随机链表的复制
排序链表
合并 K 个升序链表
LRU 缓存
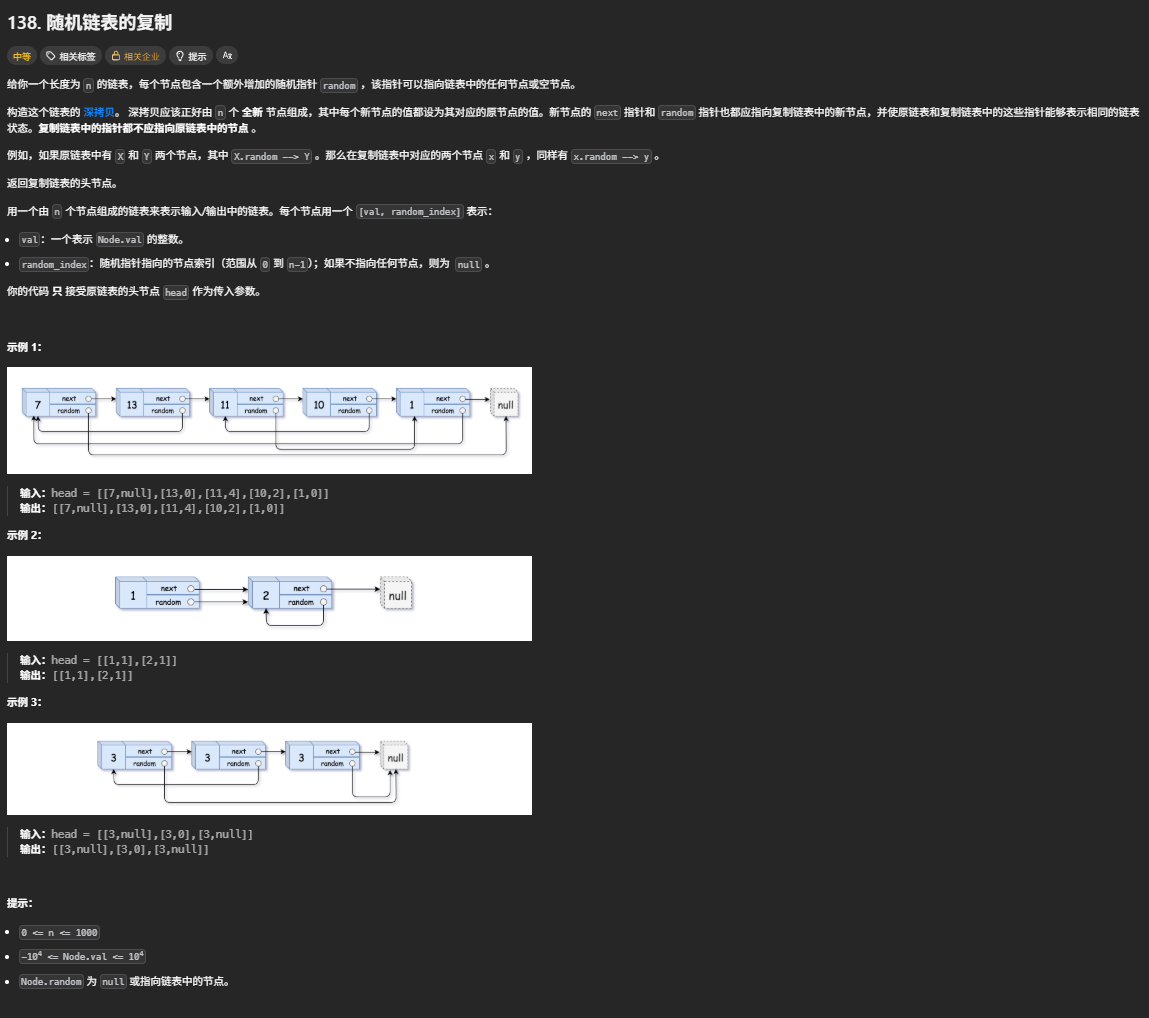
138. 随机链表的复制
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
Map<Node, Node> map = new HashMap<>();
Node cur = head;
// 第一次遍历:复制所有节点,建立映射
while (cur != null) {
map.put(cur, new Node(cur.val));
cur = cur.next;
}
// 第二次遍历:设置 next 和 random 指针
cur = head;
while (cur != null) {
Node copyNode = map.get(cur);
copyNode.next = map.get(cur.next);
copyNode.random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}解题思路1:哈希表法
遍历原链表,用哈希表建立「原节点 → 新节点」的映射。
再次遍历原链表,根据映射关系,为新节点设置 next 和 random 指针。
public class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
// 1. 复制节点并插入到原节点后
Node cur = head;
while (cur != null) {
Node copy = new Node(cur.val);
copy.next = cur.next;
cur.next = copy;
cur = copy.next;
}
// 2. 设置新节点的 random 指针
cur = head;
while (cur != null) {
Node copy = cur.next;
if (cur.random != null) {
copy.random = cur.random.next;
}
cur = copy.next;
}
// 3. 拆分原链表和复制链表
cur = head;
Node dummy = new Node(0);
Node copyCur = dummy;
while (cur != null) {
Node copy = cur.next;
cur.next = copy.next;
copyCur.next = copy;
copyCur = copy;
cur = cur.next;
}
return dummy.next;
}
}解题思路2:原地复制 + 拆分
复制节点 :在原链表每个节点后插入其副本,形成 原1 → 新1 → 原2 → 新2... 的结构。
设置 random 指针 :遍历链表,新节点的 random 指向原节点 random 指向节点的下一个副本。
拆分 链表:将原节点和新节点分离,得到复制后的链表。
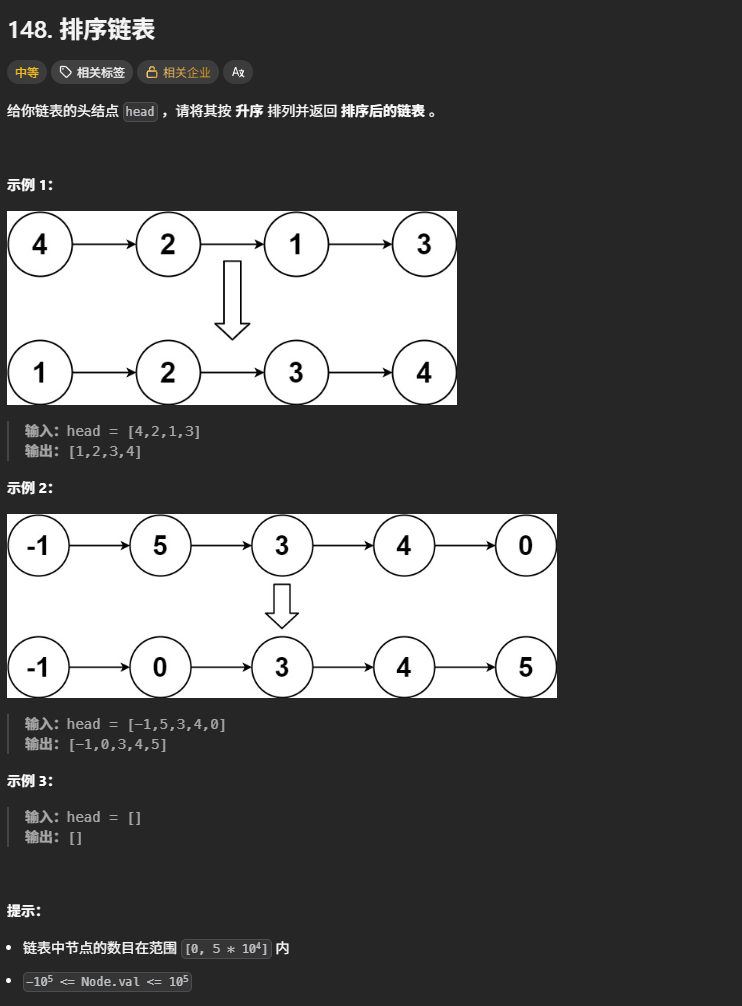
148. 排序链表
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode sortList(ListNode head) {
