一、基础概念
Redis是一个开源的、基于内存的键值对(Key-Value)存储系统。常被用做缓存中间件,基于redis可以实现数据的快速读取、会话(Session)存储、排行榜、消息队列、分布式锁等能力。
二、Redis支持的数据结构
String(字符串)
最基本的类型,可以用于存储字符串,值得注意的是Redis的基本数据类型里,是没有整型、长整型、浮点型这些数字类型的结构的,这些在redis内部都会当作字符串类型存储下来。但是Redis封装了incre、decre命令,方便开发者进行整形的运算,实际内部会把字符串型数据,转成整数进行运算。
List(列表)
列表类型,Redis 3.2之前,List底层是用ZipList(压缩列表)和LinkedList(双向链表)组成。
ZipList :连续的内存空间,但是它不像数组一样,使用指针和下标可以快速的访问到每个元素(时间复杂度:O(1)),它访问元素时,必须从头/尾遍历到目标位置,所以时间复杂度是O(n),本质原因是因为数组存储的元素类型一样,占用的内存大小都是一样的,可以通过数组指针很方便的计算出中间元素的内存起始,而ZipList由于存储的元素内存大小都不一样,所以必须从表头开始,逐个计算每个元素的偏移量,直到目标位置(第一个元素可能只有1字节,第二个元素可能有100字节,而整型数组,java里每个元素都占4个字节)。且ZipList没有指针指向原数据,因此它占用的内存极低,几乎就是数据本身紧凑编码,适用于数据量小的列表。
在头尾插入数据时,由于ZipList记录了表头/表尾的偏移量,因此直接操作即可,无需移动其他元素,时间复杂度是O(1)。而在中间插入数据时,必须把后面的数据往后挪,因此时间复杂度是O(N)
LinkedList :双向链表,内存不连续,每个元素有指针指向前面的元素和后面的元素,查询时仍然需要从表头/表尾遍历到目标位置,时间复杂度为O(N)
而插入时,只需要修改相应位置的prev/next 指针即可,无需移动其他节点。
但是LinkedList有指针开销,每个元素都需要一个指针指向(16/24字节指针),内存利用率差,且内存不连续,缓存友好性差(CPU的L1、L2、L3哪怕只取4字节,一次也会读附近的Cache Line,通常 64 Byte数据到缓存中,所以连续内存的数据读取容易命中CPU缓存)
Redis 中,list 类型默认会优先使用 ZipList(满足:元素数量 < 512 且每个元素大小 < 64KB),当超出阈值后自动转为 LinkedList。
Redis 3.2之后,使用QuickList代替了ZipList和LinkedList,其实就是它们两个的结合体,QuickList本身是一个双向链表,但链表的每一个节点QuickListNode不是存储单个元素,而是存储一个ZipList,所有元素被分散的存储在多个ZipList中,这些ZipList再通过QuickListNode串联成双向链表。由于使用双向链表存储节点,所以还是有指针的额外内存,但是并不是每个数据都需要指针,多个数据可以合到一个ZipList中,通过ZipList降低了内存消耗,相当于在LinkedList的快速插入,和ZipList的低内存消耗两者间取了个折衷。
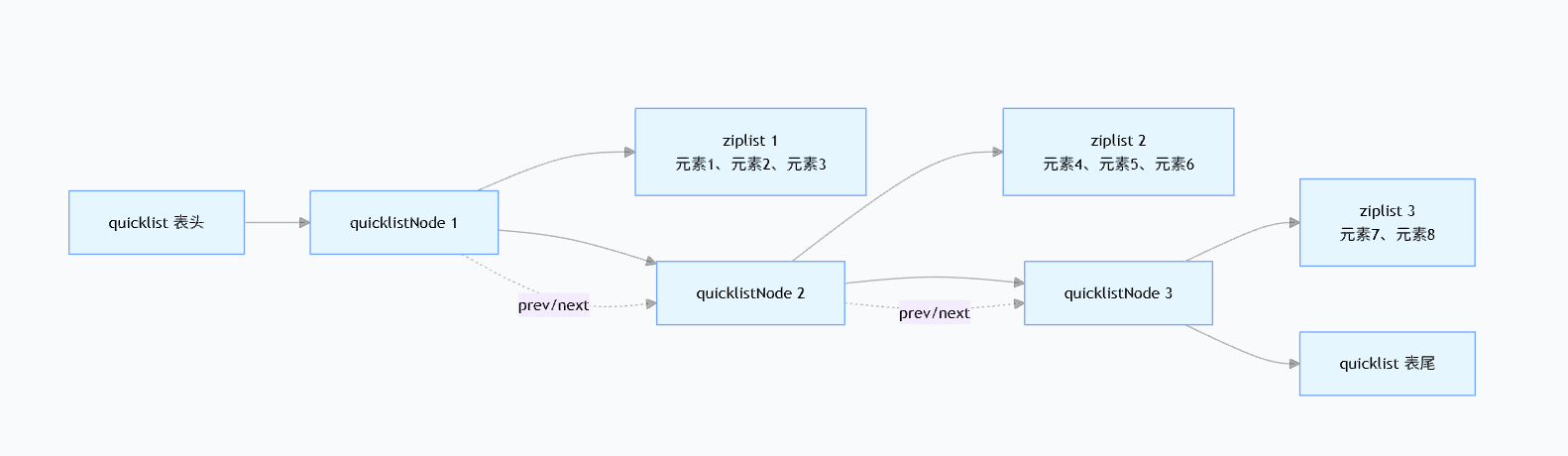
值得注意的是,redis的List数据结构中,ZipList存储的元素数量是可以自定义的,可以通过参数list-max-ziplist-size=-8配置,表示每个ZipList存8个元素,我们要取list里的第N个元素,redis内部就会通过这个配置,计算出第N个元素,位于第几个QuickListNode里,然后再通过ZipList的偏移量找到元素
Hash(哈希)
Redis 的 Hash 是一种键值对集合,专门用于存储 "字段 - 值"(field-value)形式的结构化数据,比如存储用户信息(name: "张三", age: 20, email: "xxx")
Hash数据结构,底层用的是ZipList(压缩列表)和HashTable(哈希表)。和List同理,当数据量小时
条件 1:Hash 中字段 - 值对的数量 ≤ 512 个(配置项:hash-max-ziplist-entries);
条件 2:Hash 中每个字段和值的长度 ≤ 64KB(配置项:hash-max-ziplist-value)。
它底层就是用的ZipList(3.2之前之后都是ZipList),通过一个一个偏移量从头往目标位置找,时间复杂度O(N)。
当超过阈值时,会自动转化成HashTable来存储,hashTable其实就是数组+链表(或者红黑树)来实现的了,类似JAVA中的HashMap。
数据量小时,其实ZipList利用内存连续性的O(N)复杂度时间和HashTable的O(1)时间几乎差不多,且省去了很多指针的内存空间,所以Redis内部采用了动态转换的方式。
Set(集合)
Redis 的 Set(集合)是一种无序、唯一的字符串集合,核心特性是自动去重(集合内不会有重复元素),并且支持丰富的集合运算(交集、并集、差集),尤其擅长集合运算、随机取元素、自动去重场景
Redis Set 会根据元素特征自动选择两种底层结构,核心是 intset(整数集合) 和 HashTable(哈希表),切换规则如下:
默认满足以下两个条件时,Set 用 intset 存储:
条件 1:集合中所有元素都是整数(如 1、100、-5,而非字符串 "1");
条件 2:集合中元素数量 ≤ 512 个(配置项:set-max-intset-entries)。
当任意条件不满足时(比如插入字符串元素、元素数超过 512),自动切换为 HashTable存储。
InSet是 Set 专属的紧凑结构,和 ziplist 原理类似但仅适配整数,查询 / 插入时会通过二分查找定位元素,InSet的优势是在内存上,不需要额外的指针开销,即使采用二分查找定位元素,时间复杂度也需要O(logn)。而大数据量时转化为HashTable是为了兼顾效率的,虽然多了很多指针的开销,但是HashTable索引的时间复杂度是O(1)。
ZSet(有序集合)
