通过前面的大型网站架构了解,一个网站系统会有很多节点及资源,如何对如此大规模资源进行监控?如果有节点出现故障,如何快速恢复?
这需要运维工具,运维工具也分类:
- OS Provisioning(PXE,Cobbler):操作系统自动安装配置;
- OS Configuration(ansible,puppet,saltstack,chef,cfengine):操作系统配置,安装应用软件包,配置软件等;
- Command and Control(func,ansible,fabric):命令与控制,对系统及软件的调试、控制、监控、报告等;
从个人角度理解,就是一台机器从操作系统到应用软件到最终运行的全套自动化恢复、配置、运行、监控的过程工具。OS Provisioning就是操作系统的自动安装恢复,一个系统中一个节点出现故障,要能够自动安装恢复其上的操作系统,或是新增一个硬件裸节点,要能在其上按要求自动安装操作系统;OS Configuration就是在操作系统自动安装/恢复完毕后,要自动安装/恢复其上的应用软件;Command and Control就是对应用软件等的配置与监控,确保运行正常,并处于监控中;
puppet:IT基础设施自动化管理工具
可管理IT整个生命周期:
Provisioning :供应
Configuration :配置
orchestration : 联动
reporting :报告
puppet有agent,其工作模式为:master/agent
master:puppet server
agent:真正执行相应管理操作的核心部件;周期性的去master请求与自己相关的配置;
puppet工作模式:
声明性、基于模型:
定义(Define):使用puppet配置语言定义基础配置信息,配置语言是一种编程语言(puppetDSL);
模拟(Simulation):即正式生效前进行模拟性应用,测试正确性;
强制(Enforce):正式部署配置,强制当前系统与定义的目标状态保持一致;
报告(Report):部署执行后的状态反馈,通过puppet api将执行结果发送给接收者;
puppet的三个层次:三层模型
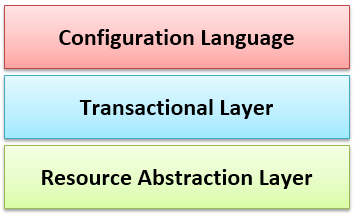
配置语言:专用的声明性的配置语言,而且是基于模型(抽象资源)来进行构建的配置机制;
事务层:资源之间可能有依赖关系,事务层保证操作的完整性;如httpd配置改变后,一般需要重新启动或重新加载配置等;
资源抽象层:把主机上每一个可被管理的对象进行抽象,即不同的被管理对象被分类归属为不同的资源,一般按如下进行抽象:
资源类型:如用户、组、文件、服务、cron任务等:File、User、Group、Host、Package、Service、Cron、Exec等;
属性及状态与其实现方式分离;
期望状态;
通过抽象资源的方式,使得每台机器能够"清楚"其本身"应该"是什么"状态",而客户端根据当前是否达到这个状态,即期望状态与现实状态的差异,决定采取指定的动作。
puppet的核心组件:资源