// 递归终止条件:空链表或只有一个节点
if (head == null || head.next == null) {
return head;
}
// 1. 快慢指针找中点
ListNode slow = head;
ListNode fast = head.next;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
ListNode mid = slow.next;
slow.next = null; // 拆分链表
// 2. 递归排序左右两部分
ListNode left = sortList(head);
ListNode right = sortList(mid);
// 3. 合并两个有序链表
return merge(left, right);
}
// 合并两个有序链表
private ListNode merge(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode cur = dummy;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
cur.next = l1;
l1 = l1.next;
} else {
cur.next = l2;
l2 = l2.next;
}
cur = cur.next;
}
cur.next = l1 != null ? l1 : l2;
return dummy.next;
}
}解题思路1:归并排序(推荐,时间复杂度 O (n log n),空间复杂度 O (log n))
这是链表排序的经典解法,利用快慢指针找中点,递归拆分后有序合并。
public class Solution {
public ListNode sortList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
// 计算链表长度
int len = 0;
ListNode cur = head;
while (cur != null) {
len++;
cur = cur.next;
}
ListNode dummy = new ListNode(0);
dummy.next = head;
// 按长度 1,2,4... 分组合并
for (int step = 1; step < len; step <<= 1) {
ListNode pre = dummy;
cur = dummy.next;
while (cur != null) {
// 拆分第一组
ListNode left = cur;
ListNode right = split(left, step);
// 拆分第二组
cur = split(right, step);
// 合并两组
pre.next = merge(left, right);
// 移动 pre 到合并后链表尾部
while (pre.next != null) {
pre = pre.next;
}
}
}
return dummy.next;
}
