本文是 RAG 系列的上篇
适合读者:懂 Python、没做过 RAG的后端开发者。
读完本文,你将能理解 RAG 的每一个细节,并独立搭建从实验到生产的完整系统。
前期回顾
1. 引言:为什么需要 RAG
三个真实场景
场景一:公司知识库问答
你的公司有几百份员工手册、产品文档、合同模板,新员工每天都要花大量时间翻找。如果直接问 ChatGPT:
arduino
员工:"我们公司新员工有几天年假?"
GPT:(凭训练数据猜)"根据劳动法,一般有 5 天..."但你们公司规定是"试用期满 3 个月后享有 10 天带薪年假"。GPT 无从知晓,只能胡猜。
有了 RAG 之后:
arduino
员工:"我们公司新员工有几天年假?"
RAG:(检索员工手册)找到:"试用期满3个月后享有10天带薪年假"
AI回答:"根据公司员工手册第3章,试用期满3个月后即享有10天带薪年假。"场景二:实时价格查询
电商平台的商品价格每天变化。LLM 的训练数据可能是 6 个月前的,价格早已过期。RAG 可以连接你的实时价格数据库,每次查询时先检索最新价格,再生成回答。
场景三:私有文档问答
医院的病历系统、律所的案件文档、银行的合规手册------这些数据绝对不能传给第三方 AI。通过 RAG,可以在本地部署嵌入模型和向量库,数据完全不出内网,同时享受 AI 问答的便利。
RAG 是什么
RAG(Retrieval-Augmented Generation,检索增强生成)= 先检索,再生成。
核心思路极其简单:在让 LLM 回答问题之前,先从你的文档库里找出最相关的内容,把这些内容塞进 Prompt,让 LLM 基于真实文档作答,而不是凭空发挥。
第一部分:RAG 核心原理
2.1 LLM 的三大局限
理解 RAG 为什么有价值,先要理解 LLM 的局限在哪里:
| 局限 | 具体表现 | RAG 的解法 |
|---|---|---|
| 知识截止日期 | 模型只知道训练截止前的事,对最新内容一无所知 | 把最新文档存入向量库,查询时实时检索 |
| 不了解私有数据 | 公司内部文档、数据库、手册,模型完全不知道 | 将内部文档向量化,存入本地向量库 |
| 幻觉(Hallucination) | 不知道时会"编造"一个听起来合理的答案 | 强制让 LLM 基于检索到的真实文档作答 |
幻觉到底有多危险?
csharp
# 没有 RAG
问:Python 3.12 的新特性是什么?
答:Python 3.12 引入了新的 match-case 语法...(这是 3.10 的特性,不是 3.12!)
# 有 RAG(从最新文档检索)
问:Python 3.12 的新特性是什么?
RAG 检索到 Python 3.12 发布说明文档后:
答:Python 3.12 主要新特性包括:更友好的错误提示、f-string 嵌套改进、
sys.monitoring 调试 API 等(基于 Python 官方文档)。2.2 RAG 工作流程
RAG 有两个阶段:离线索引 (建立知识库)和在线查询 (检索并回答): 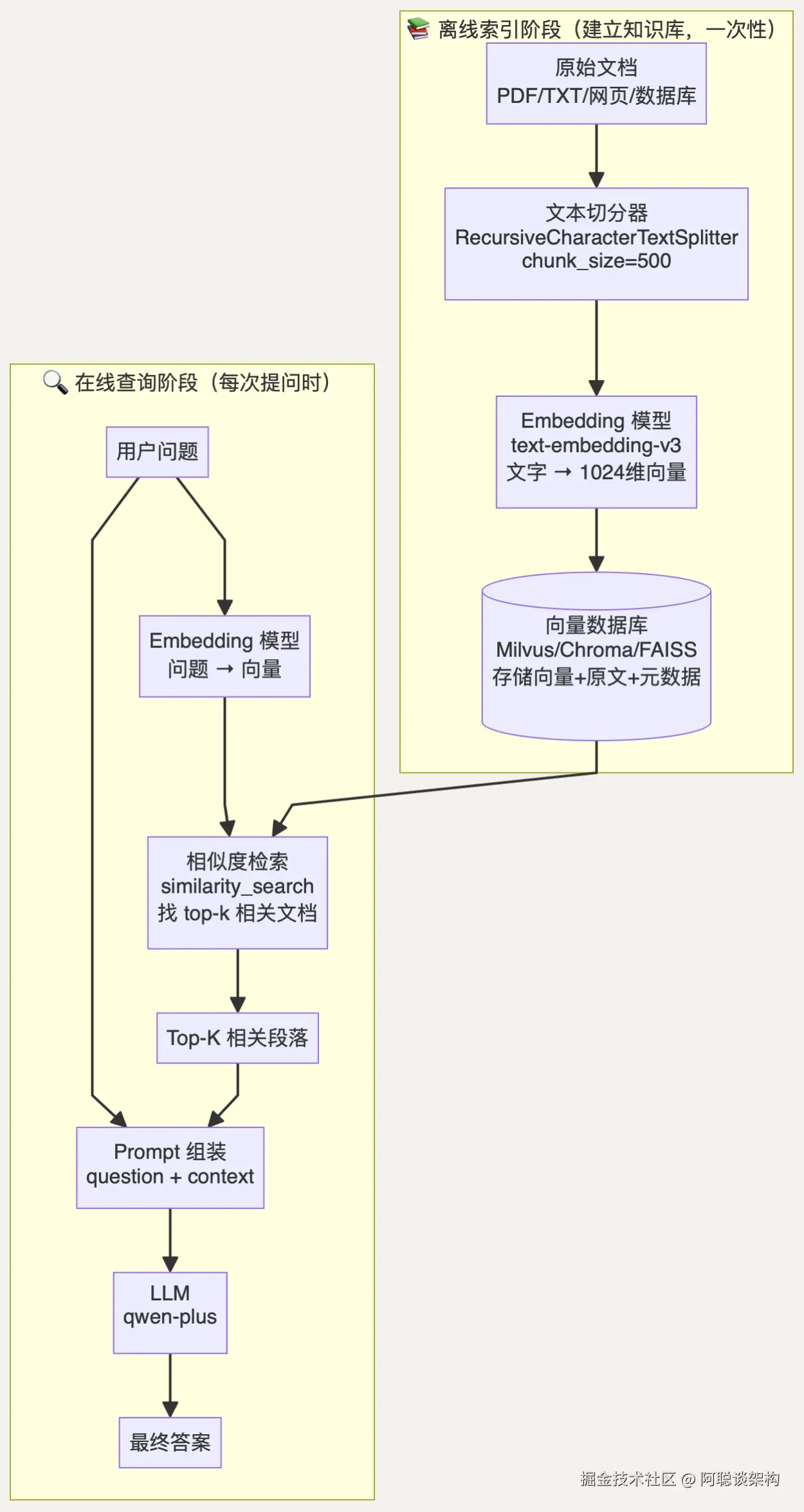
关键洞察:索引阶段只运行一次(或定期更新),查询阶段每次提问都运行。系统的响应速度主要取决于查询阶段,而查询阶段的向量检索通常只需要几毫秒。
2.3 核心组件详解
组件一:文本切分器(Text Splitter)
为什么要切分?
嵌入模型有 token 上限(通常 512-8192 token),一篇几千字的文章无法整体嵌入。更重要的是,一整篇文章嵌入后,向量代表了"整体语义",而用户通常只问其中的某个细节------这会导致检索精度下降。
切分成 500 字左右的小块,每块的语义更聚焦,检索精度更高。
ini
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块最大字符数(不是 token 数!)
chunk_overlap=50, # 相邻块的重叠字符数
separators=["\n\n", "\n", "。", ",", " ", ""], # 切分优先级
)chunk_size=500:适合中文文档,英文可调大到 1000chunk_overlap=50:防止一段话被切在两个 chunk 边界时丢失信息separators:优先按段落(\n\n)切,实在没有才按字符切
组件二:Embedding 模型
将文字转成数字向量。本项目使用阿里百炼的 text-embedding-v3:
ini
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v3",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
