三方库都是这样来的。一个陌生的三方库,想要操作这种原生的列表、字典这种数据的话,很多情况下都是操作不了的,所以要想个办法把这坨数据变成 pandas 可操作的对象。
pandas 当中有一个 DataFrame 函数,它会帮我们把这坨数据进行整理,整理成 pandas 可操作对象。把 data 拿过来。
python
pd.DataFrame(data)既然是保存,就要想如何把这个数据存储到表格中去。存的时候,我们当然非常希望能存成这样。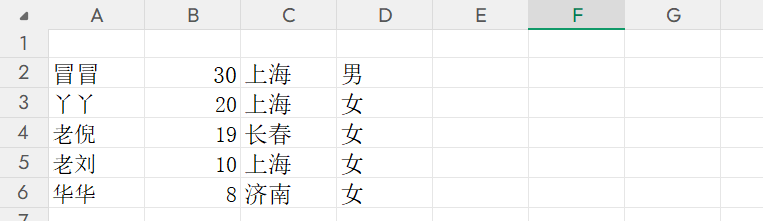
更多的时候,得有个抬头。姓名、年龄、所在地、性别。
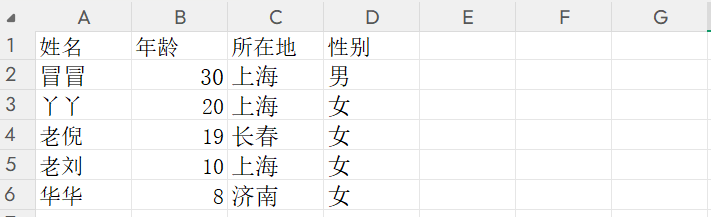
有一个抬头去存的话,才知道数据对应的是什么。所以在存的时候也要考虑把姓名、年龄、所在地、性别也都加上去,所以在这里可以指定表头。用 columns。表头一般可以是列表,可以是元组,列表是更喜欢用的,我们把数据复制过来并且转换一下,要加单引号,最后赋值给 columns。
python
pd.DataFrame(data, columns=['姓名', '年龄', '所在地', '性别'])这样就相当于给每一列的数据都安排了表头,这里就自动生成了个对象,起个名叫 df 对象。
python
df = pd.DataFrame(data, columns=['姓名', '年龄', '所在地', '性别'])打印一下看看。其实 df 对象就是 pandas 的一个对象。目前为止完整代码如下。
python
data = [
['冒冒', 30, '上海', '男'],
['丫丫', 20, '上海', '女'],
['老倪', 19, '长春', '女'],
['老刘', 10, '上海', '女'],
['华华', 8, '济南', '女']
]
# pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
df = pd.DataFrame(data, columns=['姓名', '年龄', '所在地', '性别'])
print(df)我们去执行一下,这是运行后的结果。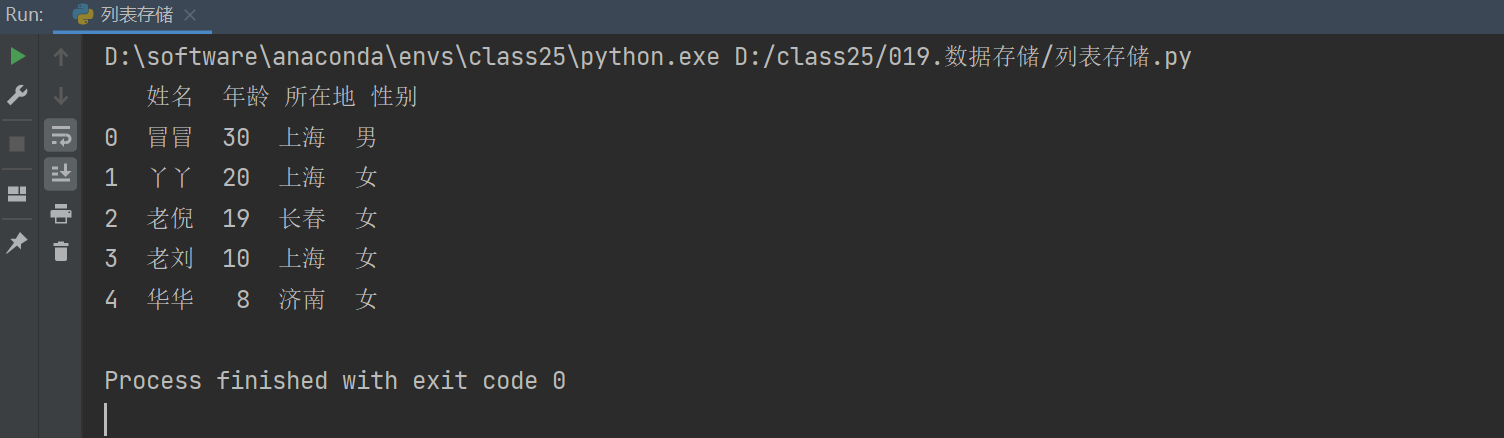
现在它已经变成了对象数据,观察一下,它现在有序号,对应的姓名,年龄,地点,性别,都对应着数据,全都对应上来了。对应上来之后,这个数据我们可以直接进行存储。
保存为 Excel 数据
存储的时候要选择存成什么样的数据,比如我要保存成 Excel 数据。直接 df.上to_excel就可以了。
这里面还要传一个参数,就是你要保存成什么样的文件。保存成 '表格数据.xlsx' 这个格式。
python
# 保存成 Excel 数据
df.to_excel('表格数据.xlsx')当然,01234序号不想要,还有个参数叫 index,设置 index=False,它就不会把序号加上去了。
python
# 保存成 Excel 数据
df.to_excel('表格数据.xlsx', index=False)目前,完整代码如下。
python
data = [