资源清单:manifest,定义了资源的一个文件,叫做manifest。
模块:module,资源清单及清单中的资源定义的所依赖文件、模版等数据按特定结构组织起即为"模块",相当于ansible中的角色role,可以理解为更大尺度上的一个资源清单包。其主要是实现代码的重用,即资源清单的重用。
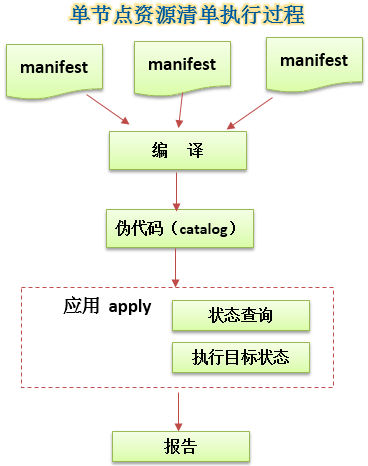
一个资源清单中定义了一堆的资源,包括了资源的类型、属性、期望状态等,因为清单本身就是一种编程语言,所以要经过编译过程,形成伪代码,就叫catalog,类似java编译后的字节码,然后在agent节点上应用,即apply这个catalog,也就相当于运行程序,执行状态查询,根据查询的状态,执行目标状态,最后报告结果。(在ruby虚拟机上运行catalog)。
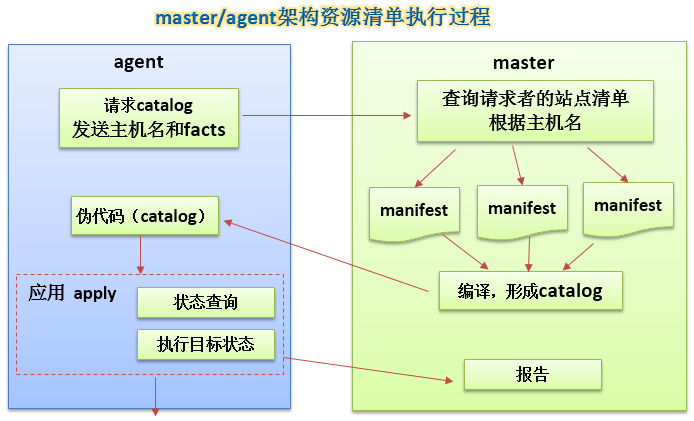
agent请求catalog时,会同时发送主机名和facts,所谓facts,就是agent节点的一些属性信息,这可以与http请求,即request进行类比,浏览器发送请求时,在请求头中携带的信息,如客户端的IP、浏览器类型等,实际上就是这里的facts,只不过二者的信息内容不同罢了。
前面讲的puppet中属性及状态与其实现方式分离是什么意思呢?其实就是说,agent节点可能是多种不同的主机,如windows、redhat、Ubuntu等,如果资源清单中定义了一个package资源,就是要安装这个包,那么,不同的系统其实现是不同的,这就是属性及状态与实现分离。实现由agent根据不同的系统,进行不同处理实现。
在master/agent架构中,master与agent之间是基于HTTPS协议,以XMLRPC远程过程调用实现通信的,基于证书进行认证、通信。master会作为CA中心,agent向其申请证书。
puppet安装与使用:
因为puppet可以只运行于agent,单节点运行,这可以让我们专注于manifest资源清单的理解与编写,在理解了资源清单、资源、属性、状态、类、模块等概念后,再将其运行于master/agent架构中,会有更好的学习效果。
puppet安装:
在阿里云上有puppet镜像下载,提供的最低版本是puppet5:
https://mirrors.aliyun.com/puppet/yum/puppet5/el/7/x86_64/
包括如下软件包:可通过yum info xxx 查看相关包的功用。
pkd-1.xx :Puppet Development Kit,是puppet开发工具
puppet-agent-5.xx :The Puppet Agent package contains all of the elements needed to run puppet, including ruby, facter,hiera and mcollective。puppet的agent,单节点安装这个包应该就可以。
