在计算机视觉(CV)领域,图像处理是所有高级任务的基石------从手机美颜、人脸识别,到安防监控、自动驾驶、医疗影像分析,背后都离不开"对图像的加工、分析与理解"。而OpenCV与YOLO,正是支撑这些场景落地的两大核心工具:OpenCV负责"图像的基础处理与预处理",是CV领域的"瑞士军刀";YOLO负责"目标检测与识别",是当前最主流、最高效的实时检测算法。
很多开发者入门图像处理时,容易陷入两个误区:要么只学OpenCV的API调用,不懂底层图像处理原理,遇到复杂场景(如光照不均、噪声干扰)无从下手;要么盲目套用YOLO模型,不清楚模型与图像处理的关联,导致检测精度低、部署卡顿。
本文拒绝碎片化知识点堆砌,以"图像处理核心原理"为线索,先讲清楚图像的本质与基础操作,再拆解OpenCV的核心功能与底层逻辑,接着深入YOLO算法的原理与实战,最后结合两者的协同场景,带你打通"图像处理→目标检测"的完整链路。无论是CV入门新手,还是需要落地项目的开发者,都能从本文掌握可复用的原理、技巧与实战代码,真正做到"懂原理、会实操、能落地"。
重点:文中所有原理讲解均搭配通俗类比,OpenCV与YOLO的代码片段均为可直接复制运行的实战版本,同时补充生产级优化技巧与面试高频考点,兼顾入门与进阶,全程贴合技术博客的实用性与可读性。
一、先搞懂:图像处理的核心逻辑(基础铺垫)
在学习OpenCV和YOLO之前,我们首先要明确:图像处理的本质是什么?简单来说,图像处理是将现实场景的连续图像,转化为计算机可识别的离散数据,再通过数学运算与算法,提取有用信息、优化图像质量或实现目标识别,核心链路可概括为:图像采集→预处理→特征提取→高级分析(识别、检测等)。
1.1 图像的本质:从连续到离散的数字化映射
现实世界中的图像(如相机拍摄的画面)是连续的------空间坐标(x,y)和灰度/颜色值均连续,可用二维函数f(x,y)表示,其中x、y为空间坐标,f(x,y)为该点的亮度或色彩强度。而计算机无法直接处理连续图像,必须通过"采样"和"量化"两个步骤,将其转化为离散的数字图像:
-
采样:将连续的空间坐标(x,y)映射为整数像素坐标(i,j),相当于把图像"分割"成一个个独立的像素点,像素是离散图像的基本单位;
-
量化:将连续的灰度/颜色值,映射为有限个整数等级(如8位灰度图的灰度值范围为0-255,0代表纯黑,255代表纯白),完成颜色信息的数字化。
最终,数字图像在计算机中以像素矩阵的形式存储:灰度图是单通道矩阵,形状为(高度,宽度);彩色图多为三通道矩阵(如RGB、BGR),形状为(高度,宽度,通道数),每个通道对应一种基础颜色的像素值。
1.2 图像处理的核心流程(必懂)
无论何种图像处理场景,核心流程都离不开以下4步,OpenCV和YOLO的所有操作都围绕这个流程展开:
-
图像采集:通过相机、摄像头、图像文件等方式获取原始图像,这是图像处理的输入;
-
图像预处理:优化原始图像质量,消除噪声、统一格式,为后续分析提供可靠输入(这是OpenCV的核心应用场景);
-
特征提取:从预处理后的图像中,提取具有辨识度的关键信息(如边缘、纹理、颜色特征),是连接基础处理与高级分析的核心环节;
-
高级分析:基于提取的特征,实现目标检测、识别、分割等任务(这是YOLO的核心应用场景)。
通俗类比:这就像我们"识别一张照片中的猫"------先通过眼睛(采集)看到照片,再眯眼调整焦距、适应光线(预处理),接着注意到猫的轮廓、耳朵形状等特征(特征提取),最后判断出"这是一只猫"(高级分析)。
1.3 核心数学基础(极简理解)
图像处理的底层依赖简单的数学运算,无需深入研究复杂公式,掌握以下3个核心即可:
-
矩阵运算:图像本身就是矩阵,所有像素操作(如亮度调整、图像叠加)本质都是矩阵的加减乘除;
-
卷积运算:图像平滑、边缘检测的核心,通过一个"卷积核"(小矩阵)遍历整个图像矩阵,实现像素值的加权计算;
-
阈值处理:将图像的灰度值按照设定阈值分割为"黑"和"白",是图像分割、目标提取的基础。