dimensions=1024, # 支持 512/1024/1536/2048,越大越准但越慢
)组件三:向量数据库
存储"文本块的向量"和"原始文本",支持快速相似度查询。本项目使用 Milvus:
- Milvus Lite :本地文件模式(
uri="./xxx.db"),零服务依赖,全平台可用 - Milvus Standalone:Docker 服务,适合团队共享
- Zilliz Cloud:全托管服务,适合生产不想自维护
组件四:LLM(生成器)
最后一步,拿到检索到的文档块 + 用户问题,生成最终答案。本项目使用 qwen-plus:
ini
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
temperature=0.3, # RAG 场景建议低温度,答案更忠实于文档
)2.4 文本切分的 4 种策略
LangChain 提供了多种切分器,根据文档类型选择:
策略一:按字符递归切分(最常用)
ini
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 适合:通用文本、中英文混合文档
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", ",", " ", ""],
)
chunks = splitter.split_text(long_text)特点:按优先级尝试不同的分隔符,尽量保持段落完整。这是最推荐的默认选项。
策略二:按固定字符切分
ini
from langchain_text_splitters import CharacterTextSplitter
# 适合:格式规整的文档,如 CSV、固定格式日志
splitter = CharacterTextSplitter(
separator="\n", # 只按换行符切
chunk_size=300,
chunk_overlap=0,
)特点:简单粗暴,只按指定分隔符切,可能切断句子。
策略三:按 Token 切分
ini
from langchain_text_splitters import TokenTextSplitter
# 适合:需要精确控制 token 数量时(防止超出模型上限)
splitter = TokenTextSplitter(
chunk_size=512, # 以 token 为单位,不是字符
chunk_overlap=50,
)特点:以 token(词语/子词)为单位,比字符更准确地控制 API 成本。
策略四:文档特定切分器
ini
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 适合:Markdown 文档,按标题层级切分
headers_to_split_on = [
("#", "h1"), ("##", "h2"), ("###", "h3"),
]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)特点:针对 Markdown、HTML、代码等特定格式保留文档结构信息。
选型建议:
| 场景 | 推荐策略 |
|---|---|
| 普通文章/手册 | RecursiveCharacterTextSplitter(默认首选) |
| 精确控制 API cost | TokenTextSplitter |
| Markdown 技术文档 | MarkdownHeaderTextSplitter |
| 代码文件 | Language.PYTHON 专用切分器 |
2.5 Embedding 向量化原理
通俗解释:用数字描述"意思"
把文字转成向量,本质上是用数字来描述一段文字的"语义坐标"。
arduino
"猫是宠物" → [0.12, 0.87, 0.34, ...] ←──┐ 距离很近(都是动物/宠物话题)
"狗是忠实伙伴" → [0.11, 0.83, 0.38, ...] ←──┘
"股票涨了" → [0.89, 0.12, 0.76, ...] ←── 距离很远(完全不同领域)text-embedding-v3 模型输出的是 1024 维向量,也就是每段文字被表示为 1024 个浮点数。
相似度计算:余弦相似度
找"语义最相近"的文档块,本质是计算余弦相似度(或内积距离):
ini
余弦相似度 = (向量A · 向量B) / (|A| × |B|)
结果范围:-1 到 1
1 = 完全相同方向 = 语义完全相同
0 = 垂直 = 语义无关