puppet-bolt-0.xx :Stand alone task runner。网上资料:bolt 是 Puppet 公司推出的开源自动化工具,用于在远程系统上执行一次性任务或编排多步骤操作。它采用无代理架构,通过 SSH(Linux/Unix)或 WinRM(Windows)连接目标节点,支持使用任意语言(如 Bash、PowerShell、Python 等)编写任务脚本。我的理解,就是一个类ansible。
puppet-client-tools-1.xx :PuppetDB CLI for querying Puppet data。是Puppet 5+ 版本中的一个独立软件包,用于分离客户端工具与完整 Puppet Agent 安装。
puppet5-release-5.xx :Release packages for the Puppet5 repository。
puppetdb-5.xx :Puppet Labs puppetdb.存储节点信息的数据库。
*PuppetDB作为基础设施自动化平台的核心数据存储组件,通过高效的数据处理机制与灵活的扩展能力,为大规模节点管理提供可靠支撑。
一、PuppetDB的技术定位与核心价值
在基础设施即代码(IaC)的实践场景中,自动化平台需要处理数以万计节点的配置数据、运行时状态及关联关系。传统关系型数据库在应对这种高频写入、复杂查询的混合负载时,常面临性能瓶颈与扩展性挑战。PuppetDB通过针对性设计解决了这一难题:
数据模型适配性:支持目录数据(Catalog)、事实数据(Facts)及自定义扩展类型,覆盖节点配置、软件包状态、硬件属性等全维度信息
异步处理机制:采用最终一致性模型,通过命令队列缓冲写入压力,确保系统在高并发场景下的稳定性
多存储引擎支持:提供嵌入式HSQLDB(适合开发测试)与生产级PostgreSQL双引擎选择,满足不同规模场景需求
二、系统架构深度解析
- 三层组件模型
命令处理层:接收来自Puppet Master的replace catalog、store report等命令,通过消息队列实现FIFO顺序处理
存储子系统:采用CQRS(命令查询职责分离)模式,写模型聚焦数据变更效率,读模型优化查询性能
REST接口层:提供标准化的CRUD接口,支持/pdb/query/v4等端点下的资源检索与聚合操作 - 数据处理流程示例
sequenceDiagram
Puppet Master->>Command Processor: POST /commands (replace catalog)
Command Processor->>Message Queue: 持久化命令
Message Queue->>Storage Writer: 触发CQRS写操作
Storage Writer->>PostgreSQL: 更新catalogs表
User->>REST API: GET /pdb/query/v4/nodes
REST API->>Storage Reader: 执行预编译查询
Storage Reader-->>User: 返回JSON格式节点列表 - 性能优化关键技术