['冒冒', 30, '上海', '男'],
['丫丫', 20, '上海', '女'],
['老倪', 19, '长春', '女'],
['老刘', 10, '上海', '女'],
['华华', 8, '济南', '女']
]
# pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
df = pd.DataFrame(data, columns=['姓名', '年龄', '所在地', '性别'])
print(df)
# 保存成 Excel 数据
df.to_excel('表格数据.xlsx', index=False)右键,执行一下。发现报错。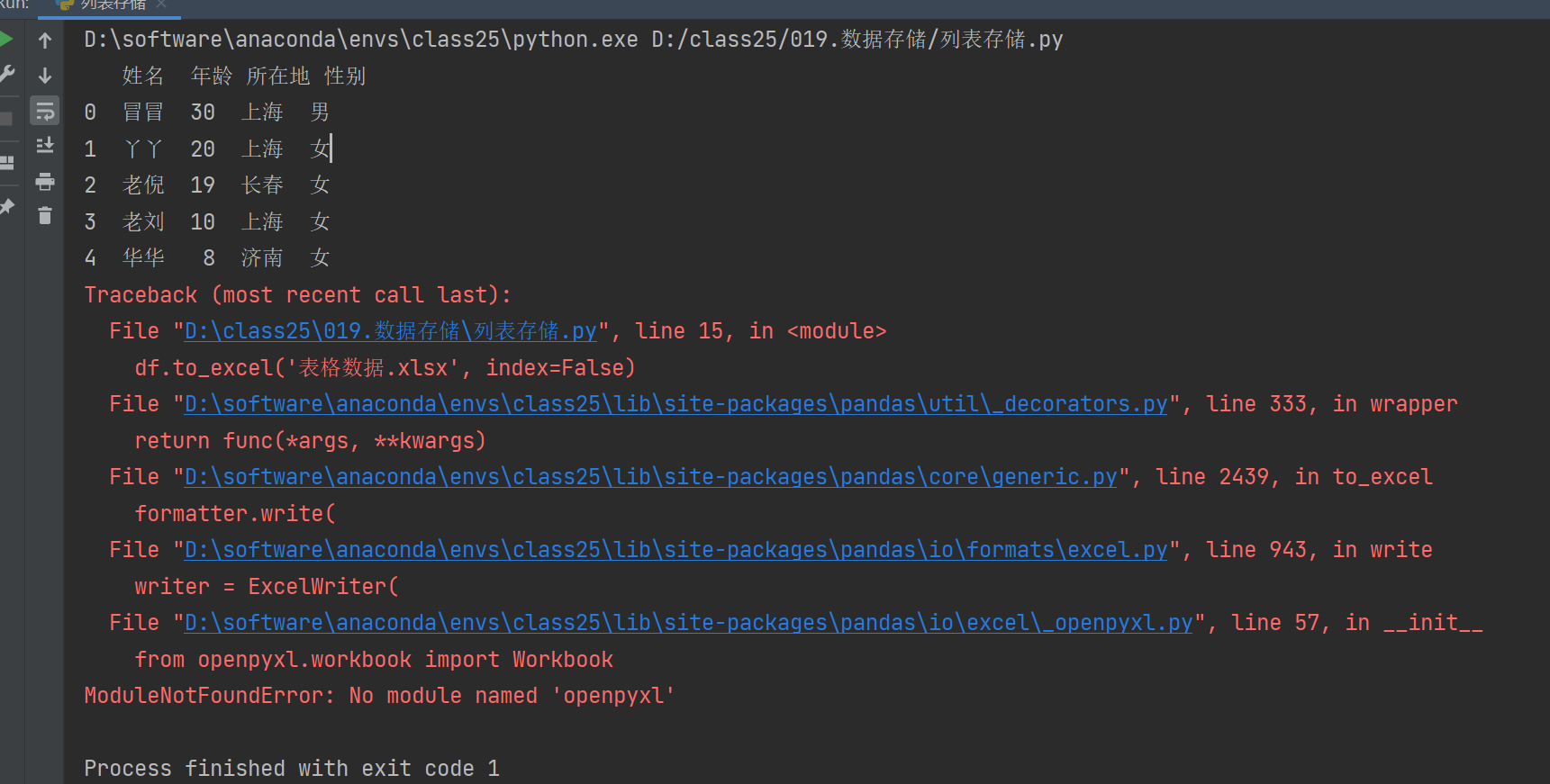
这是因为缺少 openpyxl 模块,pandas 需要它来创建和写入 Excel 文件。
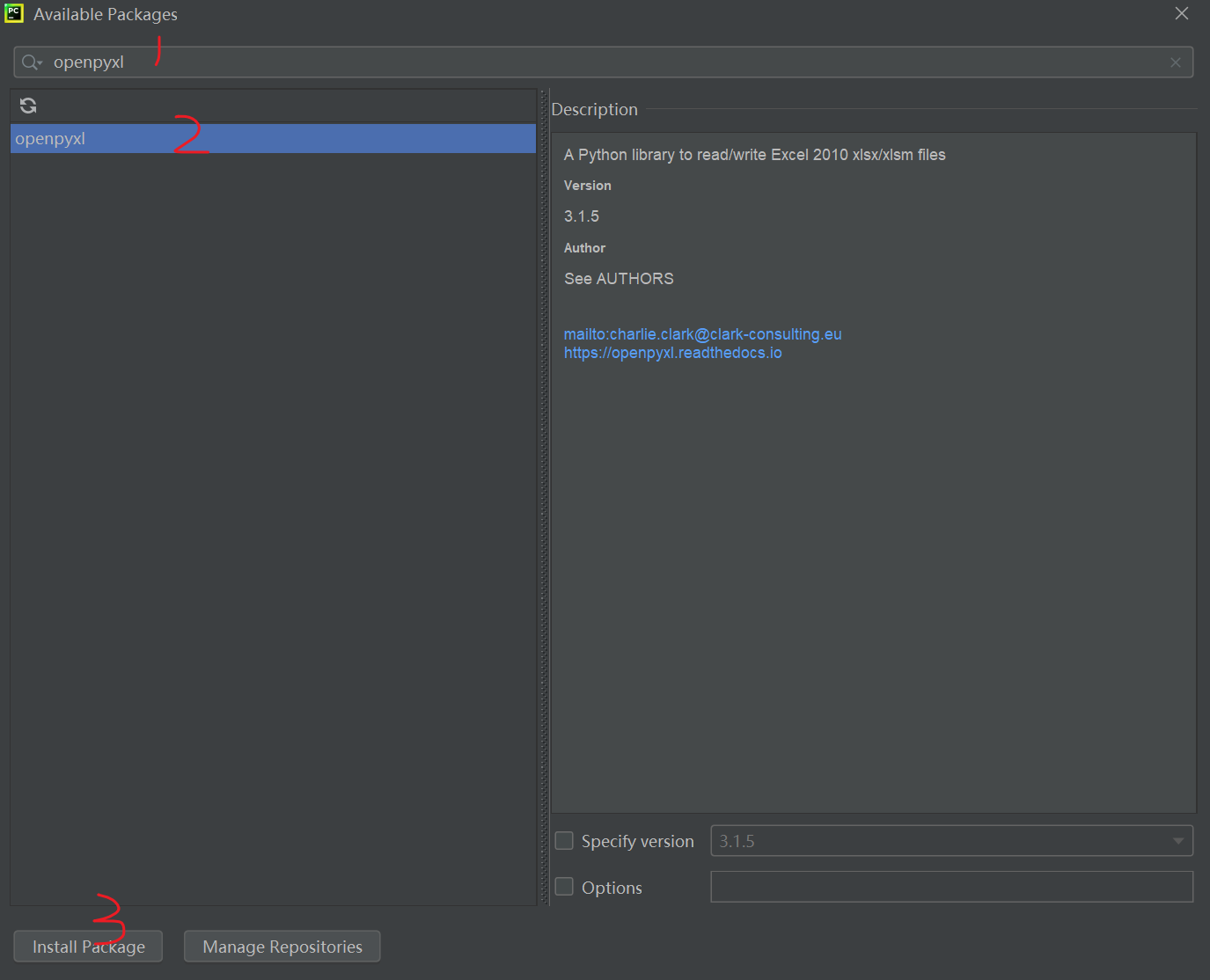
1、打开 PyCharm 的设置(File -> Settings)
2、找到 Project: class25 -> Python Interpreter,确认当前解释器是 class25 环境
3、点击 "+" 号添加包
4、搜索 openpyxl 并安装
5、安装成功后,会有个"successful"的绿色提示。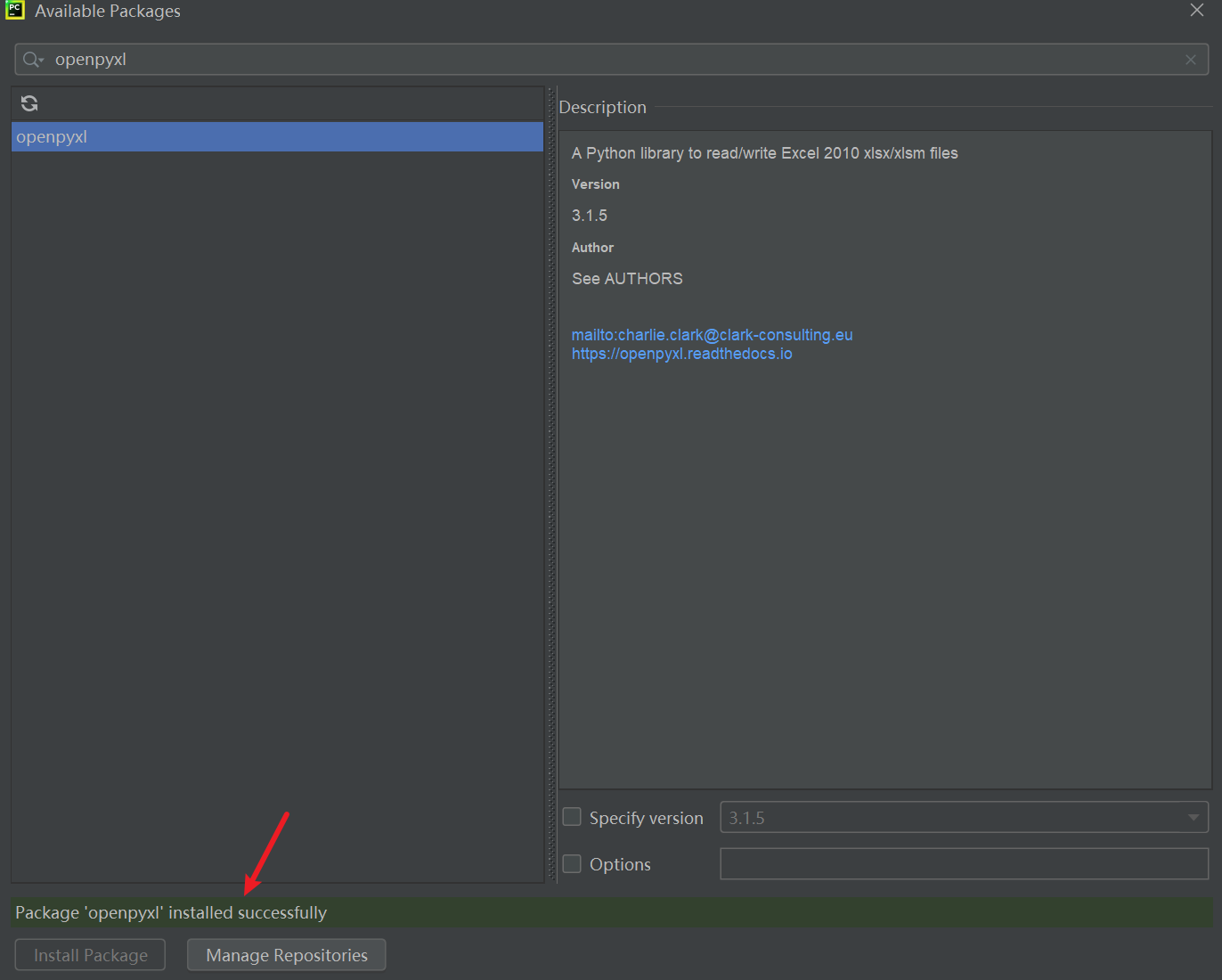
我们把刚刚的代码再右键执行一下试试。成功啦!!!在这儿!!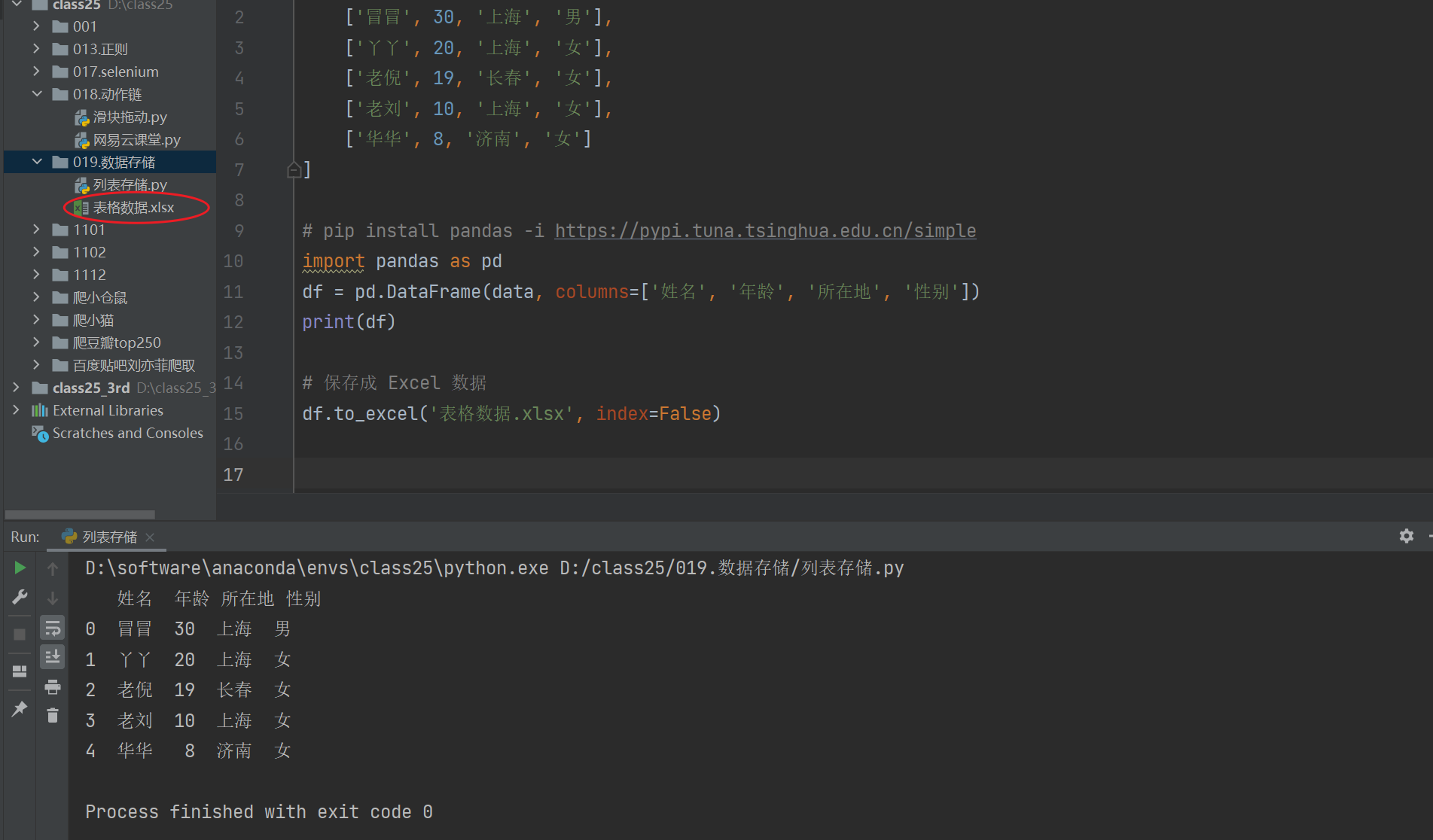
双击,在右下角会预览出来,可以瞅瞅,发现就是我们希望的那种形式。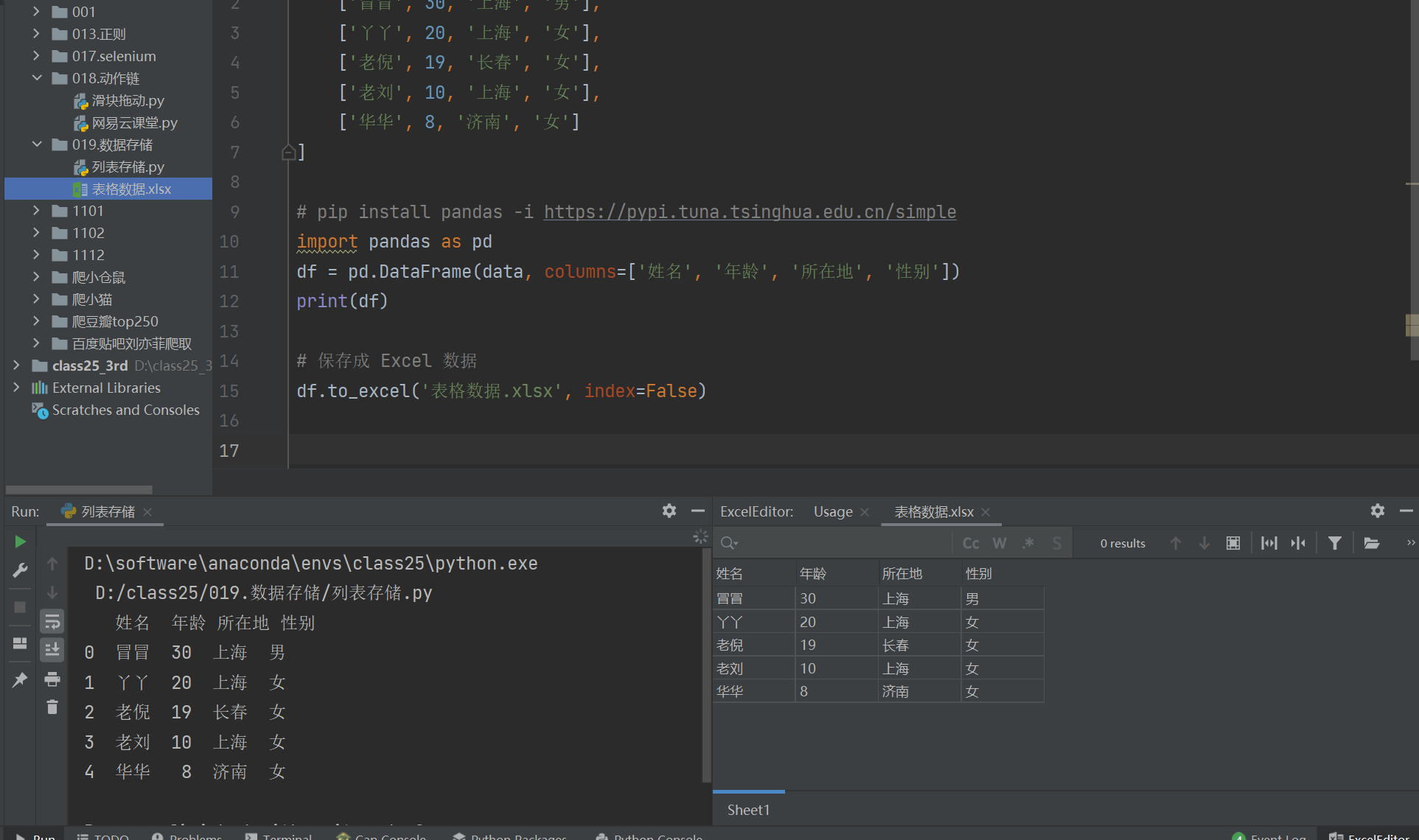
我们去项目对应的路径里打开看看,是这个效果。非常之完美。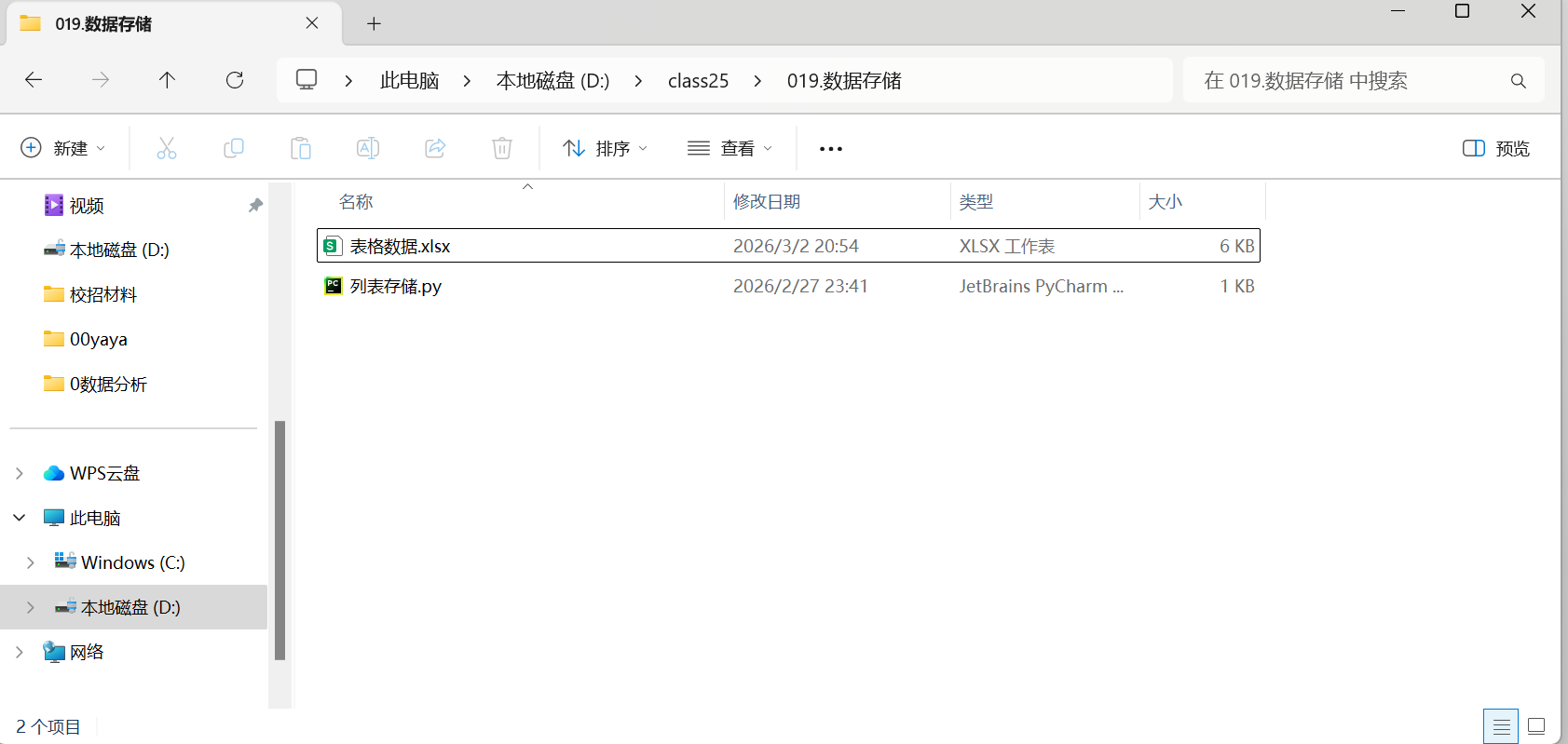
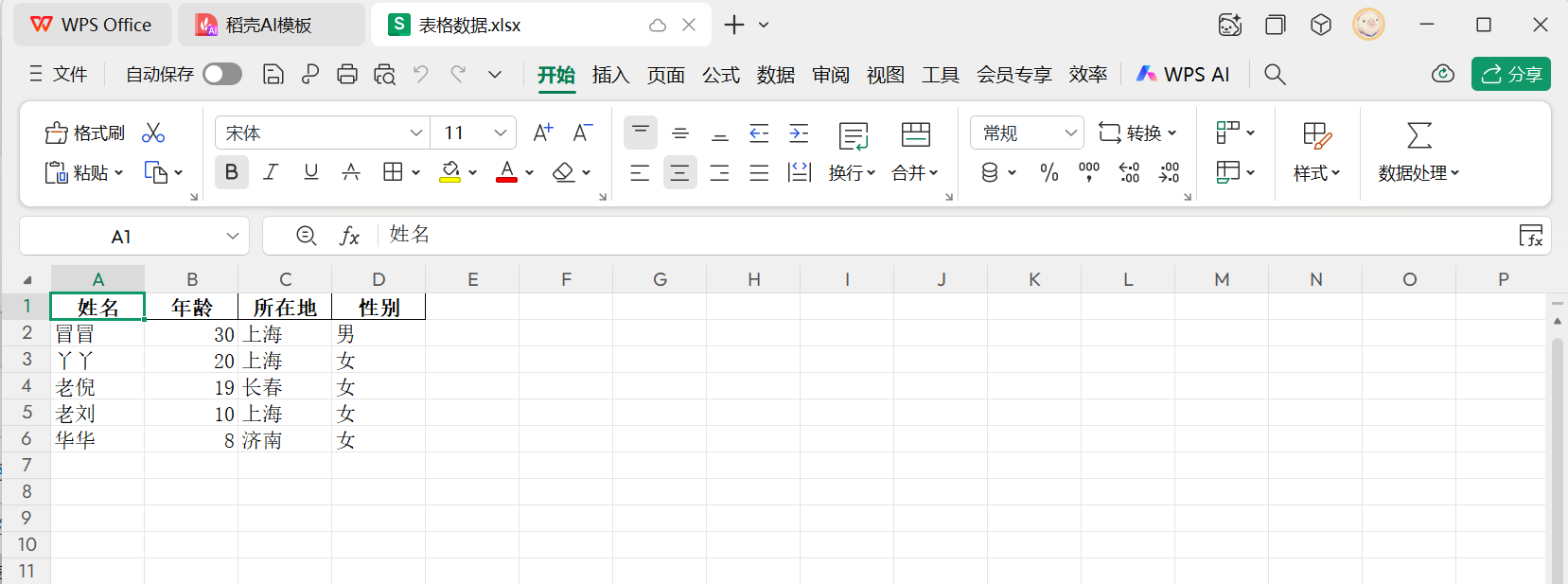
比较方便的,以前都是用普通文本去存,普通文本也没有很好的格式,看起来比较乱一点。现在可以用表格去存储了,表格点开更方便我们数据分析。这个时候就可以结合到 finebi、tebleau、powerbi 这几个工具中去。finebi 可以直接导入我们存好的表格数据。
还有一种情况,就是我们保存为 csv 的格式。
保存为 csv 数据
和上一句的代码差不多的,函数为 df.to_csv(),文件后缀名改为 .csv。
python
# 保存成 csv 数据
df.to_csv('csv文件.csv', index=False)右键运行一下看看。运行成功了,我们可以看到新生成了 csv文件.csv 这个文件。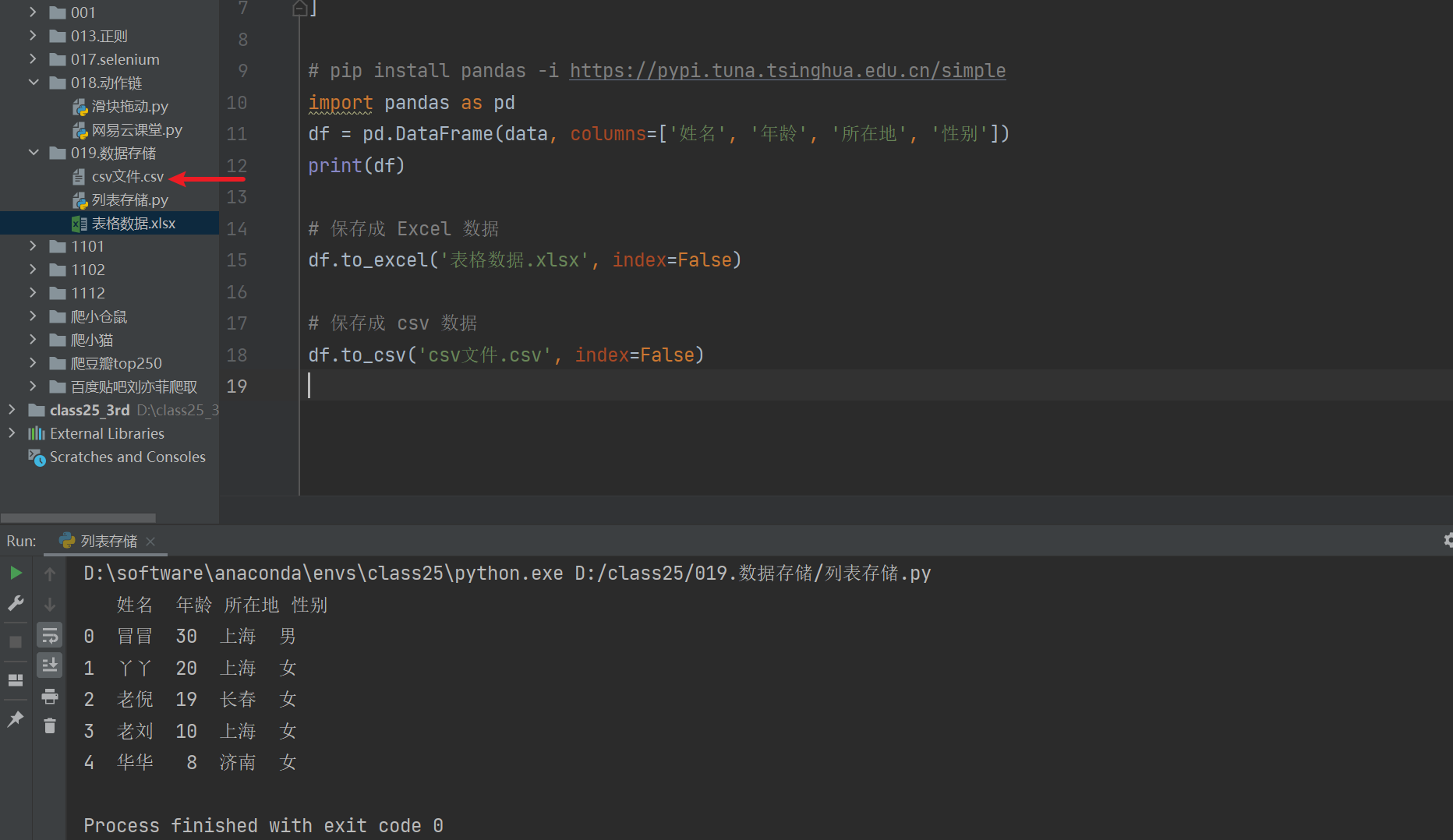
打开瞅瞅。csv 文件就张这个样子,每一个数据都用逗号隔开。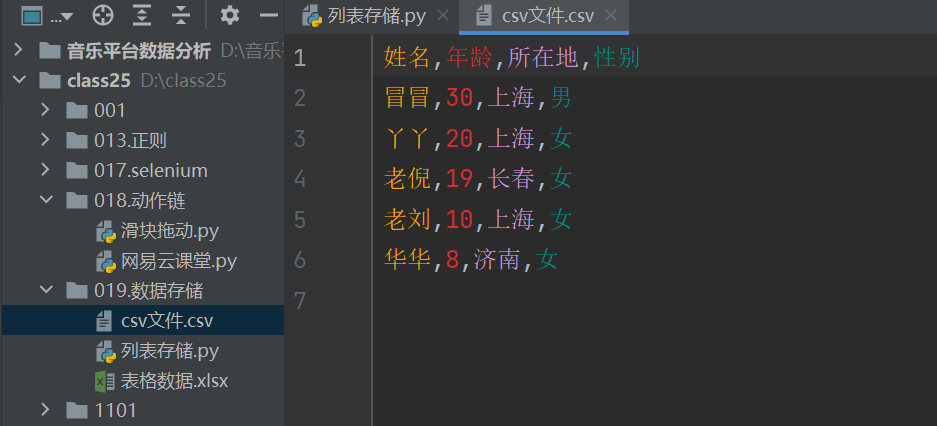
如果使用表格来打开它的话,它是长这个样子的。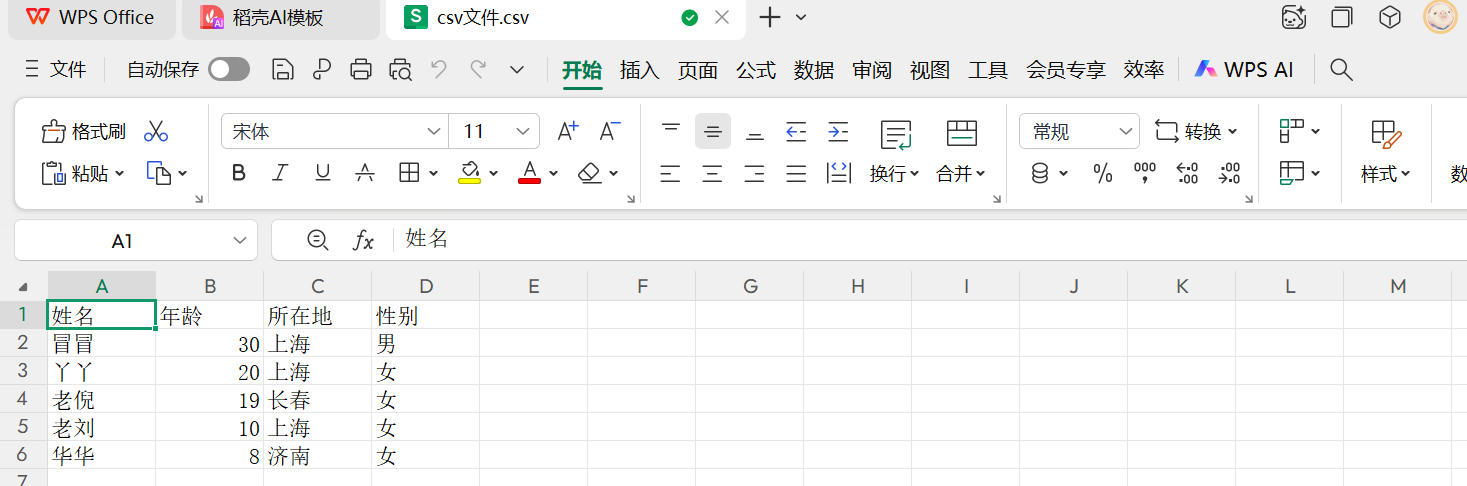