-1 = 相反方向 = 语义相反向量检索的速度:1024 维向量的余弦相似度计算只是一个矩阵乘法操作,在向量数据库的优化索引(HNSW、IVF_FLAT)下,从百万条记录中找 top-3 通常只需 1-10 毫秒。
第二部分:第一个 Milvus RAG 程序(04_milvus_rag.py)
安装步骤
bash
# 进入项目目录
cd ai-agent-test
# 安装 Milvus 相关依赖(全平台兼容,含 macOS Intel)
uv sync --extra milvus
# 设置 API Key(百炼控制台获取:https://bailian.console.aliyun.com/)
export DASHSCOPE_API_KEY="your_api_key_here"
# 运行第一个示例
uv run python lessons/06_rag/04_milvus_rag.py完整代码走读
04_milvus_rag.py 是最小可运行的 Milvus RAG 示例,约 100 行,覆盖了 RAG 的完整流程:
第一步:创建 LLM 和 Embedding 模型
python
# 来自 04_milvus_rag.py
def create_llm() -> ChatOpenAI:
"""创建百炼 API ChatOpenAI 实例。"""
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
print("错误:请设置环境变量 DASHSCOPE_API_KEY")
sys.exit(1)
return ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=api_key,
)
def create_embeddings() -> OpenAIEmbeddings:
"""创建百炼嵌入模型。"""
api_key = os.getenv("DASHSCOPE_API_KEY")
return OpenAIEmbeddings(
model="text-embedding-v3",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=api_key,
dimensions=TEXT_EMBEDDING_V3_DIMENSIONS, # = 1024
)为什么 LLM 和 Embedding 用同一个 API Key? 百炼平台同时提供对话模型(qwen-plus)和嵌入模型(text-embedding-v3),用同一个 Key 调用不同接口。这是百炼兼容 OpenAI 接口格式的设计。
第二步:准备演示文档
python
# 来自 04_milvus_rag.py
def build_demo_documents() -> list[Document]:
"""准备演示文档。"""
return [
Document(page_content="LangChain 是一个用于构建 LLM 应用的框架,支持 Prompt、链、工具与 Agent。"),
Document(page_content="Milvus 是开源向量数据库,擅长海量向量检索,支持 HNSW、IVF 等索引。"),
Document(page_content="RAG 的核心是先检索再生成:把相关文档拼接进提示词,减少模型幻觉。"),
Document(page_content="FAISS 适合本地离线相似检索,Milvus 更适合服务化与分布式检索场景。"),
]为什么用 Document 对象而不是纯字符串? Document 除了 page_content,还可以携带 metadata(元数据),比如 {"source": "手册第3章", "year": 2024}。元数据在生产环境中非常重要,可以用来过滤检索范围("只搜索 2024 年的文档")。
第三步:初始化 Milvus 并写入文档
ini
# 来自 04_milvus_rag.py(main 函数中)
db_path = Path("milvus_demo.db")
should_reset = os.getenv("MILVUS_RESET_DEMO_DB", "").strip() == "1"
if should_reset and db_path.exists():
db_path.unlink()
vectorstore = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="chapter06_milvus_demo",
connection_args={"uri": str(db_path)}, # uri 是本地文件路径 = Milvus Lite 模式
)from_documents 做了什么?