// 从 head 开始拆分 step 个节点,返回剩余部分的头节点
private ListNode split(ListNode head, int step) {
if (head == null) return null;
while (step > 1 && head.next != null) {
head = head.next;
step--;
}
ListNode next = head.next;
head.next = null;
return next;
}
// 合并两个有序链表(同方法一)
private ListNode merge(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode cur = dummy;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
cur.next = l1;
l1 = l1.next;
} else {
cur.next = l2;
l2 = l2.next;
}
cur = cur.next;
}
cur.next = l1 != null ? l1 : l2;
return dummy.next;
}
}解题思路2:自底向上归并排序(迭代版,空间复杂度 O (1))
避免递归栈开销,通过迭代方式按长度 1,2,4... 分组合并。
23. 合并 K 个升序链表

/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if (lists == null || lists.length == 0) return null;
// 最小堆:按节点值升序排列
PriorityQueue<ListNode> heap = new PriorityQueue<>((a, b) -> a.val - b.val);
// 将所有非空链表的头节点入堆
for (ListNode node : lists) {
if (node != null) heap.offer(node);
}
ListNode dummy = new ListNode(0);
ListNode cur = dummy;
while (!heap.isEmpty()) {
// 取出当前最小节点
ListNode minNode = heap.poll();
cur.next = minNode;
cur = cur.next;
// 将该节点的下一个节点入堆(如果存在)
if (minNode.next != null) heap.offer(minNode.next);
}
return dummy.next;
}
}解题思路1:优先队列(最小堆)
-
把所有 链表 的头节点放进最小堆,堆顶永远是当前最小节点
-
取出堆顶节点接到结果上
-
把这个节点的下一个节点再放回堆
-
重复直到堆空v
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if (lists == null || lists.length == 0) return null;
return merge(lists, 0, lists.length - 1);
