很多白领现在所有的工作可以尝试用
AI去实现。首当其冲是我们这些程序猿。有人说,对于软件开发工程师,如果你还没有把90%以上的代码交给AI,那么你可能已经落后了。今天要分享的是,我在尝试用
AI实现自动化的"需求/BUG 的管理和系统更新记录"过程中遇到的问题和解决思路。其中会有一些 AI 编程的最佳实践,希望对你有所帮助。
首先,要明确几个原则:
- 一个上下文窗口尽量只干一件相关的事情 ,如果你用到
/compact大概率是你任务拆分不合格 - Skill 尽量拆分,一个 Skill 只专注于解决一种相关的流程。想要写一个能解决所有流程问题的 Skill 的思路是错误的。
- Skill 和 MCP 不是竞争关系,而是协同利用的关系。MCP 更关注于单个工具的调用,而 Skill 更侧重于流程编排;在 Skill 中可以明确指定调用某一个或多个 MCP。
一、期望的场景和使用方法
理想的自动化闭环是这样的:
- 前端/后端开发同学在 ChatBox 中对 agent 说 "提交代码"后,ai 将提交代码并自动生成变更日志写入数据库。
- 变更日志存在
change_releases表里,可追溯(remark 里记录 git commit ids、Linear issue ids、仓库 remoteUrl)。 - 前端界面直接展示历史变更记录(Markdown 渲染),领导、产品、客户、开发自己都能一眼看懂。
不再需要任何人手动写"更新说明",也不用担心漏记或前后端版本冲突。
二、找一个支持 MCP 的项目需求管理和问题追踪工具(Linear √)
项目需求管理和问题追踪工具是多人研发团队必备的,可能是禅道、ONES或者飞书等。研发人员需要根据需求来开发功能、根据bug单来一个个处理问题、修复bug之后要标记状态;测试根据bug单来跟踪修复状态;项目经理要根据需求项目管理平台来跟踪研发进度...
但在现在,我们需要尝试用AI跑通这一系列的流程。
2.1 为什么需要 MCP ?