- 对每个 Document 调用
embeddings.embed_documents()生成 1024 维向量 - 将向量 + 原始文本 + 元数据批量写入本地
.db文件 - 返回一个
Milvus实例,可以直接调用similarity_search等方法
connection_args={"uri": str(db_path)} :这是 Milvus Lite 的关键。当 URI 是一个本地文件路径(以 .db 结尾),Milvus 就工作在 Lite 模式,把所有数据存在这个文件里,不需要任何服务进程。
第五步:构建 RAG 链并提问
ini
# 来自 04_milvus_rag.py
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
rag_prompt = ChatPromptTemplate.from_messages([
(
"system",
"你是问答助手。请严格依据上下文回答;如果上下文没有答案,请明确说明不知道。\n\n上下文:\n{context}",
),
("human", "{question}"),
])
# 标准 LCEL RAG 链:检索 -> 拼接 Prompt -> LLM -> 文本输出
rag_chain = (
{
"context": retriever | format_docs, # 检索并格式化为文本
"question": RunnablePassthrough(), # 原样传递用户问题
}
| rag_prompt
| llm
| StrOutputParser()
)
answer = rag_chain.invoke("Milvus 和 FAISS 在使用场景上有什么区别?")LCEL 语法解读 :| 管道操作符将多个组件串联,数据从左到右流动。RunnablePassthrough() 表示"原样传递",不做任何处理。整个 rag_chain 只是一个声明,调用 .invoke() 时才真正执行。
运行步骤与预期输出
arduino
uv run python lessons/06_rag/04_milvus_rag.py预期输出:
markdown
============================================================
Milvus Lite RAG 示例
============================================================
👤 问题:Milvus 和 FAISS 在使用场景上有什么区别?
🤖 回答:根据文档,FAISS 适合本地离线相似检索,而 Milvus 更适合服务化与分布式
检索场景。Milvus 是开源向量数据库,支持 HNSW、IVF 等索引,擅长海量
向量检索。
👤 问题:RAG 的核心流程是什么?
🤖 回答:RAG 的核心是先检索再生成:将相关文档拼接进提示词,减少模型幻觉。
✅ 运行完成:已使用 Milvus Lite 完成向量检索与回答。第三部分:生产级 RAG 链(07_milvus_vector_store_rag.py)
与 04 脚本的区别
07_milvus_vector_store_rag.py 是 04_milvus_rag.py 的升级版,主要增加了:
| 功能 | 04_milvus_rag.py | 07_milvus_vector_store_rag.py |
|---|---|---|
| 文本切分 | ❌ 直接用原始文档 | ✅ RecursiveCharacterTextSplitter |
| 文档规模 | 4 条短文本 | 6 篇完整文档,含元数据 |
| Prompt 设计 | 简单一行 | 详细的格式化要求和边界说明 |
| 语义搜索演示 | ❌ | ✅ 单独演示 similarity_search |
LCEL 链原理深解
理解 LCEL(LangChain Expression Language)是理解所有 RAG 链的关键: 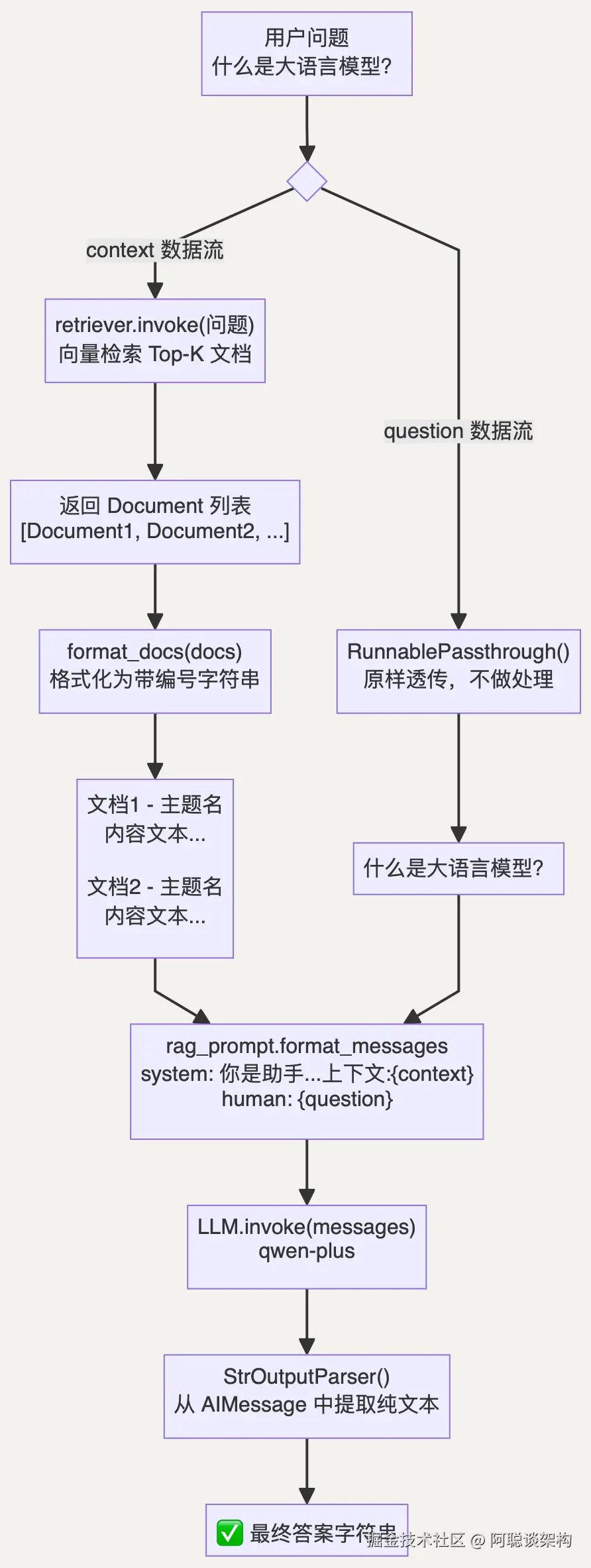
核心函数:build_vector_store
python
# 来自 07_milvus_vector_store_rag.py
def build_vector_store(
documents: list[Document],
embeddings: OpenAIEmbeddings,
) -> Milvus:
"""
从文档列表构建 Milvus 向量存储。
步骤:
1. 文本分割(将长文档切成小块)
2. 嵌入计算(调用百炼 API 将文本转为 1024 维向量)
3. 构建 Milvus Lite 索引(写入本地 .db 文件)
"""
print("正在构建 Milvus 向量存储...")