实际上,csv 文件还是逗号隔开的那种更合适一些。我们用 csv 的形式去打开它的话,照样可以拿到里面的数据。以表头的形式是可以取出来的。在后面介绍 pandas 库的时候会去做一些延伸的,本篇只是针对 pandas 存储来介绍讲解。数据就是通过这几种方式去存。除了这几种方式存,还有一种是 MySQL 的存法。先补充一下 Python 和 MySQL 的交互。
Python 与 MySQL 交互
准备工作
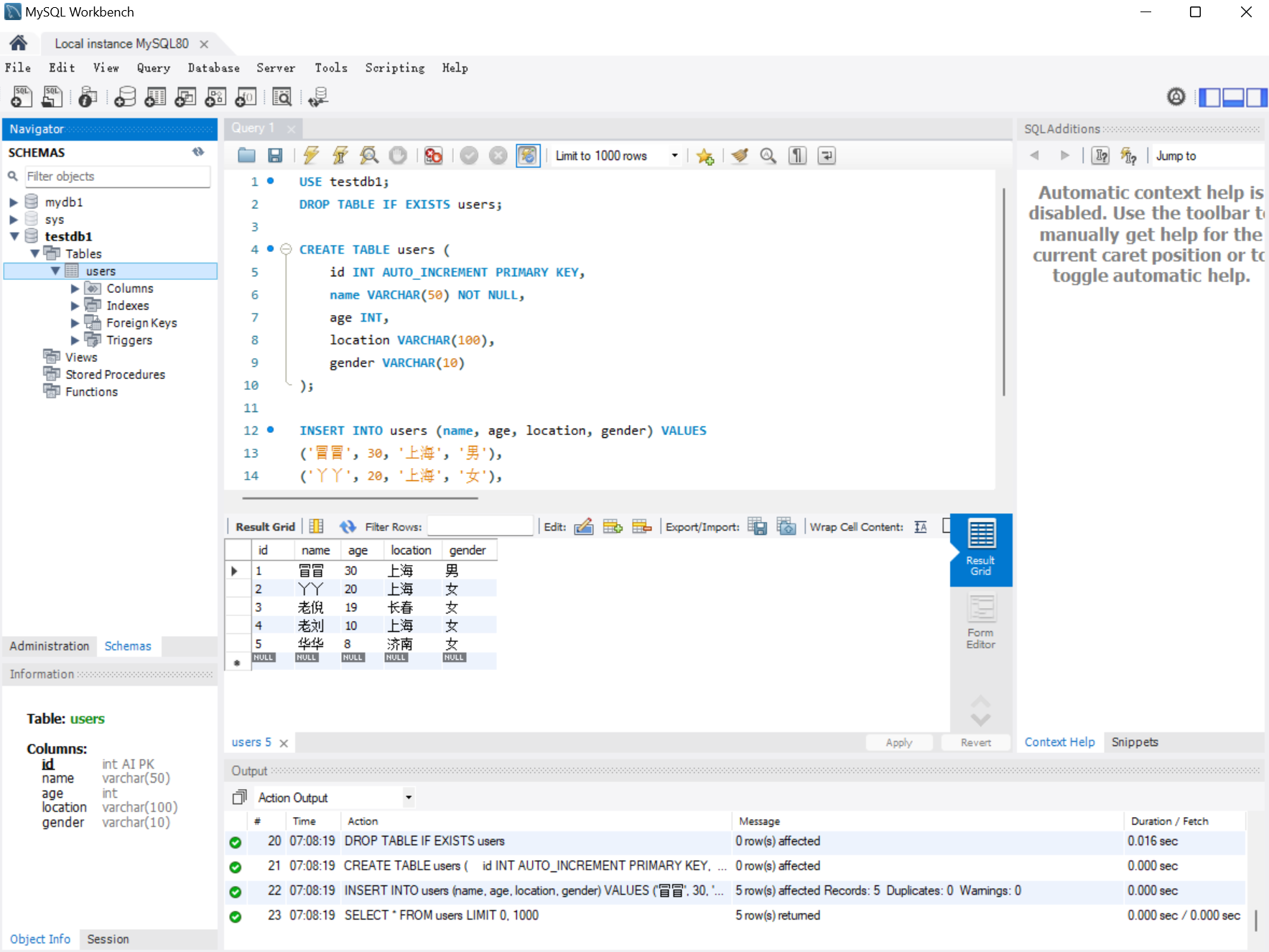
先在 MySQL 的 workbench 中建立好这个表格,将数据写入进去。
sql
USE testdb1;
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
location VARCHAR(100),
gender VARCHAR(10)
);
INSERT INTO users (name, age, location, gender) VALUES
('冒冒', 30, '上海', '男'),
('丫丫', 20, '上海', '女'),
('老倪', 19, '长春', '女'),
('老刘', 10, '上海', '女'),
('华华', 8, '济南', '女');
SELECT * FROM users;执行之后效果如下:
python链接数据库
其实在控制的时候,也不能直接控制,有一个第三方库叫 pymysql,用这个库来控制的。同样的,这个库也是需要去安装的,命令是:pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple这个是清华镜像。
用一用,打开 pycharm,新建一个 .py文件,命名为"Python与MySQL交互"
下载好之后先引入这个库。
python
import pymysql这样还不够,因为要链接它的话,一定要有配置文件。这里可以写一个字典的形式。在开发的时候更多地是写在一个配置文件夹里,而且这个文件夹也不会放到项目当中去的。另外一种做法是直接写成服务器的参数配置,这样就更安全一些。现在先用字典形式写一下。有几个参数,第一是 'host',表示要链接到哪个地方去的。这地方是一定要写的。第二个是端口号 'port',mysql 端口号默认是 3306,也可以去改它但是没必要。端口号有了之后要去连接,所以 'user' 也要告诉它。user 我用的是 root,一般 root 的权限,不会让你远程去连接的,可能还需要改一些配置文件。user 给完了之后还有一个 password 要给的,我的是 123456。再给它一个 'db',db 是库,就是指定的是哪个库,一般都把库给指定了,这里用的是 'testdb1' 库。还要给一个 'charset',charset 是编码格式,有的是 utf8mb4,这是最新的一种语法,这种语法支持的范围会更广一些。现在该给的都已经给了,只剩一个 host,如果用的是远程的服务器,这个地方就要写云服务器的公网IP;还有一种是就在本地,本地用的是'172.0.0.1'。用这个是可以去连接的。
python
# 一定要有配置文件
db_config = {