Redis 的 Zset(Sorted Set,有序集合)是 Redis 中最强大的数据结构之一 ------ 它兼具 Set 的唯一性(元素不重复)和有序性(每个元素关联一个浮点型分数 score,按 score 排序),支持按分数范围、排名范围快速查询,是实现排行榜、延时队列等场景的核心利器。
Redis Zset 同时使用两种结构来存储数据,ziplist(压缩列表) 用于小数据量场景,SkipList+ HashTable(跳表 + 哈希表) 用于大数据量场景。
小数据量的和上面是类似的。我们着重看更普遍的场景,也就是跳表 + 哈希表。
- SkipList(跳表)是 Zset 有序性的核心,它通过 "多层索引" 将有序查找的复杂度从 O(n) 降到 O(logn),比红黑树实现更简单、插入删除更高效;
- HashTable是为了弥补 SkipList的短板:SkipList按 member 查找需要遍历,而 HashTable可 O(1) 定位 member 的 score。
使用方式如下:
powershell
# 往articleSet新增文章 1001,初始阅读量 100
ZADD articleSet:20260324 100 1001
# 将articleSet里的文章1001,阅读量增加50
ZINCRBY articleSet:20260324 50 1001
# 查询articleSet里阅读量前 3 名的记录(WITHSCORES),按阅读量降序(ZREVRANGE)
ZREVRANGE articleSet:20260324 0 2 WITHSCORESBitmap(位图)
严格说,Bitmap并非Redis的独立的数据结构,而是基于 String 类型 实现的 "位操作" 功能 ------ 它将 String 视为连续的二进制位(bit)数组,每个位的取值为 0 或 1,支持按位设置、查询、统计等操作,是极致节省内存的高效结构,尤其适合海量二值状态(是 / 否、有 / 无)的存储与统计。
Redis 的 String 最大支持 512MB 容量,而 1 字节 = 8 位,因此一个 Bitmap 最多可存储 512MB×8=232 个二进制位(约 42.9 亿位)。
利用Bitmap的这种特性,可以用很少的内存存储亿级别的二值(也就是是和否)数据。举个例子,存储 1 亿用户的 "今日是否登录" 状态:
- 用 Set 存储登录用户 ID:假设每个 ID 是 8 字节,1 亿个需约 800MB 内存;
- 用 Bitmap:仅需 100000000÷8=12.5MB内存,差距近 64 倍。
类似的场景还有:用户签到、活跃统计、权限标记等
超日志(HyperLogLog)
Redis 的 HyperLogLog(简称 HLL)是一种概率型数据结构,专门用于海量数据的基数统计(即统计集合中不重复元素的个数,比如 UV、独立访客数),核心优势是:用极小的内存(约 12KB)就能统计超大规模的数据(理论上支持 2的64方个元素),代价是统计结果存在约 0.81% 的误差(可接受的近似值)。
往HLL里添加的可以是用户ID,IP地址等,查询出来的是这个HLL里不重复元素的个数,无论添加了多少个元素,一个HLL最多只会占用12KB的大小,这12KB内存被分成 16384 个 "桶",每个桶里只存一个数字 ------ 该桶内所有元素的哈希值中,末尾连续 0 的最大个数。然后利用末尾出现连续N个0的概率,利用统计原理,估算出总值。缺点就是存在0.81% 的误差。适合独立访客数统计、每日活跃用户数统计。
布隆过滤器(Bloom Filter)
Redis 布隆过滤器(Bloom Filter)是基于布隆过滤器算法、由 Redis 实现的高效去重数据结构,核心作用是判断一个元素是否存在于集合中,专门解决海量数据下的去重、缓存穿透等问题,且空间占用极低、查询速度极快
优点:
1、空间效率超高:存储百万 / 亿级数据,仅需几 MB~ 几十 MB 内存;
2、查询 / 插入速度极快:O (k) 时间复杂度(k = 哈希函数个数);
3、无冗余存储:不保存原始数据,仅存哈希标记。
缺点:
1、存在误判:判断「元素存在」可能是假的(实际不存在);
2、无法删除:一旦插入元素,不能单独删除(会影响其他元素);
工作原理:
1、初始化一个全为 0 的二进制位数组;
2、元素插入:通过 k 个独立哈希函数,计算出 k 个位置,将对应位设为 1;
3、元素查询:再次哈希计算 k 个位置,所有位都是 1 → 判定存在,任意一位是 0 → 判定不存在。误判原因:多个元素的哈希位可能重叠,导致不存在的元素刚好命中所有哈希位。
适用场景:
缓存穿透防护(防止恶意查询不存在的数据击穿数据库);
海量数据去重(如用户签到、IP 黑名单、爬虫 URL 去重);
推荐系统去重(不重复推荐已看过的内容)。
总结就是需要用到判断元素在系统中不存在,且有海量数据时,就可以用布隆过滤器。如果要统计总的基数,就用HyperLogLog。它们的插入和查询都极快。
三、Redis大Key
什么是大Key
指占用内存过大或元素数量过多的 Key,通常满足任一条件即视为大 Key:
- 单个 String 类型 > 10KB
- 哈希 / 列表 / 集合 / 有序集合类型,元素数量 > 1000 个 或 总内存 > 10MB
大Key的危害
- 阻塞请求:Redis 是单线程工作模型,所有命令串行执行。对大key执行操作时,会长时间占用CPU,导致其他Redis请求阻塞。
- 内存倾斜:集群中某个节点因大 Key 占用大量内存,其他节点空闲,资源利用率极低
- 淘汰热点数据:占用内存,触发内存淘汰机制,会淘汰掉热点数据,使关键业务不走缓存,响应变慢
- 网络带宽占用:高频的大key请求会占用大量的带宽,使节点的其他服务没有网络带宽可用
大Key的查看
redis-cli工具执行命令:
java
redis-cli --bigkeys使用第三方可视化工具:Redis Insight、AnotherRedisDesktopManager
大Key解决方案
根治方案就是拆分,减小Key的大小
- JSON字符串可以按字段拆分,List/Set/Hash/ZSet元素太多,可以按固定数量(每1000个一个key)拆分,也可以按用户ID、日期、地区等拆分,具体取决于业务形式。