索引策略:对certname、environment等高频查询字段建立复合索引
分区设计:按时间维度对报告数据(reports)进行表分区,提升历史数据查询效率
缓存机制:在REST接口层实现查询结果缓存,TTL可配置为5-30分钟
三、核心功能实现指南 - 多维度数据查询
- 布尔运算与嵌套查询
- 扩展数据类型支持*
puppetdb-termini-5.xx :Termini for puppetdb.
用于实现 Puppet Master 与 PuppetDB 集成的关键组件,其主要功能如下:
核心功能:
提供 Puppet 术语(terminus)实现:
替代旧版 ActiveRecord 后端:
在 Puppet 5 之前,Puppet 使用 ActiveRecord 库将配置数据存储在关系型数据库中;puppetdb-termini-5 作为现代替代方案,提供更高效、可扩展的数据存储机制 。
支持导出资源(Exported Resources)和库存服务(Inventory Service):
使节点能够查询其他节点的事实信息,并通过 <<| |>> 语法收集跨节点的资源,实现动态配置编排 。
与 Puppet Master 无缝集成:
安装后,Puppet Master 可通过配置文件(如 /etc/puppet/puppetdb.conf 和 /etc/puppet/routes.yaml)自动将运行时数据推送到 PuppetDB 。
puppetserver-5.xx :Puppet Labs puppetserver.
razor-server-1.xx :Razor is an advanced provisioning application。
agent单节点安装puppet-agent-5.0.0:其包含了以下组件
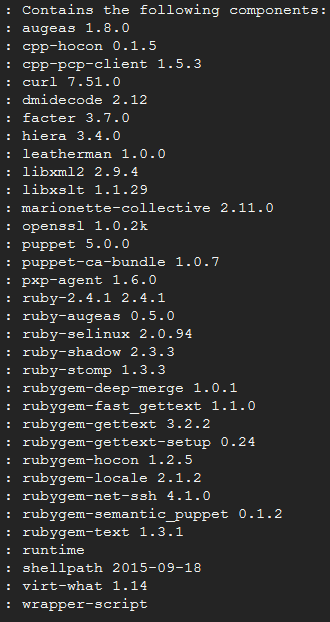
yum install puppet-agent-5.0.0
安装后的可执行文件在/opt/puppetlabs下,需在PATH环境变量中增加。如在~/.bash_profile中,设置:PATH=PATH:HOME/bin:/opt/puppetlabs/bin:
保存后执行source .bash_profile
puppet命令用法:
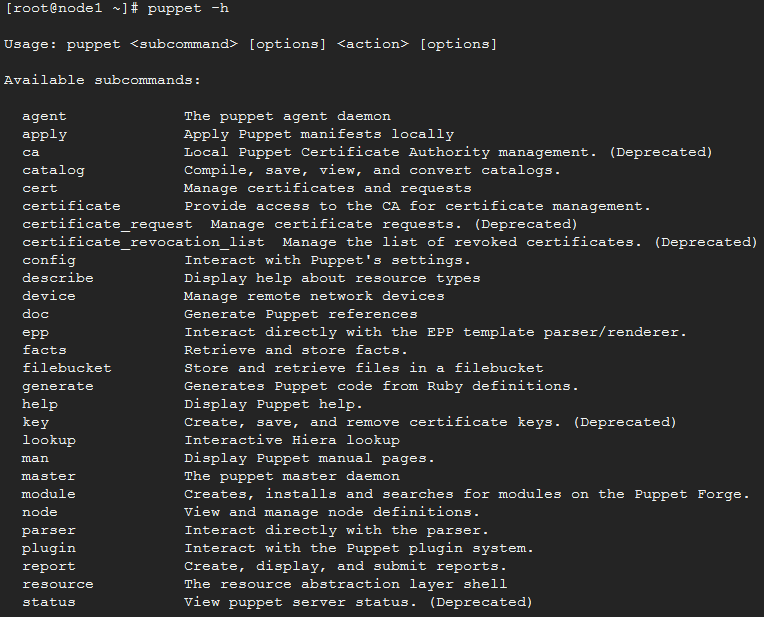
puppet有众多子命令,其中describe用于显示资源类型:
puppet describe -h\|--help -s\|--short -p\|--providers -l\|--list -m\|--meta
列出所有的资源类型:
puppet describe -l
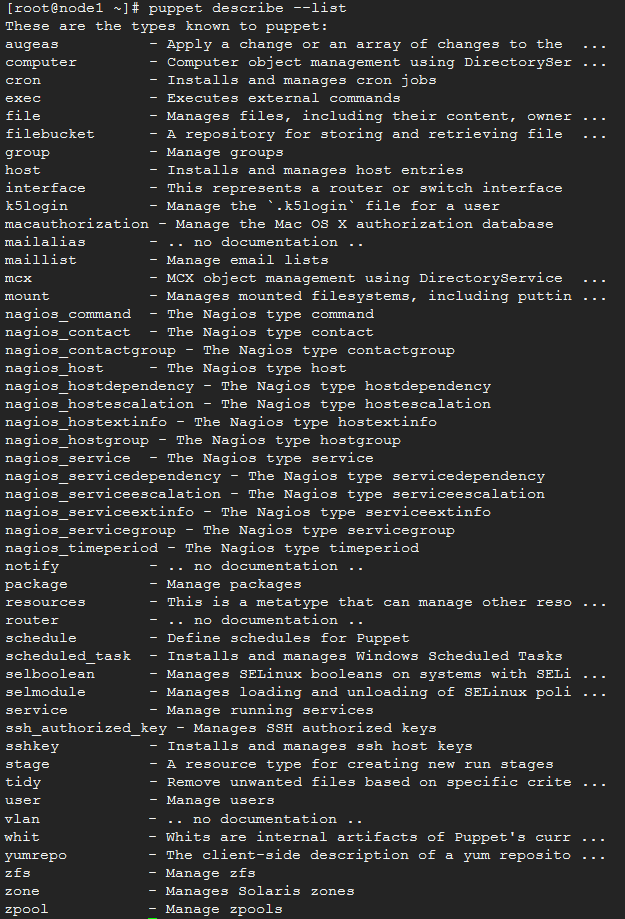
查看具体资源:
puppet describe resource_name
如puppet describe package
puppet资源定义:
定义资源:
type {'title':
attribute => value,
........
