import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.cluster import KMeans
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# 可选导入seaborn
try:
import seaborn as sns
seaborn_available = True
except ImportError:
seaborn_available = False
# 提供一个替代的sns模块占位符
class SnsStub:
def __getattr__(self, name):
def stub_function(*args, **kwargs):
# 静默返回None或空值
return None
return stub_function
sns = SnsStub()
# 页面配置
st.set_page_config(page_title="游戏玩家数据分析平台", page_icon="🎮", layout="wide")
# 自定义CSS
st.markdown("""
<style>
.main-header {
font-size: 3rem;
font-weight: 800;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
text-align: center;
padding: 30px 0;
margin-bottom: 20px;
}
.metric-card {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
padding: 20px;
border-radius: 15px;
color: white;
box-shadow: 0 4px 20px rgba(0, 0, 0, 0.1);
transition: transform 0.3s ease;
}
.metric-card:hover {
transform: translateY(-5px);
}
.stMetric [data-baseweb="metric-label"] {
color: white;
font-weight: 600;
font-size: 0.9rem;
opacity: 0.9;
}
.stMetric [data-baseweb="metric-value"] {
color: white;
font-size: 2.2rem;
font-weight: 700;
}
.section-header {
font-size: 1.8rem;
font-weight: 700;
color: #2c3e50;
margin: 25px 0 15px 0;
padding-bottom: 10px;
border-bottom: 3px solid #3498db;
}
.info-card {
background: linear-gradient(135deg, #3498db 0%, #2c3e50 100%);
padding: 25px;
border-radius: 15px;
color: white;
margin: 15px 0;
box-shadow: 0 4px 15px rgba(52, 152, 219, 0.2);
}
.warning-card {
background: linear-gradient(135deg, #f39c12 0%, #e74c3c 100%);
padding: 25px;
border-radius: 15px;
color: white;
margin: 15px 0;
box-shadow: 0 4px 15px rgba(243, 156, 18, 0.2);
}
.success-card {
background: linear-gradient(135deg, #2ecc71 0%, #27ae60 100%);
padding: 25px;
border-radius: 15px;
color: white;
margin: 15px 0;
box-shadow: 0 4px 15px rgba(46, 204, 113, 0.2);
}
.sidebar .sidebar-content {
background: linear-gradient(180deg, #2c3e50 0%, #1a252f 100%);
}
.stSelectbox, .stRadio, .stExpander {
margin-bottom: 15px;
}
.stExpander > div {
border-radius: 10px !important;
border: 1px solid #e0e0e0;
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.05);
}
.stTab {
margin-top: 20px;
}
.feature-icon {
font-size: 2.5rem;
margin-bottom: 10px;
}
.feature-title {
font-size: 1.3rem;
font-weight: 600;
margin-bottom: 10px;
}
.feature-description {
font-size: 0.95rem;
color: #666;
line-height: 1.5;
}
</style>
""", unsafe_allow_html=True)
# 数据加载与处理
@st.cache_data
def load_data(file):
df = pd.read_csv(file)
df['日均时长'] = pd.to_numeric(df['日均时长'], errors='coerce')
df['累计消费'] = pd.to_numeric(df['累计消费'], errors='coerce')
df['综合胜率'] = pd.to_numeric(df['综合胜率'], errors='coerce')
df['KDA指数'] = pd.to_numeric(df['KDA指数'], errors='coerce')
df['玩家年龄'] = pd.to_numeric(df['玩家年龄'], errors='coerce')
return df
@st.cache_data
def preprocess_data(df):
df_processed = df.copy()
# 段位编码
rank_order = ['荣耀青铜', '秩序白银', '尊贵铂金', '永恒钻石', '至尊星耀', '最强王者']
df_processed['段位等级'] = df_processed['游戏段位'].map({r: i+1 for i, r in enumerate(rank_order)})
# 登录频率编码
login_order = ['每月几次', '每周1-2次', '每周3-5次', '每天']
df_processed['登录频率等级'] = df_processed['登录频率'].map({l: i+1 for i, l in enumerate(login_order)})
# 年龄分段
df_processed['年龄分段'] = pd.cut(df_processed['玩家年龄'],
bins=[0, 18, 25, 30, 100],
labels=['青少年', '青年', '成年', '中老年'])
# 消费分段 - 在预处理阶段创建,确保所有函数都能访问
df_processed['消费分段'] = pd.cut(df_processed['累计消费'],
bins=[0, 20, 100, float('inf')],
labels=['低消费', '中消费', '高消费'])
# 时长分段
df_processed['时长分段'] = pd.cut(df_processed['日均时长'],
bins=[0, 2, 4, 6, float('inf')],
labels=['0-2小时', '2-4小时', '4-6小时', '6+小时'])
# 活跃度分数 - 在预处理阶段计算
df_processed['活跃度分数'] = (
df_processed['登录频率等级'] * 0.6 +
(df_processed['日均时长'] / df_processed['日均时长'].max()) * 0.4
)
# 活跃度分段
df_processed['活跃度分段'] = pd.qcut(df_processed['活跃度分数'],
q=[0, 0.33, 0.66, 1],
labels=['流失用户', '普通用户', '核心用户'])
# 技能分数
df_processed['技能分数'] = (
df_processed['段位等级'] * 0.4 +
df_processed['综合胜率'] * 100 * 0.3 +
(df_processed['KDA指数'] / df_processed['KDA指数'].max()) * 30
)
# 技能分段
df_processed['技能分段'] = pd.qcut(df_processed['技能分数'],
q=[0, 0.33, 0.66, 1],
labels=['新手', '进阶', '高手'])
return df_processed
def calculate_metrics(df):
metrics = {
'总玩家数': len(df),
'平均年龄': round(df['玩家年龄'].mean(), 1),
'平均日均时长': round(df['日均时长'].mean(), 1),
'总累计消费': round(df['累计消费'].sum(), 2),
'平均累计消费': round(df['累计消费'].mean(), 2),
'平均胜率': round(df['综合胜率'].mean() * 100, 1),
'平均KDA': round(df['KDA指数'].mean(), 1),
}
return metrics
def predict_churn_risk(row):
"""预测流失风险评分"""
login_score = {'每月几次': 3, '每周1-2次': 2, '每周3-5次': 1, '每天': 0}
behavior_score = {'娱乐型': 1, '休闲型': 2, '社交型': 3, '收藏型': 2, '竞技型': 4}
risk = (login_score.get(row['登录频率'], 2) * 0.4 +