'host': '172.0.0.1',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb1',
'charset': 'utf8mb4'
}这个配置文件写好之后,怎么去连接它?这个时候就用到了 pymysql 了。
获取连接对象。把配置传进去,由于是字典的形式无法直接读取,用星花的方式拆成键值对就可以了。之前也有提到,不定长的参数里面的未知参数就可以用这种方式去拆。假设这里面所有的东西都能连接上,这里保存成连接对象的话,就应该可以打印出内容来的。这个就是连接。
python
# 获取连接对象
conn = pymysql.connect(**db_config)先连接到数据库,再去创建游标。连接只是第一步,连接之后就要操作数据库里面的数据进行增删改查的。这个操作的对象就是游标。所以接下来的操作是创建游标对象。用连接的对象点上cursor,就创建好了游标对象。
python
# 创建游标对象
cur = conn.cursor()后续所有的操作都是基于它来的,现在我们可以把这个游标对象打印出来看看。目前为止完整代码如下。右键点击运行。
python
# pymysql
# pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymysql
# 一定要有配置文件
db_config = {
'host': '172.0.0.1',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb1',
'charset': 'utf8mb4'
}
# 获取连接对象
conn = pymysql.connect(**db_config)
# 创建游标对象
cur = conn.cursor()
print(cur)运行之后我们发现,已经获取到游标对象了。说明刚刚的步骤都是正确的。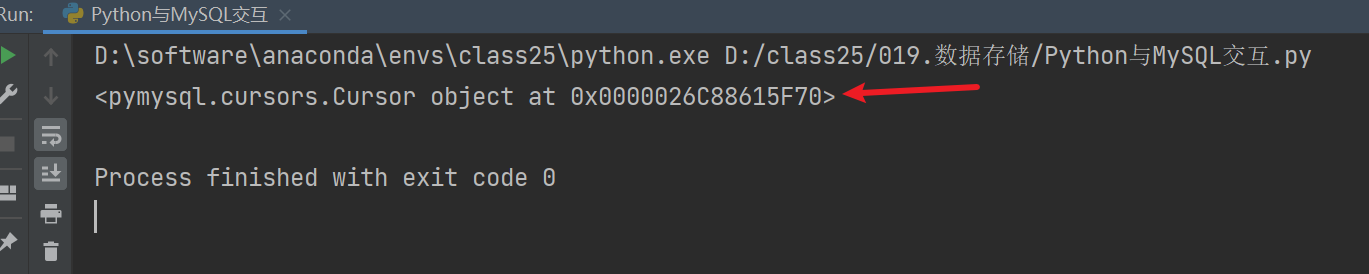
我们创建好这个游标对象之后,就想把 testdb1 里面的对象查询出来。这个地方需要我们会写一下 sql 语句。这里指向的是数据库,但是我们操作的话都是基于表格来操作的。这个地方可以这样去写。
查询
sql 语句拿过来之后,它现在只是一个字符串。然后我们还要去执行它,用游标来执行。把 sql 放到里面来,就可以拿到对象了。我把数据存到了 users 表里,注意里面的语句是表名。
python
sql = 'select * from testdb1.users;'
print(cur.execute(sql))我们可以看到打印出来的是 5,因为有 5 条数据。
如果想看到值的话,最好保存一下数据。我们在执行 execute 之后,所有的参数都在游标对象当中,用 fetchmany 的话是可以打印出所有的数据的。里面要传入数据条数。目前为止所有代码如下,运行一下看看。
python
# pymysql
# pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymysql
# 一定要有配置文件
db_config = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb1',