}// 递归分治:合并 [left, right] 区间的链表 private ListNode merge(ListNode[] lists, int left, int right) { if (left == right) return lists[left]; int mid = left + (right - left) / 2; ListNode l1 = merge(lists, left, mid); ListNode l2 = merge(lists, mid + 1, right); return mergeTwoLists(l1, l2); } // 合并两个有序链表(复用之前的代码) private ListNode mergeTwoLists(ListNode l1, ListNode l2) { ListNode dummy = new ListNode(0); ListNode cur = dummy; while (l1 != null && l2 != null) { if (l1.val < l2.val) { cur.next = l1; l1 = l1.next; } else { cur.next = l2; l2 = l2.next; } cur = cur.next; } cur.next = l1 != null ? l1 : l2; return dummy.next; }}
解题思路2:分治法(归并思想)
-
把 K 个链表不断分成两组,直到每组只剩 1 个
-
再两两合并成有序链表
-
层层合并,最后得到一条完整链表
public class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if (lists == null || lists.length == 0) return null;
ListNode res = lists[0];
for (int i = 1; i < lists.length; i++) {
res = mergeTwoLists(res, lists[i]);
}
return res;
}// 合并两个有序链表(同上) private ListNode mergeTwoLists(ListNode l1, ListNode l2) { ListNode dummy = new ListNode(0); ListNode cur = dummy; while (l1 != null && l2 != null) { if (l1.val < l2.val) { cur.next = l1; l1 = l1.next; } else { cur.next = l2; l2 = l2.next; } cur = cur.next; } cur.next = l1 != null ? l1 : l2; return dummy.next; }}
解题思路3:顺序合并(暴力法)
-
先拿第 1 个链表当结果
-
依次把第 2、3...K 个 链表和结果合并
-
全部合并完就是答案
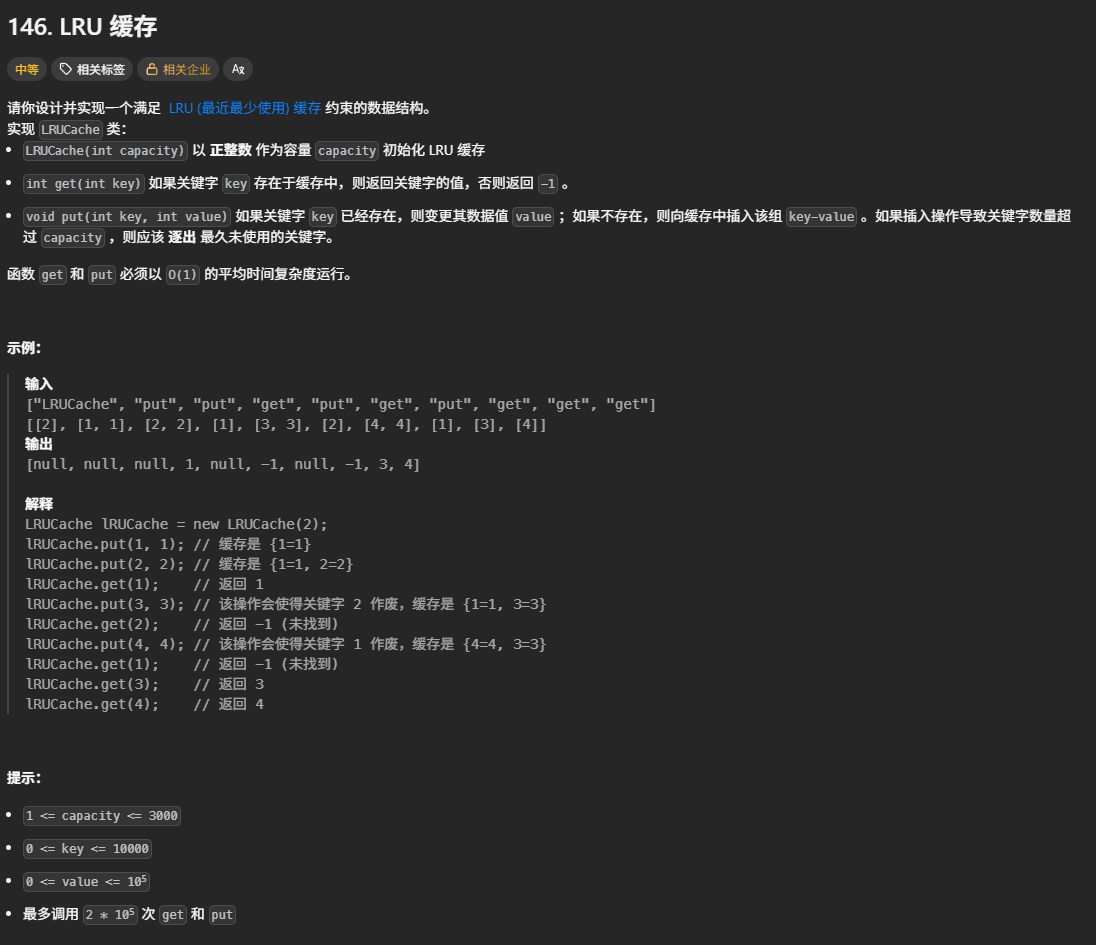
146. LRU 缓存
什么是 LRU 缓存?