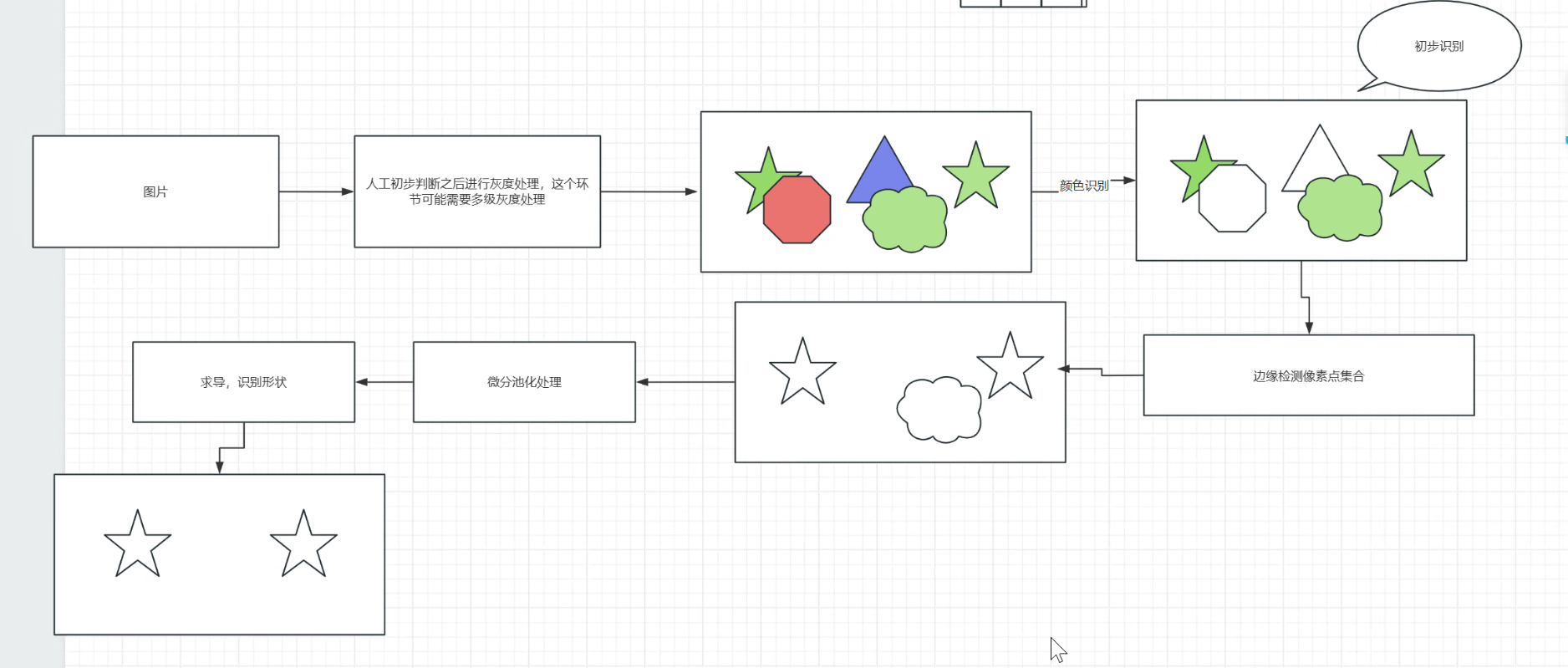
二、OpenCV图像处理原理:从基础操作到核心应用
OpenCV(Open Source Computer Vision Library)是开源的计算机视觉库,支持Python、C++、Java等多种语言,封装了海量图像处理的API,核心作用是"完成图像预处理与基础分析",是所有CV项目的"入门必备工具"。其底层原理围绕"像素矩阵的操作与优化"展开,所有API本质都是对像素的数学运算。
2.1 OpenCV核心定位:图像处理的"瑞士军刀"
OpenCV的核心价值的是"简化图像处理的复杂度"------无需手动实现卷积、阈值等底层算法,只需调用API即可完成从图像读取、预处理到特征提取的所有操作。其核心应用场景分为3类:
-
图像基础操作:读取、显示、保存、尺寸调整、像素修改;
-
图像预处理:降噪、增强、几何变换、阈值分割;
-
基础特征提取:边缘检测、轮廓提取、颜色提取。
注意:OpenCV读取彩色图像时,默认采用BGR通道顺序(而非我们常见的RGB),这是高频踩坑点,后续实战会重点说明。
2.2 OpenCV核心原理与实操(结合代码)
下面结合"实战代码+原理解析",讲解OpenCV最核心的5个操作,覆盖80%的预处理场景,代码基于Python(最易入门),可直接复制运行。
(1)基础操作:图像的读取、显示与保存
核心原理:通过API读取图像文件,将其转化为NumPy矩阵(像素矩阵),再通过矩阵操作实现显示与保存,本质是"文件与像素矩阵的相互转换"。
实战代码:
python
import cv2
import numpy as np
# 1. 读取图像(3种常用模式)
# cv2.IMREAD_COLOR:默认模式,读取彩色图像(BGR通道),忽略Alpha通道
img = cv2.imread("test.jpg", cv2.IMREAD_COLOR)
# cv2.IMREAD_GRAYSCALE:读取灰度图像(单通道)
img_gray = cv2.imread("test.jpg", cv2.IMREAD_GRAYSCALE)
# cv2.IMREAD_UNCHANGED:读取原始图像,保留Alpha通道(透明通道)
img_original = cv2.imread("test.jpg", cv2.IMREAD_UNCHANGED)
# 2. 显示图像(弹出窗口)
cv2.imshow("彩色图像(BGR)", img)
cv2.imshow("灰度图像", img_gray)
# 等待按键(0表示无限等待,按下任意键关闭窗口)
cv2.waitKey(0)
# 关闭所有显示窗口(避免内存泄漏)
cv2.destroyAllWindows()
# 3. 保存图像
cv2.imwrite("gray_test.jpg", img_gray)
print("灰度图像保存成功!")
# 查看图像基本属性
print(f"彩色图像形状(高度, 宽度, 通道数):{img.shape}") # 例:(480, 640, 3)
print(f"灰度图像形状(高度, 宽度):{img_gray.shape}") # 例:(480, 640)
print(f"像素数据类型:{img.dtype}") # 通常为uint8(0-255)关键说明:OpenCV的坐标原点在图像左上角,x轴向右、y轴向下,后续的像素操作、几何变换均基于此坐标系。
(2)图像预处理:降噪(核心操作)
核心原理:原始图像在采集、传输过程中,会引入噪声(如高斯噪声、椒盐噪声),降噪的核心是"在保留图像细节的同时,抑制噪声干扰",本质是通过卷积运算实现像素的平滑处理。
常见降噪算法(OpenCV内置):
-
高斯滤波:利用高斯核进行加权平均,抑制高斯噪声(如相机传感器热噪声),平滑效果柔和,不破坏图像细节;
-
中值滤波:取邻域像素的中位数,有效抑制椒盐噪声(如传输错误导致的黑白杂点),保留边缘细节;
-
双边滤波:结合空间距离和灰度相似度加权,兼顾降噪与边缘保留,适用于需要保留细节的场景(如人脸图像)。