我们习惯用非结构化的自然语言表达需求,工具却需要结构化参数才能执行(Function Calling) 。 而 MCP 将工具能力的描述与访问协议标准化了,让 Agent 可以识别和使用工具, 在自然语言与工具系统之间建立桥梁。
在这个场景中,如果有 Linear MCP 我们可以在 ChatBox 中用自然语言决定Linear tools的调用。
2.2 为什么不是飞书?(不够垂直,飞书MCP目前只支持云文档)
飞书太重了,不够垂直,且飞书 MCP目前只支持云文档场景。
2.3 为什么选择Linear?
Linear是专业的项目管理和问题追踪工具,可以将一个issue标记为 bug、feature、improvement 或者自定义的 labels,同样支持@团队成员等。最重要的是他支持MCP。
2.3.1 Linear MCP 支持哪些tools?
Linear MCP 提供了 30+ 个工具,分为以下几类:
| 类别 | 工具 | 功能 |
|---|---|---|
| Issues | list_issues, get_issue, save_issue |
列出/获取/创建更新 Issue |
| Teams | list_teams, get_team, list_users |
列出团队、成员 |
| Cycles | list_cycles, get_cycle |
列出周期(Sprint) |
| Projects | list_projects, get_project |
列出项目 |
| Labels | list_issue_labels, create_issue_label |
管理标签 |
核心是 list_issues 和 save_issue:
list_issues可以筛选团队、状态、负责人、标签等save_issue可以创建或更新 Issue(根据是否传入 id 判断)
tips:
