动手学深度学习------模型初始化和激活函数详解:为什么网络一开始就学偏了?
一、前言
在学习神经网络时,很多同学会把注意力放在"模型结构够不够复杂"上,比如:
-
网络层数够不够深
-
参数够不够多
-
有没有用上更高级的模块
但实际上,神经网络训练能不能顺利开始,往往取决于两个非常基础却极其关键的问题:
-
模型初始化是否合理
-
激活函数是否合适
如果初始化做得不好,模型一开始就可能进入"坏状态":
-
输出过大或过小
-
梯度爆炸或梯度消失
-
loss 不下降
-
训练极慢,甚至直接
nan
如果激活函数选择不当,也会导致:
-
网络表达能力不足
-
梯度传播困难
-
收敛速度慢
-
深层网络训练效果差
所以说,模型初始化和激活函数不是小细节,而是神经网络能否学好的基础。
这篇文章就系统梳理这一部分内容。
二、什么是模型初始化
模型初始化,就是在训练开始之前,先给神经网络中的参数一个初始值。
在神经网络中,最核心的参数就是:
-
权重
weight -
偏置
bias
例如一个全连接层:
y = Wx + b
这里的 (W) 和 (b) 在训练前都需要先赋值,这个过程就叫初始化。
三、为什么不能把参数都初始化成 0
这是一个非常经典的问题。
很多初学者第一反应会觉得:
既然训练会不断更新参数,那一开始全部设成 0 不就行了吗?
看起来好像没问题,但实际上这样会导致一个严重问题:
对称性无法被打破。
1. 什么叫对称性
假设某一层有多个神经元,如果它们的初始权重完全一样,比如全是 0,那么:
-
它们接收相同输入
-
计算得到相同输出
-
反向传播得到相同梯度
-
参数更新后仍然一样
也就是说,这一层虽然看起来有很多神经元,但它们学到的东西完全相同。
这就等于:
多个神经元退化成了一个神经元。
网络的表达能力会大幅下降。
2. 为什么偏置可以初始化为 0
一般来说:
-
权重不能全初始化为 0
-
偏置通常可以初始化为 0
因为真正负责打破对称性的主要是权重矩阵。
只要权重是随机的,不同神经元就能学出不同特征。
四、为什么要随机初始化
随机初始化的核心目的有两个:
1. 打破对称性
不同神经元用不同的初始参数,才能学到不同模式。
2. 让前向传播和反向传播更稳定
如果初始化过大:
-
前向输出容易过大
-
激活值可能进入饱和区
-
梯度可能爆炸
如果初始化过小:
-
信号越来越弱
-
梯度越来越小
-
容易梯度消失
所以合理初始化不是"随便随机一下",而是要尽量让:
-
每层输出的方差稳定
-
每层梯度的方差稳定
五、常见的初始化方式
1. 正态分布初始化
最常见的一种思路,就是从正态分布中随机采样:

也就是均值为 0、方差为某个值的小随机数。
例如:
import torch
from torch import nn
linear = nn.Linear(20, 10)
nn.init.normal_(linear.weight, mean=0, std=0.01)
nn.init.zeros_(linear.bias)这种方式简单直观,但问题在于:
-
如果标准差太大,数值容易爆炸
-
如果标准差太小,数值容易消失
所以在深层网络中,单纯固定标准差的初始化往往不够稳健。
2. 均匀分布初始化
也可以从某个均匀分布中随机采样:
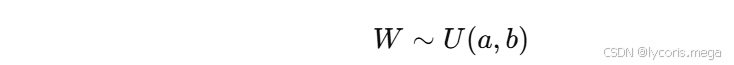
例如:
nn.init.uniform_(linear.weight, a=-0.1, b=0.1)本质上和正态分布初始化类似,关键仍然是范围不能乱设。
3. Xavier 初始化
Xavier 初始化也叫 Glorot 初始化,是深度学习里非常经典的一种方法。
它的核心目标是:
让每一层在前向传播时,输出的方差不要变化太大;
同时在反向传播时,梯度的方差也尽量稳定。
其思想是根据输入维度和输出维度来自动调整初始化范围,而不是人工拍脑袋设一个固定值。
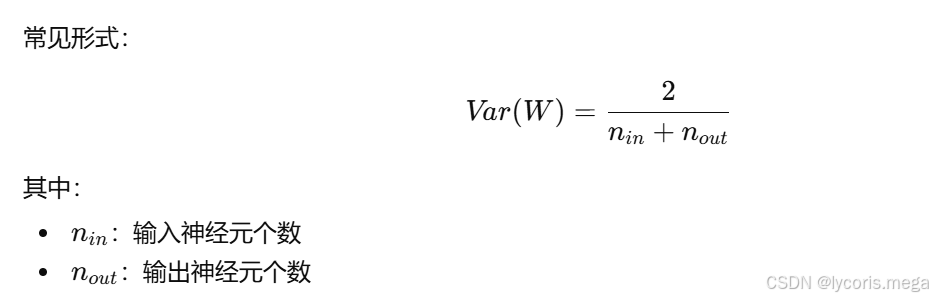
PyTorch 写法:
nn.init.xavier_uniform_(linear.weight)或者:
nn.init.xavier_normal_(linear.weight)Xavier 初始化通常更适合:
-
Sigmoid
-
Tanh
这类输出分布比较对称的激活函数。
4. He 初始化
He 初始化是针对 ReLU 类激活函数提出的。
因为 ReLU 会把一部分神经元输出直接截断为 0,所以信号会损失一部分。
为了补偿这种损失,He 初始化使用更大的方差:
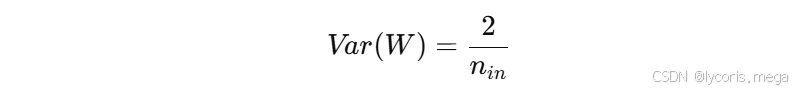
PyTorch 写法:
nn.init.kaiming_uniform_(linear.weight, nonlinearity='relu')或者:
nn.init.kaiming_normal_(linear.weight, nonlinearity='relu')He 初始化通常更适合:
-
ReLU
-
Leaky ReLU
如果你的网络主要用的是 ReLU,那么一般优先考虑 He 初始化。
六、什么是激活函数
激活函数(Activation Function)是神经网络中非常关键的一部分。
一个线性层本身只是:
y = Wx + b
如果整个网络只是一层层线性变换叠加,那么无论叠多少层,最后仍然等价于一个线性变换。
这意味着:
没有激活函数,深层网络就失去了学习复杂非线性关系的能力。
所以激活函数的作用,就是给网络加入非线性能力。
七、为什么神经网络需要非线性
现实世界中的很多问题都不是线性的。
比如:
-
图像分类不是简单的线性分割
-
语音识别不是简单的线性映射
-
自然语言理解也远比线性关系复杂
如果模型只有线性变换,它就无法拟合复杂函数。
激活函数的引入,相当于让网络具备了:
-
弯曲决策边界的能力
-
组合复杂特征的能力
-
表达非线性映射的能力
所以可以说:
激活函数是神经网络"强大表达能力"的来源之一。
八、常见激活函数详解
1. Sigmoid
Sigmoid 函数公式为:
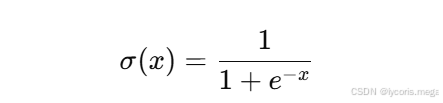
图像特点:
-
输入很小时,输出接近 0
-
输入很大时,输出接近 1
-
输出范围在 ((0,1))
优点
-
输出可以看作概率
-
形式平滑,早期神经网络中使用很多
缺点
-
容易饱和,梯度接近 0
-
导数最大值只有 0.25,容易梯度消失
-
输出不是以 0 为中心,会影响优化效率
所以现在 Sigmoid 很少作为深层隐藏层的激活函数,更多出现在:
-
二分类输出层
-
概率建模场景
PyTorch 示例:
sigmoid = nn.Sigmoid()2. Tanh
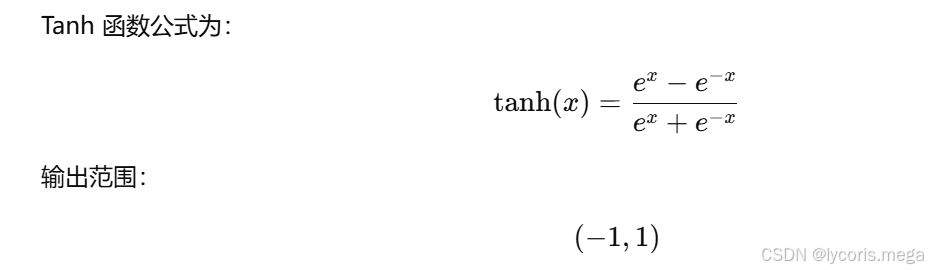
优点
-
