核心技术篇② | 虚拟人的大脑:国内头部大语言模型全解析
导语
一个能实时交互、自主思考的虚拟人,核心是背后的"AI大脑"------大语言模型(LLM)。如果说形象、语音是虚拟人的"身体",那么大语言模型就是虚拟人的"灵魂":它决定了虚拟人能不能听懂用户的问题、能不能生成流畅自然的回答、能不能完成多轮对话与专业任务。
本文就带你全面解析虚拟人背后的大语言模型,从开源大模型的现状,到国内头部LLM的技术特点,再到模型评测体系,一文讲透虚拟人"AI大脑"的核心逻辑。
1 开源大语言模型的行业现状
在正式解析国内头部模型之前,我们首先要明确开源大模型的核心定义:完整的开源应该包含权重、训练代码、训练数据 三部分。
而行业现状是:几乎所有大语言模型的"开源",都只是开放权重 ,几乎不开源训练脚本(代码),更不会开源核心的训练数据。即便是全球知名的LLaMA系列,也仅对学术场景开源,商业用途需要额外申请官方许可。
这一点,是我们选择和使用开源大模型时,必须首先明确的前提。
国内开源大语言模型根据技术能力、生态完善度、行业落地规模,大致可以分为三个梯队:
- 第一梯队:通义千问(Qwen)、DeepSeek、GLM-4.5;
- 第二梯队:Kimi-K2-Instruct、MiniMax-M1-80k、混元A13B-Instruct;
- 第三梯队:ERNIE-4.5-Turbo-128K等其他开源模型。
接下来,我们会重点解析第一梯队的三大模型系列,以及清华技术谱系的三大分支,这些也是目前国内虚拟人场景落地最主流的LLM方案。
2 国内头部大语言模型深度解析
2.1 通义千问(Qwen)系列:阿里达摩院出品,全模态能力标杆
通义千问(Qwen)是阿里达摩院推出的大语言模型系列,也是国内开源模型中,多模态能力最完善、生态覆盖最全面的系列之一,从2023年发布至今,持续迭代,版本更新节奏如下:
| 版本 | 发布时间 | 核心能力突破 |
|---|---|---|
| Tongyi Qianwen | 2023年7月 | 基础对话、理解、生成能力正式发布 |
| Qwen-VL | 2023年8月 | 视觉多模态能力上线,支持图像理解 |
| Qwen2 | 2024年6月 | 基础架构优化,性能大幅提升 |
| Qwen2.5 | 2024年7月 | 长上下文、对话流畅度优化 |
| Qwen2-Audio | 2024年8月 | 音频理解与生成能力上线,支持语音交互 |
| Qwen2.5-Coder | 2024年11月 | 代码生成能力专项优化 |
| Qwen2-VL | 2024年12月 | 视觉多模态能力大幅升级 |
| QvQ | 2024年12月 | 多模态逻辑推理、科学分析能力专项提升 |
| Qwen2.5-Omni | 2025年3月 | 端到端全模态交互,语音融合能力全新升级 |
| Qwen3 | 2025年4月 | 架构全面升级,同步推出Dense版与MoE版 |
核心技术特点:
- 架构灵活:3.x版本实现Dense与MoE混合架构,既有Dense的32B版本,也有MoE的235B-A22B版本,适配不同的部署场景;
- 双模式支持:支持thinking模式和non-thinking模式,二者在训练阶段融合,可通过tokenizer灵活切换,无需开发两套模型,同时支持thinking budget控制思考token长度上限;
- 全模态覆盖:从文本、视觉、音频到端到端全模态交互,Omni版本实现了真正的多模态融合,完美适配虚拟人"语音+文本+视觉"的全场景交互需求;
- 长上下文支持:原生支持128K token上下文,能满足虚拟人长期记忆、多轮对话的需求。