- 能冷热分离的就冷热分离,redis只存热点数据,对于不常用的数据,放到数据库中去。
- 大Key不要集中过期,应该设置一定的随机时间戳。
- 对于太大、且访问频率高,无法拆分的字符串,不要存redis上,可以使用文本形式存到CDN,或者服务器本地缓存。
总结一句话就是,能拆分的就拆分,然后怎么拆分;不能拆分的就尽量不要存,换其他更合适的地方存,存了的话,就避免集中过期。
四、Redis热Key
什么是热Key
指访问频率极高、远超其他 Key 的热点键(比如每秒几千~几万次访问)
典型场景:秒杀商品、热点新闻、热门活动、爆款商品、热点用户信息
热Key的危害
- 资源倾斜:某个节点网络带宽被占满,但其他节点却是空闲的,无法利用集群优势。
- 主从同步延迟:热 Key 所在节点写入频繁,主从同步压力大,出现数据不一致、同步延迟
热Key的查看
redis-cli工具执行命令:
java
redis-cli --hotkeys -h 主机 -p 端口使用Redis 监控(Prometheus/Grafana)查看单节点 QPS 突增
热Key解决方案
根治方案就是把访问分散。
1、使用本地缓存,把流量挡在了服务器层面,那就能发挥集群负载均衡的优势。本地缓存 (Caffeine/Guava) → Redis → DB
2、热key创建多个副本,利用hash分散到多个redis节点,请求时随机访问其中一个副本,把压力分散到不同的分片
3、限流,没啥好说的
五、Redis持久化
Redis不仅是个内存存储引擎,同时它还支持备份内存上的数据到磁盘上,保证Redis断电或者重启后,内存数据的恢复。
Redis 提供两种核心持久化机制:RDB 和 AOF,也可以组合使用。
RDB
定时快照在指定时间点,把 Redis 内存中的全量数据写入磁盘的二进制文件(dump.rdb)
触发方式:
- 手动触发
SAVE:阻塞 Redis,直到快照完成(生产禁用)
BGSAVE:后台异步执行,不阻塞服务(推荐) - 自动触发(配置文件)
powershell
# 900秒内至少1个key修改,自动保存
save 900 1
# 300秒内至少10个key修改
save 300 10
# 60秒内至少10000个key修改
save 60 10000优点 :
1、文件小,备份 / 恢复速度极快
2、对性能影响小(后台执行)
3、适合全量备份、灾难恢复
缺点 :
1、会丢失数据:两次快照之间的修改会丢失
2、大数据量时,fork 子进程会短暂阻塞主进程
AOF(Append Only File)
日志追加:把每一条写命令(增 / 删 / 改)追加到日志文件(appendonly.aof),重启时重放命令恢复数据。
配置文件:
bash
# 开启AOF
appendonly yes
# 三种刷盘策略
appendfsync always # 每次写都刷盘:最安全,性能差
appendfsync everysec # 每秒刷盘:**默认推荐**,平衡安全+性能
appendfsync no # 交给操作系统刷盘:性能最好,最不安全AOF重写(rewrite/压缩) :
随着命令的不断写入,.aof会越来越大,其中有很多命令是重复的,比方同个key的多个set命令,恢复时只需要取最后一个就行了,redis的aof支持文件压缩,把冗余的key自动剔除,生成最小命令集
AOF重写是redis自动触发的,我们可以配置它的触发条件:
bash
auto-aof-rewrite-percentage 100 # 文件比上次大100%触发
auto-aof-rewrite-min-size 64mb # 至少64MB才重写AOF优点 :
1、数据安全性极高,最多丢失 1 秒数据
2、日志是纯文本,可读性高,可手动修复
3、支持重写压缩
AOF缺点 :
1、文件比 RDB 大
2、恢复速度比 RDB 慢
AOF文件损坏
因为Redis断电或强制重启时,会导致内存数据丢失,而AOF可以做到每秒备份或者每次写入备份,但是再追加命令到aof文件的过程中,也同样存在redis异常的情况(断电或重启、磁盘满的情况),所以AOF文件是有可能为损坏状态的。通常都是结尾处的命令被截断了,写到一半,突然redis崩溃了,导致命令没有写完。
此时可以使用这个工具,检查aof文件的正确性,并试图修复:
bash
redis-check-aof --fix appendonly.aof工具会逐条解析,检查:
1、语法是否合法
2、格式是否完整
3、有没有半截命令
一旦读到不合法、不完整、乱码的内容:
1、认定从这里开始全部损坏
2、保留前面所有正确的命令
3、删除从出错位置到文件末尾的所有内容
值得注意的是,RDB文件也同样存在损坏的可能,但是rdb文件时无法修复的,它是一个紧凑的二进制文件,无法从一堆的杂乱二进制数据中进行恢复。
生产方案
推荐使用:RDB + AOF 混合使用
AOF 做主持久化:保证数据不丢
RDB 做全量备份:加快恢复速度
Redis 4.0+ 支持混合持久化:重启时:加载RDB 全量数据 + 重放AOF 增量命令
六、Redis高可用
Redis支持部署多个Redis节点,每个节点按配置模式承担不同的职责和请求压力。
一共有三种模式:
主从复制(Master-Slave)
核心:读写分离 + 数据备份
主节点负责写,从节点负责读,从节点复制主节点数据一主多从,横向扩展读性能。
缺点也很明显,只有一个节点负责写,所有写压力都分到单台节点上,且容量受单台节点容量限制,不具备故障转移,主节点挂了,就没办法写了。
哨兵(Sentinel)模式
核心:主从 + 自动故障转移
基于主从架构,增加哨兵节点监控主从状态,主节点宕机后,哨兵自动投票选举新主,自动切换,无需人工干预,提供主节点地址发现服务(客户端连接哨兵获取当前主)
缺点仍然是单主架构,写压力受单机限制,数据容量不能水平扩展
集群(Cluster)模式
核心:分布式 + 分片 + 高可用
数据按 slot(哈希槽) 分片存储在多个主节点,每个主节点可配从节点,实现高可用,自动故障转移,支持水平扩展,海量数据、高并发写入。
同时集群模式支持类似主从备份的方式建立集群,也就是每个主节点都可以有一个从节点,作为数据备份。从节点一般只用做主节点的备份,不做读的流量分担,但是也可以配置从节点分担读的流量,相对的就要承担主从不一致时,读到脏数据的风险。