比 Sigmoid 更好的一点是:输出以 0 为中心
-
在一些场景下优化效果优于 Sigmoid
缺点
-
同样存在饱和问题
-
输入绝对值大时,梯度仍然接近 0
-
深层网络中仍可能出现梯度消失
PyTorch 示例:
tanh = nn.Tanh()3. ReLU
ReLU 是目前最常见的激活函数之一。
定义为:
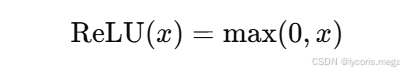
也就是说:
-
当 (x > 0) 时,输出就是 (x)
-
当 (x \le 0) 时,输出就是 0
优点
-
计算简单
-
收敛速度快
-
正区间梯度恒为 1
-
有效缓解梯度消失问题
缺点
-
负区间梯度恒为 0
-
可能出现"神经元死亡"问题
所谓神经元死亡,就是某些神经元长期输出 0,参数几乎得不到更新。
PyTorch 示例:
relu = nn.ReLU()4. Leaky ReLU

优点
-
保留了 ReLU 的大部分优点
-
负区间仍有微小梯度
-
能缓解"神经元死亡"问题
PyTorch 示例:
leaky_relu = nn.LeakyReLU(0.01)5. Softmax
Softmax 严格来说常用于输出层,不是隐藏层常规激活函数。
它把一组实数变成一个概率分布:
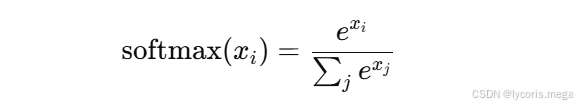
特点:
-
每个输出都在 0 到 1 之间
-
所有输出之和等于 1
常用于:
- 多分类输出层
但在 PyTorch 中,一般分类任务直接用:
nn.CrossEntropyLoss()通常不用手动先写 Softmax。
九、不同激活函数的对比
从实际使用角度,可以简单总结如下:
1. Sigmoid
适合二分类输出层,但不适合深层隐藏层。
2. Tanh
比 Sigmoid 略好,但深层网络中依然容易梯度消失。
3. ReLU
最常用,训练快,效果通常较好,是隐藏层默认首选。
4. Leaky ReLU
是 ReLU 的改进版,在某些场景下更稳。
5. Softmax
主要用于多分类输出层。
十、初始化和激活函数之间的关系
这一点非常重要。
初始化和激活函数不是各管各的,它们之间是强相关的。
1. 如果用 Sigmoid / Tanh
这类函数容易饱和,因此初始化不能过大。
通常更适合 Xavier 初始化。
2. 如果用 ReLU
ReLU 会丢掉一部分负值,因此更适合 He 初始化来保持方差稳定。
也就是说:
-
Sigmoid / Tanh → Xavier
-
ReLU / Leaky ReLU → He
这是一组非常经典的搭配。
十一、PyTorch 示例:自定义初始化
在实际项目中,我们经常会手动给网络初始化参数。
例如:
import torch
from torch import nn
net = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.kaiming_uniform_(m.weight, nonlinearity='relu')
nn.init.zeros_(m.bias)
net.apply(init_weights)
print(net[0].weight.data[0])这里的 apply() 会把初始化函数应用到每一层。
十二、一个简单理解:初始化像"起跑姿势",激活函数像"表达方式"
我觉得可以这样理解:
1. 初始化