# 步骤1:文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", ",", " ", ""],
)
chunks = text_splitter.split_documents(documents)
print(f" 文档数量:{len(documents)} → 分割后块数:{len(chunks)}")
# 如有旧数据文件则删除,保证本次演示数据干净
db_path = Path(MILVUS_DB_PATH)
if db_path.exists():
db_path.unlink()
# 步骤2 + 3:计算嵌入并写入 Milvus Lite(本地文件)
print(" 正在计算嵌入向量(调用百炼 API)...")
vectorstore = Milvus.from_documents(
documents=chunks,
embedding=embeddings,
collection_name=COLLECTION_NAME,
connection_args={"uri": MILVUS_DB_PATH},
)
print(f" 向量存储构建完成!共索引 {len(chunks)} 个文本块")
return vectorstore核心函数:build_rag_chain
python
# 来自 07_milvus_vector_store_rag.py
def build_rag_chain(vectorstore: Milvus, llm: ChatOpenAI):
"""构建完整的 RAG 链(使用 LCEL)。"""
retriever = vectorstore.as_retriever(
search_kwargs={"k": 3} # 每次检索返回 3 个最相关文档块
)
rag_prompt = ChatPromptTemplate.from_messages([
(
"system",
"""你是一个 AI 技术专家助手。请基于以下检索到的文档内容回答用户问题。
回答要求:
1. 只使用提供的文档内容回答,不要添加文档中没有的信息
2. 如果文档中没有相关信息,请明确说明
3. 回答要简洁、准确、有条理
===== 检索到的文档 =====
{context}
========================""",
),
("human", "{question}"),
])
def format_docs(docs: list[Document]) -> str:
"""将文档列表格式化为带编号的字符串,方便 LLM 识别文档边界。"""
parts = []
for i, doc in enumerate(docs, 1):
topic = doc.metadata.get("topic", "")
parts.append(f"[文档{i} - {topic}]\n{doc.page_content.strip()}")
return "\n\n".join(parts)
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough(),
}
| rag_prompt
| llm
| StrOutputParser()
)
return rag_chain关于 Prompt 设计的重要原则:
- 用
===等分隔符清晰标记文档边界,帮助 LLM 区分"检索文档"和"用户问题" - 明确要求"只用文档内容回答",这是减少幻觉的关键指令
- 用
{context}和{question}作为占位符,LCEL 会自动填充
第四部分:多轮对话 RAG(08_milvus_conversational_rag.py)
为什么需要问题重构
普通 RAG 在多轮对话中会失效。根本原因:每次检索都是独立的,不知道对话历史。
arduino
第1轮:北京有哪些必去的景点?
→ 正确检索到"北京旅游攻略"✅
第2轮:那里的特色美食是什么?
→ "那里"是什么?检索引擎不知道!❌
→ 直接用"那里的特色美食是什么?"检索,结果一片混乱
第3轮:最好什么季节去?
→ 更模糊了,"去哪里"?完全无法检索❌解决方案:问题重构(Question Contextualization)
在每次检索前,用 LLM 先把"含有指代的问题"改写成"独立完整的问题":
csharp
历史对话:
[用户] 北京有哪些必去的景点?
[AI] 北京的景点有故宫、长城...
新问题:"那里的特色美食是什么?"
