这几天我一直在折腾一件小事:
把我个人公众号后台的历史文章和数据,完整提取出来。
一开始我以为不难,结果一上手就发现各种坑:
有时候只能抓到前几篇,有些文章会漏掉,指标也会错位。
最终,按照以下循环多轮迭代搞定了
1、先把现象丢给 AI,让它帮我拆问题
2、我按它给的思路去跑、去看日志
3、出现新问题再回到 AI,继续修正

当前实现的效果
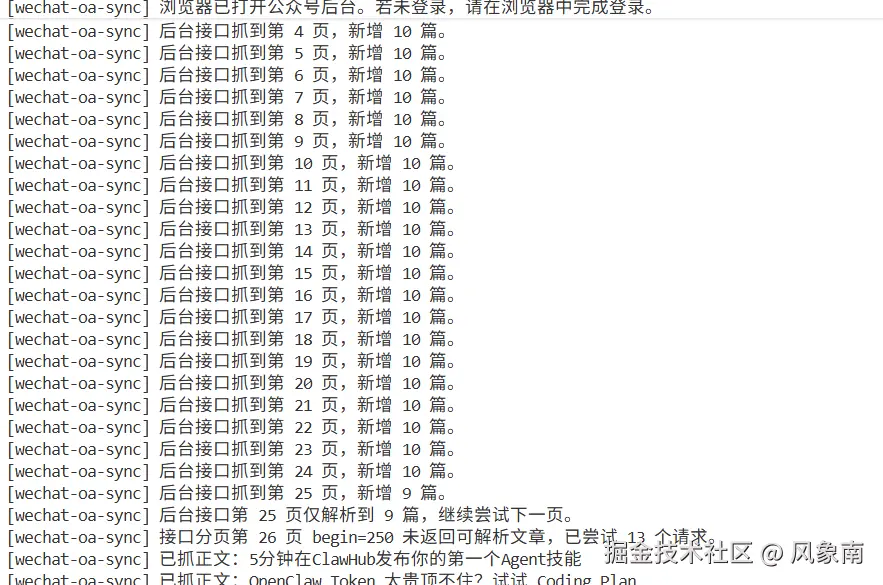
现在已经可以抓取到:
- 历史文章列表
- 每篇文章的核心指标(阅读、点赞、分享、推荐、评论)
- 对应文章正文
需要抓取文章数据时执行一行命令,就能更新最新数据,自带去重。
方案选择
这次我其实也评估过两条常见路线:
1)RAP 方案
优点:
- 上手快
- 对固定流程页面有效
缺点:
- 页面结构一变就容易失效
- 在多分页、异步加载、状态切换场景里维护成本高
2)浏览器自动化方案(如Browse-Use)
优点:
- 对页面结构变化更"有弹性"
- 不强依赖固定 DOM 选择器
缺点:
- 成本更高,每次执行都需要Token(即使有些工具框架带了缓存机制)
- 结果稳定性受截图质量、页面状态、模型波动影响
- 目前更适合"操作自动化",不太适合"高一致性数据采集"
- 更重要的一点,速度太慢了
3)我最终采用的方案:浏览器驱动的多源采集合并方案
原理也不复杂,核心就三步:
- 先用浏览器登录态打开公众号后台,按
begin=0/10/20...直接翻历史列表页 - 每一页同时从多个来源取数据:可见列表、页面状态对象、HTML内嵌数据
- 把同一篇文章做去重和合并,最后统一落盘;如果主链路拿不全,再用后台接口做兜底
这么实现主要是以下几点考虑
- 运行速度够快(考虑频繁操作会触发WX的限流风控,采集也刻意增加了间隔控制速率)
- 不依赖任何模型,一行命令就可以开始采集
一点启发
我现在越来越相信,AI 最适合切入的地方,
不是先去追那些听起来很大的应用场景,而是先回到自己每天真的会碰到的问题。
这次我做这件事,原因其实很简单。
我不是为了展示什么技术,也不是为了做一个看起来很完整的项目,
就是因为我自己确实需要复盘内容,而数据整理这一步一直很麻烦。
所以这次最让我有感触的,不是"又跑通了一个流程",
而是我终于把一个自己会长期遇到的问题,借助AI往前推进了一步。