}
type只能是小写字符;title是一个字符串,在同一类型中必须惟一;每一个属性之间需要用","隔开,最后一个","可省略。
puppet 从以下三个维度来对资源完成抽象:
- 相似的资源被抽象成同一种资源"类型",如程序包资源、用户资源及服务资源等;
- 将资源属性或状态的描述与其实现方式剥离开来,如仅说明安装一个程序包而不用关心其具体是通过yum、pkgadd、ports或是其它方式实现;
- 仅描述资源的目标状态,也即期望其实现的结果,而不是其具体过程,如"确定nginx 运行起来" 而不是具体描述为"运行nginx命令将其启动起来";
这三个也被称作puppet 的资源抽象层(RAL)
RAL 由type( 类型) 和provider( 提供者,即不同OS 上的特定实现)组成。
资源属性中的三个特殊属性:
Name/Namevar:可简称为name;
ensure:资源的目标状态;
Metaparameters:元参数或元属性;
puppet资源清单:
创建清单文件:后缀一般为.pp
test1.pp:
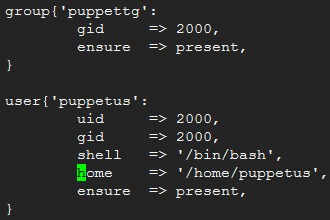
应用资源清单,使用puppet apply命令,帮助:puppet help apply
puppet apply -h\|--help -V\|--version -d\|--debug -v\|--verbose
-e\|--execute\] \[--detailed-exitcodes\] \[-L\|--loadclasses
-l\|--logdest syslog\|eventlog\|\
--catalog \

test1.pp就是资源清单,其中定义了各种资源,我们需要对各种资源及其属性、状态等有所了解。
各种资源 :
group:,组的管理,使用puppet describe group查看帮助
- name:组名;
- gid:GID;
- system:是否为系统组,true OR false;
- ensure:目标状态,present(创建)/absent(删除);
- members:成员用户;
user:用户的管理,puppet describe user
- name:用户名;
- uid: UID;
- gid:基本组ID;
- groups:附加组,不能包含基本组;
- comment:注释;
- expiry:过期时间 ;
- home:家目录;
- shell:默认shell类型;
- system:是否为系统用户 ;
- ensure:present/absent 存在/不存在;
- password:加密后的密码串;
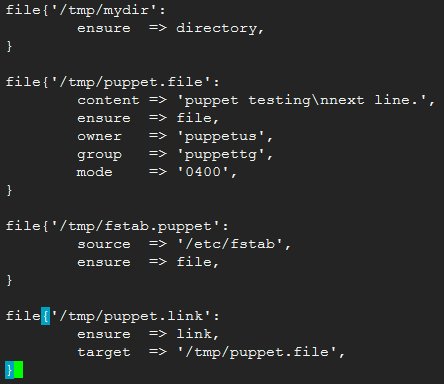
file:文件管理,包括它们的内容、所有权和权限,从属关系,内容可通过content属性直接给出,也可通过source属性根据远程服务器路径下载生成。
- ensure:`present`创建, `absent`删除, `file`创建普通文件, `directory`创建目录, link`创建软链接。file:类型为普通文件,其内容由content属性生成或复制由source属性指向的文件路径来创建;link:类型为符号链接文件,必须由target属性指明其链接的目标文件;directory:类型为目录,可通过source指向的路径复制生成,recurse属性指明是否递归复制;
- path:文件路径;
- source:源文件;当复制文件内容时需要指定
- content:文件内容;直接编写文件内容
- target:符号链接的目标文件;
- owner:属主
- group:属组
- mode:权限,支持八进制格式权限,以及u,g,o格式;
- atime/ctime/mtime:时间戳;
- access time:访问时间,atime,读取文件内容
- modify time: 修改时间, mtime,改变文件内容(数据)
- change time: 改变时间, ctime,元数据发生改变。