'charset': 'utf8mb4'
}
# 获取连接对象
conn = pymysql.connect(**db_config)
# 创建游标对象
cur = conn.cursor()
print(cur)
sql = 'select * from testdb1.users;'
cur.execute(sql)
print(cur.fetchmany(5))运行之后我们看到每条数据都打印了出来。
还有一种是打印所有的,fetchall,这个不用传参。
python
# pymysql
# pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymysql
# 一定要有配置文件
db_config = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb1',
'charset': 'utf8mb4'
}
# 获取连接对象
conn = pymysql.connect(**db_config)
# 创建游标对象
cur = conn.cursor()
print(cur)
sql = 'select * from testdb1.users;'
cur.execute(sql)
print(cur.fetchall())我们可以看到效果是一样的,全部都查询到然后打印出来了。
在查询之后我们是要给它关闭的,先关闭游标,再关连接,这个操作一直都得有。这两行代码写到最后。和 MySQL 连接完成了之后,关游标关连接要形成常态化。
python
cur.close()
conn.close()因为我们整个过程中是先建立连接,建立好了之后创建游标的。所以在后面关闭的时候,要先关闭游标,再关闭连接。有点儿像俄罗斯套娃,最开始的时候先打开最外层的,然后打开里面的,在复原的时候,肯定是先关里面小的那个,然后把外面大的给关闭。
sql 不光有查询,我们还可以加点儿数据。
增
增加小玲和小雨的信息。增加两条。python 加多条数据是用元组的形式来存的。还有一个额外的操作,因为 sql 是事务的,事务是所有东西都弄好了之后集中到一起提交的。所以我们增加之后还要把连接提交一下。完整代码如下,我们执行一下。
python
# pymysql
# pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymysql
# 一定要有配置文件
db_config = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb1',
'charset': 'utf8mb4'
}
# 获取连接对象
conn = pymysql.connect(**db_config)
# 创建游标对象
cur = conn.cursor()
print(cur)
# sql = 'select * from testdb1.users;'
sql = "insert into users (name, age, location, gender) VALUES ('小玲', 18, '上海', '女'), ('小雨', 22, '上海', '女')"