集群模式下,扩容时,数据怎么迁移?
假设之前有三个主节点A、B、C,它们分别管
槽 0~5460 → A
槽 5461~10922 → B
槽 10923~16383 → C
此时,扩容多一个主节点D出来,Redis就会计算出新的4个节点下,它们各自管的槽。分配的策略是,A要给一部分槽给D,B要给一部分槽给D,C也是,所以就存在ABC需要把数据同步给D节点了,但注意不存在A、B、C各自之间互相给数据的场景。也就是说,D此时管理的槽就是4096 ~ 5460 、8192 ~ 10922、 12288~16383:
A 把自己的 4096~5460 槽数据 → 发给 D
B 把自己的 8192~10922 槽数据 → 发给 D
C 把自己的 12288~16383 槽数据 → 发给 D
所以Redis的每个节点管理的槽其实可以是不连续的。那为什么我们平时看到是连续的?因为 redis-cli --cluster reshard,默认是按连续一段一段迁移,方便人类看。但 Redis 底层 根本不要求连续。
七、缓存失效
缓存穿透
大量请求查询根本不存在的数据,缓存里没有 → 直接查数据库 → 数据库也没有,缓存永远无法命中,流量直接打穿到 DB。
场景如:恶意攻击:疯狂请求 id=-1、不存在的用户
解决方案:
1、数据库查不到数据时,也缓存一个null值,让查询不到数据的情况也走Redis
2、布隆过滤器,它的查询很快,只需要运行K个hash运算就能判断数据在系统是否存在,但是同时也需要对数据进行预处理,把所有的数据都先加载到布隆过滤器中
3、拦截非法的请求,不走redis也不走数据库。
缓存击穿
某个热点 key 突然过期,大量并发同时请求这个 key,缓存不命中,全部涌入数据库。
解决方案:
1、互斥锁(mutex lock):只让一个线程去查 DB,其他等待
2、热点 key 永不过期
3、逻辑过期 + 后台异步更新
其实缓存击穿和穿透本质上时一样的,都是需要去数据库查一遍,然后缓存到redis上,防止后续的请求打到数据库。
缓存雪崩
大量 key 在同一时间集体过期,或 Redis 本身宕机,所有请求瞬间压到数据库。
解决方案:
1、过期时间加随机值:避免集体失效
2、集群高可用:主从、哨兵、集群
3、多级缓存:本地缓存 + Redis
4、限流、降级、熔断
八、缓存和数据库一致性
我们来看下Redis缓存更新的2种情况
假如B端编辑商品或者活动,根据活动id或者商品id加了分布式锁,修改几乎没有并发的可能。这种情况,采用更新redis的方案,在修改接口里,同事务去更新数据库,同时直接更新redis的值,因为没有并发更新redis,所以set key不存在互相覆盖的并发可能(且前提是C端只存在读缓存不存在写缓存,写缓存都由B端修改保存接口触发)。这种情况是不需要用到延迟双删的。但这种方案的缺点也很明显:C端缓存丢失时,需要定时任务兜底或者手动触发刷缓存
那再看下面这种情况:
假如某个缓存数据在创建时刷了缓存,但是缓存丢失或者过期了,在触发读请求时,缓存中没有,于是从数据库中读取,然后懒加载到Redis中,后续读只要没过期就从Redis读取,过期了就从数据库读完加载到缓存。这种方案下的缓存,就存在并发写的可能了。假如读请求进来没有缓存,然后加锁去数据库读,此时我们刚好又在修改数据库里的这条数据,就存在谁先刷缓存数据的问题了。
- 方案一 :先更新数据库,再更新缓存
存在问题:线程A(查询请求)读缓存没有,再去数据库读到旧数据,线程B(修改请求)更新数据库,然后再更新缓存,线程A拿旧的数据也去更新缓存,此时可能覆盖线程B的更新缓存,导致缓存中一直存了旧的数据。 - 方案二 :先更新缓存,再更新数据库
存在问题:假如数据库更新失败了,那缓存就是新的值,就和数据库不一致了。
解决方案 :采用延迟双删,线程B更新前,先把Redis的缓存删了,此时,线程A进来没有缓存,读到了数据库的旧数据。然后线程B更新数据库,延迟一段时间(通常根据接口的响应时间来,设置500ms之类的),在这500ms期间,线程A已经拿着旧数据去更新缓存了,然后线程B又执行了一次删除缓存(延迟500ms后第二次删除),这样就把A设置的缓存旧数据给删掉了。而这第二次删除,就是为了确保删除掉所有和修改接口并发的读接口更新的redis值的。
还可能存在的问题:第二次删除的时候,可能会删失败,导致旧数据仍然在redis中,解决方法是采用MQ发送延迟消息来删除redis的值,因为消息有重试,能确保redis会删成功。
缺点:延迟双删虽然能大概率解决缓存和数据库的不一致性,但是延迟时间不好预估
九、缓存淘汰策略
Redis内存达到配置的阈值时,此时新增Key就会触发它淘汰掉历史旧的key,以确保整体内存在配置的阈值之下,支持的淘汰策略有:
- noeviction 不淘汰(默认)
- 仅对【设置了过期时间】的 key 淘汰
- volatile-lru 淘汰最近最少使用(LRU)的过期 key
- volatile-lfu 淘汰使用频率最低(LFU)的过期 key
- volatile-random 随机删除过期 key
- volatile-ttl 淘汰最快过期的 key(TTL 越小越先删)
- 对【所有 key】淘汰(生产最常用)
- allkeys-lru 淘汰所有 key 中最近最少使用的(生产首选)
- allkeys-lfu 淘汰所有 key 中使用频率最低的
- allkeys-random 随机删除所有 key
拓展:LRU的实现原理如下:
哈希表:维护key对应双向链表里的node,快速找到 key 对应的节点(O(1))
双向链表:维护访问顺序,头部=最近使用,尾部=最久未使用
操作一个key时,从哈希表中找到它的node节点,然后修改双向链表里的指针指向,再把这个node添加到头部,假如哈希表中没有这个node,则直接添加到头部,链表满时,就踢掉尾部即最不常用的。
十、Redis常用场景
实现消息队列
Redis有个发布 / 订阅(Pub/Sub)功能,是Redis提供的消息广播模型。
发布者(Publisher):往一个 "频道" 发消息
订阅者(Subscriber):监听这个 "频道",一收到消息就消费
特点:发布者只管发,不管有没有人订阅;订阅者只管听,不听就错过