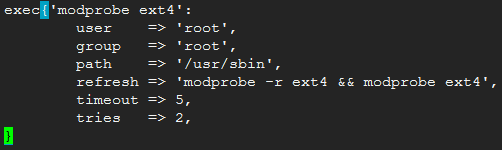
exec:执行外部命令。注意:exec资源中的任何命令都必须能够多次运行而不会造成损害------也就是说,它必须具有幂等性。
- command:要运行的命令,NameVar;
- cwd:用于运行该命令的目录,运行命令时的当前目录;
- creates:文件路径,仅此路径表示的文件不存在时,command方才执行;
- user/group:运行命令的用户身份;
- path:用于执行命令的搜索路径。如果没有指定路径,则命令必须完全限定。
- onlyif:指定一个命令,此命令正常(退出码为0)运行时,当前command才会运行;
- unless:指定一个命令,此命令非正常(退出码为非0)运行时,当前command才会运行;
- refresh:接收到其他资源发来的refresh通知时,默认是重新执行当前command,此属性可改变这种默认行为,使用这里指定的替代命令;
- refreshonly:仅接收到订阅的资源的通知时方才运行;
- returns:期望的状态返回值,返回非此值时表示命令执行失败;
notify:向代理运行时日志发送一个任意的消息
- message:要发送的消息内容,NameVar;
- name:消息名称;
cron:管理cron任务计划
- command:要执行的任务;
- ensure:present/absent;
- hour:
- minute:
- monthday:
- month:
- weekday:
- user:以哪个用户的身份运行命令
- target:添加为哪个用户的任务
- name:cron job的名称;
- environment:运行时的环境
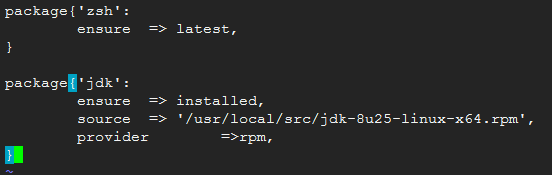
package:包管理
ensure:installed,latest,VERSION(2.3.1-2.el7),present,absent
name:程序包名称;
source:包来源,可以是本地文件路径或URL;
provider:指明安装方式;rpm/yum/...
service:管理运行的服务
- enable:是否开机自启:true(开机自启)、false(不自启)、manual(手动);
- ensure:running\true(开启), stopped/false(停止);
- name:服务名称,NameVar;
- binary:若服务不是systemctl/service 启动,则需规定启动命令;如nginx -s start;
- path:如果不是systemctl/service 这样启动服务,而是通过脚本启动,指明path路径。多个值应该由冒号分隔,或者作为数组提供。脚本的搜索路径,默认为/etc/rc.d/init.d/;
- hasrestart:是否支持restart 这个参数重启;true/fault ;true 表示支持;
- hasstatus:是否支持status 这个参数查看状态;true/false;
- start:手动定义启动命令;
- stop:手动定义关闭命令;
- status:若hasstatus 为fals,手动定义查看信息命令;
- restart:若hasrestart 为false,手动定义reload操作;
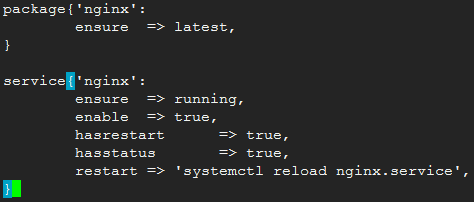
特殊属性:Metaparameters
资源之间是有次序的,也就是相互之间有依赖关系,puppet提供四个元参数定义资源间的相关性------before、require、notify 、subscribe。
这四个元参数都以另外的其它资源或资源数组作为其值,这也称作资源 引用;
资源引用要通过"Type'title'"的方式进行,如User'magedu' ;
注意:资源引用时,其类型名的首字母要大写
依赖关系:before/require