# 专门用来执行sql语句
cur.execute(sql)
# 查看查询到的所有的数据
# print(cur.fetchall())
conn.commit()
# 先关游标
cur.close()
# 再关连接
conn.close()发现没有报错。
这时候我们要去 workbench 看一下。
sql
SELECT * FROM users;执行之后我们发现这两行数据已经成功加进去了。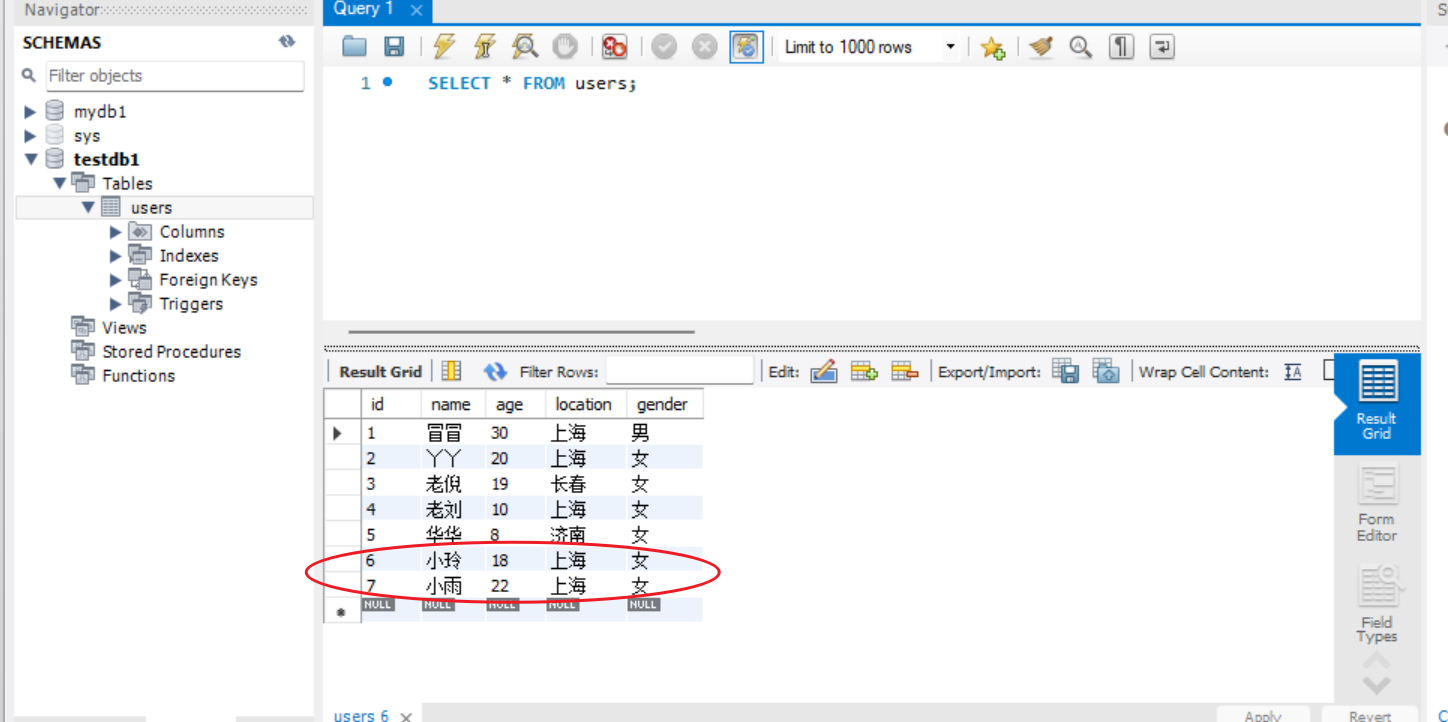
在代码上我们尽可能写的标准一些,更多的时候是用 try 来写。改好的完整代码如下:
python
# pymysql
# pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymysql
# 一定要有配置文件
db_config = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb1',
'charset': 'utf8mb4'
}
# 获取连接对象
conn = pymysql.connect(**db_config)
# 创建游标对象
cur = conn.cursor()
print(cur)
try:
# sql = 'select * from testdb1.users;'
sql = "insert into users (name, age, location, gender) VALUES ('小玲', 18, '上海', '女'), ('小雨', 22, '上海', '女')"
# 专门用来执行sql语句
cur.execute(sql)
except Exception as e:
print(e)
conn.rollback() # 回滚操作
else:
# 查看查询到的所有的数据
# print(cur.fetchall())
conn.commit() # 提交操作
finally:
# 先关游标
cur.close()
# 再关连接
conn.close()如果 try 里面的语句有错误的话,就把它打印出来。一旦真的执行发生了错误之后,会有一个 rollback 的返回。如果没有返回的话,就会用 else,去把它提交。无论提不提交,有没有错,都会有个 finally,最后都要把它关闭掉,先关掉游标再关掉连接。
整体来讲,代码没问题就提交;代码有问题就 rollback 返回回去,不去操作。因为我们在去写这个效果语法的时候,可能会有多条语法同时在执行,有的前面的数据是正常的,但是后面有一个语法它错了,错了我们就希望它要么就全错,就都不提交,要么就都提交,所以我们会用 rollback 搞一个回滚操作。
字典存储
数据不单单只有列表,还有字典。在 pycharm 中新建一个 py 文件,命名为"字典的存储"。
自己定义一个字典,在 python 中,字典会比列表更简单的,表头直接就可以写上了。
python
data = {