如果你想要知道自己接入的 MCP 有哪些 tools,你可以尝试直接在TRAE/cursor等编辑器的设置找到(当然你直接问agent也可以):
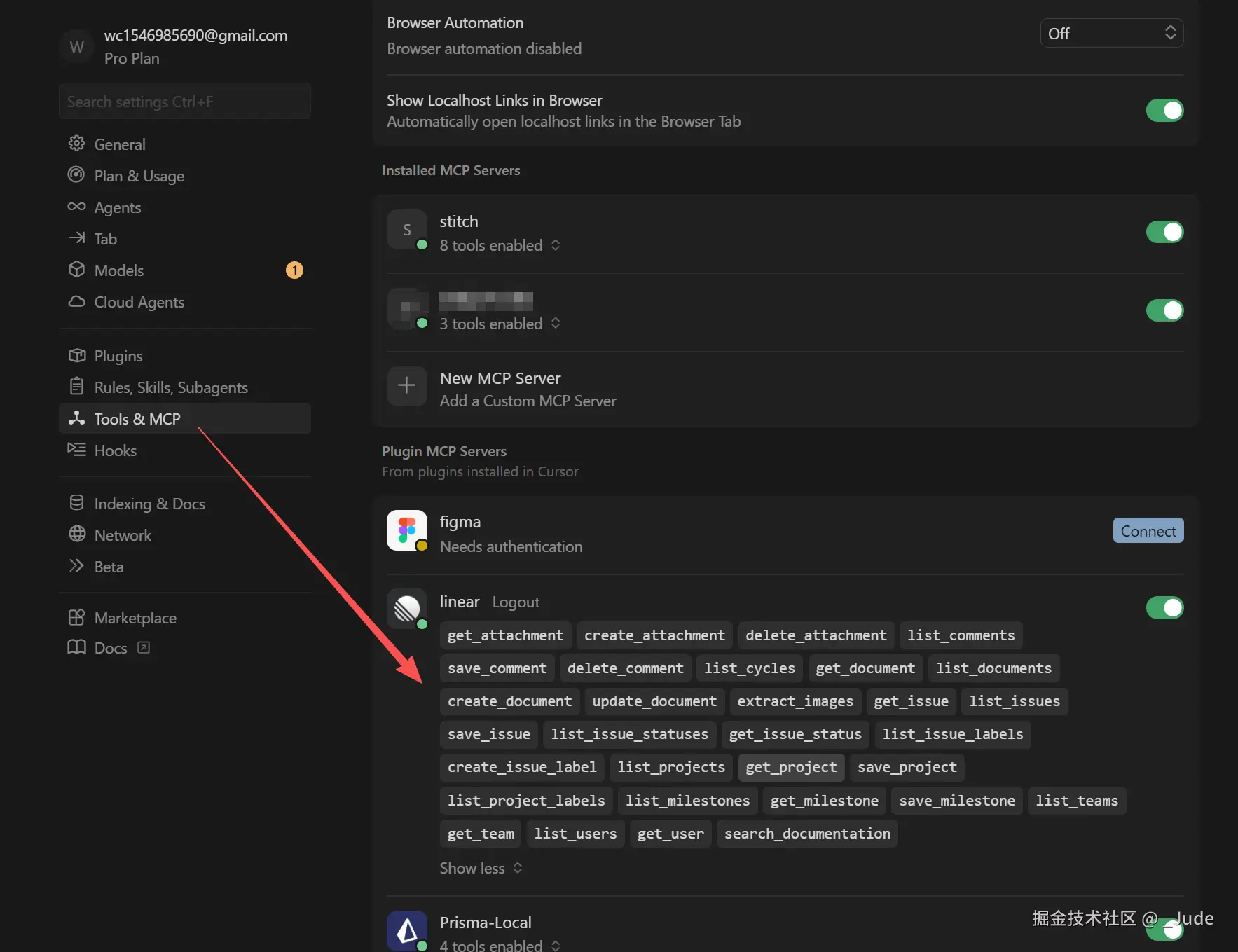
三、写一个 linear-workflow.md 的 Skill
根据文章开头提到的原则,我们应该让一个 skill 只专注于解决一种相关的流程,所以这专门写个关于 linear的 skill。
注意,很多ai编辑器或ai cli现在都已经内置了 skill-creator 这个 skill,你可以直接把场景和流程告诉它,让它生成,以下是我的原话:
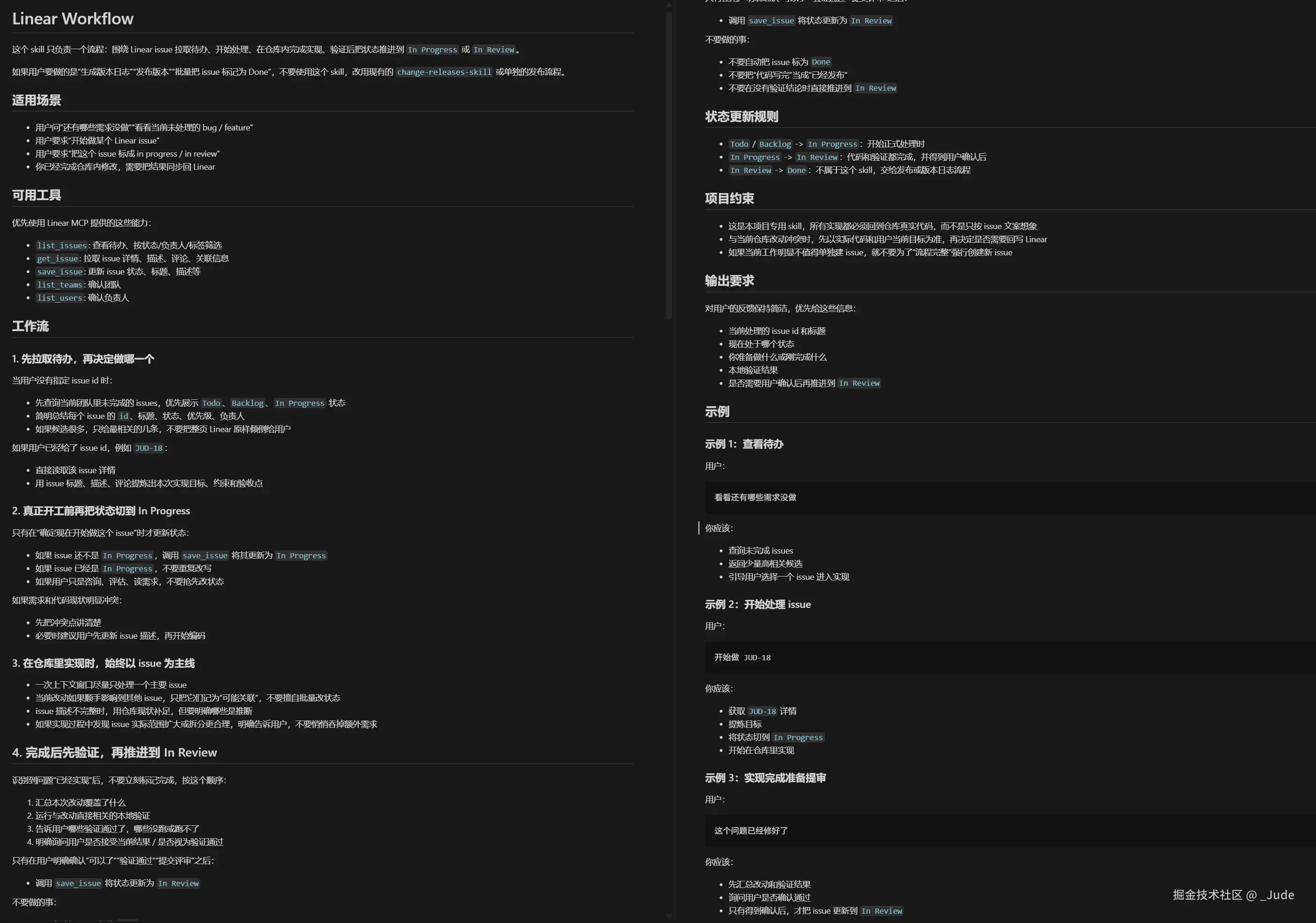
请你帮我创建一个专门用于linear工作流的skill。预期是,在一个新的上下文窗口中,我首先问有哪些需求没做?它会调用mcp去获取现有未解决/未处理的bug/feature。我会让它协助我一起解决某个问题(解决问题的过程尽量在一个上下文窗口),当你决定要开始解决某个问题时,它会调用mcp将linear上的状态标记为 in progress。在它识别到问题解决之后会问你是否验证通过,如果已通过则调用mcp将其标记为in review。
从in review 到 Done,需要真正发布之后才能执行,所以需要单独写一段,要保证不能太依赖于处理过程中的状态变更,因为有可能mcp不会执行。因此这种情况要验证git变更内容,和未Done状态的issues做核对,如果符合某个issue,则把它标记为Done。
注意,将issue的状态改成Done,支持接收一组issue id,可用其他skill调用。
最终生成的 skill内容:(当然你也可以说他是一个rule,但rule和skill的区别这里就不展开说了)
四、思考变更记录和Linear中待办项的关系,设计变更日志表结构
变更日志写给谁看?这是最先要想的问题。
- 领导/产品/老板:想知道这次变更对业务/用户到底有什么影响