被依赖的资源中定义:before,本资源需要在哪些资源之前运行
依赖的资源中定义:require,本资源运行需要哪些资源已经运行
三种实现方法:
①A before B : B依赖于A,定义在A 资源中:
{
before => Type'B',
}
②B require A : B依赖于A,定义在B 资源中:
{
require => Type'A',
}
③ A -> B,B依赖于A,链式依赖
通知关系 :notify/subscribe,通知/订阅
被依赖的资源中使用:notify,本资源有变动,主动通知其他资源
监听其他资源的资源:subscribe,本资源主动监听其他资源是否有变动
① notify:A notify B:B依赖于A,且A发生改变后会通知B;定义在A资源中:
{
notify => Type'B',
}
② subscribe:B subscribe A:B依赖于A,且B监控A资源的变化产生的事件;定义在B资源中:
{
subscribe => Type'A',
}
③ A ~> B ,B依赖于A缩写版,链式通知
puppet中的变量及其作用域:
变量名均以开头,赋值符号=;任何非正则表达式类型的数据均可赋值给变量; variable_name=value
作用域scope:定义代码的生效范围,以实现代码间隔离;
scope可用于限定变量及资源默认属性的作用 范围,但不能用于限定资源名称及资源引用的生效范围。
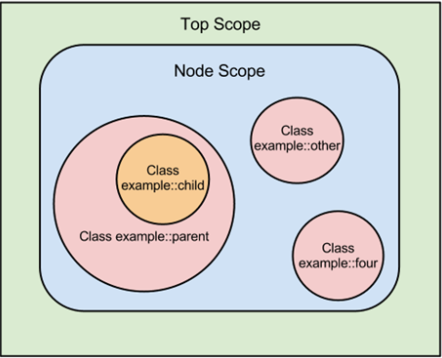
变量的数据类型:
- 字符型:引号可有可无;但单引号为强引用,双引号为弱引用;支持转义符;
- 数值型:默认均识别为字符串,仅在数值上下文才以数值对待;
- 数组:\[\]中以逗号分隔元素列表;
- 布尔型值:true, false;不能加引号;
- hash:{}中以逗号分隔k/v数据列表; 键为字符型,值为任意puppet支持的类型;{ 'mon' => 'Monday', 'tue' => 'Tuesday', };
- undef:从未被声明的变量的值类型;
正则表达式 :
(?<ENABLED OPTION>:<PATTERN>)
(?-<DISABLED OPTION>:<PATTERN>)
OPTIONS:
i:忽略字符大小写;
m:把.当换行符;
x:忽略<PATTERN>中的空白字符;
注意:不能赋值给变量,仅能用在接受=~或!~操作符的位置;
puppet的变量种类
puppet 种类有三种,为facts,内建变量和用户自定义变量。
facts:
由facter提供;top scope;使用facter -p查看所有facter变量
内建变量:
master端变量:servername, serverip, $serverversion
agent端变量:clientcert, clientversion, $environment
parser变量:$module_name
用户自定义变量:
每个变量两种引用路径:
相对路径:
绝对路径:$::scope::scope::variable
表达式:
比较操作符:==,!=,<,<=,>,>=,=~,!~,in
逻辑操作符:and,or,!
算术操作符:+,-,*,/,%,>>, <<
条件语句:if语句、case语句、slector语句,unless语句
类:class
用于公共目的的一组资源,是命名的代码块,创建后可在puppet全局进行调用,类可以被继承;
语法格式:
class class_name {
。。。puppet code 。。。
}
注意:类名只能是小写字母开头,可包含小写字母、数字、下划线等
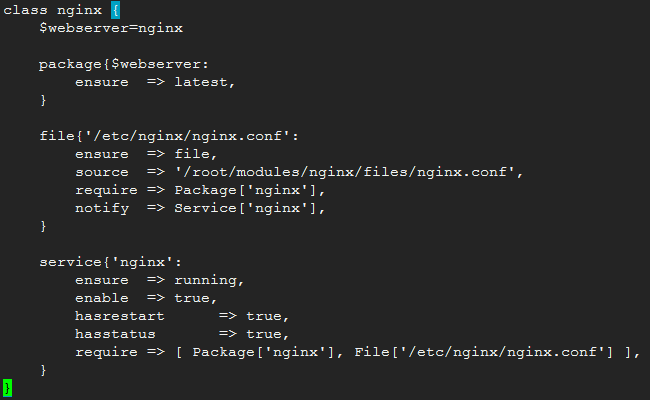
要执行类,需要声明,四种声明方法:
声明方式1:include
include class_name,class_name,。。。
定义能够接受参数的类:
class class_name(arg1=value1,arg2=value2){
...puppet code ...