2.2 DeepSeek系列:极致效率优化,成本控制标杆
DeepSeek是国内专注于模型效率与成本控制的大模型系列,也是开源社区生态最活跃的模型之一,在长上下文、推理效率、代码生成等领域有极强的竞争力,核心版本迭代如下:
| 版本 | 发布时间 | 核心能力突破 |
|---|---|---|
| DeepSeek Coder/LLM | 2023年11月 | 基础模型与代码生成模型正式发布 |
| DeepSeek-MoE | 2024年1月 | 国内首批MoE架构开源大模型 |
| DeepSeek V2 | 2024年5月 | 上下文扩展至128K,国内首批实现长上下文的开源模型 |
| DeepSeek V3 | 2024年11月 | 架构全面创新,长上下文效率、推理速度大幅提升 |
| DeepSeek R1 | 2024年11月 | 推理能力专项优化,开源推理模型标杆 |
核心技术特点:
- 架构创新:V3版本推出MLA(Multihead Latent Attention)多头潜注意力机制,大幅优化长上下文场景的内存占用与推理效率,完美适配虚拟人多轮长对话场景;
- 极致效率优化:支持FP8/混合精度训练,针对国产硬件(华为Ascend等)深度优化,同时通过集群通讯优化、Multi-Plane网络拓扑,大幅降低通信瓶颈,让大模型在资源受限场景下也能落地;
- 长上下文能力:国内首批将上下文从4K扩展到128K的开源模型,通过YaRN等机制优化长上下文处理效果,最新版本引入Sparse Attention机制,进一步降低长上下文的计算与内存成本;
- 开源生态完善:公开的技术报告全面、详细,开源社区活跃度高,二次开发与定制化门槛低,是中小团队虚拟人落地的首选方案之一。
2.3 清华技术谱系三大分支:学术正统,多赛道全面覆盖
国内大模型领域,清华系是绝对的中坚力量,衍生出三大核心分支,覆盖学术、C端、商业落地三大场景,也是虚拟人场景的主流方案。
2.3.1 GLM系列:智谱AI出品,学术正统,B端标杆
GLM系列源自清华大学KEG实验室与AMiner团队(唐杰教授),是国内学术背景最深厚的大模型系列,偏B端企业服务,最新的GLM 4.5V是国内开源多模态模型的龙头产品。
- 核心优势:多模态能力强,中文理解与生成效果顶尖,企业级服务生态完善,合规性强,适合金融、政企等行业的虚拟人落地;
- 版本迭代:从2021年GLM初代发布,到2023年ChatGLM引爆开源社区,再到2025年GLM 4.5/4.6版本,持续优化基础能力、多模态与长上下文支持。
2.3.2 Kimi系列:月之暗面出品,长上下文C端标杆
Kimi源自清华大学自然语言处理与认知计算方向的研究者,偏C端用户,从诞生之初就以超长上下文处理能力闻名。
- 核心优势:超长上下文支持、上下文缓存机制优化,能处理百万级token的长文本,交互流畅度高,适合需要处理大量知识库、FAQ语料的虚拟人场景,比如虚拟客服、虚拟讲师;
- 核心迭代:2025年推出Kimi 2版本,优化音频理解、Agent能力,推出"OK Computer"Agent模式,能实现更复杂的任务调度,为虚拟人增加了复杂任务处理能力。
2.3.3 Baichuan百川智能:王小川领衔,商业落地标杆
百川智能源自清华系企业家王小川领衔的团队,兼顾技术与商业市场化,早期聚焦于对话对齐、指令优化、安全策略,现在走"基础模型+垂直增强"的路线。
- 核心优势:中文对话对齐效果好,安全合规体系完善,垂直行业落地经验丰富,适合商业化、To C的虚拟人场景,比如虚拟陪伴、直播带货虚拟主播。
3 大语言模型评测体系:如何选到适合虚拟人的LLM