实战代码(高斯滤波+中值滤波对比):
python
import cv2
# 读取带噪声的图像
img = cv2.imread("noise_test.jpg")
# 1. 高斯滤波(ksize为卷积核大小,必须是奇数;sigmaX为高斯标准差)
gaussian_blur = cv2.GaussianBlur(img, ksize=(5, 5), sigmaX=1.5)
# 2. 中值滤波(ksize为卷积核大小,必须是奇数)
median_blur = cv2.medianBlur(img, ksize=5)
# 显示对比
cv2.imshow("原始带噪声图像", img)
cv2.imshow("高斯滤波后", gaussian_blur)
cv2.imshow("中值滤波后", median_blur)
cv2.waitKey(0)
cv2.destroyAllWindows()(3)图像预处理:增强(提升画质)
核心原理:通过调整像素的灰度值、对比度,突出图像中的有用信息,改善过暗、过亮或对比度低的图像,本质是"对像素灰度值的映射变换"。
常见增强方法:
-
灰度变换:线性变换拉伸灰度范围,对数变换增强暗部细节,伽马变换校正显示偏差;
-
直方图均衡化:通过重新分配灰度值,使图像直方图均匀分布,提升全局对比度,适用于光照不均的图像。
实战代码(直方图均衡化增强):
python
import cv2
import matplotlib.pyplot as plt
# 读取灰度图像(直方图均衡化常用于灰度图)
img_gray = cv2.imread("dark_test.jpg", cv2.IMREAD_GRAYSCALE)
# 直方图均衡化
equalized_img = cv2.equalizeHist(img_gray)
# 显示对比(用matplotlib显示,更直观)
plt.figure(figsize=(10, 4))
# 原始图像
plt.subplot(1, 2, 1)
plt.imshow(img_gray, cmap="gray")
plt.title("原始暗图像")
plt.axis("off")
# 增强后图像
plt.subplot(1, 2, 2)
plt.imshow(equalized_img, cmap="gray")
plt.title("直方图均衡化增强后")
plt.axis("off")
plt.show()(4)几何变换:尺寸调整、旋转、裁剪
核心原理:通过坐标映射与插值运算,调整图像的空间位置和尺寸,解决图像尺寸不一致、角度偏移等问题,本质是"像素坐标的变换与重新赋值"。
实战代码(常用几何变换):
python
import cv2
img = cv2.imread("test.jpg")
h, w = img.shape[:2] # 获取图像高度和宽度
# 1. 尺寸调整(缩放)
# 方法1:指定目标尺寸(宽度, 高度)
resized1 = cv2.resize(img, (320, 240))
# 方法2:按比例缩放(缩小到50%)
resized2 = cv2.resize(img, (0, 0), fx=0.5, fy=0.5)
# 方法3:放大1.5倍,使用双三次插值(精度更高)
resized3 = cv2.resize(img, (0, 0), fx=1.5, fy=1.5, interpolation=cv2.INTER_CUBIC)
# 2. 图像旋转(以图像中心为旋转中心,旋转90度,缩放比例1.0)
M = cv2.getRotationMatrix2D((w/2, h/2), 90, 1.0) # 获取旋转矩阵
rotated = cv2.warpAffine(img, M, (w, h)) # 应用旋转
# 3. 图像裁剪(ROI:感兴趣区域,语法:img[y_start:y_end, x_start:x_end])
roi = img[50:200, 100:300] # 裁剪y轴50-200、x轴100-300的区域