↓ LLM 问题重构
改写为:"北京有哪些特色美食?" ← 独立完整,可正确检索完整流程图
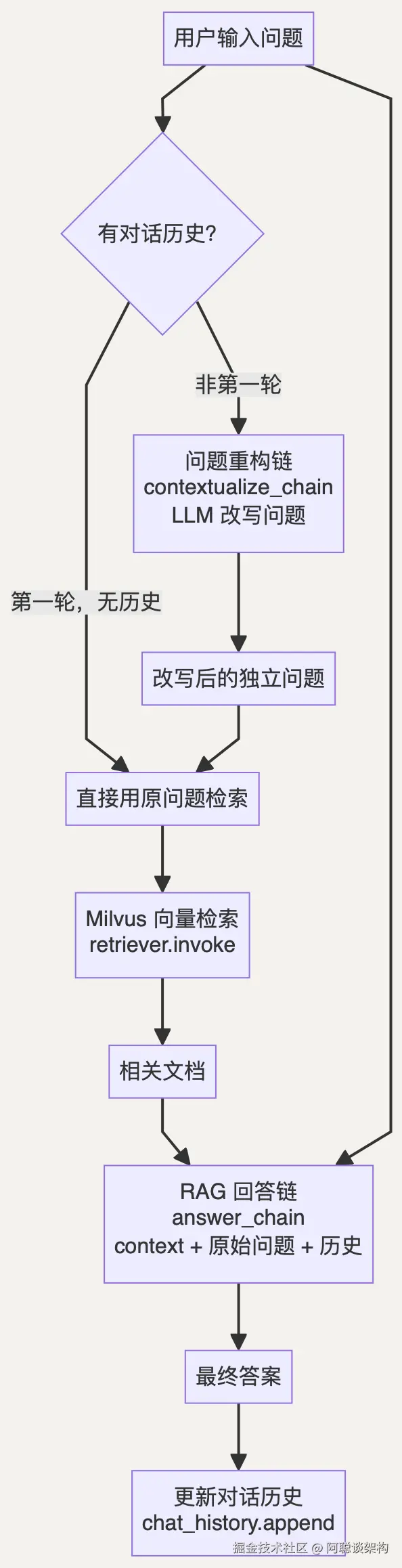
注意细节 :传给 answer_chain 的问题是原始问题 (user_message),而检索用的是改写问题 (contextualized_q)。这样 LLM 生成的回答保持了对话的自然感,而检索的精度也得到保证。
核心代码:ConversationalRAG 类
ini
# 来自 08_milvus_conversational_rag.py
class ConversationalRAG:
def __init__(self, llm: ChatOpenAI, vectorstore: Milvus) -> None:
self.llm = llm
self.vectorstore = vectorstore
self.retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
self.chat_history: list = [] # 存储 HumanMessage / AIMessage
# ── 问题重构提示 ──
self.contextualize_prompt = ChatPromptTemplate.from_messages([
(
"system",
"""你的任务是将用户的最新问题改写为一个独立的、完整的问题。
改写时要结合对话历史,使新问题不依赖上下文也能被理解。
规则:
- 如果用户问题已经是独立完整的,直接返回原问题
- 如果用户问题依赖历史(如"那它呢"、"还有哪些"),结合历史改写
- 只输出改写后的问题,不要解释""",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
# ── RAG 回答提示 ──
self.answer_prompt = ChatPromptTemplate.from_messages([
(
"system",
"""你是一个旅游助手,基于检索到的旅游攻略回答问题。
回答要具体、有用、友好。
===== 相关旅游资料 =====
{context}
========================""",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
self._build_chains()
python
# 来自 08_milvus_conversational_rag.py
def _contextualize_question(self, question: str) -> str:
"""根据对话历史重构问题。"""
if not self.chat_history:
return question # 第一轮无历史,直接返回,节省一次 LLM 调用
contextualized = self.contextualize_chain.invoke({
"chat_history": self.chat_history,
"question": question,
})
return contextualized
def chat(self, user_message: str, verbose: bool = True) -> str:
"""处理一轮对话,返回 AI 回答。"""
# 步骤1:根据历史重构问题
contextualized_q = self._contextualize_question(user_message)
# 步骤2:使用改写后的问题检索
docs = self.retriever.invoke(contextualized_q)
# 步骤3:格式化检索结果
context = self.format_docs(docs)
# 步骤4:生成回答(传入原始问题,保持对话自然感)
answer = self.answer_chain.invoke({
"chat_history": self.chat_history,
"question": user_message, # ← 原始问题
"context": context, # ← 基于改写问题检索的文档
})
# 步骤5:更新历史,供下一轮使用
self.chat_history.append(HumanMessage(content=user_message))
self.chat_history.append(AIMessage(content=answer))
return answer多轮对话示例
css
============================================================
旅游助手对话演示(对话式 RAG,Milvus 版)
============================================================
👤 用户:北京有哪些必去的景点?
[检索结果] 相关目的地:['北京']
🤖 AI:北京有故宫、长城(推荐慕田峪或八达岭)、天安门广场、颐和园...
👤 用户:那里的特色美食是什么?
[问题重构] → 北京的特色美食是什么? ← 自动补全了"北京"
[检索结果] 相关目的地:['北京']
🤖 AI:北京的特色美食有北京烤鸭(全聚德、大董)、炸酱面、豆汁、爆肚...
👤 用户:最好什么季节去?
[问题重构] → 去北京旅游最好是什么季节? ← 从历史推断出主题是北京
[检索结果] 相关目的地:['北京']
🤖 AI:去北京旅游最佳季节是春季(3-5月)和秋季(9-11月),气候宜人...第五部分:生产部署(09_milvus_production_rag.py)
8 大生产最佳实践
09_milvus_production_rag.py 是本章最成熟的脚本,直接可作为生产项目的起始模板:
| 实践 | 说明 | 关键代码 |
|---|---|---|
| 1. 环境校验 | 启动前检查 API Key,提前失败,避免深层报错 | validate_environment() |
| 2. 配置集中管理 | 所有参数在顶部统一定义,一改全生效 | CHUNK_SIZE, TOP_K, MMR_LAMBDA |
| 3. 集合生命周期 | 已有则复用,首次才新建,支持强制重建 | load_or_create_vectorstore() |
| 4. 分批入库 | 大数据量时分批处理,避免内存压力 | ingest_batch() |
| 5. 来源引用 | 每段上下文标注来源,答案可追溯 | format_docs_with_source() |
| 6. MMR 多样性 | 避免检索到大量重复文档块 | search_type="mmr" |
| 7. 元数据过滤 | 限定检索范围,提升精度 | expr='category == "rag"' |
| 8. 质量评估 | 自动化测试,上线前验证效果 | evaluate_rag() |
实践一:环境校验
python
# 来自 09_milvus_production_rag.py
def validate_environment() -> str:
"""
环境校验(生产第一步):检查必要环境变量是否存在。
在做任何 API 调用之前先校验,避免在深层调用栈中才报出"无效 key"的错误。
"""
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
print("=" * 60)
print("❌ 环境变量未设置:DASHSCOPE_API_KEY")
print("=" * 60)
print("解决方法:")
print(" export DASHSCOPE_API_KEY='your_api_key_here'")
print("获取 API Key:https://bailian.console.aliyun.com/")
sys.exit(1)
print(f"✅ DASHSCOPE_API_KEY 已设置(前8位:{api_key[:8]}...)")