'姓名': ['冒冒', '丫丫', '老倪', '老刘', '华华'],
'年龄': [30, 20, 19, 10, 8],
'城市': ['上海', '上海', '长春', '上海', '济南'],
'性别': ['男', '女', '女', '女', '女']
}姓名拿过来,然后一列全是姓名;年龄拿过来,一整列都是年龄等等。字典在存的时候是比列表更方便简单的。用它的时候也是需要引入 pandas 来处理。直接把 data 拿过来就行,列名都不需要了。
python
import pandas as pd
df = pd.DataFrame(data)保存方式和之前一样的,复制粘贴过来就行。把文件名改一下。
python
# 保存成 Excel 数据
df.to_excel('dict_表格数据.xlsx', index=False)
# 保存成 csv 数据
df.to_csv('dict_csv文件.csv', index=False, encoding='utf-8-sig')完整的代码如下,右键点击运行看一看。
python
data = {
'姓名': ['冒冒', '丫丫', '老倪', '老刘', '华华'],
'年龄': [30, 20, 19, 10, 8],
'城市': ['上海', '上海', '长春', '上海', '济南'],
'性别': ['男', '女', '女', '女', '女']
}
import pandas as pd
df = pd.DataFrame(data)
# 保存成 Excel 数据
df.to_excel('dict_表格数据.xlsx', index=False)
# 保存成 csv 数据
df.to_csv('dict_csv文件.csv', index=False, encoding='utf-8-sig')运行成功,右边也生成了两个文件,一个是 excel 文件,一个是 csv 文件。
把文件打开看看,没有任何毛病。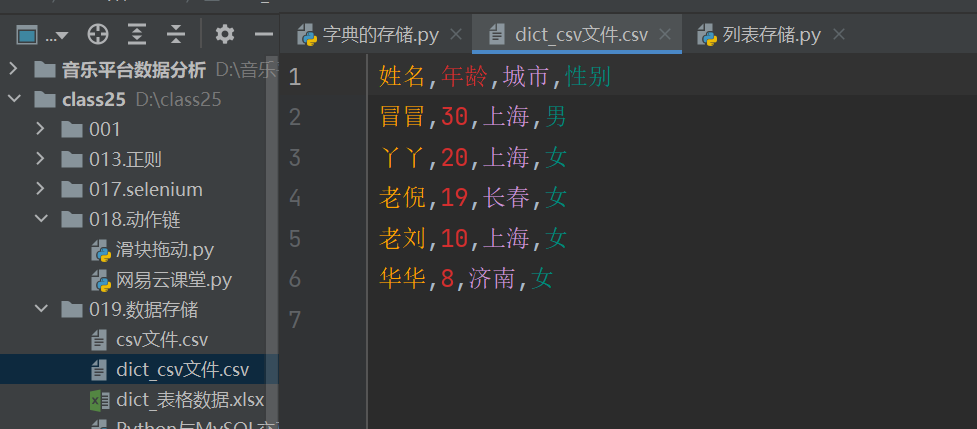
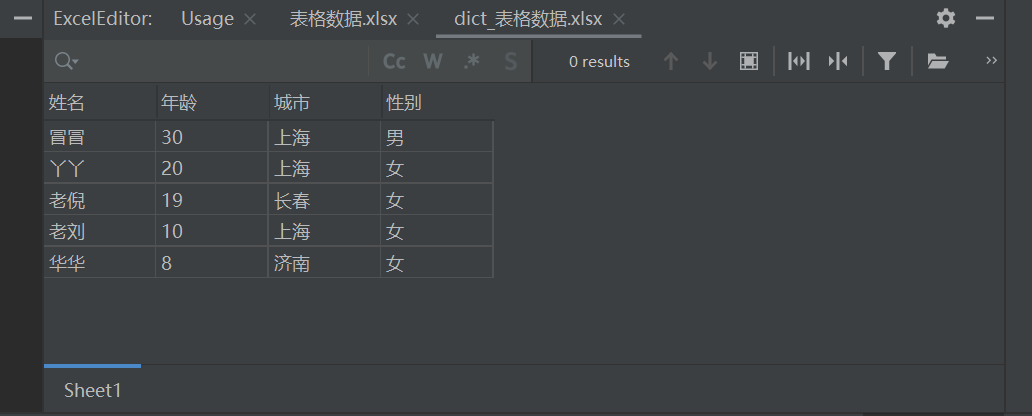
当然前面已经学了怎么用 python 操作数据库,那么想保存数据的话,应该怎么做嘞?我们用字典数据为例,将其通过 python 操作存入数据库中。
存入到数据库
重新再写一个。新建 py 文件,命名为"存入数据库"。然后把代码粘过去。
python
data = {
'姓名': ['冒冒', '丫丫', '老倪', '老刘', '华华'],
'年龄': [30, 20, 19, 10, 8],
'城市': ['上海', '上海', '长春', '上海', '济南'],
'性别': ['男', '女', '女', '女', '女']
}
import pandas as pd
df = pd.DataFrame(data)首先,基于 pandas 这种存法,它需要去配置一些引擎的。是 pandas 里面内置的一些方法。只能使用 sqlalchemy。
安装 sqlalchemy
这个需要先安装。老办法,点击左上角 file,找到设置 settings;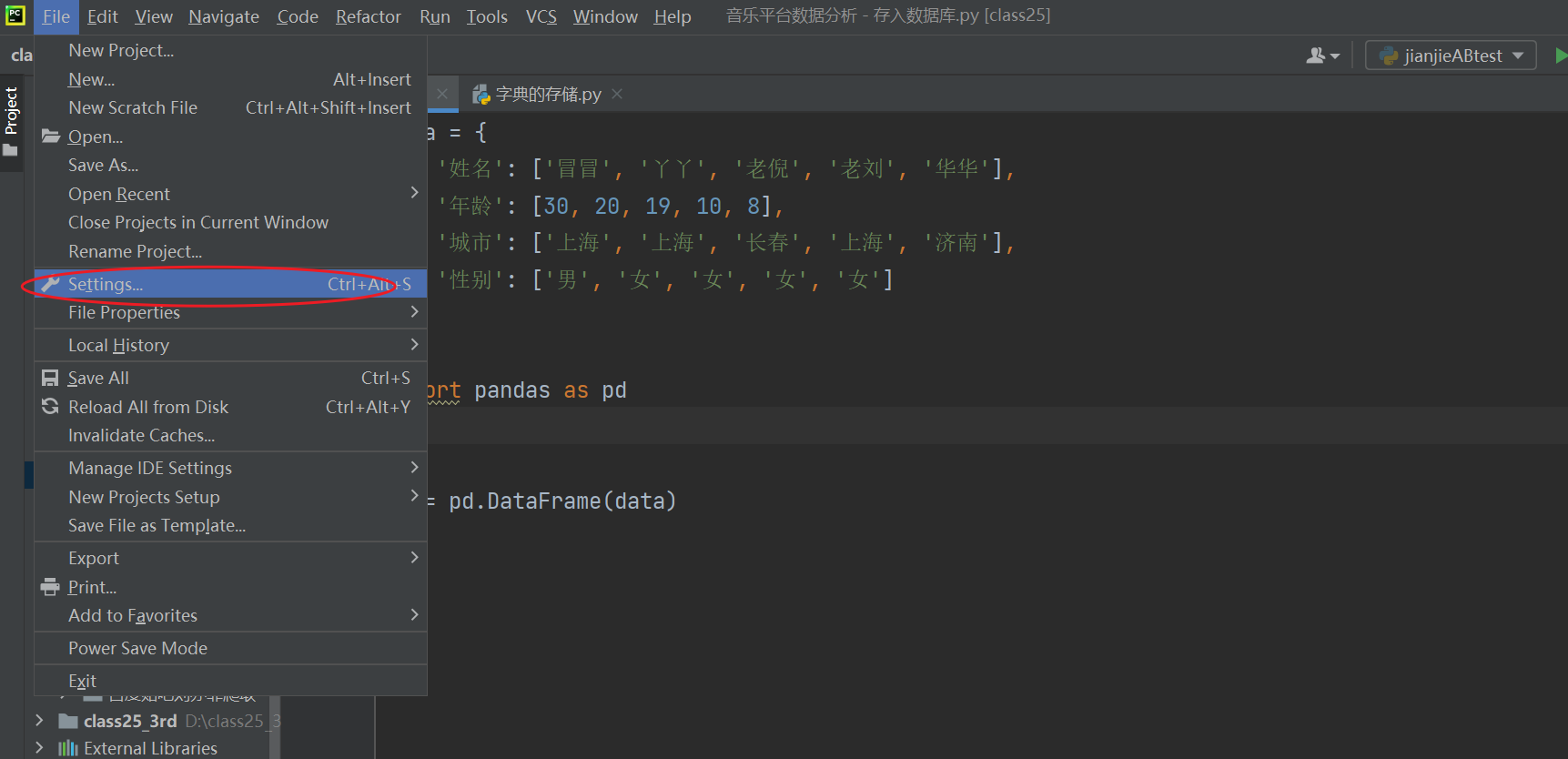