}
声明方式2:像定义一个资源一样声明,带参数:
class{'class_name':
arg1 => value1,
arg2 => value2,
}
声明方式3:require
声明方式4:ENC
类继承 :
定义方式:
class base_class::class_name inherits base_class {
。。。。puppet code 。。。。
}
类继承时:
1)声明子类时,其基类会被自动首先声明;
2)基类成为了子类的父类作用域,基类中的变量和属性默认值会被子类复制一份;
3)子类可以覆盖父类中同一资源的相同属性的值;
模版 :基于ERB模版语言
在静态文件中使用变量等编程元素生成适用于多种不同的环境的文本文件(配置文件):Embedded RuBy,用于实现在文本文件中嵌入ruby代码,原来的文本信息不会被改变,但ruby代码会被执行,执行结果将直接替换原来代码。
在资源中使用模版:一般是file资源中
file中的source改为content,因为模版需要使用template()函数执行,生成的是数据流,file的内容就来自这个数据流。
content => template(/somepath/tempatefile_name)
模块:module
到目前为止,资源申报、定义类、声明类等所有功能都只能在一个manifest文件中实现,但这却非最有效的基于puppet 管理IT基础架构的方式;
实践中,一般需要把manifest文件分解成易于理解的结构,例如将类文件、配置文件甚至包括后面将提到的模块文件等分类存放,并且通过某种机制在必要时将它们整合起来;
这种机制即"模块",它有助于以结构化、层次化的方式使用 puppet,而puppet则基于"模块自动装载器"完成模块装载;
从另一个角度来说,模块实际上就是一个按约定的、预定义的结构存放了多个文件或子目录的目录,目录里的这些文件或子目录必须遵循其命名规范;puppet会按此种规范在特定位置查找所需的模块文件,不过,这些特定目录也可以通过puppet的配置参数modulepath定义。
module layout:目录结构

module_name/ #模块名称,也即模块目录名称
manifests/ #包含当前模块的所有manifest文件;每个manifest文件必包含一个类或一个定义的类,此文件访问路径格式为 "ModuleName::SubDirectoryName::ManifestFileName" ,注意manifiest文件名不需要其后缀.pp
init.pp #只能包含一个单独的类定义,且类的名称必须与模块名称相同
files/ #静态文件,引用方式: puppet:///modules/module_name/file_name
templates/ #模版文件目录,template('module_name/template_file_name')
lib/ #插件目录
tests/ #当前模块的使用帮助文件及示例文件
spec/ #类似于tests目录,存储lib目录下定义的插件的使用帮助及示例文件
模块管理命令:
puppet module <action> --environment production --modulepath
ACTIONS:
build Build a module release package.
changes Show modified files of an installed module.
generate Generate boilerplate for a new module.
install Install a module from the Puppet Forge or a release archive.
list List installed modules
search Search the Puppet Forge for a module.
uninstall Uninstall a puppet module.
upgrade Upgrade a puppet module.

通过上述命令结果,默认的模块路径有三个。
创建一个自己的模块,如叫做nginx:
mkdir -pv /etc/puppetlabs/code/modules/nginx/{manifest,files,templates,tests,lib,spec}
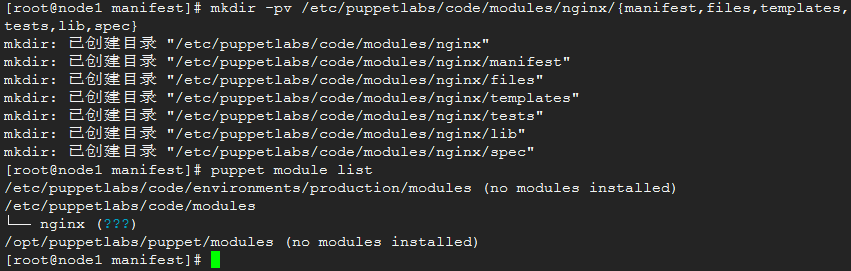
只是创建了一堆目录,就有了一个模块。在其中添加内容:在manifests中创建init.pp,files中增加静态文件,templates增加模版文件等。
使用模块中的类:
puppet apply --modulepath=/root/dev/modules -e "include ntpd::server"