return api_key实践二:配置集中管理
ini
# 来自 09_milvus_production_rag.py(顶部配置区)
MILVUS_URI = "milvus_production_rag.db"
COLLECTION_NAME = "chapter06_production_rag"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
TOP_K = 3
MMR_FETCH_K = 10
MMR_LAMBDA = 0.6 # 0=纯多样性,1=纯相关性;0.6 是实践均衡值
INGEST_BATCH_SIZE = 50
EMBEDDING_DIMENSIONS = 1024
LLM_TEMPERATURE = 0.3 # RAG 场景低温度,答案更忠实于文档实践三:集合生命周期管理
ini
# 来自 09_milvus_production_rag.py
def load_or_create_vectorstore(
embeddings: OpenAIEmbeddings,
documents: list[Document] | None = None,
reset: bool = False,
) -> Milvus:
"""
生产模式:加载已有集合,或在首次运行时新建。
- 已有集合 → 直接连接(保留数据)
- 不存在 → 用初始文档新建
- reset=True → 强制删旧建新(谨慎使用)
"""
db_path = Path(MILVUS_URI)
collection_exists = db_path.exists() and db_path.stat().st_size > 0
if reset:
if db_path.exists():
db_path.unlink()
collection_exists = False
if collection_exists:
# 连接已有集合:使用 Milvus() 构造函数(不重新写入)
vectorstore = Milvus(
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_args={"uri": MILVUS_URI},
)
return vectorstore
# 新建集合
return _build_vectorstore(documents, embeddings, drop_old=True)Milvus.from_documents() vs Milvus() 的区别:
ini
# 第一次建库(写入数据)
vectorstore = Milvus.from_documents(documents=docs, ...)
# 后续使用(连接已有集合,不重复写入)
vectorstore = Milvus(embedding_function=embeddings, collection_name="...", ...)实践四:分批入库
python
# 来自 09_milvus_production_rag.py
def ingest_batch(
vectorstore: Milvus,
documents: list[Document],
batch_size: int = INGEST_BATCH_SIZE,
) -> int:
"""
批量入库:将大量文档分批处理,避免单次请求过大导致内存压力。
适合首次建库时有数万篇文档需要入库的场景。
"""
total_chunks = 0
total_batches = (len(documents) + batch_size - 1) // batch_size
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
batch_num = i // batch_size + 1
print(f" 处理第 {batch_num}/{total_batches} 批({len(batch)} 篇文档)...")
chunks_added = ingest_documents(vectorstore, batch, drop_old=False)
total_chunks += chunks_added
return total_chunks实践五:来源引用
python
# 来自 09_milvus_production_rag.py
def format_docs_with_source(docs: list[Document]) -> str:
"""
将文档格式化为带来源标注的上下文字符串。
每段都注明来源,让 LLM 的回答可追溯,也便于后期做审计。
"""
parts = []
for i, doc in enumerate(docs, 1):
source = doc.metadata.get("source", "未知来源")
category = doc.metadata.get("category", "")
label = f"[来源: {source}]" + (f" [{category}]" if category else "")
parts.append(f"{label}\n{doc.page_content.strip()}")
return "\n\n".join(parts)实践八:RAG 质量评估
python
# 来自 09_milvus_production_rag.py
def evaluate_rag(rag_chain, test_cases: list[dict]) -> dict:
"""
简易 RAG 质量评估(生产上线前的冒烟测试)。
检查答案中是否包含预期关键词,适合 CI/CD 流水线集成。
"""
passed = 0
for case in test_cases:
answer = rag_chain.invoke(case["question"])
hit = any(kw.lower() in answer.lower() for kw in case["expected_keywords"])
if hit:
passed += 1
pass_rate = passed / len(test_cases)
# pass_rate >= 0.8:质量良好;< 0.5:需要优化
return {"total": len(test_cases), "passed": passed, "pass_rate": pass_rate}三种部署模式迁移路径
Milvus 最大的优势之一:只改一行配置,平滑从开发迁移到生产。
╔═══════════════╗ ╔══════════════════════╗ ╔═══════════════════════╗
║ 开发阶段 ║────▶║ 测试/小规模生产 ║────▶║ 大规模生产 ║
║ Milvus Lite ║ ║ Milvus Standalone ║ ║ Zilliz Cloud ║
╠═══════════════╣ ╠══════════════════════╣ ╠═══════════════════════╣