LRU 是 Least Recently Used (最近最少使用)的缩写,是一种常见的缓存淘汰策略。
核心思想:
-
缓存容量有限,当缓存满了要插入新数据时,优先删除「最久没被访问」的数据,为新数据腾出空间。
-
「访问」包括两种操作:
get(读取)和put(更新 / 插入),只要操作了,就把该数据标记为「最近刚使用」。class LRUCache {
private static class Node {
int key, value;
Node prev, next;Node(int k, int v) { key = k; value = v; } } private final int capacity; private final Node dummy = new Node(0, 0); // 哨兵节点 private final Map<Integer, Node> keyToNode = new HashMap<>(); public LRUCache(int capacity) { this.capacity = capacity; dummy.prev = dummy; dummy.next = dummy; } public int get(int key) { Node node = getNode(key); // getNode 会把对应节点移到链表头部 return node != null ? node.value : -1; } public void put(int key, int value) { Node node = getNode(key); // getNode 会把对应节点移到链表头部 if (node != null) { // 有这本书 node.value = value; // 更新 value return; } node = new Node(key, value); // 新书 keyToNode.put(key, node); pushFront(node); // 放到最上面 if (keyToNode.size() > capacity) { // 书太多了 Node backNode = dummy.prev; keyToNode.remove(backNode.key); remove(backNode); // 去掉最后一本书 } } // 获取 key 对应的节点,同时把该节点移到链表头部 private Node getNode(int key) { if (!keyToNode.containsKey(key)) { // 没有这本书 return null; } Node node = keyToNode.get(key); // 有这本书 remove(node); // 把这本书抽出来 pushFront(node); // 放到最上面 return node; } // 删除一个节点(抽出一本书) private void remove(Node x) { x.prev.next = x.next; x.next.prev = x.prev; } // 在链表头添加一个节点(把一本书放到最上面) private void pushFront(Node x) { x.prev = dummy; x.next = dummy.next; x.prev.next = x; x.next.prev = x; }}
作者:灵茶山艾府
解题思路1:手写双向链表
class LRUCache {
private final int capacity;
private final Map<Integer, Integer> cache = new LinkedHashMap<>(); // 内置 LRU
public LRUCache(int capacity) {
this.capacity = capacity;
}
public int get(int key) {
// 删除 key,并利用返回值判断 key 是否在 cache 中
Integer value = cache.remove(key);
if (value != null) { // key 在 cache 中
cache.put(key, value);
return value;
}
// key 不在 cache 中
return -1;
}
public void put(int key, int value) {
// 删除 key,并利用返回值判断 key 是否在 cache 中
if (cache.remove(key) != null) { // key 在 cache 中
cache.put(key, value);
return;
}
// key 不在 cache 中,那么就把 key 插入 cache,插入前判断 cache 是否满了
if (cache.size() == capacity) { // cache 满了
Integer eldestKey = cache.keySet().iterator().next();
cache.remove(eldestKey); // 移除最久未使用 key
}
cache.put(key, value);
}
}
作者:灵茶山艾府解题思路2:标准库