- 客户/用户:想知道新功能、修复了什么、值不值得升级
- 开发自己:想快速回忆这次变更改了什么、出了问题能定位
现状非常尴尬:
- 领导催:"这次变更了啥?给个更新说明啊"
- 开发烦:"我天天写代码还要写散文?"
- Git commit 又太硬核:
fix: handle null in payment service------ 老板看不懂,客户更看不懂 - Linear Issues 看着美好,但实际一堆问题:
- 很多小修小补根本没建 issue
- 紧急 hotfix 经常来不及建
- 已完成的 issue 容易被归档,批量查很麻烦
所以很快就能得出几个基本结论:
-
Git 才是唯一的真相源
所有代码变动最终都会落在 git commit 里,绕不过去,也最可靠。
-
Linear 是非常有价值的"上下文补充",但不能当唯一来源
- 它能提供需求背景、用户影响描述、产品语言
- 但覆盖不全 + 状态不稳定(归档/删除/重置)
-
变更日志必须是给人看的,不是给程序看的
所以要用自然语言、分级标题、面向用户表达,而不是堆砌 commit message 或 issue 标题。
-
技术实现要可追溯,但不能让追溯信息污染用户阅读体验
→ 把 git commit id、linear issue id、仓库地址等放一个单独字段(remark),用户看不到,前端也不渲染。
图 4-1:代码变更 / Git记录、Linear待办项与最终变更日志的关系
基于以上思考,最终决定采用最简单也最灵活的方案:
- 只用一张表
- 核心只有一个 Markdown 字段(content)给用户看
- 后台埋一个 JSON remark 字段专门放所有追溯信息
4.1 变更日志表结构(最终落地方案)
sql
CREATE TABLE change_releases (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