发布者配置:
java
@Configuration
public class RedisPubSubConfig {
// 定义频道名称
public static final String NOTICE_CHANNEL = "notice.channel";
public static final String ORDER_CHANNEL = "order.channel";
/**
* 注册监听器:绑定 → 通知频道
*/
@Bean
public MessageListenerAdapter noticeListenerAdapter(NoticeMessageListener listener) {
return new MessageListenerAdapter(listener, "onMessage");
}
/**
* 注册监听器:绑定 → 订单频道
*/
@Bean
public MessageListenerAdapter orderListenerAdapter(OrderMessageListener listener) {
return new MessageListenerAdapter(listener, "onMessage");
}
/**
* 消息订阅容器(自动过滤频道)
*/
@Bean
public RedisMessageListenerContainer redisMessageListenerContainer(
RedisConnectionFactory factory,
MessageListenerAdapter noticeListenerAdapter,
MessageListenerAdapter orderListenerAdapter
) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(factory);
// ====================== 关键:自动绑定频道 ======================
// 通知频道 → 通知监听器
container.addMessageListener(noticeListenerAdapter, new ChannelTopic(NOTICE_CHANNEL));
// 订单频道 → 订单监听器
container.addMessageListener(orderListenerAdapter, new ChannelTopic(ORDER_CHANNEL));
return container;
}
}发布消息:
java
@Service
public class RedisPublishService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* 发送通知消息
*/
public void sendNotice(String msg) {
stringRedisTemplate.convertAndSend(NOTICE_CHANNEL, msg);
System.out.println("已发送通知消息:" + msg);
}
/**
* 发送订单消息
*/
public void sendOrder(String msg) {
stringRedisTemplate.convertAndSend(ORDER_CHANNEL, msg);
System.out.println("已发送订单消息:" + msg);
}
}消费消息:
java
@Component
public class NoticeMessageListener {
/**
* 只接收 notice.channel 的消息
*/
public void onMessage(String message) {
System.out.println("【系统通知】收到消息:" + message);
}
}
@Component
public class OrderMessageListener {
/**
* 只接收 order.channel 的消息
*/
public void onMessage(String message) {
System.out.println("【订单消息】收到消息:" + message);
}
}这种方案实现的消息队列,没有持久化,消费者只要离线消息就丢失,因为生产者只管发,至于你听不听得到我不管,而且没有消息确认机制,没有消息重试,只适用实时广播通知,且可靠性要求不高的场景。
Redis5.0之后,引入了Stream来实现消息队列,对比pub/sub模型,Stream支持消息持久化、支持消费组、支持负载均衡、支持消息确认、支持消息重试、支持阻塞读取。核心的组件如下:
生产者(发送消息),生产者只需要关心往哪个Stream发就行了,不需要关注消费组之类的:
java
@Service
public class StreamProducer {
@Resource
private StringRedisTemplate redisTemplate;
// 发消息
public String send(String msg) {
HashMap<String, String> map = new HashMap<>();
map.put("msg", msg);
return redisTemplate.opsForStream().add(StreamConst.STREAM, map);
}
}消费者(接收消息),一个Stream里可以有多个消费组Group,每个消费组都可以消费同一个消息成功一次,也就是定义5个消费组在Stream里,那一条消息,就会被消费5次,每个组消费一次,比如下单成功了,那订单系统需要消费消息,库存系统需要消费消息这种。同一个消费组Group中的消费者(也就是线程或者实例),只有一个消费线程会获取到同一个消息,它们之间可以配置负载均衡,按比例进行消费。
java
@Service
public class StreamConsumer {
@Resource
private StringRedisTemplate redisTemplate;
// 初始化创建消费者组
@PostConstruct