(1 if row['日均时长'] < 2 else 0) * 0.3 +
behavior_score.get(row['行为模式'], 2) * 0.3)
return min(risk, 3)
def predict_pay_potential(row):
"""预测付费潜力"""
if row['累计消费'] > 100:
return '高'
elif row['累计消费'] > 20:
return '中'
else:
return '低'
def predict_promotion_time(row):
"""预测段位晋升时间"""
if row['游戏段位'] == '最强王者':
return '已达巅峰'
elif row['KDA指数'] > 4 and row['综合胜率'] > 0.55:
return '1-2周'
elif row['KDA指数'] > 3 and row['综合胜率'] > 0.5:
return '2-4周'
else:
return '4-8周'
# 用户画像分析
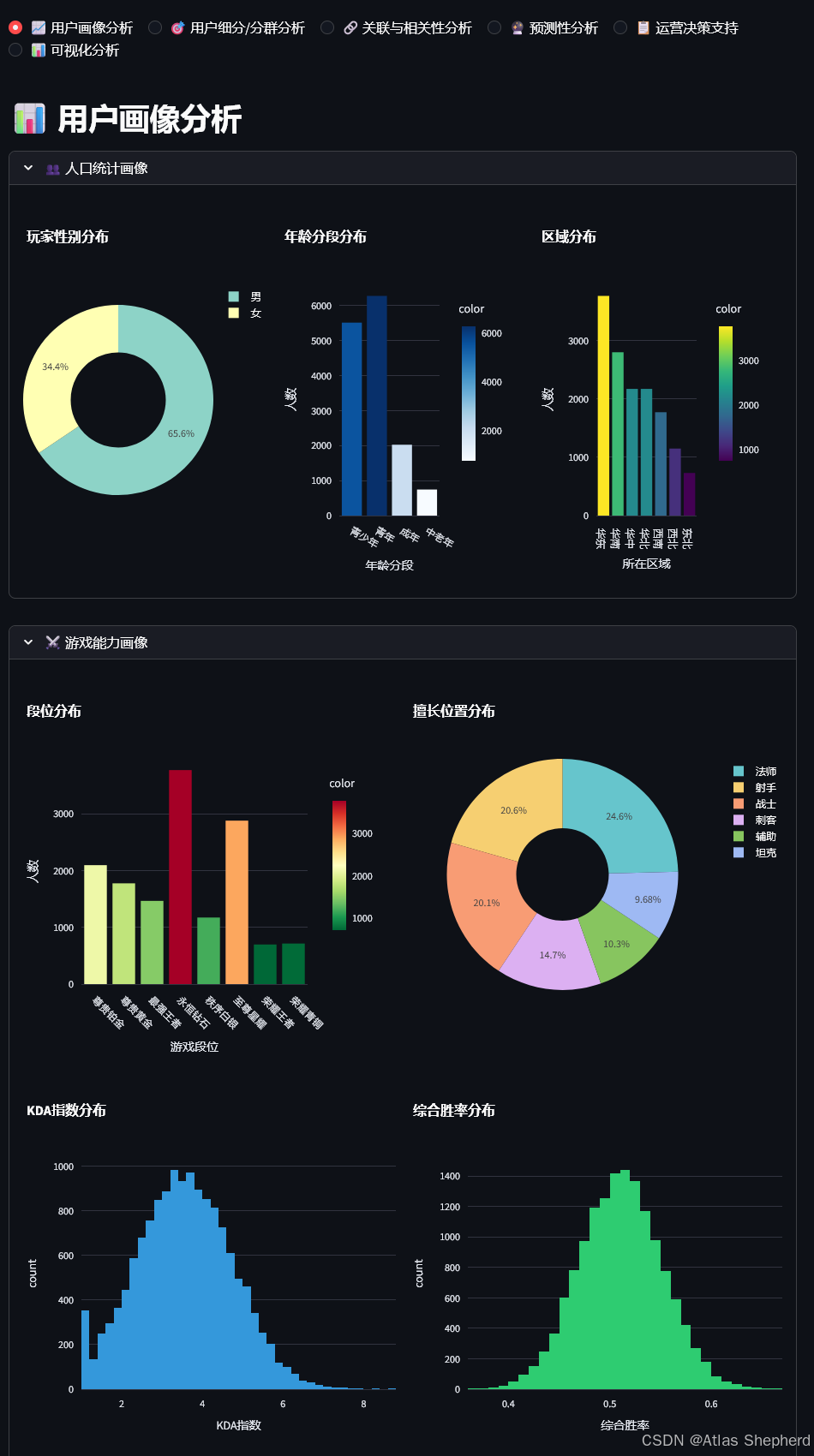
def user_profile_analysis(df, df_processed):
st.markdown("## 📊 用户画像分析")
# 1. 人口统计画像
with st.expander("👥 人口统计画像", expanded=True):
col1, col2, col3 = st.columns(3)
with col1:
gender_dist = df['玩家性别'].value_counts()
fig_gender = px.pie(gender_dist, values=gender_dist.values, names=gender_dist.index,
title='玩家性别分布', hole=0.5,
color_discrete_sequence=px.colors.qualitative.Set3)
st.plotly_chart(fig_gender, use_container_width=True)
with col2:
age_dist = df_processed['年龄分段'].value_counts().sort_index()
fig_age = px.bar(age_dist, x=age_dist.index, y=age_dist.values,
title='年龄分段分布',
labels={'x': '年龄段', 'y': '人数'},
color=age_dist.values,
color_continuous_scale='Blues')
st.plotly_chart(fig_age, use_container_width=True)
with col3:
region_dist = df['所在区域'].value_counts()
fig_region = px.bar(region_dist, x=region_dist.index, y=region_dist.values,
title='区域分布',
labels={'x': '区域', 'y': '人数'},
color=region_dist.values,
color_continuous_scale='Viridis')
st.plotly_chart(fig_region, use_container_width=True)
# 2. 游戏能力画像
with st.expander("⚔️ 游戏能力画像", expanded=True):
col1, col2 = st.columns(2)
with col1:
rank_dist = df['游戏段位'].value_counts().sort_index()
fig_rank = px.bar(rank_dist, x=rank_dist.index, y=rank_dist.values,
title='段位分布',
labels={'x': '段位', 'y': '人数'},
color=rank_dist.values,
color_continuous_scale='RdYlGn_r')
fig_rank.update_xaxes(tickangle=45)
st.plotly_chart(fig_rank, use_container_width=True)
with col2:
position_dist = df['擅长位置'].value_counts()
fig_position = px.pie(position_dist, values=position_dist.values, names=position_dist.index,
title='擅长位置分布', hole=0.4,
color_discrete_sequence=px.colors.qualitative.Pastel)
st.plotly_chart(fig_position, use_container_width=True)
# KDA和胜率分布
col1, col2 = st.columns(2)
with col1:
fig_kda = px.histogram(df, x='KDA指数', nbins=50,
title='KDA指数分布',
color_discrete_sequence=['#3498db'])
st.plotly_chart(fig_kda, use_container_width=True)
with col2:
fig_winrate = px.histogram(df, x='综合胜率', nbins=50,
title='综合胜率分布',
color_discrete_sequence=['#2ecc71'])
st.plotly_chart(fig_winrate, use_container_width=True)
# 3. 行为习惯画像
with st.expander("🎯 行为习惯画像", expanded=True):
col1, col2, col3 = st.columns(3)
with col1:
login_dist = df['登录频率'].value_counts()
login_order = ['每天', '每周3-5次', '每周1-2次', '每月几次']
login_dist = login_dist.reindex(login_order)
fig_login = px.bar(login_dist, x=login_dist.index, y=login_dist.values,
title='登录频率分布',
labels={'x': '登录频率', 'y': '人数'},
color=login_dist.values,
color_continuous_scale='YlOrRd')
st.plotly_chart(fig_login, use_container_width=True)
with col2:
behavior_dist = df['行为模式'].value_counts()
fig_behavior = px.pie(behavior_dist, values=behavior_dist.values, names=behavior_dist.index,
title='行为模式分布', hole=0.5,
color_discrete_sequence=px.colors.qualitative.Bold)
st.plotly_chart(fig_behavior, use_container_width=True)
with col3:
fig_duration = px.histogram(df, x='日均时长', nbins=50,
title='日均时长分布',
color_discrete_sequence=['#9b59b6'])
st.plotly_chart(fig_duration, use_container_width=True)
# 4. 消费能力画像
with st.expander("💰 消费能力画像", expanded=True):
col1, col2 = st.columns(2)
# 直接使用预处理阶段创建的消费分段
spend_dist = df_processed['消费分段'].value_counts()
with col1:
fig_spend = px.pie(spend_dist, values=spend_dist.values, names=spend_dist.index,
title='消费能力分布', hole=0.5,
color_discrete_sequence=['#95a5a6', '#f39c12', '#e74c3c'])
st.plotly_chart(fig_spend, use_container_width=True)
with col2:
fig_spend_hist = px.histogram(df, x='累计消费', nbins=50,
title='累计消费金额分布',
color_discrete_sequence=['#16a085'])
st.plotly_chart(fig_spend_hist, use_container_width=True)
# 用户细分分析
def segmentation_analysis(df, df_processed):
st.markdown("## 🎯 用户细分/分群分析")
# 1. 按价值分群
with st.expander("💎 按价值分群", expanded=True):
col1, col2 = st.columns(2)
with col1:
spend_segment = df_processed['消费分段'].value_counts()
fig_spend_seg = px.bar(spend_segment, x=spend_segment.index, y=spend_segment.values,
title='价值分群(按累计消费)',
labels={'x': '消费级别', 'y': '人数'},
color=spend_segment.index,
color_discrete_map={'低消费': '#95a5a6', '中消费': '#f39c12', '高消费': '#e74c3c'})
st.plotly_chart(fig_spend_seg, use_container_width=True)
with col2:
# 高价值用户特征分析
high_value = df_processed[df_processed['消费分段'] == '高消费']
if len(high_value) > 0:
st.markdown("### 高价值用户特征")
col1, col2, col3 = st.columns(3)
with col1:
st.metric("人数", len(high_value))
with col2:
st.metric("平均胜率", f"{high_value['综合胜率'].mean()*100:.1f}%")
with col3:
st.metric("平均KDA", f"{high_value['KDA指数'].mean():.1f}")
# 2. 按活跃度分群
with st.expander("🔥 按活跃度分群", expanded=True):
col1, col2 = st.columns(2)
with col1:
active_dist = df_processed['活跃度分段'].value_counts()
fig_active = px.bar(active_dist, x=active_dist.index, y=active_dist.values,
title='活跃度分群',
labels={'x': '活跃度级别', 'y': '人数'},
color=active_dist.values,
color_continuous_scale='RdYlGn')
st.plotly_chart(fig_active, use_container_width=True)
with col2:
# 活跃度与消费关系
fig_active_spend = px.box(df_processed, x='活跃度分段', y='累计消费',
title='不同活跃度用户的消费分布',
color='活跃度分段')
st.plotly_chart(fig_active_spend, use_container_width=True)
# 3. 按技能分群
with st.expander("🎮 按技能分群", expanded=True):
col1, col2 = st.columns(2)
with col1:
skill_dist = df_processed['技能分段'].value_counts()
fig_skill = px.pie(skill_dist, values=skill_dist.values, names=skill_dist.index,
title='技能水平分群', hole=0.5,
color_discrete_sequence=['#3498db', '#f39c12', '#e74c3c'])
st.plotly_chart(fig_skill, use_container_width=True)
with col2:
# 技能与活跃度关系
fig_skill_active = px.scatter(df_processed, x='技能分数', y='活跃度分数',
color='技能分段',
title='技能分数 vs 活跃度分数',
labels={'技能分数': '技能分数', '活跃度分数': '活跃度分数'},
hover_data=['游戏段位', '综合胜率'])
st.plotly_chart(fig_skill_active, use_container_width=True)
# 4. 按偏好分群
with st.expander("⭐ 按偏好分群", expanded=True):
# 确保df_processed中有消费分段字段
if '消费分段' in df_processed.columns:
# 创建一个包含擅长位置和消费分段的DataFrame用于分组
temp_df = df_processed[['擅长位置', '消费分段']].copy()
position_analysis = temp_df.groupby(['擅长位置', '消费分段']).size().unstack(fill_value=0)
fig_position_spend = px.bar(position_analysis.reset_index().melt(id_vars=['擅长位置'],
var_name='消费级别',
value_name='人数'),
x='擅长位置', y='人数', color='消费级别',
title='不同位置偏好的消费分布',
barmode='stack',
color_discrete_map={'低消费': '#95a5a6', '中消费': '#f39c12', '高消费': '#e74c3c'})
st.plotly_chart(fig_position_spend, use_container_width=True)
else:
st.warning("消费分段字段不存在,无法进行偏好分群分析")
# 5. 按行为分群
with st.expander("🎭 按行为分群", expanded=True):
col1, col2 = st.columns(2)
with col1:
behavior_rank = df.groupby(['行为模式', '游戏段位']).size().unstack(fill_value=0)
fig_behavior_rank = px.bar(behavior_rank.reset_index().melt(id_vars=['行为模式'],
var_name='段位',
value_name='人数'),
x='行为模式', y='人数', color='段位',
title='不同行为模式的段位分布',
barmode='stack')
st.plotly_chart(fig_behavior_rank, use_container_width=True)
with col2:
# 确保df_processed中有消费分段字段
if '消费分段' in df_processed.columns:
# 创建一个包含行为模式和消费分段的DataFrame用于分组
temp_df = df_processed[['行为模式', '消费分段']].copy()
behavior_spend = temp_df.groupby(['行为模式', '消费分段']).size().unstack(fill_value=0)
fig_behavior_spend = px.bar(behavior_spend.reset_index().melt(id_vars=['行为模式'],
var_name='消费级别',
value_name='人数'),
x='行为模式', y='人数', color='消费级别',
title='不同行为模式的消费分布',
barmode='stack',
color_discrete_map={'低消费': '#95a5a6', '中消费': '#f39c12', '高消费': '#e74c3c'})
st.plotly_chart(fig_behavior_spend, use_container_width=True)
else:
st.warning("消费分段字段不存在,无法进行行为模式的消费分布分析")
# 关联与相关性分析
def correlation_analysis(df, df_processed):
st.markdown("## 🔗 关联与相关性分析")
# 1. 消费驱动因素
with st.expander("💰 消费驱动因素分析", expanded=True):
col1, col2 = st.columns(2)
with col1:
# 创建一个包含所需字段的DataFrame用于散点图
scatter_df = df_processed[['日均时长', '累计消费']].copy()
if '消费分段' in df_processed.columns:
scatter_df['消费分段'] = df_processed['消费分段']
fig_spend_duration = px.scatter(scatter_df, x='日均时长', y='累计消费',
title='日均时长 vs 累计消费',
color='消费分段',
labels={'日均时长': '日均时长(小时)', '累计消费': '累计消费(元)'})
else:
fig_spend_duration = px.scatter(scatter_df, x='日均时长', y='累计消费',
title='日均时长 vs 累计消费',
labels={'日均时长': '日均时长(小时)', '累计消费': '累计消费(元)'})
st.plotly_chart(fig_spend_duration, use_container_width=True)
with col2:
fig_spend_rank = px.box(df, x='游戏段位', y='累计消费',
title='不同段位的消费分布',
labels={'游戏段位': '段位', '累计消费': '累计消费(元)'})
fig_spend_rank.update_xaxes(tickangle=45)
st.plotly_chart(fig_spend_rank, use_container_width=True)
with col1:
fig_spend_winrate = px.scatter(df, x='综合胜率', y='累计消费',
title='综合胜率 vs 累计消费',
labels={'综合胜率': '胜率', '累计消费': '累计消费(元)'})
st.plotly_chart(fig_spend_winrate, use_container_width=True)
# 2. 活跃度影响因素
with st.expander("📊 活跃度影响因素分析", expanded=True):
col1, col2 = st.columns(2)
with col1:
login_age = df.groupby(['玩家年龄', '登录频率']).size().unstack(fill_value=0)
login_age.columns.name = '登录频率'
fig_login_age = px.imshow(login_age.values,
x=login_age.columns,
y=login_age.index,
title='年龄 vs 登录频率热力图',
labels=dict(x="登录频率", y="年龄", color="人数"),
aspect="auto")
st.plotly_chart(fig_login_age, use_container_width=True)
with col2:
login_region = df.groupby(['所在区域', '登录频率']).size().unstack(fill_value=0)