# 显示所有结果
cv2.imshow("原始图像", img)
cv2.imshow("指定尺寸缩放", resized1)
cv2.imshow("比例缩放", resized2)
cv2.imshow("旋转90度", rotated)
cv2.imshow("裁剪ROI", roi)
cv2.waitKey(0)
cv2.destroyAllWindows()(5)特征提取:边缘检测(核心中的核心)
核心原理:边缘是图像中灰度值突变的区域(如目标轮廓),边缘检测的核心是"通过卷积运算捕捉灰度梯度的极值点",提取目标的轮廓特征,为后续目标检测、分割打下基础。
OpenCV常用边缘检测算法:
-
Canny边缘检测:工业界常用标准,分四步(高斯降噪→计算梯度→非极大值抑制→双阈值筛选),边缘检测效果最优;
-
Sobel算子:引入方向权重,对噪声有一定抑制,可检测水平、垂直方向的边缘;
-
Laplacian算子:对噪声敏感,可检测所有方向的边缘,但边缘不够细腻。
实战代码(Canny边缘检测):
python
import cv2
img = cv2.imread("test.jpg")
# 1. 先进行高斯降噪(减少噪声对边缘检测的干扰)
img_blur = cv2.GaussianBlur(img, (5, 5), 0)
# 2. Canny边缘检测(minVal和maxVal为双阈值,minVal以下的边缘被丢弃)
canny_edges = cv2.Canny(img_blur, minVal=50, maxVal=150)
# 显示结果
cv2.imshow("原始图像", img)
cv2.imshow("Canny边缘检测", canny_edges)
cv2.waitKey(0)
cv2.destroyAllWindows()2.3 OpenCV关键注意事项(避坑重点)
-
通道顺序:OpenCV默认读取为BGR通道,而Matplotlib、Pillow等工具默认使用RGB通道,直接用Matplotlib显示OpenCV读取的彩色图像会出现"蓝红反转",需用cv2.cvtColor(img, cv2.COLOR_BGR2RGB)转换;
-
像素值范围:OpenCV中像素值默认是0-255(uint8类型),进行数值运算时需注意溢出(如像素值加10后超过255,需手动截断);
-
卷积核大小:高斯滤波、中值滤波等操作的卷积核大小,必须是奇数(如3、5、7),否则无法对称计算;
-
内存释放:使用cv2.imshow后,必须调用cv2.destroyAllWindows()关闭窗口,避免内存泄漏;读取图像失败时,img会返回None,需提前判断,避免后续报错。
三、YOLO目标检测原理:从"一眼识别"到实时落地
YOLO(You Only Look Once)是当前最主流的实时目标检测算法,核心优势是"快且准"------不同于传统目标检测算法的"先猜区域、再识别",YOLO只需一次神经网络计算,就能同时完成"目标定位"和"目标分类",就像人眼扫一眼就能识别出物体的位置和类别,适用于实时检测场景(如监控、自动驾驶)。
YOLO的核心逻辑是"端到端学习",将图像处理与目标检测整合为一个神经网络模型,无需手动提取特征(模型自动完成特征提取与目标识别),但它的性能依赖于输入图像的质量------这也是OpenCV与YOLO协同的核心意义:用OpenCV做预处理,提升图像质量,让YOLO检测更精准、更快速。
3.1 YOLO核心定位:实时目标检测的"标杆"
YOLO的核心价值是"打破图像处理与目标检测的壁垒",实现"输入一张图像,输出目标的位置、类别和置信度",其核心应用场景包括:
-
实时监控:安防场景中,实时识别人员、车辆、危险物品;
-
自动驾驶:识别行人、车辆、交通信号灯、路标等;
-
人脸检测:识别图像中的人脸,为后续人脸识别打下基础;
-
工业质检:检测产品的缺陷(如零件破损、污渍)。