public void initGroup() {
try {
redisTemplate.opsForStream().createGroup(StreamConst.STREAM, StreamConst.GROUP);
} catch (Exception ignored) {}
}
// 启动消费
@PostConstruct
public void start() {
new Thread(() -> {
while (true) {
try {
// 阻塞读取消息
List<MapRecord<String, String, String>> messages =
redisTemplate.opsForStream().read(
Consumer.from(StreamConst.GROUP, StreamConst.CONSUMER),
org.springframework.data.redis.connection.stream.StreamReadOptions.empty()
.block(2000)
.count(1),
StreamOffset.create(StreamConst.STREAM, ReadOffset.lastConsumed())
);
if (messages == null || messages.isEmpty()) continue;
// 处理消息
for (MapRecord<String, String, String> msg : messages) {
String msgId = msg.getId().getValue();
String content = msg.getValue().get("msg");
System.out.println("消费消息:" + content);
// 确认消息
redisTemplate.opsForStream().acknowledge(
StreamConst.STREAM,
StreamConst.GROUP,
msgId
);
}
} catch (Exception e) {
try { Thread.sleep(1000); } catch (Exception ignored) {}
}
}
}).start();
}
}实现延迟队列
Java中使用RedisTemplate,调用Redis的ZSet API可以实现延迟队列功能,延迟队列就是队列里的消息,不是立马执行的,每个消息都有一个执行时间,要等到这个时间了,才会从队列里取出来执行任务。
添加任务:
java
// 1. 计算任务执行时间戳(秒)
long executeTime = System.currentTimeMillis() / 1000 + delaySeconds;
// 2. 封装任务对象
DelayTask<T> delayTask = new DelayTask<>();
delayTask.setTaskId(taskId);
delayTask.setData(taskData);
delayTask.setRetryCount(0); // 初始重试次数
// 3. 序列化为 JSON 字符串(作为 ZSet 的 member)
String taskJson = JSONObject.toJsonString(delayTask );
// 4. ZADD 原子添加(score=执行时间戳,重复 taskId 会覆盖)
return redisTemplate.opsForZSet().add(queueKey, taskJson, executeTime);消费端启动线程池,获取到期执行的任务:
java
// 1. 当前时间戳(秒)
long currentTime = System.currentTimeMillis() / 1000;
// 2. 查询 score ≤ 当前时间的任务(已到期)
Set<Object> expiredTaskSet = getZSetOps().rangeByScore(
queueKey,
0, // min score
currentTime,// max score
0, // 起始索引
batchSize // 批量大小
);
if (expiredTaskSet == null || expiredTaskSet.isEmpty()) {
return Collections.emptyList();
}
// 3. 批量删除已获取的任务(原子操作,避免重复消费)
Long deleteCount = getZSetOps().remove(queueKey, expiredTaskSet.toArray());
if (deleteCount == null || deleteCount == 0) {
return Collections.emptyList();
}这种是最基础的使用轮询的方式,实现的获取任务,因为rangeByScore命令是非阻塞的,且Redis原生的ZSet没有提供阻塞式命令,所以客户端必须要启动一个线程每秒轮询调用一次rangeByScore这个API。
一般生产上使用的工业级方案是采用Redission,它有个RDelayedQueue,可以实现阻塞式的获取。
java
// 延迟队列实例(复用)
private RDelayedQueue<String> delayedQueue;
/**
* 初始化延迟队列
*/
@PostConstruct
public void initDelayedQueue() {
// 基于 Redisson 的普通队列构建延迟队列
delayedQueue = redissonClient.getDelayedQueue(
redissonClient.getQueue(DELAY_QUEUE_NAME)
);
}
/**
* 添加延迟任务
* @param task 任务内容(字符串/序列化对象均可)
* @param delay 延迟时间
* @param timeUnit 时间单位
*/
public void addDelayTask(String task, long delay, TimeUnit timeUnit) {