login_region.columns.name = '登录频率'
fig_login_region = px.imshow(login_region.values,
x=login_region.columns,
y=login_region.index,
title='区域 vs 登录频率热力图',
labels=dict(x="登录频率", y="区域", color="人数"))
st.plotly_chart(fig_login_region, use_container_width=True)
# 3. 技能成长路径
with st.expander("📈 技能成长路径分析", expanded=True):
col1, col2 = st.columns(2)
with col1:
fig_kda_duration = px.scatter(df, x='日均时长', y='KDA指数',
title='日均时长 vs KDA指数',
color='游戏段位',
labels={'日均时长': '日均时长(小时)', 'KDA指数': 'KDA指数'})
st.plotly_chart(fig_kda_duration, use_container_width=True)
with col2:
fig_kda_rank = px.box(df, x='游戏段位', y='KDA指数',
title='不同段位的KDA分布',
labels={'游戏段位': '段位', 'KDA指数': 'KDA指数'})
fig_kda_rank.update_xaxes(tickangle=45)
st.plotly_chart(fig_kda_rank, use_container_width=True)
# 4. 区域差异分析
with st.expander("🗺️ 区域差异分析", expanded=True):
col1, col2, col3 = st.columns(3)
with col1:
region_spend = df.groupby('所在区域')['累计消费'].mean().sort_values(ascending=False)
fig_region_spend = px.bar(x=region_spend.index, y=region_spend.values,
title='各区域平均消费',
labels={'x': '区域', 'y': '平均消费(元)'},
color=region_spend.values,
color_continuous_scale='Plasma')
st.plotly_chart(fig_region_spend, use_container_width=True)
with col2:
region_active = df_processed.groupby('所在区域')['日均时长'].mean().sort_values(ascending=False)
fig_region_active = px.bar(x=region_active.index, y=region_active.values,
title='各区域平均日均时长',
labels={'x': '区域', 'y': '平均时长(小时)'},
color=region_active.values,
color_continuous_scale='Blues')
st.plotly_chart(fig_region_active, use_container_width=True)
with col3:
# 段位分布
region_rank = pd.crosstab(df['所在区域'], df['游戏段位'])
fig_region_rank = px.imshow(region_rank.values,
x=region_rank.columns,
y=region_rank.index,
title='区域 vs 段位分布热力图',
labels=dict(x="段位", y="区域", color="人数"))
st.plotly_chart(fig_region_rank, use_container_width=True)
# 预测性分析
def predictive_analysis(df, df_processed):
st.markdown("## 🔮 预测性分析")
# 1. 用户流失预测
with st.expander("⚠️ 用户流失预测", expanded=True):
df_processed['流失风险'] = df_processed.apply(predict_churn_risk, axis=1)
df_processed['流失风险等级'] = pd.cut(df_processed['流失风险'],
bins=[0, 1, 2, 3],
labels=['低风险', '中风险', '高风险'])
col1, col2 = st.columns(2)
with col1:
churn_dist = df_processed['流失风险等级'].value_counts()
fig_churn = px.pie(churn_dist, values=churn_dist.values, names=churn_dist.index,
title='流失风险分布', hole=0.5,
color_discrete_sequence=['#2ecc71', '#f39c12', '#e74c3c'])
st.plotly_chart(fig_churn, use_container_width=True)
with col2:
# 确保使用df_processed中包含消费分段字段的数据
if '消费分段' in df_processed.columns:
# 创建一个包含登录频率和消费分段的DataFrame用于分组
temp_df = df_processed[['登录频率', '消费分段']].copy()
churn_login = temp_df.groupby(['登录频率', '消费分段']).size().reset_index(name='人数')
fig_churn_login = px.bar(churn_login, x='登录频率', y='人数', color='消费分段',
title='登录频率与消费关系',
barmode='stack')
st.plotly_chart(fig_churn_login, use_container_width=True)
else:
# 如果消费分段不存在,使用游戏段位
temp_df = df_processed[['登录频率', '游戏段位']].copy()
churn_login = temp_df.groupby(['登录频率', '游戏段位']).size().reset_index(name='人数')
fig_churn_login = px.bar(churn_login, x='登录频率', y='人数', color='游戏段位',
title='登录频率与段位关系',
barmode='stack')
st.plotly_chart(fig_churn_login, use_container_width=True)
# 流失用户详细分析
st.markdown("### 高流失风险用户特征")
high_churn = df_processed[df_processed['流失风险等级'] == '高风险']
if len(high_churn) > 0:
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("高风险人数", len(high_churn))
with col2:
st.metric("平均日均时长", f"{high_churn['日均时长'].mean():.1f}h")
with col3:
st.metric("平均累计消费", f"¥{high_churn['累计消费'].mean():.1f}")
with col4:
st.metric("平均胜率", f"{high_churn['综合胜率'].mean()*100:.1f}%")
# 2. 付费潜力预测
with st.expander("💎 付费潜力预测", expanded=True):
df_processed['付费潜力'] = df_processed.apply(predict_pay_potential, axis=1)
col1, col2 = st.columns(2)
with col1:
potential_dist = df_processed['付费潜力'].value_counts()
fig_potential = px.pie(potential_dist, values=potential_dist.values, names=potential_dist.index,
title='付费潜力分布', hole=0.5,
color_discrete_sequence=['#3498db', '#f39c12', '#e74c3c'])
st.plotly_chart(fig_potential, use_container_width=True)
with col2:
potential_rank = df_processed.groupby(['付费潜力', '游戏段位']).size().reset_index(name='人数')
fig_potential_rank = px.bar(potential_rank, x='游戏段位', y='人数', color='付费潜力',
title='不同段位的付费潜力分布',
barmode='stack')
fig_potential_rank.update_xaxes(tickangle=45)
st.plotly_chart(fig_potential_rank, use_container_width=True)
# 3. 段位晋升预测
with st.expander("🏆 段位晋升预测", expanded=True):
df_processed['预计晋升时间'] = df_processed.apply(predict_promotion_time, axis=1)
col1, col2 = st.columns(2)
with col1:
promotion_dist = df_processed['预计晋升时间'].value_counts()
fig_promotion = px.bar(promotion_dist, x=promotion_dist.index, y=promotion_dist.values,