YOLO的版本迭代(v1-v8),核心是不断优化"检测精度"和"速度",目前最常用的是YOLOv5、v7、v8,其中YOLOv8兼顾精度与速度,是生产环境的首选。
3.2 YOLO核心原理(通俗拆解)
YOLO的原理看似复杂,实则可拆解为"4步流程",用通俗的语言就能理解,核心思路是"拆格子、分任务、做预测、去重留优":
第一步:统一图像尺寸(标准化输入)
无论输入图像的尺寸是多大(如1080P、4K),YOLO都会先将其缩放到固定尺寸(如640×640),这就像"统一作业本大小",方便模型统一处理,同时避免尺寸差异影响检测精度。
第二步:图像网格划分(分任务)
YOLO会将缩放后的图像,均匀分成S×S个小格子(如YOLOv1分为7×7=49个格子),核心规则是:如果一个目标的中心点落在某个格子里,就由这个格子负责预测该目标。
通俗类比:就像老师给学生分配任务,把班级(图像)分成多个小组(格子),每个小组负责检查自己的"地盘",看看有没有目标,有就上报目标信息。
第三步:格子预测目标信息(写"报告")
每个格子需要预测3类信息,相当于给模型写一份"目标报告":
-
边界框(Bounding Box):预测多个可能包含目标的方框,每个方框包含4个参数(x,y,w,h)------x、y是方框中心点相对于格子左上角的位置,w、h是方框的宽和高(占整幅图像的比例);
-
置信度(Confidence):表示这个方框包含目标的概率,以及方框的精准度(如置信度0.9,代表90%的概率有目标,且框得很准);
-
类别概率(Class Probability):预测方框内目标属于某一类别的概率(如检测80类目标,就输出80个概率,概率最高的类别即为目标类别)。
后续版本(如YOLOv5及以后)引入了"锚框"(Anchor Box)优化:不再让格子"瞎猜"边界框大小,而是提前预设几个常用尺寸的框(如小框对应猫、大框对应汽车),格子在锚框基础上微调,大幅提升小目标检测精度。
第四步:非极大值抑制(NMS)------去重留优
由于多个格子可能会预测出同一个目标(如一只猫的中心点在A格子,但B格子也预测了一个框框住这只猫),会导致重复标注,因此需要通过NMS筛选最优框,流程如下:
-
将所有预测框按"综合置信度"(类别概率×置信度)排序,留下综合置信度最高的框;
-
删除所有与该框重叠面积超过阈值(如50%)的框(认为是重复标注);
-
重复以上两步,直到每个目标都只留下1个最精准的框。
至此,YOLO完成了"目标检测"的全部流程------整个过程只需一次神经网络推理,因此速度极快,能满足实时检测需求(如YOLOv8在普通GPU上,可实现每秒几十帧的检测速度)。
3.3 YOLO实战:基于YOLOv8+OpenCV的实时检测
下面结合OpenCV与YOLOv8,实现"图像/视频流实时目标检测",代码可直接复制运行,核心逻辑是:用OpenCV读取图像/视频流,做简单预处理,再用YOLOv8模型推理,最后用OpenCV将检测结果(边界框、类别、置信度)绘制在图像上。
(1)环境准备
安装所需依赖(Python环境):
python
# 安装OpenCV
pip install opencv-python
# 安装YOLOv8官方库(ultralytics)
pip install ultralytics(2)图像目标检测(基础实战)
核心流程:OpenCV读取图像→预处理(降噪、尺寸调整)→YOLOv8推理→OpenCV绘制检测结果→显示与保存。
python
from ultralytics import YOLO
import cv2
# 1. 加载YOLOv8模型(nano版本,体积小、速度快,适合入门)
model = YOLO("yolov8n.pt") # 自动下载预训练权重
# 2. 用OpenCV读取图像,并做预处理
img = cv2.imread("test.jpg")
# 预处理:高斯降噪(减少噪声,提升检测精度)
img_blur = cv2.GaussianBlur(img, (3, 3), 0)