║ 本地文件 ║ ║ Docker 容器 ║ ║ 全托管服务 ║
║ 数据 < 100万 ║ ║ 数据 < 1 亿 ║ ║ 无上限 ║
╚═══════════════╝ ╚══════════════════════╝ ╚═══════════════════════╝迁移代码(业务代码零改动,只改连接参数):
ini
# 开发阶段(Milvus Lite)
CONNECTION_ARGS = {"uri": "./milvus_production_rag.db"}
# 测试/单机生产(Milvus Standalone)
# 先启动 Docker:docker run -d -p 19530:19530 milvusdb/milvus:latest
CONNECTION_ARGS = {"uri": "http://127.0.0.1:19530"}
# 大规模生产(Zilliz Cloud,访问 https://zilliz.com/cloud 申请)
CONNECTION_ARGS = {
"uri": "https://your-cluster.zillizcloud.com",
"token": "your_api_key",
}
# ─── 以下业务代码三种模式完全相同 ───
vectorstore = Milvus(
embedding_function=embeddings,
collection_name="production_kb",
connection_args=CONNECTION_ARGS, # ← 只改这里
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# RAG 链代码...完全不变7. 学习路径与速查表
推荐学习路径(入门) :
01_simple_rag.py → 04_milvus_rag.py → 07_milvus_vector_store_rag.py
→ 08_milvus_conversational_rag.py → 09_milvus_production_rag.py进阶路径 :在入门路径的基础上加上 05_milvus_advanced_rag.py、06_faiss_rag.py、02/03_vector_store_rag/conversational_rag.py。
一键安装命令速查
bash
cd ai-agent-test
# Milvus(推荐,全平台,含 macOS Intel)
uv sync --extra milvus
# Chroma(需要 macOS 14+ 或 Linux)
uv sync --extra rag
# FAISS(需要 Linux / macOS 14+ / Windows,不支持旧 macOS Intel)
uv sync --extra faiss
# 全部安装
uv sync --extra milvus --extra rag --extra faiss
# 设置 API Key
export DASHSCOPE_API_KEY="your_key"常见错误 FAQ
Q1:出现 ModuleNotFoundError: No module named 'pkg_resources'?
bash
# 依赖版本不对,重新同步
cd ai-agent-test && git pull && uv sync --extra milvus脚本内已内置兼容垫片,正常情况下不会出现这个错误。如果出现,说明依赖版本混乱,重新 sync 即可。
Q2:DASHSCOPE_API_KEY 环境变量失效?
bash
# 检查是否设置成功
echo $DASHSCOPE_API_KEY
# 如果为空,重新设置(每个新终端会话都需要重新 export)
export DASHSCOPE_API_KEY="sk-..."
# 或者写入 ~/.zshrc / ~/.bashrc 永久生效
echo 'export DASHSCOPE_API_KEY="sk-..."' >> ~/.zshrc
source ~/.zshrcQ3:grpc.RpcError 或 gRPC 相关报错?
bash
# 通常是 pymilvus 与 milvus-lite 版本不兼容
# 重新同步依赖(项目已锁定兼容版本)
cd ai-agent-test && uv sync --extra milvusQ4:macOS Intel 用户 FAISS 安装失败?
旧版 macOS Intel(Ventura 13 及以下)没有预编译的 FAISS wheel。
bash
# 直接用 Milvus 替代,功能完全等效
uv sync --extra milvus
uv run python lessons/06_rag/04_milvus_rag.pyQ5:Milvus.from_documents() vs Milvus() 什么时候用哪个?
ini
# 第一次建库,需要写入数据 → from_documents
vectorstore = Milvus.from_documents(documents=docs, embedding=embeddings, ...)
# 后续查询,集合已存在,不重新写入 → Milvus() 构造函数
vectorstore = Milvus(embedding_function=embeddings, collection_name="...", ...)Q6:drop_old=True 会删数据,什么时候用?
ini
# 仅在需要完全重建知识库时使用(更换嵌入模型、文档结构大改)
vectorstore = Milvus.from_documents(documents=all_new_docs, ..., drop_old=True)
# 增量更新时用 add_documents,不要用 drop_old=True
vectorstore.add_documents(new_docs)Q7:对话式 RAG 每轮多一次 LLM 调用,怎么优化?
第一轮对话无历史时会跳过重构,直接使用原问题:
python
def _contextualize_question(self, question: str) -> str:
if not self.chat_history:
return question # 无历史时直接返回,节省 LLM 调用
return self.contextualize_chain.invoke(...)对于对延迟要求极高的场景,可以考虑:将历史拼接进 Prompt 而不是用独立 LLM 调用来重构;或者只在检测到代词/指代词时才触发重构。
📌 下一章预告:AI 很厉害,但它不知道你私有数据库里有什么。第06章学 RAG(检索增强生成)下篇,聊一聊常用的用于生产环境的几种向量库
作者:阿聪谈架构公众号:阿聪谈架构 (分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码
本文属于《AI开发入门系列》,后续会持续更新。 关注博主,第一时间收到最新文章,获取完整学习路线与资料