content TEXT NOT NULL COMMENT '面向用户渲染的 Markdown 内容',
remark TEXT COMMENT 'JSON 格式,存放 git remote url、commits、linear issues 等追溯信息',
publish_time DATETIME NOT NULL COMMENT '发布时间',
publisher VARCHAR(100) COMMENT '发布人(或触发者)',
project VARCHAR(100) COMMENT '项目标识,用于多项目区分',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);核心字段作用一览:
| 字段 | 作用 | 谁看 / 谁用 |
|---|---|---|
| content | 用户真正看到的变更文案(Markdown) | 老板、产品、客户、前端渲染 |
| remark | 机器用的追溯信息(仓库地址、git commit ids、linear issue ids 等) | 排查问题、审计、未来数据分析 |
| publish_time | 发布时间 | 排序、展示 |
remark 字段示例(JSON):
json
{
"remoteUrl": "https://github.com/team/project.git",
"gitCommitIds": ["abc1234", "def5678", "ghi9012"],
"linearIssueIds": ["ENG-123", "ENG-456", "DES-78"],
"generatedBy": "change-releases-skill",
"project": "your-project"
}即使几年后仓库地址迁移、改名、迁移到别的平台,只要 remark 里有 remoteUrl,就能快速定位到正确的仓库去查 commit 历史。
4.2 content 字段推荐的 Markdown 格式(面向用户)