面对众多的大模型,我们该如何判断哪个更适合自己的虚拟人场景?核心是通过标准化的评测体系,从通用能力、垂直任务能力、交互能力三个维度进行评估。
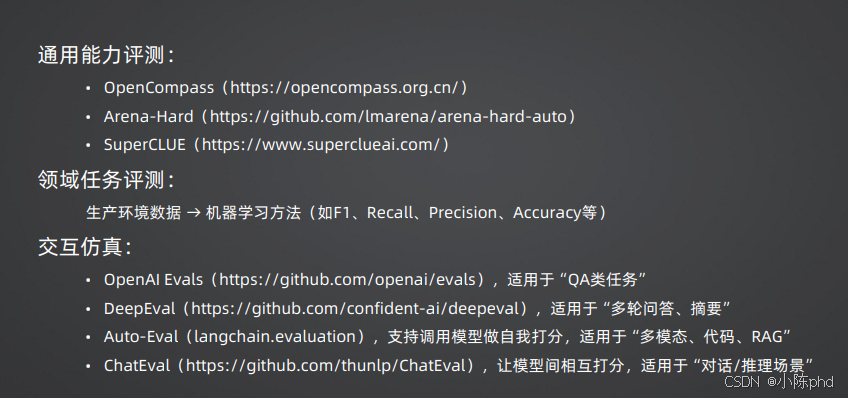
3.1 通用能力评测
通用能力评测,主要评估模型的基础理解、生成、推理、知识储备能力,主流的权威评测平台如下:
- OpenCompass:国内最权威的大模型开源评测平台,覆盖全维度通用能力评测;
- Arena-Hard:国际主流的大模型对战式评测平台,通过盲测评估模型的对话效果;
- SuperCLUE:中文大模型权威评测平台,聚焦中文场景的能力评估。
3.2 垂直任务能力评测
虚拟人落地往往有明确的垂直场景,比如直播带货、金融客服、文旅讲解,这就需要针对垂直任务做专项评测,核心方法是:
- 构建场景专属的生产环境测试数据集;
- 通过机器学习核心指标评估模型效果,核心指标包括:
- 准确率(Accuracy):回答正确的比例;
- 精确率(Precision):相关回答占总回答的比例;
- 召回率(Recall):能覆盖的场景问题比例;
- F1值:精确率与召回率的调和平均,综合评估模型效果。
3.3 交互仿真评测
虚拟人的核心是"交互",因此交互能力评测是重中之重,核心是模拟真实的用户交互场景,评估模型的多轮对话、任务完成、安全合规能力,主流的评测框架如下:
| 评测框架 | 出品方 | 核心适用场景 |
|---|---|---|
| OpenAI Evals | OpenAI | QA类问答任务,虚拟人基础答疑能力评测 |
| DeepEval | Confident AI | 多轮问答、摘要生成,虚拟人长对话能力评测 |
| Auto-Eval | LangChain | 多模态、代码、RAG场景,知识库型虚拟人评测 |
| ChatEval | 清华大学 | 模型间相互打分,对话、推理场景的虚拟人评测 |
我们以"差旅报销审核虚拟人"为例,核心交互评测指标如下:
| 指标名称 | 核心含义 | 计算方式 |
|---|---|---|
| TaskSuccess | 模型是否按正确流程完成全部审核任务 | 校验工具调用顺序是否正确、是否完成全部关键步骤、是否合规、交互轮次是否达标 |
| TurnsToSuccess | 完成审核任务所需的交互轮次,轮次越少效率越高 | 记录从用户发起请求到模型给出结论的总交互轮次 |
| Corrections | 模型重复回复的次数,次数越少流畅度越高 | 对比当前回复与上一轮回复,统计重复次数 |
| PolicySafe | 模型是否遵守隐私安全规则 | 检测回复中是否包含索取验证码、银行卡密码等敏感内容 |
| StepCoverage | 完成审核流程关键步骤的比例,越接近1完整性越好 | 统计完成的关键步骤数量,除以总步骤数得出比例 |
核心总结
大语言模型是虚拟人的"大脑",决定了虚拟人的交互上限。
- 如果你需要全模态能力、完善的生态,通义千问Qwen系列是首选;
- 如果你关注推理效率、部署成本,DeepSeek系列是最优解;
- 如果你需要企业级合规性、垂直行业落地,GLM系列、百川系列更适配;
- 如果你需要超长上下文、知识库问答能力,Kimi系列更有优势。
而选择模型的核心,不是盲目追求参数最大、能力最全的模型,而是根据你的虚拟人落地场景,选择最适配、性价比最高的方案,同时通过标准化的评测体系,验证模型在真实场景中的效果。
拓展指引
下一篇:《核心技术篇③ | 虚拟人的声音:语音合成与声音克隆从原理到落地》,我们会拆解虚拟人的"嗓子",从语音合成、语气控制,到声音克隆、工业级落地,教你给虚拟人配上专属的、有情感的声音。