delayedQueue.offer(task, delay, timeUnit);
System.out.println("添加延迟任务:" + task + ",延迟 " + delay + " " + timeUnit);
}
/**
* 阻塞式消费任务(核心:take() 方法会阻塞直到有任务到期)
*/
public void consumeTask() {
// 启动独立线程消费,避免阻塞主线程
new Thread(() -> {
try {
while (!Thread.currentThread().isInterrupted()) {
// 阻塞获取到期任务(无任务时线程挂起,无资源消耗)
String task = delayedQueue.take();
// 执行任务逻辑
System.out.println("执行到期任务:" + task + ",执行时间:" + System.currentTimeMillis());
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.err.println("消费线程被中断,退出阻塞消费");
}
}, "delay-queue-consumer").start();
}
}核心就是利用delayedQueue.offer添加任务并指定执行时间,调用delayedQueue.take();阻塞等待式的获取任务。
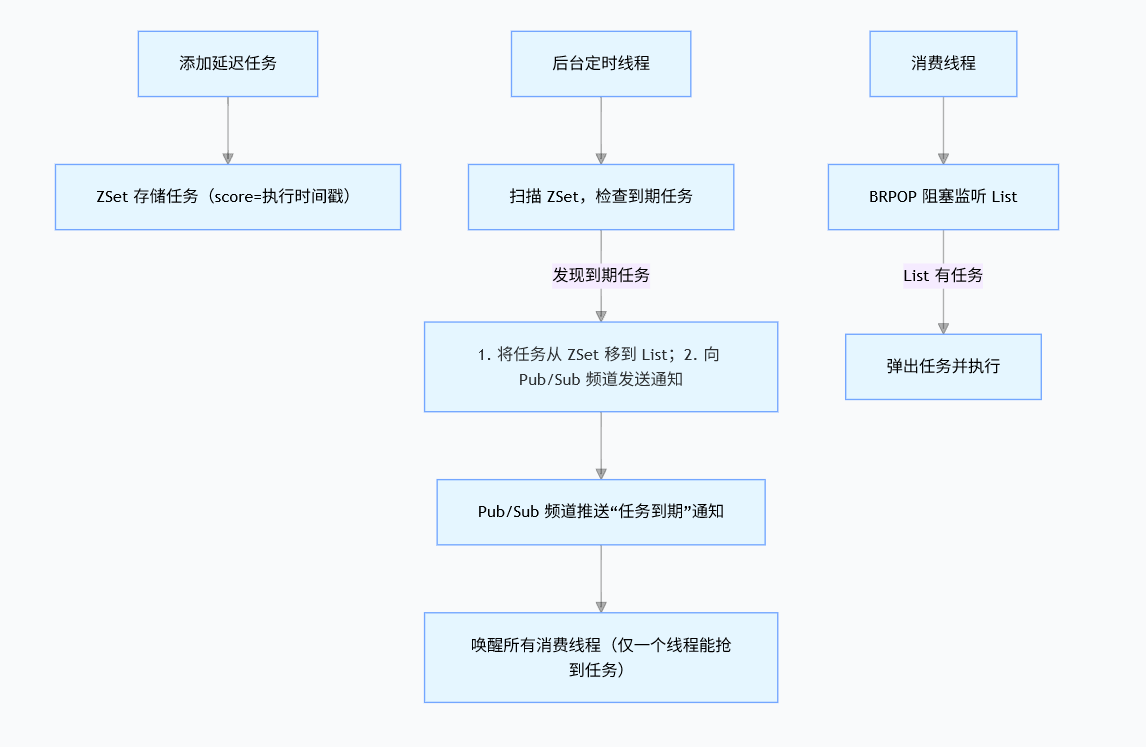
但其实这并不是什么黑魔法,Redission内部也是使用了Redis的:ZSet+ 发布订阅(Pub/Sub)模型+ Redis List 类型的阻塞式弹出命令Block Right Pop 实现的。
首先Redis提供阻塞式的API只有List类型的基本数据才有(BRPOP),但List类型又没有到期执行的能力(没有score这个维度),Redission内部实现还是轮询ZSet,当有任务到期执行时,它就往普通的List中添加这条任务,并向Redis发布消息,监听消息的消费端,就使用BRPOP命令从List拿数据执行,这个命令保证多个消费端收到消息后,只有一台能拿到这个任务(原子性),所以本质上Redission还是轮询ZSet的方式。不同的是,Redission并不是简单的1秒1次轮询,而是通过分层轮询 + 动态调整扫描间隔 + 批量处理,把轮询的开销降到最低:
- 近期到期任务(如未来 10 秒内):放入「高频扫描队列」,扫描间隔极短(默认 100ms 左右),确保任务精准到期;
- 远期到期任务(如未来 1 小时):放入「低频扫描队列」,扫描间隔很长(默认 10 秒 / 分钟级),减少无效查询。
- 动态调整扫描间隔
Redisson 会根据 ZSet 中任务的分布动态调整扫描频率:
如果 ZSet 中只有 "远期任务",扫描间隔自动拉长(比如 1 分钟扫一次);
如果 ZSet 中有 "近期任务",扫描间隔自动缩短(比如 100ms 扫一次);
如果 ZSet 为空,扫描间隔会调到最大(比如 10 分钟),几乎无资源消耗。
同时,Redssion会加锁,所有消费实例中,只有抢到锁的实例才会执行ZSet扫描,也就不会有重复添加同个任务到List里的情况,不会出现重复消费的问题。
思考:为什么Redission要加多一个 发布订阅(Pub/Sub)在中间,而不是每个客户端使用BRPOP命令,阻塞式的等待呢?
假设 Redisson 只做 "后台线程扫 ZSet → 到期任务移 List → 消费线程 BRPOP List",看似能工作,但在多实例部署场景下会有问题:
-
BRPOP 的 "唤醒延迟"(Redis 原生特性) Redis 的 BRPOP 并非 "实时唤醒"------ 当 List新增元素时,Redis 会从阻塞的客户端列表中随机唤醒一个客户端,但这个唤醒过程存在「毫秒级延迟」(极端情况甚至秒级)。
-
场景:部署了 10 个应用实例,每个实例都有消费线程执行 BRPOP list 0 阻塞监听; 现象:后台线程把任务移到 List 后,Redis 可能需要几百毫秒才唤醒其中一个消费线程,导致任务执行延迟;
Redisson 引入 Pub/Sub 后,形成了 "Pub/Sub 做通知 + BRPOP 做兜底" 的双保险机制。
- 流程:后台线程把到期任务移到 List 后,立即向 Pub/Sub 频道发送一条 "任务到期" 的通知;
- 效果:所有实例的消费线程都订阅了这个频道,收到通知后会 "主动检查 List"(而非等 Redis 随机唤醒)------ 相当于 "喊一声所有人都来抢任务",而非 "Redis 挨个叫人";
- 对比:
无 Pub/Sub:Redis 随机唤醒一个 BRPOP 线程,延迟几百毫秒;
有Pub/Sub:所有线程收到通知后立即抢任务,唤醒延迟降到 10ms 内。
需要注意的是,Redission实现的延迟队列,是存在消息丢失的可能的,因为从ZSet中读取数据,转移到List的这段时间,可能因为Redis挂了导致消息丢失。即使成功存入List中,并且开启了RDB和AOF,由于整套体系没有消息确认机制,也有可能在消费端因为消费失败,消息已被取走,消息没办法重试导致消息丢失了,这是这套方案的缺陷,一般生产都是用来做一些对可靠性不需要严格要求的业务,常见的有未支付订单的取消,配合定时任务以及前端实时判断兜底,确保订单的最终取消。
限流器:滑动窗口 / 令牌桶 / 漏斗 + Redis 原子实现
三种限流器都是用Redis的lua脚本实现的,因为并发需要保证请求数量的原子性。而且三大主流网关(Spring Cloud Gateway、Kong Gateway、APISIX)底层全都用 Redis 做限流。
滑动窗口限流器
在一个 "滚动的时间窗口" 里,只允许固定数量的请求通过。比方:最近 1 分钟内,最多只能进 100 个人。来一个人,就以当前时间往前数这1分钟内,进来了多少人,超过则限流
令牌桶限流器
以固定速率生成令牌放入桶中,桶满则不生成新令牌,请求必须获取桶里的令牌才能执行,支持突发流量(瞬间消耗桶内存量令牌)。
漏桶限流器
请求放入漏桶,固定速率流出处理。桶满则新请求直接拒绝,严格匀速,无突发。
十一、常见问题
Redis同样数据,为什么省内存?