初始化决定的是:
模型一开始站在什么位置起跑。
如果起跑姿势就不对,后面训练会非常吃力。
2. 激活函数
激活函数决定的是:
模型用什么方式表达复杂关系。
如果没有激活函数,网络再深也只是线性模型;
如果激活函数不好,梯度传播又会受阻。
所以二者共同决定了:
-
网络能不能学
-
学得快不快
-
学得稳不稳
十三、实际训练中的经验总结
在平时做实验时,可以记住下面这些经验。
1. 隐藏层默认优先用 ReLU
这是最常见的起手选择。
2. 配 ReLU 时优先用 He 初始化
这是最经典也最稳妥的组合。
3. 二分类输出层常用 Sigmoid
但注意通常配合对应损失函数使用。
4. 多分类输出层通常配合 CrossEntropyLoss
不要自己重复做 softmax。
5. 如果训练一开始就不稳定
优先排查:
-
初始化是否太大
-
激活函数是否进入饱和
-
学习率是否过高
十四、代码示例:观察不同激活函数
import torch
from torch import nn
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
sigmoid = nn.Sigmoid()
tanh = nn.Tanh()
relu = nn.ReLU()
print("Sigmoid:", sigmoid(x))
print("Tanh:", tanh(x))
print("ReLU:", relu(x))运行后你会看到:
-
Sigmoid 输出在 0 到 1 之间
-
Tanh 输出在 -1 到 1 之间
-
ReLU 会把负数全部变成 0
这也对应了它们各自的性质。
十五、这一节我学到了什么
学完"模型初始化和激活函数"后,我最大的感受是:
以前总觉得神经网络训练不好,是模型结构不够高级;
后来才发现,很多时候问题根本不在"网络不够复杂",而在于最基础的两个地方没有处理好:
-
一开始参数怎么设
-
每层后面用什么激活函数
这两个东西虽然基础,但它们直接决定了网络训练初期的状态。
如果初始化和激活函数选得合理,模型往往更容易:
-
稳定收敛
-
梯度正常传播
-
更快学到有效特征
所以它们其实是深度学习中非常底层但非常关键的知识点。
十六、结语
模型初始化和激活函数看似只是神经网络中的两个基础模块,但它们对训练效果的影响非常大。
可以说:
-
初始化决定模型能否顺利起步
-
激活函数决定模型能否表达复杂关系并稳定训练
在实际开发中,很多常见的经验组合已经比较成熟:
-
隐藏层:ReLU
-
初始化:He
-
二分类输出:Sigmoid
-
多分类输出:Softmax / CrossEntropyLoss 体系
把这些基础打牢,后面再去学 CNN、RNN、Transformer,理解会更顺很多。
十七、重点速记版
1. 为什么不能全 0 初始化
因为会导致神经元完全对称,学不到不同特征。
2. 为什么要随机初始化
为了打破对称性,并保持前向、反向传播稳定。
3. Xavier 初始化适合谁
适合 Sigmoid、Tanh。
4. He 初始化适合谁
适合 ReLU、Leaky ReLU。
5. 激活函数的核心作用
给神经网络引入非线性表达能力。
6. 常见激活函数怎么选
-
隐藏层:ReLU / Leaky ReLU
-
二分类输出层:Sigmoid
-
多分类输出层:Softmax(通常配合 CrossEntropyLoss)