找到当前文件所在项目,点击 + 号;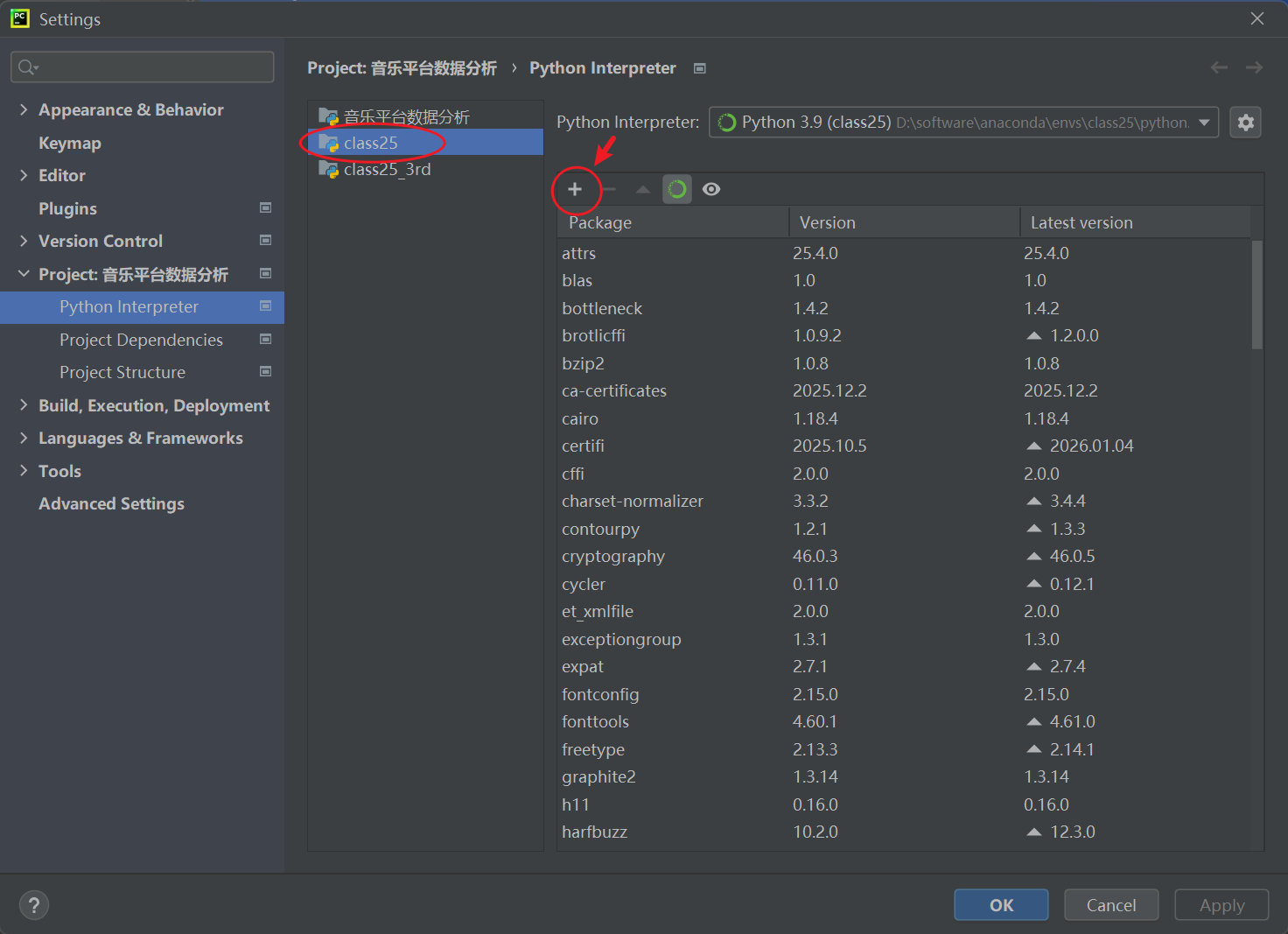
搜索 "sqlalchemy" 并安装。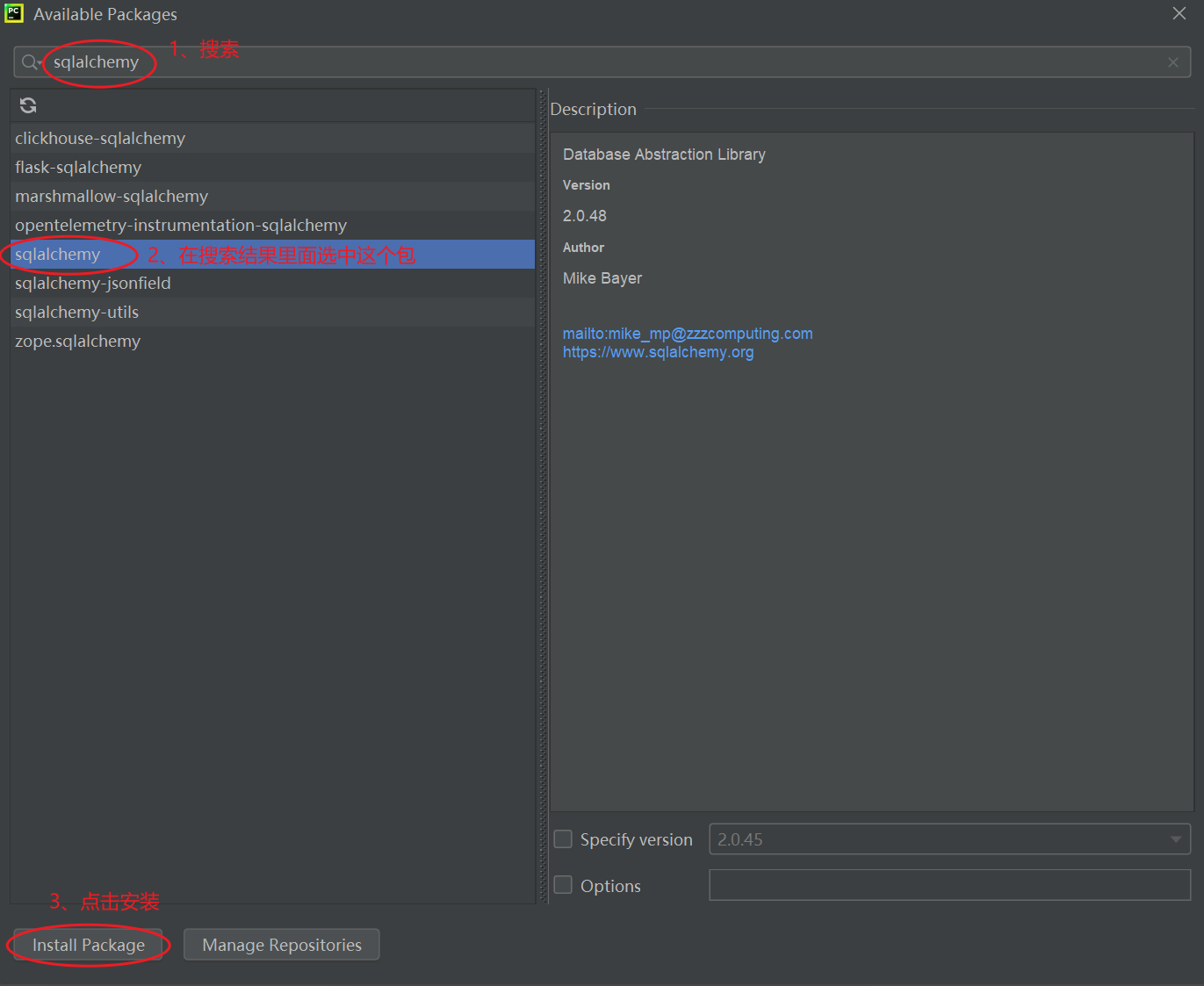
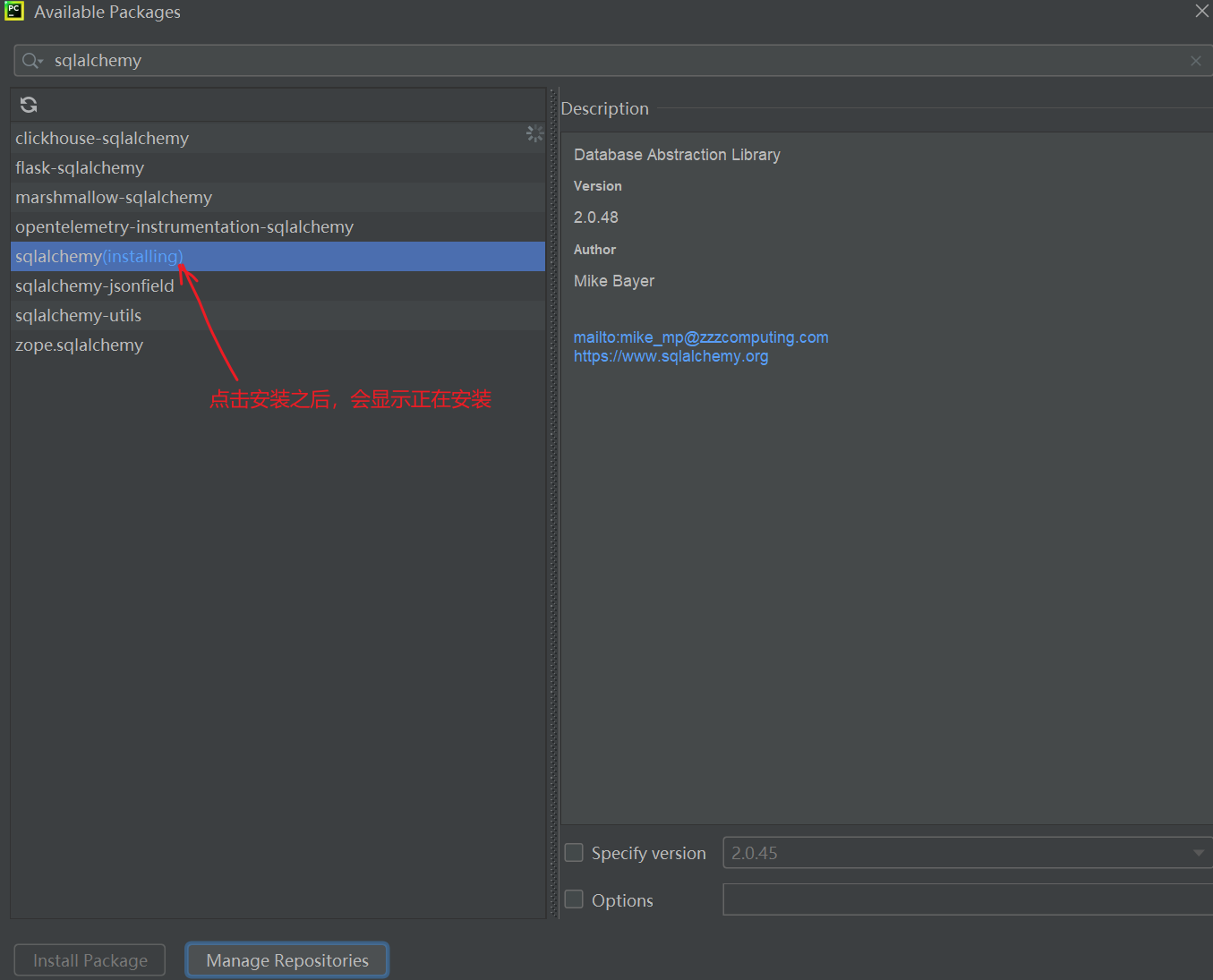
安装成功之后会显示 installing successful。
存储
安装下载好 sqlalchemy 之后,我们就可以去用它里面的引擎了。用它里面的创建引擎。
python
from sqlalchemy import create_engine这是它标准的写法。这个 sqlalchemy 如果往底层找的话,依然使用的是 pymysql。虽然不直接使用 pymysql,间接去使用的话,对我们影响也不大。这个地方把它定义出来之后,我们首先要做的是使用 create_engine() 把它们都连接起来,把它的一些数据都配置好。配置好的话,这里就要写一下配置文件,它的写法是比较固定的,我们使用的是 mysql+pymysql 这个库,这样来连的。它跟网址的访问是差不多的,用双斜杠,然后把名字写上,密码,后面还要@上ip,接上端口号,选定数据库,把这些以一个字符串的形式传过去就可以了。后面是需要把这个对象传到 to_sql 中去的,所以定义好的用 engine 作为对象来接住。
python
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/testdb1')现在只是把数据库连接上了,后面存到哪个表格去也是要指定的,是 name 的写法。还要指定引擎。这个表格有的时候就去存,没有的话需要创建,所以还有个 if 的操作,主键不需要创建的话 index 设置为 False。基本上写成这个样子应该是可以了。
python
df.to_sql(
name='testdb1',
con=engine,
if_exists='replace',
index=False
)完整代码如下,右键运行一下试试。
python
data = {
'姓名': ['冒冒', '丫丫', '老倪', '老刘', '华华'],
'年龄': [30, 20, 19, 10, 8],
'城市': ['上海', '上海', '长春', '上海', '济南'],
'性别': ['男', '女', '女', '女', '女']
}
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/testdb1')
df = pd.DataFrame(data)
df.to_sql(
name='testdb1',
con=engine,
if_exists='replace',
index=False
)我们会发现连上了,并且建立了个新表叫 'testdb1',里面数据就是我们定义好的数据。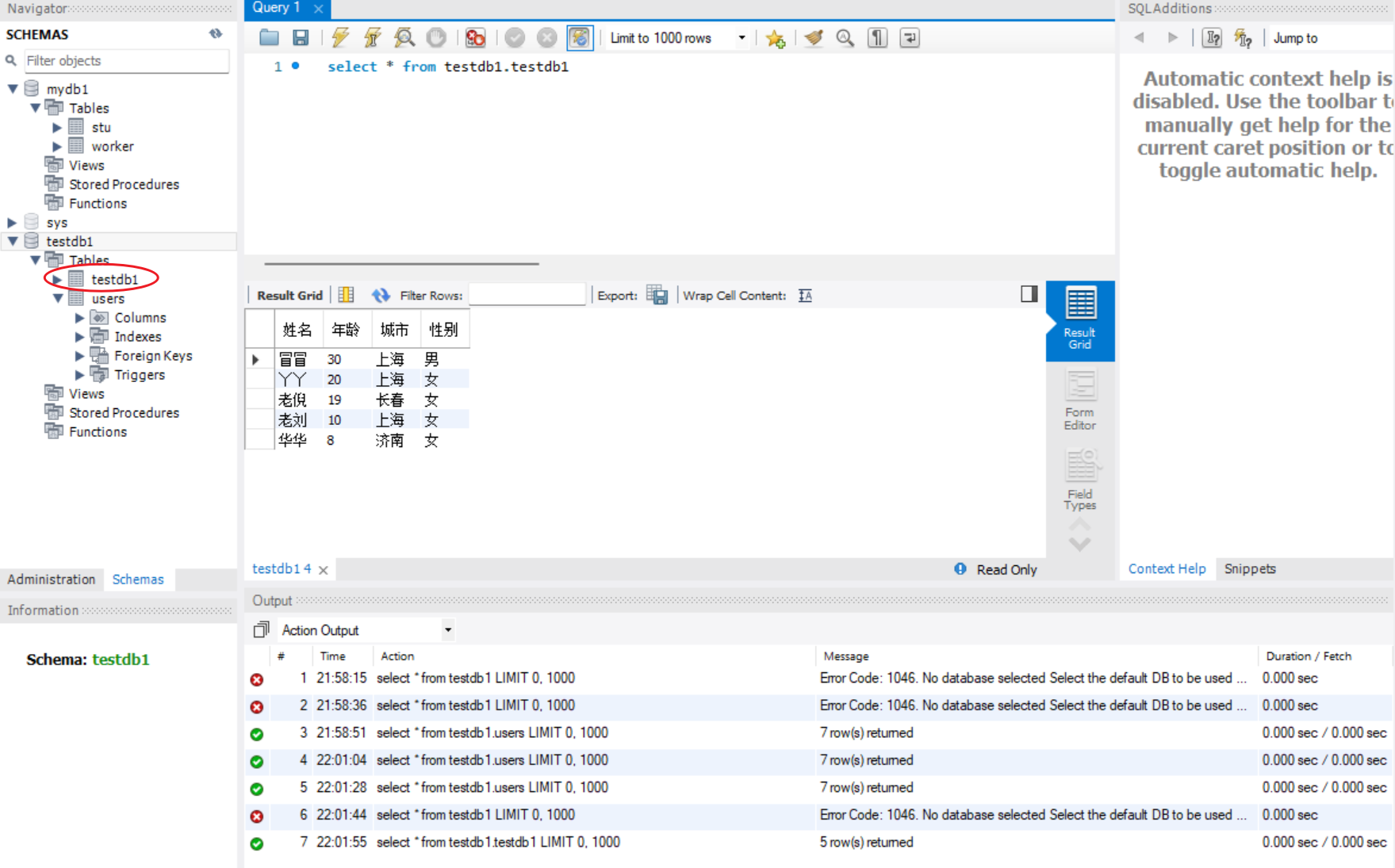
存入数据库的部分就结束啦,如果感觉新建一个文件来存太麻烦,使用本篇中间部分介绍的游标方法存储也是可以的。