- 动态编码 ,Redis的基本数据结构都采用动态编码,参考第一节内容
-List:数据量小时用ZipList,数据量大时用LinkedList,5.2之后,采用QuickList
-Set:数据量小时用IntSet,数据量大时用HashTable
-ZSet:数据量小时用ZipList,数据量大时用SkipList+HashTable
-String:SDS动态字符串,配合Jemalloc内存申请,减少了内存碎片的产生
ZipList和IntSet无链表指针开销,内存利用率接近 100% - 对象复用 ,Redis 预创建 0--9999 整数对象,所有相同值共享同一个 redisObject
存储大量 ID / 状态码时,几乎无额外对象开销 - 引用计数 ,多个地方用同一个数据,只存一份,不重复存。比方你存了1000 个 key,值都是 1
-Redis:只存一份,用引用计数记录 "有 1000 个人在用我"
-普通系统:存 1000 份 1 → 浪费 999 份空间 - 无额外索引 / 锁 / 事务元数据,也就是没有mysql那样需要建立一堆的索引树来方便查询
什么是SDS、Jemalloc
SDS(Simple Dynamic String) :Redis自己造的一种字符串,结构就三部分:长度剩余空间字符串内容。
这样的数据结构,让Redis读取头部就能知道这个字符串的长度以及还有多少预留空间。
Jemalloc :首先看什么是 内存碎片 ,就是明明是一块连续的内存,但是申请使用时,不连续申请,左一块右一块,导致连续的内存空间被切割成很多不连续的块了,当需要用到大的连续内存时,实际有足够的空闲空间,但由于被切割完的内存没有这么大的连续的,于是就无法申请了。
Jemalloc 是优化过的内存申请工具。系统自带的 malloc 管理混乱,申请内存时随便找空闲块分配,释放后空间东一块西一块,容易产生内存碎片。Jemalloc 把内存按固定大小切块管理(8B、16B、32B...),比如需要 20B 就分配 32B 的块,剩余的做预留空间,让内存布局更规整,减少碎片。
Redis 的 SDS 字符串结构(长度 + 剩余空间 + 内容)会自己做预分配和惰性释放,扩展字符串时优先复用内部预留空间,不够才重新申请内存,减少频繁分配释放。再加上 ziplist、intset 这类连续紧凑的数据结构,整体让内存更规整,进一步减少内存碎片。
集群模式下为什么是16384个槽?
① 槽数太少:扩容 / 迁移时槽分配粒度太粗;太多:槽映射表占用内存大(16384 个槽的映射表仅 2KB)
② 16384 是权衡:既满足分片粒度,又保证节点间传输槽信息时带宽消耗小
集群故障转移 "集群怎么选主?
半数投票机制
① 节点故障:超过半数主节点判定某个主节点下线(PFail→Fail)
② 选主:故障主节点的从节点发起选举,超过半数主节点投票通过后,从节点升级为主节点
③ 槽迁移:新主节点接管原主节点的所有槽
由于Redis节点故障的这个半数投票原则,因此实现集群模式的高可用,最少是3主3从,因为只有超过了半数投票从节点才能晋升为主节点
集群扩容 / 缩容,怎么给集群加节点?
① 添加新节点(主 / 从)到集群;
② 使用命令重新分配和迁移槽(redis-cli --cluster reshard);
③ 验证槽分配(cluster slots);
什么是Redis的脑裂,怎么避免?
因为网络等原因,集群里同时出现了两个主节点(Master),两边都以为自己是主,都能写,导致:数据不一致,两边数据互相冲突。
本来只有一个老大,结果网络一断,两边各选了一个老大,互不相认
脑裂在哨兵模式最容易出现,集群模式因为需要半数主节点都认为故障节点下线了,才能将从节点晋升,因此基本不会出现。
防止的方式就是配置 min-replicas-to-write 1,主节点至少要有一个从节点,才能对外写,这样就避免了2个主节点同时在写数据的情况发生
Keys命令和Scan命令
两个命令的作用是按表达式模糊查找Redis中符合匹配规则的key
Keys命令
语法:KEYS pattern
全量遍历所有键,按照通配符匹配返回结果。支持 * 匹配任意字符、? 匹配单个字符。一次性返回所有匹配的键
工作原理:Redis 会暂停所有其他请求(读写、查询、写入),直到遍历完所有键才恢复服务,如果有 100 万 + 键,会导致 Redis 卡死几秒~几分钟
SCAN命令
语法:SCAN cursor MATCH pattern COUNT count
增量式迭代遍历,分多次、分批返回键,不会阻塞 Redis。基于游标(cursor)分步遍历,不会一次性加载所有键到内存,支持匹配、数量限制
工作原理:第一次传入游标 0,Redis 返回 下一次的游标 + 一批键,用返回的新游标继续遍历,直到游标返回 0,遍历结束
查慢查询
有两个阈值需要关注:
bash
# 阈值改为 5毫秒(5000微秒),这个阈值决定多久的查询才叫慢查询
CONFIG SET slowlog-log-slower-than 5000
# 最大记录数改为 1000条,这个配置决定保存多少条慢查询
CONFIG SET slowlog-max-len 1000获取慢查询日志
bash
# 查询前20条慢日志
SLOWLOG GET 20pipeline/multi 区别
pipeline 内可以执行一系列命令,但是它不保证原子性,也就是这一系列命令中,可能会有其他redis的请求穿插进来中间执行了,且不支持事务。
multil/exec 也可以执行一系列命令,它是支持原子性的,也就是这一批命令,一个一个执行,执行出错了也不回滚,其他命令会继续执行。同时要注意,multi里操作的key必须是同一个节点里的,否则会报错,一条命令都不会执行成功。