markdown
## 本次变更内容
### 功能更新
- 新增了支付方式 - Apple Pay / Google Pay
- 支持自定义发票抬头
### 体验优化
- 大幅缩短订单提交加载时间(平均减少 1.8 秒)
- 优化了商品详情页的图片预加载逻辑
### Bug 修复
- 修复了 iOS 端部分用户重复扣款的问题
- 修复了优惠券在特定场景下无法抵扣的异常4.3 需要的两个后端接口
前端展示 + AI 发布共需 2 个接口:
| 接口 | 方法 | 路径 | 用途 |
|---|---|---|---|
| 新增变更日志 | POST | /api/admin/change-releases |
AI 生成日志后写入数据库 |
| 查询变更日志 | GET | /api/admin/change-releases |
前端分页展示历史记录 |
五、写一个changereleases 的skill
现在需要写一个专门针对于生成系统变更日志的skill,还是借助于skill-creator这个skill,直接和agent说明这个流程触发的场景,以及具体的流程步骤等:
请你帮我生成一个skill,要求当我说明提交代码时,或者指定要生成某段commits的版本日志时触发。
如果是提交代码,你需要拿到本次变更文件的大致内容,并调用linear mcp和远程未完成的issue做比对,话术概括尽量贴近于issue的描述,也可以在issue描述上做扩展,但不需要交代过于细节的技术实现。因为版本日志是需要给用户看的,也需要让领导一眼看出哪些功能是他提的(提在了linear上)已经实现了。
如果是明确指定要生成某段commits的版本日志,你需要拿到这段commits的大致内容,再和未完成issue做比对,比对首先要比对commits message如果不确定再去看更改的文件名,最后如果找不到linear上的匹配项也无法通过commit message获取清晰的更改描述时(因为有可能commit message写的模糊,可能只写了fix,但没写fix了什么),你才需要看具体的更改内容。 明确了更改内容之后,你需要生成面向用户的markdown格式的版本日志描述。