title='段位晋升时间预测分布',
labels={'x': '预计晋升时间', 'y': '人数'},
color=promotion_dist.values,
color_continuous_scale='RdYlGn_r')
st.plotly_chart(fig_promotion, use_container_width=True)
with col2:
promotion_kda = df_processed[df_processed['预计晋升时间'] != '已达巅峰'].groupby(
['预计晋升时间', '游戏段位']).size().reset_index(name='人数')
if len(promotion_kda) > 0:
fig_promotion_rank = px.bar(promotion_kda, x='游戏段位', y='人数', color='预计晋升时间',
title='不同段位的晋升时间预测',
barmode='stack')
fig_promotion_rank.update_xaxes(tickangle=45)
st.plotly_chart(fig_promotion_rank, use_container_width=True)
# 运营决策支持
def decision_support(df, df_processed):
st.markdown("## 📋 运营决策支持")
# 1. 高价值用户识别
with st.expander("💎 高价值用户识别", expanded=True):
df_processed['用户价值分'] = (
(df_processed['累计消费'] / df_processed['累计消费'].max()) * 100 * 0.5 +
df_processed['活跃度分数'] / df_processed['活跃度分数'].max() * 50 * 0.3 +
df_processed['技能分数'] / df_processed['技能分数'].max() * 20 * 0.2
)
top_users = df_processed.nlargest(10, '用户价值分')
st.markdown("### TOP 10 高价值用户")
user_display = top_users[['用户ID', '游戏段位', '累计消费', '日均时长', '综合胜率', 'KDA指数', '登录频率']].copy()
user_display['综合胜率'] = (user_display['综合胜率'] * 100).round(1).astype(str) + '%'
st.dataframe(user_display, use_container_width=True)
st.markdown("### 📌 运营建议")
st.info("""
**针对高价值用户的专属福利策略:**
- 发放专属限量皮肤/道具
- 提供优先客服通道
- 邀请参与内测和赛事
- 定期推送个性化内容推荐
- 设置VIP专属活动日
""")
# 2. 流失预警干预
with st.expander("⚠️ 流失预警干预", expanded=True):
# 如果流失风险等级字段不存在,先创建它
if '流失风险等级' not in df_processed.columns:
df_processed['流失风险'] = df_processed.apply(predict_churn_risk, axis=1)
df_processed['流失风险等级'] = pd.cut(df_processed['流失风险'],
bins=[0, 1, 2, 3],
labels=['低风险', '中风险', '高风险'])
high_churn = df_processed[df_processed['流失风险等级'] == '高风险'].nlargest(10, '累计消费')
if len(high_churn) > 0:
st.markdown("### 需要重点召回的高价值流失风险用户")
churn_display = high_churn[['用户ID', '游戏段位', '累计消费', '日均时长', '登录频率', '行为模式']].copy()
st.dataframe(churn_display, use_container_width=True)
else:
st.info("未发现高风险流失用户")
st.markdown("### 📌 召回策略")
st.warning("""
**对登录频率下降用户的召回活动:**
- 发送回归礼包和专属福利
- 推送好友互动提醒
- 邀请参与回归专属活动
- 根据行为模式推送个性化内容
- 设置连续登录奖励
""")
# 3. 匹配优化建议
with st.expander("⚔️ 匹配优化建议", expanded=True):
# 段位KDA统计
rank_stats = df.groupby('游戏段位').agg({
'综合胜率': 'mean',
'KDA指数': 'mean',
'日均时长': 'mean'
}).round(3)
st.markdown("### 各段位平均数据")
st.dataframe(rank_stats, use_container_width=True)
st.markdown("### 📌 匹配建议")
st.success("""
**根据段位、胜率、KDA优化对战匹配算法:**
- 扩大匹配考虑维度:综合胜率 + KDA指数 + 日均时长
- 设置动态匹配范围:活跃时间短的玩家匹配更接近水平的对手
- 引入段位保护机制:连续败北时适当降低匹配难度
- 组队匹配优化:综合计算队伍平均实力
- 避免新手对老手:根据注册时间和游戏时长增加匹配权重
""")
# 4. 内容推荐
with st.expander("🎯 内容推荐", expanded=True):
col1, col2 = st.columns(2)
with col1:
st.markdown("#### 按位置偏好推荐")
position_rec = df.groupby('擅长位置').agg({
'累计消费': 'mean',
'日均时长': 'mean',
'综合胜率': 'mean'
}).round(2)
st.dataframe(position_rec, use_container_width=True)
with col2:
st.markdown("#### 按行为模式推荐")
behavior_rec = df.groupby('行为模式').agg({
'累计消费': 'mean',
'日均时长': 'mean',
'玩家年龄': 'mean'
}).round(2)
st.dataframe(behavior_rec, use_container_width=True)
st.markdown("### 📌 推荐策略")
st.info("""
**根据擅长位置和行为模式推荐游戏内容:**
**竞技型玩家:**
- 推荐排位赛活动和赛事
- 新英雄/技能攻略
- 高段位对局回放
**社交型玩家:**
- 推荐组队开黑活动
- 好友系统功能
- 公会/战队内容
**休闲型玩家:**
- 推荐娱乐模式活动
- 皮肤和外观内容
- 成就任务系统
**收藏型玩家:**
- 推荐限定皮肤和道具
- 收集成就系统
- 稀有道具活动
""")
# 5. 定价策略
with st.expander("💰 定价策略", expanded=True):
region_pricing = df.groupby('所在区域').agg({
'累计消费': ['mean', 'median', 'std']
}).round(2)
region_pricing.columns = ['平均消费', '中位数消费', '消费标准差']
fig_region_pricing = px.bar(region_pricing, x=region_pricing.index, y='平均消费',
title='各区域平均消费对比',
labels={'x': '区域', '平均消费': '平均消费(元)'},
color='平均消费',
color_continuous_scale='Viridis')
st.plotly_chart(fig_region_pricing, use_container_width=True)
st.dataframe(region_pricing, use_container_width=True)
st.markdown("### 📌 定价建议")
st.info("""
**基于区域消费差异制定差异化定价:**
- **高消费区域**:可推出更多高价值礼包,提供会员专属服务
- **中等消费区域**:平衡定价策略,推出性价比优惠组合
- **低消费区域**:增加小额多次消费选项,降低单次消费门槛
- **区域性促销**:针对不同区域节日和特点推出活动
- **分层定价**:同一产品提供基础版、进阶版、豪华版
""")
# 可视化分析
def visualization_analysis(df, df_processed):
st.markdown("## 📊 可视化分析")
# 1. 用户分布
with st.expander("🗺️ 用户分布分析", expanded=True):
tab1, tab2 = st.tabs(["区域热力图", "年龄/段位金字塔"])
with tab1:
# 区域分布热力
region_age = pd.crosstab(df['所在区域'], df_processed['年龄分段'])
fig_region_heat = px.imshow(region_age.values,
x=region_age.columns,
y=region_age.index,
title='区域 × 年龄分布热力图',
labels=dict(x="年龄段", y="区域", color="人数"),
color_continuous_scale='YlOrRd',
aspect="auto")
st.plotly_chart(fig_region_heat, use_container_width=True)
with tab2:
# 年龄段位金字塔
rank_order = ['荣耀青铜', '秩序白银', '尊贵铂金', '永恒钻石', '至尊星耀', '最强王者']
age_order = ['青少年', '青年', '成年', '中老年']
pyramid_data = []
for age in age_order:
for rank in rank_order:
count = len(df_processed[(df_processed['年龄分段'] == age) & (df_processed['游戏段位'] == rank)])
pyramid_data.append({'年龄段': age, '段位': rank, '人数': count})
pyramid_df = pd.DataFrame(pyramid_data)
fig_pyramid = px.bar(pyramid_df, x='人数', y='段位',
color='年龄段',
orientation='h',
title='年龄×段位分布金字塔',
labels={'人数': '人数', '段位': '段位'},
barmode='stack',
color_discrete_map={'青少年': '#3498db', '青年': '#2ecc71',
'成年': '#f39c12', '中老年': '#e74c3c'})
st.plotly_chart(fig_pyramid, use_container_width=True)
# 2. 趋势分析
with st.expander("📈 趋势分析", expanded=True):
col1, col2 = st.columns(2)
with col1:
login_order = ['每月几次', '每周1-2次', '每周3-5次', '每天']
login_freq = df['登录频率'].value_counts().reindex(login_order)
fig_login_trend = px.line(x=login_freq.index, y=login_freq.values,
title='登录频率趋势',
labels={'x': '登录频率', 'y': '人数'},
markers=True)
fig_login_trend.update_traces(line_color='#3498db', marker_size=10)
st.plotly_chart(fig_login_trend, use_container_width=True)
with col2:
# 日均时长分段
df_processed['时长分段'] = pd.cut(df_processed['日均时长'],
bins=[0, 2, 4, 6, float('inf')],
labels=['0-2小时', '2-4小时', '4-6小时', '6+小时'])
duration_dist = df_processed['时长分段'].value_counts()
fig_duration_trend = px.bar(x=duration_dist.index, y=duration_dist.values,
title='日均时长分布',
labels={'x': '时长分段', 'y': '人数'},
color=duration_dist.values,
color_continuous_scale='Blues')
st.plotly_chart(fig_duration_trend, use_container_width=True)
# 3. 对比分析
with st.expander("📊 对比分析", expanded=True):
col1, col2 = st.columns(2)
with col1:
gender_spend = df.groupby('玩家性别')['累计消费'].mean().reset_index()
fig_gender_spend = px.bar(gender_spend, x='玩家性别', y='累计消费',
title='性别消费对比',
labels={'玩家性别': '性别', '累计消费': '平均消费(元)'},
color='累计消费',
color_continuous_scale='RdYlGn')
st.plotly_chart(fig_gender_spend, use_container_width=True)
with col2:
region_active = df_processed.groupby('所在区域')['日均时长'].mean().sort_values(ascending=False).reset_index()
fig_region_active = px.bar(region_active, x='所在区域', y='日均时长',
title='区域活跃度对比',
labels={'所在区域': '区域', '日均时长': '平均日均时长(小时)'},
color='日均时长',
color_continuous_scale='YlOrRd')
st.plotly_chart(fig_region_active, use_container_width=True)
# 性别段位对比
col1, col2 = st.columns(2)
with col1:
gender_rank = pd.crosstab(df['玩家性别'], df['游戏段位'])
fig_gender_rank = px.imshow(gender_rank.values,
x=gender_rank.columns,
y=gender_rank.index,
title='性别 × 段位分布热力图',
labels=dict(x="段位", y="性别", color="人数"),
color_continuous_scale='Viridis',
aspect="auto")
st.plotly_chart(fig_gender_rank, use_container_width=True)
with col2:
gender_kda = df.groupby('玩家性别')[['KDA指数', '综合胜率']].mean()
gender_kda['综合胜率'] = gender_kda['综合胜率'] * 100
fig_gender_kda = px.bar(gender_kda.reset_index().melt(id_vars=['玩家性别']),
x='玩家性别', y='value', color='variable',
title='性别 × 技能指标对比',
labels={'玩家性别': '性别', 'value': '数值', 'variable': '指标'},
barmode='group')
st.plotly_chart(fig_gender_kda, use_container_width=True)
# 4. 关联分析(散点图)
with st.expander("🔗 关联分析", expanded=True):
col1, col2 = st.columns(2)
with col1:
fig_scatter1 = px.scatter(df, x='日均时长', y='累计消费',
title='日均时长 vs 累计消费',
labels={'日均时长': '日均时长(小时)', '累计消费': '累计消费(元)'},
color='游戏段位',
opacity=0.6)
st.plotly_chart(fig_scatter1, use_container_width=True)
with col2:
fig_scatter2 = px.scatter(df, x='综合胜率', y='KDA指数',
title='综合胜率 vs KDA指数',
labels={'综合胜率': '胜率', 'KDA指数': 'KDA指数'},
color='游戏段位',
opacity=0.6)
st.plotly_chart(fig_scatter2, use_container_width=True)
# 3D散点图
fig_3d = px.scatter_3d(df, x='日均时长', y='累计消费', z='综合胜率',
color='游戏段位',
title='多维度关联分析(3D)',
labels={'日均时长': '日均时长', '累计消费': '累计消费', '综合胜率': '胜率'},
opacity=0.7)
st.plotly_chart(fig_3d, use_container_width=True)
# 5. 分群分析(雷达图)
with st.expander("🎯 分群分析 - 用户画像雷达图", expanded=True):
col1, col2 = st.columns(2)
with col1:
# 按行为模式分群
behavior_radar = df.groupby('行为模式').agg({
'玩家年龄': 'mean',
'日均时长': 'mean',
'累计消费': 'mean',
'综合胜率': 'mean',
'KDA指数': 'mean'
}).reset_index()
behavior_radar['综合胜率'] = behavior_radar['综合胜率'] * 100
fig_radar1 = px.line_polar(behavior_radar, r='综合胜率', theta='行为模式',
line_close=True, title='各行为模式胜率对比')
st.plotly_chart(fig_radar1, use_container_width=True)
with col2:
# 按段位分群
rank_radar = df.groupby('游戏段位').agg({
'日均时长': 'mean',
'累计消费': 'mean',
'综合胜率': 'mean',
'KDA指数': 'mean'
}).reset_index()
rank_radar['综合胜率'] = rank_radar['综合胜率'] * 100
# 标准化数据用于雷达图
radar_data = rank_radar.melt(id_vars=['游戏段位'], var_name='指标', value_name='数值')
for col in ['日均时长', '累计消费', '综合胜率', 'KDA指数']:
max_val = radar_data[radar_data['指标'] == col]['数值'].max()
radar_data.loc[radar_data['指标'] == col, '数值'] = radar_data.loc[
radar_data['指标'] == col, '数值'] / max_val * 100
fig_radar2 = px.line_polar(radar_data[radar_data['游戏段位'] == '最强王者'],
r='数值', theta='指标',
line_close=True, title='最强王者玩家画像')
st.plotly_chart(fig_radar2, use_container_width=True)