# 预处理:调整图像尺寸(与YOLOv8默认输入尺寸一致,640×640)
img_resized = cv2.resize(img_blur, (640, 640))
# 3. YOLOv8推理(detect模式,检测目标)
results = model(img_resized, conf=0.5) # conf=0.5:置信度阈值,过滤低置信度预测框
# 4. 用OpenCV绘制检测结果(边界框、类别、置信度)
# 提取检测结果(边界框、类别、置信度)
for result in results:
boxes = result.boxes # 边界框信息
for box in boxes:
# 获取边界框坐标(x1,y1:左上角;x2,y2:右下角)
x1, y1, x2, y2 = map(int, box.xyxy[0])
# 获取类别名称和置信度
cls = model.names[int(box.cls[0])]
conf = round(float(box.conf[0]), 2)
# 绘制边界框(红色,线宽2)
cv2.rectangle(img_resized, (x1, y1), (x2, y2), (0, 0, 255), 2)
# 绘制类别和置信度(白色字体,背景黑色)
cv2.putText(img_resized, f"{cls} {conf}", (x1, y1-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# 5. 显示与保存结果
cv2.imshow("YOLOv8目标检测结果", img_resized)
cv2.waitKey(0)
# 保存检测结果
cv2.imwrite("detection_result.jpg", img_resized)
cv2.destroyAllWindows()(3)视频流实时检测(进阶实战)
核心流程:OpenCV打开摄像头/视频文件→逐帧读取→预处理→YOLO推理→绘制结果→实时显示,适用于监控、自动驾驶等实时场景。
python
from ultralytics import YOLO
import cv2
# 1. 加载YOLOv8模型
model = YOLO("yolov8n.pt")
# 2. 打开视频源(三选一,取消注释即可)
# cap = cv2.VideoCapture(0) # USB摄像头(默认设备号0)
# cap = cv2.VideoCapture("test_video.mp4") # 本地视频文件
cap = cv2.VideoCapture("rtsp://admin:password@192.168.1.100:554/stream1") # RTSP网络流(监控摄像头)
# 3. 设置视频参数(提升实时性,减少延迟)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 减少缓冲,降低延迟
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
# 4. 逐帧处理视频流
while cap.isOpened():
# 读取一帧图像
ret, frame = cap.read()
if not ret:
break # 读取失败,退出循环
# 预处理:高斯降噪、尺寸调整
frame_blur = cv2.GaussianBlur(frame, (3, 3), 0)
frame_resized = cv2.resize(frame_blur, (640, 640))
# YOLOv8推理
results = model(frame_resized, conf=0.5)
# 绘制检测结果
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
cls = model.names[int(box.cls[0])]
conf = round(float(box.conf[0]), 2)