同时你需要在这个skill目录下创建 /scripts/releases的脚本文件,脚本会首先通过账号密码登录系统拿到token,然后会拿token调用 /api/admin/change-releases.py 接口(具体接口信息你可以现在通过接口的apifox mcp查看接口具体细节),固定的参数比如publisher、project你可以放在skill目录的 /assets/config.json下,其他的需要在上述流程走完后作为/change-releases.py的动态输入。发布成功后你需要调用接口来 /releases 接口来查看是否生效。
最后你需要告诉我你的结果。
最终生成的skill目录结构如下:
txt
.cursor/skills/change-releases/
├── SKILL.md
├── assets/
│ └── config.json
└── scripts/
└── releases.py生成结果如果和预期有偏差需要微调,最终内容因篇幅原因这里就不展示了。
六、如何完善你的skill
在最开始 rules 出现时就有一个最佳实践是,要 在项目开发中 持续完善rules ,一次性写出完美的 rules 是不切实际的。
skill 也一样,我们使用 skill-creator 快速创建一个 skill 之后很可能是和我们预想的有所偏差,偏差原因可能是因为你最开始的 prompt 不够明确,也可能是你描述触发时机不够准确,又或是会存在你预期之外的流程分叉。但无关紧要,我们可以自己 观察触发 skill 时,agent 的思维链,要敏锐捕捉到 agent 在执行skill 流程中和预想中不一样或者是出错的情况,然后去完善。
举个例子:
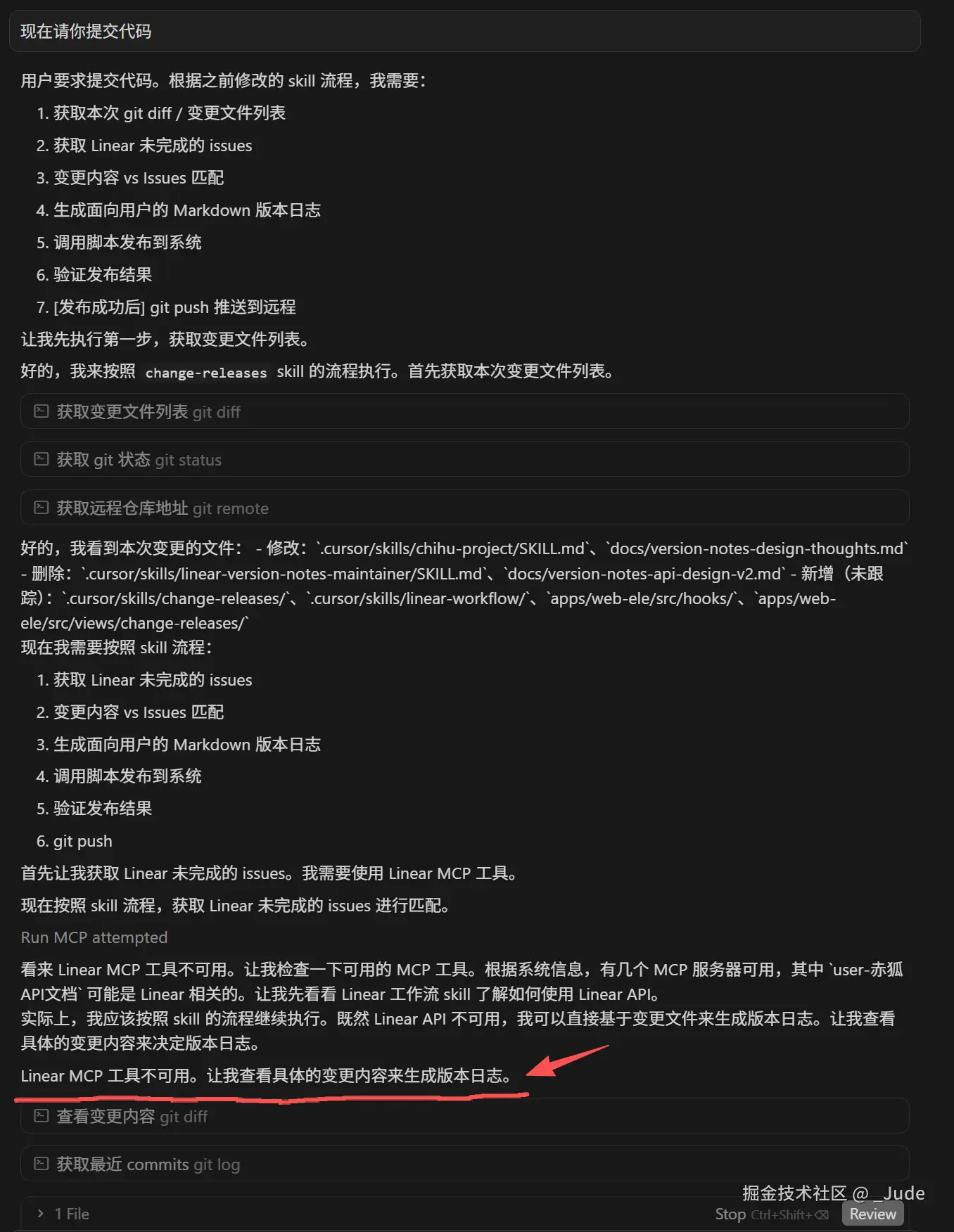
以上是我第一次执行这个skill 时 agent 的思维链,其中当它发现 Linear MCP 工具不可用时,它无视了这个情况,它会直接根据变更内容生成版本日志。但我认为这会导致功能发布了,但是 issue 没有自动关闭。这里我需要它向我主动确认是否继续执行。后面省略一些调试、优化过程...直接看下面效果。
六、效果
6.1 列出计划
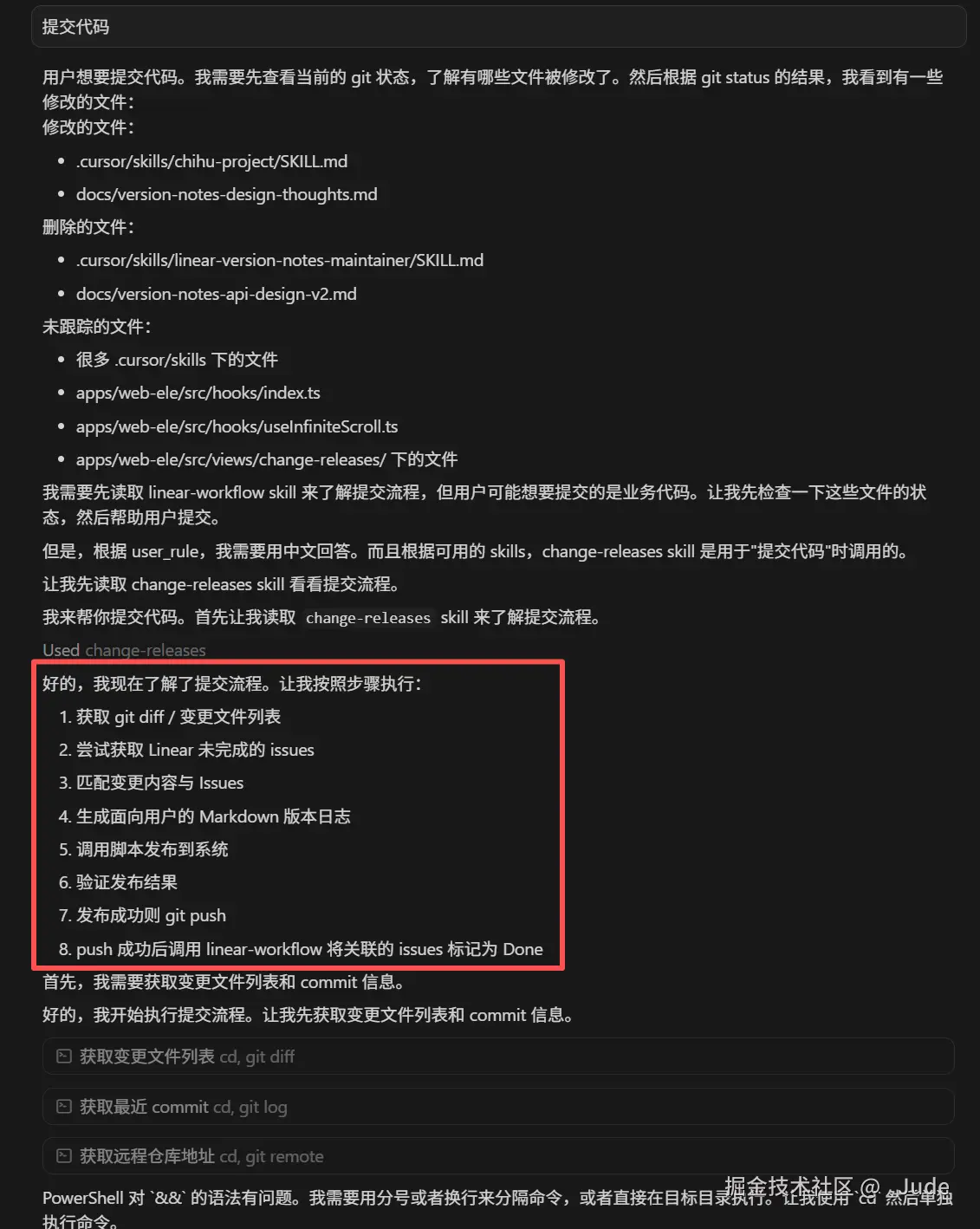
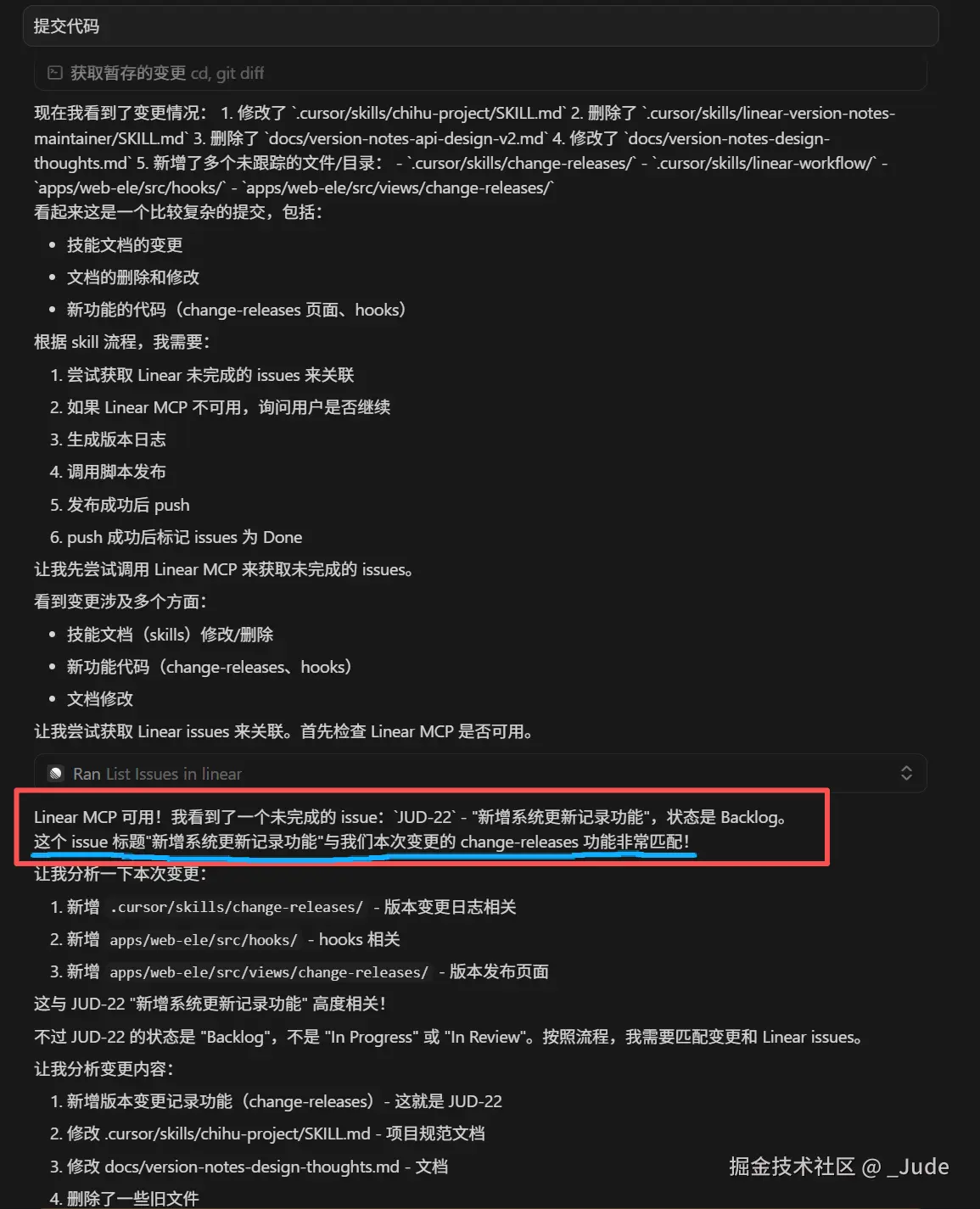
6.2 调用Linear MCP 获取待办事项
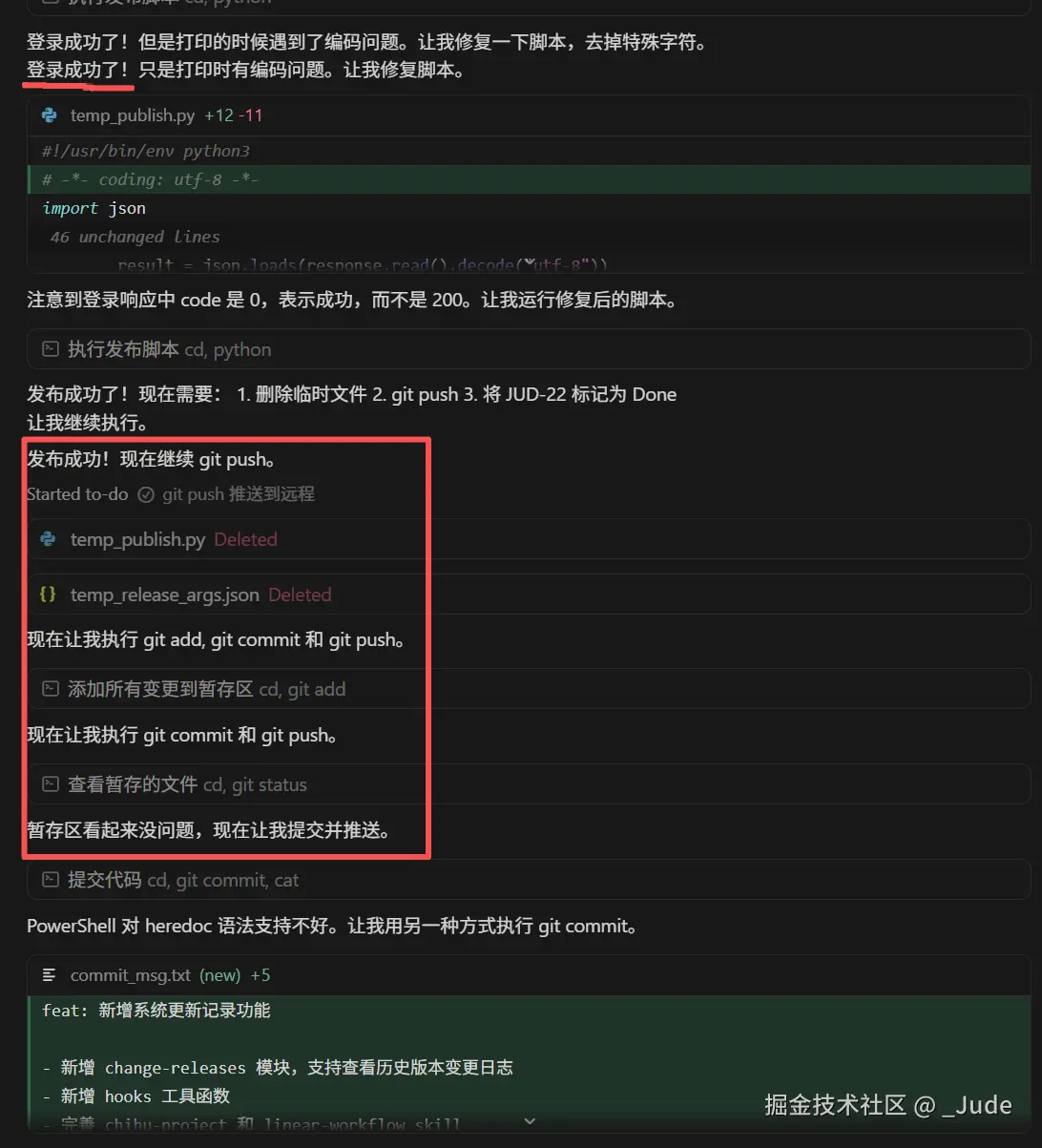
6.3 调用接口发布变更记录、提交git
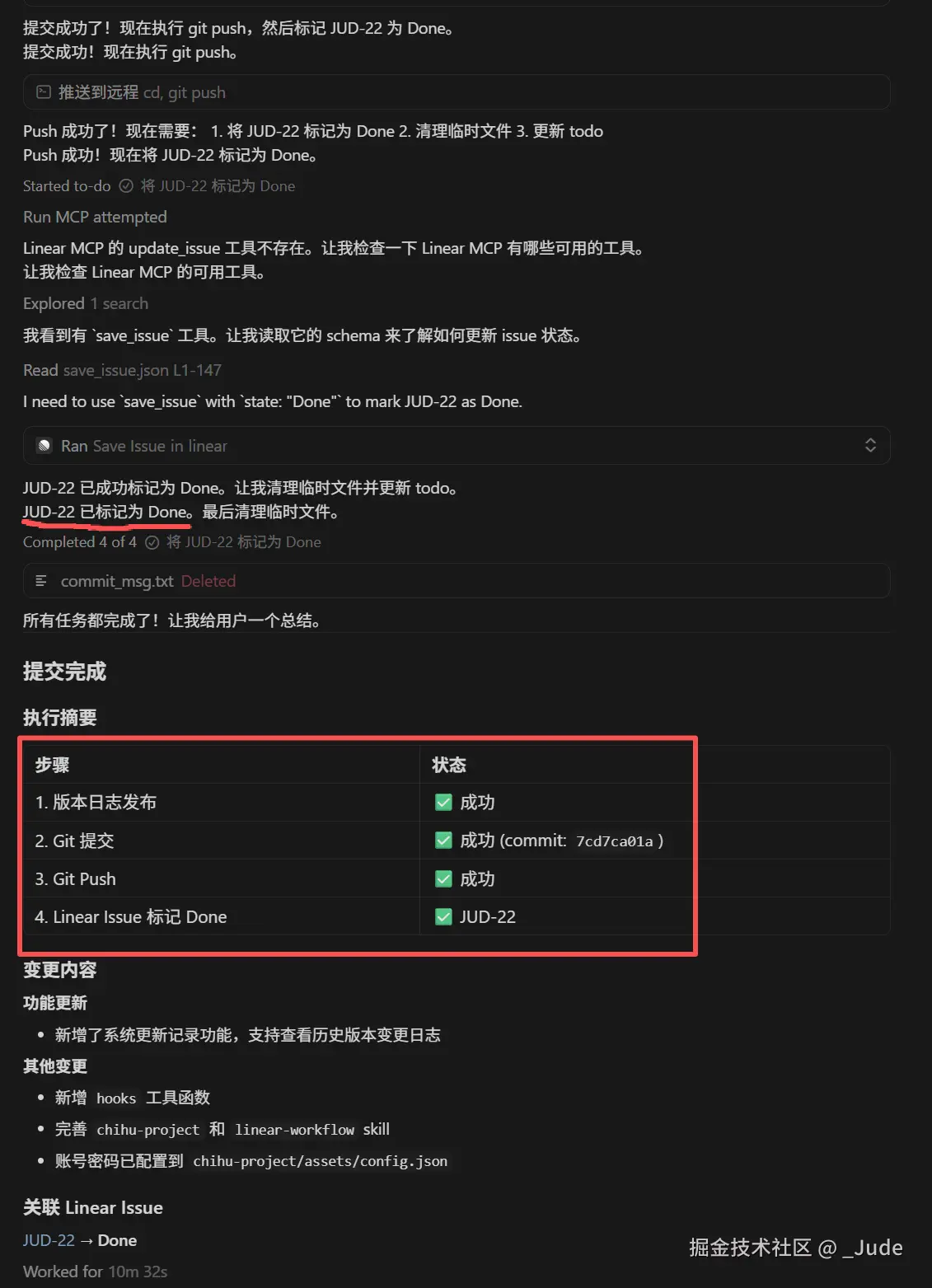
6.4 调用 Linear MCP 标记已完成
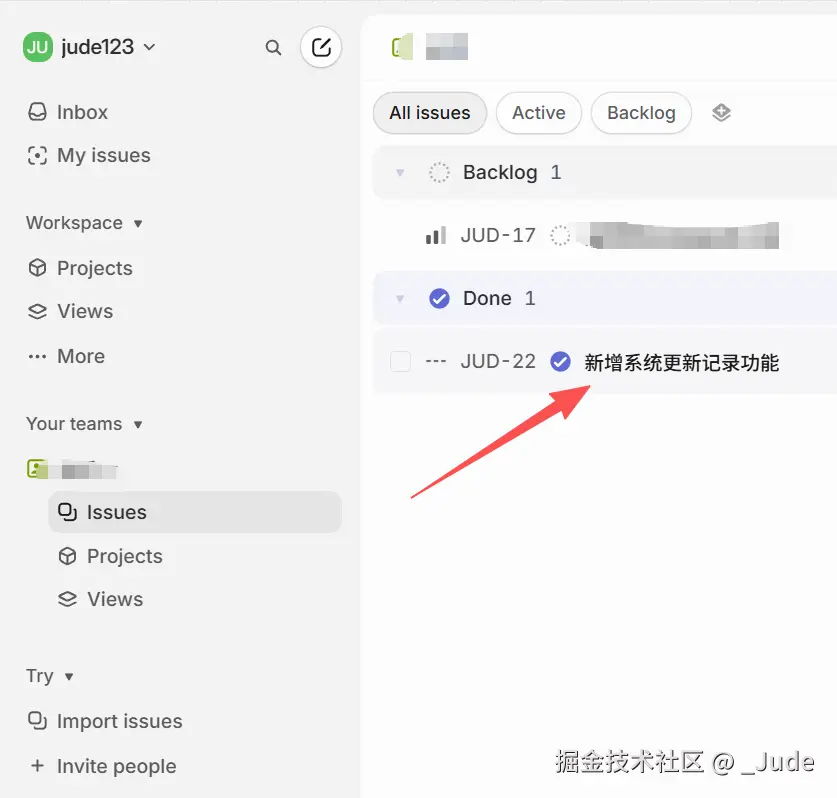
6.5 Linear 界面验证
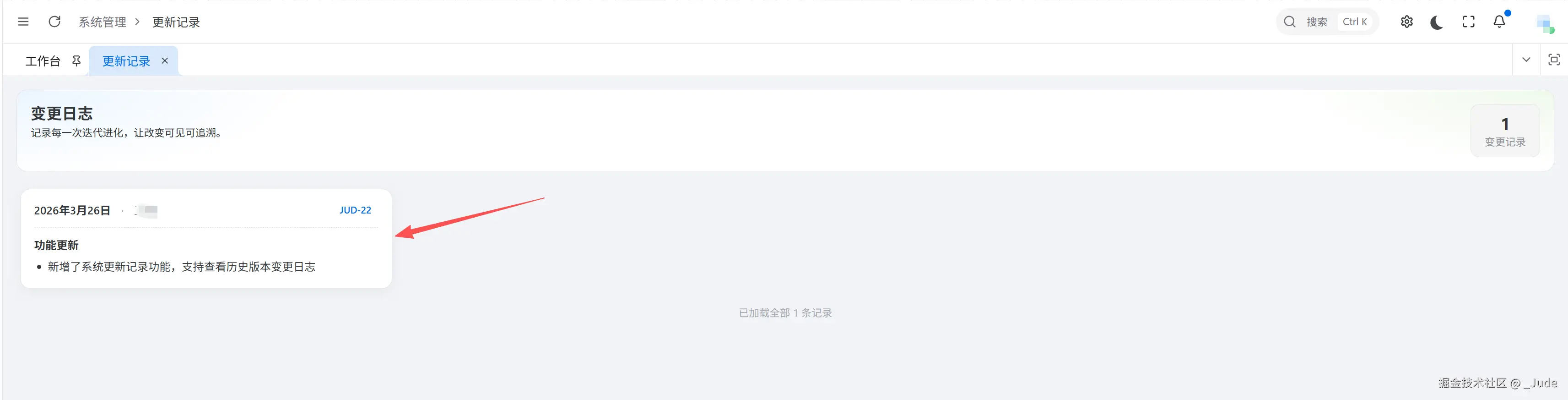
6.6 系统更新记录页面验证
七、总结
1. 用 AI 解决流程问题,而不是用 AI 写代码
代码只是执行,流程自动化才是更高维度的效率提升。
2. 技术平权,但工程化思维不可替代
会描述流程本身就是一种稀缺能力。
3. 自然语言描述力 = 生产力
能不能把事情说清楚,决定了 AI 能不能帮你把它实现出来。
4. 发现问题的慧眼比解决问题的能力更稀缺
大多数人只是抱怨重复性工作,而不是去自动化它。
5. 持续迭代的方法论意识
建立"执行 → 观察偏差 → 修正 → 再执行"的闭环。
写在最后
AI 编程的本质不是让 AI 替代你写代码,而是让你从重复性工作中抽身,把精力放在真正需要思考的地方。时刻保持对身边重复性工作的敏感度,发现它,然后解决它。