# 多行为模式对比雷达图
st.markdown("### 各行为模式综合画像对比")
fig_radar_compare = go.Figure()
categories = ['年龄', '日均时长', '累计消费', '胜率', 'KDA']
for behavior in ['竞技型', '社交型', '休闲型', '娱乐型', '收藏型']:
if behavior in behavior_radar['行为模式'].values:
data = behavior_radar[behavior_radar['行为模式'] == behavior].iloc[0]
values = [
(data['玩家年龄'] / behavior_radar['玩家年龄'].max()) * 100,
(data['日均时长'] / behavior_radar['日均时长'].max()) * 100,
(data['累计消费'] / behavior_radar['累计消费'].max()) * 100,
data['综合胜率'],
(data['KDA指数'] / behavior_radar['KDA指数'].max()) * 100
]
fig_radar_compare.add_trace(go.Scatterpolar(
r=values,
theta=categories,
fill='toself',
name=behavior
))
fig_radar_compare.update_layout(
polar=dict(radialaxis=dict(visible=True, range=[0, 100])),
showlegend=True,
title="各行为模式综合画像对比(标准化后)"
)
st.plotly_chart(fig_radar_compare, use_container_width=True)
# 主函数
def main():
# 标题
st.markdown('<div class="main-header">🎮 游戏玩家数据分析平台</div>', unsafe_allow_html=True)
# 侧边栏
with st.sidebar:
st.header("📂 数据上传")
# 文件上传
uploaded_file = st.file_uploader("上传CSV文件", type=['csv'])
if uploaded_file:
st.success(f"✅ 已加载: {uploaded_file.name}")
else:
st.info("💡 请上传包含玩家数据的CSV文件")
st.markdown("""
**数据格式要求:**
- 用户ID
- 玩家性别
- 玩家年龄
- 所在区域
- 游戏段位
- 日均时长
- 累计消费
- 擅长位置
- 综合胜率
- KDA指数
- 登录频率
- 行为模式
""")
# 默认使用示例数据
if uploaded_file is None:
try:
import os
default_file = r"d:\daku\游戏玩家数据分析\player_behavior_data.csv"
if os.path.exists(default_file):
uploaded_file = open(default_file, 'rb', encoding=None)
st.info(f"使用默认数据: {os.path.basename(default_file)}")
except:
pass
# 数据加载
if uploaded_file:
df = load_data(uploaded_file)
df_processed = preprocess_data(df)
# 显示关键指标
metrics = calculate_metrics(df)
st.markdown("---")
col1, col2, col3, col4, col5, col6, col7 = st.columns(7)
with col1:
st.metric("👥 总玩家数", metrics['总玩家数'])
with col2:
st.metric("🎂 平均年龄", f"{metrics['平均年龄']}岁")
with col3:
st.metric("⏱️ 平均日均时长", f"{metrics['平均日均时长']}h")
with col4:
st.metric("💰 总累计消费", f"¥{metrics['总累计消费']:,.0f}")
with col5:
st.metric("💵 平均消费", f"¥{metrics['平均累计消费']:.1f}")
with col6:
st.metric("🏆 平均胜率", f"{metrics['平均胜率']}%")
with col7:
st.metric("⚔️ 平均KDA", metrics['平均KDA'])
st.markdown("---")
# 分析模块选择
analysis_type = st.radio(
"📊 选择分析模块",
["📈 用户画像分析", "🎯 用户细分/分群分析", "🔗 关联与相关性分析",
"🔮 预测性分析", "📋 运营决策支持", "📊 可视化分析"],
horizontal=True,
label_visibility="collapsed"
)
# 执行对应分析
if analysis_type == "📈 用户画像分析":
user_profile_analysis(df, df_processed)
elif analysis_type == "🎯 用户细分/分群分析":
segmentation_analysis(df, df_processed)
elif analysis_type == "🔗 关联与相关性分析":
correlation_analysis(df, df_processed)
elif analysis_type == "🔮 预测性分析":
predictive_analysis(df, df_processed)
elif analysis_type == "📋 运营决策支持":
decision_support(df, df_processed)
elif analysis_type == "📊 可视化分析":
visualization_analysis(df, df_processed)
else:
# 欢迎页面
st.markdown("""
<div style="text-align: center; padding: 40px 20px; background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); border-radius: 20px; color: white; margin-bottom: 40px;">
<h1 style="font-size: 3.5rem; margin-bottom: 20px;">🎮 游戏玩家数据分析平台</h1>
<p style="font-size: 1.5rem; margin-bottom: 30px;">基于Python与Streamlit构建的多维度数据分析应用</p>
<div style="background: rgba(255,255,255,0.2); padding: 20px; border-radius: 15px; display: inline-block;">
<p style="font-size: 1.2rem; margin: 0;">📁 请在左侧上传CSV文件开始分析</p>
</div>
</div>
""", unsafe_allow_html=True)
# 平台特色介绍
st.markdown('<div class="section-header">🌟 平台特色</div>', unsafe_allow_html=True)
col1, col2, col3, col4 = st.columns(4)
with col1:
st.markdown("""
<div style="text-align: center; padding: 25px; background: #f8f9fa; border-radius: 15px; height: 280px;">
<div class="feature-icon">📊</div>
<div class="feature-title">多维度分析</div>
<div class="feature-description">
基于12个玩家维度的全面分析,涵盖人口统计、游戏能力、行为习惯和消费能力
</div>
</div>
""", unsafe_allow_html=True)
with col2:
st.markdown("""
<div style="text-align: center; padding: 25px; background: #f8f9fa; border-radius: 15px; height: 280px;">
<div class="feature-icon">🎯</div>
<div class="feature-title">智能分群</div>
<div class="feature-description">
支持5种用户细分方式:价值、活跃度、技能、偏好、行为模式分群
</div>
</div>
""", unsafe_allow_html=True)
with col3:
st.markdown("""
<div style="text-align: center; padding: 25px; background: #f8f9fa; border-radius: 15px; height: 280px;">
<div class="feature-icon">🔮</div>
<div class="feature-title">预测分析</div>
<div class="feature-description">
提供流失预测、付费潜力预测、段位晋升预测等智能分析功能
</div>
</div>
""", unsafe_allow_html=True)
with col4:
st.markdown("""
<div style="text-align: center; padding: 25px; background: #f8f9fa; border-radius: 15px; height: 280px;">
<div class="feature-icon">💡</div>
<div class="feature-title">决策支持</div>
<div class="feature-description">