# 绘制边界框
cv2.rectangle(frame_resized, (x1, y1), (x2, y2), (0, 0, 255), 2)
# 绘制类别和置信度
cv2.putText(frame_resized, f"{cls} {conf}", (x1, y1-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# 实时显示检测结果
cv2.imshow("YOLOv8实时检测", frame_resized)
# 按下q键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()3.4 YOLO关键注意事项(避坑重点)
-
模型选择:YOLOv8有多个版本(nano、small、medium、large),版本越大,精度越高,但速度越慢、占用内存越多,入门选nano版本,生产环境根据需求选择;
-
置信度阈值:conf参数(默认0.25)可调整,值越高,检测越严格(减少误检),值越低,检测越宽松(可能出现误检),建议根据场景调整为0.5左右;
-
图像预处理:YOLO对图像质量敏感,输入图像若有大量噪声、光照不均,会导致检测精度下降,建议先用OpenCV做降噪、增强预处理;
-
实时性优化:视频流检测时,可通过"降低图像尺寸(如640×640)、使用更小的模型、启用GPU加速"提升帧率,避免卡顿;
-
自定义训练:预训练模型仅支持80类常见目标(如人、车、猫),若需检测自定义目标(如工业零件、特定物品),需用标注数据训练自定义YOLO模型。
四、OpenCV与YOLO的协同逻辑:1+1>2的落地技巧
很多开发者会分开使用OpenCV和YOLO,但实际上,两者的协同才是CV项目落地的关键------OpenCV负责"输入优化",YOLO负责"核心检测",预处理的质量直接决定检测的精度和速度,两者的协同流程可总结为:
原始图像 → OpenCV预处理(降噪→增强→尺寸调整→边缘优化) → YOLO目标检测(推理→NMS筛选) → OpenCV结果可视化(绘制边界框→保存/显示)
4.1 协同核心场景(生产级实战)
-
光照不均场景:用OpenCV的直方图均衡化、伽马变换增强图像对比度,解决YOLO在暗环境、强光环境下检测精度低的问题;
-
噪声干扰场景:用OpenCV的高斯滤波、中值滤波降噪,避免噪声被YOLO误判为目标(如监控画面的雪花点、工业图像的污渍);
-
小目标检测场景:用OpenCV的图像放大、边缘增强,突出小目标的特征,配合YOLO的多尺度检测,提升小目标(如小零件、远处行人)的检测精度;
-
视频流低延迟场景:用OpenCV调整视频帧尺寸、减少缓冲,配合YOLO的轻量化模型,实现高帧率实时检测(如监控摄像头、无人机视频流)。
4.2 生产级优化技巧(提升精度与速度)
-
预处理优化:根据场景选择合适的预处理方法(如椒盐噪声用中值滤波,高斯噪声用高斯滤波),避免过度预处理导致特征丢失;
-
模型优化:启用GPU加速(YOLOv8支持CUDA),将图像尺寸调整为YOLO的默认输入尺寸(如640×640),减少模型推理时间;
-
参数优化:调整YOLO的置信度阈值(conf)和NMS阈值(iou),平衡误检率和漏检率;
-
结果优化:用OpenCV对YOLO的检测结果做后处理(如过滤过小的边界框、合并重叠框),提升结果的准确性。
五、面试高频题:OpenCV与YOLO必问10题(附通俗解析)
OpenCV与YOLO是CV面试的高频考点,常结合图像处理原理、实战场景考查,整理了10道最常考题,解析通俗贴合本文内容,面试时直接套用即可。
5.1 基础必问(初级面试)
-
考题1:OpenCV是什么?核心作用是什么? 解析:OpenCV是开源的计算机视觉库,支持多种编程语言,核心作用是实现图像的读取、预处理、特征提取等基础操作,是CV项目的基础工具,为后续目标检测、识别提供高质量输入。
-