基于数据分析结果,提供可执行的运营策略和决策建议
</div>
</div>
""", unsafe_allow_html=True)
# 功能介绍卡片
st.markdown('<div class="section-header">📋 功能模块</div>', unsafe_allow_html=True)
# 第一行功能
col1, col2, col3 = st.columns(3)
with col1:
with st.container():
st.markdown('<div class="info-card">', unsafe_allow_html=True)
st.markdown("### 📈 用户画像分析")
st.markdown("- 👥 **人口统计画像**: 性别、年龄、区域分布")
st.markdown("- ⚔️ **游戏能力画像**: 段位、胜率、KDA、位置")
st.markdown("- 🎯 **行为习惯画像**: 时长、登录频率、行为模式")
st.markdown("- 💰 **消费能力画像**: 消费分布、消费能力评估")
st.markdown('</div>', unsafe_allow_html=True)
with col2:
with st.container():
st.markdown('<div class="info-card">', unsafe_allow_html=True)
st.markdown("### 🎯 用户细分分析")
st.markdown("- 💎 **按价值分群**: 高/中/低消费用户")
st.markdown("- 🔥 **按活跃度分群**: 核心/普通/流失用户")
st.markdown("- 🎮 **按技能分群**: 新手/进阶/高手")
st.markdown("- ⭐ **按偏好分群**: 不同位置偏好")
st.markdown("- 🎭 **按行为分群**: 社交/竞技/休闲型")
st.markdown('</div>', unsafe_allow_html=True)
with col3:
with st.container():
st.markdown('<div class="info-card">', unsafe_allow_html=True)
st.markdown("### 🔗 关联性分析")
st.markdown("- 💰 **消费驱动因素**: 时长、段位、胜率与消费关系")
st.markdown("- 📊 **活跃度影响因素**: 年龄、区域对活跃度影响")
st.markdown("- 📈 **技能成长路径**: 时长、段位与KDA关联")
st.markdown("- 🗺️ **区域差异分析**: 各区域消费、段位、活跃度对比")
st.markdown('</div>', unsafe_allow_html=True)
# 第二行功能
col4, col5, col6 = st.columns(3)
with col4:
with st.container():
st.markdown('<div class="warning-card">', unsafe_allow_html=True)
st.markdown("### 🔮 预测性分析")
st.markdown("- ⚠️ **用户流失预测**: 基于登录频率、时长、行为模式")
st.markdown("- 💎 **付费潜力预测**: 基于段位、活跃度、行为模式")
st.markdown("- 🏆 **段位晋升预测**: 基于KDA、胜率、游戏时长")
st.markdown('</div>', unsafe_allow_html=True)
with col5:
with st.container():
st.markdown('<div class="success-card">', unsafe_allow_html=True)
st.markdown("### 📋 运营决策支持")
st.markdown("- 💎 **高价值用户识别**: TOP10用户及运营策略")
st.markdown("- ⚠️ **流失预警干预**: 需要召回的用户及策略")
st.markdown("- ⚔️ **匹配优化建议**: 优化对战匹配算法")
st.markdown("- 🎯 **内容推荐**: 基于位置偏好推荐")
st.markdown("- 💰 **定价策略**: 区域差异化定价")
st.markdown('</div>', unsafe_allow_html=True)
with col6:
with st.container():
st.markdown('<div class="info-card">', unsafe_allow_html=True)
st.markdown("### 📊 可视化分析")
st.markdown("- 🗺️ **用户分布**: 区域热力图、年龄/段位金字塔")
st.markdown("- 📈 **趋势分析**: 登录频率、日均时长趋势")
st.markdown("- 📊 **对比分析**: 性别消费、区域活跃度对比")
st.markdown("- 🔗 **关联分析**: 时长vs消费、胜率vs段位散点图")
st.markdown("- 🎯 **分群分析**: 用户画像雷达图")
st.markdown('</div>', unsafe_allow_html=True)
# 数据格式要求
st.markdown('<div class="section-header">📁 数据格式要求</div>', unsafe_allow_html=True)
data_format = """
<div style="background: #f8f9fa; padding: 20px; border-radius: 15px; border-left: 5px solid #3498db;">
<h4>CSV文件需包含以下12个维度:</h4>
<table style="width: 100%; border-collapse: collapse; margin-top: 15px;">
<tr style="background: #3498db; color: white;">
<th style="padding: 12px; text-align: left;">字段</th>
<th style="padding: 12px; text-align: left;">说明</th>
<th style="padding: 12px; text-align: left;">示例</th>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">用户ID</td>
<td style="padding: 10px;">玩家唯一标识</td>
<td style="padding: 10px;">100001</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">玩家性别</td>
<td style="padding: 10px;">性别</td>
<td style="padding: 10px;">男/女</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">玩家年龄</td>
<td style="padding: 10px;">年龄</td>
<td style="padding: 10px;">27</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">所在区域</td>
<td style="padding: 10px;">区域</td>
<td style="padding: 10px;">华东/华南/华北</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">游戏段位</td>
<td style="padding: 10px;">段位</td>
<td style="padding: 10px;">荣耀青铜/尊贵铂金/最强王者</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">日均时长</td>
<td style="padding: 10px;">平均每日游戏时长(小时)</td>
<td style="padding: 10px;">3.9</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">累计消费</td>
<td style="padding: 10px;">累计消费金额(元)</td>
<td style="padding: 10px;">22.41</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">擅长位置</td>
<td style="padding: 10px;">擅长的游戏位置</td>
<td style="padding: 10px;">坦克/刺客/辅助/射手</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">综合胜率</td>
<td style="padding: 10px;">综合胜率(0-1之间)</td>
<td style="padding: 10px;">0.483</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">KDA指数</td>
<td style="padding: 10px;">KDA指数</td>
<td style="padding: 10px;">5.4</td>
</tr>
<tr style="border-bottom: 1px solid #ddd;">
<td style="padding: 10px;">登录频率</td>
<td style="padding: 10px;">登录频率</td>
<td style="padding: 10px;">每天/每周3-5次/每月几次</td>
</tr>
<tr>
<td style="padding: 10px;">行为模式</td>
<td style="padding: 10px;">行为模式类型</td>
<td style="padding: 10px;">竞技型/社交型/休闲型</td>
</tr>
</table>
</div>
"""
st.markdown(data_format, unsafe_allow_html=True)
if __name__ == "__main__":
main()