考题2:OpenCV读取彩色图像时,默认的通道顺序是什么?如何转换为RGB通道? 解析:默认通道顺序是BGR;转换方法:使用cv2.cvtColor(img, cv2.COLOR_BGR2RGB),避免用Matplotlib显示时出现颜色反转。
-
考题3:YOLO是什么?核心优势是什么? 解析:YOLO是实时目标检测算法,全称You Only Look Once;核心优势是"端到端学习、快且准",只需一次神经网络推理,就能同时完成目标定位和分类,适用于实时检测场景。
-
考题4:图像预处理的核心目的是什么?OpenCV常用的预处理方法有哪些? 解析:核心目的是改善图像质量、消除噪声、统一格式,为后续分析提供可靠输入;常用方法:降噪(高斯滤波、中值滤波)、增强(直方图均衡化)、几何变换(尺寸调整、旋转)。
5.2 核心必问(中级面试)
-
考题5:OpenCV的Canny边缘检测分为哪几步?核心作用是什么? 解析:分4步:① 高斯降噪(抑制噪声);② 计算灰度梯度(捕捉边缘);③ 非极大值抑制(细化边缘);④ 双阈值筛选(保留有效边缘);核心作用是提取图像的轮廓特征,为目标检测、分割打下基础。
-
考题6:YOLO的核心原理是什么?简要说明其检测流程? 解析:核心原理是"网格划分+端到端推理";检测流程:① 统一图像尺寸;② 划分S×S网格,每个网格负责预测目标;③ 网格预测边界框、置信度、类别概率;④ 非极大值抑制(NMS)筛选最优框。
-
考题7:OpenCV与YOLO的协同逻辑是什么?为什么需要协同? 解析:协同逻辑:OpenCV做图像预处理(降噪、增强等),提升图像质量;YOLO基于预处理后的图像做目标检测,输出检测结果;OpenCV再绘制、显示结果。需要协同的原因:YOLO对图像质量敏感,预处理能提升检测精度和速度,避免噪声、光照不均等问题导致的误检、漏检。
-
考题8:YOLO中的NMS(非极大值抑制)是什么?核心作用是什么? 解析:NMS是筛选YOLO预测框的算法;核心作用是删除重复的预测框,保留每个目标的最优框,避免同一目标被多次标注,提升检测结果的准确性。
5.3 高级必问(中高级面试)
-
考题9:如何优化YOLO的检测精度和速度? 解析:① 精度优化:用OpenCV做预处理(降噪、增强),调整置信度和NMS阈值,自定义训练模型(适配特定目标);② 速度优化:使用轻量化模型(如YOLOv8n),启用GPU加速,降低图像尺寸,减少视频流缓冲。
-
考题10:请描述一个OpenCV+YOLO的实际应用场景,并说明其实现流程? 解析:以"监控场景的人员检测"为例,实现流程:① 用OpenCV打开RTSP网络流,逐帧读取监控画面;② 用OpenCV做高斯降噪、尺寸调整预处理;③ 用YOLOv8推理,检测画面中的人员;④ 用OpenCV绘制人员边界框和置信度,实时显示;⑤ 若检测到异常人员(如闯入禁区),触发告警。
六、总结:从原理到落地,打通图像处理全链路
图像处理的核心是"将图像转化为计算机可识别的数据,提取有用信息",而OpenCV与YOLO,正是支撑这一核心的两大工具:OpenCV是"基础基石",负责将原始图像优化为高质量输入,其底层是像素矩阵的数学运算;YOLO是"核心引擎",负责快速、精准地识别目标,其底层是端到端的神经网络学习。
对于入门者:先掌握OpenCV的基础操作与预处理原理,再上手YOLO的实战,理解两者的协同逻辑,避免"只会调用API,不懂底层原理";对于开发者:重点关注生产级优化技巧,结合场景选择合适的预处理方法和YOLO模型,平衡检测精度与速度;对于面试者:重点掌握核心原理、协同逻辑和常见问题,本文的面试真题解析可直接套用。
随着CV技术的发展,OpenCV和YOLO的应用场景会越来越广泛,从日常的手机美颜,到工业质检、自动驾驶,都离不开它们的支撑。后续可深入学习YOLO的自定义训练、OpenCV的高级特征提取,结合深度学习框架(如PyTorch、TensorFlow),实现更复杂的CV项目,真正做到"懂原理、会实操、能落地"。
如果觉得有收获,欢迎点赞、收藏,也可以留言讨论你在OpenCV、YOLO使用中遇到的问题,一起交流进步~